Unittest数据驱动
Unittest数据驱动
测试数据与功能代码是要分离开的
- 代码轻易不会去动,而数据可以经常修改
- 代码可以由自动化工程师来写来维护,而测试数据可以由其他人来写
- 有些系统测试数据的量非常大,自己一个人来不及,必须要给别人能够协助自己的方法,这时就可以用到数据驱动
执行自动化测试的时候,数据驱动框架就从外部根据函数的参数个数,读取一组数据,然后将这组数据,按照函数参数的个数拆分到具体的函数参数上,进行执行。函数执行的次数取决于外部数据的条数,就不用自己写for循环了,只要写数据就行
两个广泛应用的数据驱动的框架,一个是ddt,一个是parameterized
ddt是unittest中应用,parameterized是pytest中应用。
ddt的安装
pip3 install ddt
ddt的使用
@ddt 装饰测试类
@data或者@file_data来装饰需要驱动的测试方法
举例—只传单参数
@data的位置就是我实际上要传的参数
我有三个参数,所以会执行三遍
@data(“手机”, “电脑”, “书包”)
# 数据驱动
# ddt的使用
import unittest
from selenium import webdriver
from ddt import ddt, data, file_data
from time import sleep
# 写一个测试用例类
@ddt
class MyShop(unittest.TestCase):
def setUp(self):
# 打开浏览器
self.driver = webdriver.Chrome()
# 设置隐式等待
self.driver.implicitly_wait(20)
# 设置窗口最大化
self.driver.maximize_window()
# 设置初始路径
self.base_url = "http://shop.pro.17lebo.com/"
def tearDown(self):
# 退出浏览器
self.driver.quit()
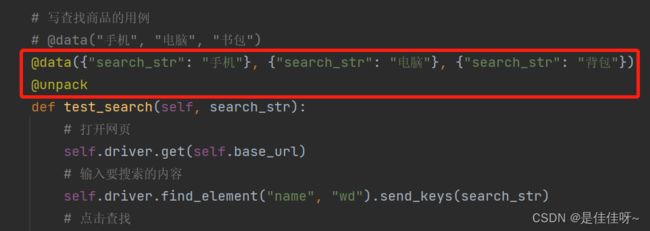
# 写查找商品的用例
@data("手机", "电脑", "书包")
def test_search(self, search_str):
# 打开网页
self.driver.get(self.base_url)
# 输入要搜索的内容
self.driver.find_element("name", "wd").send_keys(search_str)
# 点击查找
self.driver.find_element("id", "ai-topsearch").click()
# 等待5秒,方便查看
sleep(2)
# 执行
if __name__ == '__main__':
unittest.main()
此外,也支持字典格式,字典格式需要解包。@unpack是解包
举例—传多组多个参数
# 数据驱动
# 多组多个参数
# 登录
import unittest
from selenium import webdriver
from ddt import ddt, data, file_data,unpack
from time import sleep
from selenium.webdriver.common.by import By
# 写一个测试用例类
@ddt
class MyShop(unittest.TestCase):
def setUp(self):
# 打开浏览器
self.driver = webdriver.Chrome()
# 设置隐式等待
self.driver.implicitly_wait(20)
# 设置窗口最大化
self.driver.maximize_window()
# 设置初始路径
self.base_url = "http://shop.pro.17lebo.com/"
def tearDown(self):
# 退出浏览器
self.driver.quit()
# 写登录用例
@data({"username": "lebo19_001", "password": "lebo19.001"}, {"username": "lebo19_002", "password": "lebo19.002"}, {"username": "lebo19_003", "password": "lebo19.003"})
@unpack
def test_login(self, username, password):
# 打开网页
self.driver.get(self.base_url)
# 点击登录
self.driver.find_element(By.PARTIAL_LINK_TEXT, "登录").click()
# 等待2秒,方便查看
sleep(2)
# 进入登录页面后输入用户名和密码
self.driver.find_element("name", "accounts").send_keys(username)
self.driver.find_element("name", "pwd").send_keys(password)
# 点击登录按钮
self.driver.find_element("xpath", "//button[text()='登录']").click()
sleep(2)
# 执行
if __name__ == '__main__':
unittest.main()
也可用列表(也需要拆包)
![]()
如果参数太多太长了觉得不好看可以用可变长参数
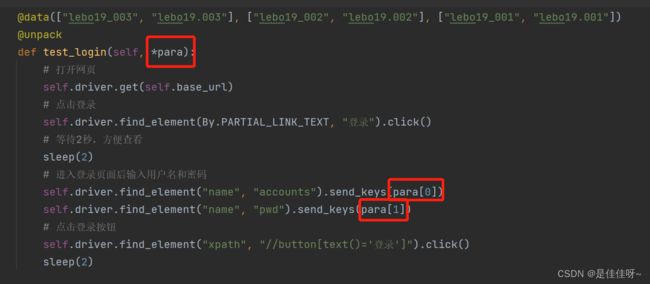
用函数
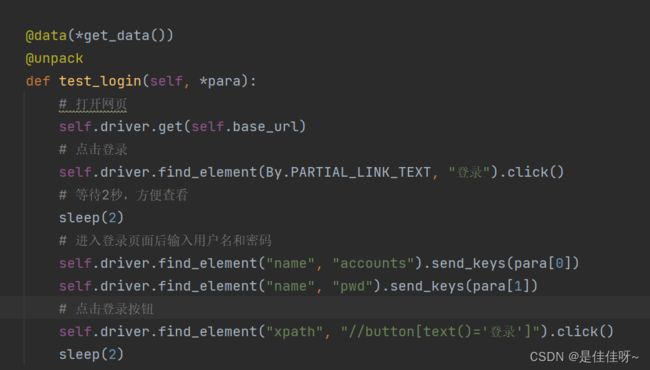
数据都是由函数返回的,返回的是个元组,把元组作为不定长参数放在data后面
import unittest
from selenium import webdriver
from ddt import ddt, data, file_data, unpack
from time import sleep
from selenium.webdriver.common.by import By
# 定义一个函数,这个函数用来存放要传的参数
def get_test_data():
datas = {"username": "lebo19_001", "password": "lebo19.001"},
{"username": "lebo19_002","password": "lebo19.002"},
{"username": "lebo19_003", "password": "lebo19.003"}
return datas
# 写一个测试用例类
@ddt
class MyShop(unittest.TestCase):
def setUp(self):
# 打开浏览器
self.driver = webdriver.Chrome()
# 设置隐式等待
self.driver.implicitly_wait(20)
# 设置窗口最大化
self.driver.maximize_window()
# 设置初始路径
self.base_url = "http://shop.pro.17lebo.com/"
def tearDown(self):
# 退出浏览器
self.driver.quit()
# 写登录用例
@data(*get_test_data())
@unpack
def test_login(self, username, password):
# 打开网页
self.driver.get(self.base_url)
# 点击登录
self.driver.find_element(By.PARTIAL_LINK_TEXT, "登录").click()
# 等待2秒,方便查看
sleep(2)
# 进入登录页面后输入用户名和密码
self.driver.find_element("name", "accounts").send_keys(username)
self.driver.find_element("name", "pwd").send_keys(password)
# 点击登录按钮
self.driver.find_element("xpath", "//button[text()='登录']").click()
sleep(2)
# 执行
if __name__ == '__main__':
unittest.main()
或者

既然可以用函数返回数据,那么这个函数同样可以打开放在项目里的数据文件
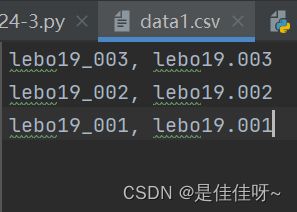
打开csv文件
新建一个csv文件,用逗号间隔数据
import csv
import unittest
from selenium import webdriver
from ddt import ddt, data, file_data, unpack
from time import sleep
from selenium.webdriver.common.by import By
# 获取外部文件
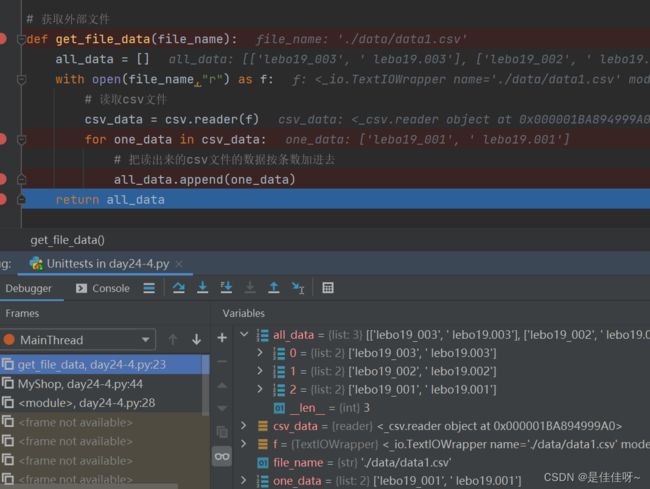
def get_file_data(file_name):
all_data = []
with open(file_name,"r") as f:
# 读取csv文件
csv_data = csv.reader(f)
for one_data in csv_data:
# 把读出来的csv文件的数据按条数加进去
all_data.append(one_data)
return all_data
# 写一个测试用例类
@ddt
class MyShop(unittest.TestCase):
def setUp(self):
# 打开浏览器
self.driver = webdriver.Chrome()
# 设置隐式等待
self.driver.implicitly_wait(20)
# 设置窗口最大化
self.driver.maximize_window()
# 设置初始路径
self.base_url = "http://shop.pro.17lebo.com/"
def tearDown(self):
# 退出浏览器
self.driver.quit()
# 读取csv数据文件
@data(*get_file_data('./data/data1.csv'))
@unpack
def test_login(self, *para):
# 打开网页
self.driver.get(self.base_url)
# 点击登录
self.driver.find_element(By.PARTIAL_LINK_TEXT, "登录").click()
# 等待2秒,方便查看
sleep(2)
# 进入登录页面后输入用户名和密码
self.driver.find_element("name", "accounts").send_keys(para[0])
self.driver.find_element("name", "pwd").send_keys(para[1])
# 点击登录按钮
self.driver.find_element("xpath", "//button[text()='登录']").click()
sleep(2)
# 执行
if __name__ == '__main__':
unittest.main()
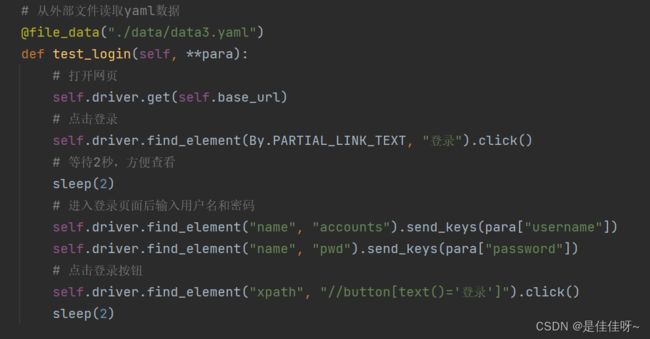
ddt的file_data只支持json文件和yaml文件
json文件
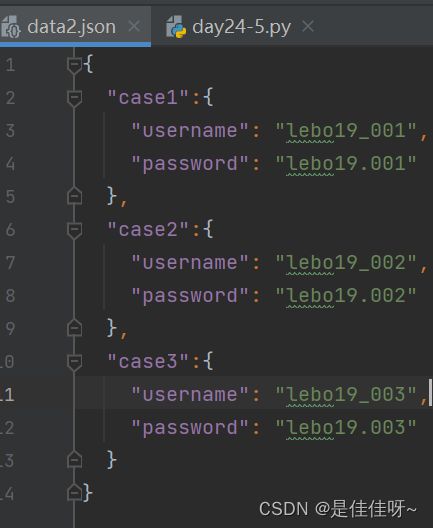
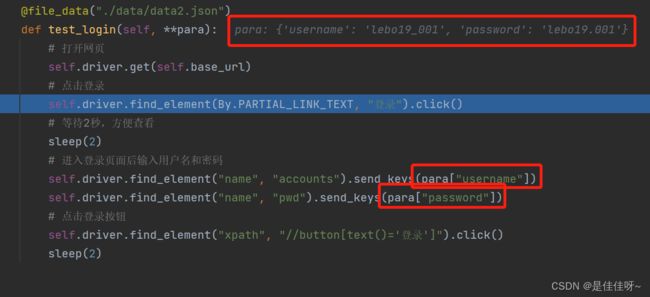
用file_data可以直接跟文件名,读取文件的操作都不用自己做了,也不需要解包unpack了
传进来的数据也是字典格式的,所以要用字典格式来处理(字典的不定长参数是两个星号)
yaml文件(需要下载pyyaml)
yaml文件有自己的语法规则
yaml格式必须对齐
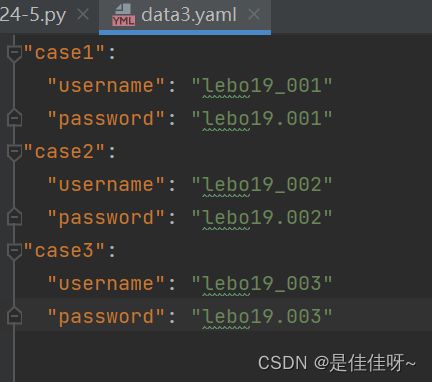
和json格式相比,只有文件名变了,其他都是一致的