背景
Impala是一个SQL on Hadoop的MPP查询引擎,由Cloudera主导开发并捐献给Apache软件基金会,在2017年底正式孵化成为Apache顶级项目。

如图,大数据领域里的OLAP系统种类繁多,它们各自有自己的特长和局限性,需要根据实际业务场景合理进行选择。存储方式往往决定了系统的能力和兼容性,跟据存储方式我们可以把它们分为三大类:
不存储原始数据,只保留聚合结果,如Druid、Kylin等
存储计算一体,自己实现存储层,如Greenplum、Clickhouse、Doris(原Baidu Palo)等
存储计算分离,依托HDFS、S3等实现存储层,这类系统又可以细分为两类:
使用自定义的文件格式,如HAWQ、VectorH等
使用开源文件格式,如Hive、Impala、Presto、SparkSQL、Drill等
第1类系统不保留原始数据,可以把性能做得很高,但由于聚合方式需要事先定义,比较适合报表类业务等查询模式相对固定的场景。当需要明细查询或交互式的灵活查询(Adhoc查询)时,仍需要另两类系统的加入才能支持。
第2类系统自己管理数据,可以做很多定制的优化,从而也能达到较高的性能。但由于数据没法与其它系统共享,往往需要将已有数据重新导入一次,在引入时需要考虑迁移成本以及多存一份数据的代价,因此一般在新建数仓中被考虑使用。第3.a类系统虽然依托外部存储,但因为采用封闭的文件格式,仍需要多存一份数据,其地位其实与第2类相同,常常在新建数仓时才被考虑。
使用最广的还是属于3.b类的系统,主要原因是基于Hadoop的数仓使用广泛,此类系统不需要重新生成一份数据,能与已有架构充分兼容。在此类系统中,Impala、Presto、Drill属于MPP(Massively Parallel Processing)系统,各节点流式地在内存中完成计算,中间数据几乎不落盘,相比Hive、SparkSQL等批处理系统能达到极高的性能。
在Hadoop生态圈的MPP系统中,Impala具有优异的性能,它的优势缘于:
C++实现,相比Presto、Drill等Java实现要更高效,也省去了Java GC的开销
基于LLVM的Code Generation,能根据实际数据类型生成高效的执行代码
CBO (Cost Based Optimizer),基于各表的统计信息得出代价最低的执行计划
缓存元数据,生成执行计划时不再需要和Hive、HDFS进行交互
RuntimeFilter,在运行时基于已读的小表数据裁剪大表需要扫描的数据量
Predicate/Aggregation Pushdown,虽然MPP系统都会有下推优化,但支持的程度各有不同,也依赖于底层文件格式的支持。Impala在Parquet存储格式上做了很多native的下推优化,如IMPALA-3654、IMPALA-4624 、IMPALA-4985、IMPALA-6113等。
Impala在Hulu的数仓中有很多应用,我们对Impala做了一些内核级别的开发和优化,希望能与大家共同探讨。
Impala内部原理
Impala集群由一台Catalog Server (简称catalogd),一台Statestore Server (简称statestore) 和若干 Impala Daemon (简称impalad)组成。自Impala 2.10之后,Impalad又可分为Coordinator或Executor两种角色。各服务的功能如下:
Statestore负责管理集群心跳和广播元数据更新。
Catalogd负责从Hive和HDFS拉取元数据并缓存下来,同时将元数据更新发给statestore进行广播。另外catalogd还负责执行建表、新建partition等DDL语句。
Impalad中的Coordinator也会缓存元数据,负责接收SQL查询请求并生成执行计划,并将执行计划的分片(PlanFragment)调度到各Executor去执行,最终汇总结果返回给客户端。
Impalad中的Executor则只负责PlanFragment的执行。
下图展示了一个SQL查询的执行过程:
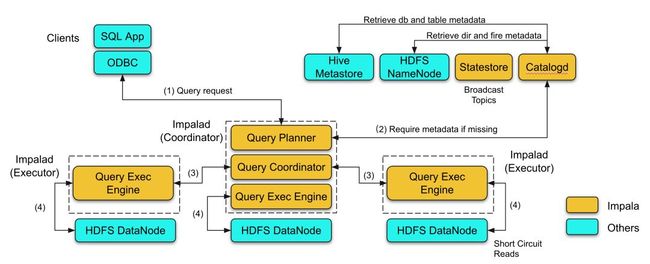
(1) 只有Coordinator角色的Impalad才会接收客户端请求。Coordinator对查询进行语法分析、语义分析。
(2) 语义分析中需要查询各表的元数据(元数据的具体内容见后文),如果在该Coordinator的元数据缓存中缺失,则会向catalogd请求加载。catalogd 会向Hive Metastore和HDFS NameNode查询所要的元数据,并将元数据的更新发送给statestore进行广播,从而所有Coordinator都会得到更新。
(3) Coordinator通过语义分析生成执行计划,并根据数据的本地性(locality)将Plan Fragment调度到各Executor去执行
(4) Executor从HDFS读取数据,并将PlanFragment实例的执行结果返回给上层结点,最终汇总到Coordinator得到最终结果。
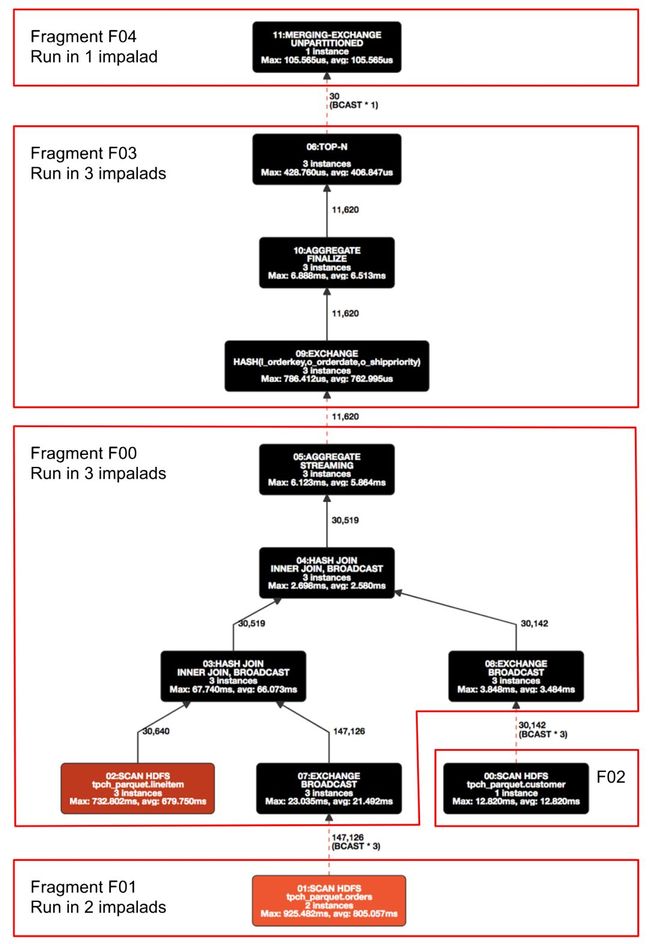
Impala的执行计划遵从Volcano的Iterator模型,是由若干PlanNode组成的执行计划树,叶子节点读取外部数据并传输给上层节点做下一步处理,最终在根节点汇总。
Iterator模型使得整个查询可以最大限度地流式进行,从而降低了查询的延迟。Volcano模型的另一大贡献是引入了Exchange节点,使得执行计划可以划分为不同的分片,各自采用合适的并行度去执行。
如图是TPC-H Benchmark中Query3的执行计划,根据是否需要broadcast、shuffle等被切分成几个PlanFragment。每个Executor执行的就是Plan Fragment的实例。
Hulu对Impala的改进
1. 增加对ORC文件格式的支持
ORC是一种列式存储的文件格式,由Hortonworks主导开发,而Cloudera主推的是Parquet。因此在Cloudera和Hortonworks宣布合并之前,Impala并没有支持ORC的计划。由于历史原因,Hulu的Hive数仓中大量使用了ORC存储格式,为了引入Impala,我们决定对它进行内核级的修改,让其支持ORC存储格式。我们分两步走,第一步先实现基本类型(primitive types)的支持(IMPALA-5717),第二步再增加了嵌套类型(struct、array、map)的支持(IMPALA-6503)。这两部分工作均已贡献给社区,impala在2.12及3.1版本开始支持读取ORC文件中基本类型的列,在3.2版本支持读取ORC文件中嵌套类型的列。
这部分工作的核心是实现一个HdfsOrcScanner,因为Query执行的大部分逻辑如语法分析、语义分析、调度等基本可以复用已有的实现,唯独最终解析ORC文件这块需要专门的实现。前面我们介绍过了Impala的执行计划树,树的叶子节点都是ScanNode。每个ScanNode的实例负责读取若干个数据分片(split),每个split由一个Scanner线程去处理。如下图所示,编号02的HdfsScanNode有14个实例,分别运行在14个Executor上。每个实例会启动若干个Scanner线程来读取split。
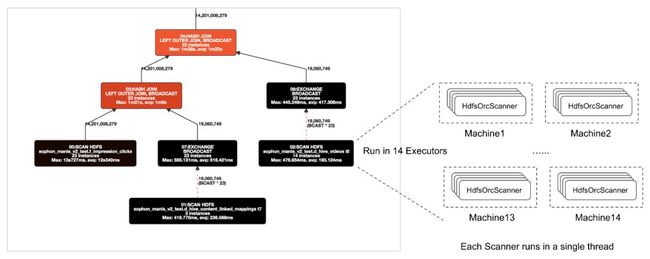
Impala支持的所有HDFS文件格式(如Parquet、Avro、SequenceFile、RCFile、Text等)都有一个对应的scanner实现,为了支持ORC,我们同样要实现一个HdfsOrcScanner。
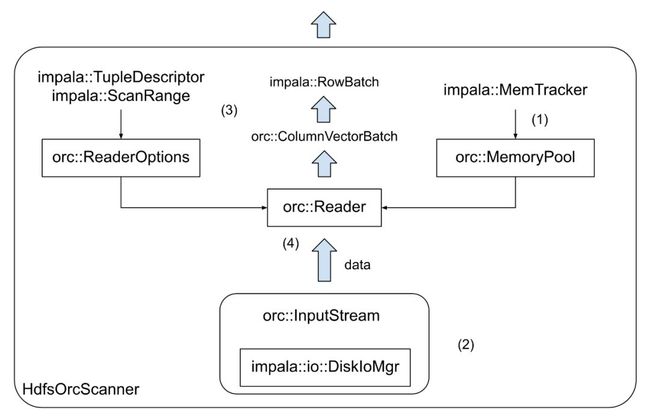
上图是HdfsOrcScanner的内部结构,主要可分为以下几方面:
(1) Impala如何管理内存:Impalad会追踪每个查询占用了自己多少内存,超过阈值的查询会被kill掉。HdfsOrcScanner的内存管理要遵从既有的流程,从而让impalad能正确统计内存占用量(通过impala::MemTracker)。
(2) Impala如何读取数据:Scanner并不需要真正读取HDFS上的数据,Impala把IO读取封装成了DiskIoMgr。ORC文件的读取并不是从头读到尾,而是先解析文件尾得到元信息,然后跳到每个Stripe(行组)中读取所需的列。每个Stripe的读取又要先解析Stripe尾部的元信息。这些都要求Scanner正确地与DiskIoMgr进行交互,避免无用的IO。
(3) Impala如何表示数据:不管底层文件是列存还是行存,Scanner都会将其物化(materialization)成为内存中按行存放的Tuple,若干个Tuple组成RowBatch返回给ScanNode。每个Tuple包含了一行中被选择的各列数据,具体的样子由TupleDescriptor进行描述。Scanner需要理解TupleDescriptor,并将ORC数据物化成所需的Tuple。这块的工作比较细,比如需要考虑Tuple所引用的内存空间的生命周期管理、TupleDescriptor所要的列在ORC文件中是否存在及是否兼容、遇到正常中断(如被cancel或达到limit)或解析异常时的处理等。
(4) 如何解析ORC格式的文件:ORC Reader已经有C++版的官方开源实现,我们直接将其封装在HdfsOrcScanner里即可,主要的工作是把前3个层面封装成ORC Reader的参数或输入,并解析ORC Reader的输出。在集成ORC Reader(属于ORC library)的过程中,我们还发现并修复了一些bug,详见ORC-311、ORC-312、ORC-313、ORC-314、ORC-317、ORC-403。
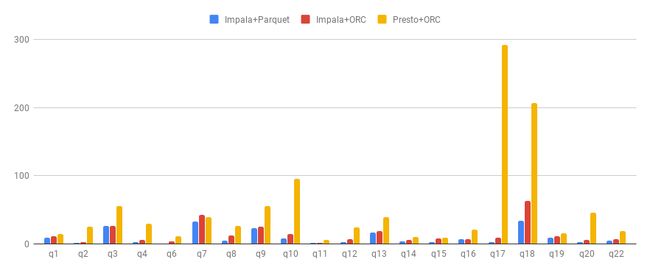
上图对比了Impala on Parquet、Impala on ORC、Presto on ORC在TPC-H基准测试中的20个查询的耗时(单位:秒)。可以看到Impala on ORC的性能虽然比不上Impala on Parquet,但相比Presto on ORC还是有很大的优势。Impala的ORC scanner还有很多优化可做,比如支持Aggregation Pushdown、结合ORC文件的统计信息来减少无用IO、使用DiskIoMgr的异步IO接口等,理论上应该能达到与Parquet scanner相近的性能。关于后续的工作,欢迎关注IMPALA-6505、IMPALA-6636、IMPALA-8046等相关JIRA。
2. 自动刷新元数据
Impala缓存了Hive中各表的元数据,包括列的定义、partition的位置和权限、HDFS文件的信息(大小、权限、复本位置等)。这些信息从Hive Metastore (HMS)和HDFS NameNode (NN)得来,当查询再次访问相同的表时,Impala可以利用缓存的元数据直接生成执行计划并开始执行,省去了对 HMS和NN的多次交互。
这是Impala元数据层的设计初衷,确实加速了查询性能,也降低了对HMS和NN的访问压力,但因此引入了两个非常不友好的语句: "INVALIDATE METADATA"和 "REFRESH"。
当Hive中的表有更新时(如新增partition或重新覆盖了原表数据),Impala并不能自动感知,需要用户手动执行 "REFRESH tableName"语句来刷新元数据缓存。如果在Hive中建了一个新表,还需要在Impala中执行 "INVALIDATE METADATA tableName"来通知Impala这个新表的存在。如果没有及时操作,对应表上的查询基本都会挂掉。
为了将Impala无缝引入我们已有的Hadoop数仓,我们需要将元数据刷新自动化。如图所示,我们搭建了一个pipeline,当Hive中的表有更新时,Hive MetaStore会记下一条audit 日志。Audit collector将其发送到Kafka,然后被一个Flink job消费,触发Impala刷新缓存。
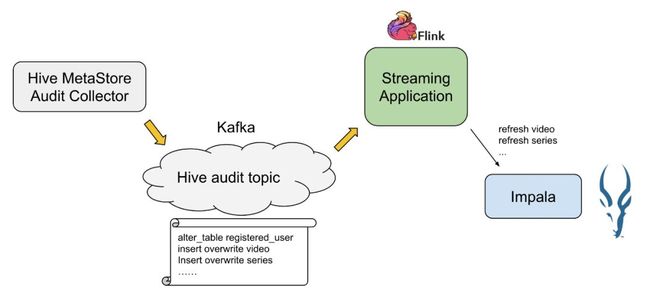
这条pipeline可以达到秒极延迟,但维护起来还是有点麻烦。幸运的是,Impala在3.2版本引入了自动刷新元数据的功能(IMPALA-7970),将来也会merge到2.x的版本中去。自动刷新元数据的功能还有许多细化的工作,具体见IMPALA-7954。这部分工作是Cloudera和Hortonworks合并之后才开始的,还处于起步阶段,大家可以关注一下。
3. Built-in的get_json_object函数
get_json_object是Hive中一个处理JSON字符串的函数,用于抽取JSON中的指定内容。Impala中并没有该函数的native实现,我们需要将Hive中实现该函数的Java类定义成Impala的UDF才能使用。在低版本的Hive(apache版本小于2.3或cdh版本小于5.12.0)中这个函数有内存泄漏的bug(HIVE-16196),而且Impala目前还没法追踪各查询在JVM里所占用的内存,我们的Impala集群曾因此遭遇了OOM。为此我们实现了native的get_json_object函数,并贡献给了社区(IMPALA-376)。
总结
Impala是SQL-on-Hadoop中一个高性能的MPP查询引擎。本文简要介绍了Impala的内部原理,以及Hulu在实际应用中对其做的一些优化和改进,包括增加对ORC文件格式的支持、外围的自动刷新元数据框架、支持native的JSON处理函数等。
大家在使用Impala中遇到的任何问题,欢迎加入Impala技术交流群与我们探讨!同时也欢迎加入Impala社区的SlackChannel(文末有链接)!