Background-Machine Learning 【ML-Agents 官方文档翻译(ML-Agent 1.9.1,Unity 2018-2020)】
Background: Machine Learning
鉴于许多 ML-Agents Toolkit 的用户可能没有正式的机器学习背景。
本页面提供了一个对机器学习的概述,以帮助开发者更好的理解 ML-Agents Toolkit。
然而,我们不打算提供一个完整的机器学习的教程,因为网上有很多优秀的学习资源。
机器学习是人工智能的一个分支,专注于从数据中学习自动处理和判断的方法。
机器学习算法主要有三类:非监督学习、监督学习和强化学习。
每一类算法使用从不同类型的数据进行训练。
下面的段落将依次对这三种机器学习的分支进行概述,并展示一些例子。
Unsupervised Learning
非监督学习的目标是将数据集内的相似元素分组或聚类。
举例而言,对于某款游戏的玩家,我们可以根据玩家对游戏的参与度来分组。
这使我们能够瞄准不同的玩家群体。
例如,对于高参与度的玩家,我们会邀请他们成为新功能的测试者,而对于不太投入的玩家,我们可以给他们推送有用的教程。
假设我们希望将玩家分成两组,首先定义玩家的基本属性,如游戏时间、消费总额以及完成关卡数量。
然后我们可以将这个数据集(每个玩家有3个属性)输入到一个非学习算法中,指定算法中的分组数量为 2。
算法会将玩家的数据集分成两组,每组中的玩家之间都很相似。
考虑到我们用来描述每个玩家的属性,在这种情况下,输出将把所有玩家分成两组,在语义上分别代表高/低参与度的玩家。
对于非监督学习而言,我们并没有提供具体的数据用于区分玩家参与度。
我们只是定义了适当的属性,并依靠算法本身发现了两个分组。
这种类型的数据通常被称为非标记数据,因为它缺少用于分组的直接标签。
因此,非监督学习常用于标注数据代价高昂或难以生产的情况。
在下一段中,我们将概述监督学习算法,它接受除了属性之外的输入标签。
Supervised Learning
在监督学习中,我们不希望只是将相似的元素分组,而是学习从每个元素到它所属的组(或类)的映射关系。
回到我们之前将玩家数据聚类的例子,现在假设我们希望预测哪些玩家会弃坑(即未来30天内停止玩游戏)。
我们可以查看我们的历史记录并创建包含玩家属性的数据集,除此之外添加一个标签来表示玩家是否弃坑。
请注意,我们在弃坑预测任务中使用的玩家属性可能与之前的聚类任务中使用的不同。
然后我们可以将这个数据集(每个玩家的属性和标签)输入到一个监督学习算法中,该算法将学习从玩家属性到表明玩家是否弃坑标签的映射。
直觉上,监督学习算法将学会玩家属性的哪些值与是否弃坑相关(例如,算法可能知道那些玩游戏时间短的玩家更倾向于弃坑)。
现在有了这个训练好的模型,我们给它提供一个新玩家(最近开始玩游戏的玩家)的属性,它将为该玩家输出一个_预测的_标签。
这种预测是算法对玩家是弃坑的预期。
我们现在可以根据预测结果,瞄准那些可能弃坑的玩家,吸引他们继续玩游戏。
你可能已经注意到,无论监督学习和非监督学习,都需要执行两个任务:选择属性和选择模型。
属性选择(也称为特征选择)涉及如何选择我们希望如何表示研究对象实体,在本例中是玩家。
另一方面,模型选择涉及到选择能够在当前任务上表现良好的算法(及其参数)。
这两个任务都是机器学习研究的活跃领域,在实践中,需要多次迭代才能得到好的结果。
接着我们再来看强化学习,第三种机器学习算法,可以说是 ML-Agents Toolkit 相关程度最高的一种。
Reinforcement Learning
强化学习可以被看作是做出序列决策的一种学习形式,常用于控制机器人相关。
设想有一个自主消防机器人,它的任务是导航到一个区域,发现火灾并扑灭它。
在任意时刻,机器人通过其传感器(如摄像头、加热、触摸)感知环境,处理这些信息并产生一个动作(如向左移动、旋转水管、打开水阀)。
换句话说,它根据环境信息(如传感器输入)和目标(如消除火灾)不断地做出决策,与环境中进行互动。
让机器人学习如何成功过执行消防任务正是强化学习的目的。
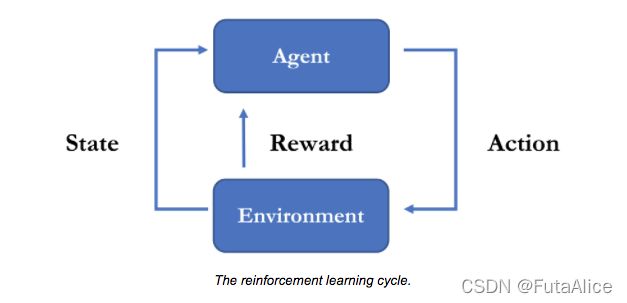
强化学习的目标是学习一个策略(Policy),本质上是从观测(Observations)到行动(Actions)的映射。
观测(Observations)是机器人可以感知的环境(Environment),本例中是传感器输入。
行动(Actions),即改变机器人的状态(例如,其底座的位置、其水管的位置以及软管开关)。
强化学习任务的最后一个部分是奖励信号(Reward Signal)。
机器人的训练目标是学习一种策略,使其整体回报最大化。
当训练一个机器人完成消防任务时,我们提供奖励(正奖励或负奖励)来指示它完成任务的情况。
注意,机器人在训练之前_不知道_如何灭火。
机器人扑灭火焰时,它会得到一个正奖励,而每过一秒,它就会得到一个很小的负奖励,以此它使机器人学会完成任务。
事实上,奖励是稀疏的,也就是说,并非每一步都提供奖励,只有当机器人成功完成任务或失败的情况时才会提供奖励,这是强化学习的一个决定性特征,也是为学习应对复杂的环境的策略困难(或耗时的)的原因。
[学习策略]通常需要反复试验和迭代策略更新。
更具体地说,机器人被放置在不同的火灾情况下,随着时间的推移,它会学习一个最优策略,使其更有效地扑灭火灾。
显然,我们不能指望在现实世界中反复训练机器人,尤其是涉及火灾的时候。
这就是为什么使用 Unity 作为模拟器是训练这类任务的最佳训练场所。
虽然我们关于强化学习的讨论是围绕机器人展开的,但在机器人和游戏中角色之间存在着许多相似之处。
在许多方面,我们都可以将非可玩角色(NPC)视为一个虚拟机器人,拥有自己对环境的观测,自己的一系列行动和特定目标。
因此,探索如何使用强化学习在 Unity 中训练角色行为是很自然的。
这正是 ML-Agents Toolkit 所提供的。
下面链接的视频包括一个强化学习演示,展示了使用 ML-Agents Toolkit 训练角色行为。
http://www.youtube.com/watch?feature=player_embedded&v=fiQsmdwEGT8
与非监督学习和有监督学习相似,强化学习也涉及两个任务:属性选择和模型选择。
属性选择是定义机器人的观察集合,以帮助机器人完成其目标,而模型选择是定义决策的形式(从观测到动作的映射)及其参数。
在实践中,训练是一个迭代的过程,可能需要改变属性和模型的选择。
Training and Inference
机器学习的三个分支的一个共同点是,它们同样涉及训练阶段和推理阶段。
虽然训练和推理阶段的细节实现在三种分支都不尽相同,但训练阶段提供已有的数据训练模型,而推理阶段则将模型应用到以前未见的新数据。
更具体地说:
- 在我们的非监督学习例子中,
训练阶段根据描述现有玩家的数据学习最优的两个分组,
而推理阶段将一个新玩家分配到这两个分组中的一个。 - 在我们的监督学习例子中,
训练阶段学习从玩家属性到玩家标签的映射,
而推理阶段则使用训练完成的模型,根据新玩家的属性,预测其标签。 - 在我们的强化学习例子中,
训练阶段通过引导试验学习最优策略,
而在推理阶段,Agent 收集观察并使用其学到的策略作出行动。
简而言之:这三种算法除了属性选择和模型选择外,还包括训练和推理阶段。
最终区分它们的是可供学习的数据类型。
在非监督学习中,我们的数据集是属性的集合,在监督学习中,我们的数据集是成对的属性-标签集合,最后,在强化学习中,我们的数据集是观测-行为-奖励元组的集合。
Deep Learning
深度学习是用来解决上述例子中问题的一系列算法。
近年来,深度学习因其在一些具有挑战性任务中的出色表现而受到欢迎。
其中之一便是 AlphaGo,一个计算机围棋程序,它利用了深度学习,能够击败李世石(围棋世界冠军)。
深度学习算法的一个关键特点是能够从大量的训练数据中学习非常复杂的函数。
强化学习任务会生成大量数据(通过模拟或 Unity 等引擎),使用深度学习便成了自然而然的选择。
通过在 Unity 中生成成千上万的环境模拟,我们可以训练出应对复杂环境的策略(复杂环境指 Agent 能够收集到的观测和可采取的行动数量都很大)。
我们在 ML-Agents 中提供的许多算法都使用了某种形式的深度学习,是基于开源库 PyTorch 构建的。