基于UE4的多RHI线程实现
1 UE4的现有多线程架构
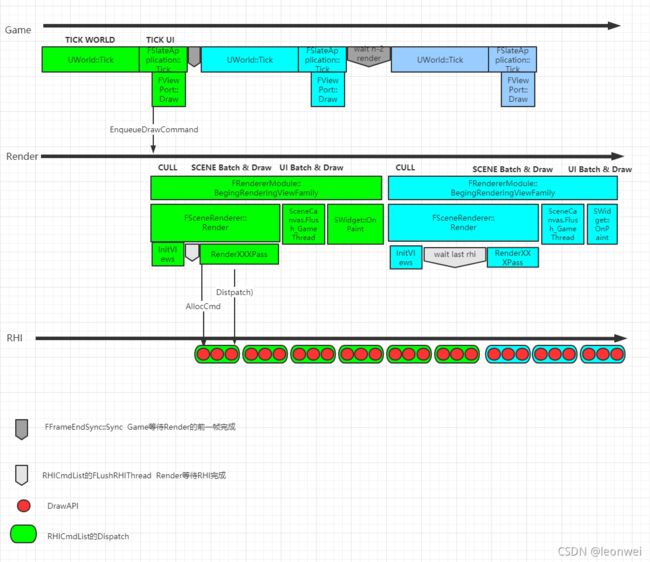
UE的多线程渲染结构如下图, 它有几个特点
- game thread 负责逻辑tick,render thread 负责culling、batching和draw api的生成, rhithread 负责drawapi的执行
- game和render两个线程最多可以差一帧,即前后两帧的gam额和render可以并发,通过Fframeendsync做同步
- render 和rhi之间的关系是帧内的合作关系,即不能达到前后两帧render和rhi的并发,前一帧的drawapi最多在下一帧的culling完成时完成。
2 为什么需要更多的RHI线程
在相当多的情况下,RHI线程仍然会成为瓶颈,例如更复杂的场景,伴随更多的渲染状态切换同更多的drawcall,RHI线程的瓶颈典型的有以下两种情况:
大量dracall
这种情况存在大量的api call调用,通常是场景的物件量实在过大,如下图,它的瓶颈实际上发生在cpu driver对api command的serilize到cmd buffer的过程中,因为单个rhi线程只拥有单个cmdbuffer的serialize能力,所以造成瓶颈。

对这种情况,可以优化的方向是基于vulkan/METAL等先进api,他们具有多个command buffer,开启多个rhi线程,在多个rhi线程中并行serrielize api commmands。
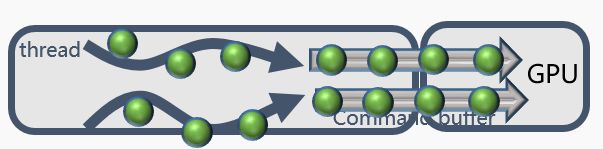
如果是gles平台,这样做则意义不大,因为gles只能提供一个并发的command buffer供serialize
heavy api call瓶颈
有些api call的开销是巨大的,它通常需要在cpu的driver内进行大量的数据操作,这种api本文称为heavy api,以gles为例,典型如:
- glBufferData()
- glBufferSubData()
- glCompressedTexImage2D() and glCompressedTexImage3D()
- glCompressedTexSubImage2D() and glCompressedTexSubImage3D()
- glTexImage2D() and glTexImage3D()
- glTexSubImage2D() and glTexSubImage3D()
- glcompileshader and glshadersource
- gllinkprogram
- …
这些大多为资源准备型的api call,在很多android机上一次glcompileshader调用可能要上百ms,相比之下通常的gldrawprimitive则开销很小,通常在0.1ms以下,heavy api call的瓶颈如下图
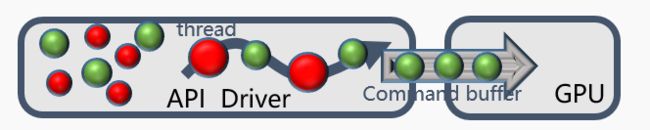
其中红色为heavy api,而绿色的为drawprimitve api。可以看到heavy api卡住了正常drawprimitve api的输送,瓶颈不在“serielize”而是在cpu侧driver对api的处理。
对于这种情况,可以考虑的优化是将heavy api同drawprimitive api分离,使用单独的线程处理heavy api,以使drawprimitive api更顺畅的被提交。如下图

在实际项目中,heavy api call带来的RHI线程瓶颈比单纯的大量drawcall本身要严重,即RHI通常是卡在对api的处理上,而不是对api的serielize上,所以我们常说drawcall多并不一定就会卡,drawcall多只是会更加容易触发渲染状态的改变,继而更加容易触发heavy api call的发生。
此外对heavy api call的优化在gles这种低端机使用的平台上也能奏效,更有实际意义。
所以在我的项目中,主要进行了“将heavy api call分离到单独rhi线程”这种多RHI线程优化。
3 “分离heavy API call”的多RHI线程的设计思想
3.1 总体架构
我们为UE增加了更多的RHI线程。UE原本的这个RHI线程本文称为主RHI线程,或“Draw RHI Thread”, 而新增的一个或多个RHI线程称做辅助RHI线程,或“Auxiliary RHI Thread”。我们将原本主rhi线程上的heavy api call分离出来放在auxiliary rhi thread上运行。整体的多线程渲染架构如图

auxiliary rhi上运行了很多heavy api call,为draw rhi准备好资源
3.2 多RHI线程间的关系和同步策略
这里最大的难点是将原有一条线上有时序关系的api command 队列的执行分布到了多条线上,同时要保证每个drawprimitive api发生时它所需要的资源已经在auxliary 线程上准备好。
api call之间存在三种依赖形式:
- 1 drawprimitive call对资源准备 api call(buffer,shader,texture)的依赖
- 2 资源准备api call对另一个资源的依赖(gllinkprogram需要依赖所使用的shader编译好)
- 3 资源在cmd buffer中途的状态改变(如绘制原语a之前和绘制原语b之前的某个ub内容发生改变)
3.2.1 drawprimitive对资源(buffer shader texture)的依赖
一个最容易想到的策略是“资源预测式”,即我们能够提前预测到对资源的使用,保证在draw rhi thread处理到primtive之前,早已经在auxiliary rhi thread上处理好resouce,(例如在物件加载时就去处理RHI资源,赶在渲染前处理好),这种方式对代码的破坏巨大,需要在很多地方插入预处理资源rhi的代码。此外这种方式不够稳妥,某些资源如果在使用前没有处理好依然会卡住 draw rhi thread。
我们目前采用的方式是“no ready no use”,即resouce api还是在原有时机产生,只是发送到auxliary rhi thread 处理,在draw rhi thread上,使用这个resource前检查其是否ready,如果没有准备好,则后续的primitive取消绘制。这种方案的结果就是在资源准备好之前物件不显示,类似于streaming加载。
这种方式的机制如下图:

- render thread产生的所有 rhi cmd要同时发送给draw和auxliary两个thread
- draw thread 使用前只检查资源状态
- auxilary thread真正处理资源
- draw thread上的drawprimitive可能因为res没有准备好而被在当前帧取消绘制(延迟出现)
3.2.2 处理资源之间的依赖
使用一个全局的表记录每个资源当前的状态,例如pending/ processing/ waiting/ ready,当依赖的资源没有ready的情况下,这个资源的处理就会在线程上waiting

这种waiting会导致aux rhi thread的阻塞,影响效率,我们优化成下图,即跳过这个需要waiting的资源,将该cmd重新加入队尾,后面再执行

3.2.3 处理资源的状态改变
这种情形比较复杂,目前只在aux thread上处理静态资源改变,如shader的编译,static buffer的创建等。
4 其他细节
Gles上实现多线程访问
在gles上,可以使用多个线程访问gles资源,但是需要遵从一些规范:
-
需要为每个rhi线程创建单独的egldrawsurface,eglreadsurface和eglcontex,并在该rhi线程上调用eglmakecurrent将egldrawsurface,eglreadsurface和eglcontex三者进行绑定,创建durface和context的代码补充在了AndroidEGL::InitContexts()和AndroidEGL::CreateEGLSurface()中,对三者进行绑定的代码在void AndroidEGL::SetAuxRenderingContenxt(uint32 AuxIndex)中
-
如果a线程需要访问b线程创建的gl resource,那么a线程的eglcontext必须是b线程的eglcontext的parent,只有单向的线程间资源访问,这意味着只有drawrhithread能够访问au rhi thread创建的资源,反之不能,draw rhi的eglcontext需要设置为所有aux rhi的eglcontext的parent
5 其他问题
使用多少个Auxiliary RHI Thread是合适的?
这取决于运行机器有多少个小核,为了不影响功耗,我们将Auxiliary RHI Thread绑定在小核上运行,超过小核数量的线程数意义不大,主流android机一般至少有4个小核,所以最多开启4个aux rhi thread是没问题的
为什么在gles上实际shader和program的编译都放在了同一个aux thread上?
在测试中发现,在主流机器的gles实现上,即使是不同的shader的编译,在多个线程上依然会存在较大的互斥区发生线程间的等待,这个情况同样发生在shader的编译和program的link上,所以使用多个aux thread的效率不能提升太多。