算法基础的数据结构模板
文章目录
-
- 一、链表
-
- 1.单链表
- 2.双链表
- 二、堆栈
-
- 1.栈
-
- (1)基本特点
- (2)单调栈
- 2.队列
-
- (1)基本特点
- (2)单调队列
- 三、KMP字符匹配,Trie
-
- 1.KMP字符匹配
- 2.Trie
- 四、并查集
- 五、堆
- 六、散列表
-
- 1.模拟散列表
- 2.字符串哈希
一、链表
由于动态链表new一个新空间的时候耗时较长,因此写算法题时,尽量用数组模拟链表,即静态链表,不需要new,更快速,可以节约很多时间;
1.单链表
const int N=1e8;
int e[N]; //存储节点的值
int ne[N]; //存储节点的next指针
int idx; //表示当前用到了哪个节点
int head; //head存储链表头
void init(void) //初始化
{
idx=0;
head=-1;
}
void insert(int x) //在链表头插入数x(即在链表的最开头插入x)
{
e[idx] = x;
ne[idx] = head;
head = idx++;
}
void add(int k,int x) //在节点后插入数x
{
e[idx] = x;
ne[idx] = ne[k];
ne[k] = idx++;
}
void del(int k) //删除第k个节点后的结点
{
ne[k] = ne[ne[k]];
}
void remove(void) //将当前头结点删除
{
head = ne[head];
}
模板题
2.双链表
使单个节点具有左右两个next指针;
记得main函数中引入初始化!!!
const int N=1e5+10;
int e[N];
int l[N]; //当前节点的左next指针
int r[N]; //当前节点的右next指针
int idx;
void init(void)
{
l[1] = 0; //初始时使得0号节点为头节点,1号节点为尾节点,都不存数值,只是作为链表的起点和终点形式
r[0] = 1;
idx = 2;
}
void insert(int k,int x) //在k号节点右边插上数x
{
e[idx] = x;
l[idx] = k; //建立插入节点与左右节点关系
r[idx] = r[k];
l[r[k]] = idx; //修改左右节点指向,与下一行顺序不能反,否则l[r[k]]会变化
r[k] = idx++;
}
void remove(int k) //删除k号节点
{
r[l[k]] = r[k];
l[r[k]] = l[k];
}
模板题
二、堆栈
1.栈
(1)基本特点
一种后进先出的数据结构;
数组模拟栈:需要一个数组和一个栈顶top指针;
int st[N];
int top=0; //栈顶指针
st[++top] = x; //入栈
--top; //出栈
if(!top) empty; //判断是否为空
else not_empty;
st[top]; //访问栈顶元素
模板题
(2)单调栈
栈中元素大小如下图呈现单调增加或单调减少的趋势;
应用时先用栈按照暴力模拟做法解出题目,然后去掉其中无用的元素,再分析其中的单调性,若剩下元素有单调性,则进行优化;优化后取极值或最值即取两边端点值,查找值可用二分;

一般需要用单调栈的问题就是求一个数左边第一个比它小的数,或者右边第一个比它大的数这种类似的问题;
给定一个长度为N的整数数列,输出每个数左边第一个比它小的数,如果不存在则输出-1。
输入格式
第一行包含整数N,表示数列长度。
第二行包含N个整数,表示整数数列。
输出格式
共一行,包含N个整数,其中第i个数表示第i个数的左边第一个比它小的数,如果不存在则输出-1。
数据范围
1≤N≤105
1≤数列中元素≤109
输入样例:
5
3 4 2 7 5
输出样例:
-1 3 -1 2 2
题目链接
#include 2.队列
(1)基本特点
一种先进先出的数据结构;
数组模拟队列:需要一个数组和两个指针,其中一个是队头指针,另一个是队尾指针;
int q[N];
int head; //队头指针
int tail; //队尾指针
q[tail ++] = x; //入队,队尾插入
++ head; //出队,队头弹出
if(head == tail) empty; //若首尾指针相遇,则队列为空
else not_empty;
q[head]; //队头元素
(2)单调队列
队列中元素大小规律与单调栈类似;
应用时先用队列按照暴力模拟做法解出题目,然后去掉其中无用的元素,再分析其中的单调性,若剩下元素有单调性,则进行优化;优化后取极值或最值即取两边端点值,查找值可用二分;
一般用单调队列的就是窗口滑动类似的问题;
典型问题:窗口滑动
给定一个大小为 n ≤ 1 0 6 n≤10^6 n≤106的数组。 有一个大小为k的滑动窗口,它从数组的最左边移动到最右边。 您只能在窗口中看到k个数字。
每次滑动窗口向右移动一个位置。 您的任务是确定滑动窗口位于每个位置时,窗口中的最大值和最小值。
输入格式 输入包含两行。
第一行包含两个整数n和k,分别代表数组长度和滑动窗口的长度。
第二行有n个整数,代表数组的具体数值。
同行数据之间用空格隔开。
输出格式 输出包含两个。
第一行输出,从左至右,每个位置滑动窗口中的最小值。
第二行输出,从左至右,每个位置滑动窗口中的最大值。

题目链接
参考题目解析:
以样例为例;
我们用q来表示单调队列,p来表示其所对应的在原列表里的序号。
由于此时队中没有一个元素,我们直接令1进队。此时,q={1},p={1}。
现在3面临着抉择。下面基于这样一个思想:假如把3放进去,如果后面2个数都比它大,那么3在其有生之年就有可能成为最小的。此时,q={1,3},p={1,2}
下面出现了-1。队尾元素3比-1大,那么意味着只要-1进队,那么3在其有生之年必定成为不了最小值,原因很明显:因为当下面3被框起来,那么-1也一定被框起来,所以3永远不能当最小值。所以,3从队尾出队。同理,1从队尾出队。最后-1进队,此时q={-1},p={3}
出现-3,同上面分析,-1>-3,-1从队尾出队,-3从队尾进队。q={-3},p={4}。
出现5,因为5>-3,同第二条分析,5在有生之年还是有希望的,所以5进队。此时,q={-3,5},p={4,5}
出现3。3先与队尾的5比较,3<5,按照第3条的分析,5从队尾出队。3再与-3比较,同第二条分析,3进队。此时,q={-3,3},p={4,6}
出现6。6与3比较,因为3<6,所以3不必出队。由于3以前元素都<3,所以不必再比较,6进队。因为-3此时已经在滑动窗口之外,所以-3从队首出队。此时,q={3,6},p={6,7}
出现7。队尾元素6小于7,7进队。此时,q={3,6,7},p={6,7,8}。
那么,我们对单调队列的基本操作已经分析完毕。因为单调队列中元素大小单调递*(增/减/自定义比较),
因此,队首元素必定是最值。按题意输出即可。
作者:Tyouchie
链接:https://www.acwing.com/solution/content/2499/
#include 三、KMP字符匹配,Trie
1.KMP字符匹配
KMP算法真的难,多思考思考吧;
可求循环节;
关键是模板串p与模板串s匹配的时候,p的移动并不是暴力做法那样一位位移动,而是跳着移动,即利用已经匹配好的部分same,在s后面未匹配的部分中寻找与same相同的部分,再跳到该部分,如p=abc,s=abdabfabdabc,此时p与s中ab是相同的,即相同部分same=ab,所以在s中找ab即可,具体实现是由next数组完成,而next数组是通过p与自身匹配后得出的,实际上next数组的得出与kmp匹配类似,不同的是前者为p与p匹配,后者p与s匹配;匹配过程中s与p中指针j的物理位置是不变的,j= next[j],实际上是整个模板串p的向右移动,移动到具有s中相同部分same处,而这样相对来看就是j向左移动了。且实际上j只能在p上面移动,即j的移动范围是0~n,(初始为0,n为p的长度),且j之前的都是匹配成功的,所以匹配失败j就向前移动,若无法匹配则j=0,匹配成功j就在p上++,即向右移动,若j移动到p末尾n的位置,就说明整个模板串p都成功匹配了;
但是强也是真的强,时间复杂度为O(n+m),即O(n);
给定一个模式串S,以及一个模板串P,所有字符串中只包含大小写英文字母以及阿拉伯数字。
模板串P在模式串S中多次作为子串出现。
求出模板串P在模式串S中所有出现的位置的起始下标。
输入格式
第一行输入整数N,表示字符串P的长度。
第二行输入字符串P。
第三行输入整数M,表示字符串S的长度。
第四行输入字符串S。
输出格式
共一行,输出所有出现位置的起始下标(下标从0开始计数),整数之间用空格隔开。
数据范围
1≤N≤105
1≤M≤106
输入样例:
3
aba
5
ababa
输出样例:
0 2
#include 模板题链接
解释一下下标从1开始的好处,首先KMP算法的核心就是要理解next数组的含义。
当下标从0开始时,next[i]表示子串s[0,i]的最长相等前后缀的前缀最后一位的下标,如果我们要求出这个子串的最长相等前后缀的长度时,需要next[i]+1;
当下标从1开始时,next[i]依然表示子串s[1,i]的最长相等前后缀的前缀最后一位的下标,而且next[i]就是这个子串的最长相等前后缀的长度(这也是next[i]数组的另一层含义),不需要我们再去人为加1了。
从另一个角度来讲,下标从0开始时,next[i]=-1,表示我们找不到相等的前后缀。如果下标从1开始,next[i]=0,表示最长相等前后缀的长度为0,也就是说没有相等的前后缀,显然后者更符合我们的一般思路。
所以推荐大家最好从下标为1开始输入。
参考文献 胡凡-算法笔记
时间复杂度分析:
首先,在每次i++的过程中,j最多只会增加一次,因此j总共最多增加M次,而while循环中j总共的回退次数不可能超过它增加的次数,因此while循环中j最多回退M次,所以 KMP 匹配过程时间复杂度为 O(M)。Next[ ]求解时间复杂度为 O(N)。
因此,整个算法的总时间复杂度为 O(M+N)
参考题解1
参考题解2
参考题解3
2.Trie
Trie是一种高效地存储和查找字符串集合的数据结构(一颗树);

模板题链接
#include 数值型Trie数题
#include 四、并查集
作用:
1.合并两个集合;
2.询问两个元素是否在同一个集合当中;基本原理:
1.用一棵树来表示一个集合;
2.树根的编号就是整个集合的编号;
3.每个节点存储它的父节点,p[x]就是x的父节点,根节点的父节点就是它本身;
实现细节:
if(p[x] == x) True; //1.判断树根
int find(int x)//2.求x的集合编号,即通过递归结合路径压缩求对应根节点
{
if(p[x] != x)
p[x] = find(p[x]);
return p[x];
}
p[y] = x;//3.合并两个集合,如让集合y成为集合x的子树
并查集优化方法: 路径压缩
还可通过添加其他变量来维护集合某些性质,如添加一个数组记录集合中节点数量可以维护集合内部节点数;
模板题
#include 较复杂模板题链接
五、堆
功能:
1.插入一个数;
2.求集合当中的最值(大根堆,小根堆);
3.删除最值;
4.删除任意一个元素;//4,5在STL中只能间接实现,不能直接实现
5.修改任意一个元素;
建堆的时间复杂度是O(n),
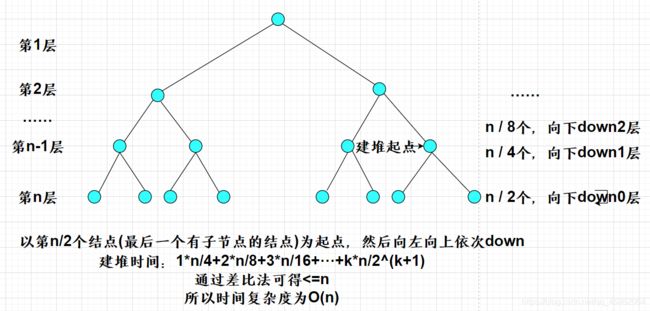
堆排序模板题
简单无映射堆:
#include 较复杂有映射堆
模板题链接
若全局数组值作为函数参数,可能会在函数中把本来不该改变的全局数组值给修改掉,因此不能直接传全局数组值,因此提前设置一个变量,使其代替该全局数组值;
#include 六、散列表
1.模拟散列表
有两种创建散列的方法:
一是开放寻址法,即如果插入元素与表内元素发生位置上的冲突,插入元素就会移动到空位置再插入;
二是拉链法,用个数组表示每个hash后的值,然后数组的每个槽上连一条单链表;
散列表的操作一般只有插入和查找两种操作,删除的话并不是直接删除元素,而是在对应位置做个bool标记;
散列表模板题
(1)开放寻址法
#include (2)拉链法
#include 2.字符串哈希
字符串前缀哈希法
h[n] = 前n个字符的hash值(数值)
hash过程:
(1)将字符串str看成p进制的数,位数为str.size;
(2)计算值,转化为10进制数,如str = “abc”,则 n u m = a ∗ p 2 + a ∗ p 1 + c num = a*p^2+a*p^1+c num=a∗p2+a∗p1+c;
(3)将值取模q,即将hash值映射到0~q-1,num = num % q;
这样可以将任意字符串映射到0~q-1;
注意事项:
(1)不能将某个字符映射成0,如h(a) = 0,则h(aa)= 0也成立,这样就会有冲突;
(2)p =131或13331,且 q = 2 64 q = 2^{64} q=264,这样几乎不会发生hash冲突;
若已知h[R]和h[L-1](R>L,h[R]是前R个字符的hash值)
则 h [ R − L ] = h [ R ] − h [ L − 1 ] ∗ p R − L + 1 h[R-L] = h[R] - h[L-1]*p^{R-L+1} h[R−L]=h[R]−h[L−1]∗pR−L+1;(先让h[L-1]乘上p的R-L+1次方,使得其与h[R]对齐,然后相减即得结果)
预处理:(类似前缀和)
h [ i ] = h [ i − 1 ] + s t r [ i ] h[i] = h[i-1] + str[i] h[i]=h[i−1]+str[i]
字符串hash模板题
#include