Java多线程基础-9:代码案例之阻塞队列
阻塞队列是一种特殊的队列,带有“阻塞特性”,也遵守队列 “先进先出” 的原则。阻塞队列是一种线程安全的数据结构,并且具有以下特性:
- 当队列满时,继续入队列就会阻塞,直到有其他线程从队列中取走元素。
- 当队列空时,继续出队列也会阻塞,直到有其他线程往队列中插入元素。
在多线程代码编程中,多个线程之间要进行数据交互,我们可以使用阻塞队列来简化代码的编写。

目录
一、Java标准库:BlockingQueue接口
1、使用标准库中的阻塞队列
2、生产者-消费者模型:多线程下阻塞队列应用
a.什么是生产者-消费者模型?
b.生产者-消费者模型是用来解决什么问题的?
第一,可以让上下游模块之间,更好地“解耦合”。
第二,使用生产者-消费者模型,可以削峰填谷。
二、使用 BlockingQueue 代码实现生产者-消费者模型
三、代码实现 BlockingQueue
1、实现一个普通队列
2、加上线程安全
3、加上阻塞功能
4、用while替代if进行条件判断
5、完整代码:MyBlockingQueue
6、实现生产者-消费者模型
四、**补充:SynchronousQueue
1、SynchronousQueue的使用
2、注意
(1)对于 SynchronousQueue 来说,put 和 take 操作必须是交替执行的
(2)SynchronousQueue 中的元素不可重复使用。
一、Java标准库:BlockingQueue接口
1、使用标准库中的阻塞队列
在 Java 标准库中内置了阻塞队列。如果我们需要在一些程序中使用阻塞队列,可以直接使用标准库中的 BlockingQueue 。
与BlockingQueue相关的具体的继承和实现关系如下:
collection接口------>Queue接口------>BlockingQueue接口----->7个实现类
- ArrayBlockingQueue:由数组结构组成的有界阻塞队列。它在构造的时候用户必须传入一个capacity。
- LinkedBlockingQueue:由链表结构组成的有界阻塞队列,默认capacity为
Integer.MAX_VALUE。也可以自行指定capacity。
- PriorityBlockingQueue:支持优先级排序的无界阻塞队列。
- DelayQueue:使用优先级队列实现的延迟无界阻塞队列。
- SynchronousQueue:不存储元素的阻塞队列,它的容量为0.
- LinkedTransferQueue:由链表结构组成的无界阻塞队列。
- LinkedBlockingDeque:由链表结构组成的双向阻塞队列。


BlockingQueue 是一个接口,真正实现的类是 LinkedBlockingQueue(链表实现)和 ArrayBlockingQueue (顺序表实现)。
BlockingDeque queue1 = new LinkedBlockingDeque<>();
BlockingDeque queue2 = new ArrayBlockingQueue<>(); 1.如果队列空,尝试出队列,就会阻塞等待.等待到队列不空为止2.
- put() 用于阻塞式的入队列。put()方法会抛出 InterruptedException 异常,因为该方法可能会带来阻塞。而一旦阻塞了,就有可能被interrupt方法提前唤醒,此时就会抛出该异常(会带来阻塞的方法往往会抛出 InterruptedException 异常)。如果队列已满,尝试put(),就会阻塞等待,直到队列不满为止。
- take() 用于阻塞式的出队列。如果队列空,尝试take(),也会阻塞等待,直到队列不空为止。
如下面代码所示,put 5 次后,执行take 6 次的操作。由于第6次出队列时队列已空,线程就会阻塞:
import java.util.concurrent.BlockingDeque;
import java.util.concurrent.LinkedBlockingDeque;
public class Test {
public static void main(String[] args) throws InterruptedException {
BlockingDeque queue = new LinkedBlockingDeque<>();
// 阻塞队列的和核心方法主要有两个
// 1. put() 入队列
queue.put("hello1");
queue.put("hello2");
queue.put("hello3");
queue.put("hello4");
queue.put("hello5");
// 2.take() 出队列
String ret = null;
// 出队列 1 次
ret = queue.take();
System.out.println(ret);
// 出队列 2 次
ret = queue.take();
System.out.println(ret);
// 出队列 3 次
ret = queue.take();
System.out.println(ret);
// 出队列 4 次
ret = queue.take();
System.out.println(ret);
// 出队列 5 次
ret = queue.take();
System.out.println(ret);
// 出队列 6 次
ret = queue.take();
System.out.println(ret);
}
}

BlockingQueue 也有 offer,poll, peek 等方法, 但是这些方法不带有阻塞特性。
2、生产者-消费者模型:多线程下阻塞队列应用
a.什么是生产者-消费者模型?
生产者-消费者模型这个概念很关键,是我们服务器开发中一种非常常见的写法。
可以用擀饺子皮和包饺子这两件事情来类比。假设过年有一桌子人围在一起准备饺子。每个人自己擀一个饺子皮,自己包一个;再擀一个,再自己包一个……这样的做法虽然能完成任务,但是并不高效:家里只有一根擀面杖,当一个人正在使用擀面杖的时候,剩下的几个人只能干等着,即使有多根擀面杖,但每个人都在不停地状态切换,也很费劲。
更常见的包法是一个人负责擀皮,另外几个人负责包(类似于流水线)。此时,就构成了生产者-消费者模型。
注意,生产者、消费者的角色是针对某个资源而言的,针对的资源不同,角色分配也就不同。对于饺子皮来说,负责擀皮的人就是生产饺子皮的,所以是生产者;负责包饺子的人是饺子皮的消耗饺子皮的,所以是消费者。
生产者和消费者之间交换数据,就需要用到一个交易场所。比如放饺子的盖帘:

这个交易场所就相当于是一个阻塞队列。如果擀饺子皮的人擀得很快,盖帘上一下子堆满了饺子皮,擀饺子皮的人就可以歇会儿;如果包饺子的包得很快,一下子把饺子皮都包完了,那包子饺子的就停下来等待擀饺子皮的人再擀点皮出来。
b.生产者-消费者模型是用来解决什么问题的?
生产者-消费者能解决很多问题,最主要的是两个方面:
第一,可以让上下游模块之间,更好地“解耦合”。
耦合指的是模块之间的关系是强还是弱,关联越强,耦合越高。而写代码追求的就是低耦合高内聚,避免代码牵一发动全身。(高内聚指的是将相关联的代码分门别类地规制起来。)
什么是耦合高的情况呢?考虑以下情景:有两台服务器A和B直接通信。

此时,如果要再加一个与A通信的C服务器,A的代码就必须作出很大调整。
而使用生产者-消费者模型,耦合就能够降低了。仍然有要进行通信的服务器A和服务器B,但此时它们不直接进行通信,A把它的请求发给一个阻塞队列服务器(也叫消息队列服务器。是把阻塞队列的功能单列出来,再扩充上更多的功能做成单独的服务器)。
A和B彼此不知道对方的存在,它们都只与阻塞队列服务器通信。此时B挂了,对A没有影响。如果再加一个C,此时直接让C从队列中获取请求即可,对于A的影响是非常小的。
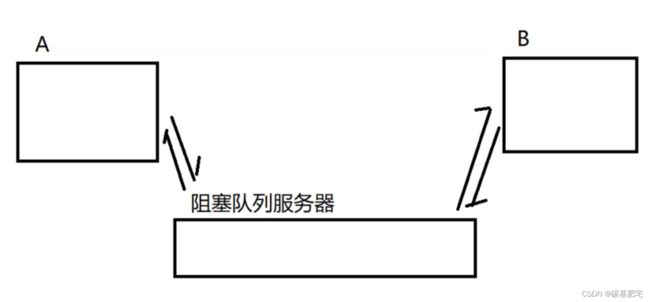
A、B、C作为业务服务器,代码是不断在变化的;而阻塞队列服务器和业务无关,代码不太会变化,也就更稳定。因此,阻塞队列服务器挂的概率是远小于业务服务器的。
第二,使用生产者-消费者模型,可以削峰填谷。
仍然是两个服务器:
 A与B直接通信的情况
A与B直接通信的情况
如果此时A和B是直接调用的关系,A收到了请求峰值,B也同样会有这个峰值。假设A平时收到的请求是 10000个/s,而在某个时间点突然收到了 30000个/s,对于B来说,它的请求同样是 30000个/s。服务器在处理每个请求时,都要消耗一定的硬件资源,包括不限于CPU,内存,带宽等,如果某个硬件资源达到瓶颈,此时服务器就挂了。
如果B在设计时,没有考虑峰值处理的情况,B可能也就挂了,这就给系统的稳定性带来了极大的风险。但是,如果引入生产者-消费者模型,风险就大大降低了。
 引入阻塞队列的情况
引入阻塞队列的情况
A不直接向B发送请求,而是向消息队列服务器发送请求。A收到的请求多了,队列中的元素也就多了,而此时的B仍然可以按照之前的速率来取元素。换句话说,队列帮B承担了压力。(队列没有业务,代码稳定,承担了压力也不容易挂。另外,A作为入口服务器,一般来说起到的效果就是调用一下其他服务武器,并把结果汇总,统一返回,业务比较简单,因此A服务器也不容易挂。而B服务器是有具体的业务的,B承担的工作量更大,单个请求吃的资源更多,也就更“娇贵”,更容易挂。)
假设流量高峰后还有个波谷,此时B仍然可以按照原有速率消费队列中之前积压的数据。
阻塞队列的削峰填谷作用与水库、湖泊对河流水量削峰填谷的作用是相似的。
这就像一条河流,当雨季时,天降暴雨(降水量达到峰值),河流上游的水量激增,下游的水量也会随之暴增。此时如果下游没有相应的排洪泄洪设施,河流下游就可能因为河水决堤而引发洪灾;另一方面,当旱季降水不足,上游水量供给减少,也会直接导致下游旱灾。而在中游建设一个水库,在雨季用于蓄洪,在旱季用于给下游开闸放水,此时就能一直保持河流下游水量适中且变化平缓了。如三峡大坝就是如此。
阻塞队列、三峡大坝等起到的效果与生产者-消费者模型起到的效果也是一致的。
二、使用 BlockingQueue 代码实现生产者-消费者模型
下面是使用BlockingQueue实现生产者-消费者模型模型的一个代码案例。注意,其中的生产者和消费者不一定只有一个,可以同时存在多个消费者和生产者。
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class Main3 {
public static void main(String[] args) {
// 创建一个阻塞队列
BlockingQueue blockingQueue = new LinkedBlockingQueue<>();
// 消费者
Thread t1 = new Thread(() -> {
while(true) {
try {
int value = blockingQueue.take();
System.out.println("消费元素:" + value);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t1.start();
// 生产者
Thread t2 = new Thread(() -> {
int value = 0;
while(true) {
try {
System.out.println("生产元素: " + value);
blockingQueue.put(value);
value++;
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
});
t2.start();
}
}
运行结果:每隔一秒(1000ms)生产者会生产出一个元素,put进阻塞队列blockingQueue内;而消费者消费元素没有时间间隔,一旦blockingQueue中有元素,它就会take,立即进行消费;没有元素的时候消费者将阻塞等待生产者生产出元素。

生产者-消费者模型是阻塞队列BlockingQueue的应用。如何使用BlockingQueue是简单的,但关键还要掌握如何通过自己的代码实现BlockingQueue。
三、代码实现 BlockingQueue
此处介绍如何采用数组实现阻塞队列(不带泛型)。
阻塞队列就是“带有阻塞特性的队列”,实现一个阻塞队列主要分为3步:
- 实现一个普通队列。
- 加上线程安全。
- 加上阻塞功能。
1、实现一个普通队列
结合数据结构的知识,可以通过数组构造出一个循环队列:
class MyBlockingQueue {
// 创建数组空间
private int[] elem = new int[1000];
private int front = 0;
private int back = 0;
private int size = 0;
public void put(int value) {
// 数组满
if(elem.length == size) {
return;
}
elem[back] = value;
back++;
// 判断
if(back == elem.length) {
back = 0;
}
size++;
}
public Integer take() {
// 数组空
if(size == 0) {
return null;
}
int value = elem[front];
front++;
// 判断是否到数组末尾
if(front == elem.length) {
front = 0;
}
size--;
return value;
}
}
讲解一下这里为什么要加:
if(back == elem.length) {
back = 0;
}
或
if(front == elem.length) {
front = 0;
}在tail或head到达数组的末端时,需要让这两个指针回到数组的开头,以此“循环”。很多同学可能接触过取余数的写法:back += (back+1)%数组长度。 这样的方式也是可行的,但是效率不高。
在写代码时,一般会追求开发效率和执行效率。开发效率是针对程序员开发程序而言的,而执行效率是针对代码运行而言的。写成上面取余数的方式,既没有提高程序的开发效率(这样写代码的可读性并不高),也没有保证执行效率,因此不是一种好的写法,尽管它也能达成目的。

而写成if的方式能够提高这两个效率。在执行效率方面,表面上看if语句有两行,但实际上,每次只有指针到达数组末尾了,才会进入if判断;而到达数组末尾的次数是远远小于操作总次数的。比如上述的elem数组,总长度为1000,只有执行了1000次操作后,才会进入一次if判断让back回到开头,而剩下的999次操作都不会进入if判断。
2、加上线程安全
即加锁,用synchronized即可。直接把synchronized加在成员方法take()和put()上,锁对象是this,即MyBlockingQueue类的实例。
如下面代码中,对象myBlockingQueue被创建出来,那么当它调用take和put时,该对象的实例就是锁对象,即this。找到谁是锁对象,对后面实现阻塞功能有重要影响。
public class Test {
public static void main(String[] args) {
MyBlockingQueue myBlockingQueue = new MyBlockingQueue();
}
}
class MyBlockingQueue {
// 创建数组空间
private int[] elem = new int[10];
private int front = 0;
private int back = 0;
private int size = 0;
synchronized public void put(int value) {
// 数组满
if(elem.length == size) {
return;
}
elem[back] = value;
back++;
// 判断
if(back == elem.length) {
back = 0;
}
size++;
}
synchronized public Integer take() {
// 数组空
if(size == 0) {
return null;
}
int value = elem[front];
front++;
// 判断是否到数组末尾
if(front == elem.length) {
front = 0;
}
size--;
return value;
}
}3、加上阻塞功能
根据阻塞队列的特性:队列满时继续put()会阻塞,直到有线程take();队列空时继续从队列中take()也会阻塞。,直到有线程put()。通过wait()和notify()配合来实现。调用 wait() 和 notify() 方法的对象必须是共享同一个锁对象的线程,否则会抛出 IllegalMonitorStateException 异常。由于synchronized直接加在了成员方法上,因此锁对象就是this,那么调用wait()和notify()的对象也是this。
public class Test {
public static void main(String[] args) {
MyBlockingQueue myBlockingQueue = new MyBlockingQueue();
}
}
class MyBlockingQueue {
// 创建数组空间
private int[] elem = new int[10];
private int front = 0;
private int back = 0;
private int size = 0;
synchronized public void put(int value) throws InterruptedException {
// 数组满
if(elem.length == size) {
this.wait(); //队列满再入队列->阻塞
}
elem[back] = value;
back++;
// 判断
if(back == elem.length) {
back = 0;
}
size++;
this.notify(); // 唤醒因队列空而阻塞的情况
}
synchronized public Integer take() throws InterruptedException {
// 数组空
if(size == 0) {
this.wait(); // 队列空而出队列->阻塞
}
int value = elem[front];
front++;
// 判断是否到数组末尾
if(front == elem.length) {
front = 0;
}
size--;
this.notify(); // 唤醒因队列满而阻塞的情况
return value;
}
}注意,上面两个队列不可能同时阻塞,也就是说,一个队列不可能既是空,又是满。
4、用while替代if进行条件判断
还有一点要强调,其实Java官方并不是非常推荐这样使用wait:

查看Java官方的说明,可以发现:

也就是说,wait()方法可能会被其它其它方法中断,如interrupt方法。此时,wait的等待条件其实还没成熟,就被提前唤醒了,这样代码的执行可能就不符合预期了。
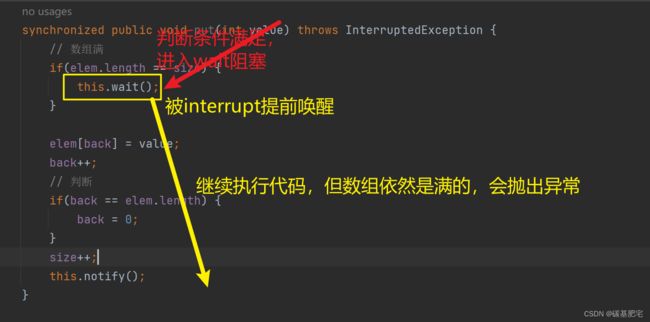 明明队列非空的条件还没满足,但wait被唤醒后就继续往下走了,没有进行条件判断
明明队列非空的条件还没满足,但wait被唤醒后就继续往下走了,没有进行条件判断
解决这个问题很简单:更稳妥的方法,是在wait被唤醒之后,再进行一次条件判断。wait之前,发现继续执行的条件不满足,开始wait,然后等到wait被唤醒之后,再确认一下条件是不是满足。如果不满足,还可以继续wait。
wait应总是在while中使用。如这个例子:https://blog.csdn.net/wyd_333/article/details/130575605
当中,涉及的“虚假唤醒”问题就与wait是否在while中使用直接相关。
5、完整代码:MyBlockingQueue
class MyBlockingQueue {
// 创建数组空间
private int[] elem = new int[10];
private int front = 0;
private int back = 0;
private int size = 0;
synchronized public void put(int value) throws InterruptedException {
// 数组满
// 用while判断是否满足条件
while(elem.length == size) {
this.wait();
}
elem[back] = value;
back++;
// 判断
if(back == elem.length) {
back = 0;
}
size++;
this.notify();
}
synchronized public Integer take() throws InterruptedException {
// 数组空
// 用while判断是否满足条件
while(size == 0) {
this.wait();
}
int value = elem[front];
front++;
// 判断是否到数组末尾
if(front == elem.length) {
front = 0;
}
size--;
this.notify();
return value;
}
}6、实现生产者-消费者模型
public class Test {
public static void main(String[] args) {
MyBlockingQueue myBlockingQueue = new MyBlockingQueue();
// 生产者 put
Thread t1 = new Thread(() -> {
try {
int value = 0;
while(true) {
System.out.println("生产:" + value);
myBlockingQueue.put(value);
Thread.sleep(1000);
value++;
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t1.start();
// 消费者 take
Thread t2 = new Thread(() -> {
while(true) {
try {
int value = myBlockingQueue.take();
System.out.println("消费:" + value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
}
}在生产者中添加Thread.sleep(),此时是生产得快,消费得慢。运行后可以直观感受到,元素是生产一个、消费一个的。每生产完一个,就立即消费掉,等待再次生产。
当然,也可以在消费者中添加Thread.sleep()。此时是生产得慢,而消费得快。在消费者sleep的时候,生产者生产迅速,很可能会一口气生成完整个队列中的所有元素,令队列满而生产者进入阻塞。等待消费者结束sleep,消费1个元素,此时生产者才会再次生产。
Thread t2 = new Thread(() -> {
while(true) {
try {
// 令消费者sleep
Thread.sleep(3000);
int value = myBlockingQueue.take();
System.out.println("消费:" + value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
上面之所以一口气只生产到10,是因为在MyBlockingQueue中,把队列容量设定为了10.
// 创建数组空间
private int[] elem = new int[10];四、**补充:SynchronousQueue
在 Java 中,SynchronousQueue 是一个实现了 BlockingQueue 接口的类。与普通的 BlockingQueue 不同的是,SynchronousQueue没有容量capacity,具有一些特殊的行为。
1、SynchronousQueue的使用
***有一个疑问:SynchronousQueue没有capacity,那么它怎么存放put进来的元素呢?又从哪里take元素呢?
确实,SynchronousQueue 并不是像其他阻塞队列那样有固定的容量,它的实现实际上是基于一种传输机制,即:一个线程试图将元素添加到队列中时,必须等待另一个线程从队列中取走该元素,反之亦然。换句话说,SynchronousQueue 可以看作是一个零容量的阻塞队列,其中元素的存储和移除,是通过线程之间的相互配合完成的。
具体来说:当一个线程调用 put 方法时,它会将要添加的元素暂时保存在本地变量中,然后阻塞自己,等待另一个线程调用 take 方法取走该元素。当另一个线程调用 take 方法时,它也会阻塞自己,等待另一个线程调用 put 方法并将要传递的元素交给它。在这个过程中,元素的实际存储并不需要使用队列,因为队列并没有容量,而是仅用于实现线程之间的协作机制。
因此,SynchronousQueue 可以用于在两个线程之间传递元素:一个线程生产元素并调用 put 方法,另一个线程消费元素并调用 take 方法。这种交换操作在两个线程之间同步进行(因此也称为同步队列)。
下面展示了如何在两个线程之间使用 SynchronousQueue 进行元素交换:
import java.util.concurrent.SynchronousQueue;
public class SynchronousQueueExample {
public static void main(String[] args) {
final SynchronousQueue queue = new SynchronousQueue();
Thread producer = new Thread(new Runnable() {
public void run() {
try {
int value = 42;
System.out.println("Producer is putting: " + value);
queue.put(value);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
});
Thread consumer = new Thread(new Runnable() {
public void run() {
try {
int value = queue.take();
System.out.println("Consumer is taking: " + value);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
});
producer.start();
consumer.start();
}
}
在上面程序中,我们创建了一个 SynchronousQueue 实例,然后创建了一个生产者线程和一个消费者线程。生产者线程调用 put 方法将值 42 添加到队列中,然后阻塞等待消费者线程取走这个元素。消费者线程调用 take 方法从队列中取出一个元素,并在控制台输出它。由于这个队列是同步的,因此生产者线程和消费者线程将会同步进行,直到元素被成功交换。
2、注意
(1)对于 SynchronousQueue 来说,put 和 take 操作必须是交替执行的
如果一个线程调用了 put 方法并被阻塞,那么它只有等待另一个线程调用 take 方法才能继续执行。反之,如果一个线程调用了 take 方法并被阻塞,那么它只有等待另一个线程调用 put 方法才能继续执行。
这种交替执行的特性使得 SynchronousQueue 在某些情况下非常有用。
例如,当一个线程需要向另一个线程传递数据时,可以使用 SynchronousQueue 来保证线程之间的同步和可靠性。在这种情况下,一个线程负责生产数据并将其添加到队列中,而另一个线程负责消费数据并从队列中取出它。由于队列中始终只有一个元素,因此这种操作是非常高效和可靠的。
但要注意,如果一个线程调用了 put 方法但是没有其他线程调用 take 方法取走元素,那么这个线程就会一直被阻塞下去。同样地,如果一个线程调用了 take 方法但是没有其他线程调用 put 方法添加元素,那么这个线程也会一直被阻塞下去。
(2)SynchronousQueue 中的元素不可重复使用。
一旦一个线程调用 put 方法将元素添加到队列中,并被另一个线程调用 take 方法取走,该元素就会从队列中消失,不再可用于后续的操作了。这也是 SynchronousQueue 的一个特殊之处,使得它非常适用于需要高效、安全地将数据传递给另一个线程的场景。
因此,在使用 SynchronousQueue 时,需要特别注意线程的调度和同步问题,以免造成死锁或其他问题。