CENTOS上的网络安全工具(八)Scapy协议解析
一般来说,使用诸如Arkima、Suricata等现成的开源网络安全工具已经可以满足大多数需求,但需求总是无止境的。当我们需要关注网络通信中一些奇奇怪怪的行为的时候,常规工具给出的数据特征常常无法满足我们特立独行的需求,这个时候往往需要我们自己进行网络数据的处理,解析协议并获取想要的数据。最直接的方法当然是编写程序,按照RFC文档逐比特逐字节的去拆解,这样我们能够获得最为定制化的能力,随心提取任何需要的字段;然而,这样往往对应大量的程序编写和调试工作,除非是面向长期、固定、大量和性能攸关的需要,否则是不太合算的。所幸,还有一个折衷的办法,就是基于python的易用性,调用一些第三方模块,获得即可基本满足定制化需求,开发又不太困难的数据处理程序。
比如Scapy。
一、使用Scapy解析pcap文件
Scapy可以做很多事情,比如构造数据包,模拟浏览器,从而被用来定制扫描器、爬虫工具等等。在这里,我们只关心如何使用其处理pcap文件。
1.使用Scapy读取pcap文件的两种方法
使用scapy读取pcap文件的有两种方法:
其一,是直接使用rdpcap函数,将整个pcap文件读入内存并解析,函数返回解析结果,用户遍历解析结果获得需要的数据。这一方法对于较小的、较少的pcap文件比较好用,但如果是大量的、单个文件达到100MB以上的pcap文件,可能就会让人等到抓狂了。
from scapy.all import *
pcap = rdpcap('/pcapfile_path/pcapfile_name')
if len(pcap) > 0:
for packet in pcap:
custom_analyse(packet )其二,是使用sniffer函数,该函数以嗅探器方式工作逐次从pcap文件中提取数据包,并调用用户指定的回调函数进行进一步分析。如此可避免一次读入整个数据包导致的慢响应。
from scapy.all import *
def callback_func(packet):
custom_analyse(packet)
sniff(offline=pcapfile_pathname,prn=lamda packet:callback_func(packet),store=0)2.并行化运行python程序的方法
使用scapy解析pcap文件会遇到的另一个比较麻烦的问题,是python的执行效率。由于python是解释性的,本身来说就不至于如C一般高效,再加上scapy内部的复杂解析逻辑(不管需要与否,scapy似乎都会将其认识的所有协议要素解析出来并组织成字典、列表等等数据结构),势必进一步降低性能。对于需要处理较大数量和文件大小的pcap来说,需要尽可能去榨干机器的资源,以达到较高处理性能。
其一,对于C程序员比较容易想到的,是使用多线程方法。在python中,可基于线程池ThreadPoolExecutor简单地实现:
这里对给定的your_pcapfiles_path中的文件,使用os.listdir()方法进行枚举,从中选择后缀为pcap的文件(这里用了列表推导式来生成),然后仅仅是将这些文件及处理文件的函数提交给线程池就完成了。
import os
from concurrent.futures import ThreadPoolExecutor
def threadfunc(pcapfilename):
……
with ThreadPoolExecutor(max_workers=your_threads_count) as t:
for pcapFile in [f for f in os.path.join(your_pcapfiles_path,os.listdir(your_pcapfiles_path)) if os.path.isfile(f) and f.endswith(".pcap"):
t.submit(threadfunc,pcapfile)
其二,python程序并行化。然而,当程序运行起来我们会发现,没有任何并行化效果——比单线程还要慢。这是因为python的解释器是单线程的……,即使使用线程池,实际真正跑起来的线程也只有一个而已。要想真正利用主机的多核、多盘资源,需要使用python的进程并发机制。 总的来看进程池使用方式和线程池很像,只是需要注意的,一个是参数是以元组的方式传递的,另一个是需要按要求关闭进程池,并join主进程等待,以免主进程提前挂掉。
from multiprocessing import Pool, cpu_count
def profunc(pcapfilename):
……
#获取本机的CPU核数,并使用其中的90%启动并行进程
cpucount = int(cpu_count()*0.9)
print('Use {0:d} CPU cores to parse pcap files in multi threads ......'.format(cpucount))
#初始化进程池
processPool = Pool(cpucount)
#仍然使用一个推导式生成迭代对象枚举pcap文件,并向进程池提交
for pcapFile in [f for f in os.path.join(your_pcapfiles_path,os.listdir(your_pcapfiles_path)) if os.path.isfile(f) and f.endswith(".pcap"):
processPool.apply_async(procfunc,(pcapFile,))
#进程池使用完毕必须关闭
processPool.close()
#主进程需要等待进程池结束才能关闭
processPool.join()二、DNS协议的scapy解析
这里主要讨论一下使用scapy解析DNS协议的方法。一个主要的原因,当然是suricata、arkime等安全工具并不能支持我们深入的观察DNS协议细节。
1. DNS协议的工作方式
介绍DNS原理的文章很多,如递归查询、迭代查询等等,所以这里不再赘述。不过几个比较容易混的名词,在递归、迭代中也会出现,这里再梳理一下:
根域名服务器:DNS域名使用中规定由尾部句点'.'来指定名称位于根或者更高层次的域层次结构,根服务器有13台。它们的名称用一个英文字母命名,从a一直到m。这些服务器由各种组织控制,并由 ICANN(互联网名称和数字地址分配公司)授权。实际上每个根服务器都有镜像服务器,每个根服务器与它的镜像服务器共享同一个 IP 地址,中国大陆地区内只有6组根服务器镜像(F,I(3台),J,L)。
顶级域名服务器:负责管理在该顶级域名服务器下注册的二级/次级域名。通用域名通常采用三个字符,如com -> 商业公司,edu -> 教育机构,net -> 网络公司,gov -> 非军事政府机构等等。国家、组织或个人域名常采用两个字符,如:cn -> 代表中国,jp -> 日本,uk -> 英国,hk -> 香港等等。
权威域名服务器:是域名查询链的最后一环,实际持有查询答案的服务器。权威域名服务器负责一个区的域名解析工作。实际域名并非按域而是按区管理的,一个权威服务器所负责管辖(或有权限)的范围叫做区zone,权威域名服务器保有区中所有主机到域名IP地址的映射。从而,一般而言,域名服务器管理范围从小到大大致是:本地域名服务器 -> 权限域名服务器 -> 顶级域名服务器 -> 根域名服务器
本地域名服务器:当一个主机发出DNS查询请求的时候,这个查询请求首先就是发给本地域名服务器的。如果本地域名服务器存在主机查询的结果,则可以直接返回——这个返回的结果是费授权的。一般来说本地域名服务器在最靠近主机的网络中,通常一些应用会利用这一点来进行网络负载均衡。当然,由于主机允许用户手动设置本地域名服务器,这也可能造成例外(比如Google的8.8.8.8在台湾省)。
2. DNS协议的格式
一般来说,主机查询DNS走的路线都是“主机——本地域名服务器——根域名服务器——顶级域名服务器——权威域名服务器”,区别只在递归还是迭代而已。而DNS应答中,也会携带一些如名字服务器应答(NS),授权服务器应答(AS)等等的标识,这个还是需要和上面的概念略做区分——这里主要指的是应答内容,与应答内容强相关。
因此,此处还有必要简要梳理一下DNS协议的格式,也方便我们确定scapy解析中需要提取的协议要素。
DNS的承载协议:
RFC1035规定递归解析使用UDP,区传输要求可靠性,必须使用TCP。另一种情况是,UDP只允许512字节overload,超过这个长度DNS报文会被截断,Flags-Truncated位被设置。此时,若服务器支持,可使用TCP重新发送查询请求以申请大于512字节的应答。
由于网络应用多样与复杂,DNS目前越来越多的被用于非域名信息的交换,这导致协议报文长度超出512字节限制。因此,新的DNS协议允许用户在UDP中显式指定长报文,比如使用EDNS(RFC2671),即基于OPT字段指定UDP的payload长度。
DNS的协议格式:
DNS协议由报头段+若干资源段构成。报头段有固定的协议格式,而资源段则根据资源类型不同有不同的协议格式。如图所示:
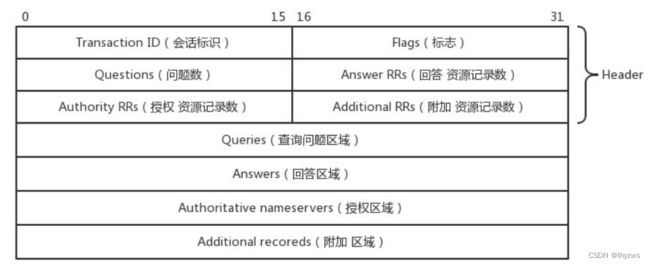
其中,Transaction ID为会话标识,查询报文与应答报文一致,故可用于构建查询/应答绘画
Flags标志包括:
- QR(1bit):查询/响应的标志位,1为响应,0为查询
- opcode(4bit):定义查询或响应的类型(0为标准的,1为反向的,2为服务器状态请求,3-15保留值)
- AA(1bit):授权回答的标志位。该位在响应报文中有效,1表示域名服务器是权限服务器
- TC(1bit):截断标志位。1表示响应已超过512字节并已被截断
- RD(1bit):被请求报文设置,该位为1表示客户端希望得到递归回答,应答时使用相同的值返回。
- RA(1bit):支持递归, 这个比特位在应答中设置或取消,用来代表服务器是否支持递归查询。
- zero(3bit):保留字段。
- rcode(4bit):返回码,表示响应的差错状态,通常为0和3,各取值含义如下:
- 0 无差错
- 1 报文格式差错(Format error)服务器不能理解的请求报文
- 2 服务器失败(Server failure)因为服务器的原因导致没办法处理的请求
- 3 名字错误(Name error) 只有对授权域名解析服务器有意义,指出解析的域名不存在
- 4 没有实现(Not Implemented)域名服务器不支持的查询类型
- 5 拒绝(Refused)服务器由于设置的策略据局给出应答
- 6 - 15 保留值
然后,问题数、应答数、授权资源记录、附加资源记录数标识了其后所跟各种资源字段的数量。由于资源类型不同,其对应的字段不同,这里就不再赘述——直接看RFC更直观。这里想强调的,是大多数资源都有class,type,name,data,ttl这么几个字段,在其各自不同的语境下,代表相同或相近的意思:
CLASS:早期有几种,现在多数是IN了,代表Internet的意思。另外还有CH(chaos)和HS(hesiod)两类,但几乎已淘汰
TYPE:资源类型,非常众多,几乎难以穷尽,但是比较多的就是A/AAAA,CNAME,MX,NS,PTR,TXT,OPT,SOA,NSEC,NSEC3,RRSIG这么几类,简单梳理含义与字段如下:
- SOA: start of authority 所查询域名的授权开始域名
- origin 授权起始域名
- mail addr 邮件地址
- serial 序列号(一般格式为年月日次)
- refresh slave 表示slave服务器多久向master DNS申请一次更新数据
- retry 如果申请更新不成功,多久以后再申请
- expire 如果申请更新不成功,多久以后放弃
- minimum 即TTL,指外部服务器保存本服务器数据,保存时限
- A:IP地址,俗称A记录
- AAAA:IP V6地址
- address 指定域名的IP地址
- MX:邮件交换 此类型和邮箱服务器设置有关,用来标识当前域名对应的邮箱服务器
- mail exchanger 查询域名的邮箱服务器
- NS:标识给定域名下所包含的DNS域名服务器信息
- name server 指定域名的名字服务器信息
- CNAME:别名,也叫规范名
- canonial name 指定域名的别名/规范名
- HINFO:主机描述信息,包括CPU和OS信息
- hardware info 指定域名对应的主机硬件信息
- PTR:指针,用于反向解析
- ptr 指定IP地址对应的域名辛纳希
- TXT:其他一些文本信息
- txt 指定域名对应的一些文本信息
- MINFO:查找邮箱信息
- ANY:查看关于主机域的左右信息
- RP:查看域负责人记录
- UINFO:查看用户信息
- AXFR:对区域转换的要求
- WKS:知名服务的描述
- MINFO:邮件列表描述
- AFSDB:AFX数据库位置
- X25:PSTN地址
- ISDN:ISDN地址
- NSAP:NSAP地址
- SIG:安全签名
- KEY:密钥
- PX:X.400邮件映射信息
- GPOS:物理地址
- LOC:地址信息
- RT:路由穿透
- KX:密钥交换
- CERT:证书
- RRSIG
- NSEC
- DNSKEY
- IPSECKEY
- SSHFP
- DS:Delegatioin Designer
- TLSA
NAME,DATA: 通常情况下,在scapy解析的结果中,如果出现name字段,常常对应问题;如果出现*data字段,则常常对应问题的答案。
3.基于scapy解析DNS
承载协议判断:
通常,对读入的pcap报文,应该使用scapy的haslayer()方法进行承载协议判断。如首先判断是否存在DNS的常见承载协议UDP和TCP,及其之下的IP协议。这样,在判断的同时,还可以提取最为常见常用的五元组信息:
if packet.haslayer(IP):
packettime = time.strftime("%Y-%m-%d %H:%M:%S",time.localtime(float(packet.time)))
srcIP = packet[IP].src
dstIP = packet[IP].dst
proto = packet[IP].get_field('proto').i2repr(packet[IP],packet[IP].proto).upper()
ipTTL = packet[IP].ttl
if packet.haslayer(UDP) and packet.haslayer(TCP):
srcPort = packet.sport
dstPort = packet.dport
注意上面用到了scapy的一个内置转换i2repr(),可以将一些枚举值转换为标准定义的字符串,挺好用,可以套用在class和type上。
虽然scapy也提供了更为直接的判断方法haslayer(DNS),但是我并不建议这么用。因为实际操作过程中,它可能会将被ICMP打回来的DNS协议报文解析为真实DNS报文,从而在随后的数据分析中给出一些诡异的结果。另外,建议也可以考虑剔除5353端口的MDNS协议,如果并不打算涉及内网uPnP服务设备发现的话。
协议头解析与资源段枚举:
if packet.haslayer(DNS):
dns = packet[DNS]
flag_qr = dns.qr #查询/应答
flag_aa = dns.aa #授权应答
flag_tc = dns.tc #截断
flag_rd = dns.rd #递归申请
flag_ra = dns.ra #递归同意
flag_op = dns.opcode #操作状态
flag_rc = dns.rcode #应答状态
sessionid = dns.id #会话ID
#如果是DNS查询
if dns.qr==0:
if dns.qdcount>0: #枚举问题资源段
for record in dns.qd:
……
#如果是DNS应答
elif dns.qr==1:
if dns.ancount >0: #枚举应答资源段
for answer in dns.an:
……
if dns.nscount >0: #枚举授权资源段
for author in dns.ns:
……
if dns.arcount >0: #枚举附加资源段
for optres in dns.ar:
……
资源字段中元素的检索:
scapy在解析资源字段时,会将解析出的元素放在资源字段(对应如上代码如record、answer、author和optres等对象的fields属性中,这是一个字典类型。如上文所述,不同的类型,往往造成其解析出的元素不同,而scapy又好给这些不同的元素起不同的名字,所以在提取这些元素时,一方面需要使用条件语句来判断,另一方面也需要使用异常处理语句做最坏情况的准备。
比如:
try:
if 'type' in resource.fields:
type = resource.get_field('type').i2repr(resource,resource.type)
if 'rclass' in resource.fields:
class = resource.get_field('rclass').i2repr(resource,resource.rclass)
if 'ttl' in resource.fields:
ttl = resource.ttl
if 'rrname' in resource.fields:
name = resource.rrname
if 'rdata' in resource.fields:
data = resource.rdata
except:
……三、使用mysql管理元数据
如果只是从几百兆的pcap文件提取元数据,在程序中直接使用数据结构进行管理就行,毕竟现在的主机内存吃下这种规模的数据还是没有啥问题的。但是如果是大量的pcap文件,其中提出出来的元数据可能超过数个GB,若还使用内存就不合适了。最为简单直接的替代方法就是把这些数据先录入到数据库中,再通过SQL语言来使用。
既然我们之前已经搭建过Mysql环境,就直接使用Mysql吧。
1. PyMysql
简单起见,使用pymysql访问mysql数据库,具体流程实际与使用C++接口类似,均需要依次获得连接对象、游标对象,并通过游标对象提交sql命令;不同在于,在python中我们可以使用pandas的dataframe对象来配合管理返回结果。
直接执行SQL命令:
import pymysql as mysql
try:
connect = mysql.connect(host='主机名或IP地址',port='一般是3306',user='比如root',passwd='口令')
cursor = connect.cursor()
cursor.execute('SQL 语句')
connect.commit()
connect.close()
except mysql.MySQLError as error:
print(error)
使用Pandas查询数据库:
import pandas as pd
import pymysql as mysql
try:
connect = mysql.connect(host='',port='',user='',passwd='')
query = pd.read_sql_query('SELECT * FROM sometable',connect)
print(query)
except mysql.MySQLError as error:
print(error)2. 常用SQL命令
使用pandas加上pymysql,基本上可以应付大多数协议元数据分析的需求了,一下罗列一下常用mysql环境下的SQL命令,方便查找使用:
数据库相关操作:
create database dbname 创建数据库
show databases 列出数据库
use dbname 使用数据库
drop database dbname 删除数据库
数据表相关操作:
create table tablename( 创建数据表
column1 type1 constrains1,
column2 type2 constrains2,
column3 type3 constrains3
)
其中约束可指定如: unsigned not null
类型可指定如: tinyint 1字节
mallint 2字节
mediumint 3字节
int,integer 4字节
bigint 8字节
float 4字节
double 8字节
dec(m,d)
decimal(m,d)
bit(M) <=64字节
date 4字节
datetime 8字节
timestamp 4字节
time 3字节
year 1字节
char(M) M字节
varchar(M) <=M字节
binary(M) M字节
varbinary(M) <=M字节
tinyblob <=255字节
blob <=65535字节
mediumblob <=167772150字节
longblob <=4294967295字节
tinytext <=255字节
text <=65535字节
mediumtext <=167772150字节
longtext <=4294967295字节
desc tablename 查看数据表
show create tablename \G 查看数据表详细定义
drop table tablename 删除数据表
alter table tablename modify [column column-name] column_definition [first|after col_name] 更改数据表字段
alter table tablename add [column column-name] column_definition [first|after col_name] 增加数据表字段
alter table tablename drop [column column-name] col_name 删除数据表字段
alter table tablename change [column column-name] old_name column_definition [first|after col_name 更改字段名称
alter table tablename rename newname 更改表名
记录操作类:
insert into tablename (field1,...,fieldn) values (value1,...,valuen) 插入记录
insert into tablename (field1,...,fieldn) values (value1,...,valuen),(value1,...,valuen),(value1,...,valuen) 插入多条记录
update tablename set f1=v1,...,fn=vn where condition 更改记录
update t1,...,tm set t1.f1=v1,...,tm.fn=vmn where condition 同时更改多个表中记录
delete from tablename where condition 删除记录
select * from tablename where condition 查询记录
select field1,...,fieldn from tablename where condition 指定字段查询
select distinct field from tablename 查询不重复记录
select f1,...,fn from tablename where condition order by f1 desc|asc,f2 desc|asc,... 查询记录排序
select * from tablename where condition limit offseet,linecount 显示部分查询结果
select f1,f2,....fn [sum|count(*)|avg|max|min] 聚合操作
from tablename
where condition 前置过滤降低聚合成本
group by f1,f2,...,fm 按照字段分组聚合
with rollup 聚合结果再汇总
having condition 聚合结果再过滤
连接两表中符合条件的列
select f1,...,fm from table1,table2 where table1.fi=table2.fj
左右连接,左右表中所有对应字段需要被列出,即使不满足匹配条件
select f1,...,fm from table1 [left|right] join talbe2 where table1.fi=talbe2.fj
嵌套查询
select f1,...,fn from tablename where fm [in|=](select ... from tablename)
select ..... from table1 合并查询结果(只会合并两表中都有的字段)
union [all] 去重[不去重]
select ..... from table2
mysql还可以支持一些奇怪的type:
ENUM
create table t (flag enum('Y','N'))
insert into t (flag) values 'Y','Y','N',NULL
SET
create table t (flag set('a','b','c'))
insert into t (flag) values ('a,b'),('a,c'),('b')
JSON
create table t (flag json)
insert into t (flag) values ('json fromat string')
condition运算符:
=
<> !=
<=>(NULL)
< <= > >=
a BETWEEN min and max
a IN ('a','b','c')
IS NULL
IS NOT NULL
LIKE 以%为通配符
REGEXP RLIKE 正则
解析数据,提取元数据,入库管理,检索使用,实际是比较标准的ETL流程。实际上,如果仅仅入库几万、十几万条数据,使用mysql数据库在单机上进行检索还是比较顺畅的,当数据达到百万、千万,甚至数亿、数十亿时,在单机上使用mysql就很困难了,尤其时还需要join、in操作的时候,其运算时间足以让人抓狂。而在实际的生产环境中,数据达到千万级以上是很现实的,所以在单机无法支持时,求助于集群就成为必然。这也许是为什么ETL总是会和大数据扯在一起的原因吧。