算法训练第六天 | 哈希表 242.有效的字母异位词、349. 两个数组的交集、202. 快乐数、1. 两数之和
目录
- 哈希表的理解
- LeetCode 242.有效的字母异位词
-
- 题目链接
- 思路
- 反思
- LeetCode 349. 两个数组的交集
-
- 题目链接
- 思路
- 反思
- LeetCode 202. 快乐数
-
- 题目链接
- 思路
- 反思
- LeetCode 1. 两数之和
-
- 题目链接
- 思路
- 反思
- 总结
没有写漏掉一天哟,元旦休息出去玩惹,所以今天算第六天啦,元旦快乐鸭欸瑞巴蒂~
哈希表的理解
值直接通过哈希函数得到对应索引,从而达到快速查找某个元素是否在集合里的目的。
(详解是:需要的值首先通过hashCode转化成数值,% tablesize后得到索引(此为整个hashfunction的过程),如果数值>tablesize,则会进行取模运算保证值一定落在hashtable上面,有index可得)
过程中不会存在值找不到对应索引的情况,但会存在几个值都落在同一个索引的情况(哈希碰撞),此时有两种解决方案:拉链法、线性探测法 (线性探测法必须保证tablesize>datasize,因为是按空位诺的)
哈希法的数据结构通常选择:数组、set(集合)、 map(映射)
(注意“有序”“重复”“效率”列的对比)
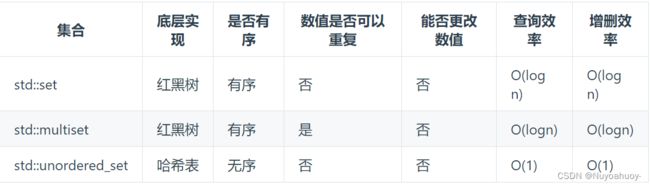
当我们要使用集合来解决哈希问题的时候,优先使用unordered_set,因为它的查询和增删效率是最优的,如果需要集合是有序的,那么就用set,如果要求不仅有序还要有重复数据的话,那么就用multiset
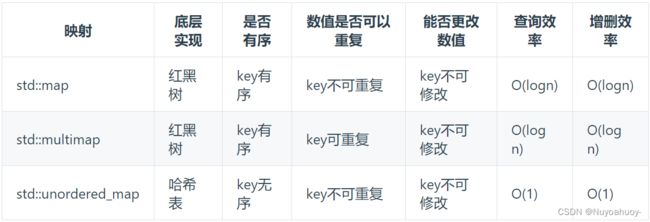
那么再来看一下map ,在map 是一个key value 的数据结构,map中,对key是有限制,对value没有限制的,因为key的存储方式使用红黑树实现的
(图片来源:代码随想录)
LeetCode 242.有效的字母异位词
题目链接
242.有效的字母异位词
思路
哈希法的思想:找到值对应的索引位置,通过±操作,最后判断该位置是否为0,全为0则√
(附上代码)
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
record = [0] *26
for i in range(len(s)):
record[ord(s[i])-ord('a')] += 1
for j in range(len(t)):
record[ord(t[j])-ord('a')] -= 1
for i in range(26):
if record[i] != 0:
return False
return True
以下是通过defaultdict方式完成,未使用数组,直接是比较了两个字典是不是一样的:
(defaultdict介绍:建立了一种字典,不包含在其中的key会给写一个默认值0)
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
from collections import defaultdict
s_dic = defaultdict(int)
t_dic = defaultdict(int)
for x in s:
s_dic[x] += 1
for y in t:
t_dic[y] += 1
return s_dic == t_dic
以下是通过Counter方式完成,未使用数组,也是直接比较了两个字典是不是一样的:
(Counter介绍:直接对list里面的元素计数,然后返回一个字典,键为元素,值为元素个数)
from collections import Counter
s_dic = Counter(s)
t_dic = Counter(t)
return s_dic == t_dic
真漂亮的代码呜呜,好简洁
反思
在相对tablesize小的情况下,能用数组就用数组,因为更便利更快,太大不适用。
ord()函数主要用来返回对应字符的ascii码,chr()主要用来表示ascii码对应的字符他的输入时数字ord('a')->97,chr(97)-> 'a'
LeetCode 349. 两个数组的交集
题目链接
349. 两个数组的交集
思路
原思路是找到短的数组,判断短数组值是否在长数组中,再存进一个新建的数组中,最后输出新数组(就是一个乱想的操作,嗯)
意外发现set的方案差不多就是这个思路,一整个误打误撞。。。难点在于怎么把number1用哈希表的方式放进set中(新建set要用set(),直接使用{}就建成了一个字典)
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
val_dict = set() #建立一个set集合,准备把num1塞进去
result = [] #建立一个list用来放结果
for i in nums1:
val_dict.add(i)
#对比nums2在nums1中是否出现了
for j in nums2:
if j in val_dict:
result.append(j)
return list(set(result))
第二思路是采用上一题的方案,数组建立哈希表(因为此题设置值<1000,是可以用数组的),还是用的set思路,框架都是一样的,代码如下:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
hashcord = [0] *1005 #建立一个数组,用1表示nums出现过的数字
result = [] #建立一个list用来放结果
for i in range(len(nums1)):
hashcord[nums1[i]] = 1
#对比nums2在nums1中是否出现了
for j in nums2:
if hashcord[j] == 1:
result.append(j)
return list(set(result))
反思
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的
什么时候用数组/set:
数组:值比较小
set:值比较大,或值之间的跨度比较大,比较分散的(会很浪费空间)
LeetCode 202. 快乐数
题目链接
202. 快乐数
思路
一开始的思路是递归,直接算完每个位置^2的sum,不是1就把sum当成n递归,然后没写出来。。。卡死在各种类型的转换上
难点在忽视了一个问题:求和的过程中,sum会重复出现,难怪我一直找不到怎么return false
对于int型去每个数:采用取模的方式,从个位数开始
def isHappy(self, n: int) -> bool:
def caculatesum(num):
sum1 = 0
while num:
sum1 += (num % 10) ** 2
num = num // 10
return sum1
resultsum = set()
while True:
n = caculatesum(n)
if n == 1:
return True
elif n in resultsum:
return False
else:
resultsum.add(n)
反思
遇到的问题:解决方案
1、不知道怎么取出整数里的每个数字:用取模方式
2、不知道在哪个地方定义set:建一个函数丢出去专门计算sum,用一个while包裹操作
3、用递归方案失败了:发现是会不断的重新定义set集合,前面都白add了
LeetCode 1. 两数之和
题目链接
1. 两数之和
思路
两个思路,第一个是把数组再存一个,然后两个for循环一个一个对,对上的返回其索引。第二个是用map(直觉告诉我最后一题了,该用map了哈哈哈)key是索引value是数值,返回数值和为target的key。(答案揭晓:写反了。。。key是值value是index)
(第一个暴力方案如下:)
def twoSum(self, nums: List[int], target: int) -> List[int]:
result = []
for i in range(len(nums)):
for j in range(len(nums)):
if i != j and nums[i] + nums[j] == target:
result.append(i)
result.append(j)
return result
return None
(第二个方案采用哈希法,用map数据结构,思路是把数组一个一个遍历,没有出现的就存进map里面,但是找的是(target-遍历的值)这个数,然后返回索引)
def twoSum(self, nums: List[int], target: int) -> List[int]:
map_ = {}
result = []
for i in range(len(nums)):
if (target - nums[i]) not in map_:
map_[nums[i]] = i
else:
result.append(map_[target-nums[i]])
result.append(i)
return result
反思
通过遍历数组元素,找之前有没有遍历到过target-num[i]这个方法挺巧思的,聪明人的思维啊,令人羡慕
因为这里也是直接找一个在集合中的元素,所以用了哈希表来完成。至于此处用的map,因为需要通过值找到索引,这样存更简便
总结
遇到要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
哈希法是牺牲了空间换取了时间,因为要使用额外的数组,set或map来存放数据,才能实现快速的查找。
如果在做面试题目的时候遇到需要判断一个元素是否出现过的场景也应该第一时间想到哈希法