数据结构9——树和二叉树
文章目录
- 树
-
- 树和非树
- 有关树的术语
-
- 根节点、父节点、子节点
- 度:
- 层次和高度
- 祖先和子孙:
- 树结构的表示:
- 二叉树:
-
- 二叉树的逻辑结构
- 特殊的二叉树
- 二叉树的存储结构
- 二叉树的性质
树
前面我们学习的都是一对一的数据结构,可现实中还存在许多一对多的结构需要处理。这时就需要用到数据结构树了。
树结构广泛存在于现实世界中,公司的组织机构,书的章节等。在计算机应用中,最为人们熟悉的就是磁盘中的文件夹,即文件目录,他包含文件和文件夹。
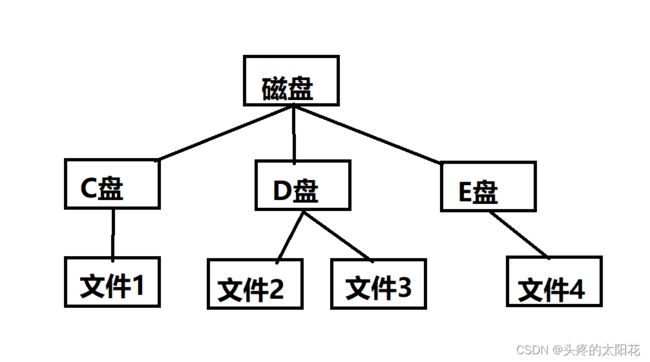
树是n 个节点的有限集合,当n=0时, 该树为空树,否则,树为非空树。这是一个非空树的概念图(AB…H都是树的节点)。

树和非树
注意:在一个树结构中:每一个节点只能由一个父节点,但是可以由多个孩子节点。
树和非树
有关树的术语
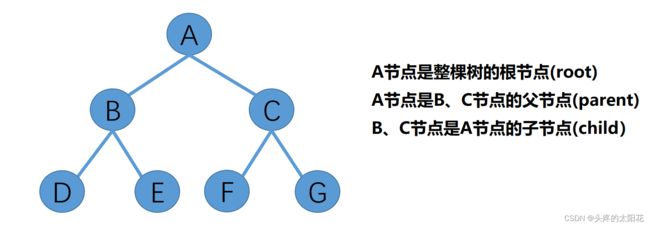
根节点、父节点、子节点
节点也可以称为结点。
一个节点包含了一个数据项以及指向其他节点的分支 。
在数据结构“树”中,第一个节点被称为根节点root。
-
树是一个非线性的结构
-
树有一个特殊的节点, 称为根节点,和现实中每一棵树有很多根须不同,在数据结构中每一棵树只有一个根节点。
-
树的定义是一个递归的定义,即树的定义中又用到了树的概念。
对于上面这一颗树中,我们可以理解为A树是由B、C两棵树组成。
对于B树,B 节点是该树的根节点,DE分别是他的两个子节点。

度:
节点的度:该节点所拥有的子树棵树。
叶子节点或者终端节点:度为0 的节点就是叶子节点
分支节点或者非终端节点:度不为0 的节点
树的度:整棵树中最大节点的度就是树的度。

层次和高度
从根开始定义,根为第一层,根的子节点为第二层,以此类推。(这个概念没有强制要求,也可以将根节点定义为第0层,这样根节点的子节点就是第一层……)
树的高度:树的高度等于它的最大层数。

祖先和子孙:
节点的祖先和子孙:从根到该节点所经分支的全部节点是该节点的祖先,一个节点的根的子树中所有的节点都是该节点的子孙
注意:在数据结构中,一个节点的祖先节点和子孙节点包括该节点本身。

树结构的表示:
树结构其实是不容易表示出来的,主要原因是因为一棵树中某个节点孩子的数量不确定。
在定义线性表结构的时候,我们知道每一个节点后面最多只会有一个节点,所以我们可以通过数组或者链表中的一对一结构来将多个数据联系起来。
但是在定义树的时候,如果无法确定一个数据项需要对应多少个数据项。所以我们会面临这些问题
1.我们不知道树的度,我们无法确定需要多大的空间来存放子节点的指针。
2.如果我们指定了一棵树的度,那么我们可以利用指针数组来保存数中的各个节点。
#define N 4
struct TreeNode
{
DataType data;
struct TreeNode* sub[N];
}
但是这个方法会存在很大的空间浪费问题:我们需要将每一个节点的度视为最大节点,从而为他们开辟出足够大的空间来存放子节点的指针。
孩子兄弟表示法
在所有用来存储树的结构中,这种结构是最优秀的。
该结构的定义是:
typedef int DataType;
struct TreeNode
{
DataType data; //节点中存储的数据。
struct TreeNode* firstChild; //指向第一个孩子节点
struct TreeNode* pNextBrother; //指向下一个兄弟节点
}
在这个结构中,如果没有子节点,那么firstChild 指针为空指针,
如果后面没有兄弟节点,那么nextBrother指针为空指针。

下面是其中四个节点(ABDE)的内容,可以方便理解孩子兄弟表示法:
其中A节点中的内容是:
firstChild = pB; //该节点保存第一个子节点的地址。 nextBrother = NULL; //该节点保存下一个兄弟节点的地址。B节点中的内容:
firstChild = pD; nextBrother = NULL;D 节点中的内容:
firstChild = NULL; nextBrother = pE;E 节点中的内容:
> firstChild = NULL; nextBrother = pF;
二叉树:
二叉树就是一颗指明了度为2 的树,即每一个节点最多有两个子节点。
二叉树的逻辑结构
这是一颗典型的二叉树:

对于这颗二叉树每一个根刚好有两个子树,每一棵子树作为根节点时又有两颗子树。
注意:二叉树有一个很重要的性质:二叉树有序的。
简单理解就是:二叉树是分左右子树的,左右子树不能随意颠倒。
二叉树的几种状态:
二叉树的每一个非空节点可以有4种不同的状态:

特殊的二叉树
1.满二叉树
满二叉树是特殊的完全二叉树
满二叉树:每一层的节点都是最大值。
如果一棵树的的层次为k,并且总结点个数为(2^k)-1,那么这棵树就是慢二叉树

2.完全二叉树
完全二叉树:前k-1层是满的,最后一层不一定是满的,但是一定是从左往右连续的

所以说,满二叉树是一种特殊的完全二叉树
二叉树的存储结构
二叉树的逻辑结构是一个根节点可以指向一个左子树,也可以指向右子树。
在物理结构上,由于二叉树的结构十分清晰,所以我们可以实现为链式二叉树,也可以实现为数组型二叉树。
链式二叉树:在定义每一个节点的时候都需要两个指针,一个指针指向左子树,一个指针指向右子树。一个结构用来存储数据。
我们每一个节点的结构应该是这样的:
typedef char HPDAtaType;
typedef struct BinaryTreeNode{
BinaryTreeNode *left; //存储左子节点的地址
BinaryTreeNode *right; //存储右子节点的地址
HPDataType data; //存储数据
}BTNode;
第一个指针指向左子树的根节点,第二个指针指向右子树的根节点,第三个变量用来存储数据。
然后将类型重定义为
BTNode
如果我们要实现一个这样的二叉树:

我们可以这样将数据存储进去:我们用NULL来代表是空节点。(这里只是为了可以明显看出树的结构)
int main()
{
BTNode *node_a = malloc(sizeof(BTNode));
BTNode *node_b = malloc(sizeof(BTNode));
BTNode *node_c = malloc(sizeof(BTNode));
BTNode *node_d = malloc(sizeof(BTNode));
BTNode *node_e = malloc(sizeof(BTNode));
BTNode *node_f = malloc(sizeof(BTNode));
node_a->left = node_b;
node_a->right = node_C;
node_b->left = node_d;
node_b->right = NULL;
node_c->left = node_e;
node_c->right = node_f;
node_d->left = NULL;
node_d->right = NULL;
node_e->left = NULL;
node_e->right = NULL;
node_f->left = NULL;
node_f->right = NULL;
return 0;
}
数组型二叉树:
我们可以让二叉树的根节点作为下标为0 的位置,然后一层一层的将二叉树中的数据放入数组中:

我们知道二叉树的特点是可以通过父节点找到对应的两个子节点(两个子节点都存在),那么如果我们利用这样一种数组的形式来表示树,是否还可以达到“通过父节点找到子节点”的要求呢?答案是可以的。
在数组中,每一个数据都有着自己独一无二的下标。而父节点和子节点的下标又有相互对应的关系:
通 过 父 节 点 找 到 左 子 节 点 的 下 标 : c h i l d 左 = p a r e n t ∗ 2 + 1 通过父节点找到左子节点的下标: child_左 = parent*2+1 通过父节点找到左子节点的下标:child左=parent∗2+1
通 过 父 节 点 找 到 右 子 节 点 的 下 标 : c h i l d 右 = p a r e n t ∗ 2 + 1 通过父节点找到右子节点的下标:child_右 = parent *2 + 1 通过父节点找到右子节点的下标:child右=parent∗2+1
同样,当我们知道一个节点的下标的时候,我们可以找到他的父节点的下标
通 过 子 节 点 ( 无 论 左 节 点 还 是 右 节 点 ) 找 到 父 节 点 的 下 标 : p a r e n t = ( c h i l d − 1 ) / 2 通过子节点(无论左节点还是右节点)找到父节点的下标:parent = ( child-1) / 2 通过子节点(无论左节点还是右节点)找到父节点的下标:parent=(child−1)/2
实际上二叉树是用数组来表示的嘛?
使用数组作为二叉树的物理存储结构也有缺点:有时候会十分浪费空间,比如这样一个二叉树:
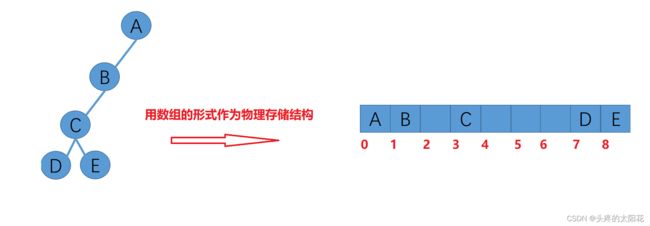
我们可以看出,遇到这样一种结构的二叉树,我们还去使用数组作为存储结构的话就太浪费空间了。
但是如果是一个完全二叉树:利用这种数组存储结构就会减少很多的空间浪费:

对比下来我们可以发现:两种存储形式都有它的使用场景。
一般结构的二叉树我们可以利用链式存储结构,这样可以节约内存
如果是完全二叉树,我们可以利用数组存储结构。实际上,数据结构中的堆就是完全二叉树利用数组存储结构实现的。
二叉树的性质
-
若规定根节点的层数为
1,则一颗非空二叉树的第i层上最多有(2^i)-1个节点如果这棵树的前
i-1层都是度为2的节点,那么此时第i层上的节点最多,计算该层节点数量可以用等比数列的公式计算:
-
若规定根节点的层数为
1,则深度为h的二叉树的最大节点数是2^h-1如果这个二叉树是一个满二叉树,那么此时就可以达到最大节点
层数 个数 1 2^0 = 1 2 2^1 = 2 3 2^2 = 4 … … h 2^(h-1) 总 数 : 2 0 + 2 1 + 2 3 . . . + 2 h − 1 = 2 h − 1 总数:2^0+2^1+2^3...+2^{h-1}=2^h-1 总数:20+21+23...+2h−1=2h−1
-
对于任何一颗二叉树 ,如果度为
0的叶节点个数为n,那么度为2的节点的个数是n-1如图:
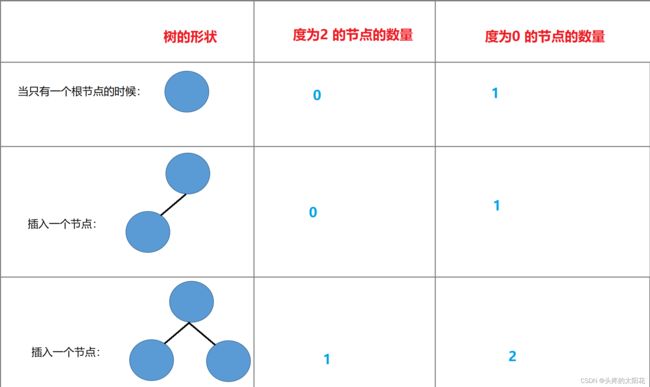
可以看出来:当只有一个根节点的时候,度为0 的节点数量是1,度为2 的节点数量是1
后面每加一个度为0 的节点,就会多一个度为2 的节点。所以度为2 的节点的数量远远比度为0 的节点的数量少1。
-
若规定根节点的层数为1 ,具有
n个节点的满二叉树的深度是h = log2(n+1)以2为底,n+1为对数。对于满二叉树:如果根节点的层数是1, 那么深度h 和总结点的树量关系可以又前面计算等比数列的方法求出:
s u m 总 节 点 数 = 2 h − 1 ; sum_{总节点数} = 2^h - 1; sum总节点数=2h−1;h 层 数 = l o g 2 ( s u m + 1 ) ; h_{层数} = log_2^{(sum+1)}; h层数=log2(sum+1);
-
对于具有
n个节点的完全二叉树,如果按照从上到下,从左至右的顺序存储在数组中,则对于序列为i的节点有:a.
若i > 0,则i位置的父节点下标是(i-1)/2;若i=0,则说明i是根节点,没有父节点。
b.
若2 * i+12 * i+1;若2*i+1>=n就没有左孩子节点这里一共右十个节点,左孩子节点的下标是9,9<10;所以该节点的左孩子节点是存在的。
c.
若2 * i+22 * i+2;若2*i+2>=n就没有右孩子节点