【面试算法——动态规划 21】正则表达式匹配(hard)&& 交错字符串
10. 正则表达式匹配
链接: 10. 正则表达式匹配
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 ‘.’ 和 ‘*’ 的正则表达式匹配。
‘.’ 匹配任意单个字符
‘*’ 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
示例 1:
输入:s = “aa”, p = “a”
输出:false
解释:“a” 无法匹配 “aa” 整个字符串。
示例 2:
输入:s = “aa”, p = “a*”
输出:true
解释:因为 ‘*’ 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 ‘a’。因此,字符串 “aa” 可被视为 ‘a’ 重复了一次。
示例 3:
输入:s = “ab”, p = “."
输出:true
解释:".” 表示可匹配零个或多个(‘*’)任意字符(‘.’)。
1.状态表示*
dp[i][j] 表⽰:字符串 p 的 [0, j] 区间和字符串 s 的 [0, i] 区间是否可以匹配
2.状态转移方程
⽼规矩,根据最后⼀个位置的元素,结合题⽬要求,分情况讨论:
- i. 当 s[i] == p[j] 或 p[j] == '. ’ 的时候,此时两个字符串匹配上了当前的⼀个字符,只能从 dp[i - 1][j - 1] 中看当前字符前⾯的两个⼦串是否匹配。只能继承上个状态中的匹配结果, dp[i][j] = dp[i][j - 1] ;
- ii. 当 p[j] == ‘*’ 的时候,此时匹配策略有两种选择:
• ⼀种选择是: * 匹配空字符串,此时相当于它匹配了⼀个寂寞,直接继承状态 dp[i] [j - 1] ,此时 dp[i][j] = dp[i][j -1] ;
• 另⼀种选择是: * 向前匹配 1 ~ n 个字符,直⾄匹配上整个 s1 串。此时相当于从 dp[k][j - 1] (0 <= k <= i) 中所有匹配情况中,选择性继承可以成功的情况。此时 dp[i][j] = dp[k][j - 1] (0 <= k <= i) ; - iii. 当 p[j] 不是特殊字符,且不与 s[i] 相等时,⽆法匹配。 三种情况加起来,就是所有可能的匹配结果。
综上所述,状态转移⽅程为:
▪ 当 s[i] == p[j] 或 p[j] == ‘?’ 时: dp[i][j] = dp[i][j - 1] ;
▪ 当 p[j] == ‘*’ 时,有多种情况需要讨论: dp[i][j] = dp[k][j - 1] (0 <=k <= i) ;
3. 初始化
由于 dp 数组的值设置为是否匹配,为了不与答案值混淆,我们需要将整个数组初始化为false 。
由于需要⽤到前⼀⾏和前⼀列的状态,我们初始化第⼀⾏、第⼀列即可。
dp[0][0] 表⽰两个空串能否匹配,答案是显然的,初始化为 true 。
第⼀⾏表⽰ s 是⼀个空串, p 串和空串只有⼀种匹配可能,即 p 串全部字符表⽰为"任⼀字符+*",此时也相当于空串匹配上空串。所以,我们可以遍历 p 串,把所有前导为"任⼀字符+"的 p ⼦串和空串的 dp 值设为 true 。
第⼀列表⽰ p 是⼀个空串,不可能匹配上 s 串,跟随数组初始化即可
4. 填表顺序
根据「状态转移⽅程」得:从上往下填写每⼀⾏,每⼀⾏从左往右
5. 返回值
返回 dp[m][n]
代码:
bool isMatch(string s, string p) {
int n=s.size();
int m=p.size();
//表示的是 s串中0~i 位置的子串,能否于 p串 0~j 上完全匹配
vector<vector<bool>> dp(n+1,vector<bool>(m+1,false));
//初始化
dp[0][0]=true;
for(int i=2;i<=m;i+=2)//初始化有坑
{
if(p[i-1]=='*') dp[0][i]=1;
else break;
}
//填表
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
if(s[i-1]==p[j-1]||p[j-1]=='.')
{
dp[i][j]=dp[i-1][j-1];
}
if(p[j-1]=='*')
{
if(p[j-2]=='.')
{
dp[i][j]=dp[i][j-2]||dp[i-1][j];
}
else
{
if(p[j-2]==s[i-1])//相等的时候,
dp[i][j]=dp[i][j-2]||dp[i-1][j];
//当不相等的时候,也需要考虑匹配空串的情况
else dp[i][j]=dp[i][j-2];
}
}
}
}
return dp[n][m];
}
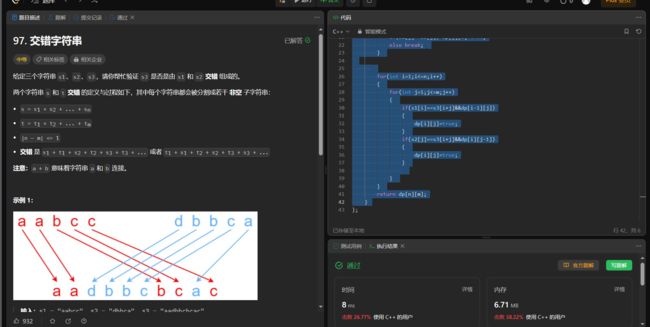
97. 交错字符串
链接: 97. 交错字符串
给定三个字符串 s1、s2、s3,请你帮忙验证 s3 是否是由 s1 和 s2 交错 组成的。
两个字符串 s 和 t 交错 的定义与过程如下,其中每个字符串都会被分割成若干 非空 子字符串:
s = s1 + s2 + … + sn
t = t1 + t2 + … + tm
|n - m| <= 1
交错 是 s1 + t1 + s2 + t2 + s3 + t3 + … 或者 t1 + s1 + t2 + s2 + t3 + s3 + …
注意:a + b 意味着字符串 a 和 b 连接。

示例 2:
输入:s1 = “aabcc”, s2 = “dbbca”, s3 = “aadbbbaccc”
输出:false
示例 3:
输入:s1 = “”, s2 = “”, s3 = “”
输出:true
1.状态表示*
dp[i][j] 表⽰字符串 s1 中 [1, i] 区间内的字符串以及 s2 中 [1, j] 区间内的字符串,能否拼接成 s3 中 [1, i + j] 区间内的字符串。
2.状态转移方程
先分析⼀下题⽬,题⽬中交错后的字符串为 s1 + t1 + s2 + t2 + s3 + t3… ,看
似⼀个 s ⼀个 t 。实际上 s1 能够拆分成更⼩的⼀个字符,进⽽可以细化成 s1 + s2 +s3 + t1 + t2 + s4… 。
也就是说,并不是前⼀个⽤了 s 的⼦串,后⼀个必须要⽤ t 的⼦串。这⼀点理解,对我们的状态转移很重要。
继续根据两个区间上「最后⼀个位置的字符」,结合题⽬的要求,来进⾏「分类讨论」:
- i. 当 s3[i + j] = s1[i] 的时候,说明交错后的字符串的最后⼀个字符和 s1 的最后⼀个字符匹配了。那么整个字符串能否交错组成,变成: s1 中[1, i - 1] 区间上的字符串以及 s2 中 [1, j] 区间上的字符串,能够交 错形成 s3 中 [1, i + j - 1] 区间上的字符串,也就是 dp[i - 1][j] ; 此时
dp[i][j] = dp[i - 1][j] - ii. 当 s3[i + j] = s2[j] 的时候,说明交错后的字符串的最后⼀个字符和 s2 的最后 ⼀个字符匹配了。那么整个字符串能否交错组成,变成: s1 中 [1, i] 区间上的字符串以及 s2 中 [1, j - 1] 区间上的字符串,能够交 错形成 s3 中 [1, i + j - 1] 区间上的字符串,也就是dp[i][j - 1] ;
- iii. 当两者的末尾都不等于 s3 最后⼀个位置的字符时,说明不可能是两者的交错字符串。
上述三种情况下,只要有⼀个情况下能够交错组成⽬标串,就可以返回 true 。因此,我们可以定义状态转移为:
dp[i][j] = (s1[i - 1] == s3[i + j - 1] && dp[i - 1][j])|| (s2[j - 1] == s3[i + j - 1] && dp[i][j - 1])
3. 初始化
于⽤到 i - 1 , j - 1 位置的值,因此需要初始化「第⼀个位置」以及「第⼀⾏」和「第⼀列」。
第⼀个位置:
dp[0][0] = true ,因为空串+空串能够构成⼀个空串。
第⼀⾏:
第⼀⾏表⽰ s1 是⼀个空串,我们只⽤考虑 s2 即可。因此状态转移之和 s2 有关:
dp[0][j] = s2[j - 1] == s3[j - 1] && dp[0][j - 1] , j 从 1 到 n
第⼀列:
第⼀列表⽰ s2 是⼀个空串,我们只⽤考虑 s1 即可。因此状态转移之和 s1 有关:
dp[i][0] = s1[i - 1] == s3[i - 1] && dp[i - 1][0] , i 从 1 到 m
4. 填表顺序
根据「状态转移⽅程」得:从上往下填写每⼀⾏,每⼀⾏从左往右
5. 返回值
返回 dp[m][n]
代码:
bool isInterleave(string s1, string s2, string s3) {
int n=s1.size();
int m=s2.size();
if(m+n!=s3.size()) return false;
s1=" "+s1;
s2=" "+s2;
s3=" "+s3;
//表示的是s1中前i位置的和s2中前j位置能否和s3中前 i+j 位置进行组成
vector<vector<bool>> dp(n+1,vector<bool>(m+1));
dp[0][0]=true;
for(int i=1;i<=m;i++)
{
if(s2[i]==s3[i]) dp[0][i]=true;
else break;
}
for(int j=1;j<=n;j++)
{
if(s1[j]==s3[j]) dp[j][0]=true;
else break;
}
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
if(s1[i]==s3[i+j]&&dp[i-1][j])
{
dp[i][j]=true;
}
if(s2[j]==s3[i+j]&&dp[i][j-1])
{
dp[i][j]=true;
}
}
}
return dp[n][m];
}