linux MMU以及初始化过程内存布局
本文以linux-3.14.17(arm)版本的代码来讲述linux从第一行代码运行至start_kernel()的过程。
arch/arm/kernel/vm-linux.lds
链接脚本定义了kernel image各段的分布,以及定义了一些全局符号,如下图:

这个链接脚本同时定义了入口符号stext.

stext定义在arch/arm/kernel/head.S

92行safe_svcmode_maskall做了些什么?
arch/arm/include/asm/assembler.h

274行,读取cpsr寄存器到r9;
278行,设置r9中cpsr的值中的I,F位(禁IRQ, 禁FastIRQ),并设置mode为svc模式,即特权模式。
283行,将修改后的r9寄存器中的值写回到spsr寄存器。
286行,将修改后的r9寄存器值写回到cpsr,即此时当前cpu进入了svc模式,且禁IRQ, 禁FastIRQ.
我们回到head.S中继续看safe_svcmode_maskall后面的代码。

366行,通过协处理器cp15,获取当前cpu的processor id,并保存在r9中。
367行,跳转到__lookup_processor_type。
arch/arm/kernel/head-common.S

153行,r3保存__lookup_processor_type_data的地址
154行,将__lookup_processor_type_data地址处的数据,分别加载到r4, r5, r6中。
我们在编译kernel image的时候,设置了LC为0xC0008000,即3G以上的地址空间。
arch/arm/kernel/vm-linux.lds

所以,image里面的virtual address(虚拟地址)都是3G以上的。而程序的执行实际上和LC设置的不一样。下面是uboot跳转内核前的打印:
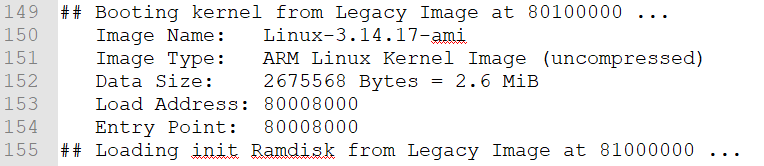
从uboot的打印可以看出来,内核image时被加载到0x80008000地址处了。
故155-157这几行是将__lookup_processor_type_data数据段中保存的原虚地址值修正为实际上的物理地址physical address。
158-161行,遍历proc_info_list,找出r9(processor id)中对应的proc_info, 找到了,则返回。如果没有对应的proc_info,则r5置为0,然后返回。
我们回到head.S中,继续看代码。

如果__lookup_processor_type不能找到processor id对应的proc_info,则r5为0,98行跳转到__error_p出错处理。
我们继续…

2f标号处的数据段,定义了一个数据0xC0000000.
109-112行就是计算虚拟地址和运行地址的偏差,然后修正r8中的PAGE_OFFSET的值为实际的运行地址(物理地址)。
所以,此时r8中保存的不再是虚拟地址0xC0000000(3G), 而是它(0xC0000000)对用的实际的物理地址。
我们继续看代码…

uboot在跳转到内核时,将DTB(device-tree-binary)文件拷贝到内存,并将该内存地址通过r2寄存器传递过来。
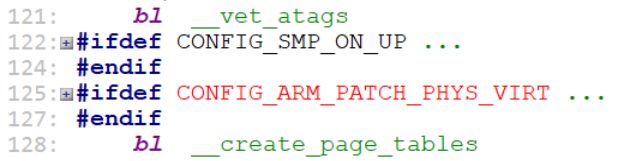
121行,跳转到__vet_atags来处理这个DTB。
arch/arm/kernel/head-common.S

47-48行,检查dtb地址是否4字节对齐。
下面的代码也是检查dtb中的数据是否正确。
最后返回(64行),如果地址没对齐,或数据检查不正确,则从67行返回,同时,设置r2为0.
我们回到head.S.
128行,直接跳转到__create_page_tables去创建临时页表,为开启MMU准备。

__create_page_tables调用pgtbl,将r4指向r8 + 16K处的内存,用作MMU段式地址转换的first level descriptor.
pgtbl是个宏,定义如下:

169行-178行,将r4后面的16K的内存清零。效果如下:

继续看__create_page_tables的代码…

208行,r10指向.proc.info.init段中processor id对应的Proc_info,假如我们的是v6, 那么,对应的proc_info定义在arch/arm/mm/proc-v6.S

208行就是将__v6_proc_info中276行的值赋给r7寄存器。
214-220行,取出__turn_mmu_on_loc的实际运行地址处存放的__turn_mmu_on和__turn_mmu_on_end符号的虚拟地址(连接脚本决定lds),并修正为当前运行的实际物理地址(连接地址和实际加载地址存在offset),然后计算其对应的物理内存段(每段1M),这样r5 | r7就构成了将要设置的MMU段式映射的first level descriptor中__turn_mmu_on的entry。
arm的MMU的地址映射分为段式和页式,段式只有一级,页式有两级页表,如下:

第一级描述符entry的最后两个bits为0b10时为段式映射,entry中的base为物理内存段基地址。如果最后两个bits为0b01时,为页式映射,第一级entry中的base为第二级页表的物理地址。
arm linux在开始的时候使用段式映射来启动内核。
第一级描述符的结构如下:

结合代码中r7寄存器的值可知,最后两个bits的值为0b10, 且没有设置bit18,即bit18 = 0,所以这时候设置的为1M的段式映射。
我们继续看代码,来佐证上述的描述。

222行,此时r5保存的是__turn_mmu_on实际物理地址的高20bits数据(即物理内存的段号,1M1段),这里将__turn_mmu_on地址的高20bits还原会bit31-bit20, 然后和r7进行或运算,构成第一级描述符entry,并写回对应的第一级描述符entry处。从这里看出来,__turn_mmu_on地址采用了平射,即虚地址1映射物理地址1.
我们继续看代码…

231-238行将从内核加载处的地址(0x80000000)开始的内存增加对应的段式映射的第一级描述符表项。
231行,r0指向内核镜像起始虚拟地址(3G)处对应的段式映射第一级描述表项。
232行,r6为内核镜像image的结束地址(虚拟地址, 3G + X)
233行, 内核被加载到的实际物理内存地址(r8) | r7
234行,r6指向内核image的结束地址(虚拟地址)对应的段式映射的第一级描述符表项,即内核image 3G – X的段式映射的描述符范围为r0 – r6, 当建立好了段式映射,那么3G就是对应内核image当前的加载地址0x80000000。这里为什么是r6 >> 18? 正常计算时,_end对应的表项为r4 + _end的bit[31:20],即r4 + (addr(_end) >>20) * 4(描述符表项为4bytes),这就相当于r4 + addr(_end) >> 18了。
235-238行,循环将整个内核image的当前加载地址构筑到段式映射的表项中,这样,开启MMU后,就可以使用连接脚本定义的起始虚拟地址0xC0000000来跑内核了。
好了,我们继续看后面的代码…

263-264行,保留dtb地址的段号(多少M),bit31-bit20保留到r0
265行,dtb的物理地址和内核image加载地址的offset,
266行,计算dtb的虚拟地址offset + 3G,dtb的虚地址保存到r3
267行,计算dtb对应的段式映射的第一级描述符表项位置,并将表项位置保存到r3
268行,r0 | r7构成dtb的一级描述符表项entry的值。
269行,将r0 | r7写入dtb虚地址对应的一级描述符表项
270-271行,多写一个表项,是为了应对dtb跨两个段。
到这里,我们的临时段式映射的一级描述符的表项构建完成。

下图展示的是内存的布局,以及以及描述符表项以及映射关系。

程序在339行,返回到stext中继续执行。

137行,指令ldr r13, =__mmap_switched, 加载r13为__mmap_switched的链接地址(虚拟地址)。这里说明一下,adr和ldr的区别,adr取的地址是pc+offset,它拿的可是实际的加载到的内存的地址,而ldr拿到的是链接脚本中指定的地址,这个地址不一定存在(虚地址),需要映射到实际的加载到的内存的地址才能使用。
140行,r4寄存器在__create_page_tables时设置为段式映射的一级描述符表的基地址,这里保存到r8,用于后面__v6_setup时设到TTBR1中(os, i/o)。
141行,跑去执行proc_info中的initfunc。对于v6,即“b __v6_setup”
144行,跳转到__enable_mmu。
再进入__enable_mmu之前,我们先来看一下141行的__v6_setup做了什么,这关系到后面的enable mmu。
arch/arm/mm/proc-v6.S


218行,将段式映射的一级表基地址加载到TTBR1(TTBR0为mcr p15, 0, r8, c2, c0, 0)
222行,取v6_crval的地址。
223行,取出v6_crval地址处的数据,依次赋给r5,r6,那这个v6_crval处保存了什么数据?

arch/arm/mm/proc-macro.S

从上述代码片段可知,v6_crval处定义了两个word,一个为0x01e0fb7f (clear),另一个为0x00c0387d (mmuset), 所以,r5为0x01e0fb7,r6为0x00c0387d。
225行,取控制寄存器的值,保存到r0,
226行,清除控制寄存器拷贝r0中的r5表示的掩码中bit为1的位。


227行,设置控制寄存器拷贝r0中的r6掩码中bit位为1的bit, 即M = 1,如果生效,则MMU enable了。
244行,返回。
故,__v6_setup设置了控制寄存器的拷贝r0中的M位,只要将r0赋值给控制寄存器,则MMU马上就enable了。
接着,我们来看__enable_mmu.

429行,disable d-cache
435行,disable I-cache
443行,设置TTBR0为r4,即设置以及描述符表地址。如果是TTBR1,则应该是”mcr p15, 0, r4, c2, c0, 1”。这里将TTBR0也设置了一下,可以理解为是给INIT_TASK用的。
ARM中,保存/设置一级描述符表基地址的有两个寄存器,分别为TTBR0和TTBR1。TTBR0为进程专用的;TTBR1为内核,IO等特权使用。


445行,跳转到__turn_mmu_on。这个时候,虽然设置了mmu段式映射的一级描述符表项,但是还没有enable mmu,所以还是运行在实地址模式。
我们接着看__turn_mmu_on.

467行,将r0寄存器中的值写入控制寄存器,由于之前__v6_setup的时候,我们设置了mmu 使能位为1,这里写入了控制寄存器后,MMU就开始工作了。由于之前我们设置MMU段式映射一级描述符表的时候,将__turn_mmu_on到__turn_mmu_on_end做了平映射,所以467行开始MMU后,它的下一条指令的地址还是映射到了468行,这个平映射直到474行为止。

471-472行,将PC设置为r13,前面我们说过r13保存的是__mmap_switched的虚拟地址,故472行后,pc指向了一个虚拟地址,这个虚拟地址经过段式映射后,映射到__mmap_switched的加载内存地址处。
这样,pc就进入了虚地址空间了,后面的内存访问(指令和数据),就都是虚地址空间了。
我们接着来看__mmap_switched.
arch/arm/kernel/head-common.S

81行,加载__mmap_switched_data的地址到r3,由于pc已经处于虚地址空间了,故r3拿到的地址也是虚地址空间的地址。__mmap_switched_data保存的是栈内存虚地址,bss虚地址,__mmap_switched_data定义的数据如下:

86行,将栈帧指针fp指向__data_loc的,r4 += 4
87行,将栈帧指针fp存储的地址,保存到_sdata处,r5 += 4
88行,循环85-88行,直到r5 == r6, 此时,fp指向__data_loc+(__bss_start - _sdata)
90行,将栈帧指针设为0.
91-93行,循环,将bss段内存清零。
我们接着看下面的代码:

97行,将栈指针sp指向init_thread_union + THREAD_START_SP处
98行,保存processor id到.long processor_id指示的内存位置(__mmap_switched_data中的.long processor_id指示的位置)
99行,保存machine type到.long __machine_arch_type指示的内存位置
100行,保存dtb指针到.long __atags_pointer指示的内存位置
104行,跳转到start_kernel处执行。
好了,我们终于来到了第一个C函数start_kernel()处了。这个时候,内存布局视图如下:

下面,我们继续看start_kernel()之后的有关内存和MMU的操作。
init/main.c
start_kernel() -> setup_arch()
arch/arm/kernel/setup.c(代码有删减)

setup_arch()首先调用setup_machine_fdt去解析DTB数据,并把实际物理内存的所有bank都解析到了meminfo中。
890行,调用sanity_check_meminfo(),对内存bank排序,并将系统内存物理地址高于760M的bank标记为高端内存(high_mem),低于760M的则标记为低端内存(low_mem)。
arch/arm/mm/mmu.c

回到setup_arch(),891行,setup_arch()调用arm_memblock_init().
arch/arm/mm/init.c


![]()
arm_memblock_init()将系统内存全部放入memblock来管理,memblock.memory用来管理可用内存,memblock.reserved用来管理已经被reserved的内存。memblock内存分配的原理是从memblock.memory中找出一段未被reserve的内存来分配使用。
之后,reserve内核镜像占据的内存(这个属于先上车后补票了),reserve initrd内存。319行调用arm_mm_memblock_reserve()来reserve内核空间页表所占据的内存。
arch/arm/mm/mmu.c

reserve完页表内存后,调用arm_dt_memblock_reserve()将DTB(device-tree data)占据的内存给reserve掉。最后,调用dma_contiguous_reserve()从760M内存往下分配一块可用的内存给DMA,大小为系统总内存的%10(依赖于自己的配置).
做完后,我们回到setup_arch().
893行,调用paging_init()去初始化页映射页表,前面我们介绍的是临时用的段式映射描述符表的构建,linux内核是使用页式映射的。
arch/arm/mm/mmu.c

arch/arm/mm/mmu.c


1200-1201行,清除TTBR1指向的一级描述符表中虚地址0 ~ (3G-8M)对应的表项,MODULES_VADDR为(3G – 8M),PMD_SIZE为2M,如下:
arch/arm/mm/mmu.c
![]()
arch/arm/include/asm/pgtable-2level.h

pmd_off_k()拿到的是虚地址对应的一级描述符表项:
arch/arm/mm/mm.h

arch/arm/include/asm/pgtable.h

init_mm.pgd指向swapper_pg.dir.
mm/init-mm.c

swapper_pg.dir这个就是前面构建的段式映射的一级映射描述符表的基地址:
arch/arm/kernel/head.S

KERNEL_RAM_VADDR为内核虚地址3G+32K, PG_DIR_SIZE为16K,所以swapper_pg_dir = 3G + 32K -16K = 3G + 16K, 就是第一次创建page table时指定描述符表物理基地址的r4寄存器对应的虚地址。即swapper_pg_dir指向段式映射的一级描述符表的基地址。
pdg_index(addr) = addr >> 20 >> 1 = addr >> 21,多向右移一位是因为pmd_clear()的时候,一次clear两个表项。
回到pmd_off_k()看其他的函数:
arch/arm/mm/mm.h

arm不使用pud,故
include/asm-generic/pgtable-nopud.h

pmd_offset如下:
arch/arm/include/asm/pgtable-2level.h
最后,prepare_page_table()中调用的pmd_clear(),定义如下:
arch/arm/include/asm/pgtable-2level.h

pmd_clear()一次清除2个表项。
我们回到prepare_page_table()中
arch/arm/mm/mmu.c
![]()

1207-1208行清除3G-8M ~ 3G这段虚地址对应的一级描述符表项。
1221-1223行,清除memblock.memory.regions[0].end ~ VMALLOC_START在一级描述符表中的表项。内核image是驻留在memblock.memory.region[0]中的,这里清除的是除它之外到VMALLOC_START为止的所有内存映射。所以,内核指令还是能get到的。
物理地址转虚拟地址(__phys_to_virt)的方式是:当前内存地址 – 内存起始地址 + 3G。

好了,到这里,prepare_page_table()结束了,主要是清除0-3G这段虚地址对应的一级描述符表项,同时清除arm_lowmem_limit ~ VMALLOC_START对应的一级描述符表项。
程序返回到paging_init()
arch/arm/mm/mmu.c

1515行,调用map_lowmem()映射低端内存。
map_lowmem()建立低端内存(low_mem)以下的内存的页映射的二级页表项(包括内核镜像本身占据的内存)。即物理内存 0 ~ low_mem_limit映射到3G ~ 3G + low_mem_limit




map_lowmem()是通过create_mapping()去建立页映射表项的。
上述代码片段中.prot_l1为一级描述符表项的属性,PMD_TYPE_TABLE表示是页映射。

这里有一个疑问,当重写内核镜像的段式映射页表为页式映射时,内核指令地址是否还能正确翻译?
答案是可以的,当执行复写内核镜像指令对应的页表时,先前的TLB缓存了段式映射的内存,可以缓存8个entries,即可以缓存8M的地址转换。

复写内核页表的操作是在一个while循环中进行的,指令大小不可能超过8M,当执行完第一轮的页表写操作,这些指令的地址转换就被缓存到TLB中了,后续的循环写页表,地址转换不会访问页表内存,TLB直接转换了。

之后,调用dma_contiguous_remap()映射dma内存。
映射dma内存后,将dma对应的虚拟地址空间加到vma_list中,并打上IOREMAP的flag.
dma_contiguous_remap() -> iotable_init()
arch/arm/mm/mmu.c

devicemaps_init()映射异常向量表到0xFFFF0000, 大小4k,并调用pci_reserve_io()去reserve pci_io虚拟地址空间(0xfee00000, 2M), 即挂到vma_list.
arch/arm/mm/mmu.c


从这里看出,到目前为止,我们地址映射信息都是写在swap_pg_dir页表中,这个页表由TTBR1加载。而进程使用的TTBR0还没有出现。
此时,内存的布局如下:

我们接下来看,系统第一个进程init_task.
start_kernel() -> sched_init()
kernel/sched/core.c

![]()

这里的init_task是系统的第一个进程,init_mm是它的mm。
init/init_task.c
![]()
include/linux/init_task.h

mm/init-mm.c

init_task.active_mm.pgd = swapper_pg_dir,可见,系统第一个进程的mmu地址映射表的基地址就是前面构建的页表。
下面介绍用户进程和TTBR0相关的页表使用。
此后,如果我们调用fork系统调用创建新的进程,则
do_fork() -> copy_process() -> copy_mm()


879-882行,表示新进程共享父进程的mm。fork()时,就是这样,子进程共享父进程的mm,直到exec()之后。
新进程task->mm会调用dup_mm()来构建, 且mm和active_mm都指向新构建的mm

dup_mm()调用mm_init(), mm_init()再调用mm_alloc_pgd(),来申请该进程的地址映射表基地址。


所以,每个进程有它自己的地址转换映射表task->mm->pgd. 这个是进程特有的,会写入TTBR0寄存器,它用于0 – 3G的虚地址映射。而3G – 4G的虚地址映射的pgd由TTBR1保存。
最后,我们来看以下进程切换时候这个虚地址到实地址转换的描述符表的切换。
schedule() -> __schedule() -> context_switch() -> switch_mm() -> check_and_switch_context() -> cpu_switch_mm()
arch/arm/include/asm/mmu-context.h

cpu_switch_mm()就是processor.switch_mm()
arch/arm/include/asm/proc-fns.h

![]()
那么,这个processor.switch_mm()是什么呢?
对于v6而言,其proc_info的定义如下:
arch/arm/mm/proc-v6.S

296行定义的就是v6的processor变量的符号地址。
这个v6_processor_functions定义在这:
arch/arm/mm/proc-v6.S

arch/arm/mm/proc-macro.S

那processor变量如何关联到这个v6_processor_functions呢?
setup_arch() -> setup_processor()
arch/arm/kernel/setup.c


所以,processor.switch_mm() 就是v6_processor_function中的cpu_v6_switch_mm.
我们接着来看看cpu_v6_switch_mm是怎么做的…
arch/arm/mm/proc-v6.S

107行,加载r0到TTBR0(process specific), 这里的r0就是新进程的pgd, 即task->mm.pgd. 这样就完成了进程页表(用户空间)的切换了。(task->mm.pgd指向的是用户空间的MMU表基地址)
注意,对于3G-4G的内核空间的地址映射,其转换表基地址是存在于TTBR1中,且由于这个空间是所有task共享的,故进程切换不涉及TTBR1,即TTBR1用于指向init_mm.active_mm.pgd(指向swapper_pg_dir)
前面,我们提过,当我们使用fork()创建子进程时,子进程是共享父进程的mm,这时,子进程的代码和数据空间,和父进程是一样。我们用fork()来创建进程后,通常都会使用exec族函数来加载和执行子进程自己的程序。
do_execve() -> do_execve_common() -> exec_binprm() -> search_binary_handler() ->
search_binary_handler() 调用fmt->load_binary()。对于elf文件,这个fmt->load_binary()就是load_elf_binary().
load_elf_binary() -> flush_old_exec() -> exec_mmap()
fs/exec.c


exec_mmap()的参数mm就是新elf程序的mm。
848行,activate_mm() -> switch_mm(),进程了页表的切换。
子进程切换到新页表后,访问内存时,当内存不实际存在时,会触发缺页异常。
ARM处理器的异常处理表的地址是0Xffff0000. 所以这个地址处需要放置异常向量表:

如果是实地址模式,则实地址0xffff0000处的内存要放置异常向量表。
如果开启了MMU,需要将0xffff0000映射到的地方放置异常向量表。
start_kernel() -> setup_arch() -> paging_init() -> devicemaps_init()
arch/arm/mm/mmu.c


1270行,给异常向量表分配2页物理内存,返回的是对应的虚拟地址va。
1272行,将异常向量表拷贝到这2页内存(虚地址都有正确的映射)
arch/arm/kernel/traps.c
![]()

1312-1320,将异常向量表重新映射到0xffff0000。
这里__vectors_start就是arm的异常向量表的起始处。
arch/arm/kernel/entry-armv.S

1138行,定义了数据异常跳转: b vector_dabt
1140行,定义了irq跳转:b vector_irq
vector_dabt定义:
arch/arm/kernel/entry-armv.S

vector_stub是个宏,定义为:
arch/arm/kernel/entry-armv.S


所以,对于用户空间发生的异常,进入__dabt_usr
arch/arm/kernel/entry-armv.S

而内核空间发生的异常,进入__dabt_svc.
arch/arm/kernel/entry-armv.S

__dabt_usr和__dabt_svc都进入dabt_helper.
arch/arm/kernel/entry-armv.S

74行,ip指向processor.
arch/arm/kernel/entry-armv.S

76行, [ip, #PROCESSOR_DABT_FUNC]就是v6_procssor_functions
arch/arm/mm/proc-v6.S
v6_processor_functions定义:
arch/arm/mm/proc-v6.S
![]()
arch/arm/mm/proc-macro.S

所以,dabt_helper最终就是进入v6_early_abort处理。
arch/arm/mm/abort-ev6.S

v6_early_abort最后进入了do_DataAbort()处理。
arch/arm/mm/fault.c
551行, inf->fn()在exception_init()时注册一部分,还一部分是静态的。
arch/arm/mm/fault.c


arch/arm/mm/fsr-2level.c

对于缺页异常,do_DataAbort()进入do_translation_fault()
arch/arm/mm/fault.c

对于异常地址是用户空间的,则调用do_page_fault(),我们只分析这种情况。