Java8新特性学习_001_(Lambda表达式,函数式接口,方法引用,Stream类,Optional类)
目录
■代码 (Lambda表达式,函数式接口,方法引用 等等)
■代码运行结果 (Lambda表达式,函数式接口,方法引用 等等)
■代码说明 (Lambda表达式,函数式接口,方法引用 等等)
・44行:Stream的、foreach方法ー参数类型:函数式接口
・82行:Interface中,default方法
・92行 Stream的、max方法的ー参数类型:函数式接口
・Stream的优点(特性)
■四种常见的【函数式接口】以及【运用】
・Function (T -> R)(函数描述符, T:参数列表;R返回值) apply
・Consumer (() -> T)(函数描述符, 无需参数;T返回值) accpect
・Supplier (T -> void)(函数描述符, T:参数列表;无返回值) get
・ Predicate (T -> boolean) boolean test (T t)
■更多代码
■更多代码1(Stream,Optional)
■更多代码2(Java8 文件操作)
42行:①Files类 ②Files类的lines方法 ③try-with-resource
①Files类 // since 1.7
②lines方法 // since 1.8
③try-with-resource since 1.7
■更多代码3:传统内部类
■更多Java知识
■更多学习总结
1.Java8新特性
2.线程相关 (Java.util.concurrent.XXXXX)
3.Java8新特性学习_002_(Stream的各种方法:【map】【reduce】【limit】【skip】【collect】) (私密文章)
4.Junit (Mock) (私密文章) ⇒ 【Mockito】
5.TreeMap
6.循环处理 (数学公式【(1+1+2+1+2+3+1+2+3+4。。。)⇒n*(n+1)*(n+2)/6】)
7.正则表达式
8.文件处理 (和7链接相同,里面含有文件处理的内容)、try-with-resource
9. Comparator 与 Comparable
10.数组变成ArrayList
11.Spring + AspectJ
11.1. Spring XML 配置时【aop:aspect】与 【aop:advisor】
12.Spring、SF4J、Logback、Log4j
12.1.AOP术语
13.Optional类
14.【代理模式】 与【装饰者】的区别
15.【JDK静态代理,AspectJ】、 【JDK动态代理、CGLIB动态代理】
16.SpringBoot + Thymeleaf
17.SpringBoot + Thymeleaf + MyBatis
17.1.★★★ SpringBoot工程,Package构造笔记 ★★★
18.java中的【强引用】,【软引用】,【弱引用】,【虚引用】 ⇒与 GC 相关 ;应用【ThreadLocal】
19. finall Return
20. Map的4中遍历方式
21. Java 二维数组 (String s[][] = new String[2][];)
22.Java格式化字符串输出 (System.out.printf(String str, String[] args))
23.java基础 之------访问控制 之----protected
24.IO操作
25.网络编程
26.transient 修饰的变量,不会被 序列化。
27.Oracle:Case when
28.Java:Case、break
29.普通Maven工程配置Log4j,并使用(无Spring)
30.反射(reflect),Junit中反射的使用 ⇒ 【JMockit】
31.Spring Bean 的别名 :两种方式
31.Java Web容器加载顺序
32.Collections.rotate(Arrays.asList(arr), 2);
33.使用工具类复制文件 (FileUtils)
34.ER图生成工具(Eclipse中:【ERMaster】)
35.Mysql同时删除多个表的数据
36.Oracle 更新查询
37.List list = new ArrayList<>(20); 中的list扩充几次
38.@Autowired
39.MD5
40. ★★★ java各种考试题
41.String.format()
42.java基础 (自增,日期格式化)
43.注解 Target
44.javax.inject 需要下载额外的 javax.inject-1.jar
45.文件的 Flush
46.java中的常量
47.引用传值,方法中new时,传递进来的值会失效
48.使用javap,查看类中的 常量 和 方法
49.年金计算 (平方函数)
50.加密
51.java 注解 @NOtNull @NotEmpty @NotBlank @Null 有什么区别
52.ORM框架是什么 和 JPA 之间有联系吗
53.特殊符号【::】
54.Stream 与 Optional 中的 forEach
55.Optional.ofNullable("1").map(String::trim).map(String::isEmpty).orElse(true); 的结果
56.Oprional 的 map 方法的返回值
57.Stream 的 map 方法
58.CLOB 和 BLOB 有什么区别
59.使用Spring XML配置的示例代码
60.Spring的 BeanFacory,他有那些实现类
61.ApplicationConetext 和 BeanFactory 之间有什么关系
62.类从顶层致底的顺序初始化,基类早于子类的初始化。这个说法是否正确
63.java中 接口 属不属于 类
64.只调用类的静态块,能否造成类的初始化
65.只调用子类的静态块,是否会造成父类的初始化
66.JSP 的Directive指令有那些
67.spring自定义事件 ApplicationEvent
68.java Web 容器 的加载顺序
69.java web 中 context 和 context-param 和 Listener 之间的关系
70.介绍一下发布和订阅模式,并给出一段java代码的例子
71.Spring Bean 如果只有name属性,没有id属性,那么是否会报错
72.介绍一下 Spring 的 通知类型
73.Spring 的 @propertySource
74.@PropertySource 的源代码
75.介绍一下 Optional的ofNullable方法
76.介绍一下 Spring 动态代理 CGLIB
77.Spring 默认使用哪种代理
78.为什么Spring中一些类使用了代理,去看不见代理类的class文件
79.Spring 和AspectJ 之间是什么关系
80.Springboot 默认采用哪种代理方式
81.介绍一些 AspectJ
82.Spring中,能否使用AspectJ
83.AspectJ支持多种通知类型,如果不是AspetJ,Spring自身有没有通知类型
84.Oracl ,mysql,db2 默认使用的事务隔离级别
85.介绍一下Spring中的静态工厂方法
86.java 子类 重写 父类方法时, 那些可以不一样
87.java 方法中的 形参 在方法结束后,会立刻释放空间吗
88.一个SQL语句,能否同时删除多个表中的数据
89.JPA 事务交由 WebSphere容器处理, 数据库异常时,事务可以回滚,java异常时,数据不能回滚,原因是什么
90.什么叫做 未检查异常 和 RuntimeException Exception 之间有什么关系
91.WebSphere容器 管理 JPA事务 如果不是SQL异常,数据无法回滚
92.介绍一下 ibatis 和 mybatis
93.mybatis 和 JPA 是两种不同的数据库持久层 的框架吗
94.javax.ws.rs.Path
95.Struts 的 Action 如何能直接接受JSON类型的数据
96.Struts中的package
97.Struts 配置的 Action ,代码里面,如何接收JSON数据
98.Spring配置文件中【context:annotation-config】和【context:component-scan】
99.为什么 websphere 要在 war的基础上,再套一层ear
100.XXX
101.XXX
102.XXX
103.XXX
■SpringBoot 与 Spring
●1.@SpringBootApplication注解背后
1.ComponentScan
2.@EnableAutoConfiguration
●2. Spring的@import
代码1:SpringBoot中的使用(@EnableAutoConfiguration中,就使用了这个标注)
代码1的补充说明:AutoConfigurationImportSelector.class
代码2: AspecJ中的使用
●3.组件的注册方式
1.Spring的核心:都是一种设计模式(工厂,代理)
2.BeanFactory 是 Spring的 根容器
●4.使用SpringBoot,启动SpringBatch
●5.SpringBoot配置多个数据源
■Spring框架源码分析
1.SpringBoot的jar传递参数时,使用两个「--」横线来标记参数
2.SpringBoot 数据源自动配置
3.使用SpringBoot,启动SpringBatch (经过的各个类以及方法) (私密)
4.配置Log时,【logging.file.name】,【logging.file】
■Java中的标注
1.@PostConstruct // javax.annotation.PostConstruct
2.XX
3.XXX
■Java工具应用
1.打包Jar
2.使用Log4J (私密)
3.使用VBA调用Jar
■更多学习笔记(大篇幅 整理的笔记 )
Java学习
Servlet,Spring,Spring Boot,Sprint Batch,ThymeLeaf 学习
Spring Batch学习
Oracle学习
====
■代码 (Lambda表达式,函数式接口,方法引用 等等)
package com.sxz.test;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Optional;
import java.util.function.Consumer;
import java.util.stream.Stream;
public class TestStreamAPI {
public static void main(String[] args) {
List list= new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
list.add(6);
// 例子001
System.out.println("---Java5 For");
for (int i: list){
System.out.println("item="+i);
}
// 例子002
System.out.println("---匿名内部类 ");
Stream streamInt= list.stream();
streamInt.forEach(new Consumer() {
@Override
public void accept(Integer item) {
System.out.println("item="+item);
}
});
// 例子003
System.out.println("---Lambda ");
streamInt= list.stream();
// forEach函数,Consumer——消费型接口(只有输入,无返回)
streamInt.forEach(item -> {
System.out.println("item="+item);
});
// list.stream().forEach(item -> {
// System.out.println("item="+item);
// });
// 例子004
// 当lambda表达式只是调用了某个方法时,可以用【方法引用】代替Lambda
System.out.println("---Method Referance");
list.stream().forEach(System.out::println);
// ■函数式接口(Functional Interface)就是一个有且仅有一个抽象方法,但是可以有多个非抽象方法的接口。
// 函数式接口可以被隐式转换为 lambda 表达式。
// ■四大函数式接口--(位置:java.util.function) // 1.8
// Function——函数型接口(有输入、有返回)
// Predicate——断定型接口(有输入,返回boolean)
// Consumer——消费型接口(只有输入,无返回)
// Supplier——供给型接口(无入参,只有返回值)
// ■.1.8之前的接口特性:
//
// 1.接口中的变量都是静态常量,必须显示初始化
//
// 2.接口中的所有方法默认都是public abstract,方法不能有方法体。
//
// 3.接口中没有构造方法,不可以被实例化,可以被实现
//
// 4.实现类必须实现接口的所有方法
//
// 5.实现类可以实现多个接口
// ■JDK8及以后,允许我们在接口中定义static方法和default方法。
// https://blog.csdn.net/sxzlc/article/details/108139670
// 比如,Comparator这个接口
Comparator com;
// 例子101
// ■Java 8中提供了java.util.Optional 类,是一个容器类,
// 避免java.lang.NullPointerException
System.out.println("---Optional---Max ");
streamInt = list.stream();
// Optional one = streamInt.max(Comparator.comparing( item -> item)); // 返回值 6
// Optional one = streamInt.max((item1,item2) -> item2 - item1); // 返回值 1
Optional one = streamInt.max((item1,item2) -> item1 - item2); // 返回值 6
System.out.println(one.get());
// 例子102
System.out.println("---Optional---Greater Then Three ");
streamInt = list.stream();
Stream greateThanThree = streamInt.filter(item -> item >3);
greateThanThree.forEach(System.out::println);
// 例子102_1
System.out.println("---Optional---Greater Then Three And Get Any ");
streamInt = list.stream();
Optional greateThanThree2 = streamInt.filter(item -> item >3).findAny();
System.out.println(greateThanThree2.get());
// 例子103
System.out.println("---Optional---Greater Then Seven ");
streamInt = list.stream();
Stream greateThanSeven = streamInt.filter(item -> item >7);
greateThanSeven.forEach(System.out::println);
// 例子103_1
System.out.println("---Optional---Greater Then Seven And Get Any ");
streamInt = list.stream();
Optional greateThanSeven2 = streamInt.filter(item -> item >7).findAny();
if (greateThanSeven2.isPresent()){
System.out.println(greateThanSeven2.get());
// 如果不加判断,会出下面的错误
// Exception in thread "main" java.util.NoSuchElementException: No value present
// at java.util.Optional.get(Optional.java:135)
// at com.sxz.test.TestStreamAPI.main(TestStreamAPI.java:118)
}
}
}
■代码运行结果 (Lambda表达式,函数式接口,方法引用 等等)
---Java5 For
item=1
item=2
item=3
item=4
item=5
item=6
---匿名内部类
item=1
item=2
item=3
item=4
item=5
item=6
---Lambda
item=1
item=2
item=3
item=4
item=5
item=6
---Method Referance
1
2
3
4
5
6
---Optional---Max
6
---Optional---Greater Then Three
4
5
6
---Optional---Greater Then Three And Get Any
4
---Optional---Greater Then Seven
---Optional---Greater Then Seven And Get Any
■代码说明 (Lambda表达式,函数式接口,方法引用 等等)
・44行:Stream的、foreach方法ー参数类型:函数式接口

---
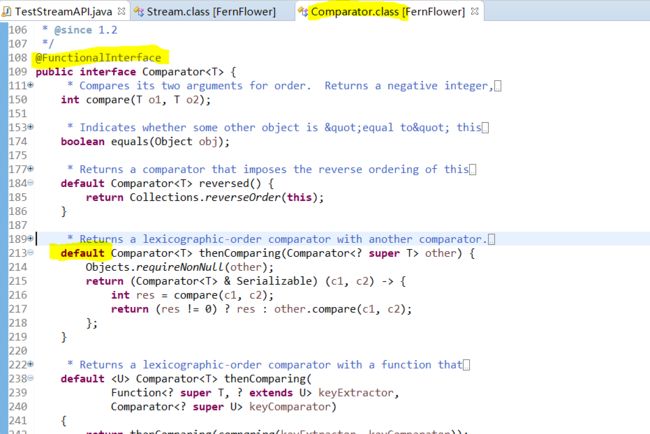
・82行:Interface中,default方法
在Java中可以为接口定义一个默认方法的实现,使用的关键字就是default,有了默认方法,实现类就可以不对接口中的默认方法进行重写。
---
--
・92行 Stream的、max方法的ー参数类型:函数式接口
参数(Comparator)是一个函数式接口

---
・Stream的优点(特性)
・无存储。stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或I/O channel等。
・为函数式编程而生。
・对stream的任何修改都不会修改背后的数据源
比如对stream执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新stream。
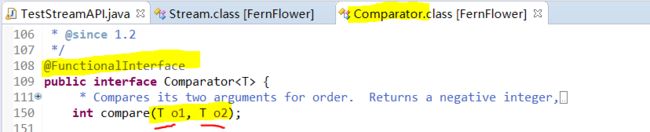
・可消费性。stream只能被“消费”一次,一旦遍历过就会失效,要再次遍历必须重新生成。
比如代码的42行:【streamInt= list.stream(); 】再次使用时,需重新生成
直接使用有两个参数的Lambda表达式
---
■四种常见的【函数式接口】以及【运用】
・Function (T -> R)(函数描述符, T:参数列表;R返回值) apply
【java.util.stream.Stream】类中
Stream map(Function mapper); ・Consumer (() -> T)(函数描述符, 无需参数;T返回值) accpect
【java.util.stream.Stream】类中
void forEach(Consumer action);・Supplier (T -> void)(函数描述符, T:参数列表;无返回值) get
【java.util.Optional】类中
public T orElseGet(Supplier other) {
return value != null ? value : other.get();
}https://blog.csdn.net/sxzlc/article/details/123946309
・ Predicate (T -> boolean) boolean test (T t)
【java.util.stream.Stream】类中
Stream filter(Predicate predicate); ====
■更多代码
====
■更多代码1(Stream,Optional)
===
package com.sxz.test;
import java.util.Arrays;
import java.util.List;
import java.util.Optional;
public class TestStream {
public static void main(String[] args) {
List list = Arrays.asList(7, 6, 9, 3, 8, 2, 1);
// 遍历输出符合条件的元素
list.stream().filter(x -> x > 6).forEach(System.out::println);
// 匹配第一个
Optional findFirst = list.stream().filter(x -> x > 6).findFirst();
// 匹配任意(适用于并行流)
Optional findAny = list.parallelStream().filter(x -> x > 6).findAny();
Optional findAny1 = list.stream().findAny();
// 是否包含符合特定条件的元素
boolean anyMatch = list.stream().anyMatch(x -> x < 6);
System.out.println("---------------");
// Stream也是支持类似集合的遍历和匹配元素的,
// 只是Stream中的元素是以Optional类型存在的。Stream的遍历、匹配非常简单。
System.out.println("匹配第一个值:" + findFirst.get());
System.out.println("匹配任意一个值:" + findAny.get());
System.out.println("匹配任意一个值1:" + findAny1.get());
System.out.println("是否存在大于6的值:" + anyMatch);
}
}
=====
■更多代码2(Java8 文件操作)
java中,正则表达式的使用 (最普通使用,Group,贪婪模式)_sun0322-CSDN博客_java正则表达式贪婪模式
package com.sxz.test;
import java.io.File;
import java.io.IOException;
import java.nio.charset.Charset;
import java.nio.file.Files;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Stream;
public class TestFileOperate {
private static String BATH_PATH = "C:\\test\\";
private static String COLUMN_REGEX=".*? ";
public static int count;
public static void main(String[] args) {
getFileNameAndPrintColumnName("test001");
}
public static void getFileNameAndPrintColumnName(String folderName){
File[] files = listFilesMatching(BATH_PATH + folderName, ".*\\.(txt|TXT)$");
List listFile = Arrays.asList(files);
listFile.stream().forEach(readFileTxt -> process(readFileTxt));
}
private static File[] listFilesMatching(String path, String regex){
final Pattern p = Pattern.compile(regex);
return new File(path).listFiles(file -> p.matcher(file.getName()).matches());
}
private static void process(File readFileTxt){
System.out.println("---" + readFileTxt.getName() + "------START");
count = 0;
final Pattern ptn = Pattern.compile(COLUMN_REGEX);
try(Stream lines = Files.lines(readFileTxt.toPath(),Charset.forName("UTF-8"))){
lines.forEach(line->{
Matcher match = ptn.matcher(line);
if(match.find()){
System.out.println(match.group());
count = count + 1;
}
});
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("---" + readFileTxt.getName() + " 项目数:" + count + "------END");
}
} ---
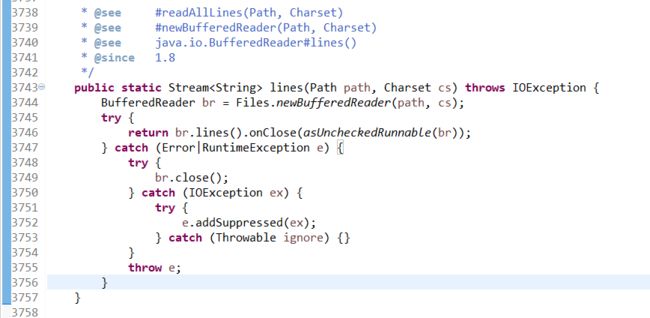
42行:①Files类 ②Files类的lines方法 ③try-with-resource
①Files类 // since 1.7

②lines方法 // since 1.8

③try-with-resource since 1.7
旨在减轻开发人员释放try块中使用的资源的义务。 它最初是在Java 7中引入的,其背后的全部想法是,开发人员无需担心仅在一个try-catch-finally块中使用的资源的资源管理。
---
■更多代码3:传统内部类
//students是个list
Collections.sort(students, new Comparator() {
@Override
public int compare(Student s1, Student s2) {
int num = s1.getAge() - s2.getAge();
if(num == 0) {
return s1.getName().compareTo(s2.getName());
}
return num;
}
}); ---
■更多Java知识
Java面试题大全(2020版)_Java笔记-CSDN博客_java面试
---
2020 最新Spring面试题_duchaochen的博客-CSDN博客_spring的接口编程主要目的是
---
■更多学习总结
1.Java8新特性
Java8新特性学习_001_(Lambda表达式,函数式接口,方法引用,Stream类,Optional类)_sun0322的博客-CSDN博客
2.线程相关 (Java.util.concurrent.XXXXX)
Java学习之Thread之【Monitor】与【wait】与【notify】与【sleep】_加【Callable】【Executor】【ExecutorService】【Future】_sun0322的博客-CSDN博客
3.Java8新特性学习_002_(Stream的各种方法:【map】【reduce】【limit】【skip】【collect】) (私密文章)
https://blog.csdn.net/sxzlc/article/details/123563903
4.Junit (Mock) (私密文章) ⇒ 【Mockito】
https://blog.csdn.net/sxzlc/article/details/123195147
5.TreeMap
https://blog.csdn.net/sxzlc/article/details/123920981
6.循环处理 (数学公式【(1+1+2+1+2+3+1+2+3+4。。。)⇒n*(n+1)*(n+2)/6】)
数学公式【(1+1+2+1+2+3+1+2+3+4。。。)⇒n*(n+1)*(n+2)/6】_sun0322的博客-CSDN博客
7.正则表达式
java中,正则表达式的使用 (最普通使用,Group,贪婪模式)_sun0322的博客-CSDN博客_java正则贪婪模式
以下是部分代码:
String checkRE = "^([a-zA-Z0-9])+@([a-zA-Z0-9\\.]+)$";
Pattern ptn = Pattern.compile(checkRE);
Matcher matStr = ptn.matcher("[email protected]");
System.out.println(matStr.find());
8.文件处理 (和7链接相同,里面含有文件处理的内容)、try-with-resource
java中,正则表达式的使用 (最普通使用,Group,贪婪模式)_sun0322的博客-CSDN博客_java正则贪婪模式
以下是部分代码:
try(Stream lines = Files.lines(readFileTxt.toPath(),Charset.forName("UTF-8"))){
lines.forEach(line->{
Matcher match = ptn.matcher(line);
if(match.find()){
System.out.println(match.group());
count = count + 1;
}
});
} catch (IOException e) {
e.printStackTrace();
---
【try-with-resource】中声明的变量,会隐式的加上【final】关键字,无法在进行赋值操作。
---
9. Comparator 与 Comparable
Comparator的使用,一般使用匿名的内部类
Collections.sort(studentList, new Comparator(){
}); 重写 compare(Object o1, Object o2)方法
return st1.age-st2.age // 升序Comparable的使用,一般实现这个接口,实现 compareTo(Object o)方法
// Object is Student
return(this.age > st.age)?1:-1 // 升序
(String类,就实现了,Comparable接口,所以String对象,可用直接比较)
negatice 负数;否点;拒绝, positive 正数;正面;积极
10.数组变成ArrayList
Arrays.AsList(String...)11.Spring + AspectJ
Java学习之「Spring + AspectJ 」_sun0322的博客-CSDN博客
11.1. Spring XML 配置时【aop:aspect】与 【aop:advisor】
//定义切面
public class SleepHelperAspect{
public void beforeSleep(){
System.out.println("睡觉前要脱衣服!");
}
public void afterSleep(){
System.out.println("起床后要穿衣服!");
}
}
//aop配置
//定义通知
public class SleepHelper implements MethodBeforeAdvice,AfterReturningAdvice{
@Override
public void before(Method arg0, Object[] arg1, Object arg2)
throws Throwable {
System.out.println("睡觉前要脱衣服!");
}
@Override
public void afterReturning(Object arg0, Method arg1, Object[] arg2,
Object arg3) throws Throwable {
System.out.println("起床后要穿衣服!");
}
}
//aop配置
12.Spring、SF4J、Logback、Log4j
JNDI RMI 注入(Log4j2漏洞)_sun0322的博客-CSDN博客_jndi注入
12.1.AOP术语
一 概念理解
■ 1 AOP的术语重在理解。 =======
Join Point:(连接点) Spring AOP中,join point就是一个方法。(通俗来讲就是起作用的那个方法,具体执行的方法)
Pointcut:(切入点) 用来指定join point(通俗来讲就是描述的一组符合某个条件的join point)。通常使用pointcut表达式来限定joint point,Spring默认使用AspectJ pointcut expression language。
Advice: 在join point上特定的时刻执行的操作,Advice有几种不同类型,下文将会讨论(通俗地来讲就是起作用的内容和时间点)。
Introduction:给对象增加方法或者属性。
Target object: Advice起作用的那个对象。
AOP proxy: 为实现AOP所生成的代理。在Spring中有两种方式生成代理:JDK代理和CGLIB代理。
Aspect: 组合了Pointcut与Advice,在Spring中有时候也称为Advisor。某些资料说Advisor是一种特殊的Aspect,其区别是Advisor只能包含一对pointcut和advice,但是aspect可以包含多对。AOP中的aspect可以类比于OOP中的class。
Weaving:将Advice织入join point的这个过程。
切面(Aspect): 切面是通知和切点的结合。
■ 2 Advice的类型 =======
Before advice: 执行在join point之前的advice,但是它不能阻止joint point的执行流程,除非抛出了一个异常(exception)。
After returning advice: 执行在join point这个方法返回之后的advice。
After throwing advice: 执行在join point抛出异常之后的advice。
After(finally) advice: 执行在join point返回之后或者抛出异常之后的advice,通常用来释放所使用的资源。
Around advice: 执行在join point这个方法执行之前与之后的advice。
■ 3 两种代理 =======
Spring AOP是基于代理机制的。上文说到,Spring AOP通过JDK Proxy和CGLIB Proxy两种方法实现代理。
如果target object没有实现任何接口,那么Spring将使用CGLIB来实现代理。CGLIB是一个开源项目,它是一个强大的,高性能,高质量的Code生成类库,它可以在运行期扩展Java类与实现Java接口。
如果target object实现了一个以上的接口,那么Spring将使用JDK Proxy来实现代理,因为Spring默认使用的就是JDK Proxy,并且JDK Proxy是基于接口的。这也是Spring提倡的面向接口编程。当然,你也可以强制使用CGLIB来进行代理,但是这样可能会造成性能上的下降。
Aop动态代理如下遵从如下规则, 如果bean有接口, 则默认使用Jdk动态代理, 否则使用CGlib动态代理
CGLib Code Generation Library--
13.Optional类
https://blog.csdn.net/sxzlc/article/details/123946309
14.【代理模式】 与【装饰者】的区别
工作中使用到的单词(软件开发)_sun0322的博客-CSDN博客_https://10.59.142.4/integration
■相同点
对装饰器模式来说,装饰者(Decorator)和被装饰者(Decoratee)都实现一个接口。对代理模式来说,代理类(Proxy Class)和真实处理的类(Real Class)都实现同一个接口。此外,不论我们使用哪一个模式,都可以很容易地在真实对象的方法前面或者后面加上自定义的方法。
■不同点
在上面的例子中,
【装饰器模式】是使用的调用者从外部传入的被装饰对象(coffee),调用者只想要你把他给你的对象装饰(加强)一下。
而【代理模式】使用的是代理对象在自己的构造方法里面new的一个被代理的对象,不是调用者传入的。调用者不知道你找了其他人,他也不关心这些事,只要你把事情做对了即可。
15.【JDK静态代理,AspectJ】、 【JDK动态代理、CGLIB动态代理】
・JDK动态代理,需要实现接口
16.SpringBoot + Thymeleaf
SpringBoot + Thymeleaf 之 HelloWorld_sun0322的博客-CSDN博客
17.SpringBoot + Thymeleaf + MyBatis
SpringBoot + MyBatis + Thymeleaf 之 HelloWorld_sun0322的博客-CSDN博客
17.1.★★★ SpringBoot工程,Package构造笔记 ★★★
Spring工程,Package构造_sun0322的博客-CSDN博客
18.java中的【强引用】,【软引用】,【弱引用】,【虚引用】 ⇒与 GC 相关 ;应用【ThreadLocal】
https://blog.csdn.net/sxzlc/article/details/123988666
19. finall Return
java中 有return 的情况,return以及try,finally代码块的执行顺序_sun0322的博客-CSDN博客
20. Map的4中遍历方式
Map的四种遍历方式_sun0322的博客-CSDN博客_map四种遍历
21. Java 二维数组 (String s[][] = new String[2][];)
https://blog.csdn.net/sxzlc/article/details/124070892
22.Java格式化字符串输出 (System.out.printf(String str, String[] args))
https://blog.csdn.net/sxzlc/article/details/124077379
23.java基础 之------访问控制 之----protected
https://blog.csdn.net/sxzlc/article/details/124079131
24.IO操作
InputStream和Reader的区别 (OutputStream和Writer的区别)
Java 流(Stream)、文件(File)和IO | 菜鸟教程
序列化/反序列化的定义
Java 序列化 | 菜鸟教程
25.网络编程
Socket通信的原理及用法 (Socket 基于网络操作的 IO)
Java 网络编程 | 菜鸟教程
RESTful Web services的原理
RESTful 架构详解 | 菜鸟教程
Web Services
JAX-WS Tutorial - javatpoint
26.transient 修饰的变量,不会被 序列化。
transient 英[ˈtrænziənt]
n. 过往旅客;临时旅客;候鸟;瞬变现象
adj. 短暂的;路过的;临时的对于transient 修饰的成员变量,在类的实例对象的序列化处理 过程中会被忽略。 因此,transient变量不会贯穿对象的序列化和反序列化,生命周期仅存于调用者的内存中而不会写到磁
public final class StringBuffer
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
/**
* A cache of the last value returned by toString. Cleared
* whenever the StringBuffer is modified.
*/
private transient char[] toStringCache;27.Oracle:Case when
Case when的用法,一旦满足了某一个WHEN ,则这一条数据就会退出CASE WHEN,而不再考虑其他CASE
Oracle:Case when 没有 Break
28.Java:Case、break
break;语句"不是必须的"。
如果不写,如果一旦case相应的值成功,但内部没有break语句,
那么将会无条件(不再进行case匹配)的继续向下执行其它case中的语句,
直到遇到break;语句或者到达switch语句结束。
29.普通Maven工程配置Log4j,并使用(无Spring)
https://blog.csdn.net/sxzlc/article/details/124621551
----
30.反射(reflect),Junit中反射的使用 ⇒ 【JMockit】
https://blog.csdn.net/sxzlc/article/details/124655686
---
31.Spring Bean 的别名 :两种方式
1.使用alias
使用alias设置别名,alias的name要和bean的ID相同。可以设置多个别名
2.使用name
多个别名用、英文逗号(,)、英文分号(;) 分隔
===
31.Java Web容器加载顺序
ServletContext -> context-param -> listener-> filter -> servlet
启动web项目后,web容器首先回去找web.xml文件,读取这个文 件。
容器会创建一个 ServletContext ( servlet 上下文),整个 web 项目的所有部分都将共享这个上下文。
容器将 转换为键值对,并交给 servletContext
容器创建 中的类实例,创建监听器。
容器加载filter,创建过滤器, 要注意对应的filter-mapping一定要放在filter的后面。
容器加载servlet,加载顺序按照 Load-on-startup 来执行java web的初始化加载顺序,以及servlet的运行过程_douya_bb的博客-CSDN博客_servlet初始化加载类
32.Collections.rotate(Arrays.asList(arr), 2);
代码
package com.sxz.test;
import java.util.Arrays;
import java.util.Collections;
public class CollectionRotate {
public static void main(String[] args)
{
Integer arr[] = {10, 20, 30, 40, 50};
System.out.println("Original Array:" + Arrays.toString(arr));
// rotating an array by distance 2
System.out.println("rotating an array by distance 2 ");
Collections.rotate(Arrays.asList(arr), 2);
System.out.println("Modified Array:" + Arrays.toString(arr));
}
}
结果
Original Array:[10, 20, 30, 40, 50]
rotating an array by distance 2
Modified Array:[40, 50, 10, 20, 30]
===
33.使用工具类复制文件 (FileUtils)
FileUtils走读笔记 - - ITeye博客
java
package com.sxz.study;
import java.io.File;
import java.io.IOException;
import org.apache.commons.io.FileUtils;
public class FileUtilsTest {
public static void main(String[] args) {
File from = new File("C:\\test\\from\\test001\\sss.txt");
File to = new File("C:\\test\\to");
try {
FileUtils.copyFileToDirectory(from ,to);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
pom引用第三方jar
commons-io
commons-io
2.8.0
34.ER图生成工具(Eclipse中:【ERMaster】)
https://blog.csdn.net/sxzlc/article/details/124738001
35.Mysql同时删除多个表的数据
DELET
t1, t2
FROM
TABLEA t1
INNER JOIN TABLEB t2 ON t1.id = t2.id
WHERE
DATEDIFF(CURRENT_DATE(), t1.create_time) > 2;36.Oracle 更新查询
根据条件,更新全部执行:
update tableName set (a,b,c)=(select a,b,c from ida where ida.id=tableName.id);
update tableName t1 set a=(select t2.a from ida t2 where t1.id=t2.id),b=(select t2.b from ida t2 where t1.id=t2.id),c=(select t2.c from ida t2 where t1.id=t2.id)
每条数据执行:
UPDATEtableName SET (A,B,C)=(select A,B,C from tableName where id=''xxxxxx) WHERE id='xxxxxxx'37.List list = new ArrayList<>(20); 中的list扩充几次
List list = new ArrayList<>(20); 0次
面试题|集合ArrayList list = new ArrayList(20) 中的list扩充几次?_赵先生-的博客-CSDN博客_list扩充了几次
ArrayList list=new ArrayList();
这种是默认创建大小为10的数组,每次扩容大小为1.5倍
ArrayList list=new ArrayList(20);
使用的ArrayList的有参构造函数===
38.@Autowired
@Target({ElementType.CONSTRUCTOR, ElementType.METHOD, ElementType.PARAMETER, ElementType.FIELD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface Autowired {
/**
* Declares whether the annotated dependency is required.
* Defaults to {@code true}.
*/
boolean required() default true;
}
39.MD5
MD5 与 Base64一起使用 加密,计算原理_sun0322的博客-CSDN博客_md5加密base64
40. ★★★ java各种考试题
https://blog.csdn.net/sxzlc/article/details/124956082
41.String.format()
string.format()详解 - 双间 - 博客园 (cnblogs.com)
42.java基础 (自增,日期格式化)
https://blog.csdn.net/sxzlc/article/details/124767861
43.注解 Target
| @Target({ElementType.TYPE, ElementType | |
| TYPE | 类、接口(包括注释类型)或枚举声明 |
| FIELD | 字段声明(包括枚举常量) |
| METHOD | 方法声明 |
| PARAMETER | 参数声明 |
| CONSTRUCTOR | 构造方法声明 |
| LOCAL_VARIABLE | 局部变量声明 |
| ANNOTATION_TYPE | 注释类型声明 |
| PACKAGE | 包声明 |
44.javax.inject 需要下载额外的 javax.inject-1.jar
。。。
javax.inject
javax.inject
1
repo1
repo1
https://repo1.maven.org/maven2
===
/*
* Copyright (C) 2009 The JSR-330 Expert Group
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package javax.inject;
import java.lang.annotation.Retention;
import java.lang.annotation.Documented;
import static java.lang.annotation.RetentionPolicy.RUNTIME;
/**
* String-based {@linkplain Qualifier qualifier}.
*
* Example usage:
*
*
* public class Car {
* @Inject @Named("driver") Seat driverSeat;
* @Inject @Named("passenger") Seat passengerSeat;
* ...
* }
*/
@Qualifier
@Documented
@Retention(RUNTIME)
public @interface Named {
/** The name. */
String value() default "";
}
45.文件的 Flush
package com.sxz.test2;
import java.io.FileWriter;
import java.io.IOException;
public class FlushTest {
public static void main(String[] args) throws IOException {
// 文件大小是0size,里面什么也没有
FileWriter fileWriter1 = new FileWriter("C:\\test\\Hello1.txt");
fileWriter1.write("123\r\n" +
"456");
// 不调用flush()方法你会发现,文件是空白的,没有把数据写进来,也是因为数据在内存中而不是落盘到磁盘了。
// 所以为了实时性和安全性,IO在写操作的时候,需要调用flush()或者close()
// close() 和flush()的区别:关close()是闭流对象,但是会先刷新一次缓冲区,关闭之后,流对象不可以继续再使用了,否则报空指针异常。
// flush()仅仅是刷新缓冲区,准确的说是"强制写出缓冲区的数据",流对象还可以继续使用。
// 文件有内容
try (FileWriter fileWriter2 = new FileWriter("C:\\test\\Hello2.txt");){
fileWriter2.write("12345\r\n" +
"456789");
}
// public class FileWriter extends OutputStreamWriter {
// public class OutputStreamWriter extends Writer {
// public abstract class Writer implements Appendable, Closeable, Flushable {
}
}
46.java中的常量
・项目在经javac编译成class文件后、常量在应用中(编译后的class中)不是以常量名的形式存在的、而是以常量值的形式存在。
・因此、即使我们修改了一个常量类、 其他的编译好的仍然使用原值。
・也就是说无论我怎么替换这个常量类的class文件、其他文件只要指向这个class文件里面的常量、都会加载之前的值(原值)===
遇到的问题:
想直接替换发布的Web工程的class文件,结果发现直接替换被引用的常量类无效。
解决:
引用常量的类的class,也要作为替换对象,重新编译,替换。
47.引用传值,方法中new时,传递进来的值会失效
下面代码运行结果是aaa
package com.sxz.reference;
public class Test {
public static void main(String[] args) {
// TODO Auto-generated method stub
TestAAA aaa = new TestAAA();
aaa.setAaa("aaa");
setAAAInfo(aaa);
System.out.println(aaa.getAaa());
}
public static void setAAAInfo(TestAAA aaa){
aaa = new TestAAA();
aaa.setAaa("bbb");
}
}
class TestAAA{
private String aaa;
public String getAaa() {
return aaa;
}
public void setAaa(String aaa) {
this.aaa = aaa;
}
}
48.使用javap,查看类中的 常量 和 方法
java
package com.sxz.constants;
public class TestConstant {
private String testAbc;
public final String TEST_AAA = "12345";
public static final String TEST_STATIC_AAA = "1223456";
public String getTestAbc() {
return testAbc;
}
public void setTestAbc(String testAbc) {
this.testAbc = testAbc;
}
}
javap
javap -constants .\TestConstant.class
49.年金计算 (平方函数)
==
package com.sxz.calc;
public class Test {
public static void main(String[] args){
double result;
double rate = 0.1;
double money =2000;
int year =5;
result=money*rate/(Math.pow((1+rate), year)-1);
System.out.println(result);
}
}50.加密
AES加密、MD5、SHA256等散列生成(java代码)_md5密钥生成_sun0322的博客-CSDN博客
51.java 注解 @NOtNull @NotEmpty @NotBlank @Null 有什么区别
这些注解都是用于数据校验的,但是有些微小的区别:
・@NotNull:用于检查一个对象是否为 null,如果是 null,则会抛出异常。
・@NotEmpty:用于检查一个字符串、集合或数组是否为空,如果为空,则会抛出异常。
・@NotBlank:用于检查一个字符串是否为空或者只包含空格,如果是,则会抛出异常。
・@Null:用于检查一个对象是否为 null,如果不是 null,则会抛出异常。
总的来说,这些注解都是用于数据校验,但是它们的校验范围和校验规则略有不同
这些注解可以在各种 Java 框架和应用程序中使用。例如,Spring 框架中的数据验证、Hibernate 的 ORM 框架等。
pom
com.google.code.findbugs
jsr305
3.0.2
org.apache.commons
commons-lang3
3.9
org.hibernate.validator
hibernate-validator
6.1.5.Final
xxx
52.ORM框架是什么 和 JPA 之间有联系吗
ORM(Object Relational Mapping)框架是一种将对象模型与关系数据库模型映射起来的技术,它可以让开发人员直接使用对象来操作数据库,避免了直接使用SQL语言的繁琐和复杂。
JPA(Java Persistence API)是Java EE 5规范中定义的一组API,它提供了一种标准的方式来进行对象持久化,也就是将Java对象存储到数据库中。JPA并不是一个具体的实现,而是一种规范,具体实现可以是Hibernate、TopLink等等。
因此,JPA是一种ORM框架的规范,而Hibernate、TopLink等是JPA的具体实现。JPA规范提供了一些接口和注解,让开发人员可以用标准的方式来进行对象持久化操作,而具体实现则由不同的ORM框架来完成。
xxx
53.特殊符号【::】
在Java 8中,"::"被用作方法引用的操作符。它允许您引用一个已经存在的方法而不是执行它。
在使用方法引用时,可以使用以下几种不同的语法形式:
静态方法引用:ClassName::staticMethodName 例如:Math::abs,表示引用 Math 类中的静态方法 abs。
实例方法引用:instance::instanceMethodName 例如:str::length,表示引用字符串对象 str 的实例方法 length。
类构造器引用:ClassName::new 例如:ArrayList::new,表示引用 ArrayList 类的构造器。
数组构造器引用:Type[]::new 例如:int[]::new,表示引用 int 类型数组的构造器。
方法引用主要用于简化Lambda表达式,使代码更加简洁和易读。它可以替换一些简单的Lambda表达式,例如只调用一个已存在的方法的Lambda表达式,可以使用方法引用来提高可读性和可维护性。
---

--

----
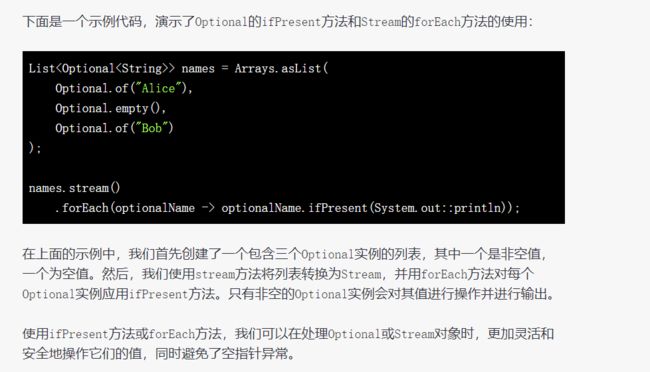
54.Stream 与 Optional 中的 forEach
xxx
在Java 8中,
Stream和Optional是两个非常有用的类。Stream用于处理集合(或其他数据源)中的元素序列,而Optional用于处理可能存在或不存在的值。
Stream类中的forEach方法接受一个函数式接口作为参数,并对Stream中的每个元素都应用该函数。而Optional类也有一个名为ifPresent的方法,它的作用和Stream中的forEach类似,用于对Optional中的值进行操作。
xxx

xxx
xxx
55.Optional.ofNullable("1").map(String::trim).map(String::isEmpty).orElse(true); 的结果
xxx
在这段代码中,调用 Optional.ofNullable("1") 创建了一个 Optional 实例,该实例的值为字符串 "1"。然后使用 map 方法依次对值进行处理。
首先,调用 map(String::trim) 方法对字符串进行 trim 操作,去除首尾空格,得到一个新的 Optional 实例。然后再次调用 map(String::isEmpty) 方法,判断字符串是否为空,返回一个新的 Optional 实例。
最后,调用 orElse(true) 方法,如果最终的 Optional 实例的值存在,就返回该值;如果值不存在,则返回传入的参数 true。
因此,根据代码的处理,结果为 false。因为经过 trim() 方法处理后的字符串 "1" 并非空字符串,所以最终返回 false。
xxx
56.Oprional 的 map 方法的返回值
Optional类中的map方法是一个非常有用的方法,它接受一个函数式接口作为参数,并将Optional实例中的值进行转换。map方法将原始的Optional对象转换为一个新的Optional对象,该对象包含经过映射函数处理后的值。

xxx
57.Stream 的 map 方法
Stream类中的map方法是一个非常重要的方法,它用于对流中的每个元素进行转换和映射操作。map方法接受一个函数式接口作为参数,并将流中的每个元素传入该函数进行处理,然后返回一个新的Stream对象,该对象包含了映射后的元素。
x'x'x

xxx

58.CLOB 和 BLOB 有什么区别
CLOB(Character Large Object)和BLOB(Binary Large Object)是用于存储大型对象的数据类型,但它们在处理的数据类型上有所不同。
数据类型:CLOB用于存储包含字符数据的大型对象,例如文本、日志文件等。BLOB用于存储二进制数据,如图像、音频、视频等。
字符编码:CLOB支持单字节字符集和多字节字符集,因此适用于存储字符数据,可以进行字符级别的排序和比较。BLOB存储的是二进制数据,不涉及字符编码。
存储方式:CLOB存储的是文本数据,可以进行文本处理操作,如查找、替换、连接等。BLOB存储的是二进制数据,可以进行二进制处理操作,如图像处理、音频转换等。
存储限制:CLOB可以存储最多4GB的数据。BLOB也可以存储最多4GB的数据。
总之,CLOB适用于存储字符数据,而BLOB适用于存储二进制数据。选择何种类型取决于您要存储的数据的性质和需要进行的操作。
xxx
数据库 大写超过多少 算是 大型对象
在数据库中,大型对象(Large Objects)通常指的是用于存储大容量数据的特殊数据类型,比如文档、图像、音频或视频等。
具体来说,在关系型数据库中,常见的大型对象数据类型包括以下几种:
BLOB:二进制大型对象,用于存储二进制数据,比如图像、音频、视频等。CLOB:字符大型对象,用于存储较大的文本数据。NCLOB:用于存储较大的 Unicode(多字节字符集)文本数据。根据每种数据库的实现和具体的配置,大小的界限可能有所不同。一般来说,当数据大小超过存储引擎所支持的最大长度限制时,可以认为数据字段是大型对象。
===
例如,MySQL InnoDB 存储引擎支持大型对象,而其最大行大小限制为 65,535 字节,所以超过这个限制的字段可能被认为是大型对象。但是请注意,这只是一个大致的参考,具体限制可能因数据库版本、配置或其他因素而有所差异。
==
因此,超过存储引擎所支持的最大长度限制,或者超过常规字段数据类型的容量限制的数据字段,可以被认为是大型对象。对于具体的数据库系统,建议参考其官方文档或与数据库管理员确认来获取更准确的信息。
xxx
定义数据库字段时, 使用哪种方式代替 varchar(20000) 比较合适
定义数据库字段时, 使用哪种方式代替 varchar(20000) 比较合适
===
当定义数据库字段时,如果想代替 VARCHAR(20000),以下几种方式可能更合适:TEXT:这是一种用于存储较大文本数据的数据类型,不限制字符数。它适合存储大段的文本,比如文章内容。
====
MEDIUMTEXT:这是一种数据类型,用于存储中等长度的文本数据,可以存储最大长度为 16,777,215 (2^24 - 1) 个字符的文本。
LONGTEXT:这是一种适用于存储非常长文本数据的数据类型,可以存储最大长度为 4,294,967,295 (2^32 - 1) 个字符的文本。
===
选择合适的数据类型取决于你需要存储的文本数据的预期大小。如果文本数据不超过 65,535 个字符,可以考虑使用 VARCHAR 数据类型加上适当的长度。如果文本数据超过这个限制,上述的 TEXT、MEDIUMTEXT 或 LONGTEXT 可能更适合。请根据具体的需求选择合适的方式。
xxx
59.使用Spring XML配置的示例代码
applicationContext.xml的Spring配置文件,该文件位于项目的classpath中。可以在文件中定义bean以及它们的属性和依赖关系。
然后,创建相应的Java类来使用上述配置文件中定义的bean
public class MessageServiceImpl implements MessageService {
private String message;
public void setMessage(String message) {
this.message = message;
}
public String getMessage() {
return message;
}
}
public class MessagePrinter {
private MessageService messageService;
public void setMessageService(MessageService messageService) {
this.messageService = messageService;
}
public void printMessage() {
System.out.println(messageService.getMessage());
}
}
public class Main {
public static void main(String[] args) {
// 加载Spring配置文件
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
// 获取messagePrinter的bean实例
MessagePrinter printer = context.getBean("messagePrinter", MessagePrinter.class);
// 调用printMessage方法打印消息
printer.printMessage();
}
}===
60.Spring的 BeanFacory,他有那些实现类
Spring的
BeanFactory是Spring IoC容器的最底层接口,用于管理和提供bean的实例。BeanFactory提供了对bean的创建、装配和生命周期的管理。Spring提供了多个
BeanFactory的实现类,其中一些常用的实现类如下:
XmlBeanFactory:从XML配置文件中加载bean定义并实例化bean。这是Spring早期的经典实现,现已不推荐使用。
DefaultListableBeanFactory:支持XML和注解配置的通用BeanFactory实现。它可以从各种资源(如XML文件、Java注解)中读取bean定义,并负责实例化、配置和管理所有bean。
AnnotationConfigApplicationContext:基于Java注解的配置,从Java类中加载bean定义并实例化bean。它使用注解方式来声明bean和配置Spring容器,而无需XML文件。
ClassPathXmlApplicationContext:从类路径下的XML文件中加载bean定义并实例化bean。这是最常用的ApplicationContext实现类之一。
FileSystemXmlApplicationContext:从文件系统中的XML文件中加载bean定义并实例化bean。它允许指定绝对路径或相对路径的XML配置文件位置。此外,Spring还提供了其他一些特殊用途的
BeanFactory实现类,如:
HierarchicalBeanFactory:支持层次性父子关系的BeanFactory。子容器可以访问父容器中的bean,但父容器无法访问子容器中的bean。
ApplicationContext:是BeanFactory的子接口,为Spring提供了更多的功能和特性。ApplicationContext包含了BeanFactory的所有功能,并且额外提供了国际化、事件传播、资源管理等。需要根据具体的使用场景和需求选择合适的
BeanFactory实现类。一般来说,推荐使用ApplicationContext的具体实现类,例如ClassPathXmlApplicationContext、AnnotationConfigApplicationContext,以支持更便捷和强大的Spring功能。
61.ApplicationConetext 和 BeanFactory 之间有什么关系
ApplicationContext是BeanFactory的子接口,它扩展了BeanFactory的功能,提供了更多的企业级特性和便捷的应用程序上下文管理。
ApplicationContext相比于BeanFactory,提供了以下额外的功能和特性:
定位和加载bean定义:
ApplicationContext可以从不同的资源(如XML文件、注解等)中加载bean定义,而BeanFactory只能从XML文件中加载。预实例化bean:
ApplicationContext在初始化时会预实例化所有非延迟加载的单例Bean。而BeanFactory在调用getBean()方法时才实例化bean。AOP支持:
ApplicationContext提供了对AOP(面向切面编程)的支持,可以方便地创建和管理切面、通知等。国际化支持:
ApplicationContext提供了国际化和本地化消息处理的能力。事件传播:
ApplicationContext支持事件发布和订阅模型,可以在容器中发送事件,并被其他对象监听和响应。Web应用支持:
ApplicationContext提供了与Web应用相关的功能,如处理请求、处理表单、文件上传等。总结来说,
ApplicationContext是BeanFactory在功能上的扩展,提供了更多的特性和便捷的应用程序上下文管理。在实际开发中,通常使用ApplicationContext的具体实现类,如ClassPathXmlApplicationContext、AnnotationConfigApplicationContext,以获得更强大和方便的Spring功能。
62.类从顶层致底的顺序初始化,基类早于子类的初始化。这个说法是否正确
不,这个说法是错误的。在Java中,类的初始化是通过以下顺序进行的:
静态成员的初始化。静态成员包括静态变量和静态代码块,它们在类加载时按照顺序依次执行。这些静态成员的初始化与类的继承关系无关。
父类的初始化。如果当前类有父类,那么会先初始化父类。基类的初始化是在子类的构造方法中调用super关键字实现的。
子类的初始化。当父类初始化完成后,才会进行子类的初始化。子类的初始化包括实例变量的初始化和构造方法的执行。
所以,在类的初始化过程中,先进行静态成员的初始化,然后是基类的初始化,最后是子类的初始化。可以说基类在子类之前初始化是正确的说法。
xxx
63.java中 接口 属不属于 类
在Java中,接口(Interface)是一种特殊的引用类型,它被用于定义一组相关方法的集合,但是不包含实际的实现代码。
尽管接口在语法上和类类似,但它并不是类的一种形式。类被用于定义对象的结构和行为,而接口则被用于定义对象的行为规范。
类可以实现一个或多个接口,这意味着类需要遵循接口中定义的一组方法的规范。类通过使用关键字
implements来实现接口。同时,一个类可以同时继承一个类(父类)并实现一个或多个接口。所以,接口在Java中不属于类,但是类可以实现接口。
64.只调用类的静态块,能否造成类的初始化
是的,调用类的静态代码块可以触发该类的初始化。静态代码块是在类加载的过程中执行的,用于初始化类的静态成员变量或执行一些静态逻辑。
当调用一个类的静态代码块时,如果该类尚未被初始化,则会触发类的初始化。类的初始化过程包括执行静态代码块,并初始化该类的静态成员变量。
需要注意的是,类的初始化只会发生一次。如果类已经被初始化过了,后续对静态代码块的调用不会再触发初始化。所以,每个类的静态代码块只会被执行一次,无论调用多少次。
65.只调用子类的静态块,是否会造成父类的初始化
在调用子类的静态代码块时,如果父类尚未进行初始化,则会触发父类的初始化过程。这是因为子类的静态代码块可能依赖于父类的静态成员或静态代码块,因此在子类初始化之前,需要确保父类已经完成初始化。
由于父类在子类之前进行初始化,所以即使只调用子类的静态代码块,父类的静态代码块也会被触发执行,以确保父类的静态成员被正确初始化。
需要注意的是,父类的静态代码块只会在第一次调用子类的静态代码块时执行一次,后续调用子类的静态代码块不会重新触发父类的初始化。而且每个类的静态代码块只会执行一次,无论被调用多少次。
66.JSP 的Directive指令有那些
在JSP中,Directive指令用于控制JSP页面的整体行为和属性。以下是几种常用的Directive指令:
page指令:用于定义整个JSP页面的属性和行为,如页面编码、缓存控制等。 示例: <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8" %>
include指令:用于将其他JSP页面的内容嵌入当前页面。 示例: <%@ include file="header.jsp" %>
taglib指令:用于引入标签库(Tag Library)的定义,以便在页面中使用自定义标签。 示例: <%@ taglib uri="http://example.com/mytags" prefix="my" %>
taglib指令(EL):用于引入标签库(Tag Library)的定义,并指定EL前缀。 示例: <%@ taglib uri="http://java.sun.com/jstl/core_rt" prefix="c" %>
这些Directive指令在JSP中使用<%@ ... %> 的形式进行声明,放置在JSP页面的最顶部。它们用于控制页面的整体行为和属性,影响整个页面的渲染和执行过程。
67.spring自定义事件 ApplicationEvent
在Spring框架中,可以通过自定义事件来实现模块间的松耦合,将业务逻辑分离开来,提高系统的可扩展性和可维护性。Spring提供了一个基于观察者模式的事件机制。
在Spring框架中,事件是一种发布和订阅模式,用于处理应用程序内部的事件通知和响应。事件可以是应用程序内部的状态改变、用户操作、系统事件等,用于驱动应用程序中的业务逻辑。
Spring中的事件包括以下几个关键元素:
事件:表示应用程序内部的某个状态或动作,通常以类的形式存在,继承自ApplicationEvent类。
事件发布者:负责发布事件的对象,通过ApplicationContext的publishEvent()方法来发布事件。
事件监听器:负责监听和处理事件的对象,通过实现ApplicationListener接口来定义事件的处理逻辑。
当事件发布者触发某个事件时,应用程序会自动调用对应的事件监听器,执行相应的业务逻辑。通过事件机制,可以将不同模块之间耦合度降低,并实现模块之间的解耦。
自定义事件的关键是两个部分:事件类和事件监听器。
首先,要定义一个事件类,该事件类必须继承自ApplicationEvent类,同时需要提供一个构造函数,该构造函数会接受事件的数据。
public class CustomEvent extends ApplicationEvent {
private String eventData;
public CustomEvent(Object source, String eventData) {
super(source);
this.eventData = eventData;
}
public String getEventData() {
return eventData;
}
}接下来,需要定义一个事件监听器类,该类需要实现ApplicationListener接口,并实现onApplicationEvent方法,该方法会处理接收到的事件。
public class CustomEventListener implements ApplicationListener {
@Override
public void onApplicationEvent(CustomEvent event) {
System.out.println("Received custom event with data: " + event.getEventData());
// 按需处理事件
}
} 在Spring容器中注册事件监听器,可以使用@Component注解或者在配置文件中配置bean。
@Component
public class CustomEventListener {
// ...
}
最后,要发布自定义事件,可以使用ApplicationEventPublisher接口的publishEvent方法
@Autowired
private ApplicationEventPublisher applicationEventPublisher;
public void publishCustomEvent(String eventData) {
CustomEvent event = new CustomEvent(this, eventData);
applicationEventPublisher.publishEvent(event);
}这样,当调用publishCustomEvent方法发布事件时,所有注册的CustomEventListener监听器就会接收到该事件,并执行相应的处理逻辑。
自定义事件的使用可以使代码更加灵活和可扩展,方便模块间的解耦。
xxx
===
68.java Web 容器 的加载顺序
在Java Web程序中,容器是指Servlet容器(如Tomcat、Jetty等)。下面是Servlet容器加载Web应用程序的基本顺序:
容器检测并读取web.xml文件:当Servlet容器启动时,它会检测Web应用程序的部署描述符(web.xml文件),并将其加载到内存中。这个文件包含了Web应用程序的配置信息,如Servlet、Filter、Listener的声明以及应用程序的初始化参数等。
初始化容器:容器会根据web.xml文件中的配置信息,初始化Servlet容器的相关组件,如上下文(ServletContext)对象、会话管理器等。
加载并初始化Servlet:容器会根据web.xml文件中的配置信息,加载Servlet类,并调用其init()方法进行初始化。在初始化过程中,Servlet可以执行一些必要的初始化操作,如建立数据库连接、加载配置文件等。
加载并初始化Filter:容器会根据web.xml文件中的配置信息,加载Filter类,并进行初始化。Filter可以对请求和响应进行预处理和后处理操作。
加载并注册Listener:容器会根据web.xml文件中的配置信息,加载Listener类,并注册它们。这些Listener可以监听Web应用程序的生命周期事件,如应用程序的启动和关闭。
初始化上下文参数:容器会读取web.xml文件中定义的上下文参数,并将它们设置到ServletContext对象中。这些参数可以在整个Web应用程序中被访问和使用。
初始化完成:当上述步骤都完成后,容器会认为Web应用程序已经成功加载并初始化,可以开始接受请求并提供相应的响应。
需要注意的是,具体的加载顺序可能会因为不同的Servlet容器或配置方式而有所不同,可以根据实际情况进行调整和配置。
===
68.1.context 和 context-param 那个先加载
===
在Java Web应用程序中,ServletContext对象是在应用程序启动时首先被加载和创建的。也就是说,ServletContext对象是Web容器启动和初始化后的第一个对象。
===
接着,Servlet容器会读取web.xml文件,并在加载ServletContext对象后立即加载和设置context-param中的参数。这就意味着context-param中的参数是在ServletContext对象之后被加载的。
xxxx
69.java web 中 context 和 context-param 和 Listener 之间的关系
xx
Context(上下文):在Java Web开发中,Context通常指的是ServletContext对象,它是Servlet容器(如Tomcat、Jetty等)中的一个全局对象,代表整个Web应用程序。ServletContext对象提供了对当前Web应用程序的上下文信息和配置的访问。
Context参数(context-param):Context参数是在web.xml文件中配置的一种全局参数,可以通过ServletContext对象访问。它们是为整个Web应用程序提供的配置信息,可以在应用程序的任何地方使用。通常用于存储一些全局的、不容易改变的配置信息,如数据库连接信息、日志级别等。
Listener(监听器):Listener是一种特殊的类,可以监听Web应用程序的生命周期事件。常见的Listener有ServletContextListener、ServletRequestListener、HttpSessionListener等。它们可以在Web应用程序启动和关闭、请求和会话的创建和销毁等事件发生时触发相应的回调方法。通过监听器,可以执行一些与事件相关的处理逻辑,如初始化数据库连接池、记录用户活动日志等。
综上所述,context-param可以用来存储全局的配置信息,通过ServletContext对象进行访问;而Listener可以监听Web应用程序的生命周期事件,可以在需要执行一些初始化或清理工作时进行操作。两者都与ServletContext对象密切相关,通过ServletContext对象可以访问context-param中的参数值,并通过监听器接收和处理相应的事件。
===
xxx
70.介绍一下发布和订阅模式,并给出一段java代码的例子
发布和订阅模式,也称为观察者模式,是一种软件设计模式,它定义了对象之间的一对多依赖关系。在该模式中,一个对象(称为主题或发布者)维护一个订阅者列表,并在状态发生变化时通知所有订阅者。订阅者(也称为观察者)可以自动接收到发布者的通知,并执行相应的行为。
以下是一个使用Java代码实现的发布和订阅模式的例子:
首先,我们定义一个主题类(Publisher)作为发布者,它维护一个订阅者列表,并提供添加、删除和通知订阅者的方法:
import java.util.ArrayList;
import java.util.List;
public class Publisher {
private List subscribers = new ArrayList<>();
public void addObserver(Subscriber subscriber) {
subscribers.add(subscriber);
}
public void removeObserver(Subscriber subscriber) {
subscribers.remove(subscriber);
}
public void notifyObservers(String message) {
for (Subscriber subscriber : subscribers) {
subscriber.update(message);
}
}
} 然后,我们定义一个订阅者类(Subscriber),它实现了更新(update)方法来接收发布者的通知:
public class Subscriber {
private String name;
public Subscriber(String name) {
this.name = name;
}
public void update(String message) {
System.out.println(name + " received message: " + message);
}
}最后,我们可以使用上述的发布者和订阅者来演示发布和订阅模式:
public class Main {
public static void main(String[] args) {
Publisher publisher = new Publisher();
// 创建两个订阅者
Subscriber subscriber1 = new Subscriber("Subscriber 1");
Subscriber subscriber2 = new Subscriber("Subscriber 2");
// 将订阅者添加到发布者的订阅者列表中
publisher.addObserver(subscriber1);
publisher.addObserver(subscriber2);
// 发布者发布消息
publisher.notifyObservers("Hello, subscribers!");
// 移除一个订阅者
publisher.removeObserver(subscriber1);
// 再次发布消息
publisher.notifyObservers("How are you doing?");
}
}运行上述代码,将会输出以下结果:
Subscriber 1 received message: Hello, subscribers!
Subscriber 2 received message: Hello, subscribers!
Subscriber 1 received message: How are you doing?
Subscriber 2 received message: How are you doing?
这个例子演示了一个发布者将消息通知给多个订阅者的过程,订阅者可以自动接收到发布者的通知,并做出相应的响应。整个过程中,发布者和订阅者之间通过观察者模式实现了解耦,使得它们可以独立演化和扩展。
xx
71.Spring Bean 如果只有name属性,没有id属性,那么是否会报错
在Spring中,name属性用于指定Bean的名称(ID)。如果您使用只有name属性而没有id属性的方式声明Bean,通常不会报错,但不推荐这样做。
如果只有name属性,Spring会将name属性的值作为Bean的唯一标识符(ID)。但这样做会使代码可读性变差,并且可能会引起命名冲突问题。建议使用id属性来指定Bean的ID。
以下是正确的方式定义一个Bean:
或者可以同时使用id和name属性来定义Bean:
这样myBean将作为主要的Bean ID,而beanAlias1和beanAlias2则作为别名。
总之,为了代码的可读性和可维护性,我们建议使用id属性来指定Bean的ID,而不要仅仅依赖name属性。
xxx
72.介绍一下 Spring 的 通知类型
Spring框架中的通知(AOP通知)是在面向切面编程(AOP)中使用的横切关注点代码的实际实现。通知可以在目标方法的前、后或环绕时执行特定的操作。Spring中定义了五种通知类型:
Before(前置通知):在目标方法执行之前执行。可以在目标方法调用前执行一些预处理操作,也可以更改方法的输入参数。
After-returning(返回通知):在目标方法成功执行并返回结果后执行。可以在目标方法返回结果后执行一些后处理操作。
After-throwing(异常通知):在目标方法抛出异常时执行。可以在目标方法抛出异常后执行一些处理操作,比如记录异常日志、发送错误通知等。
After(后置通知):无论目标方法是否成功执行,都会在目标方法执行之后执行。可以进行一些清理工作,无论目标方法是否抛出异常。
Around(环绕通知):在目标方法执行前后都会执行。可以完全控制目标方法的执行,包括在目标方法执行前后添加额外的操作,甚至可以决定是否执行目标方法。
通知是AOP的核心概念之一,它允许开发者将不同的关注点代码(比如日志记录、事务管理等)与应用程序的核心逻辑分开。通过使用这些通知类型,可以更好地管理代码的可重用性、可扩展性和可维护性。
xxx
73.Spring 的 @propertySource
@propertySource是Spring框架中的一个注解,用于指定外部属性文件的位置并将其加载到Spring环境中。
使用@propertySource注解可以将外部的配置文件加载到Spring的Environment中,然后可以通过@Value注解或者使用Environment对象来获取配置属性的值。
该注解通常与@Configuration注解一起使用,被标记的类代表一个配置类,在其中可以通过使用@Value注解来获取外部属性值。
使用@propertySource注解时,需要在注解中指定属性文件的路径,可以使用classpath:前缀指定类路径下的文件,也可以使用file:前缀指定文件系统中的文件路径。
示例代码如下:
@Configuration
@PropertySource("classpath:application.properties")
public class AppConfig {
@Value("${my.property}")
private String myProperty;
// getter and setter methods
}xxx
74.@PropertySource 的源代码
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface PropertySource {
@AliasFor("location")
String[] value() default {};
@AliasFor("value")
String[] location() default {};
String[] name() default {};
boolean ignoreResourceNotFound() default false;
}xxx
@propertySource注解位于Java的元注解(meta-annotation)中,用于标记其他注解,它具有以下属性:
- value: 属性文件路径的别名。可以用来指定外部属性文件的位置,支持使用classpath:前缀指定类路径下的文件,或使用file:前缀指定文件系统中的文件路径。
- location: 属性文件路径。同样用来指定外部属性文件的位置,可以与value属性互为别名。
- name: 属性文件的名称。当指定了name属性时,可以用于从Environment中获取属性文件的值。
- ignoreResourceNotFound: 指定在找不到属性文件时是否忽略异常。默认情况下,找不到属性文件会抛出异常,当设置为true时,将会忽略此异常。
该注解通常与@Configuration注解一起使用,标记@Configuration类,指定要加载的外部属性文件的位置。当加载属性文件时,可以使用@Value注解或者Environment对象来获取属性值。
可以通过Spring的依赖注入机制,将外部属性文件的值注入到应用程序中,从而实现灵活配置和管理。
===
75.介绍一下 Optional的ofNullable方法
Optional是Java 8引入的一个容器类,用于解决空指针异常的问题。ofNullable方法是Optional类的一个静态方法,用于创建一个包含指定值的Optional对象。
ofNullable方法的使用格式如下:
OptionalofNullable(T value) 其中,T是指定值的类型,value是要包装的值。
ofNullable方法有以下几个特点:
如果value为null,则返回一个空的Optional对象。
如果value不为null,则返回一个包含value值的Optional对象。
ofNullable方法可以接收任意类型的值,包括引用类型和基本类型的包装类。
下面是一些示例用法:
// 创建一个包含非空值的Optional对象 Optionaloptional1 = Optional.ofNullable("hello"); System.out.println(optional1.isPresent()); // 输出: true System.out.println(optional1.get()); // 输出: hello // 创建一个包含空值的Optional对象 Optional optional2 = Optional.ofNullable(null); System.out.println(optional2.isPresent()); // 输出: false // 使用ofNullable方法可以避免因为值为null而抛出空指针异常 String str = null; Optional optional3 = Optional.ofNullable(str); str = optional3.orElse("default"); System.out.println(str); // 输出: default 使用ofNullable方法创建Optional对象可以方便地处理值为null的情况,避免代码中出现空指针异常。可以通过isPresent方法判断Optional对象是否包含非空值,使用get方法获取包装的值,使用orElse方法指定一个默认值,以备Optional对象为空时使用。
xxx
76.介绍一下 Spring 动态代理 CGLIB
Spring 动态代理是 Spring 框架中的一个核心特性,它基于 Java 动态代理(JDK Dynamic Proxy)和 CGLIB(Code Generation Library)两种技术实现。
===
Java 动态代理是 JDK 提供的一种代理技术,通过反射机制来动态生成代理类和代理对象。它只能代理接口,要求被代理的类必须实现相应的接口。Java 动态代理通过 Proxy 类和 InvocationHandler 接口来实现,通过在代理对象的方法调用前后加入额外的逻辑,实现对目标方法的增强。
===
CGLIB 是一个基于字节码操作的代码生成库,它可以在运行时动态的生成指定类的子类。与 Java 动态代理不同的是,CGLIB 可以直接代理普通类,而不仅限于代理接口。CGLIB 通过继承目标类的方式来生成代理类,然后通过重写和增强父类的方法来实现对目标方法的拦截。
===
Spring 动态代理根据被代理的对象类型以及是否实现了接口来选择不同的代理方式。如果目标类实现了接口,则使用 Java 动态代理;如果目标类没有实现接口,则使用 CGLIB。
===
Spring 动态代理的优点是它可以在运行时动态地增强目标类的功能,而无需修改源代码。它可以在方法调用前后进行切面逻辑的注入,如事务管理、性能监控、日志记录等。同时,封装了动态代理的细节,使开发者能够更简单地使用和配置代理功能。
xxx
77.Spring 默认使用哪种代理
Spring 默认使用的是 JDK 动态代理。
当一个类实现了至少一个接口时,Spring 会使用 JDK 动态代理来生成代理对象。JDK 动态代理通过
java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口来实现,它只能代理接口,要求被代理的类必须实现相应的接口。JDK 动态代理使用的是字节码生成技术,而不需要依赖第三方库。===
Spring 使用 JDK 动态代理的优势是它比较轻量级,无需额外依赖,不需要生成额外的代理类文件。同时,作为 Java 标准库的一部分,JDK 动态代理具有较高的兼容性和稳定性。
===
然而,当一个类没有实现任何接口时,Spring 会选择使用 CGLIB 动态代理来生成代理对象。CGLIB 是一个基于字节码操作的代码生成库,它可以在运行时动态生成指定类的子类。CGLIB 动态代理通过继承目标类的方式来生成代理类,然后通过重写和增强父类的方法来实现对目标方法的拦截。相对于 JDK 动态代理,CGLIB 动态代理更加强大,但也更加复杂和重量级。
xxx
78.为什么Spring中一些类使用了代理,去看不见代理类的class文件
在 Spring 中,使用代理的目的是为了实现 AOP(面向切面编程)。AOP 是一种编程范式,它通过将横切关注点(如日志记录、性能统计等)与业务逻辑分离,将其以模块化的方式横向切入到系统中。
==
当 Spring 在运行时生成代理类的时候,它并不会生成类文件(即 .class 文件),而是通过字节码生成技术直接在内存中生成代理类。这样做的好处是可以避免生成大量的代理类文件,使得应用程序更加清晰和易于维护。
==
通过使用字节码生成技术,Spring 可以动态地创建代理类,然后在运行时将方法调用转发到代理类。Spring 支持使用 JDK 动态代理或 CGLIB 动态代理生成代理类,具体使用哪种方式取决于目标类是否实现了接口。
===
对于使用 JDK 动态代理生成的代理类,Spring 在生成代理对象时,会使用
java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口来动态生成代理类的实例。==
对于使用 CGLIB 动态代理生成的代理类,Spring 使用 CGLIB 库来动态生成代理类的实例。这种情况下,Spring 会通过继承目标类来生成代理类,并且在运行时重写和增强父类的方法。
==
无论是使用 JDK 动态代理还是 CGLIB 动态代理,Spring 都会生成代理类的实例,而不会生成实际的代理类文件。这样做的好处是减少了磁盘的占用空间并且可以更加灵活地进行代理操作。
xxx
79.Spring 和AspectJ 之间是什么关系
Spring和AspectJ都是在Java应用程序中实现面向切面编程(AOP)的工具。
==
AspectJ是一个独立的、功能强大的AOP框架,它可以在编译时或运行时对Java代码进行静态或动态织入,以实现横切关注点(cross-cutting concerns)的处理。AspectJ提供了更广泛的AOP支持,可以直接的在代码中进行切面的定义和织入,包括使用注解或XML配置。
===
相反,Spring是一个综合性的应用程序框架,提供了广泛的功能和特性,并且可以与各种第三方库和框架集成。Spring AOP是Spring框架中的一部分,它通过代理方式实现了AOP的支持。Spring AOP是建立在动态代理的基础上,利用代理对象包装目标对象,对方法的调用进行拦截,并在方法调用前、后或周围执行切面逻辑。
===
总的来说,AspectJ是一个独立的、功能丰富的AOP框架,而Spring AOP是Spring框架中对AOP的封装和实现。AspectJ可以更细粒度地控制切面的织入,而Spring AOP是基于代理的方式实现的。在实际应用中,可以根据需要选择使用AspectJ或Spring AOP来实现AOP的功能。
xxx
80.Springboot 默认采用哪种代理方式
在Spring Boot中,默认采用的是基于JDK动态代理的方式来实现AOP。当目标类实现了接口时,Spring Boot会使用JDK动态代理来创建代理对象。 但是,当目标类没有实现接口时,Spring Boot会使用CGLIB动态代理来创建代理对象。
===
JDK动态代理是Java提供的一种代理机制,它是通过接口的方式进行代理,只能对实现了接口的类进行代理。
===
CGLIB动态代理是基于字节码技术实现的,可以对未实现接口的类进行代理。CGLIB动态代理通过生成目标类的子类,并将方法调用重定向到代理类的逻辑中来实现代理。
===
Spring Boot会根据目标类是否实现接口来选择使用JDK动态代理还是CGLIB动态代理。如果目标类实现了接口,则使用JDK动态代理;如果目标类没有实现接口,则使用CGLIB动态代理。
==
当然,我们也可以通过配置来修改默认的代理方式,可以通过设置@EnableAspectJAutoProxy注解的proxyTargetClass属性来强制使用CGLIB动态代理。
xxx
81.介绍一些 AspectJ
AspectJ是一个功能强大的面向切面编程(AOP)框架,它扩展了Java语言,并提供了丰富的AOP特性。下面是一些AspectJ的特点和功能:
切点表达式:AspectJ提供了灵活且功能强大的切点表达式语言,可以通过切点表达式选择具体的方法或代码段来进行横切关注点的织入。
切面声明:AspectJ通过特定的注解或XML配置文件,声明具体的切面和切面逻辑。切面可以定义切点和通知,以及其他的AOP相关配置。
丰富的通知类型:AspectJ支持多种通知类型,包括前置通知(@Before)、后置通知(@AfterReturning)、异常通知(@AfterThrowing)、后置通知(@After)和环绕通知(@Around),可以根据需要选择合适的通知类型来进行处理。
条件切面:AspectJ支持基于条件的切面,可以根据特定的条件来控制切面的织入。
强大的织入能力:AspectJ提供了基于编译时、类加载时和运行时的三种织入方式,可以根据不同需求选择合适的织入方式。此外,AspectJ还支持静态和动态织入。
对象增强和引入:AspectJ允许通过引入(Introduction)的方式向目标类动态添加新的方法和属性,以及实现接口。
横切关注点的模块化:使用AspectJ可以将横切关注点的逻辑抽取到独立的切面中,实现横切关注点的模块化和复用。
完整的工具支持:AspectJ提供了一系列的工具,如编译器、调试器、IDE插件等,帮助开发者更方便地使用和调试AspectJ的相关功能。
总之,AspectJ作为一个成熟的AOP框架,具有强大的特性和灵活的功能,可以帮助开发者更好地实现横切关注点的处理,并改善代码的结构和可维护性。
xxx
82.Spring中,能否使用AspectJ
是的,Spring框架对AspectJ进行了集成,可以与AspectJ结合使用。
在Spring中,可以使用基于注解或XML的方式声明AspectJ切面,并通过Spring AOP框架将切面逻辑织入到应用程序中。Spring AOP与AspectJ的集成提供了一种更简单、更轻量级的AOP解决方案,可以方便地在Spring应用程序中使用AOP来实现横切关注点的处理。
使用AspectJ与Spring AOP结合可以实现以下功能:
- 声明式事务管理:可以使用AspectJ的事务切面将事务管理逻辑织入到应用程序中,实现声明式的事务管理。
- 缓存管理:使用AspectJ的缓存切面将缓存逻辑织入到应用程序中,提升系统性能。
- 安全性控制:使用AspectJ的安全切面实现安全性控制,例如权限验证、日志记录等。
- 日志记录:使用AspectJ的日志切面将日志记录逻辑织入到应用程序中,方便追踪和调试。
- 性能监控:使用AspectJ的性能监控切面将性能监控逻辑织入到应用程序中,实现对系统性能的监控和分析。
总的来说,Spring框架可以与AspectJ无缝集成,提供了更加便捷和灵活的AOP解决方案,可以充分发挥AspectJ的功能并结合Spring的特性来实现切面编程。
xxx
83.AspectJ支持多种通知类型,如果不是AspetJ,Spring自身有没有通知类型
是的,除了AspectJ之外,Spring框架本身也提供了几种通知类型,用于实现AOP功能:
前置通知(Before advice):在目标方法执行前执行的通知。可以用于做一些准备工作或输入参数的校验等。
后置返回通知(After returning advice):在目标方法正常返回后执行的通知。可以获取目标方法的返回值,进行一些后续处理。
异常通知(After throwing advice):在目标方法抛出异常后执行的通知。可以用于捕获和处理异常,执行相应的逻辑。
后置通知(After advice):无论目标方法是否正常返回,都会在目标方法执行后执行的通知。可以用于释放资源或执行一些清理操作。
环绕通知(Around advice):在目标方法的前后都执行的通知。它可以完全控制目标方法的执行,包括是否执行、何时执行以及如何处理返回值和异常。
这些通知类型可以通过Spring AOP框架来声明和配置,与AspectJ不同,这些通知类型是通过Spring自身的代理机制来实现的。虽然相比AspectJ,Spring的通知类型功能相对较弱,但在大多数场景下已经足够使用。
==
前置通知:使用
@Before注解。后置返回通知:使用
@AfterReturning注解。异常通知:使用
@AfterThrowing注解。后置通知:使用
@After注解。环绕通知:使用
@Around注解。
xxx
84.Oracl ,mysql,db2 默认使用的事务隔离级别
针对不同的数据库管理系统,默认的事务隔离级别可能会有所不同。以下是针对Oracle、MySQL和DB2数据库的默认事务隔离级别:
Oracle数据库默认的事务隔离级别是“读已提交”(Read Committed)。这意味着一个(事务中的)查询只能看到已提交的数据。在此级别下,其他事务对数据进行更改时,其他事务只能等待事务完成或者使用一致性读取。
MySQL数据库的默认事务隔离级别是“可重复读”(Repeatable Read)。在这个级别下,一个事务不会看到其他事务插入、更新或删除的数据。这意味着在同一个事务中,多次读取同一数据将获得相同的结果。
(不正确)DB2数据库的默认事务隔离级别是“序列化”(Serializable)。在这个级别下,所有事务串行执行,不存在并发问题。这是最高的隔离级别,可以确保事务之间相互独立,但也可能导致性能下降。
需要注意的是,这些默认的事务隔离级别可以通过配置或者在代码中进行修改,以满足具体业务需求。
以上是 Chat GPT 的回答,有的部分并不正确
Isolation levels - IBM Documentation
根据IBM的文档,DB2 没有 串行 这种事物 隔离级别
======
Regardless of the isolation level, the database manager places exclusive locks on every row that is inserted, updated, or deleted. Thus, all isolation levels ensure that any row that is changed by an application process during a unit of work is not changed by any other application process until the unit of work is complete.
The database manager supports four isolation levels.
- Repeatable read (RR)
- Read stability (RS)
- Cursor stability (CS)
- Uncommitted read (UR)
=============
DB2数据库提供以下四个事务隔离级别:
Read Uncommitted(读未提交):在该隔离级别下,事务可以读取到其他未提交的事务所做的修改。这意味着读取到的数据可能存在脏读和不可重复读的问题。with UR
Cursor Stability(游标稳定性):在该隔离级别下,事务只能读取到其他事务已提交的数据。但是,在事务执行期间,其他事务可以修改已读取的数据,从而可能导致不可重复读的问题。
Read Stability(读稳定性):在该隔离级别下,事务只能读取到其他已提交的数据,并且在事务执行期间,其他事务无法修改已读取的数据。这样可以解决脏读和不可重复读的问题,但仍可能出现幻读(Phantom Read)的问题。
(不一定正确)Repeatable Read(可重复读):在该隔离级别下,事务在第一次读取数据后,其他事务无法修改已读取的数据,保证了读取的一致性。在该隔离级别下,脏读、不可重复读和幻读的问题都可以避免。
mysql分为下,两种数据库 Repeatable Read 的含义,是不一样的!!!!读未提交(Read Uncommitted):最低级别的隔离级别,事务未提交的修改可以被其他事务读取。可能会出现脏读、不可重复读和幻读的问题。
读已提交(Read Committed):事务只能读取已经提交的数据。解决了脏读的问题,但仍可能出现不可重复读和幻读的问题。
可重复读(Repeatable Read):默认的事务隔离级别,事务能够多次读取同一数据,并保持一致。解决了脏读和不可重复读的问题,但仍可能出现幻读的问题。
串行化(Serializable):最高级别的事务隔离级别,确保事务串行执行,避免了脏读、不可重复读和幻读的问题。但这也意味着并发性能会受到影响。
=============
The isolation level for static SQL statements is specified as an attribute of a package and applies to the application processes that use that package. The isolation level is specified during the program preparation process by setting the ISOLATION bind or precompile option. For dynamic SQL statements, the default isolation level is the isolation level that was specified for the package preparing the statement. Use the SET CURRENT ISOLATION statement to specify a different isolation level for dynamic SQL statements that are issued within a session. For more information, see “CURRENT ISOLATION special register”. For both static SQL statements and dynamic SQL statements, the isolation-clause in a select-statement overrides both the special register (if set) and the bind option value. For more information, see “Select-statement”.
xxx
db2 values CURRENT ISOLATION
默认隔离级别
TxnIsolation CLI/ODBC configuration keyword - IBM Documentation
Sets the default isolation level.
db2cli.ini keyword syntax:
TxnIsolation = ReadUncommitted | ReadCommitted | RepeatableRead | Serializable | NoCommit | 1 | 2 | 4 | 8 | 32Default setting:
2 or ReadCommitted (Cursor Stability)
Only applicable when:
the default isolation level is used. This keyword will have no effect if the application has specifically set the isolation level.
Equivalent statement attribute:
SQL_ATTR_TXN_ISOLATION
Usage notes:
Sets the isolation level to:
- 1 = SQL_TXN_READ_UNCOMMITTED - Read uncommitted (Uncommitted read)
- 2 = SQL_TXN_READ_COMMITTED (default) - Read committed (Cursor stability)
- 4 = SQL_TXN_REPEATABLE_READ - Repeatable read (Read stability)
- 8 = SQL_TXN_SERIALIZABLE - Serializable (Repeatable read)
- 32 = SQL_TXN_NOCOMMIT - (No commit, Db2 Universal Database for AS/400 only; this setting is similar to autocommit).
===
db2 select中 后面 with cs 是什么意思
在DB2的SELECT语句中,后面的WITH CS是指定使用“游标稳定性”(Cursor Stability)作为事务隔离级别。
游标稳定性是DB2中的一种事务隔离级别,它提供了更高的并发性能和读取一致性。当一个事务使用游标稳定性时,SELECT语句在执行期间会锁定被查询的行,但在读取后立即释放锁。这意味着其他事务可以同时读取这些行,但不能修改它们直到当前事务提交。
使用WITH CS选项可以在SELECT语句中显式指定游标稳定性作为事务隔离级别,例如:
SELECT col1, col2 FROM table1 WITH CS通过显式指定事务隔离级别,在某些情况下可以提高查询性能和并发性。但是需要根据应用程序的具体要求和环境来选择合适的隔离级别。
===
85.介绍一下Spring中的静态工厂方法
在Spring框架中,静态工厂方法是一种创建对象的方式,可以使用静态方法来替代直接调用构造函数。Spring通过静态工厂方法提供了一种灵活的机制来创建和配置对象。
在Spring中,使用静态工厂方法创建对象需要以下几个步骤:
创建一个类,并在该类中定义一个静态方法作为工厂方法,该方法将负责创建对象。
在Spring配置文件中使用标签配置静态工厂方法,并使用"factory-method"属性指定工厂方法的名称。
在配置文件中使用标签配置要创建的对象,并利用"factory-bean"属性指定使用的工厂类。
==

通过上述配置,Spring将使用MyObjectFactory类的createObject()方法来创建MyObject对象。
通过使用静态工厂方法,你可以在创建对象时执行一些额外的逻辑,例如使用缓存、调用其他服务或根据不同的条件返回不同的实例。这样可以使对象的创建过程更加灵活和可控
xxx
86.java 子类 重写 父类方法时, 那些可以不一样
在Java中,当子类重写父类的方法时,有几个方面是可以有所不同的:
方法的返回类型:子类可以选择与父类相同的返回类型,或是父类返回类型的子类型(即协变返回类型)。这是从Java 5开始引入的特性。举例来说,如果父类的方法返回类型是
Animal,子类可以重写该方法,将返回类型改为Dog,因为Dog是Animal的子类。方法的访问修饰符:子类可以选择与父类相同的访问修饰符,或是更宽松的修饰符,但不能使用更严格的修饰符。例如,如果父类的方法是
public访问修饰符,子类可以将其重写为public或protected,但不能将其改为private。方法的参数列表:子类重写的方法的参数列表必须与父类方法的参数列表完全一致。也就是说,参数的数量、类型和顺序都必须相同。
方法的异常:子类重写的方法可以选择与父类相同的异常类型,或是父类声明异常的子类型,或是不抛出异常(即子类方法没有声明任何异常)。但是,子类不能抛出父类方法未抛出的异常,也不能抛出比父类方法声明的更通用的异常。
需要注意的是,重写方法时不能改变父类方法的名字、参数列表或是方法的修饰符。此外,还需要遵守多态原则,即通过父类引用调用重写的方法时,实际执行的是子类的方法。
xxx
87.java 方法中的 形参 在方法结束后,会立刻释放空间吗
在Java中,方法的形参是在方法调用时创建的局部变量,它们存储了传递给方法的参数值。当方法执行完毕时,方法的栈帧会被弹出,形参在栈帧中的内存空间会被释放。这意味着方法结束后,形参占用的内存空间会被释放。
==
当方法结束后,形参的作用域也会终止,这意味着在方法的外部不能访问方法的形参。形参只在方法执行期间才是可见和可用的。
==
需要注意的是,如果方法调用期间将形参的值传递给其他变量或对象的引用,那么这些变量或对象的引用将会在方法完成后继续持有形参的值。即使方法结束后,形参本身的内存空间被释放,但是其他变量或对象引用仍然可以访问对应的值。
xxx
88.一个SQL语句,能否同时删除多个表中的数据
是的,你可以使用一个SQL语句来同时删除多个表中的数据。你可以使用多个DELETE语句并将它们包含在一个事务中,或者使用JOIN语句来连接多个表并删除对应的数据
方法一:使用多个DELETE语句和事务

xxx
89.JPA 事务交由 WebSphere容器处理, 数据库异常时,事务可以回滚,java异常时,数据不能回滚,原因是什么
在使用WebSphere容器管理JPA事务时,数据库异常可以正常回滚事务,但Java异常却无法回滚事务。原因是WebSphere容器的事务管理机制中,只有在遇到未捕获的未检查异常(Unchecked Exception)时才会回滚事务。
==
未检查异常是RuntimeException及其子类,这些异常属于运行时异常,在代码中可以选择捕获或不捕获。当容器检测到未捕获的运行时异常时,会主动触发回滚操作。
==
然而,对于已检查异常(Checked Exception)如IOException或SQLException,这些异常需要在代码中显式捕获并处理。容器不会自动回滚事务,因为这些异常通常表示一个已知的业务情况,需要开发者自行决定如何处理异常。
==
如果你想让Java异常也能触发事务回滚,可以将Java异常转换为运行时异常或者直接抛出运行时异常,这样就能够在遇到该异常时触发事务回滚操作。可以使用
throw new RuntimeException(e)或者创建自定义的运行时异常来达到这个目的。==
总结起来,WebSphere容器的事务管理机制中,只有未捕获的未检查异常(运行时异常)会触发事务回滚,而已检查异常需要在代码中显式处理。如果希望Java异常也能回滚事务,需要将其转换为未检查异常或者直接抛出未检查异常。
xxx
90.什么叫做 未检查异常 和 RuntimeException Exception 之间有什么关系
未检查异常(Unchecked Exception)是指在Java中不需要强制进行异常处理的异常类型。它们是RuntimeException及其子类,例如NullPointerException、ArrayIndexOutOfBoundsException等。
==
RuntimeException是一个运行时异常类,继承自Exception类。RuntimeException及其子类是未检查异常,它们的特点是在代码编写过程中,不需要显示地声明或捕获这些异常,即不需要使用try-catch块或throws语句进行处理。
==
与之相对的是已检查异常(Checked Exception),它不是RuntimeException及其子类。已检查异常在代码编写阶段需要进行显式地声明或捕获,否则编译器会报错,要求处理这些异常。例如IOException、SQLException等就是已检查异常。
==
已检查异常主要用于表示外部资源异常、网络异常、文件IO异常等情况,需要在代码中进行适当的异常处理。而未检查异常则主要用于表示程序逻辑的错误、数据异常等,它们往往意味着代码存在bug或者逻辑错误,可以通过修复代码来避免它们的发生。
==
RuntimeException及其子类作为未检查异常,其子类可以自由地在代码中抛出或不抛出,不需要进行强制处理。但是,对于已检查异常,编译器要求在代码中明确进行处理,以保证异常的安全处理和程序的健壮性。
==
总结起来,未检查异常是指运行时异常(RuntimeException及其子类),它们不需要进行强制处理。已检查异常需要在代码中明确进行处理,以保证异常的安全处理。
==
RuntimeException是一个运行时异常类,继承自Exception类,所以RuntimeException也是一个未检查异常。
xxx
91.WebSphere容器 管理 JPA事务 如果不是SQL异常,数据无法回滚
在WebSphere容器中,JPA事务的管理是由容器自动处理的。默认情况下,JPA事务会依赖于底层数据库的事务管理器来管理事务。因此,如果不是SQL异常导致的回滚,数据可能无法自动回滚。
要在JPA事务中处理非SQL异常并触发回滚,你可以使用
@Transactional注解的
rollbackFor属性来指定所需的异常类型。例如:
@Transactional(rollbackFor = Exception.class)
public void someMethod() {
// JPA事务管理的代码
}在上述例子中,如果
someMethod()方法中发生任何类型的异常,都会触发事务的回滚。另外,你也可以使用编程方式来控制事务回滚。在捕获非SQL异常时,你可以手动调用
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly()来设置事务回滚。例如:
@Autowired
private PlatformTransactionManager transactionManager;
public void someMethod() {
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
// JPA事务管理的代码
} catch (Exception e) {
transactionManager.rollback(status);
throw e;
}
transactionManager.commit(status);
}在上述例子中,如果捕获到非SQL异常,手动调用transactionManager.rollback(status)来触发事务回滚。
92.介绍一下 ibatis 和 mybatis
iBatis 和 MyBatis 都是用于数据持久化的Java持久层框架,它们的目标是简化数据库访问和数据映射。
iBatis(现已更名为 Apache MyBatis)是最早出现的一款数据持久化框架。它倡导使用简单的XML配置文件将Java对象和SQL语句进行映射。通过配置文件,可以轻松地定义数据表与Java对象之间的映射关系,同时也可以定义数据库操作语句,如增删改查等。 iBatis底层使用的是JDBC,它允许开发人员灵活地编写SQL语句。iBatis在大部分情况下可以显著地简化数据库访问操作。
MyBatis 是在iBatis的基础上进行了改进和发展的持久层框架。相对于iBatis,MyBatis在性能、灵活性和易用性方面有所提升。 MyBatis继承了iBatis的核心设计理念,使用XML文件进行映射配置,并且仍然允许开发人员编写自定义的SQL语句。此外,MyBatis还引入了注解方式进行映射配置,使得开发人员可以在Java类中直接使用注解进行映射。这大大简化了映射配置的过程。
iBatis和MyBatis都具有以下特点:
- 简化数据库访问:通过将Java对象和SQL语句进行映射,开发人员可以使用面向对象的方式进行数据库操作,提高了代码的可读性和可维护性。
- 灵活性:iBatis和MyBatis都允许开发人员编写自定义的SQL语句,满足复杂查询和灵活的数据操作需求。
- 易于集成:iBatis和MyBatis与Java应用程序的集成非常简单,可以方便地与其他框架(如Spring)进行整合。
总之,iBatis和MyBatis是两个功能强大的Java持久层框架,它们通过简化数据库操作、定义数据映射关系和提供灵活的SQL编写方式,使得开发人员可以更加便捷地进行数据持久化操作。
xxx
93.mybatis 和 JPA 是两种不同的数据库持久层 的框架吗
是的,MyBatis和JPA是两种不同的数据库持久层框架。
MyBatis是一种基于XML或注解配置的持久化框架,它主要通过映射文件或注解将Java对象映射到数据库表,然后使用SQL语句对数据库进行操作。MyBatis使用简单且灵活,因为开发人员可以直接编写SQL语句来执行数据库操作,可以自定义和优化SQL语句从而获得最佳的数据库性能。
JPA(Java Persistence API)是Java持久层标准,它是一种面向对象的持久化框架。JPA提供了一种面向对象的方式来操作数据库,通过注解或XML配置实现对象和数据库表之间的映射。JPA提供了一套标准的API和一些标准的查询语言(JPQL),并且可以与不同的持久化提供者(如Hibernate、EclipseLink等)进行集成。
两者的主要区别在于:
- 编程模式:MyBatis更加面向SQL,开发人员需要编写和优化SQL语句;而JPA更加面向对象,开发人员只需要关注对象的操作,而不需要直接编写SQL语句。
- 映射方式:MyBatis使用XML或注解来定义对象和数据库表之间的映射;而JPA使用注解或XML进行映射定义,并且提供了标准的映射规范。
- 查询语言:MyBatis使用原生的SQL语句进行查询;而JPA使用JPQL(Java Persistence Query Language)进行查询,它是一种面向对象的查询语言。
选择使用哪种框架取决于项目需求和开发人员的技术背景。MyBatis适合需要精细控制SQL语句和性能优化的场景,而JPA可以提供更多的ORM功能和更高层次的抽象。
xxx
94.javax.ws.rs.Path
・javax.ws.rs.Path 包名字中 ws 是 什么单词的缩写
在javax.ws.rs.Path包名中,ws是Web Service的缩写。 Web服务是一种在网络上提供服务的技术,通过使用标准的HTTP协议和基于XML或JSON的消息格式,使得应用程序可以通过网络相互通信和交换数据。javax.ws.rs.Path是JavaEE中定义的一种用于声明和映射RESTful服务端点URL路径的注解。================================
・pom.xml中引入方式1
javax.ws.rs
javax.ws.rs-api
2.1.1
这将为您的项目导入javax.ws.rs-api的jar包,其中包括javax.ws.rs.Path注解的定义和其他RESTful Web Service API的类和接口。请确保您的项目的构建配置文件中已包含此依赖项,并且您的构建工具(如Maven)能够正确解析并下载所需的jar包。================================
・pom.xml中引入方式2
如果您想使用Java EE Web相关的功能,您可以添加以下依赖项到您的pom.xml文件中
javax
javaee-web-api
8.0.1
provided
这将为您的项目导入Java EE Web API的jar包,其中包括javax.ws.rs.Path注解和其他相关类和接口的定义。请注意,上述依赖项的范围被设置为“provided”,这意味着您的应用服务器或容器将提供这些API的实现,因此无需在您的构建工具(如Maven)中包含这些类的实际jar包。确保您的应用服务器或容器支持Java EE Web API,并已正确配置以提供这些API的实现。
================================
xxx
代码
java处理,调用外系统的 WebAPI(https请求)时,相关知识整理_java调用https接口_sun0322的博客-CSDN博客
==
package com.sxz.webapi.test;
import javax.ws.rs.Consumes;
import javax.ws.rs.POST;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
import com.sxz.entity.TestRequest;
import com.sxz.entity.TestResponse;
@Path("/test")
public class UserRes {
//创建用户
@Path("/createUser")
@POST
@Consumes(MediaType.APPLICATION_JSON+";charset=utf-8")
@Produces(MediaType.APPLICATION_JSON+";charset=utf-8")
public TestResponse add(final TestRequest test) {
TestResponse response = new TestResponse();
String userName = test.getUserName();
String age = test.getUserAge();
response.setMessage(userName + "---" + age);
response.setStatus("1");
return response ;
}
}==
package com.sxz.entity;
import org.codehaus.jackson.annotate.JsonProperty;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class TestRequest {
// JackSon 默认是通过驼式命名
@JsonProperty(value = "userName")
private String userName;
@JsonProperty(value = "userAge")
private String userAge;
// {"user_name":"sss", "user_age":"22"}
}95.Struts 的 Action 如何能直接接受JSON类型的数据
在Struts中,Action可以直接接受JSON类型的数据。要实现这个功能,可以按照以下步骤进行操作:
首先,确保你的Struts配置文件中包含了对JSON插件的支持。在struts.xml文件中添加以下内容:
在Action类中添加一个属性,用于接收JSON数据。你可以使用JavaBean来表示JSON数据的结构。
public class MyAction extends ActionSupport { private MyDataBean jsonData; public void setJsonData(MyDataBean jsonData) { this.jsonData = jsonData; } public MyDataBean getJsonData() { return jsonData; } // ...其他Action方法... }在提交的请求中,将JSON数据作为一个参数传递给Action。你可以使用Ajax请求或其他方式提交JSON数据。
在struts.xml文件中,配置一个能够接受JSON数据的拦截器。这个拦截器将会帮助你将传递的JSON数据转换为Action中的属性。
true 现在,当请求发出时,Struts将自动将JSON数据转换为Action中的属性对象。你可以在Action中使用这些数据进行处理。
===
以上是Struts接收JSON数据的基本步骤。你可以根据自己的需求进行具体的调整和扩展。
xxx
96.Struts中的package
在Struts框架中,package是一种组织和配置Action的方式。每个Action类都必须属于一个package。一个package可以包含多个Action,并且可以具有自己的配置信息。
在struts.xml配置文件中,你可以定义多个package节点来组织和配置你的Action。每个package节点包含一个或多个action节点,用于定义和配置你的Action类。
下面是一个示例的package节点的配置:
/success.jsp
/error.jsp
/success.jsp
/error.jsp
在这个示例中,我们定义了一个名为"default"的package节点。它继承自"struts-default",这是一个Struts默认的package。我们在"default" package中定义了两个action节点,分别是"login"和"register"。
每个action节点有以下属性:
- name:指定Action的名称,用于在请求URL中识别Action。
- class:指定Action类的完整类名。
- result:定义Action执行后的结果。可以配置多个result节点,每个节点都有一个name属性,用于标识结果的名称。result节点的内容可以是一个JSP视图页面,也可以是一个重定向URL。
通过这种方式,在package中配置多个action节点,可以管理和组织你的不同Action类,并且为每个Action类提供不同的配置信息。这使得你可以在一个地方集中管理和维护所有的Action配置。
xxx
97.Struts 配置的 Action ,代码里面,如何接收JSON数据
在Struts中,要接收JSON数据,可以使用JSONObject类来解析JSON字符串,并将其转换为Java对象。
首先,需要添加相关的依赖,例如json-lib或gson。这些库可以帮助你解析和处理JSON数据。
然后,在你的Action类中,你可以定义一个setter方法来接收JSON数据。假设你的JSON数据格式如下:
{ "name": "John", "age": 25, "email": "[email protected]" }
你可以在Action类中定义如下的setter方法:
public void setData(String data) {
JSONObject json = JSONObject.fromObject(data);
String name = json.getString("name");
int age = json.getInt("age");
String email = json.getString("email");
// 在这里可以对接收到的数据进行处理或存储
// ...
}在这个例子中,setData()方法接收一个名为"data"的参数,该参数是一个JSON字符串。首先,我们使用JSONObject.fromObject(data)将字符串转换为JSONObject对象。然后,我们可以使用getString()和getInt()等方法从JSONObject对象中获取数据。
你可以在setData()方法中按照你的需求进一步处理数据,例如存储到数据库或执行业务逻辑。
当客户端发送一个包含JSON数据的请求时,Struts框架会将请求参数映射到Action类的setter方法上,并将JSON数据作为字符串传递给这个方法。你只需在Action类中定义相应的setter方法,即可接收和处理JSON数据。
xxx
98.Spring配置文件中【context:annotation-config】和【context:component-scan】
xxx
・context:annotation-config 标签只会启用对注解的支持
・context:component-scan 标签指定的 base-package 属性为 "com.example",表示 Spring 容器会扫描该包及其子包中的类,并加载并注册被 @Component 注解标注的类。
==
99.为什么 websphere 要在 war的基础上,再套一层ear
WebSphere是一个Java EE应用服务器,用于部署和运行企业级Java应用程序。它支持将应用程序打包为WAR(Web Archive)文件或EAR(Enterprise Archive)文件进行部署。
WAR文件是一种用于打包和部署用于Web应用程序的文件格式。它包含了Web应用程序的所有资源,如HTML、CSS、JavaScript、JSP和Servlet等。
EAR文件是一种用于打包和部署用于企业级应用程序的文件格式。它可以包含多个WAR文件以及其他的企业级Java组件,如EJB(Enterprise JavaBean)、消息队列和持久化单元等。
将应用程序打包为WAR文件可以方便地部署和管理Web应用程序,而将应用程序打包为EAR文件可以支持更复杂的企业级应用程序的部署和管理。EAR文件可以提供诸如分布式事务管理、资源共享和集中式配置管理等功能,以满足企业级应用程序对于可伸缩性、高可用性和安全性等方面的要求。
因此,在WebSphere中使用EAR文件可以更好地满足企业级Java应用程序的需求,提供更强大的功能和更灵活的部署和管理方式。
===
一些 和 WebSphere关联的配置,是配置在外层(Ear工程下面)的web.xml中的
JPA、EJB、事物管理、WebSphere ---相关内容整理_ejb websphere_sun0322的博客-CSDN博客
xxx
java.net.URL
xxx
javax.sql.DataSource
==
以下是一个使用Maven生成EAR(Enterprise ARchive)项目的pom.xml文件的示例:
4.0.0
com.example
my-ear-project
1.0.0
ear
org.apache.maven.plugins
maven-ear-plugin
3.2.0
lib
100.XXX
xxx
101.XXX
xxx
102.XXX
xxx
103.XXX
xxx
===
■SpringBoot 与 Spring
●1.@SpringBootApplication注解背后
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan(excludeFilters = { @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
@Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
public @interface SpringBootApplication {
---
但其实,最主要的是以下这三个
@Configuration
@EnableAutoConfiguration
@ComponentScan1.ComponentScan

常用的几个属性【basePackages】、【includeFilters】,【excludeFilters】
2.@EnableAutoConfiguration

・@EnableAutoConfiguration 中,有 【exclude】、【excludeName】这两个属性;
当不想某个特定配置类生效时使用。
====
●2. Spring的@import
借助@import,将符合自动配置条件的bean,加载到IOC容器中。

代码1:SpringBoot中的使用(@EnableAutoConfiguration中,就使用了这个标注)
// SpringBoot中的 @EnableAutoConfiguration中,就使用了这个标注
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@AutoConfigurationPackage
@Import(AutoConfigurationImportSelector.class)
public @interface EnableAutoConfiguration {代码1的补充说明:AutoConfigurationImportSelector.class
(@EnableAutoConfiguration中,@Import(AutoConfigurationImportSelector.class))
该组件内部调用SpringFactoriesLoader
加载autoconfigure.jar包中的spring.factories文件,
根据文件定义列表载入各个配置类代码2: AspecJ中的使用
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Import(AspectJAutoProxyRegistrar.class)
public @interface EnableAspectJAutoProxy {●3.组件的注册方式
@Bean
@ConmponetScan
@import
@FactoryBean===
1.Spring的核心:都是一种设计模式(工厂,代理)
IoC的思想基于工厂模式 // FactoryBean: 以Bean结尾,表示它是个Bean,它并不是简单的Bean,而是一个能生产对象或者修饰对象的工厂Bean
AOP的思想则是基于代理模式。
AspectJ是一个面向切面的框架,是目前最好用,最方便的AOP框架
2.BeanFactory 是 Spring的 根容器
BeanFactory:它是Spring IoC容器的一种形式,提供完整的IoC服务支持,也可以看出主语是Factory,即是一个管理Bean的工厂
---
●4.使用SpringBoot,启动SpringBatch
使用SpringBoot启动SpringBatch_sun0322的博客-CSDN博客
----
●5.SpringBoot配置多个数据源
SpringBoot + MyBatis 配置多个数据源_sun0322的博客-CSDN博客
====
■Spring框架源码分析
1.SpringBoot的jar传递参数时,使用两个「--」横线来标记参数
SpringBoot的jar传递参数时,使用两个「--」横线来标记参数_sun0322的博客-CSDN博客_springboot 两个参数
===
2.SpringBoot 数据源自动配置
SpringBoot 数据源自动配置_sun0322的博客-CSDN博客_springboot 自动配置数据源
===
3.使用SpringBoot,启动SpringBatch (经过的各个类以及方法) (私密)
https://blog.csdn.net/sxzlc/article/details/124323644
===
4.配置Log时,【logging.file.name】,【logging.file】
Springboot,log文件配置时,logging.file.name与logging.file_sun0322的博客-CSDN博客
===
■Java中的标注
1.@PostConstruct // javax.annotation.PostConstruct
Core Technologies (spring.io)
2.XX
xxx
3.XXX
xxxx
■Java工具应用
1.打包Jar
POM 打包 Jar,指定Main方法的类,指定使用的JDK_sun0322的博客-CSDN博客_pom打包指定main
2.使用Log4J (私密)
https://blog.csdn.net/sxzlc/article/details/124621551
3.使用VBA调用Jar
下面文章的 No.14
VBA中 各种数据类型的使用(自定义数据类型Type,数组,数据字典)、读写文件_sun0322的博客-CSDN博客_vba数据类型
===
■更多学习笔记(大篇幅 整理的笔记 )
Java学习
Java学习(更新中)_sun0322的博客-CSDN博客_javajava学习
Servlet,Spring,Spring Boot,Sprint Batch,ThymeLeaf 学习
Servlet,Spring,Spring Boot,Sprint Batch,ThymeLeaf 学习_sun0322的博客-CSDN博客
Spring Batch学习
https://blog.csdn.net/sxzlc/article/details/124183805
Oracle学习
数据库学习(Oracle)_sun0322的博客-CSDN博客_oracle数据库学习
===