大数据笔记--Hadoop(第一篇)
目录
一、大数据简介
1、简介
2、特点
3、应用场景
4、组织结构
二、Hadoop简介
1、概述
2、版本
3、模块
4、安装模式
5、web访问端口
三、Hadoop发展
1、创始人
2、发展历程
四、Hadoop伪分布式安装
五、hadoop完全分布式安装
一、大数据简介
1、简介
①、美国调研机构Gartner给出了定义:大数据是一种新的处理模式,针对海量数据能够提供更强 的决策力、洞察发现力和流程优化能力
②、维基百科给出了定义:大数据是指无法在可承受的时间范围内用常规的软件或者法来对大量的数据进行捕捉、管理和处理
③、无论哪个机构对大数据进行定义,实际上都是围绕对海量数据进行快速有效的处理方案
2、特点
Volumn:数据体量大。很多中小型企业的入门数据量是从TB级别开始,很多大型企业的入门数据量是从PB级别开始,更有累计达到EB级别至ZB级别。
Variety:数据种类样式和来源多;
种类:文本(日志)、图片、音频、视频、flash等
样式:结构化数据(数据本身有结构并且数据解析之后能够用一张或者几张固定的表来存储);半结构化数据(数据本身有结构但是解析之后无法用一张或者几张固定的表来存储,例如接json、xml等);非结构化数据(数据本身没有结构并且解析之后无法用几张固定的表来进行存储,例如视频、音频等)
来源:日志、爬虫、网页埋点、手动录入、数据库等
Value:数据价值密度低。价值密度指的是想要的数据在总的数量中的占比。随着网络的发展,价值密度越来越低,但是不意味着获取到的数据越来越少,恰恰相反,获取到的数据是在变多的。只是想要的数据的增长速度比不上样本总量的增长速度。
Velocity:数据增长速度快。随着网络的发展,数据的产生速度以及增长数据越来越快
Veracity:真实性,数据的质量,即数据的准确性和可信赖度,信息的发展,信息来源广,但是真实度就不太行了
Valence:数据的连通性。随着大数据的发展,衍生出来了很多的技术、模块和产业,这个时候,就不得不考虑这些模块、技术和产业之间的关系
随着大数据的发展,产生了越来越多的特性:Vitality(动态性)、Visualization(可视化)、Validity(合法性,例如大数据杀熟、APP的过度索权)等
3、应用场景
i、物流仓储:利用大数据对配送路线、物流中转点进行设计
ii、电商零售:利用大数据技术对用户的消费行为进行分析,抓住用户的心理变化,做到精准营销
iii、旅游:利用大数据技术来为用户进行合理规划(经济能力、路线等)
iv、保险:利用大数据技术进行精准营销、风险预测
v、金融:利用大数据技术对用户进行抗压预测以及风险控制
vi、人工智能:利用大量数据对模型进行训练,提高模型的准确性
4、组织结构

二、Hadoop简介

1、概述
Hadoop是由Yahoo!开发的后来贡献给Apache的一套开源的、可靠的、可伸缩的分布式机制
Hadoop是大数据生态系统中的基础框架,在大数据中,有超过70%的技术或者产业是围绕Hadoop产生的
Hadoop提供了简单的编程模型来对大量数据进行分布式处理
Hadoop能够从一台服务器扩展到上千台服务器,每一台服务器都能够提供计算和存储的功能
Hadoop本身提供了探测和处理异常的机制
Hadoop之父:Doug Cutting(道格·卡丁)
Hadoop的发行版:
Apache Hadoop:最基础、最原始的版本。相对而言,部署和维护比较复杂,但是适合于初学者,因为它没有将细节隐藏,更适合于理解底层机制
CDH:Cloudera公司推出的商用版本的Hadoop。这版Hadoop更易于部署和维护,能够相对轻松的扩展集群规模。Cloudera的标价是每个节点每年4000美元(现在每一个节点的价钱飙升到了10000美元)
HDP:Hortonworks提供的商用版本的Hadoop,更注重分布式存储,增强了分布式存储的功能。Hortonworks在售卖的时候,以打包的方式来售卖,每个包(包含不超过10个节点)每年收费12500美元。最近,Hortonworks已经被Cloudera公司收购
Apache Hadoop目前的版本比较混乱。目前市面上,Hadoop2.X和Hadoop3.X都在流行使用
2、版本
Hadoop1.X:包含了Common、HDFS和MapReduce模块。现在市面上已经停止使用
Hadoop2.X:包含了Common、HDFS、MapReduce以及YARN模块。从Hadoop2.7版本开始,还包含了Ozone模块。Hadoop2.X和Hadoop1.X全版本不兼容
Hadoop3.X:包含了Common、HDFS、MapReduce、YARN和Ozone模块。Hadoop3.X和Hadoop2.X部分版本兼容
3、模块
Hadoop Common:公共依赖模块
Hadoop Distributed File System (HDFS™):分布式文件系统,解决存储问题
Hadoop YARN:负责任务调度和集群的资源管理
Hadoop MapReduce:基于YARN的分布式计算系统
Hadoop Ozone:一个可伸缩、冗余和分布式的对象存储
4、安装模式
单机模式:在一台服务器上安装Hadoop,只能启动Hadoop的MapReduce模块
伪分布式:在一台服务器上安装Hadoop,利用多个进程来模拟Hadoop集群环境,能够启动Hadoop的绝大部分主要服务
完全分布式:在集群中安装Hadoop,能够启动Hadoop中的所有的服务
5、web访问端口
| Process | Hadoop2.X | Hadoop3.X |
| NameNode | 50070 | 9870 |
| SecondaryNameNode | 50090 | 9868 |
| DataNode | 50075 | 9864 |
| ResourceManager | 8088 | 8088 |
| NodeManager | X | X |
三、Hadoop发展
1、创始人
Doug Cutting:创建了Lucene,与Mike Cafarella共同创建了搜索引擎Nutch
Mike Cafarella:是一位专攻数据库管理系统的科学家
2、发展历程
早在2002年的时候,Doug和Mike设计一个搜索引擎Nutch,爬取了全网10亿个网页的数据,爬取完成之后,在设计搜索引擎的过程中,遇到了存储的问题
在2003年的时候,Google发表了一篇论文
在2004年的时候,Doug和Mike根绝GFS实现了Nutch中的存储系统 - NDFS(Nutch Distributed File System - Nutch分布式文件系统)
在2004年的时候,Google发表了一篇论文
在2005年的时候,Doug根据这篇论文实现了Nutch中的MapReduce
在Nutch0.8的时候,Doug发现NDFS和MapReduce不只可以用于搜索引擎,也可以用于其他的分布式处理,所以就把NDFS和MapReduce以及其他的一些需要的基本以来分离出来,组成了一个新的框架Hadoop,同时NDFS改名为HDFS(Hadoop Distributed File System),至此,Hadoop正式面世
在2007年11月的时候,Doug加入了Yahoo!,在Yahoo!工作期间,深度开发了Hadoop,后来还根据网友的建议,实现了HBase、Pig等框架
后来Yaoo!将Hadoop、HBase、Pig等框架贡献给了Apache
四、Hadoop伪分布式安装
1、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
2、修改主机名- Hadoop集群中,主机名中尽量不要出现-或者_
vim /etc/hostname
将原来的主机名删除,添加自己指定的主机名hadoop01
3、需要将主机名和IP进行映射
vim /etc/hosts
进入文件之后,除了127.0.0.1以及::1这开头的两行以外,其余的行全部删除
之后添加当前主机的IP 主机名,例如
192.168.186.128 hadoop01
4、关闭SELINUX
vim /etc/selinux/config
将SELINUX属性的值改为disabled
5、重启
reboot
6、 配置免密登录
ssh-keygen
ssh-copy-id
输入主机的密码
测试是否免密成功:ssh hadoop01
如果不需要密码,那么说明免密成功,那么输入logout
7、进入/home/software目录,来上传或者下载Hadoop。
cd /home/software/
wget http://网络地址/hadoop-3.1.3.tar.gz
8、解压Hadoop安装包
tar -xvf hadoop-3.1.3.tar.gz
9、进入Hadoop的配置文件目录
cd hadoop-3.1.3/etc/hadoop/
10、编辑文件
vim hadoop-env.sh
在文件中添加JAVA_HOME,值是JDK的安装路径
export JAVA_HOME=/home/software/jdk1.8
保存退出,重新生效这个文件
source hadoop-env.sh
11、编辑文件
1、编辑文件
vim core-site.xml
添加内容
fs.default.name
hdfs://hadoop01:9000
hadoop.tmp.dir
/home/software/hadoop-3.1.3/tmp
2、编辑文件
vim hdfs-site.xml
添加内容
dfs.replication
1
3、编辑文件
vim mapred-site.xml
添加内容
mapreduce.framework.name
yarn
4、编辑文件
vim yarn-site.xml
添加内容
yarn.resourcemanager.hostname
hadoop01
yarn.nodemanager.aux-services
mapreduce_shuffle
5、编辑文件
vim workers ------- 注意,如果是在Hadoop2.X,那么这个文件是slaves
将原来的localhost删除掉,然后添加当前主机的主机名hadoop01
12、配置环境变量
vim /etc/profile
在文件末尾添加
export HADOOP_HOME=/home/software/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出,重新生效这个文件
source /etc/profile
通过hadoop version命令来确定配置是否有效
13、第一次启动Hadoop之前,需要先进行一次格式化
hadoop namenode -format
如果出现了Storage directory /home/software/hadoop-3.1.3/tmp/dfs/name has been successfully formatted.表示格式化成功
14、进入Hadoop安装目录的子目录sbin下
cd /home/software/hadoop-3.1.3/sbin/
15、编辑文件
vim start-dfs.sh
在文件头部添加
HDFS_DATANODE_USER=root
HDFS_DATANODE_SERCURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
16、启动HDFS
start-dfs.sh
17、通过jps查看,会发现三个进程
NameNode
DataNode
SecondaryNameNode
18、编辑文件
vim start-yarn.sh
在文件头部添加
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
YARN_NODEMANAGER_USER=root
19、启动YARN
start-yarn.sh
20、通过jps查看,会发现多出来两个进程
ResourceManager
NodeManager
21、可能出现的问题的解决方案
1、如果出现了Name or Service not known或者是UnknownHost之类的问题,那么检查hosts文件是否配置正确,或者是主机名是否写对
2、如果出现了commandc not found,那么检查环境变量是否正确,或者修改完环境变量之后是否进行了source
3、在第一次关闭Hadoop之前,同样修改stop-dfs.sh以及stop-yarn.sh
4、之后,再次启动Hadoop,那么可以使用start-all.sh。如果单独启动HDFS,那么使用start-dfs.sh;如果单独启动YAR,那么使用start-yarn.sh。如果要关闭,将start命令改成stop命令即可
五、hadoop完全分布式安装
1、三台主机关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
2、修改三台主机的主机名
vim /etc/hostname
修改对应的主机名,最好是hadoop01~hadoop03
3、将主机名和IP进行映射
vim /etc/hosts
然后将三台主机的主机名和IP配置

4、关闭SELINUX
vim /etc/selinux/config 将SELINUX的值改为disabled
此处是关闭SELINUX安全策略
5、三台主机重启
reboot
6、三台主机之间需要相互免密
ssh-keygen
ssh-copy-id root@hadoop01
ssh hadoop01
如果不需要密码,那么输入logout
ssh-copy-id root@hadoop02
ssh hadoop02
如果不需要密码,那么输入logout
ssh-copy-id root@hadoop03
ssh hadoop03
如果不需要密码,那么输入logout
7、在第一台主机上进入software目录,下载或者上传Hadoop的安装包
cd /home/software/ 我们用的版本是hadoop-3.1.3.tar.gz
8、如果你安装了伪分布式,先将伪分布式保留下来,没安装跳过这一步
mv hadoop-3.1.3 hadoop-alone
9、解压
tar -xvf hadoop-3.1.3.tar.gz
10、进入Hadoop的配置目录
cd /home/software/hadoop-3.1.3/etc/hadoop/

11、编辑文件 hadoop-env.sh
vim hadoop-env.sh
添加JAVA_HOME,例如
export JAVA_HOME=/home/software/jdk1.8.0_131此处要根据自己的java路径填写 ,可以使用 echo $JAVA_HOME来查询
保存退出,重新生效
source hadoop-env.sh

12、编辑文件 core-site.xml
vim core-site.xml
添加内容
fs.defaultFS hdfs://ns hadoop.tmp.dir /home/software/hadoop-3.1.3/tmp ha.zookeeper.quorum hadoop01:2181,hadoop02:2181,hadoop03:2181

13、编辑文件 hdfs-site.xml
vim hdfs-site.xml
添加内容
dfs.nameservices ns dfs.ha.namenodes.ns nn1,nn2, nn3 dfs.namenode.rpc-address.ns.nn1 hadoop01:9000 dfs.namenode.rpc-address.ns.nn2 hadoop02:9000 dfs.namenode.rpc-address.ns.nn3 hadoop03:9000 dfs.namenode.http-address.ns.nn1 hadoop01:9870 dfs.namenode.http-address.ns.nn2 hadoop02:9870 dfs.namenode.http-address.ns.nn3 hadoop03:9870 dfs.namenode.shared.edits.dir qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/ns dfs.journalnode.edits.dir /home/software/hadoop-3.1.3/tmp/journal dfs.namenode.name.dir file:///home/software/hadoop-3.1.3/tmp/hdfs/name dfs.datanode.data.dir file:///home/software/hadoop-3.1.3/tmp/hdfs/data dfs.ha.automatic-failover.enabled true dfs.client.failover.proxy.provider.ns org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.fencing.methods sshfence dfs.ha.fencing.ssh.private-key-files /root/.ssh/id_rsa dfs.replication 3 dfs.permissions false
14、编辑文件 mapred-site.xml
vim mapred-site.xml
添加内容
mapreduce.framework.name yarn

15、编辑文件 yarn-site.xml
vim yarn-site.xml
添加内容
yarn.resourcemanager.ha.enabled true yarn.resourcemanager.cluster-id ns-yarn yarn.resourcemanager.ha.rm-ids rm1,rm2 yarn.resourcemanager.hostname.rm1 hadoop01 yarn.resourcemanager.hostname.rm2 hadoop03 yarn.resourcemanager.recovery.enabled true yarn.resourcemanager.store.class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore yarn.resourcemanager.zk-address hadoop01:2181,hadoop02:2181,hadoop03:2181 yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname hadoop03
16、编辑文件 workers
vim workers 删除掉localhost,将三台主机的主机名写上

17、进入Hadoop安装目录的子目录sbin下
cd /home/software/hadoop-3.1.3/sbin/

18、编辑文件 start-dfs.sh
vim start-dfs.sh
在文件头部添加
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root HDFS_JOURNALNODE_USER=root HDFS_ZKFC_USER=root

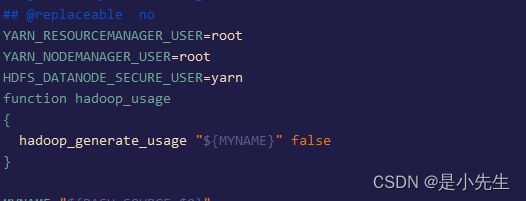
19、编辑文件 start-yarn.sh
vim start-yarn.sh
在文件头部添加YARN_RESOURCEMANAGER_USER=root YARN_NODEMANAGER_USER=root HDFS_DATANODE_SECURE_USER=yarn
20、远程拷贝给另外两台主机
cd /home/software/
注意:这里software文件夹是自己提前创建的,我们都安装在这个文件夹中
scp -r hadoop-3.1.3 hadoop02:/home/software/
scp -r hadoop-3.1.3 hadoop03:/home/software/
21、三台主机配置环境变量
vim /etc/profile
在文件末尾添加
export HADOOP_HOME=/home/software/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出,重新生效
source /etc/profile可以通过hadoop version来查看是否配置成功

22、三台主机需要启动Zookeepe
cd /home/software/zookeeper-3.5.7/bin/
sh zkServer.sh start
sh zkServer.sh status
如果出现了1个leader+2个follower表示启动成功
23、在第一台主机上格式化Zookeeper - 实际上就是在Zookeeper上注册节点
hdfs zkfc -formatZK
如果出现Successfully created /hadoop-ha/ns in ZK.表示格式化成功

24、在三台主机上启动JournalNode
hdfs --daemon start journalnode 注意三台都启动

25、在第一台主机上格式化NameNode
hadoop namenode -format
如果出现Storage directory /home/software/hadoop-3.1.3/tmp/hdfs/name has been successfully formatted.表示格式化成功

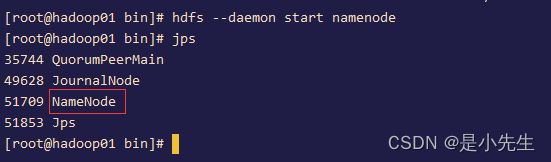
26、在第一台主机上启动NameNode
hdfs --daemon start namenode
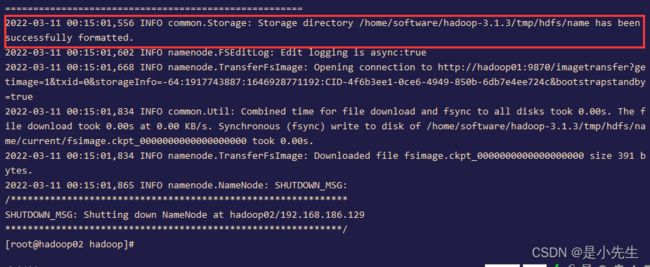
27、在第二台和第三台主机上格式化NameNode
hdfs namenode -bootstrapStandby
如果出现Storage directory /home/software/hadoop-3.1.3/tmp/hdfs/name has been successfully formatted.表示格式化成功
28、在第二台和第三台主机上启动NameNode
hdfs --daemon start namenode

29、在三台节点上启动DataNode
hdfs --daemon start datanode
30、在三个节点上启动zkfc
hdfs --daemon start zkfc
31、在第三台主机上启动YARN
start-yarn.sh 注意如果你的yarn启动报错如下图,那可能是你的start-yarn.sh配置错误
位置应该在这:


通过jps查看,第一台主机上出现
NameNode
DataNode
JournalNode
ResourceManager
NodeManager
DFSZKFailoverController
QuorumPeerMain
第二台主机上出现
NameNode
DataNode
JournalNode
NodeManager
DFSZKFailoverController
QuorumPeerMain
第三台主机上出现
NameNode
DataNode
JournalNode
ResourceManager
NodeManager
DFSZKFailoverController
QuorumPeerMain


