pytorch实现经典神经网络:VGG16模型之复现
可以参考https://blog.csdn.net/m0_37867091/article/details/107237671



分成 提取特征网络结构+分类结构
模型代码:
此模型写了VGG的几种网络结构
一、官方权重
# official pretrain weights
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
一、 根据论文中模型结构搭建 提取特征网络1部分
首先写了cfgs这个字典
我们以vgg11为例
他的值构建了一个列表
其中数字代表了卷积核个数(通道数)
M代表进入池化工作
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
以VGG11的特征提取网络部分为例:
所谓11就是 8层卷积层+3层池化

二、然后是提取特征网络2部分:
此处定义特征提取网络函数
首先参数以列表形式传进来
这里学一下函数定义传入方法
http://www.manongjc.com/detail/51-busecnjmsdoijob.html
https://www.jianshu.com/p/20d1b512b8b2
1、其中
def make_features(cfg: list):
cfg:list表示传入的是一个配置变量。它是一个list类型,因此用的时候只需要传入对应配置的列表即可。
2、我们首先创建一个空列表叫做layers以存放自己的神经网络。
3、初始设定in_channels=3,因为初始图片是3通道
4、遍历我们传入的配置列表,如果是M,代表进入池化操作,因为计算过,池化的卷积核都是2,stride=2。因此在layers列表中自动添加池化
5、如果不是,进入添加卷积核的操作,输入是in_channels,输出是我们传入列表的当前值。(所有卷积核都是3,stride=1)
6、卷积的每一步后面添加ReLU激活函数减少数据量
7、并且把当前的列表值,赋给v作为下一层卷积的输入
8、最神的来了!
return nn.Sequential(*layers)
*将我们的列表layer,以非关键字参数的行书传入nn.Sequential(layers),可以传入任意数量,星号的作用是解包,把序列里面的元素一个个拆开
这是因为Sequential,一般是以这样非关键字形式传入(当然也可以用字典的形式)

def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
插个楼
https://www.jianshu.com/p/20d1b512b8b2
这里讲解了函数def的一下方法:

三、继承nn.moudule的神经网络主框架
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
首先定义变量features,类别1000种。
类种的features=全局变量种的features(特征)
也就是特征提取部分刚才的 代码二
后面是分类器也就是全连接层
nn.Dropout(p=0.5)的目的是防止过拟合
最后全连接层linear输出的是分类的类别个数
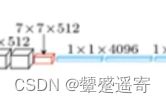
因为全连接层之前最后是7×7×512,所以linear输入是7×7×512
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
定义正向传播函数,我们继承VGG类后,函数传入这里
首先便利列表传入feature内实现提取特征
然后展平 **这里start_dim=1是从第1个维度展开**
flatten就是把(N,C,H,W)的张量,变成(N,C*HW)
展平后进入上面定义好的分类网络结构
这里start_dim=1是从第1个维度展开
因为第0个维度是batchsize
四个维度是(batchsize,channel,H,W) flatten就是把(N,C,H,W)的张量,变成(N,C*HW)
判断是否需要对网络结构进行参数初始化
如果之前class VGG(nn.Module):
def init(self, features, num_classes=1000, **init_weights=**False):
这里为TRUE时则初始化
if init_weights:
self._initialize_weights()
我们再来看一下初始化函数:
首先会便利网络的每一个子模块,
如果当前层是 卷积层 则会进入xavier初始化方法
去初始化卷积核的权重
如果卷积核采用了偏置
则会被置为变量0;
如果当前层是 全连接层(linaer) 则会进入xavier初始化方法
同理如果卷积核采用了偏置
则会被置为变量0;
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
四、实例化我们VGG网络的方法:
通过给定model_name来实例化自己需要的模型
以“vgg16”为例
我们将model_name(vgg16)这个key值传入到定义好的字典中,得到vgg16后面的一系列列表:
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
通过model实例化我们第三步定义的VGG网络:将cfg
的列表传入vgg网络的make_feature内。。
model = VGG(make_features(cfg), **kwargs)
return model
**kwargs代表可变长度字典变量,
就是这些东西都可以传进去

以上,就是我们VGG网络的整体
也就是model.py的内容
整体代码:
import torch.nn as nn
import torch
# official pretrain weights
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
assert in的用法:
assert () // 断言,用于判断一个表达式,在这里,这个表达式是'pre_boxes' in outputs,仅在条件为false时触发,且一般写在代码的开始处。
() = 'pre_boxes' in outputs // in 关键词,用于判断关坚持是否在字典中,存在则返回true,不存在则返回false。
————————————————
版权声明:本文为CSDN博主「蛊惑one」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/guhuoone/article/details/124540721
五、训练部分代码:
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
主要讲一下预处理这里:
随即裁剪
随机翻转。
转为tensor格式
发现在一般人写的代码中:
在预处理环节会分别用rgb剪去123.68,116.78,103,94
这三个值对应着 Imgnet数据集所有数据三通道的均值
如果自己采用迁移学习的方式,则需要有这一步。
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=nw)
这里num_workers线程数,如果是windows就是0
其他ubuntu可以改线程
这里输入自己要用的模型
model_name = "vgg16"
net = vgg(model_name=model_name, num_classes=5, init_weights=True)
参数会保存model.py中

六、一些想法:
1、dropout随即失活
全连接层linear后dropout防止过拟合

最后一步linear后面不加dropout是由于
linear最后的输出是 类的数量
随即失火反而会出错
2、from tqdm import tqdm
tqdm是运行时动态展示训练的情况、比如进度条啥的
3、导入model.py时红色下划线:
把上级目录设置为根目录即可