财经资讯爬虫
-
数据来源
港股金融界 :http://hk.jrj.com.cn/
资本邦 :http://www.chinaipo.com/
智通财经网:http://www.zhitongcaijing.com/
腾讯财经:https://pacaio.match.qq.com/ -
资讯表结构
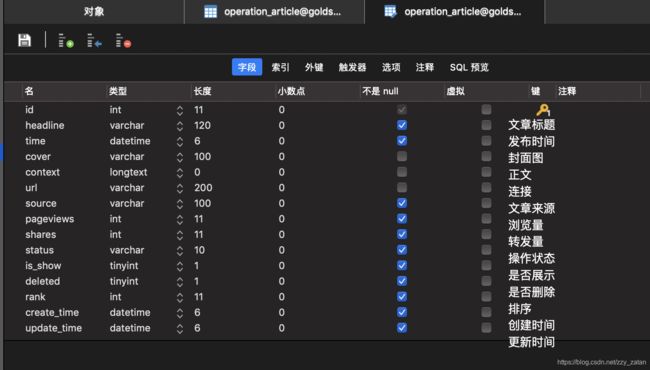
-
使用 requests 模块爬取资讯,清洗数据,存放到Django models中
"""
发现页新闻爬取
定时任务
"""
import json
import re
import threading
from io import BytesIO
from bs4 import BeautifulSoup
import requests
from django.core.files import File
from lxml import etree
import os, django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "goldshell_end.settings")
django.setup()
from operation.models import Article
class JinRongJie(object):
"""
港股金融界
"""
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Accept": 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive"
}
def get_url_list(self):
"""
获取新闻列表
:return:
"""
for i in ["1", "2", "3", "4"]:
if i == "1":
url = 'http://hk.jrj.com.cn/list/hgxw.shtml'
else:
url = f'http://hk.jrj.com.cn/list/hgxw-{i}.shtml'
try:
response = requests.get(url=url, headers=self.headers)
except Exception:
return False, '服务器网络故障'
if response.status_code != 200:
return False, '来源服务器错误'
context = response.content.decode('gbk')
"""
提取有效数据
新闻列表
"""
detail_html = etree.HTML(context)
url_list = detail_html.xpath('//div[@class="list-s1"]/ul/li/a/@href')
self.detail_data(url_list) # 获取新闻详情
return True
def detail_data(self, url_list):
"""
获取新闻详情
:param data:
:return:
"""
context_list = []
for url in url_list:
try:
response = requests.get(url=url, headers=self.headers)
except Exception:
return False, '服务器网络故障'
if response.status_code != 200:
return False, '来源服务器错误'
context = response.content.decode('gb18030')
# context = response.text
detail_html = etree.HTML(context)
"""
提取有效数据
headline # 文章标题
time # 发布时间
cover # 封面图
context # 正文
url # 连接
source # 文章来源
"""
item = {}
try:
item["time"] = detail_html.xpath('//p[@class="inftop"]/span/text()')[0]
item["time"] = ''.join(item["time"].split("\r\n"))
item["headline"] = detail_html.xpath('//div[@class="titmain"]/h1/text()')
item["headline"] = ''.join(''.join(item["headline"]).split("\r\n"))
con_list = detail_html.xpath('//div[@class="texttit_m1"]/p/text()')
item["context"] = ''
for con in con_list:
item["context"] = item["context"] + ''
+ con + ''
item["context"] = ''.join(''.join(item["context"]).split('\u3000\u3000'))
item["url"] = url
item["source"] = "金融界"
try:
if len(Article.objects.filter(url=item['url'])) == 0:
Article.objects.create(
headline=item["headline"],
time=item["time"],
context=item["context"],
url=item["url"],
source=item["source"],
status="WAITING"
)
except Exception:
'数据写入失败'
context_list.append(item)
except Exception:
'数据提取失败'
print(f'数据爬取完成,数量{len(context_list)}')
return True, '数据保存成功'
class ChinaIpo(object):
"""
港股资本邦
"""
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Content-Length": "40",
"Content-Type": "application/x-www-form-urlencoded",
"Cookie": "PHPSESSID=sejm46mvdu9gmuidfpnem5v894; UM_distinctid=16bdedf96a6da-0c4487051c35f3-37677e02-1fa400-16bdedf96a7458; XSBlang=zh-cn; CNZZDATA1255725096=2112891795-1562809799-%7C1563172642; Hm_lvt_61a2d81fc23a3a8087c8791bf55f7e6e=1562826422,1562929083,1563175398,1563176881; Hm_lpvt_61a2d81fc23a3a8087c8791bf55f7e6e=1563176886",
"Host": "www.chinaipo.com",
"Origin": "http://www.chinaipo.com",
"Referer": "http://www.chinaipo.com/hk/",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
def get_url_list(self):
"""
获取新闻列表
:return:
"""
url = "http://www.chinaipo.com/index.php?app=information&mod=Index&act=getMoreNewsFromCate"
data = {
"catid": "100022",
"type": "1",
"t": "0.4098812290943108"
}
try:
response = requests.post(url=url, headers=self.headers, data=data)
except Exception:
return False, '服务器网络故障'
if response.status_code != 200:
return False, '来源服务器错误'
context = response.text.encode('utf8').decode("unicode-escape")
context = context[20:-2:1]
data_list = [] # 消息数据
"""
提取有效数据
新闻列表
"""
detail_html = etree.HTML(context)
url_list = detail_html.xpath('//div[@class="htn-de clearfix"]/a/@href')
img_list = detail_html.xpath('//div[@class="htn-de clearfix"]/a/img/@src')
for index, val in enumerate(url_list):
url_text = ''.join(val.split("\\"))
img_text = ''.join(img_list[index].split("\\"))
data_list.append({'url': url_text, 'img': img_text})
self.detail_data(data_list)
return True
def detail_data(self, data_list):
"""
获取新闻详情
:param data:
:return:
"""
context_list = []
for data in data_list:
url = data['url']
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
}
try:
response = requests.get(url=url, headers=headers)
except Exception:
return False, '服务器网络故障'
context = response.content.decode('utf8')
detail_html = etree.HTML(context)
"""
提取有效数据
headline # 文章标题
time # 发布时间
cover # 封面图
context # 正文
url # 连接
source # 文章来源
"""
item = {}
try:
item['cover'] = data['img']
item["time"] = detail_html.xpath('//p[@class="news-from"]/text()')[1][3:13:]
# item["time"] = ''.join(item["time"].split("\r\n"))
item["headline"] = detail_html.xpath('//h1[@class="tt-news"]/text()')[0]
con_list = detail_html.xpath('//div[@class="newscont"]/p/text()')
item["context"] = ''
for con in con_list:
item["context"] = item["context"] + ''
+ con + ''
item["context"] = ''.join(''.join(item["context"]).split('\u3000\u3000'))
item["context"] = ''.join(item["context"].split('\r\n'))
item["context"] = ''.join(item["context"].split('\t'))
item["context"] = ''.join(item["context"].split(':123RF
'))
item["url"] = url
item["source"] = "资本邦"
try:
if len(Article.objects.filter(url=item['url'])) == 0:
article = Article.objects.create(
headline=item["headline"],
time=item["time"],
context=item["context"],
url=item["url"],
source=item["source"],
status="WAITING"
)
try:
file = requests.get(url=item['cover'], headers=self.headers)
article.cover.save("_{}.jpg".format('zibenbang'),
File(BytesIO(file.content)))
except Exception:
'图片写入失败'
except Exception:
'数据写入失败'
except Exception:
'数据提取失败'
context_list.append(item)
print(f'数据爬取完成,数量{len(context_list)}')
return True, '数据保存成功'
class ZhiTongCaiJing(object):
"""
美股智通财经
"""
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
base_url = "https://www.zhitongcaijing.com"
def get_url_list(self):
"""
获取新闻列表
:return:
"""
data_list = [] # 消息数据
for i in ["1", "2", "3", "4", "5"]:
url = 'https://www.zhitongcaijing.com/content/meigu.html?page=' + i
try:
response = requests.get(url=url, headers=self.headers)
except Exception:
return False, '服务器网络故障'
if response.status_code != 200:
return False, '来源服务器错误'
context = response.content.decode('utf8')
"""
提取有效数据
"""
soup = BeautifulSoup(context, 'html.parser')
dt_list = soup.select('dt > a')
for dt in dt_list:
url = dt.get('href')
dt = str(dt)
img = re.findall('src="https://img.zhitongcaijing.com/image/.*?\?', dt)
if not len(img):
img = None
else:
img = img[0][5:-1:1]
data_list.append({"url": url, "img": img})
self.detail_data(data_list)
return True, 'success'
def detail_data(self, data_list):
"""
获取新闻详情
:param data:
:return:
"""
context_list = []
for data in data_list:
url = self.base_url + data['url']
try:
response = requests.get(url=url, headers=self.headers)
except Exception:
return False, '服务器网络故障'
context = response.content.decode('utf8')
detail_html = etree.HTML(context)
"""
提取有效数据
headline # 文章标题
time # 发布时间
cover # 封面图
context # 正文
url # 连接
source # 文章来源
"""
item = {}
try:
item["time"] = detail_html.xpath('//div[@class="h-30 line-h-30 color-c size-14 padding-b10"]/text()')[0]
item['time'] = re.sub(' ', '', item['time'])
item['time'] = ' '.join(('-'.join(('-'.join(item['time'].split('年'))).split('月'))).split('日'))
item["headline"] = detail_html.xpath('//h1/text()')[0]
item["cover"] = data['img']
con_list = detail_html.xpath('//article/p/text()')
item["context"] = ''
for con in con_list:
item["context"] = item["context"] + ''
+ con + ''
item["url"] = self.base_url + data['url']
item["source"] = "智通财经网"
try:
if len(Article.objects.filter(url=item['url'])) == 0: # 如果链接存在则不保存
article = Article.objects.create(
headline=str(item["headline"]),
time=item['time'],
context=item["context"],
url=item["url"],
source=item["source"],
status="WAITING"
)
try:
file = requests.get(url=item['cover'], headers=self.headers)
article.cover.save("_{}.jpg".format('zhitongcaijing'),
File(BytesIO(file.content)))
except Exception:
'图片写入失败'
except Exception:
'数据写入失败'
context_list.append(item)
except Exception:
'数据提取失败'
print(f'数据爬取完成,数量{len(context_list)}')
return True, '数据保存成功'
class TengXun(object):
"""
美股腾讯网
"""
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36",
"Accept": 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive"
}
def get_url_list(self):
"""
获取新闻列表
:return:
"""
data_list = []
for i in [1, 2, 3, 4]:
url = f"https://pacaio.match.qq.com/irs/rcd?cid=52&token=8f6b50e1667f130c10f981309e1d8200&ext=3921,3916&page={i}&isForce=1&expIds=20190713A0ARSH|20190713A04T3S|20190713A035IC|20190712A0IF3G|20190712A0I6BK|20190712A05PZC|20190713A04O0U|20190713A018KR|20190713A00OMV|20190713A007BT|20190712A0UA2N|20190712A0U944|20190712A0TZC0|20190712A0TOTJ|20190712A0T2S2|20190712A0Q8IC|20190712A0C70J|20190712A0BRMX|20190712A0BD56|20190712A0BAAM&callback=__jp6"
try:
con = requests.get(url=url).content.decode('utf8')[6:-1:]
except Exception:
return False, '服务器网络故障'
con = json.loads(con)
"""
提取有效数据
新闻列表
"""
for data in con["data"]:
img_url = data["img"]
title = data["title"]
url_text = data["url"]
data_list.append({'img_url': img_url, 'title': title, 'url': url_text})
data_list_01 = []
# 列表去重
for data in data_list:
if data not in data_list_01:
data_list_01.append(data)
self.detail_data(data_list_01) # 获取新闻详情
return True
def detail_data(self, data_list):
"""
获取新闻详情
:param data_list:
:return:
"""
context_list = []
for data in data_list:
url = data['url']
try:
response = requests.get(url=url, headers=self.headers)
except Exception:
return False, '服务器网络故障'
context = response.content.decode('utf8')
"""
提取有效数据
headline # 文章标题
time # 发布时间
cover # 封面图
context # 正文
url # 连接
source # 文章来源
"""
item = {}
try:
item["cover"] = data['img_url']
item["headline"] = data['title']
item["url"] = url
con_list = json.loads(re.findall('contents:.*?}]', context)[0][10::])
item['time'] = re.findall('articleid:.+', context)[0][12:20:]
item['time'] = item['time'][0:4:] + '-' + item['time'][4:6:] + '-' + item['time'][6:8:] + ' 00:00'
item["context"] = ''
try:
for con in con_list:
item["context"] = item["context"] + ''
+ con['value'] + ''
except Exception:
pass
item["source"] = "美股腾讯网"
context_list.append(item)
try:
if len(Article.objects.filter(url=item['url'])) == 0: # 如果链接存在则不保存
article = Article.objects.create(
headline=str(item["headline"]),
time='2019-07-16 11:22',
context=item["context"],
url=item["url"],
source=item["source"],
status="WAITING"
)
try:
file = requests.get(url=item['cover'], headers=self.headers)
article.cover.save("_{}.jpg".format('tengxun'),
File(BytesIO(file.content)))
except Exception:
'图片写入失败'
except Exception:
'数据写入失败'
except Exception:
'数据提取失败'
print(f'数据爬取完成,数量{len(context_list)}')
return True, '数据保存成功'
class TuiJian(object):
"""
推荐智通财经
"""
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"
}
base_url = "https://www.zhitongcaijing.com"
def get_url_list(self):
"""
获取新闻列表
:return:
"""
data_list = [] # 消息数据
for i in ["1", "2", "3", "4", "5"]:
url = 'https://www.zhitongcaijing.com/content/recommend.html?page=' + i
try:
response = requests.get(url=url, headers=self.headers)
except Exception:
return False, '服务器网络故障'
if response.status_code != 200:
return False, '来源服务器错误'
context = response.content.decode('utf8')
"""
提取有效数据
"""
soup = BeautifulSoup(context, 'html.parser')
dt_list = soup.select('dt > a')
for dt in dt_list:
url = dt.get('href')
# img = dt.get('src')
dt = str(dt)
img = re.findall('src="https://img.zhitongcaijing.com/image/.*?\?', dt)
if not len(img):
img = None
else:
img = img[0][5:-1:1]
data_list.append({"url": url, "img": img})
self.detail_data(data_list)
return True, 'success'
def detail_data(self, data_list):
"""
获取新闻详情
:param data:
:return:
"""
context_list = []
for data in data_list:
url = self.base_url + data['url']
try:
response = requests.get(url=url, headers=self.headers)
except Exception:
return False, '服务器网络故障'
context = response.content.decode('utf8')
detail_html = etree.HTML(context)
"""
提取有效数据
headline # 文章标题
time # 发布时间
cover # 封面图
context # 正文
url # 连接
source # 文章来源
"""
item = {}
try:
item["time"] = detail_html.xpath('//div[@class="h-30 line-h-30 color-c size-14 padding-b10"]/text()')[0]
item['time'] = re.sub(' ', '', item['time'])
item['time'] = ' '.join(('-'.join(('-'.join(item['time'].split('年'))).split('月'))).split('日'))
item["headline"] = detail_html.xpath('//h1/text()')[0]
item["cover"] = data['img']
con_list = detail_html.xpath('//article/p/text()')
item["context"] = ''
for con in con_list:
item["context"] = item["context"] + ''
+ con + ''
item["url"] = self.base_url + data['url']
item["source"] = "智通财经网"
try:
if len(Article.objects.filter(url=item['url'])) == 0: # 如果链接存在则不保存
article = Article.objects.create(
headline=str(item["headline"]),
time=item['time'],
context=item["context"],
url=item["url"],
source=item["source"],
status="WAITING"
)
try:
file = requests.get(url=item['cover'], headers=self.headers)
article.cover.save("_{}.jpg".format('tuijian'),
File(BytesIO(file.content)))
except Exception:
'图片写入失败'
except Exception:
'数据写入失败'
context_list.append(item)
except Exception:
'数据提取失败'
print(f'数据爬取完成,数量{len(context_list)}')
return True, '数据保存成功'
def run():
"""
异步爬取数据
:return:
"""
threading.Thread(target=JinRongJie().get_url_list).start() # 港股金融界
threading.Thread(target=ChinaIpo().get_url_list).start() # 港股资本邦
threading.Thread(target=ZhiTongCaiJing().get_url_list).start() # 美股智通财经网
threading.Thread(target=TengXun().get_url_list).start() # 美股腾讯网
threading.Thread(target=TuiJian().get_url_list).start() # 推荐智通财经网
# multiprocessing
if __name__ == '__main__':
run()