机器学习:决策树
一、决策树定义
1、决策树构成
根节点、内部节点、叶节点(终节点);

2、学习算法
决策树学习算法包含特征选择、决策树的生成与决策树的剪枝。
树的学习算法是 "贪⼼算法",从包含全部训练数据的根开始,每⼀步都选择最佳划分。依赖于所选择的属性是数值属性还是离散属性,每次将数据划分为两个或多个⼦集,然后使⽤对应的⼦集递归地进⾏划分,直到所有训练数据⼦集被基本正确分类,或者没有合适的特征为⽌,此时,创建⼀个树叶结点并标记它,这就⽣成了⼀颗决策树。
决策树的⽣成只考虑局部最优,决策树的剪枝则考虑全局最优。
3、特征选择
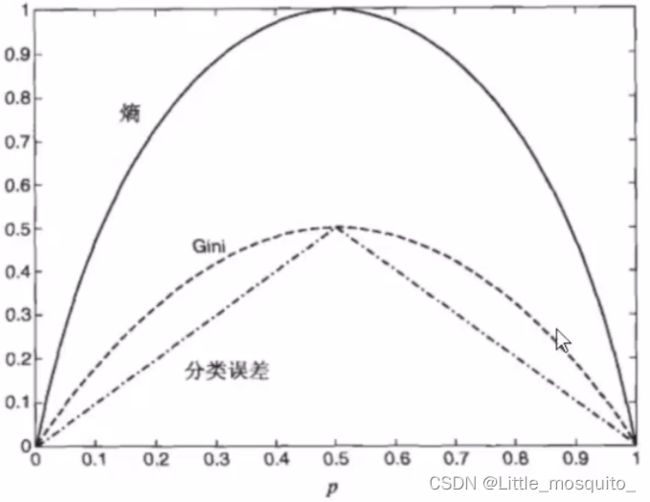
在分类树中,划分的优劣⽤不纯度度量定量分析。
度量不纯性的函数:熵函数(p为概率)


基尼系数:

二、手写代码
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
import numpy as np
import pandas as pd1、模型数据集
data = pd.DataFrame(
{'年龄':['青年'] * 5 + ['中年'] * 5 + ['老年'] * 5,
'有工作': ['否', '否', '是', '是', '否','否','否','是','否','否','否','否','是','是','否'],
'有自己的房子':['否','否','否','是','否','否','否','是', '是','是', '是','是','否','否','否'],
'信贷情况':['一般','好','好','一般','一般','一般','好','好','非常好','非常好','非常好','好','好','非常好','一般'],
'类别':['否', '否', '是', '是', '否','否','否','是', '是','是','是', '是','是','是','否']
}
)2、计算信息增益
# 定义墒函数:输入带标签的数据集,返回墒
def calEnt(data):
prob = data.iloc[:,-1].value_counts()/data.shape[0]
return -(prob * np.log2(prob)).sum()
# 计算信息增益
# 根据特征分裂(有自己的房子)
d1 = data[data["有自己的房子"] == "是"]
d2 = data[data["有自己的房子"] != "是"]
# 计算父节点、子节点信息熵
Ent_d = calEnt(data)
Ent_d1 = calEnt(d1)
Ent_d2 = calEnt(d2)
# 计算信息增益
calEnt(data)-(d1.shape[0]/data.shape[0]*calEnt(d1)+d2.shape[0]/data.shape[0]*calEnt(d2))3、最优特征的选择
# 上述计算分裂出节点的信息熵的代码,用groupby简化
data.groupby("有工作").apply(lambda x:x.shape[0]/data.shape[0]*calEnt(x)).sum()
# 封装函数:输入一个列数据,按数据集这一列进行划分,返回划分出子节点的信息墒
feature = "有工作"
def f(feature, data):
return data.groupby(feature).apply(lambda x:x.shape[0]/data.shape[0]*calEnt(x)).sum()
# 循环计算信息增益,选出信息增益最大的特征
all_info = []
for i in range(0, data.shape[1]-1):
feature = data.columns[i]
all_info.append(calEnt(data) - f(feature, data))
data.columns[all_info.index(max(all_info))]
# 封装函数:输入一个数据集,返回信息增益最大的特征
def bestSplit(data):
info = calEnt(data)- data.iloc[:,:-1].apply(lambda feature: f(feature, data))
return info.idxmax()4、树的生成
def createTree(dataSet):
# 终止条件
classlist = dataSet.iloc[:,-1].value_counts()
if classlist.values[0]==dataSet.shape[0] or dataSet.shape[1] == 1:
return classlist.idxmax()
# 确定出当前最佳切分列的索引
bestfeat = bestSplit(dataSet)
# 采用字典嵌套的方式存储树信息
myTree = {bestfeat:{}}
# 使用groupby.groups自动的来进行分组
df_groupby_dict = dataSet.groupby(bestfeat).groups
for best_col_values in df_groupby_dict:
sub_df = dataSet.loc[df_groupby_dict[best_col_values], :]
sub_df = sub_df.drop([bestfeat], axis = 1)
myTree[best_col_values] = createTree(sub_df)
return myTree三、sklearn算法实现
1、ID3算法
ID3算法的核⼼是在决策树各个结点应⽤信息增益准则选择特征,递归地构建决策树。
具体方法是:
- 从根结点开始,对结点计算所有可能的特征的信息增益;
- 选择信息增益最⼤的特征作为结点的特征,由该特征的不同取值建⽴⼦结点;
- 再对⼦结点调⽤以上⽅法,构建决策树;
- 直到所有特征的信息增益均很⼩或没有特征可以选择为⽌,最后得到⼀个决策树;
缺点:
- 分⽀度越⾼(分类越多)的离散变量⼦结点的总信息熵更⼩,按照此列切分,可能结果不是很好,如身份证号,这样的分类⽅式是没有效益的;
- 不能处理连续型变量,需要对连续变量进⾏离散化;
- 对缺失值较为敏感,需要提前对缺失值进⾏处理;
- 没有剪枝的设置,容易导致过拟合;
2、C4.5
修改局部最优化条件:
⽤信息增益⽐准则来选择特征。

连续变量处理:
输⼊特征字段是连续型变量,则算法⾸先会对 这⼀列数进⾏从⼩到⼤的排序,然后选取相邻的两个数的中间数作为切分数据集的备选点,若⼀个连续 变量有N个值,则在C4.5的处理过程中将产⽣N-1个备选切分点,并且每个切分点都代表着⼀种⼆叉树 的切分⽅案;

剪枝:
- 过拟合:模型的复杂度往往会⽐真模型更⾼,导致泛化性能下降;
- ⽋拟合:模型学习能⼒低下,对训练样本的⼀般性质尚未学好;
剪枝:指在去除部分叶结点,⽤来防⽌过拟合;
剪枝策略有:”预剪枝“、”后剪枝“;
- 预剪枝:在决策树⽣成的过程中,对每个结点在划分前先进⾏估计,如果当前的结点划分不能带来 决策树泛化性能(预测性能)的提升,则停⽌划分并且将当前结点标记为叶结点。
- 后剪枝:先训练⽣成⼀颗完整的树,⾃底向上对⾮叶结点进⾏考察,如果将该结点对应的⼦树替换 为叶结点能带来决策树泛化能⼒的提升,则将该⼦树替换为叶结点。
3、CART算法
分类回归树:
- ⼆叉递归划分:条件成⽴向左,反之向右;
连续变量:条件是最优分裂点;
分类变量:条件是若⼲类; - 预测变量x的类型既可以是连续型变量也可以是分类型变量;
分类树:Gini准则;
回归树:标准偏差减少; - ⽤于数值型预测时,并没有使⽤回归,⽽是基于到达叶结点的案例的平均值做出预测;
剪枝:
判断每个叶节点在验证集上的错误率,计算⼦节点总加权平均错误率并和⽗节点进⾏⽐较,若⼦节点总加权平均错误率高于父节点,考虑剪枝;
4、Sklearn下的决策树
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
# 导入数据集:乳腺癌数据集
from sklearn.datasets import load_breast_cancer
# 提取乳腺癌数据集
lbc = load_breast_cancer()
X = lbc["data"]
Y = lbc["target"]
# 拆分训练集、测试集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,Y,test_size=0.3,random_state=420)
# 训练模型
model = DecisionTreeClassifier()
model = model.fit(Xtrain, Ytrain)
# score评价模型很不严谨,很可能过拟合
model.score(Xtrain, Ytrain) , model.score(Xtest, Ytest)
# 使用训练好的模型,对训练集做交叉验证
# 取平均值从而展示模型在上面这些设置好的参数下,在未知数据集上的综合能力
cross_val_score(model, Xtrain, Ytrain, cv = 5).mean() 重要参数:最优参数一般通过交叉验证来寻找;
- splitter:默认是best:按信息增益最大的变量进行分裂;也可以设置成random:随机分裂;
错误认知:随机选择变量进行分裂;
正确认知:每个变量中随机选择一个分割点,再计算信息增益比; - min_samples_split:若样本量小于等于此值则不进行分裂;
- min_samples_leaf:设置叶节点最小样本量;
- min_impurity_decrease:不纯度的降低小于此值则不分裂;
- max_depth:树的深度;
# 预剪枝参数设置
model = DecisionTreeClassifier(max_depth = 4,
min_samples_split = 4,
min_impurity_decrease= 0.01)
# 几个变量分裂的信息增益完全相等,会随机选一个变量进行分裂
# 生成树的时候加个种子进去,树的结果就不会随机变化了
model=DecisionTreeClassifier(splitter='best',random_state=0).fit(Xtrain,Ytrain)
参数调优:
# 单个参数调优
# 对max_depth调优
tree_score = []
for i in range(1, 9):
model = DecisionTreeClassifier(max_depth = i)
model = model.fit(Xtrain, Ytrain)
tree_score.append(cross_val_score(model, Xtrain, Ytrain, cv = 5).mean())
# 汇总学习曲线
plt.plot(range(1, 9), tree_score)
# 网格搜索
from sklearn.model_selection import GridSearchCV
# 做网格:字典的形式,key为决策树的参数,值为一个范围,需要是数组的形式
d = {
"max_depth": list(range(1, 9)),
"min_samples_leaf": [*range(1, 15)],
"min_samples_split": list(range(2, 6)),
"class_weight": [None, "balanced"]
}
# 实例化:不用设定任何参数,网格搜索包会自动将字典中可能的组自动传入
model = DecisionTreeClassifier()
# 够造一个GS对象,只需要定义好的模型,参数字典,cv,模型评价标准
GS = GridSearchCV(model, d , cv = 5, scoring="accuracy")
# 可以直接把GS看成一个可以自动通过交叉验证的方式搜索最优参数一个决策树
GS = GS.fit(Xtrain, Ytrain)
# best_params_查看调整出来的最佳参数
GS.best_params_
# best_score_查看在最好的参数下,交叉验证中在测试集上最高的一个表现
GS.best_score_
# 最好的参数已经存到这个GS,这个已经是最好的一个决策树,直接可以用来做预测
GS.predict(Xtest)
决策树的可视化:
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['Simhei']
plt.rcParams['axes.unicode_minus']=False
import graphviz
dot_data = tree.export_graphviz(model,
out_file = None
,feature_names= feature_name
,class_names=["琴酒","雪莉","贝尔摩德"]
,filled=True
,rounded=True)
graph = graphviz.Source(dot_data)
graph重要方法与接口:
# predict:做预测
model.predict(Xtest)
# apply:显示叶节点的索引
model.apply(Xtest)
# predict_prob:输出每一个样本在各个标签类别下的概率值
model.predict_proba(Xtest)
# feature_importance:特征重要性
pd.DataFrame(model.feature_importances_, index = feature_name).sort_values(0)
四、分类模型的评估指标
1、样本不平衡问题
分类模型倾向让多数类更容易被判断正确,少数类被牺牲掉。对模型⽽⾔,样本量越⼤的标签可以学习的信息越多,会更依赖从多数类中学到信息进⾏判断;
当模型什么也不做,把所有结果都预测为多数类,准确率也⾮常⾼,则模型评估指标准确率将失去意义。如果我们希望捕获少数类,模型也会失败;
决策树中,调节样本均衡的参数:class_weight & 接⼝fit中的sample_weight;
class_weight:默认None,表示假设数据标签是均衡的,即⾃动认为标签的⽐例是1:1;
这时候剪枝,需要搭配min_ weight_fraction_leaf这个基于权重的剪枝参数来使⽤。基于权重的剪枝参数(min_weight_ fraction_leaf)将⽐不知道样本权重的标准(min_samples_leaf)更少偏向主导类;
代码:
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
# 模型数据集
class_1 = 1000 #类别1:1000个样本
class_2 = 100 #类别2:100个样本
centers = [[0,0], [2.0, 2.0]] # 两个类别的中心
clusters_std = [1.5, 0.5] # 两个类别的标准差
X, y = make_blobs(n_samples= [class_1, class_2],
centers= centers,
cluster_std= clusters_std,
random_state= 0, shuffle= False)
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = "rainbow",s = 10) # 画图看数据集
# 原始的决策树:不做平衡
model = DecisionTreeClassifier(max_depth= 4)
model = model.fit(X, y)
model.score(X,y)
# 新的决策树:做平衡
model = DecisionTreeClassifier(max_depth = 4, class_weight= "balanced")
model = model.fit(X, y)
model.score(X, y)2、混淆矩阵
现实中,单纯地追求捕捉出少数类,将会成本太⾼,⽽不顾及少数类,则⽆法达成模型的效果。实际中将在寻找捕获少数类的能⼒和将多数类判错后需要付出的成本做平衡。
模型评估指标:混淆矩阵,用来评估即能尽量捕获少数类,还能尽量对多数类判断正确的能⼒;

准确率:所有预测正确的所有样本除以总样本;

精确度(查准率):表示在所有预测结果为1的样例数中,实际为1的样例数所占⽐重。精确度越低,则代表我们误伤了过多的多数类。精确度是”将多数类判错后所需付出成本“的衡量;
做了样本平衡,精确度是下降的,有更多的多数类被误伤;

召回率(敏感度、真正率、查全率): 表示所有真实为1的样本中,被预测正确的样本所占的⽐例。召回率越⾼,代表我们尽量捕捉出了越多的少数类;

召回率和精确度的分⼦是相同的(都是11),只是分⺟不同。⽽召回率和精确度是此消彼⻓的,两 者之间的平衡代表了捕捉少数类的需求和尽量不要误伤多数类的需求的平衡。究竟要偏向于哪⼀⽅,取决于我们的业务需求:究竟是误伤多数类的成本更⾼,还是⽆法捕捉少数类的代价更⾼;
F1 measure:精确度和召回率的调和平均数,考量两者平衡的综合性指标,F1 measure在[0,1]之间分布,越接近1越好。
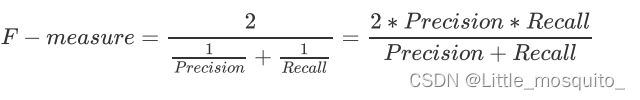
# 借助sklearn包直接画出混淆矩阵
from sklearn.metrics import confusion_matrix as CM
CM(y, model.predict(X))
# 借助sklearn包计算召回率与查准率
from sklearn.metrics import recall_score,precision_score,f1_score
# 不做平衡,计算召回率与查准率
model = DecisionTreeClassifier(max_depth= 4)
model = model.fit(X, y)
Ypred = model.predict(X)
recall_score(y, Ypred),precision_score(y, Ypred)
# 做平衡,计算召回率与查准率
model = DecisionTreeClassifier(max_depth= 4,class_weight= "balanced")
model = model.fit(X, y)
Ypred = model.predict(X)
recall_score(y, Ypred),precision_score(y, Ypred)
# 加上了weight之后,召回率上升了,但是这个过程中也误伤很多多数类,所以发现查准率下降
# 业务中,如果非常注重少数类,就需要选择recall分数高的模型
# 如果需要综合的判定,多数和少数类都不能误伤太多的话,选择f1-score最高的分数
f1_score(y, Ypred)
# sklearn.metrics.precision_recall_curve:精确度-召回率平衡曲线