Spark 源码(6) - 任务提交之 Driver 启动流程
一、Master 处理 Driver 注册消息
上次阅读到客户端发送了一个 RequestSubmitDriver 消息给 Master,Master 收到消息后开始处理。
在 Master 类中搜索 case RequestSubmitDriver,可以看到具体的处理逻辑:
首先创建了一个 DriverInfo:
val driver = createDriver(description)
new DriverInfo(now, newDriverId(date), desc, date)
然后把 Driver 信息持久化到 zk 中:
persistenceEngine.addDriver(driver)
放到这个 waitingDrivers 列表中(这个列表很重要)
waitingDrivers += driver
放到 Master 自己的内存中:
drivers.add(driver)
然后 schedule() 起来
schedule()
二、Schedule() 的处理
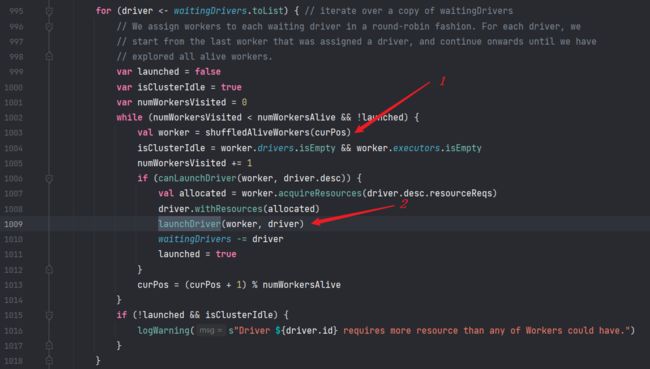
schedule() 方法,主要遍历了两个列表,一个是 waitingDrivers 列表,另一个是 waitingApps 列表。这里我们重点看 waitingDrivers 列表的处理。
首先筛选出状态为 ALIVE 的 Worker,并随机排序:

然后,随机取一个 Worker 出来,判断是否有足够的资源启动 Driver,如果有,则开始 launchDriver
然后从 waitingDrivers 列表中去掉这个 Driver
三、LaunchDriver 处理
启动驱动之前,先把 driver 放到 Worker 自己的内存中,然后往 Worker 发送一个 LaunchDriver 消息:

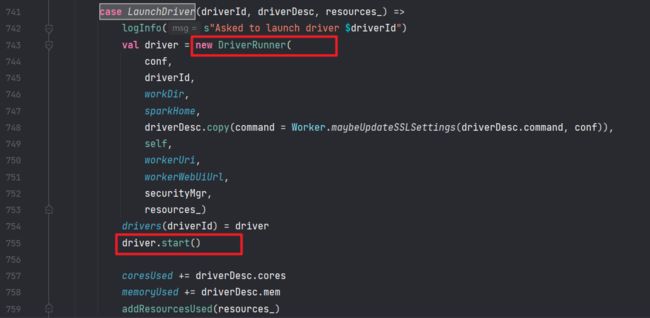
然后我们去 Worker 类中搜索 case LaunchDriver,看 Worker 是如何处理的
封装了一个 DriverRunner ,并且把它启动了起来:
在 start() 方法中,直接启动了一个 Thread,在 线程处理中,调用了:
val exitCode = prepareAndRunDriver()
在这个方法中,首先初始化了本地目录,然后把 jar 文件下载下来

然后封装了一个 shell 命令,这个命令实际上就是 java DriverWrapper,启动了一个 JVM,DriverWrapper 是上一节中提到的类
然后进入这个方法:
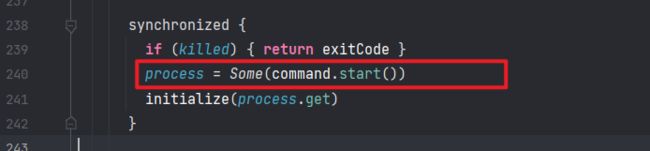
runCommandWithRetry(ProcessBuilderLike(builder), initialize, supervise)
在这个方法中,使用 command.start() 把 Driver 就启动了起来:
四、Driver 的启动
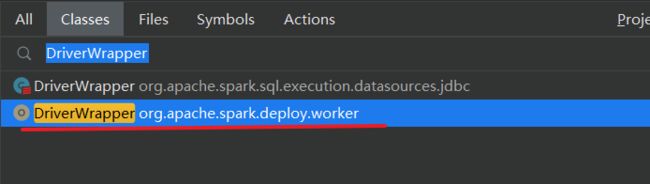
在执行了 java DriverWrapper 了以后,实际上就启动了一个 JVM,里面开始执行 DriverWrapper 的 main 方法,我们就跳转到 DriverWrapper 的 main 方法。
注意是 deploy 包下的类:
在 DriverWrapper 的 main 方法中,实际上就是在执行我们提交的 jar 包中的 main 方法了
可以看到设置了类加载器,并且使用反射来执行了提交 jar 包中的 main 方法:
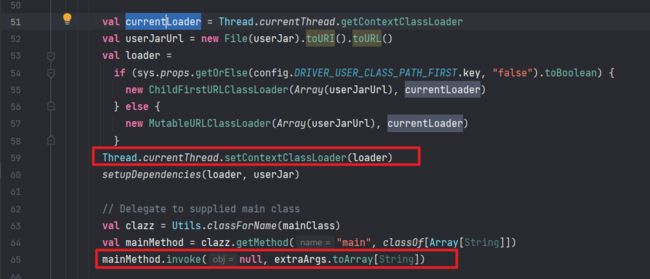
然后就到了我们比较熟悉的 Spark 业务逻辑代码中,也就是 new SparkContext(),执行算子,这个我们就放到下次再讲了。
五、总结
本次源码阅读之后,Master 已经找到了一个 Worker ,并在上面启动了 Driver 进程,流程图如下:
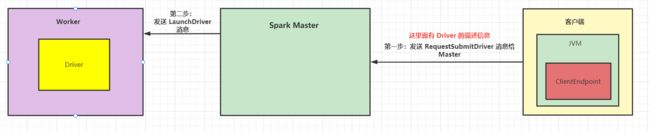
下次,我们再来讲 Driver 中 new SparkContext() 都做了些什么。