数据分析SQL常考题型、大厂例题及面试要点
文章目录
-
-
- 1. 数据分析岗位技能要求
-
- 1.1 哪一个工具是数据分析师的核心工具
- 1.2 对于数据分析师来说,是否需要建模能力
- 1.3 数据分析岗位对业务有什么要求
- 1.4 数据的特点
- 1.5 优秀数据分析师的特点
- 1.6 数据分析工作的四大步骤
-
- 1.6.1 数据抓取
- 1.6.2 数据清洗
- 1.6.3 数据分析
- 1.6.4 业务决策
- 1.6.5 数据可视化
- 1.6.6 数据分析报告
- 1.7 数据分析技能在互联网产品中的应用
- 2.数据分析师必须掌握的SQL核心技能
-
- 2.1 SQL万能查询框架
- 2.2 你最应该掌握的SQL语句和知识
-
- 2.2.1 最基本(选数据)
-
- 2.2.2 最常用(单个或组合使用)
- 2.2.3 基础进阶(开窗函数)
- 3.大厂数据分析SQL面试精讲
-
- 3.1 面试常考基本题型
- 3.2 大厂面试原题讲解
- 3.3 SQL面试注意事项
- 4. 数据分析求职指导
-
1. 数据分析岗位技能要求
1.1 哪一个工具是数据分析师的核心工具
SQL是当之无愧的第一工具,排名第二的是BI,excel也相当重要,python所占比例不大。
1.2 对于数据分析师来说,是否需要建模能力
随着经验要求上升,岗位对数据分析建模能力的要求越来越广泛,学习算法和建模是数据分析进阶的必备路径。建模指机器学习算法和深度学习算法。
1.3 数据分析岗位对业务有什么要求

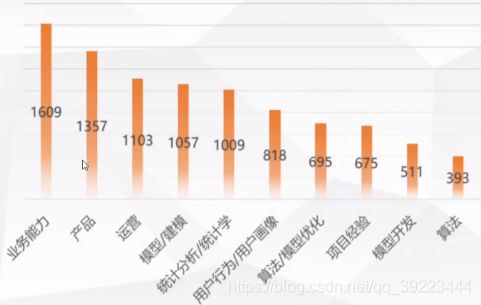
业务能力排名第一,产品、运营和项目经验等也都和业务能力挂钩。除了业务外,统计分析、建模也十分重要。
1.4 数据的特点
数据可以做什么?
天气预报:利用物理数据对未来天气进行预测
商业应用:把数据转换成帮助企业发展的生产力
数据分析在不同行业可以做什么?
电商类
电商网站会采集大量的用户行为数据,如浏览、购买等,通过这些数据,数据分析师了解不同用户的喜好、行为方式从而帮助增加产品销量
社交类
利用社交网络数据,可以更好的进行精准营销,通过对站子、推文、博客和其他社交数据进行分析,可以有效改善用户服务和体验。
医疗类
卫生保健机构可以针对电子医疗数据进行记录,数据分析师可以基于这些数据,帮助医疗机构改善卫生服务,并发现潜在隐患。
金融类
在金融行业,通过对用户的日常交易数据进行分析,险可以帮助信贷机构评判用户的信用等级,确定信贫额度
1.5 优秀数据分析师的特点
什么是数据?
数据是科学实验、检验、统计、观测等所获得的和用于科学研究、技术设计、查证、决策等的数值。
数据的变异性(体温)
数据的规律性(大数定律) → \rightarrow → 数据分析 → \rightarrow → 数据驱动决策
数据的客观性
1.业务理解
能跑数,不叫数据分析,和业务结合并产生价值才是数据分析。
2.工具使用
掌握并熟练应用基本的数据分析工具、分析模型和分析方法。
3.沟通表达
具备高效听说写的能力和用数据讲故事的能力
对业务的洞察力决定了一个数据分析师的职业上限。
对行业和产品有热情、热爱学习
从事数据分析工作,首先必须要对进入的行业和产品感兴趣,有好奇心,愿意学习―切未知的知识
关注数据分析对业务产生的价值
能够把业务和数据结合起来,尝试用数据量化业务状态和结果,能够用数据解释潜藏的未被发现的业务逻辑
多问、多思考
当分析需求来的时候,要问下为什么要做这个分析,想解决什么问题。
数据分析师总是需要通过说服产品和工程方面来改变产品,产生影响力
能够跨部门高效沟通
与需求方沟通可以快速了解业务价值,分析背景;与开发部门沟通可以了解业务实现、数据来源;推动数据分析落地业务方需要跨部门沟通
良好的数据可视化能力和撰写分析报告的能力
能够把分析结果变得直观、简单、易理解;分析报告全面、有逻辑、经得住推敲;分析结论可靠、可验证
技术水平决定了数据分析师的下限
熟练使用各类分析模型和分析方法
对使用的模型能清楚其优劣势;对没用过的方法能有所了解,在遇到已有方法解决不了的问题时能够联想到尝试其他方法是否可以解决
一定的编程语言技能
SQL/Python/R; SQL是基础,Python或R可以提升长期工作效率
对数据有很高的敏感度,最好有一定的统计学基础
能够及时发现数据展现的问题,指出深挖的方向;对数据的理解有很强的逻辑性和科学性
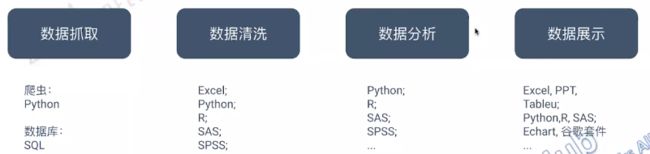
1.6 数据分析工作的四大步骤
数据抓取 → \rightarrow → 数据清洗 → \rightarrow → 数据分析 → \rightarrow → 业务决策
1.6.1 数据抓取
数据抓取:确定要抓取什么样的数据


还有日志什么的,也可以归入埋点
如何规划数据埋点

曝光时间:页面有没有加载到,加载了几次。
数据埋点-京东案例


1.6.2 数据清洗



1.6.3 数据分析
数据分析是指通过某种方法和技巧,对准备好的数据进行探索、分析,从中发现因果关系、内部联系和业务规律等分析结果,为特定的研究或商业目的提供参考。
描述性分析(发生了什么?)
描述某项事物的特性。需要准确、完善甚至是实时的数据。
描述性分析是通过计算数据的集中性特征(平均值和中位数)和波动性特征(标准差值)以了解数据的基本情况。因此在研究中经常是首先进行描述性分析,再次基础之上再进行深入的分析。
描述性分析还可用于查看数据是否有异常情况(最小值或最大值查看),比如数据中出现-2,-3等异常情况。
描述性分析也可以通过峰度和偏度用于判断数据正态性情况。
诊断性分析(为什么会发生?)
在对描述性数据进行评估时,诊断分析工具将使分析师能够深入到细分的数据,从而隔离出问题的根本原因。
诊断性分析是基于描述性分析之上的。诊断分析的目标是了解事情发生的原因。通过诊断分析,可以深入挖掘问题根源,识别依赖关系,找出影响因子。各种分析方法,可以知道问题是怎么发生的,这个过程依赖于我们对业务的了解程度,另外也要多和业务人员进行头脑风暴,只要是可能相关的,都纳入考虑,也可以基于现有特征构造新特征,至于是否相关可在后面的分析中进行验证。
思考题:为什么6月份京东电商平台的订单量激增?从哪些角度去分析?需要哪些数据?
订单量激增,618活动,是不是带来很多流量,转化率怎么样,是不是有直播,爆款产品等等,用户购买率激增。
预测性分析(将会发生什么?)
对数据特征和变量的关系进行描述,基于过去的数据对未来进行预测
相比较于描述性分析与诊断性分析的对于过去数据的分析,预测性分析可以用来说明未来可能发生的事情。它使用描述性和诊断性分析的结果来检测趋势或者关联性,并预测未来动态。
尽管预测性分析可以为未来的趋势提供指导,但是预测也只是一种估计,数据的质量和业务状态的稳定性决定着预测的准确性,所以这类分析往往需要持续不断的优化
规范性分析(需要做什么?)
规范模型利用对发生的事情的理解,为什么发生了这种情况以及各种~可能发生的"分析,以帮助用户确定采取的最佳行动方案。
规范性分析(指导性分析)的目标是告诉我们应该采取什么样的措施来获得最优的结果。它通过利用对已发生事件的理解和事件发生的原因,以及各种可能发生的情况分析来帮助确定可采取的最佳行动方案。指导性分析通常是各类分析的组合。
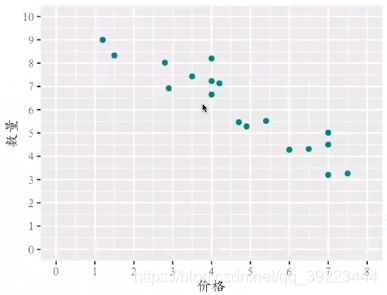
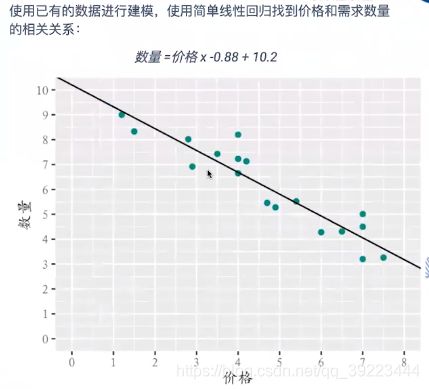
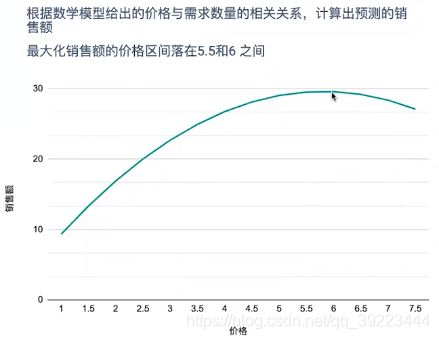
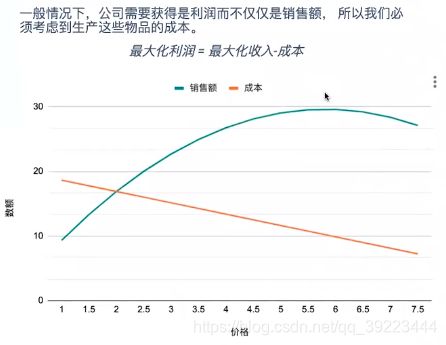
比如采用数学模型确定最优的商品定价以实现利润最大化、应该怎样实现网页的最优广告位布局等

![]()
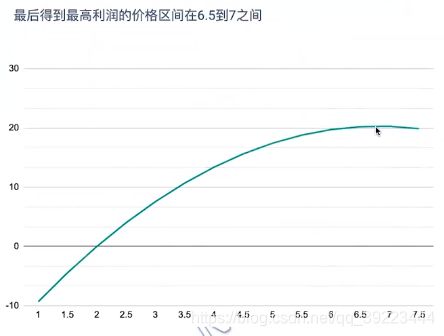
1.6.4 业务决策
数据分析师总是需要通过说服产品和工程方面来改变产品,产生影响力
清晰的可视化和完整的分析报告
能够把分析结果变得直观、简单、易理解;分析报告全面、有逻辑、经得住推敲;分析结论可靠、可验证
推动产品按数据分析的结论进行修正、落地
数据分析师总是需要通过说服产品和工程方面来改变产品,产生影响力。
1.6.5 数据可视化
数据可视化的基本准则:
1.保证图表的可信性
2.图表能够高效传达信息
3.图表符合美学原则
4.图表参考:经济学人
数据可视化:不准确的坐标轴
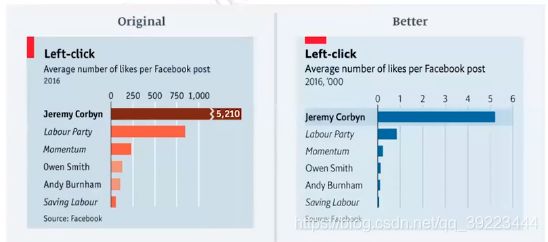
- 折断的坐标轴低估了Jeremy Corbyn的点赞数量,还夸大了其他人的点赞数量
- 另一个奇怪的是颜色的选择。对于不太熟悉英国政治的人来说没有什么意义

- 在原始图表中,两个坐标轴的跨度均为三个单位(左边是21到18;右边是45到42)。按百分比计算,左边的比例下降了14%而右边则下降了7%。
数据可视化:错误的图表类型

- 数据以折线图绘制,似乎受访者对公投结果的看法相当不稳定,每周都会增加或减少几个百分点。
- 坐标轴不是从0开始的,应该在坐标轴最小值下方有所留白
数据可视化:包含太多细节

- 颜色太多,而且其中一些很难被区分。另外,因为对应的值太小了,压根没有办法得到任何图表信息。
- 这些细节并没有起到关键作用
数据可视化:颜色的错误使用
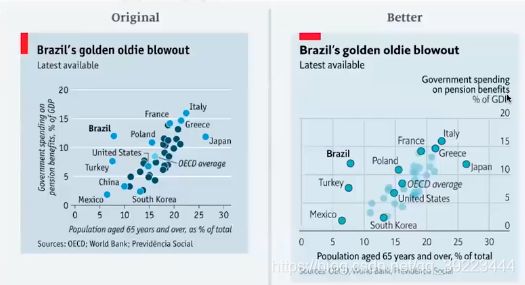
- 不同颜色通常意味着不同分类。第一张图里的不同的蓝色看起来是两种不同类型的国家。但其实他们的区别只是一个有打上国家标签,一个没有而已。
1.6.6 数据分析报告
撰写数据分析报告的一些基本要求
分析报告一般可以分为专题分析报告、综合分析报告和日常数据通报
分析报告的基本要求:
1.介绍分析背景和分析目的
2.说明数据来源、数据的时间区间和统计口径,如日活的定义
3.分析逻辑清晰,可采用金字塔结构、总分总结构等
4.既要给出结论,也要给出解决方案
撰写数据分析报告的一般框架
- 分析背景:简述分析或者报告的背景,为什么做,目的是什么,明确分析报告要回答的问题
- 名词解释:关键性指标定义是什么,为什么这么定义
- 数据获取方法:数据获取的时间区间,怎么获取到的数据,会有哪些问题
- 数据概览:重要指标的趋势,变化情况(数据通报)
- 数据分析:拆分问题,使用数据支撑结论
- 结论汇总:汇总之前数据分析的主要结论,作为概览给出建议:根据数据分析的结论,给出改进建议
1.7 数据分析技能在互联网产品中的应用
精准营销 :网站推荐
精细化运营:拉新、留存、推送
产品设计:优化步骤提高转化率
2.数据分析师必须掌握的SQL核心技能
2.1 SQL万能查询框架
- SQL操作的一般框架
select <select_list>
from <table_list>
[where <condition>]
[group by <group_by_list>]
[having <having_condition>]
[order by <order_by_list> ASC|DESC]
[limit <limit_number>]
select-查询
from-从
where-哪里(满足XX条件的)
group by-依据XX分组
order by-依据XX排序
limit-限制N条
总结:从XX表中查询满足XX条件的XX列,结果依据XX分组,依据XX排序,限制返回N条。
- SQL语句的书写顺序vs执行顺序

- 首先会定位到from关键词确认语句将要对哪些表进行操作
- 然后定位到where关键词看看限定了什么样的查询条件,
- 之后定位到group by关键词看是否有分组统计需求,
- 前面执行结束之后执行having语句,对查询结果进行条件筛选,
- 之后确定最终要返回哪些字段呈现给用户(也就是select关键词后面的列名)
- 如果有distinct关键词就执行去重操作,
- 最后根据order by关键词后面字段对返回的结果进行升序或者降序排列,
- 如果有返回行数限制的要求,就按照limit关键词后面的数字返回相应的行数
2.2 你最应该掌握的SQL语句和知识
2.2.1 最基本(选数据)
-
怎么把数据从表中选择出来–select
-
想要的数据在多张表中,想取多个字段,该怎么办?–表连接
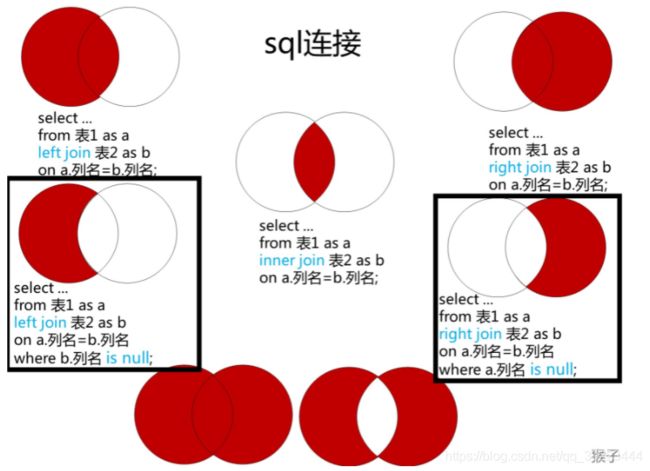
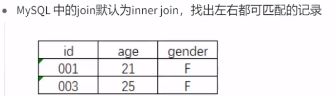
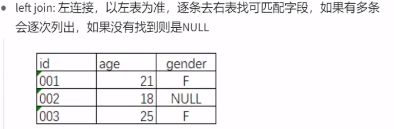

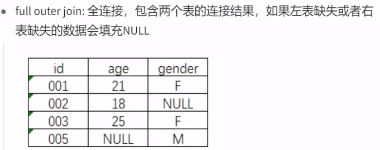
注意:
-
MySQL中不支持全连接
-
每种join都有on,on的是左表和右表中都有的字段。join之前要确保关联键是否去重,是不是刻意保留非去重结果。
-
两张表数据的字段一样,想合并起来,怎么办?–union
union和union all均基于列合并多张表的数据,所合并的列格式必须完全一致。union的过程中会去重并降低效率,union all直接追加数据。
-
2.2.2 最常用(单个或组合使用)
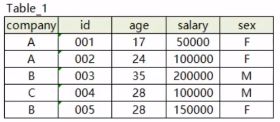
-
去重 distinct
如果有千万用户数据。想知道有多少不重复的用户数? -
罗列不同的id
select distinct id from Table_1 -
统计不同的ld数
select count(distinct id) from Table_1 -
优化版本的count distinct
- 使用count distinct进行去重统计会将reducer数量强制限定为1
- 影响查询效率
- 可以使用子查询进行优化
select count(*) from (select distinct id from table_1) tb
-
聚合 max/min/sum/count+group by
-
想分性别进行统计,看看男女各多少?
- 统计不同性别(F、M)中,不同的id个数
select count(distinct id) from table_1 group by hender; - 统计最大/最小/平均年龄
select max(age),min(age),avg(age) from table_1
- 统计不同性别(F、M)中,不同的id个数
-
筛选 having、where
-
只想查看A公司的男女人数数据?
- 统计A公司的男女人数
select count(distinct id) from table_1 where company = 'A' group by gender; - 统计各公司的男性平均年龄,并且仅保留平均年龄30岁以上的公司
select company,avg(age) from table_1 where gender = "M" group by company having avg(age)>30
- 统计A公司的男女人数
-
排序 order by
- 希望查询结果从高到低/从低到高排序?
- 按年龄全局倒序排序取最年长的10个
select id,age from table_1 order by age DESC limit 10;
- 按年龄全局倒序排序取最年长的10个
- 希望查询结果从高到低/从低到高排序?
-
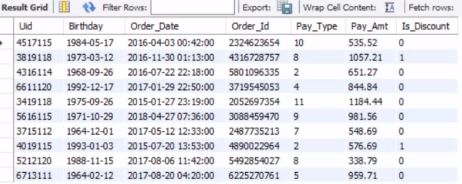
条件 case when
- 将数值型的变量转换为类型的变量
select id case when CAST(salary as float)<50000 then "5万" when CAST(salary as float)>=5000 and CAST(salary as float)<100000 then "5-10万" when CAST(salary as float)>=100000 and CAST(salary as float)<200000 then "10-20万" when CAST(salary as float)>=200000 then "20万以上" else NULL end from table_1;
cast是将salary转化为浮点数,防止是字符串不能计算
再举一个例子:



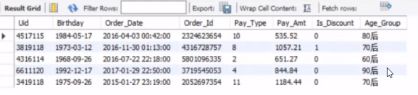
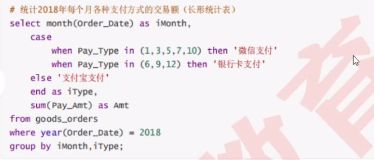
- group by后面为什么可以使用别名?
- 前面说SQL语句的执行顺序是group by在select之前
- 为什么这里可以在group by之后使用select里面设置的别名呢?
- 原因在于MySQL对查询做了加强处理,所以允许在group by中使用别名
- 但是在RDBMS中(比如Oracle)别名的使用都是严格遵照SQL执行顺序的——group by后面不能使用别名。
2.2.3 基础进阶(开窗函数)
-
窗口函数是什么
- 窗口这个概念,可以简单理解为记录集合,或者分区
- 窗口函数也就是在满足某种条件的记录集合上执行的特殊函数
- 对于每条记录都要在此窗口内执行函数
- 普通聚合函数vS窗口函数
- 本质上说,窗口函数还是聚合运算。只不过它更具灵活性。它对数据的每一行,都使用与该行相关的行进行计算并返回计算结果
- 二者区别:聚合函数是将多条记录聚合为一条;而窗口函数是每条记录都会执行,有几条记录执行完还是几条。
- 聚合函数也可以用于窗口函数
-
窗口函数语法
- 开窗函数名 ([]) over ([partition by ] [order by [desc]] [])
- over是关键字,用来指定函数执行的窗口范围
- partition子句:窗口按照那些字段进行分组,窗口函数在不同的分组上分别执行
- order by子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号。可以和partition子句配合使用,也可以单独使用。
- 开窗函数名 ([]) over ([partition by ] [order by [desc]] [])
-
MySQL开窗函数的种类
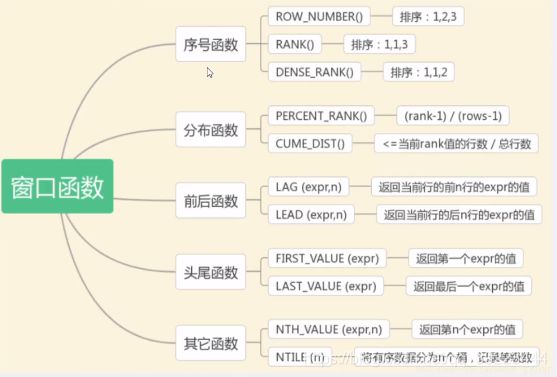
最常用的是前三个。
3.大厂数据分析SQL面试精讲
3.1 面试常考基本题型
-
题型1【查询不在表里的数据】
这里有两张表,一张是学生表Table_1,一张是已经选课了的学生的信息表Table_2。现在要求找出还没有选课的同学。
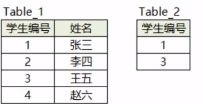
解题思路:- 首先认真读题:还没有选课的学生有哪些?
所有学生信息在Table_1中·已经选课的学生在Table_2中;那么没有选课的学生就是在Table_1中;但是不是在Table_2中 - 判断是否需要多表连接
数据设计两张表,需要多表连接 - 使用哪种连接方式
在A中不在B中,选择左连接 - 确定连接主键
Table_1和Table_2共有的字段为学生编号,确定学生编号字段为主键
完整代码:

同类题型——LeetCode数据库【183.从不订购的客户】 - 首先认真读题:还没有选课的学生有哪些?
-
题型2【查找第N高的数据】
有一张“成绩表"Table_1,包含学生编号,选修课程的编号和成绩信息。现在需要找出某课程成绩第二高的学生成绩。这里以课程编号为“01"的同学为例。如果不存在第二高成绩的学生,那么查询应返回null。
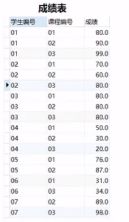
解题思路:- 先找出所有选修"01"课的学生成绩
select * from table_1 where 课程编号=‘01’; - 查找"01"课程成绩的第二名
考虑到成绩可能一样,所以需要使用distinct成绩进行去重。
select distinct 成绩 from table_1 where 课程编号=‘01’ order by 课程编号,成绩 desc limit 1 offset 1;- 考虑第二高的成绩不存在的情况
如果不存在第二高成绩的学生,那么查询应返回null。
使用ifnull函数可以满足要求
–select ifnull(第二步的结果,null) as '01课第二名成绩';
完整代码
# 利用ORDER BY排序,再利用Limit限制offset偏移,排除只有1个值情况结合IFNULL SELECT IFNULL( (SELECT DISTINCT 成绩 FROM Table_1 ORDER BY 成绩 DESC LIMIT 1 OFFSET 1), NULL)AS "01课程第二高的成绩"; - 先找出所有选修"01"课的学生成绩
知识点
- limit 2,1和limit 2 offset 1的区别是什么?
limit 2,1为跳过2条取出1条数据,limit后面是从第2条开始读,读取1条信息,即读取第3条数据
limit 2 offset 1从第1条(不包括)数据开始取出2条数据,limit后面跟的是2条数据,offset后面是从第1条开始读取,即读取第2,3条。 - 判断是否为null–ifnull函数
-
题型3【分组排序问题】
下图是成绩表Table_1中的内容,记录了每个学生学生编号,课程编号和成绩。现在需要根据成绩来排名,如果两个分数相同,那么排名要是并列的。
比如题目中的成绩从大到小排序应该是80,80,76,70,50,31。
分数相同排名并列,那么6位同学的排序应该是1,1,3,4,5,6。
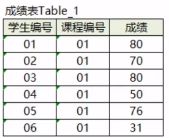
解题思路:- 遇到分组排序问题,可以考虑使用开窗函数
- 根据题干的要求两个分数相同,那么排名要是并列的。
- 选择合适的开窗函数―—rank()函数
完整代码
select *, rank() over (order by 成绩 desc) as "排名" from table_1;知识点
rank, dense_rank, row_number三种开窗函数的区别- ROW_NUMBER():顺序排序——1、2、3
- RANK():并列排序,跳过重复序号―—1、1、3
- DENSE_RANK():并列排序,不跳过重复序号―—1、1、2
同类题型——LeetCode数据库【178.分数排名】
-
题型4【连续出现N类问题】
下面是某班级学生的某课程的成绩表(表名Sscore,列名:学号、成绩),使月SQL查找所有至少连续出现3次的成绩。
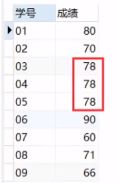
解题思路:- 如何理解连续出现3次?
首先有三位同学的学号依次递增
其次,这三位的同学的成绩相等 - 如何解决?
使用三张相同的表自连接可以将判断三列相等的问题转化为同一行3个值相等的问题

参考代码1
select distinct a.成绩 as 连续出现3次的成绩 from sscore as a, Sscore as b, Sscore as c where a.学号=b.学号-1 and b.学号= c.学号-1 and a.或绩=b.成绩and b.成绩= c.成绩;参考代码2
SELECT 成绩, max(rk) AS 成绩_cnt FROM (SELECT 成绩, row_number() over(PARTITION BY成绩) AS rk --先计算出排名 FROM Sscore) t GROUP BY t.成绩--根据最大的排名来知道“成绩"的出现次数 HAVING 成绩_cnt >= 3;--用排名进行筛选知识点
同类题型——LeetCode数据库【180.连续出现的数字】
- 如何理解连续出现3次?
3.2 大厂面试原题讲解
-
蚂蚁金服面试真题
sql中过滤条件放在on和where中的区别
我们知道on和where是筛选条件,那么具体区别是什么?我们分开看下。


inner join:结果没有区别- 前者是先求笛卡尔积然后按照on后面的条件进行过滤

- 后者是先用on后面的条件过滤,再用where的条件过滤。
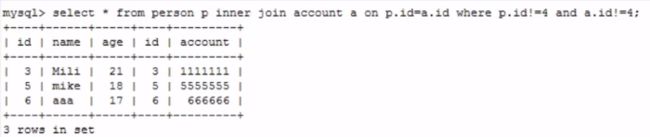
- 但是两者的结果是一样的
left join、right join:使用left join(right join)时on后面的条件只对右表(左表)有效。
-
join过程可以这样理解: where的执行顺序在join之后,on执行在join之中。
-
由于join要求索引列保留,所以对于left join来说on对右表生效(可以看到右表的id=4的记录没了)
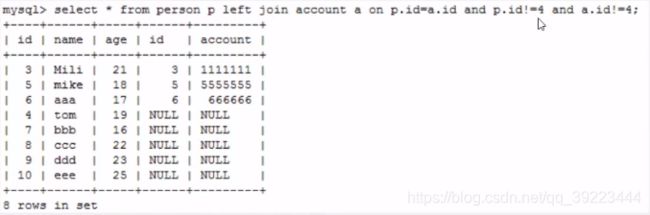
只把右表里面的4去掉了 -
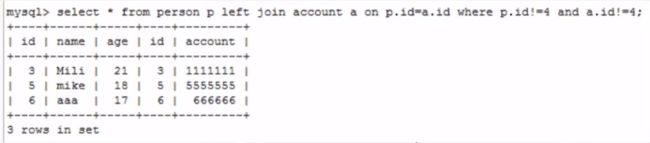
但是在左连接之后使用where,就能明显看到起到了过滤作用
- 前者是先求笛卡尔积然后按照on后面的条件进行过滤
-
滴滴面试题
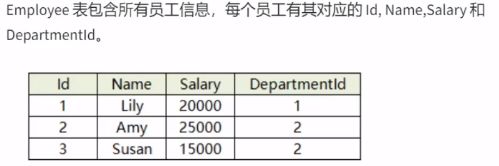
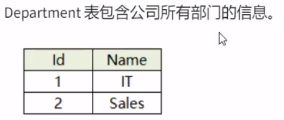
编写一个sQL查询,找出每个部门工资第二高的员工。
这是查找第N高的题型SELECT*FROM Employee WHERE ld = (SELECT ld FROM Employee WHERE Departmentld = a.Departmentld ORDER BY Employee.Salary desc LIMIT 1 OFFSET 1);这也是分组排序的问题,可以考虑直接上开窗函数
select Departmentid,Name,Salary,rn from(select *,row_number() over (PARTITION by Departmentid ORDER BY Salary desc) as rn from Employee) as a WHERE rn=2;select d.name department, ifnull( (select salary from employee e left join department d on e.departmentid=d.id group by e.departmentid ORDER BY e.salary DESC limit 1,1 ),null) as '第二高工资' -
支付宝面试真题

select b.user_namefrom (select I user_name, ntile(5)over(order by sum(pay_amount) desc) as levelfrom user_sales_table group by user_name ) b where b.level= 1; -
字节跳动面试真题
统计连续登陆的三天数和以上的用户以及他们的首次登录和最后登陆时间

思路:
1.分组排序打行号
select uid ,dt ,row_number()over (partition by uid order by dt) rn from continuous
2.让时间戳-行号根据差值检查是否为连续select uid ,dt, date_sub(dt,rn) as dis from ( select uid,dt,row_number()over(partition by uid order by dt)rnfrom continuous )t13.为连续的接果为一样的用count(1)函数计算行数总数
select uid,min(dt),max(dt),count(1) as counts from ( select uid ,dt, date_sub(dt,rn) as dis from ( select uid ,dt,row_number()over(partition by uid order by dt )rnfrom continuous )t1 -) t2 group by uid;参考代码:
select uid,min(dt),max(dt),count(1) as counts from ( select uid ,dt, date_sub(dt,rn) as dise from ( select uid ,dt,row_number()over(partition by uid order by dt) rnfrom continuous )t1 )t2 group by uid ,dis having counts>2; -
腾讯经典数据分析面试题
-
PDD数据分析笔试题
3.3 SQL面试注意事项
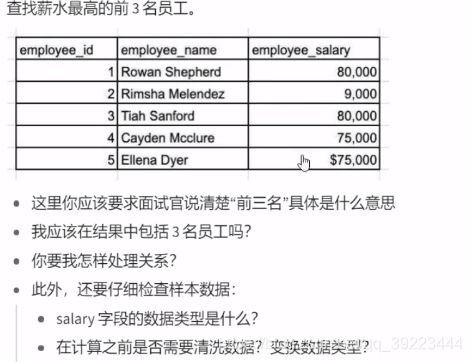
首先要提问,收集所需的细节
- 要搞定一场SQL面试,最重要的是尽量多问问题,获取关于给定任务和数据样本的所有细节。
- 充分理解需求后,接下来你就可以节省很多迭代问题的时间,并且能很好地处理边缘情况。
- 建议大家在参加SQL面试时,就当成是自己在和业务伙伴共事。所以在你提供解决方案之前,应该要针对数据请求了解清楚所有的需求。
与面试官交流你的思路
- 在SQL面试期间要随时与面试官沟通交流 #这一点非常重要
- 不要有疑问的时候才吱声,要随时沟通,面试官很乐意听你的想法的
- 在技术面试期间保持沟通交流往往会是有价值的
- 你可以谈论对问题和数据的理解
- 说明你计划如何解决问题
- 为什么使用某些函数而不是其他选项
- 以及正在考虑哪些极端情况
当面试官问:你的SQL能力怎么样?
- 其实面试官这样问主要是想了解你用SQL处理过什么样的数据场景
- 即使在面试中没有问你,你也可以自己说一下曾经使用SQL处理过哪些数据场景(也就是案例)


4. 数据分析求职指导
-
首先你需要明白公司最关注的问题是哪些? #这些问题在某些方面会比你的基础知识更重要
- 第一,你是否能够解决当前的问题(这里面对于实际问题的理解和抽象能力尤其关键)
- 第二,团队合作(你是否可以与其他同学形成合力,共同实现目标)
- 第三,你的潜力如何(入职后会有绩效、晋升的需求,你成长潜力如何,是否能和团队一起共同成长)
-
问题解决能力如何考察?
- 对于问题解决能力的考察,关注的不是问题是否被你完整解决,而是得到答案的思考路径和方法如何。
- 这里具体会关注三个能力
- 一是读题能力,是否能够正确定义问题;
- 二是分析能力,识别问题中的关键点和难点,确定解题思路;
- 三是应用能力,是否能将已有方法在具体情境中应用,真正掌握了先进技术。
- 能力考查方法
- 一般是逻辑题或者编程题
- 首先关注你是否能够通过沟通和互动,对问题建立正确的理解
- 其次是看你面对问题的时候,是能够进入问题情境,就事论事的分析问题,一步步建立对问题理解
- 还是说急于把未知问题套到一个已知问题的框架内解决
- 或者是在思考不完整的情况下轻易下判断
- 具体情境考察
- 是把你拉到一个具体的情境中来看,让你现场调试
- 但现场调试需要时间比较长,题目的设计也需要下功夫
- 一般大公司比较有精力搞这种面试
- 构造一个实际场景,观察你的思考角度和方法
- 是把你拉到一个具体的情境中来看,让你现场调试
- 一般是逻辑题或者编程题
- 对于问题解决能力的考察,关注的不是问题是否被你完整解决,而是得到答案的思考路径和方法如何。
-
合作能力如何考察?
- 团队合作能力在面试中很难考察的很深入,最好是你实习一段时间,才能完整判断合作能力。面试过程中,主要关注你沟通中的一些特质体现。
- 第一,你在面试环节中是很自我的在思考、表达,还是尊重面试官、尊重题目。
- 第二,你的沟通能力如何,是否能够快速理解面试官问题,有疑问的时候是否能用沟通解决疑问。
- 第三,你的表达能力如何,能够简明扼要的说清楚自己的观点,还是说表达缺乏重点,效率很低。
- 团队合作能力在面试中很难考察的很深入,最好是你实习一段时间,才能完整判断合作能力。面试过程中,主要关注你沟通中的一些特质体现。
-
成长潜力如何?
- 成长潜力体现在自控力、主动性、学习能力几个方面。
-
自控力和主动性的考察,主要是体现在简历考核中
- 你是能够主动探索自己希望学习的方向
- 还是被动的接受学校的培养计划
- 当自己确定了努力的方向,是否能够按照自己的期望进行努力,还是说很容易放弃
-
学习能力体现在题目考察中
- 读题的时候理解题目速度如何
- 分析题目时是否有很强的逻辑性
- 是否能够快速找到问题的关键
-
成长潜力的考核是贯穿面试整个过程的,从各个细节中形成完整的判断,你是否成长潜力合格
-
- 成长潜力体现在自控力、主动性、学习能力几个方面。
-
你如何准备面试?
准备面试分为2个阶段: -
一个是长期积累
- 学习能力、学术能力、解题能力都不是短期能够突击的。大家建立正确,的学习观念:面试的目的是双方相互了解,进行匹配,通过一些短期手段,即时通过了面试,后续的工作也是很痛苦的。
- 长期能力的培养
- 牛客网和leetcode都是很好的工具
- 不要简单的去满足题目通过了,
- 而是是否能够独立分析题面,理解题意,解题的时候都有哪些方法解决,优缺点如何,解题方法选型依据如何。
- 坚持这样的思考过程,做了几百道题,编程和解决问题的能力自然提升了。
- 主动性的培养可以尝试主动去参加比赛,以及各种活动,并不断改进方法提升成绩。
-
另一个是短期冲刺
- 冲刺的目的是完整的展示自己,避免面试的短时间无法利用好,展示自己的优点。
- 首先是整理好简历以及相关内容的了解,说清楚自己的核心优点,简历内容中相关的支撑点都有哪些。
- 其次是对于自己的项目,看看相关资料,说清楚难点和自己的价值,也对于领域内其他人的相关工作可以简要说明。
- 最后是多演练,找同学模拟练习,表达熟练了,情境熟悉了,自然面试表现会好不少。
- 冲刺的目的是完整的展示自己,避免面试的短时间无法利用好,展示自己的优点。
参考:数据分析面试通关
京东数据分析训练营