项目管理与SSM框架(一)| Mybatis
什么是ORM框架?
ORM(Object Relationl Mapping),对象关系映射,即在数据库和对象之间作映射处理。
使用ORM框架代替JDBC后,框架可以帮助程序员自动进行转换,只要像平时一样操作对象,ORM框架就会根据映射完成对数据库的操作,极大的增强了开发效率。
什么是MyBatis?
MyBatis是一个半自动的ORM框架,其本质是对JDBC的封装。使用MyBatis不需要写JDBC代码,但需要程序员编写SQL语句。之前是apache的一个开源项目iBatis,2010年改名为MyBatis。
补充:
Hibernate也是一款持久层ORM框架,多年前的市场占有率很高,但近年来市场占有率越来越低。
MyBatis与Hibernate的比较:
- MyBatis是一个半自动的ORM框架,需要手写SQL语句。
- Hibernate是一个全自动的ORM框架,不需要手写SQL语句。
- 使用MyBatis的开发量要大于Hibernate。
为什么Hibernate市场占有率越来越低:
- 对于新手学习Hibernate时间成本比MyBatis大很多,MyBatis上手很快。
- Hibernate不需要写SQL语句是因为框架来生成SQL语句。对于复杂查询,开发者很难控制生成的SQL语句,这就导致SQL调优很难进行。
- 之前的项目功能简单,数据量小,所以使用Hibernate可以快速完成开发。而近年来项目的数据量越来越大,而互联网项目对查询速度要求也很高,这就要求我们一定要精细化的调整SQL语句。此时灵活性更强,手动编写SQL语句的MyBatis慢慢代替了Hibernate使用。
- 在高并发、大数据、高性能、高响应的互联网项目中,MyBatis是首选的持久框架。而对于对性能要求不高的比如内部管理系统等可以使用Hibernate。
MyBatis入门
环境搭建
1. 准备一个SQL文件导入数据库
2. 创建一个Maven工程
<dependencies>
<dependency>
<groupId>org.mybatisgroupId>
<artifactId>mybatisartifactId>
<version>3.5.7version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.26version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.10version>
dependency>
<dependency>
<groupId>log4jgroupId>
<artifactId>log4jartifactId>
<version>1.2.12version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.1.21version>
dependency>
dependencies>
3. 创建mybatis核心配置文件SqlMapConfig.xml
DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC" />
<dataSource type="com.alibaba.druid.pool.DruidDataSource">
<property name="url" value="jdbc:mysql://localhost:3306/db_name" />
<property name="username" value="your_username" />
<property name="password" value="your_password" />
<property name="initialSize" value="5" />
<property name="maxActive" value="20" />
dataSource>
environment>
environments>
<mappers>
<mapper resource="mapper/YourMapper.xml" />
mappers>
configuration>
4. 将log4j.properties文件放入resources中,让控制台打印SQL语句。
5. 创建实体类
public class User {
private int id;
private String username;
private String sex;
private String address;
// 省略getter/setter/构造方法/toString方法
}
创建持久层接口和映射文件
1. 在java目录创建持久层dao包接口
public interface UserMapper {
List<User> findAll();
}
2. 在resource目录创建映射文件*Mapper.xml文件
DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.gb.mapper.UserMapper">
<select id="findAll" resultType="com.gb.pojo.User">
select * from user
select>
mapper>
3. 将映射文件配置到mybatis核心配置文件中
<mappers>
<mapper resource="/mapper/UserMapper.xml">mapper>
mappers>
resource后是你的创建的*.Mapper的文件的包路径,可以创建一个mapper包将映射文件都放到里面
- 映射文件要和接口名称相同。
- 映射文件要和接口的目录结构相同。(可以通过配置修改)
- 映射文件中namespace属性要写接口的全名。
- 映射文件中标签的id属性是接口方法的方法名。(必须一致)
- 映射文件中标签的resultType属性是接口方法的返回值类型。
- 映射文件中标签的parameterType属性是接口方法的参数类型。
- 映射文件中resultType、parameterType属性要写全类名,如果是集合类型,则写其泛型的全类名。(可以在配置文件中配置别名)
paramterType 的参数对应的Java中类型的别名

测试持久层接口方法
在test包中创建测试类 通过@Before 和@After 标签
public class UserMapperTest {
InputStream is = null;
SqlSession session = null;
UserMapper userMapper = null;
@Before
public void before() throws IOException {
// (1)读取核心配置文件
is = Resources.getResourceAsStream("SqlMapConfig.xml");
// (2)创建SqlSessionFactoryBuilder对象
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
// (3)SqlSessionFactoryBuilder对象获取SqlSessionFactory对象
SqlSessionFactory factory = builder.build(is);
// (4)SqlSessionFactory对象获取SqlSession对象
session = factory.openSession();
// (5)获取代理对象
userMapper = session.getMapper(UserMapper.class);
}
@After
public void after() throws IOException {
// 释放资源
session.close();
is.close();
}
// 测试方法
@Test
public void findAll(){
// 代理对象执行方法
List<User> all = userMapper.findAll();
all.forEach(System.out::println);
}
}
MyBatis核心对象及工作流程

MyBatis核心对象
- SqlSessionFactoryBuilder
SqlSession工厂构建者对象,使用构造者模式创建SqlSession工厂对象。 - SqlSessionFactory
SqlSession工厂,使用工厂模式创建SqlSession对象。 - SqlSession
该对象可以操作数据库,也可以使用动态代理模式创建持久层接口的代理对象操作数据库。 - Mapper
持久层接口的代理对象,他具体实现了持久层接口,用来操作数据库。
MyBatis工作流程
- 创建SqlSessionFactoryBuilder对象
- SqlSessionFactoryBuilder对象构建了SqlSessionFactory对象:构造者模式
- SqlSessionFactory对象生产了SqlSession对象:工厂模式
- SqlSession对象创建了持久层接口的代理对象:动态代理模式
- 代理对象操作数据库
Mapper动态代理原理
我们通过源码,了解MyBatis的Mapper对象究竟是怎么生成的,他又是如何代理接口的方法。
获取代理对象
点开测试类的 getMapper 方法,查看该方法最终调用了什么方法。
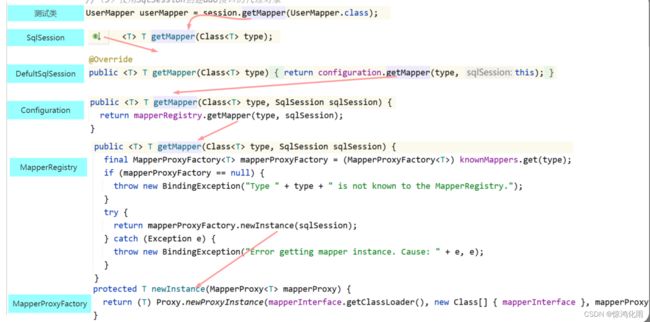
当看到 Proxy.newProxyInstance 时,可以确定 getMapper 方法最终调用的是JDK动态代理方法,且使用MapperProxy类定义代理方式
查看代理方式
点开MapperProxy类,查看invoke方法,查看代理对象是如何工作的。
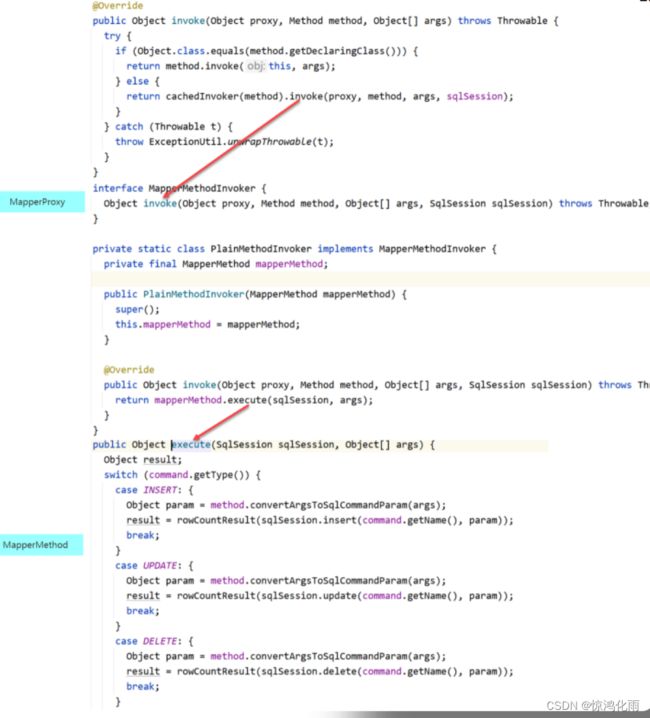
可以看到,MapperProxy调用了MapperMethod的execute方法定义了代理方式,且底层调用的是SqlSession的方法,根据映射文件标签不同调用不同的SqlSession方法。
结论:
- SqlSession的getMapper方法,最终是调用的是JDK动态代理方法,生成一个代理对象,类型就是传入的接口类型。
- MapperProxy对象通过调用MapperMethod的execute方法定义了代理方式,该方法的底层调用的是SqlSession的方法。
MyBatis模糊查询
使用$定义参数
模糊查询如果不想在调用方法时参数加%,可以使用拼接参数的方式设置Sql:
<select id="findByUsernameLike" parameterType="string" resultType="com.itbaizhan.pojo.User">
select * from user where username like '%${value}%'
select>
#和$的区别:
- #表示sql模板的占位符,$表示将字符串拼接到sql模板中。
- #可以防止sql注入,一般能用#就不用$。
- ${}内部的参数名必须写value。
使用定义参数
如果使用 # 还不想在调用方法的参数中添加 % ,可以使用 ,
<select id="findByUsernameLike" parameterType="string" resultType="com.itbaizhan.pojo.User">
<bind name="likeName" value="'%'+username+'%'"/>
select * from user where username like # {likeName}
select>
MyBatis分页查询
顺序传参
不推荐使用
/**
* 分页查询
* @param startIndex 开始索引
* @param pageSize 每页条数
* @return
*/
List<User> findPage(int startIndex,int pageSize);
POJO传参
自定义POJO类,该类的属性就是要传递的参数,在SQL语句中绑定参数时使用POJO的属性名作为参数名即可。此方式推荐使用。
public class PageQuery {
private int startIndex;
private int pageSize;
// 省略getter/setter/构造方法
}
List<User> findPage2(PageQuery pageQuery);
Map传参
可以使用Map作为传递参数的载体,在SQL语句中绑定参数时使用Map的Key作为参数名即可。此方法推荐使用
1. 持久层接口方法
List<User> findPage3(Map<String,Object> params);
2. 映射文件
<select id="findPage3" resultType="com.itbaizhan.pojo.User" parameterType="map">
select * from user limit # {startIndex},#{pageSize}
select>
3. 测试类
@Test
public void testFindPage3(){
Map<String,Object> params = new HashMap();
params.put("startIndex",0);
params.put("pageSize",4);
List<User> users = userMapper.findPage3(params);
users.forEach(System.out::println);
}
MyBatis聚合查询、主键回填
主键回填
有时我们需要获取新插入数据的主键值。如果数据库中主键是自增的,这时我们就需要使用MyBatis的主键回填功能。
1. 持久层接口方法
void add(User user);
2. 映射文件
<insert id="add" parameterType="com.gb.user.User">
<selectKey keyProperty="id" keyColumn="id" resultType="int" order="AFTER">
SELECT LAST_INSERT_ID();
selectKey>
insert into user(username,birthday,sex,address) values(#{username},#{birthday},#{sex},#{address})
insert>
SELECT LAST_INSERT_ID():查询刚刚插入的记录的主键值,只适用于自增主键,且必须和insert语句一起执行。
3. 测试类
@Test
public void testAdd(){
User user = new User("尚学堂", new Date(), "男", "北京");
userMapper.add(user);
session.commit();
System.out.println(user.getId());
}
MyBatis配置文件_

properties
属性值定义。properties标签中可以定义属性值,也可以引入外部配置文件。无论是内部定义还是外部引入,都可以使用${name}获取值。
1. 编写db.properties
jdbc.url=jdbc:mysql://localhost:3306/mybatis
jdbc.driver=com.mysql.cj.jdbc.Driver
jdbc.username=root
jdbc.password=root
jdbc.initialSize=5
jdbc.maxActive=20
2. 在配置文件中引入db.properties
<properties resource="db.properties">properties>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">transactionManager>
<dataSource type="com.alibaba.druid.pool.DruidDataSource">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
<property name="initialSize" value="${jdbc.initialSize}"/>
<property name="maxActive" value="${jdbc.maxActive}"/>
dataSource>
environment>
environments>
MyBatis配置文件_
<settings>
<setting name="lazyLoadTriggerMethods" value=""/>
settings>
MyBatis配置文件_
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<property name="helperDialect" value="mysql"/>
plugin>
plugins>
MyBatis配置文件_
MyBatis对常用类有默认别名支持,比如java.lang.Stirng的别名为string。除此之外,我们也可以使用 设置自定义别名。
<typeAliases>
<package name="com.gb.pojo"/>
typeAliases>
MyBatis配置文件_
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">transactionManager>
<dataSource type="com.alibaba.druid.pool.DruidDataSource">
<property name="driver" value="${jdbc.driver}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
<property name="initialSize" value="${jdbc.initialSize}"/>
<property name="maxActive" value="${jdbc.maxActive}"/>
dataSource>
environment>
environments>
dataSource的type属性:
- POOLED:使用连接池管理连接,使用MyBatis自带的连接池。
- UNPOOLED:不使用连接池,直接由JDBC连接。
- JNDI:由JAVAEE服务器管理连接,如果使用Tomcat作为服务器则使用Tomcat自带的连接池管理。
MyBatis配置文件_
1. 使用相对路径注册映射文件
<mappers>
<mapper resource="/mapper/UserMapper.xml"/>
mappers>
这种方式比较好用
2. 使用绝对路径注册映射文件
<mappers>
<mapper url="file:///C:\Users\a\IdeaProjects\mybatiscase\mybatisDemo1\src\main\resources\com\gb\mapper\UserMapper.xml"/>
mappers>
3. 注册持久层接口
<mappers>
<mapper class="com.gb.mapper.UserMapper"/>
mappers>
4. 注册一个包下的所有持久层接口
<mappers>
<package name="com.gb.mapper"/>
mappers>
MyBatis映射文件_
resultMap
标签的作用的自定义映射关系。
MyBatis可以将数据库结果集封装到对象中,是因为结果集的列名和对象属性名相同:
当POJO属性名和数据库列名不一致时,MyBatis无法自动完成映射关系。如:

此时有两种解决方案:
1. Sql语句的查询字段起与POJO属性相同的别名。
<select id="findAll" resultType="com.itbaizhan.pojo.Teacher">
select tid as id,tname as teacherName from teacher;
select>
2 自定义映射关系
在映射文件中,使用
<resultMap id="teacherMapper" type="com.itbaizhan.pojo.Teacher">
<id property="id" column="tid">id>
<result property="teacherName" column="tname">result>
resultMap>
在 标签中,使用resultMap属性代替 resultType 属性,使用自定义映射关系。
<select id="findAll" resultMap="teacherMapper">
select * from teacher
select>
MyBatis映射文件_
<sql id="selectAllField">
select tid as id,tname as teacherName
sql>
<select id="findAll" resultType="com.itbaizhan.pojo.Teacher">
<include refid="selectAllField">include>
from teacher;
select>
MyBatis映射文件_特殊字符处理
在Mybatis映射文件中尽量不要使用一些特殊字符,如: < , > 等。
我们可以使用符号的实体来表示:

<select id="findById2" resultType="com.itbaizhan.pojo.Teacher">
<include refid="selectAllField">include>
from teacher where tid > #{id}
select>
动态SQL
例如:根据不同条件查询用户:
1. 持久层接口添加方法
// 用户通用查询
List<User> findByCondition(User user);
2. 映射文件添加标签
<select id="findByCondition" parameterType="com.gb.pojo.User" resultType="com.gb.pojo.User">
select * from user where 1 = 1
<if test="username != null and username.length() != 0">
and username like #{username}
if>
<if test="sex != null and sex.length()!= 0">
and sex = #{sex}
if>
<if test="address != null and address.length() != 0">
and address = #{address}
if>
select>
3. 编写测试方法
@Test
public void testFindByCondition(){
User user = new User();
List<User> users1 =userMapper2.findByCondition(user); // 空的会查询所有
users1.forEach(System.out::println);
user.setUsername("%北京%");
List<User> users2 = userMapper2.findByCondition(user); // 根据姓名模糊查询
users2.forEach(System.out::println);
user.setAddress("北京");
List<User> users3 = userMapper2.findByCondition(user); // 姓名和地址组合多条件查询
users3.forEach(System.out::println);
}
- if中的条件不能使用&&/||,而应该使用and/or
- if中的条件可以直接通过属性名获取参数POJO的属性值,并且该值可以调用方法。
- where后为什么要加1=1?
任意条件都可能拼接到Sql中。如果有多个条件,从第二个
条件开始前都需要加And关键字。加上1=1这个永久成立的
条件,就不需要考虑后面的条件哪个是第一个条件,后面的
条件前都加And关键字即可。
<select id="findByCondition" resultType="User"parameterType="User">
select * from user
<where>
<if test="username != null and username.length() != 0">
username like #{username}
if>
<if test="sex != null and sex.length() != 0">
and sex = #{sex}
if>
where>
select>
<update id="updateUser" parameterType="User">
update user
<set>
<if test="username!=null and username.length !=0">
username = #{username},
if>
<if test="sex !=null and sex.length !=0">
sex = #{sex},
if>
<if test="address!=null and address.length !=0">
address = #{address}
if>
set>
<where>
id = #{id}
where>
update>
这些标签表示多条件分支,类似JAVA中的 switch…case 。
<select id="selectUserByUsername" resultType="User" parameterType="string">
<include refid="selectAllFiled">include>
from user
<where>
<choose>
<when test="username !=null and username.length() <5">
<bind name="likename" value="'%'+username+'%'"/>
username like #{likename}
when>
<when test="username !=null and username.length() <10">
username = #{username}
when>
<otherwise>
id =1
otherwise>
choose>
where>
select>
这段代码的含义为:用户名<5时使用模糊查询,用户名>=5并且<10时使用精确查询,否则查询id为1的用户
- collection:遍历的对象类型
- open:开始的sql语句
- close:结束的sql语句
- separator:遍历每项间的分隔符
- item:表示本次遍历获取的元素,遍历List、Set、数组时表示每项元素,遍历map时表示键值对的值。
- index:遍历List、数组时表示遍历的索引,遍历map时表示键值对的键。
遍历数组
我们使用
1. 持久层接口添加方法
void deleteBatch(int[] ids);
2. 映射文件添加标签
<delete id="deleteBatch" parameterType="int">
delete from user
<where>
<foreach open="id in (" close=")" separator="," collection="array" item="id">
#{id}
foreach>
where>
delete>
遍历Collection
1. 持久层接口添加方法
void insertBatch(List<User> users);
2. 映射文件添加标签
<insert id="insertBatch" parameterType="User">
insert into user(username,sex,address) values
<foreach collection="list" separator="," item="user">
(#{user.username},#{user.sex},#{user.address})
foreach>
insert>
遍历Map
我们使用
1. 持久层接口添加方法
/**
* 多条件查询
* @param map 查询的条件键值对 键:属性名 值:属性值
* @return
*/
List<User> selectUserByMap(@Param("queryMap") Map<String,Object> map);
2. 映射文件添加标签
<select id="selectUserByMap" resultType="User" parameterType="map">
<include refid="selectAllFiled">include>
from user
<where>
<foreach collection="queryMap" separator="and" index="key" item="value">
${key} = #{value}
foreach>
where>
select>
缓存介绍

缓存是内存当中一块存储数据的区域,目的是提高查询效率。MyBatis会将查询结果存储在缓存当中,当下次执行相同的SQL时不访问数据库,而是直接从缓存中获取结果,从而减少服务器的压力。
- 什么是缓存?
存在于内存中的一块数据。
- 缓存有什么作用?
减少程序和数据库的交互,提高查询效率,降低服务器和数据库的压力。
- 什么样的数据使用缓存?
经常查询但不常改变的,改变后对结果影响不大的数据。
- MyBatis缓存分为哪几类?
一级缓存和二级缓存
- 如何判断两次Sql是相同的?
- 查询的Sql语句相同
- 传递的参数值相同
- 对结果集的要求相同
- 预编译的模板Id相同
MyBatis一级缓存

- MyBatis一级缓存也叫本地缓存。SqlSession对象中包含一个Executor对象,Executor对象中包含一个PerpetualCache对
象,在该对象存放一级缓存数据。 - 由于一级缓存是在SqlSession对象中,所以只有使用同一个SqlSession对象操作数据库时才能共享一级缓存。MyBatis的一级缓存是默认开启的,不需要任何的配置。
MyBatis清空一级缓存
进行以下操作可以清空MyBatis一级缓存:
SqlSession调用close():操作后SqlSession对象不可用,该对象的缓存数据也不可用。SqlSession调用clearCache() / commit():操作会清空一级缓存数据。SqlSession调用增删改方法:操作会清空一级缓存数据,因为增删改后数据库发生改变,缓存数据将不准确。
MyBatis二级缓存

- MyBatis二级缓存也叫全局缓存。数据存放在SqlSessionFactory中,只要是同一个工厂对象创建的SqlSession,在进行查询时都能共享数据。一般在项目中只有一个SqlSessionFactory对象,所以二级缓存的数据是全项目共享的。
- MyBatis一级缓存存放的是对象,二级缓存存放的是对象的数据。所以要求二级缓存存放的POJO必须是可序列化的,也就是
要实现Serializable接口。 - MyBatis二级缓存默认不开启,手动开启后数据先存放在一级缓存中,只有一级缓存数据清空后,数据才会存到二级缓存中。
SqlSession 调用
clearCache()无法将数据存到二级缓存中。
开启二级缓存
- POJO类实现Serializable接口。
- 在MyBatis配置文件添加如下设置:
<settings>
<setting name="cacheEnabled" value="true"/>
settings>
- 在映射文件添加
如果查询到的集合中对象过多,二级缓存只能缓存1024个对象引用。可以通过
标签的size属性修改该数量。<cache size="2048"/>
MyBatis关联查询
MyBatis的关联查询分为一对一关联查询和一对多关联查询。
例如有学生类和班级类:
一个学生对应一个班级,也就是学生类中有一个班级属性,这就是一对一关系。
一个班级对应多个学生,也就是班级类中有一个学生集合属性,这就是一对多关系。
数据库设计如下:

实体类:
public class Student {
private Integer sid;
private String name;
private int age;
private String sex;
private Classes classes;
// 省略getter/setter/toString
}
public class Classes {
private int cid;
private String className;
private List<Student> studentList;
// 省略getter/setter/toString
}
MyBatis一对一关联查询
查询学生时,将关联的一个班级对象查询出来,就是一对一关联查询。
创建持久层接口
public interface StudentMapper {
List<Student> findAll();
}
创建映射文件
<sql id="selectAllField">
select sid, name, age, sex, classId, cid, class_name
sql>
<resultMap id="studentMapper" type="Student">
<id property="sid" column="sid">id>
<result property="name" column="name">result>
<result property="age" column="age">result>
<result property="sex" column="sex">result>
<association property="classes" column="classId" javaType="Classes">
<id property="id" column="cid">id>
<result property="className" column="className">result>
association>
resultMap>
<select id="selectAll" resultMap="studentMapper">
<include refid="selectAllField">include>
from student s left join classes c on s.classId = c.cid;
select>
MyBatis一对多关联查询
查询班级时,将关联的学生集合查询出来,就是一对多关联查询。
创建持久层接口
public interface ClassesMapper {
List<Classes> findAll();
}
创建映射文件
<sql id="selectAllField">
select c.cid,c.className,s.sid,s.name, s.age,s.sex,s.classId
sql>
<resultMap id="classesMapper" type="Classes">
<id property="id" column="cid">id>
<result property="className" column="className">result>
<collection property="studentList" column="classId" ofType="Student">
<id property="sid" column="sid">id>
<result property="name" column="name">result>
<result property="age" column="age">result>
<result property="sex" column="sex">result>
collection>
resultMap>
<select id="selectAll" resultMap="classesMapper">
<include refid="selectAllField">include>
from classes c
left join student s on c.cid = s.classId
select>
MyBatis多对多关联查询
MyBatis多对多关联查询本质就是两个一对多关联查询。
例如有老师类和班级类:
一个老师对应多个班级,也就是老师类中有一个班级集合属性。
一个班级对应多个老师,也就是班级类中有一个老师集合属性。
实体类设计如下:
public class Teacher {
private Integer tid;
private String tname;
private List<Classes> classes;
// 省略getter/setter/toString
}
public class Classes {
private Integer cid;
private String className;
private List<Student> studentList;
private List<Teacher> teacherList;
// 省略getter/setter/toString
}
在数据库设计中,需要建立中间表,双方与中间表均为一对多关系。
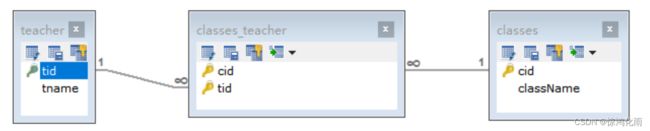
查询老师时,将关联的班级集合查询出来。
创建持久层接口
public interface TeacherMapper {
List<Teacher> findAll();
}
创建映射文件
<sql id="selectAllField">
select t.tid, t.tname, c.cid, c.className
sql>
<resultMap id="teacherMapper" type="Teacher">
<id property="id" column="tid">id>
<result property="name" column="tname">result>
<collection property="classesList" column="tid" ofType="Classes">
<id property="id" column="cid">id>
<result property="className" column="className">result>
collection>
resultMap>
<select id="selectAll" resultMap="teacherMapper">
<include refid="selectAllField">include>
FROM
teacher t
LEFT JOIN classes_teacher ct ON t.tid = ct.tid
LEFT JOIN classes c ON ct.cid = c.cid;
select>
如果想查询班级时,将关联的老师集合查询出来,只需要修改班级映射文件的Sql语句和 即可:
<sql id="selectAllField">
select c.cid,c.className,s.sid,s.name, s.age,s.sex,s.classId,t.tid,t.tname
sql>
<resultMap id="classesMapper" type="Classes">
<id property="id" column="cid">id>
<result property="className" column="className">result>
<collection property="studentList" column="classId" ofType="Student">
<id property="sid" column="sid">id>
<result property="name" column="name">result>
<result property="age" column="age">result>
<result property="sex" column="sex">result>
collection>
<collection property="teacherList" column="tid" ofType="Teacher">
<id property="id" column="tid">id>
<result property="name" column="tname">result>
collection>
resultMap>
<select id="selectAll" resultMap="classesMapper">
<include refid="selectAllField">include>
from classes c
left join student s on c.cid = s.classId
LEFT JOIN classes_teacher ct ON c.cid = ct.cid
LEFT JOIN teacher t on ct.tid =t.tid;
select>
MyBatis分解式查询_一对多
在MyBatis多表查询中,使用连接查询时一个Sql语句就可以查询出所有的数据。如:
# 查询班级时关联查询出学生
select *
from classes
left join student
on student.classId = classes.cid
也可以使用分解式查询,即将一个连接Sql语句分解为多条Sql语句,如:
# 查询班级时关联查询出学生
select * from classes;
select * from student where classId = 1;
select * from student where classId = 2;
这种写法也叫N+1查询。
连接查询:
- 优点:降低查询次数,从而提高查询效率。
- 缺点:如果查询返回的结果集较多会消耗内存空间。
N+1查询:
- 优点:结果集分步获取,节省内存空间。
- 缺点:由于需要执行多次查询,相比连接查询效率低。
我们以查询班级时关联查询出学生为例,使用N+1查询:
创建每个查询语句的持久层方法
public interface ClassesMapper {
// 查询所有班级
List<Classes> findAll();
}
public interface StudentMapper {
// 根据班级Id查询学生
List<Student> findByClassId(int classId);
}
在映射文件中进行配置
<resultMap id="MyClassesMapper" type="com.gb.pojo.Classes">
<id property="cid" column="cid">id>
<result property="className" column="className">result>
<collection property="studentList" ofType="com.gb.pojo.Student" select="com.gb.mapper2.StudentMapper2.findByClassId" column="cid">
collection>
resultMap>
<select id="findAll" resultMap="MyClassesMapper">
select * from classes
select>
MyBatis分解式查询_一对一
查询学生时关联查询出班级也可以使用分解式查询,首先将查询语句分开
select * from student;
select * from classes where cid = ?;
创建每个查询语句的持久层方法
public interface StudentMapper {
// 查询所有学生
List<Student> findAll();
}
public interface ClassesMapper {
// 根据ID查询班级
Classes findByCid(int cid);
}
在映射文件中进行配置
<select id="findAll"
resultType="com.itbaizhan.pojo.Student">
select *
from student
select>
<select id="findByCid"
resultType="com.itbaizhan.pojo.Classes"
parameterType="int">
select * from classes where cid = ${cid}
select>
修改主表映射文件中的查询方法
<resultMap id="MyStudentMapper" type="Student">
<id property="sid" column="sid">id>
<result property="name" column="name">result>
<result property="age" column="age">result>
<result property="sex" column="sex">result>
<association property="classes" javaType="Classes"
select="com.gb.mapper2.ClassesMapper2.findByCid" column="classId">
association>
resultMap>
<select id="findAll" resultMap="MyStudentMapper">
select * from student
select>
MyBatis延迟加载
分解式查询又分为两种加载方式:
- 立即加载:在查询主表时就执行所有的Sql语句。
- 延迟加载:又叫懒加载,首先执行主表的查询语句,使用从表数据时才触发从表的查询语句。
延迟加载在获取关联数据时速度较慢,但可以节约资源,即用即取。
开启延迟加载
设置所有的N+1查询都为延迟加载:
<settings>
<setting name="lazyLoadingEnabled" value="true"/>
settings>
设置某个方法为延迟加载:
在
lazy:延迟加载;eager:立即加载。
由于打印对象时会调用对象的 toString 方法, toString 方法默认会触发延迟加载的查询,所以我们无法测试出延迟加载的效果。
我们在配置文件设置lazyLoadTriggerMethods属性,该属性指定对象的什么方法触发延迟加载,设置为空字符串即可。
一般情况下,一对多查询使用延迟加载,一对一查询使用立即加载。
MyBatis注解开发
MyBatis可以使用注解替代映射文件。映射文件的作用就是定义Sql语句,可以在持久层接口上使用@Select/@Delete/@Insert/@Update定义Sql语句,这样就不需要使用映射文件了。
MyBatis注解开发_增删改查
@Select("select * from user where username like #{username}")
List<User> findByUsernameLike(String username);
/**
* @SelectKey 主键回填
* @param user
*/
@SelectKey(keyProperty = "id",keyColumn = "id",resultType = int.class,before = false,statement = "SELECT LAST_INSERT_ID() ")
@Insert("insert into user(user_name, sex, address) values (#{username}, #{sex}, #{address})")
void insertUser(User user);
@Update("update user set username=#{username},sex=#{sex},address=#{address} where id=#{id}")
void updateUser(User user);
@Delete("delete from user where id=#{id}")
void deleteUser(int userid);
MyBatis注解开发_动态Sql
在MyBatis中有 @SelectProvider 、 @UpdateProvider 、@DeleteProvider 、@InsertProvider 注解。当使用这些注解时将不在注解中直接编写SQL,而是调用某个类的方法来生成SQL。
/**
* 用户通用查询
* @SelectProvider 使用注解时将不在注解中直接编写SQL,而是调用某个类的方法来生成SQL。
* @param user
*/
@ResultMap("userMapper")
@SelectProvider(type = UserProvider.class,method = "selectByConditionSql")
List<User> selectUserByCondition(User user);
public class UserProvider {
public String selectByConditionSql(User user){
StringBuffer sb = new StringBuffer("select id, user_name, sex, address from user where 1=1");
if (user.getUsername()!=null && user.getUsername().length()>0){
sb.append(" and user_name like #{username}");
}
if (user.getSex()!=null && user.getSex().length()>0){
sb.append(" and sex = #{sex}");
}
if (user.getAddress()!=null && user.getAddress().length()>0){
sb.append(" and address = #{address}");
}
return sb.toString();
}
}
MyBatis注解开发_自定义映射关系
当POJO属性名与数据库列名不一致时,需要自定义实体类和结果集的映射关系,在MyBatis注解开发中,使用 @Results 定义并使用自定义映射,使用 @ResultMap 使用自定义映射,用法如下:
@Results(id = "userMapper",value = {
@Result(id = true,property = "id",column = "id"),
@Result(property = "username",column = "user_name"),
@Result(property = "sex",column = "sex"),
@Result(property = "address",column = "address")
})
@Select("select id, user_name, sex, address from user")
List<User> selectUser();
@ResultMap("userMapper")
@Select("select id,user_name,sex,address from user where id =#{id}")
User selectUserById(int userid);
MyBatis注解开发_二级缓存
MyBatis默认开启一级缓存,接下来我们学习如何在注解开发时使用二级缓存:
- POJO类实现Serializable接口。
- 在MyBatis配置文件添加如下设置:
<settings>
<setting name="cacheEnabled" value="true"/>
settings>
- 在持久层接口上方加注解
@CacheNamespace(blocking=true),该接口的所有方法都支持二级缓存。
MyBatis注解开发_一对一关联查询
在MyBatis的注解开发中对于多表查询只支持分解查询,不支持连接查询。
@Select("select sid, name, age, sex, classId from student")
@Results(id = "studentMapper",value = {
@Result(id = true,property = "sid",column = "sid"),
@Result(property = "name",column = "name"),
@Result(property = "age",column = "age"),
@Result(property = "sex",column = "sex"),
/**
* property:属性名
* column:调用从表方法时传入的参数列
* one:表示该属性是一个对象
* select:调用的从表方法
* fetchType:加载方式
*/
@Result(property = "classes",column = "classId",
one = @One(select = "com.gb.dao.ClassesMapper.selectClassesById", fetchType = FetchType.EAGER)
)
})
/**
* 查询所有学生和所在的班级 (一对一查询)
*/
List<Student> selectAll();
MyBatis注解开发_一对多关联查询
@Results(id = "classesMapper",value = {
@Result(id = true,property = "id",column = "cid"),
@Result(property = "className",column = "class_name"),
@Result(property = "studentList",column = "cid",
many = @Many(select = "com.gb.dao.StudentMapper.selectAllStudentByClassId",fetchType = FetchType.LAZY))
})
/**
* 查询班级和班级里面的所有学生 (一对多查询)
* @return
*/
@Select("select cid,class_name from classes")
List<Classes> selectAll();
注解开发与映射文件开发的对比
MyBatis中更推荐使用映射文件开发,Spring、SpringBoot更推荐注解方式。具体使用要视项目情况而定。它们的优点对比如下:
映射文件:
- 代码与Sql语句是解耦的,修改时只需修改配置文件,无需修改源码。
- Sql语句集中,利于快速了解和维护项目。
- 级联查询支持连接查询和分解查询两种方式,注解开发只支持分解查询。
注解:
- 配置简单,开发效率高。
- 类型安全,在编译期即可进行校验,不用等到运行时才发现错误。
PageHelper分页插件
开发过程中如果要进行分页查询,需要传入页数和每页条数。返回页面数据,总条数,总页数,当前页面,每页条数等数据。此时使用PageHelper插件可以快速帮助我们获取这些数据。
PageHelper是一款非常好用的开源免费的Mybatis第三方分页插件。使用该插件时,只要传入分页参数,即可自动生成页面对象。
我们使用该插件分页查询所有用户:
- 引入依赖
<dependency>
<groupId>com.github.pagehelpergroupId>
<artifactId>pagehelperartifactId>
<version>5.3.0version>
dependency>
- Mybatis配置文件中配置PageHelper插件
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<property name="helperDialect" value="mysql"/>
plugin>
plugins>
- 使用PageHelper插件
/**
* 分页插件测试
*/
@Test
public void testSelectPage(){
// (1)查询前设置分页参数,参数一:页数,从1开始。参数二:每页条数
PageHelper.startPage(2,2);
// (2)正常查询
List<User> userList = userMapper.selectUser();
// (3)创建页面对象,创建时将查询结果传入构造方法
PageInfo pageInfo = new PageInfo(userList);
// (4)打印页面对象的属性
System.out.println("结果集:"+pageInfo.getList());
System.out.println("总条数:"+pageInfo.getTotal());
System.out.println("总页数"+pageInfo.getPages());
System.out.println("当前页"+pageInfo.getPageNum());
System.out.println("每页条数"+pageInfo.getSize());
}