python爬虫(一)——爬虫框架设计
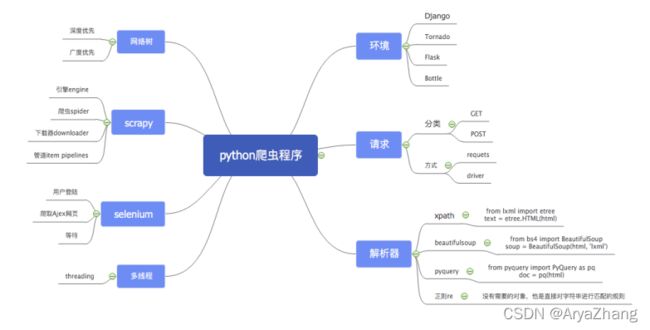
一、web框架
(1)Django:比较“重”的框架,同时也是最出名的Python框架。包含了web开发中常用的功能、组件的框架(ORM、Session、Form、Admin、分页、中间件、信号、缓存、ContenType....),Django是走大而全的方向,最出名的是其全自动化的管理后台:只需要使用起ORM,做简单的对象定义,它就能自动生成数据库结构、以及全功能的管理后台。
(2)Tornado:大特性就是异步非阻塞、原生支持WebSocket协议;
(3)Flask:Flask 是一个轻量级的基于 Python 的 Web 框架,支持 Python 2 和 Python 3,简单易用,适合快速开发。封装功能不及Django完善,性能不及Tornado,但是Flask的第三方开源组件比丰富,其 WSGI工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 。Flask也被称为 “microframework” ,因为它使用简单的核心,用 extension 增加其他功能。Flask没有默认使用的数据库、窗体验证工具。
(4)Bottle:是一个简单高效的遵循WSGI的微型python Web框架。说微型,是因为它只有一个文件,除Python标准库外,它不依赖于任何第三方模块。
二、请求Get与Post
两种最常用的 HTTP 方法是:GET 和 POST
| get |
post |
|
| 后退按钮/刷新 |
无害 |
数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 |
| 书签 |
可收藏为书签 |
不可收藏为书签 |
| 缓存 |
能被缓存 |
不能缓存 |
| 编码类型 |
application/x-www-form-urlencoded |
application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。 |
| 历史 |
参数保留在浏览器历史中。 |
参数不会保存在浏览器历史中。 |
| 对数据长度的限制 |
是的。当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。 |
无限制。 |
| 对数据类型的限制 |
只允许 ASCII 字符。 |
没有限制。也允许二进制数据。 |
| 安全性 |
与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。 在发送密码或其他敏感信息时绝不要使用 GET ! |
POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。 |
| 可见性 |
数据在 URL 中对所有人都是可见的。 |
数据不会显示在 URL 中。 |
请求头的说明:
HTTP的头信息比较多,Headers主要分为Response Headers(响应)和Request Headers(请求)两部分。
Requests的元素表
| Header |
解释 |
示例 |
| Accept |
指定客户端能够接收的内容类型 |
Accept: text/plain, text/html |
| Accept-Charset |
浏览器可以接受的字符编码集。 |
Accept-Charset: iso-8859-5 |
| Accept-Encoding |
指定浏览器可以支持的web服务器返回内容压缩编码类型。 |
Accept-Encoding: compress, gzip |
| Accept-Language |
浏览器可接受的语言 |
Accept-Language: en,zh |
| Accept-Ranges |
可以请求网页实体的一个或者多个子范围字段 |
Accept-Ranges: bytes |
| Authorization |
HTTP授权的授权证书 |
Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control |
指定请求和响应遵循的缓存机制 |
Cache-Control: no-cache |
| Connection |
表示是否需要持久连接。(HTTP 1.1默认进行持久连接) |
Connection: close |
| Cookie |
HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。 |
Cookie: $Version=1; Skin=new; |
| Content-Length |
请求的内容长度 |
Content-Length: 348 |
| Content-Type |
请求的与实体对应的MIME信息 |
Content-Type: application/x-www-form-urlencoded |
| Date |
请求发送的日期和时间 |
Date: Tue, 15 Nov 2010 08:12:31 GMT |
| Expect |
请求的特定的服务器行为 |
Expect: 100-continue |
| From |
发出请求的用户的Email |
From: [email protected] |
| Host |
指定请求的服务器的域名和端口号 |
Host: www.kccdzz.com |
| If-Match |
只有请求内容与实体相匹配才有效 |
If-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Modified-Since |
如果请求的部分在指定时间之后被修改则请求成功,未被修改则返回304代码 |
If-Modified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| If-None-Match |
如果内容未改变返回304代码,参数为服务器先前发送的Etag,与服务器回应的Etag比较判断是否改变 |
If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Range |
如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。参数也为Etag |
If-Range: “737060cd8c284d8af7ad3082f209582d” |
| If-Unmodified-Since |
只在实体在指定时间之后未被修改才请求成功 |
If-Unmodified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| Max-Forwards |
限制信息通过代理和网关传送的时间 |
Max-Forwards: 10 |
| Pragma |
用来包含实现特定的指令 |
Pragma: no-cache |
| Proxy-Authorization |
连接到代理的授权证书 |
Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range |
只请求实体的一部分,指定范围 |
Range: bytes=500-999 |
| Referer |
先前网页的地址,当前请求网页紧随其后,即来路 |
Referer: http://www.kccdzz.com |
| TE |
客户端愿意接受的传输编码,并通知服务器接受接受尾加头信息 |
TE: trailers,deflate;q=0.5 |
| Upgrade |
向服务器指定某种传输协议以便服务器进行转换(如果支持) |
Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent |
User-Agent的内容包含发出请求的用户信息 |
User-Agent: Mozilla/5.0 (Linux; X11) |
| Via |
通知中间网关或代理服务器地址,通信协议 |
Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning |
关于消息实体的警告信息 |
Warn: 199 Miscellaneous warning |
Responses元素表
| Header |
解释 |
示例 |
| Accept-Ranges |
表明服务器是否支持指定范围请求及哪种类型的分段请求 |
Accept-Ranges: bytes |
| Age |
从原始服务器到代理缓存形成的估算时间(以秒计,非负) |
Age: 12 |
| Allow |
对某网络资源的有效的请求行为,不允许则返回405 |
Allow: GET, HEAD |
| Cache-Control |
告诉所有的缓存机制是否可以缓存及哪种类型 |
Cache-Control: no-cache |
| Content-Encoding |
web服务器支持的返回内容压缩编码类型。 |
Content-Encoding: gzip |
| Content-Language |
响应体的语言 |
Content-Language: en,zh |
| Content-Length |
响应体的长度 |
Content-Length: 348 |
| Content-Location |
请求资源可替代的备用的另一地址 |
Content-Location: /index.htm |
| Content-MD5 |
返回资源的MD5校验值 |
Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
| Content-Range |
在整个返回体中本部分的字节位置 |
Content-Range:bytes 21010-47021/47022 |
| Content-Type |
返回内容的MIME类型 |
Content-Type: text/html; charset=utf-8 |
| Date |
原始服务器消息发出的时间 |
Date: Tue, 15 Nov 2010 08:12:31 GMT |
| ETag |
请求变量的实体标签的当前值 |
ETag: “737060cd8c284d8af7ad3082f209582d” |
| Expires |
响应过期的日期和时间 |
Expires: Thu, 01 Dec 2010 16:00:00 GMT |
| Last-Modified |
请求资源的最后修改时间 |
Last-Modified: Tue, 15 Nov 2010 12:45:26 GMT |
| Location |
用来重定向接收方到非请求URL的位置来完成请求或标识新的资源 |
Location: http://www.kccdzz.com |
| Pragma |
包括实现特定的指令,它可应用到响应链上的任何接收方 |
Pragma: no-cache |
| Proxy-Authenticate |
它指出认证方案和可应用到代理的该URL上的参数 |
Proxy-Authenticate: Basic |
| refresh |
应用于重定向或一个新的资源被创造,在5秒之后重定向(由网景提出,被大部分浏览器支持) |
Refresh: 5; url=http://www.kccdzz.com |
| Retry-After |
如果实体暂时不可取,通知客户端在指定时间之后再次尝试 |
Retry-After: 120 |
| Server |
web服务器软件名称 |
Server: Apache/1.3.27 (Unix) (Red-Hat/Linux) |
| Set-Cookie |
设置Http Cookie |
Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1 |
| Trailer |
指出头域在分块传输编码的尾部存在 |
Trailer: Max-Forwards |
| Transfer-Encoding |
文件传输编码 |
Transfer-Encoding:chunked |
| Vary |
告诉下游代理是使用缓存响应还是从原始服务器请求 |
Vary: * |
| Via |
告知代理客户端响应是通过哪里发送的 |
Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning |
警告实体可能存在的问题 |
Warning: 199 Miscellaneous warning |
| WWW-Authenticate |
表明客户端请求实体应该使用的授权方案 |
WWW-Authenticate: Basic |
三、XPath
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。最初是用来搜寻 XML 文档的,但同样适用于 HTML 文档的搜索。所以在做爬虫时完全可以使用 XPath 做相应的信息抽取。
(1)XPath 常用规则:
| 表达式 |
描述 |
| nodename |
选取此节点的所有子节点 |
| / |
从当前节点选区直接子节点 |
| // |
从当前节点选取子孙节点 |
| . |
选取当前节点 |
| .. |
选取当前节点的父节点 |
| @ |
选取属性 |
- 解析方法
html=etree.HTML(text)
Result=html.xpath(‘//title[@lang='eng']’)
其中的//title[@lang='eng'],代表的是选择所有名称为 title,同时属性 lang 的值为 eng 的节点,后面会通过 Python 的 lxml 库,利用 XPath 进行 HTML 的解析。具体写法不加赘述,目前浏览器可以直接导出xpath。
一个元素kennel有多个属性: Class、ID、name、text、href、vaule
xpath 获取标签内的 text , href
/li/a/@herf 这样取的应该是href的内容
/li/a/text() 这样取得是text内容
获取页面标签中的href值:百度
url = driver.find_element_by_xpath("标签a的xpath").get_attribute("href")
print url
url = soup.find_all("标签a的xpath").get("href")
四、正则表达式re
(1)解析方式
正则表达式的使用方法主要有4种: re.search(进行正则匹配), re.match(从头开始匹配) re.findall(找出所有符合条件的字符列表) re.split(根据条件进行切分) re.sub(根据条件进行替换)
Import re
re.findall(‘正则化’,‘ ’)
re.search(‘正则化’,‘ ’)
匹配某个字符串使用 match 函数,输出匹配到的字符使用 group() 函数
text = 'hello'
ret = re.match('he',text)
print(ret.group())
- 基本规则
| 元字符 |
描述 |
| . |
匹配任意除换行符"\n"外的字符(在DOTALL模式中也能匹配换行符) |
| \ |
将下一个字符标记符、或一个向后引用、或一个八进制转义符。例如,“\\n”匹配\n,“\n”匹配换行符。序列“\\”匹配“\”而“\(”则匹配“(”。 |
| ^ |
匹配行首,在多行模式中匹配每一行的开头。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ |
匹配行尾,在多行模式中匹配每一行的末尾。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * |
匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于{0,}。 |
| + |
匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。等价于{1,}。 |
| {n} |
n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} |
n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} |
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? |
匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于{0,1}。 |
| ? |
当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少地匹配所搜索的字符串,而默认的贪婪模式则尽可能多地匹配所搜索的字符串。例如,对于字符串“oooo”,“o+”将尽可能多地匹配“o”,得到结果[“oooo”],而“o+?”将尽可能少地匹配“o”,得到结果 [‘o’, ‘o’, ‘o’, ‘o’] |
| x|y |
匹配x或y。例如,“z|food”能匹配“z”或“food”(此处请谨慎)。“[zf]ood”则匹配“zood”或“food”。 |
| [xyz] |
字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] |
负值字符集合。匹配未包含的任意字符。例如,“[ ^ abc]”可以匹配“plain”中的“plin”任一字符。 |
| [a-z] |
字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。注意:只有连字符在字符组内部时,并且出现在两个字符之间时,才能表示字符的范围; 如果出字符组的开头,则只能表示连字符本身. |
| [^a-z] |
负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[ ^ a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b |
匹配一个单词的边界,也就是指单词和空格间的位置(即正则表达式的“匹配”有两种概念,一种是匹配字符,一种是匹配位置,这里的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”;“\b1_”可以匹配“1_23”中的“1_”,但不能匹配“21_3”中的“1_”。 |
| \B |
匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er” |
| \s |
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S |
匹配任何可见字符。等价于[ ^ \f\n\r\t\v]。 |
| \w |
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,这里的"单词"字符使用Unicode字符集。 |
| \W |
匹配任何非单词字符。等价于“[ ^ A-Za-z0-9_]”。 |
| \d |
匹配一个数字字符。等价于[0-9]。grep 要加上-P,perl正则支持 |
| \D |
匹配一个非数字字符。等价于[ ^ 0-9]。grep要加上-P,perl正则支持 |
| \n |
匹配一个换行符。等价于\x0a和\cJ。 |
| \r |
匹配一个回车符。等价于\x0d和\cM。 |
| \t |
匹配一个制表符。等价于\x09和\cI。 |
| ( ) |
将( 和 ) 之间的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域(一个正则表达式中最多可以保存9个),它们可以用 \1 到\9 的符号来引用。 |
| (?:pattern) |
非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分时很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
| | |
将两个匹配条件进行逻辑“或”(Or)运算。例如正则表达式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:这个元字符不是所有的软件都支持的。 |
五、Beautifulsoup
- 转载HTML文档
(1)BeautifulSoup类的基本元素
Tag 标签,最基本的信息组织单元,分别用<>和标明开头和结尾
Name 标签的名字, ....
Attributes 标签的属性,字典形式组织,格式:
NavigableString 标签内非属性字符串,<>...中字符串,格式:
Comment 标签字符串的注释部分,一种特殊的comment类型
(2)用bs4库让页面更“友好”的显,有prettify方法:
import requests
r = requests.get("http://www.lofter.com")
demo = r.text
from bs4 import BeautifulSoup
soup = BeautifulSoup(demo,"html.parser") #bs4库将任何读入的html文件或字符串转换成utf-8编码。
print (soup.prettify())#每一个标签和相关内容自动分行显示
2、查找文档元素
定义:
Find_All(tag, attributes, recursive, text, limit, keywords) #查找符合条件的所有
find(tag, attributes, recursive, text, keywords) #查找符合条件的第一个
95%的时间只用前2个参数:tag,attributes。
(1)tag
可以传一个标签的名称或多个标签名称组成的 Python列表做标签参数。例如,下面的代码将返回一个包含 HTML 文档中所有标题标签的列表:
.find_All({"h1","h2","h3","h4","h5","h6"})
(2)attributes
属性参数 attributes 是用一个 Python 字典封装一个标签的若干属性和对应的属性值。例如,下面这个函数会返回 HTML 文档里红色与绿色两种颜色的 span 标签:
.find_All("span", {"class":{"green", "red"}})
如果只返回一种颜色的,如绿色:
.find("span", {"class": "green"})
3、遍历文档元素
(1)标签树的下行遍历
.contents 子节点的列表,将
.children 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点
.descendants 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
(2)标签树的上行遍历
.parent 节点的父亲标签
.parents 节点先辈标签的迭代类型,用于遍历先辈节点
(3)标签树的平行遍历(发生在同一个父节点下的各节点间)
.next_sibling 返回按照HTML文本版顺序的下一个平行节点标签
.previous_sibling 返回按照HTML文本顺序的上一个平行节点标签
.next_siblings 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签
.previous_siblings 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签
(4)函数书写如下:
find_parent()
find_parents()
find_next_sibling()
find_next_siblings()
find_previous_sibling()
find_previous_siblings()
find_previous()
find_all_previous()
find_next()
find_all_next()
4、CSS语法查找
我们在写 CSS 时,标签名不加任何修饰,类名前加点,id名前加 #,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
(1)通过标签名查找
print soup.select('title')
#[
print soup.select('a')
print soup.select('b')
#[The Dormouse's story]
(2)通过类名查找
print soup.select('.sister')
(3)通过 id 名查找
print soup.select('#link1')
(4)组合查找
组合查找即和写 class 文件时,标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
print soup.select('p #link1')
直接子标签查找
print soup.select("head > title")
#[
(5)属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print soup.select('a[href="http://example.com/elsie"]')
同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print soup.select('p a[href="http://example.com/elsie"]')
- 网络树爬取
(1)结构
计算机
#标题
(2)广度优先
其过程检验来说是对每一层节点依次访问,访问完一层进入下一层,而且每个节点只能访问一次。先往队列中插入左节点,再插右节点,这样出队就是先左节点后右节点了。
广度优先遍历树,需要用到队列(Queue)来存储节点对象,队列的特点就是先进先出。广度优先遍历的 结果是:A,B,C,D,E,F,G,H,I(假设每层节点从左到右访问)。
(3)深度优先
其过程简要来说是对每一个可能的分支路径深入到不能再深入为止,而且每个节点只能访问一次。对于上面的例子来说深度优先遍历的结果就是:A,B,D,E,I,C,F,G,H.(假设先走子节点的的左侧)。
深度优先遍历各个节点,需要使用到栈(Stack)这种数据结构。stack的特点是是先进后出。整个遍历过程如下:先往栈中压入右节点,再压左节点,这样出栈就是先左节点后右节点了。
七、实现多线程
- 原因
多线程对爬虫的效率提高是非凡的,当我们使用python的多线程有几点是需要我们知道的:
1.Python的多线程并不如java的多线程,其差异在于当python解释器开始执行任务时,受制于GIL(全局解释所),Python 的线程被限制到同一时刻只允许一个程执行这样一个执行模型。
2.Python 的线程更适用于处理 I/O 和其他需要并发行的阻塞操作(比如等待 I/O、等待从数据库获取数据等等),而不是需要多处理器行的计算密集型任务。幸运的是,爬虫大部分时间在网络交互上,所以可以使用多线程来编写爬虫。
3.这点其实和多线程关系不大,scrapy的并发并不是采用多线程来实现,它是一个twisted应用,通过异步非阻塞来达到并发,这个后面我会写文章来讲解。
4.Python中当你想要提高执行效率,大部分开发者是通过编写多进程来提高运行效率,使用multiprocessing进行并行编程,当然,你可以编写多进程爬虫来爬取信息,缺点是每个进程都会有自己的内存,数据多的话,内存会吃不消。
5.使用线程有什么缺点呢,缺点就是你在编写多线程代码时候,要注意死锁的问题、阻塞的问题、以及需要注意多线程之间通信的问题(避免多个线程执行同一个任务)。
2、threading
多线程是为了同步完成多项任务,通过提高资源使用效率来提高系统的效率。线程是在同一时间需要完成多项任务的时候实现的。
threading模块是python中专门提供用来做多线程编程的模块。threading模块中最常用的类是Thread。
(1)threading模块的对象
| 对象 |
描述 |
| Thread |
线程对象 |
| Lock |
互斥锁 |
| Condition |
条件变量 |
| Event |
事件,该事件发生后所有等待该事件的线程将激活 |
| Semaphore |
信号量(计数器) |
| Timer |
定时器,运行前会等待一段时间 |
| Barrier |
创建一个障碍,必须达到指定数量线程才开始运行 |
(2)Threading模块的Thread类
| 对象 |
描述 |
| name |
线程名(属性) |
| ident |
线程标识符(属性) |
| daemon |
线程是否是守护线程(属性) |
| _init_(group=None, tatget=None, name=None, args=(),kwargs ={}, verbose=None, daemon=None) |
实例化一个线程对象,需要有一个可调用的 target,以及其参数 args或 kwargs。还可以传递 name 或 group 参数,不过后者还未实现。此外, verbose 标 志 也 是 可 接 受 的。 而 daemon 的 值 将 会 设定thread.daemon 属性/标志 |
| start() |
开启线程 |
| run() |
定义线程功能的方法(通常在子类中被应用开发者重写) |
| Barrier |
创建一个障碍,必须达到指定数量线程才开始运行 |
(3)过程
直接创建 Thread 对象
class threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
Thread 的构造方法中,最重要的参数是 target,所以我们需要将一个 callable 对象赋值给它,线程才能正常运行。上面的 callable 没有参数,如果需要传递参数的话,args 是固定参数,kwargs 是可变参数。
如果要让一个 Thread 对象启动,调用它的 start() 方法就好了。
thread = threading.Thread(target=test)
thread.start()
通过 thread.current_thread() 方法可以返回线程本身,然后就可以访问它的 name 属性。
通过 Thread 的 is_alive() 方法查询线程是否还在运行
join() 提供线程阻塞手段。
上面代码两个线程是同时运行的,但如果让一个先运行,一个后运行,怎么做呢?
调用一个 Thread 的 join() 方法,可以阻塞自身所在的线程。
TestThread 中 daemon 属性默认是 False,这使得 MainThread 需要等待它的结束,自身才结束。当然也可以在子线程的构造器中传递 daemon 的值为 True。
具体实现:
import threading
import time
def test():
for i in range(5):
print(threading.current_thread().name+' test ',i)
time.sleep(0.5)
thread = threading.Thread(target=test,name='TestThread',daemon=True)
# thread = threading.Thread(target=test)
thread.start()
thread.join()
for i in range(5):
print(threading.current_thread().name+' main ', i)
print(thread.name+' is alive ', thread.isAlive())
time.sleep(1)
此外,还有自定义类继承 Thread,直接初始化一个 Thread,然后,现在还有一种方式就是自定义一个 Thread 的子类,然后复写它的 run() 方法。
八、Scrapy
- Scrapy框架
| engine |
引擎,类似于一个中间件,负责控制数据流在系统中的所有组件之间流动,可以理解为“传话者” |
| spider |
爬虫,负责解析response和提取Item |
| downloader |
下载器,负责下载网页数据给引擎 |
| scheduler |
调度器,负责将url入队列,默认去掉重复的url |
| item pipelines |
管道,负责处理被spider提取出来的Item数据 |
2、Scrapy Item数据封装
爬取的主要目标就是从非结构性的数据源提取结构性数据,例如网页。 Scrapy spider可以以python的dict来返回提取的数据.虽然dict很方便,并且用起来也熟悉,但是其缺少结构性,容易打错字段的名字或者返回不一致的数据,尤其在具有多个spider的大项目中。
为了定义常用的输出数据,Scrapy提供了Item 类。Item对象是种简单的容器,保存了爬取到得数据。 其提供了类似于词典(dictionary-like)的API以及用于声明可用字段的简单语法。
熟悉Django的人一定会注意到Scrapy Item定义方式与Django Models很类似, 不过没有那么多不同的字段类型(Field type),更为简单。
Item使用简单的class定义语法以及 Field对象来声明。例如:
import scrapy
class Product(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
stock = scrapy.Field()
last_updated = scrapy.Field(serializer=str)
3、scrapy管道处理
(1)管道的典型用途:
清理HTML数据
验证抓取的数据(检查项目是否包含特定字段)
检查重复(并删除)
将抓取的数据存储在数据库中
4、Item管道构建
每个项目管道组件是一个Python类,必须实现以下方法:
process_item(self, item, spider)
对于每个项目管道组件调用此方法。
process_item() 必须:返回一个带数据的dict,返回一个Item (或任何后代类)对象,返回一个Twisted Deferred或者raise DropItemexception。丢弃的项目不再由其他管道组件处理。参数:item(Itemobject或dict) - 剪切的项目 ;Spider(Spider对象) - 抓取物品的爬虫。
另外,它们还可以实现以下方法:
open_spider(self, spider)
参数:爬虫(Spider对象) - 打开的爬虫
close_spider(self, spider)
参数:爬虫(Spider对象) - 被关闭的爬虫
from_crawler(cls, crawler)
如果存在,则调用此类方法以从a创建流水线实例Crawler。它必须返回管道的新实例。Crawler对象提供对所有Scrapy核心组件(如设置和信号)的访问; 它是管道访问它们并将其功能挂钩到Scrapy中的一种方式。参数:crawler(Crawlerobject) - 使用此管道的crawler
5、Scrapy的Spider支持处理HTML/XML/JSON/CSV等数据服务接口
scrapy提供了本身提供了一种基于XPath和CSS 表达式的选择器,叫做Scrapy Selectors。
Selector有四个基本的方法:
xpath():参数是xpath表达式,也就是类似于上面例子中的表达式,
css():输入css表达式;
extract():序列化该节点为unicode字符串并返回list;
re():输入正则表达式,返回unicode字符串list列表;
这四个方法返回的都是包含所有匹配节点的list列表。
6、scrapy 数据持久化
Scrapy的数据持久化,主要包括存储到数据库、json文件以及内置数据存储
持久化流程:
1).爬虫文件爬取到数据后,需要将数据封装到items对象中。
2).使用yield关键字将items对象提交给pipelines管道进行持久化操作。
3).在管道文件中的process_item方法中接收爬虫文件提交过来的item对象,然后编写持久化存储的代码将item对象中存储的数据进行持久化存储
4).settings.py配置文件中开启管道
九、Selenium
- 查找HTML元素
selenium可以通过以下各个方法获取元素并进行各种操作,具体解释请看上方链接文档:
(1)单个节点返回:WebElement 类型
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
变式:
find_element(By.a,b)——参数a输入属性,参数b输入值
用 find_elements()方法,返回:列表类型,包含所有符合要求的节点,列表中的每个节点是 WebElement 类型
(2)多个节点返回
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
(3)常用的判断条件:
title_is 标题是某内容
title_contains 标题包含某内容
presence_of_element_located 元素加载出,传入定位元组,如(By.ID, 'p')
visibility_of_element_located 元素可见,传入定位元组
visibility_of 可见,传入元素对象
presence_of_all_elements_located 所有元素加载出
text_to_be_present_in_element 某个元素文本包含某文字
text_to_be_present_in_element_value 某个元素值包含某文字
frame_to_be_available_and_switch_to_it frame加载并切换
invisibility_of_element_located 元素不可见
element_to_be_clickable 元素可点击
staleness_of 判断一个元素是否仍在DOM,可判断页面是否已经刷新
element_to_be_selected 元素可选择,传元素对象
element_located_to_be_selected 元素可选择,传入定位元组
element_selection_state_to_be 传入元素对象以及状态,相等返回True,否则返回False
element_located_selection_state_to_be 传入定位元组以及状态,相等返回True,否则返回False
alert_is_present 是否出现Alert
2、实现用户登录
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
elenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
用python写爬虫的时候,主要用的是selenium的Webdriver。
(1)相关函数
声明浏览器对象:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
节点交互(模拟人的操作—有特定对象):
输入文字—— send_keys()方法
清空文字—— clear()方法
点击按钮—— click()方法
Cookies:
对 Cookies 进行操作
例如获取、添加、删除 Cookies 等
get_cookies() ——获取
add_cookie()——添加
delete_all_cookies() ——删除所有的 Cookies
选项卡:
execute_ script()方法
switch_ to_ window()——切换选项卡
浏览器的前进和后退:
back()
forward()
获取当前窗口句柄与切换回原窗口句柄:
通过执行js命令实现新开选项卡window.open()
不同的选项卡是存在列表里browser.window_handles
通过browser.window_handles[0]就可以操作第一个选项卡
3、爬取Ajax网页数据
有时候我们在抓取网页的时候,会发现request返回的数据和我们在浏览器页面看的不一样,在浏览器可以看到的图片和文章在返回的结果中并没有,这时候就可以考虑这是不是一个Ajax渲染的网页了。具体来讲就是在进行数据加载时,原始的网页数据可能并不包含最终看到的全部数据,,当原始的页面数据加载完后,会再想浏览器请求某个接口获取数据,然后数据再进行处理加载在界面上,这就是发送了一个Ajax请求。可以看到这里在XHR这一个选项卡中出现了许多条目,打开一个看到我们关心的数据都在这里。这就是一个Ajax渲染的网页。Ajax渲染的网页有一个很大的好处就是但我们相要更新页面的数据时,我们没必要刷新整个页面,只需要再通过页面向服务器请求一个.json数据然后在解析利用javascript插入到对应的位置就可以改变页面了,典型的例子就是一直下拉网页一直出现新的内容。
webdriver通过browser.page_source得到网页源代码,再进行xpath提取。
4、等待HTML元素
selenium 显示等待wait.until 常用封装及下拉框的选择操作等。一是强制等待time。Sleep(1.5);二是隐形等待driver。Implicitly _wait(1.5);三是显性等待
waitTime=0
While waitTime<10:
Marks=...
If makes>0:
break
If waitTime>=10:
Raise Exception(“Waiting time out”)
隐形等待:到了一定的时间发现元素还没有加载,则继续等待我们指定的时间,如果超过了我们指定的时间还没有加载就会抛出异常,如果没有需要等待的时候就已经加载完毕就会立即执行.
Python Selenium关于显式等待WebDriverWait.until的使用方法。首先先说明一下 具体使用的参数 :
WebDriverWait(driver,timeout=程序需要等待时间,poll_frequency=每隔几秒执行until中的方法).until(method='执行什么方法,具体来做什么事情')
第一个driver是固定的参数,就是 webdriver.Chrome()的实例化对象:
WebDriverWait(driver,t10,0.5).until(EC.presence_of_elemet_located(locator))
其中等待方法有:
EC.presence_of_elemet_located(locator)
EC.visiblity_of_elemet_located(locator)
EC.elemet_to_be_clickable(locator) #
Locator=(By.XPATH,” ”)
5、selenium 和 IP代理池
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作(模拟浏览器操作),同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬Selenium支持非常多的浏览器,如 Chrome、Firefox、PhantomJS等。
IP(代理):网站为了防止被爬取,会有反爬机制服务器会检测某个IP在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返回一些错误信息——可以称为封IP。
应对IP被封的问题:
(1)修改请求头,模拟浏览器(把你当做是个人)访问;采用代理IP 并轮换
设置访问时间间隔(同样是模拟人,因为人需要暂停一会)。
(2)代理:在本机和服务器之间搭桥:
本机不直接发送请求,通过桥(代理服务器)发送请求,web代理通过桥返回响应。
(3)requests 的代理设置:只需要构造代理字典,然后通过 proxies数即可,而不需要重新构建 pener
proxies = {
'http': 'http ://'+ proxy,
'https': 'https://'+ proxy }
如果需要验证,下面的代码输入两个部分即可
proxy= 'username:password@代理 ’
(4)使用 SOCKS5 代理(需要安装SOCKS库)
1)
proxies = {
'http':'socks5 ://'+ proxy,
'http': 'socks5: // '+ proxy
}
2)全局设置:
import requests
import socks
import socket
socks.set_default_proxy(socks . 50CKS5,’127.0 .0.1 ’, 9742)
socket.socket = socks.socksocket
(5)Selenium代理设置:
以Chrome为例
from selenium import webdriver
proxy= 127.0.0.1:9743
chrome_ options = webdriver.ChromeOptions ()
chrome_options.add_argument('…proxy-server=http://'+ proxy)
browser = webdriver.Chro e(chrome_options=chrome_options)
browser.get(’ http://httpbin.org/get ' )
若是认证代理:
需要在本地创建一个 manifest.json 配置文件 和 background.js 脚本来设置认证代理运行代码之后本地会生成一个 proxy auth __plugin.zip 文件来保存当前配置代理池:不是所有的代理都能用,所以要进行筛选,提出不可用代理,保留可用代理.
(6)建立代理池,设计代理的基本思路:(代理池的目标)
1):存储模块(存代理)——负责存储抓取下来的代理。首先要保证代理不重复,要标识代理的可用情况,还要动态实时处理每个代理。所以一种比较高效方便的存储方式就是使用 Redis的Sorted Set,即有序集合
2):获取模块(抓代理)——需要定时在各大代理网站抓取代理。代理可以是免费公开代理也可以是付费代理,代理的形式都是IP加端口,此模块尽量从不同来源获取,尽量抓取高匿代理,抓取成功之后将可用代理保存到数据库中
3):检测模块(能用否)——需要定时检测数据库中的代理。这里需要设置一个检测链接,最好是爬取哪个网站就检测哪个网站,这样更加有针对性,如果要做一个通用型的代理,那可以设置百度等链接来检测。
另外,我们需要标识每一个代理的状态,如设置分数标识,100分代表可用,分数越少代表越不可用。——检测一次,如果代理可用,我们可以将分数标识立即设置为100分,也可以在原基础上加1分;如果代理不可用,可以将分数标识减1分,当分数减到一定阈值后,代理就直接从数据库移除。通过这样的标识分数,我们就可以辨别代理的可用情况,选用的时候会更有针对性
4):接口模块(拿出来)——需要用 API 来提供对外服务的接口。其实我们可以直接连接数据库采取对应的数据,但是这样就需要知道数据库的连接信息,并且要配置连接。
而比较安全和方便的方式就是提供一个 Web API 接口,我们通过访问接口即可拿到可用代理。另外,由于可用代理可能有多个,那么我们可以 设置一个 随机返回 某个可用代理 的接口,这样就能保证 每个可用代理都可以取到,实现 负载均衡。