VIT、CILP、Swin Transformer、MAE模型论文阅读笔记
本博客针对视觉Transformer方面的工作,对当前热点研究做一下总结。主要是VIT、Swin Transformer、MAE、CILP 这四篇。有一句话说的很有道理,因此放在这篇博客最前面。为什么NLP领域的预训练模型很好用,但是图像领域的预训练模型就很一般?这因为我们在NLP领域中找到了非常棒的 pretext task (代理任务),比如回想一下bert,我们需要理解一句话的意思,知道语义信息,那么我们把其中一个词遮住,如果我们真的搞懂了这句话的意思,搞懂了语义信息,把这块补出来这是非常简单的。但是目前对于图像的 pretext task 还有很大的改进,我们没有找到适合图像信息的 pretext task ,即使和NLP一样遮住图像某一块信息,这对于我们人类来说,都很少去做这种的题目吧,所以这就导致了图像的预训练模型是比较差的。
VIT(用于图像分类)
ViT(vision transformer)是Google在2020年提出的直接将transformer应用在图像分类的模型,后面很多的工作都是基于ViT进行改进的。
ViT的思路很简单:直接把图像分成固定大小的patchs,然后通过线性变换得到patch embedding,这就类比NLP的words和word embedding,由于transformer的输入就是a sequence of token embeddings,所以将图像的patch embeddings送入transformer后就能够进行特征提取从而分类了。

整体思路比较简单,但是有几个有意思的点要明确:
为什么小数据时CNN效果要好于VIT,大数据时VIT效果更好一些?
传统的CNN卷积神经网络有很强的inductive biases(归纳偏置),是根据图像的本质而设计的一种网络,比如卷积核的平移不变性和局部性。因此在小数据时,VIT学不到这些,自然效果就不好,但是数据多起来后,就不太需要针对图像特意去设计这些小tips了。
混合架构
作为原始图像图块的替代,可以从CNN的特征图形成输入序列。在该混合模型中,将patch embedding投影应用于从CNN特征图提取的图块。(即,将图像块先经过CNN网络,然后将CNN的网络输出的特征矩阵输进Transformer中,这样也是可以的,论文有尝试过)
位置信息
Transformer和CNN不同,需要position embedding来编码tokens的位置信息,这主要是因为self-attention是permutation-invariant,即打乱sequence里的tokens的顺序并不会改变结果。如果不给模型提供patch的位置信息,那么模型就需要通过patchs的语义来学习拼图,这就额外增加了学习成本。但是CNN是滑动的,是本身就具有位置信息的。所以在使用VIT时要手动加上位置信息。论文中试验过使用1-D和2-D的位置信息效果差不多。
微调和更高的分辨率
通常,我们在大型数据集上对ViT进行预训练,并微调到(较小的)下游任务。为此,我们删除了预训练的预测head,并附加了一个零初始化的D*K的前馈层,其中K是下游类的数量。以比预训练更高的分辨率进行微调通常是有益的。当提供更高分辨率的图像时,我们将图块大小保持不变,这会导致更大的有效序列长度。ViT可以处理任意序列长度(直到内存限制),但是,预训练的位置embedding可能不再有意义。因此,我们根据预先训练的位置嵌入在原始图像中的位置执行2D插值。请注意,只有在分辨率调整和色块提取中,将有关图像2D结构的感应偏差手动注入到Vision Transformer中。
参考:
https://zhuanlan.zhihu.com/p/356155277
https://zhuanlan.zhihu.com/p/359071701
Swin Transformer(用于图像分类)
目前Transformer应用到图像领域主要挑战在于:图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大(例如VIT);在不同场景下视觉Transformer性能未必很好(我理解的是小目标和大目标的识别)。
因此Swin Transformer横空出世,有效的解决了上述两个弊端。不过我个人感觉Swin Transformer不会很火爆,因为它比较繁琐,没有像Resnet和VIT等模型“大道至简”的感觉。
Swin Transformer最主要的两方面:层级化+滑窗设计,我们先看下Swin Transformer的整体架构

整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野。
在输入开始的时候,做了一个Patch Embedding,将图片切成一个个图块,并嵌入到Embedding。具体是将图像先分割成4 × 4 的小块,然后将每一个小块通过映射成一个像素点,进行了通道上的扩充。以swin-s为例,输入的224 × 224 图像经过这一步操作就变成了56 × 56的特征图。
第一个stage中做了一个线性嵌入,将48的通道数变成了通道数C,然后Transformer的输入和输出维度是相同的,所以进入下一个stage的大小是不变的。
第二个stage中做patch merging,块融合(降低图像分辨率),所以H和W各变为二分之一,总共是缩小4分之一,然后通道数增加了4倍(用空间换深度),经过一个全连接层再调整通道维度为原来的2倍,也就是说每经过一个stage,总的数据量变为原来的1/2。可以参考下面的示意图(输入张量N=1, H=W=8, C=1,不包含最后的全连接层调整)。
Block具体结构如右图所示,主要是LayerNorm,MLP,Window Attention 和 Shifted Window Attention组成。

Window Attention 和 shift window attention:
这是这篇文章的关键。传统的Transformer都是基于全局来计算注意力的,因此计算复杂度十分高。而Swin Transformer则将注意力的计算限制在每个窗口内,进而减少了计算量。
window attention就是按照一定的尺寸将图像划分为不同的window,每次transformer的attention只在window内部进行计算。那么如果只有window attention就会带来每一个像素点的感受野得不到提升的问题,所以它又设计了一个shift window attention(下移两个patchs)的方法,就是换一下window划分的方式,让每一个像素点做attention计算的window块处于变化之中。那么就起到了提升感受野的作用。

不过,Shift Window Attention引入了一个问题:即window的个数翻倍了,由原本四个窗口变成了9个窗口。
缩小Shift Window Attention的窗口数:
在实际代码里,我们是通过对特征图移位,并给Attention设置mask来间接实现的。能在保持原有的window个数下,最后的计算结果等价。
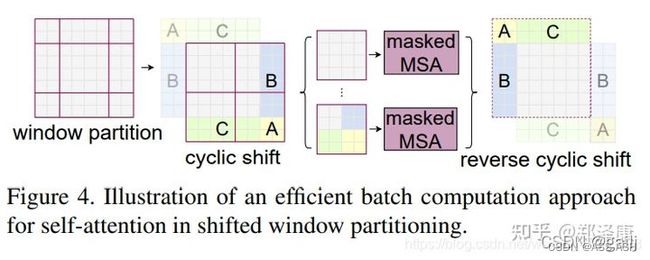
但是这样的话,如何计算Attention呢,因为A只能和A计算,不能和B计算,如果直接如上图所示算的话,肯定会计算A与B的注意力,但是A和B的顺序本来就是不同的啊,是我们为了快速计算强行拉到了相同的位置,所以计算A和B的注意力是没有意义的。这里参考这篇博客:https://zhuanlan.zhihu.com/p/367111046
采用一种Mask的方法,将不需要计算注意力的地方遮盖住就可以了。(实际是用-1000这种特别大的负数,然后经过softmax函数,达到mask效果)。我们算的是同一个图像中,图像像素与图像像素之间的权重嘛,但是不同图像间(或者说位置不同的图形块间)是没必要计算相似度,相似度为0就行了,-1000的数值经过softmax函数后必然是等于0的。
MAE(预训练模型)
MAE是由凯明大神提出的,在CV领域中,Masked Autoencoders(MAE)是一种scalable的自监督学习器。MAE方法很简单:我们随机mask掉输入图像的patches并重建这部分丢失的像素。
MAE论文从三个方面做了分析,这也是MAE方法的立意:
图像的主流模型是CNN,而NLP的主流模型是transformer,CNN和transformer的架构不同导致NLP的BERT很难直接迁移到CV。但是vision transformer的出现已经解决这个问题;
图像和文本的信息密度不同,文本是高语义的人工创造的符号,而图像是一种自然信号,两者采用masked autoencoding建模任务难度就不一样,从句子中预测丢失的词本身就是一种复杂的语言理解任务,但是图像存在很大的信息冗余,一个丢失的图像块很容易利用周边的图像区域进行恢复;
用于重建的decoder在图像和文本任务发挥的角色有区别,从句子中预测单词属于高语义任务,encoder和decoder的gap小,所以BERT的decoder部分微不足道(只需要一个MLP),而对图像重建像素属于低语义任务(相比图像分类),decoder需要发挥更大作用:将高语义的中间表征恢复成低语义的像素值。
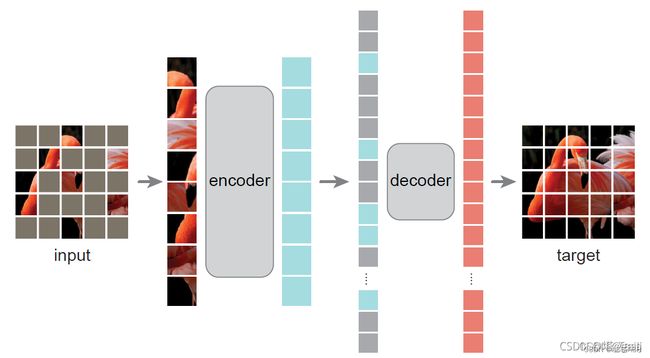
现将MAE的核心总结如下:
MAE采用encoder-decoder结构,但属于非对称结构,一方面decoder采用比encoder更轻量级设计,另外一方面encoder只处理一部分patchs(visible patchs,除了masked patchs之外的patchs),而decoder处理所有的patchs,如上图。这也就是为什么MAE能够只用较少的内存和计算消耗就能训练大的encoders
MAE采用很高的masking ratio(比如75%甚至更高),这是因为图像存在很大的信息冗余,一个丢失的图像块很容易利用周边的图像区域进行恢复,所以必须遮住比较多的patches。同时因为遮住了更多的patches,
论文还研究了一种变体,解码器重建目标是每个masked patches的归一化像素值。具体来说,我们计算每个patches中所有像素的平均值和标准偏差,并使用它们来规范化patches。在我们的实验中,使用归一化像素作为重构目标提高了表示质量。
decoder就是Transformer中的decoder,训练时需要encoder-decoder,测试时只需要encoder+MLP(MLP用于微调)。
参考:
https://zhuanlan.zhihu.com/p/439020457
https://blog.csdn.net/weixin_44876302/article/details/121302921
https://blog.csdn.net/weixin_46782905/article/details/121432596
https://blog.csdn.net/herosunly/article/details/121874941
CLIP(预训练模型)
CLIP打通了文本和图像之间的联系,是多模态方面的经典之作。
大量的文本-图片 数据对,OpenAI采集了一个总量超过4亿图像-文本对的数据集WIT,尽可能的提高数据集在不同场景下的覆盖度,查询了50W个词条,每个词条找到的数据对不超过2W个。
CLIP由两个编码器组成,一个是图像编码器(VIT和ResNet,都用了),另一个是文本编码器(Transformer)
采用对比学习的方法,对图片嵌入特征和文本嵌入特征进行矩阵相乘,对角线上都是配对的正样本对打分,而矩阵的其他元素,则是由同个batch内的图片和不配对的文本(相反亦然)组成的负样本,如下图。

预训练阶段的文本大多数某个短句,也就是一个图片对应一个短句。
考虑到大部分的数据集的标签都是以单词的形式存在的,比如“bird”,“cat”等等,然而在预训练阶段的文本描述大多都是某个短句,为了填补这种数据分布上的差别,作者考虑用指示上下文(guide context) 对标签进行扩展。可以用a photo of a label.作为文本端的输入,其中的 label 恰恰是需要预测的zero-shot标签。
CLIP模型的效果实现了图像和文本向同一个特征空间映射的能力。当进行图像识别时,我们将待识别的图像映射成一个特征向量。同时我们将所有的类别文本转换成一个句子(指示上下文),然后将这个句子映射成另外一组特征向量。文本特征向量和图像特征向量最相近的那一个便是我们要识别的目标图像的类。

考虑到以单词作为标签存在多义的情况,比如boxer表示斗牛犬、拳击运动;crane同时表示了起重机和鹤。这种词语的多义显然对是因为缺少对标签的上下文描述导致的。为了解决这种问题,作者在指示上下文中添加了一些提示标签类型的词语,比如A photo of a label, a type of pet.。作者将这个方法称之为“prompt engineering”。在合适地选取了不同的指示上下文,并且将其打分进行ensemble之后。作者发现这些Tricks竟能在zero-shot实验上提高5个绝对百分位。
优点:
训练高效、预训练任务简单;
方便迁移,CLIP图像对应的标签不再是一个值了,而是一个句子,这就让模型映射到足够细粒度的类别上提供了可操作空间;
全局学习:CLIP学习的不再是图像中的一个物体,而是整个图像中的所有信息,不仅包含图像中的目标,还包含这些目标之间的位置,语义等逻辑关系。这便于将CLIP迁移到任何计算机视觉模型上。这也就是为什么CLIP可以在很多看似不相关的下游任务上(OCR等)取得令人意外的效果。
参考:https://zhuanlan.zhihu.com/p/477760524
参考:https://blog.csdn.net/gailj/article/details/123664828