孙哥Netty视频笔记总结
视频在这儿:https://blog.csdn.net/weixin_43996338/article/details/133771464
【视频来源于:B站up主孙帅suns Spring源码视频】【微信号:suns45】
【更多面试资料请加微信号:suns45】
https://flowus.cn/share/f6cd2cbe-627a-435f-a6e5-1395333f92e8
【FlowUs 息流】suns-Java资料
访问密码:【请加微信号:suns45】
文章目录
- 1、Nio的组件有哪些?
- 2、Nio常用的方法有哪些?
- 3、NIO的服务端建立过程
- 4、聊聊:BIO、NIO和AIO的区别?
- 5、如何减少空转?
- 6、如何减少重复的accept
- 7、cancel的作用是什么?
- 8、数据如果一次性没有写完怎么办?
- 9、reactor模型有哪些?
- 10、谈一下零拷贝
- 11、客户端关闭也会触发读操作吗?
- 12、如何给读感兴趣事件代码加保护?
- 13、如何给读感兴趣事件代码加异常保护?
- 14、半包粘包的原因?以及如何解决半包粘包问题?
- 15、网络连接常见的问题有哪些?
- 16、在服务写数据之后我们会发出多个0呢?原因是什么呢?
- 17、单线程服务端角度这种流量控制有什么问题?
- 18、OP_WRITE在什么情况下会使用?
- 19、怎么知道ByteBuffer有没有写完?
- 20、Nio写数据的完整流程是什么?
- 21、单线程版的reactor
- 22、如何在两个线程中保证运行顺序呢?
- 23、多线程版Reactor
- 24、NioEventLoopGroup是什么?
- 25、NioEventLoop和DefaultEventLoop有什么区别?
- 26、当netty的work线程做比较耗时的操作怎么办?
- 27、异步和多线程有什么关系?有什么区别呢?
- 28、Netty的Promise和原生Future有什么差别吗
- 29、Netty的Promise主要是解决了什么问题?
- 30、runable和callable异步处理的两个问题?为什么使用promise就没有问题?
- 31、Netty异步设计的原理
- 32、关于写业务是否会使用到Promise呢?
- 33、当bootstrap.connect()时,为什么future.sync阻塞了,还需要去异步处理呢,这个步骤是不是多余的
- 34、添加监听的顺序是否会影响到future的监听?
- 35、Netty为什么要自己再封装一套Channel?
- 36、Netty封装channel提供哪些API(方法)
- 37、调用channel.close需要注意什么?
- 38、为什么channel.close程序客户端还是未结束运行?
- 39、请你说下你handler的作用,pipeline是什么呢?pipeline和handler以及ChannelHandlerContext他们之间的关系又是什么?
- 40、请你说下handler之间是如何传递数据的?
- 41、如果handler无需传递数据又该怎么办呢?
- 42、pipeline有几个默认的handler分别是什么?
- 43、handler和childrenHandler有什么区别吗
- 44、为什么NettyClinet的bootstrap的handler不能设置NioServerSocketChannel只能设置NioSocketChannel呢?而NettyServer的ServerBootStrap可以设置NioServerSocketChannel以及childrenHandler可以设置NioServerSocketChannel呢?
- 45、请你说下整个netty的服务端运行过程
- 46、如何方便的测试Netty的Handler
- 47、输入时会走head和tail吗,输出时会走head和tail吗
- 48、ByteBuf相对于java原生的ByteBuffer的优势
- 49、如何获得ByteBuf
- 50、ByteBuf最大的内存空间Integer最大值是多少?
- 52、如何获得ByteBuf,ByteBuf有什么特点?
- 53、自动扩容的规律是什么呢?
- 54、堆内存和直接内存的关系,以及特点
- 55、池化的好处
- 56、netty默认开启池化吗?
- 57、被废弃的数据在Bytebuf还存在吗?
- 58、如何重复读一个ByteBuf?
- 59、ByteBuf read和get的区别是什么?
- 60、ByteBuf内存释放 是不是回收,清空,销毁?
- 61、Netty是如何释放内存的?
- 62、Netty是通过什么释放内存的?
- 63、ByteBuf什么时候需要释放呢?
- 64、什么情况下会使用切片?使用切片需要注意什么?
- 65、数据传输过程
- 66、发送方内核态Socket缓冲区和接收方Socket内核区一样吗?
- 67、用户缓存区大 还是 Socket缓冲区大?
- 68、Socket缓冲区和滑动窗口的区别
- 69、流量控制->滑动窗口是什么?
- 70、Socket缓冲区数据是如何到达网卡呢?
- 71、write()返回值含义是什么呢?
- 72、Socket缓冲区 默认大小是多少?
- 73、Netty如何获得ByteBuf?
- 74、如何修改Netty创建的ByteBuf默认大小?
- 75、Netty 封装了channel 可以设置TCP 接受缓冲区大小参数
- 76、半包粘包如何解决?
- 77、什么是编解码器?
- 78、codec是什么?
- 79、Netty中编解码的体现
- 80、有哪些编解码方式呢?以及各自的优缺点1、java序列化 和 反序列化
- 81、具体的编解码器是那两个?
- 82、 Netty常见的编解码器 有哪些?它们有啥特殊的地方吗?
- 83、MessageToMessage门派编解码器与ByteToMessage&&MessageToByte的区别有哪些?
- 84、封帧相关的有哪些Handler
- 85、序列化和编解码区别
- 86、那些编解码自带封帧呢?
- 87、使用StringDecoder或者StringEncoder需要注意什么呢?
- 88、pipeline的调用与Message个数相关
- 89、如何限定handler中msg的类型呢?
- 90、SimpleChannelInBound作用
- 91、channelRead和channelRead0的区别?
- 92、HTTP编解码器相关有哪些?
- 93、Http协议的解码器,会出现半包粘包问题么?
- 94、编解码器合二为一如何自定义?
- 95、ReplayingDecoder有什么作用吗?
- 96、编码器ByteBuf数据 一次处理不完有什么后果吗?
- 97、如何自定义系统的通信协议?
- 99、Pipeline里面到底有几个Handler呢?
- 100、channel的生命周期方法都有哪些?
- 101、异常的处理是如何处理的?
- 102、总结handler
- 103、IdleStateHandler
- 104、如何应对当客户端没有问题但是服务器把客户端的链接给关掉这种情况?
- 105、WebSocketServerProtocalHandler有什么作用?
- 106、 WebSocket干什么用的?
- 107、WebSocket发送消息过程中需要注意什么?
- 108、Handler处理过程中 什么情况下可以被多个pipeline共用【使用Shareable 】?
- 109、关于公用Handler需要注意什么地方?
- 110、如何公用?以及公用Handler的含义?
- 111、Channel什么时候关闭?
- 112、netty客户端的参数是怎么设置的?服务端的参数是怎么设置的?
- 113、RCVBUF_ALLOCATOR设置的内容以及作用?
- 114、RCVBUF_ALLOCATOR如何主动设置?
- 115、SO_RCVBUF & SNDBUF的作用
- 116、SO开头的参数有什么意义呢?
- 117、Socket缓冲区大小如何修改呢?它和滑动窗口是什么关系呢?
- 118、RCVBUF_ALLOCATOR 和 SO_RCVBUF & SNDBUF的区别是什么?
- 119、如何控制是池化内存还是非池化内存?
- 120、如何控制netty使用直接内存还是非直接内存?
- 121、TCP_NODELAY的作用
- 122、CONNECT_TIMEOUT_MILLIS的作用
- 123、SO_BACKLOG的作用
- 124、三次握手四次挥手
- 125、三次握手和四次挥手的本质是什么?
- 126、为什么TCP连接的时候是3次?2次不可以吗?
- 127、为什么TCP连接的时候是3次,关闭的时候却是4次?
- 128、三、为什么客户端发出第四次挥手的确认报文后要等2MSL的时间才能释放TCP连接?即为什么客户端在TIME-WAIT阶段要等2MSL?
- 129、如果已经建立了连接,但是客户端突然出现故障了怎么办?
- 130、SO_REUSEADDR的理解
- 131、为什么需要SO_REUSEADDR这个方式?
- 132、SO_KeepAlive有使用场景吗?
- 133、SO_KeepAlive工作过程
- 134、为什么有了KeepAlive还需要心跳?
- 135、Http协议1.1,保证 有限长连接 KeepAlive头 60秒和Tcp的keepAlive有什么区别呢?
- 136、HTTP和TCP的关系
1、Nio的组件有哪些?
- NIO(New I/O)是 Java 提供的用于高效处理 I/O 操作的一种机制,它包含以下几个组件:
- Channel(通道):Channel 是 NIO 中的基本组件,它代表了一个可以进行读写操作的实体,可以是文件、网络连接、管道等。Channel 提供了非阻塞的读写操作,可以实现异步的 I/O 操作。
- Buffer(缓冲区):Buffer 是 NIO 中用于读写数据的容器。在读取数据时,将数据从 Channel 读取到 Buffer 中;在写入数据时,将数据从 Buffer 写入到 Channel 中。缓冲区提供了对数据的统一管理和操作,可以高效地完成数据的读写操作。
- Selector(选择器):Selector 是 NIO 中的多路复用器,它可以同时监控多个 Channel 的 I/O 状况。通过 Selector,可以实现单线程高效处理多个 Channel 的 I/O 事件。Selector 提供了基于事件驱动的开发模式,可以有效地提高系统的吞吐量。
- SelectionKey(选择键):SelectionKey 是 Selector 和 Channel 之间的关联标记。每个注册在 Selector 上的 Channel 都会对应一个 SelectionKey。通过 SelectionKey 可以获取到关联的 Channel、就绪事件集合以及附加的对象信息。
- Pipe:两个线程之间的单向数据连接,数据会被写到sink通道,从source通道读取
这些组件共同构成了 NIO 的基本框架,可以实现高效地进行 I/O 操作。相比于传统的阻塞 I/O,NIO 提供了非阻塞的操作模式和复用器的支持,能够更好地应对高并发的情况,并提升系统的性能。
2、Nio常用的方法有哪些?
-
在 NIO 编程中,常用的方法有以下几个:
-
Channel#open():打开一个新的 Channel。 -
Channel#close():关闭当前的 Channel。 -
Channel#read(ByteBuffer):从 Channel 中读取数据,并写入指定的 ByteBuffer。 -
Channel#write(ByteBuffer):将指定的 ByteBuffer 中的数据写入到 Channel。 -
Channel#register(Selector, int):将当前的 Channel 注册到指定的 Selector 上,同时指定感兴趣的事件类型(如读、写、连接、接收等)。 -
Selector#open():打开一个新的 Selector。 -
Selector#select():阻塞,等待至少一个已注册的事件发生。 -
Selector#selectedKeys():返回一个包含已选中事件的集合(SelectionKey 的集合)。 -
SelectionKey#isReadable():判断是否有可读的数据。 -
SelectionKey#isWritable():判断是否可以写入数据。 -
SelectionKey#isConnectable():判断是否可以建立连接。 -
SelectionKey#isAcceptable():判断是否可以接收新的连接。 -
ByteBuffer#allocate(int):分配一个新的 ByteBuffer。 -
ByteBuffer#flip():切换到读模式,准备从缓冲区中读取数据。 -
ByteBuffer#clear():切换到写模式,准备写入数据到缓冲区。 -
ByteBuffer#put():将数据写入缓冲区。 -
Buffer#rewind():重置 position 为 0,准备重新读取缓冲区。
这些方法提供了一系列的操作,可以进行数据的读取、写入以及通道的打开、关闭等。需要根据具体的需求和业务逻辑来选择和使用合适的方法,以实现高效的 NIO 编程。同时,还可以结合使用选择器(Selector)和事件驱动模型,实现多个通道的并发管理和处理。
-
3、NIO的服务端建立过程
-
在 NIO 编程中,建立 NIO 服务端的一般过程如下:
-
创建 Selector:使用
Selector.open()方法创建一个 Selector 实例,用于处理多个通道的事件。 -
创建 ServerSocketChannel:使用
ServerSocketChannel.open()方法创建一个 ServerSocketChannel 实例,用于监听和接收客户端的连接。 -
绑定端口:使用
ServerSocketChannel.bind()方法将 ServerSocketChannel 绑定到指定的 IP 地址和端口。 -
设置为非阻塞模式:通过调用
ServerSocketChannel.configureBlocking(false)将 ServerSocketChannel 设置为非阻塞模式。 -
注册 Selector:使用
ServerSocketChannel.register()方法将 ServerSocketChannel 注册到 Selector 上,并指定感兴趣的事件类型(如接收连接事件)。 -
循环处理事件:通过调用
Selector.select()方法阻塞等待就绪事件,一旦有就绪事件发生,就能够得到一个就绪事件集合(SelectedKeys)。 -
处理就绪事件:遍历就绪事件集合,根据事件类型执行对应的业务逻辑。对于接收连接事件,可以使用
ServerSocketChannel.accept()方法接收客户端的连接,并创建对应的 SocketChannel。 -
设置非阻塞模式:通过调用
SocketChannel.configureBlocking(false)将 SocketChannel 设置为非阻塞模式。 -
注册 Selector:使用
SocketChannel.register()方法将 SocketChannel 注册到 Selector 上,并指定感兴趣的事件类型(如读事件、写事件)。 -
循环处理事件:继续循环处理事件,包括读取客户端数据、处理业务逻辑、写入响应数据等。
-
关闭连接:当需要关闭连接时,调用相应的方法关闭对应的通道。
以上就是建立 NIO 服务端的一般过程。需要注意的是,NIO 采用非阻塞的模型,可以通过单线程或少量线程处理多个通道的并发连接,提高系统的并发处理能力。在实际开发中,需要根据具体的业务需求,合理处理事件的注册和处理逻辑,以保证高效和可靠的运行。
-
4、聊聊:BIO、NIO和AIO的区别?
-
BIO(Blocking I/O)、NIO(Non-blocking I/O)和AIO(Asynchronous I/O)是 Java 中处理 I/O 操作的三种不同的编程模型,它们之间存在一些重要的区别:
-
阻塞 vs 非阻塞:
- BIO 是面向流的阻塞 I/O 模型,即在读写操作时,如果数据没有准备好或无法立即处理,调用线程会被阻塞,直到数据准备完毕或操作完成。
- NIO 是面向缓冲区的非阻塞 I/O 模型,即在读写操作时,如果数据没有准备好或无法立即处理,调用线程不会被阻塞,而是继续执行其他任务,直到数据准备完毕或操作完成。
- AIO 是面向事件的异步 I/O 模型,即在读写操作时,如果数据没有准备好或无法立即处理,系统会将整个操作交给操作系统处理,操作完成后,操作系统会通知应用程序。
-
线程模型:
- BIO 采用一个连接一个线程的模型,在有大量的并发连接的情况下,需要为每个连接都创建一个线程,导致资源的浪费。
- NIO 采用一个线程处理多个连接的模型,通过使用选择器(Selector)和非阻塞的方式来实现,可以使用较少的线程处理多个连接。
- AIO 则是完全的异步模型,不需要主动的轮询和选择器等机制,可以通过回调函数或者 Future 对象来处理异步操作的结果。
-
编程复杂度:
- BIO 的编程方式相对简单,使用字节流和字符流进行读写操作。
- NIO 提供了 Channel、Buffer、Selector 等更为复杂的抽象,需要较高的熟悉程度和编程技巧。
- AIO 在 NIO 的基础上提供了更为高层次的异步接口,相对于 NIO 更加方便和易用。
总的来说,BIO 适用于连接数较少且连接时间较长的场景,NIO 适用于连接数较多且连接时间较短的场景,而 AIO 适用于高并发、连接数较多且数据传输量比较大的场景。选择合适的 I/O 模型需要根据具体的应用需求和环境来决定。
-
5、如何减少空转?
使用 Selector 循环监听事件的方式可以有效地减少空转。以下是一个简单的示例代码:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.Set;
public class EventLoopExample {
public static void main(String[] args) {
try {
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.socket().bind(new InetSocketAddress("localhost", 8080));
serverChannel.configureBlocking(false);
// 创建 Selector,并将 ServerSocketChannel 注册到 Selector 上,并绑定相应的事件
Selector selector = Selector.open();
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
// 阻塞等待就绪事件
int readyCount = selector.select();
if (readyCount > 0) {
Set<SelectionKey> readyKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = readyKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
// 处理就绪事件
if (key.isAcceptable()) {
// 处理连接事件
handleAccept(key);
} else if (key.isReadable()) {
// 处理读事件
handleRead(key);
} else if (key.isWritable()) {
// 处理写事件
handleWrite(key);
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
private static void handleAccept(SelectionKey key) throws IOException {
// 处理连接事件的逻辑
ServerSocketChannel serverChannel = (ServerSocketChannel) key.channel();
SocketChannel clientChannel = serverChannel.accept();
clientChannel.configureBlocking(false);
// 注册读事件
clientChannel.register(key.selector(), SelectionKey.OP_READ);
}
private static void handleRead(SelectionKey key) throws IOException {
// 处理读事件的逻辑
SocketChannel channel = (SocketChannel) key.channel();
// 读取数据
// ...
}
private static void handleWrite(SelectionKey key) throws IOException {
// 处理写事件的逻辑
SocketChannel channel = (SocketChannel) key.channel();
// 写入数据
// ...
}
}
在上述示例中,通过创建一个 Selector 并将 ServerSocketChannel 注册到 Selector 上,通过循环调用 select() 阻塞等待就绪事件。当有就绪事件发生时,通过迭代选中的就绪键集合,根据键的类型进行相应的处理逻辑。在处理完事件后,从就绪键集合中移除该键。
这种基于 Selector 的事件循环模型可以在等待事件时避免空转,最大程度地提高系统的并发处理能力。通过非阻塞地监听事件,可以充分利用 CPU 资源,避免无谓的等待,提高程序的效率和响应性。
6、如何减少重复的accept
确实,在处理就绪事件的时候,使用 iterator.remove() 可以将已处理的 SelectionKey 对象从 SelectionKeys 集合中移除,以避免重复处理同一个就绪事件。
以下是示例代码,在处理就绪事件时使用 iterator.remove():
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
// 处理就绪事件
if (key.isAcceptable()) {
// 处理连接事件
handleAccept(key);
} else if (key.isReadable()) {
// 处理读事件
handleRead(key);
} else if (key.isWritable()) {
// 处理写事件
handleWrite(key);
}
}
在每次处理完一个就绪事件后,调用 iterator.remove() 将对应的 SelectionKey 从就绪键集合中移除,确保下一次循环不会再处理该就绪事件。这样可以防止重复处理同一个就绪事件,确保代码的正确性。
需要注意的是,在使用 iterator.remove() 后,需要确保在与该 SelectionKey 关联的处理逻辑中没有再次注册相同类型的事件,否则可能会导致逻辑错误。
7、cancel的作用是什么?
在 Java NIO 的 SelectionKey 中,cancel() 方法用于取消注册的通道与选择器之间的关联关系。取消一个 SelectionKey 可以用于释放资源、终止对应通道的监听以及取消通道的事件。
cancel() 方法的作用包括:
-
释放资源:调用 cancel() 方法后,底层的 Selector 将不再追踪该 SelectionKey,并且将其从内部的键集合中移除。这样可以确保不再浪费资源在已经不需要监听的通道上。
-
取消通道的监听:通过调用 cancel() 方法,可以取消对应通道在选择器上的注册,停止对该通道的事件监听。这可以有效地终止不再需要监听的通道,避免处理不必要的事件。
-
取消通道的事件:当调用 cancel() 方法后,SelectionKey 中关联的通道不再处理对应的事件类型。这表示该通道将不再触发该类型的事件,并且在判断事件类型时返回 false。在需要暂时关闭通道的情况下,可以使用 cancel() 方法取消相关事件,待需要时再重新注册。
需要注意的是,一旦调用了 cancel() 方法,SelectionKey 对象就不再可用,并且无法再使用该 SelectionKey。因此,在调用 cancel() 方法后,需要小心处理相关资源,避免出现使用已取消的 SelectionKey 导致的错误。
总的来说,cancel() 方法的作用是取消选择器与通道之间的关联关系,释放资源,终止监听和取消特定事件,以提高性能和资源利用率。
8、数据如果一次性没有写完怎么办?
对于数据一次性没有写完的情况,可以设置写监听状态,等待Socket缓冲区可写时继续写入剩余的数据。这样可以确保将数据完整地写入通道。
以下是一个示例代码片段,展示如何使用写监听状态来处理数据一次性未写完的情况:
ByteBuffer buffer = ByteBuffer.wrap(data); // 假设数据存在 ByteBuffer 中
// 将数据写入通道
int bytesWritten = channel.write(buffer);
if (buffer.hasRemaining()) {
// 如果数据未完全写入,设置写监听状态,等待Socket缓冲区可写
SelectionKey key = channel.register(selector, SelectionKey.OP_WRITE);
// 将剩余的数据保存在SelectionKey的attachment中
key.attach(buffer);
} else {
// 数据已经完全写入,进行后续处理
// ...
}
在上述示例中,首先将数据写入通道,并通过 channel.write(buffer) 获取写入字节数。如果发现 buffer 中仍有剩余数据(buffer.hasRemaining()),则注册写监听状态(SelectionKey.OP_WRITE)。然后将剩余数据的 ByteBuffer 通过 key.attach(buffer) 方法附加到 SelectionKey 上,以便在下次写入时取回剩余数据。
在监听到写事件发生后,通过 SelectionKey 获取附加的 ByteBuffer,进行剩余数据的写入操作,直到所有数据都成功写入。然后可以进行后续的处理逻辑。
这样通过写监听状态的设置和处理,可以确保数据完整地写入通道,并能够在需要时合理地处理数据的分批写入。
9、reactor模型有哪些?
- 你提到的三种 reactor 模型是常见的基本 reactor 设计模式的变体。下面是对每种模型的简要介绍:
- 基本 Reactor 设计:
- 一个 Reactor 对象负责处理连接和读写操作。
- 当有新的连接到达时,Reactor 负责接收并建立连接。
- 当连接上有数据可读时,Reactor 负责读取数据,并调用相应的处理逻辑进行处理。
- Worker 线程池:
- 一个 Reactor 对象负责处理连接。
- 当有新的连接到达时,Reactor 负责接收并建立连接。
- 当连接上有数据可读时,Reactor 将读取到的数据提交给线程池中的工作线程进行异步处理。
- 工作线程执行相应的处理逻辑,并将处理结果返回给 Reactor。
- 多个 Reactor:
- 一个 Boss Reactor 对象负责处理连接。
- 当有新的连接到达时,Boss Reactor 负责接收并建立连接,并将建立的连接分配给具有独立事件循环的 Worker Reactor。
- 每个 Worker Reactor 负责处理连接上的读写操作。
- 当连接上有数据可读时,Worker Reactor 负责读取数据,并调用相应的处理逻辑进行处理。
这些模型都是为了实现高效的并发网络编程而设计,通过充分利用多线程和事件驱动的特性,提高系统的吞吐量和响应性。具体使用哪种模型需要根据应用场景和需求来决定,选择合适的模型可以提高系统的性能和可扩展性。
10、谈一下零拷贝
零拷贝(Zero-copy)是一种优化技术,旨在减少数据在多个内存缓冲区之间的拷贝,以提高系统性能和效率。在传统的数据传输过程中,数据需要多次在内核和用户空间之间进行拷贝,而零拷贝技术则通过优化数据传输路径,避免了部分数据拷贝的过程。
在传统的拷贝方式中,数据的传输会经过多次拷贝:
- 磁盘数据拷贝到内核缓冲区。
- 内核缓冲区数据拷贝到用户缓冲区。
- 用户缓冲区修改数据后,再次拷贝到内核缓冲区。
- 内核缓冲区拷贝到网络驱动的内核态。
- 最后,网络驱动的内核态拷贝到网卡进行传输。
零拷贝技术有三种常见的实现方式:
- mmap(内存映射):通过利用内存映射的方式,将文件映射到用户空间的内存中,避免了用户态和内核态之间的数据拷贝。
- sendfile:在支持 sendfile 系统调用的情况下,数据可以直接从文件描述符的内核缓冲区拷贝到网络驱动的内核缓冲区,省去了用户态和内核态之间的数据拷贝。
- 高速网络设备的直接内存访问(SG-DMA):当网络设备支持 SG-DMA 技术时,可以直接在内存和网络设备之间传输数据,避免了传统拷贝方式中的内核缓冲区到网络驱动之间的数据拷贝。
需要注意的是,尽管称为零拷贝,实际上 sendfile 仍然有两次数据拷贝。第一次是从磁盘读取数据到内核缓冲区,第二次是从内核缓冲区拷贝到网卡的缓冲区(协议引擎)。只有在使用 SG-DMA 技术时,才能避免数据从 Page Cache 再次拷贝到 Socket 缓冲区。
总结来说,零拷贝是通过减少内存拷贝来优化数据传输的技术,可以提高系统的性能。尽管 mmap 在严格的定义上可能不是真正的零拷贝,但它仍然可以减少一次数据拷贝。而 sendfile 在网卡支持 SG-DMA 技术的情况下,可以实现真正的零拷贝。选择适合的零拷贝技术需要根据具体的使用场景和需求来决定。
11、客户端关闭也会触发读操作吗?
当客户端关闭连接时,服务器端会触发读操作。这是因为在传统的网络编程中,关闭连接一方通常要向对方发送一个关闭连接的请求,这被称为半关闭(half-close)。关闭连接的一方会发送一个特殊的数据包给对方,告知对方自己要关闭连接。
当服务器端收到客户端的关闭请求时,它会对应地触发一个读操作,以读取这个关闭请求,并做出相应的处理。这可以让服务器端正确地关闭连接并释放相应的资源。
需要注意的是,一旦服务器端收到关闭请求并完成相应的读操作后,通常会在后续的处理中关闭连接并释放资源。这是因为,客户端关闭连接后,即使服务器端触发了读操作,后续可能并没有数据可读。所以,服务器端需要判断读操作是否真正有数据可读,如果没有,它可以在读操作后立即关闭连接。
综上所述,客户端关闭连接通常会触发服务器端的读操作,但服务器端需要根据实际情况进行判断并及时关闭连接。
12、如何给读感兴趣事件代码加保护?
在给读感兴趣事件的代码中加入保护措施,可以避免无数据可读时频繁地触发 select 操作。一个常见的保护方式是使用 selectNow() 或 poll(0) 等非阻塞的选择操作来检查是否有数据可读,如果没有,可以调用 cancel() 方法将读感兴趣的事件从选择器中取消。
以下是一个示例代码片段,展示如何在读事件上加入保护:
// 创建选择器
Selector selector = Selector.open();
// 注册读感兴趣事件到选择器
SelectionKey key = channel.register(selector, SelectionKey.OP_READ);
while (true) {
// 非阻塞地检查是否有读事件发生
int readyChannels = selector.selectNow();
if (readyChannels == 0) {
// 没有数据可读,进行保护处理
key.cancel();
break;
}
// 有数据可读,进行处理
// ...
// 处理完数据后,再次感兴趣读事件
key.interestOps(SelectionKey.OP_READ);
}
在上述示例中,我们在一个循环中使用 selectNow() 方法非阻塞地检查是否有数据可读。如果返回的 readyChannels 为 0,表示没有数据可读,我们可以调用 cancel() 方法将读事件从选择器中取消,并跳出循环执行其他保护处理逻辑。这样可以避免频繁地触发 select 操作。
当有数据可读时,我们执行相应的处理逻辑,处理完数据后再次将读事件设置为感兴趣状态,以便下一次进行读操作。
需要注意的是,具体的保护措施需要根据实际情况来决定。例如,在程序中可能需要设置一个计数器,当连续多次检查到没有数据可读时再进行保护处理。或者在保护处理之后,触发某些其他操作来恢复对读事件的兴趣。
保护读事件的措施可以提高程序的效率和资源利用率,确保只在有数据可读时才进行相应的处理。
13、如何给读感兴趣事件代码加异常保护?
在给读感兴趣事件的代码中加入异常保护措施,可以有效地处理读操作可能引发的异常,以避免程序的异常终止或意外行为。以下是一些常见的异常保护方法:
-
使用 try-catch 语句块捕获异常:
try { // 读取数据操作 } catch (IOException e) { // 处理读取异常 }通过在代码中使用 try-catch 语句块,可以捕获可能发生的异常,如 IO 异常。在 catch 语句块中,可以根据具体情况进行相应的异常处理,如记录日志、关闭连接等。
-
在异常发生时取消对读事件的兴趣:
catch (IOException e) { // 处理读取异常 key.cancel(); }当发生异常时,可以调用
cancel()方法将对读事件的兴趣从选择器中取消。这样可以避免在出现异常后不断触发读事件的情况,同时也可以保护代码免受进一步的异常干扰。 -
释放资源:
catch (IOException e) { // 处理读取异常 key.cancel(); channel.close(); }在异常处理过程中,及时释放相应的资源是很重要的。比如,在发生异常后,可以关闭连接或释放其他相关资源,避免资源泄漏和进一步的异常。
-
异常上抛或重新抛出:
catch (IOException e) { // 处理读取异常 throw e; // 或者通过 try-catch 包装后重新抛出 }在一些情况下,对异常进行处理后可能决定将异常上抛给调用方或重新抛出,以便更高层次的代码进行统一的异常处理。这需要根据具体需求和代码结构来决定是否合适。
总之,给读感兴趣事件的代码加入异常保护措施是很重要的,它可以提升程序的稳定性和健壮性。通过合理地捕获、处理异常,并及时释放相关资源,可以使程序更加容错,减少意外行为的发生。
14、半包粘包的原因?以及如何解决半包粘包问题?
半包和粘包是网络编程中常见的问题,原因主要有以下几点:
-
数据传输过程中的分包和合包问题:在网络传输过程中,数据往往会被划分成多个数据包进行传输,但由于网络延迟、带宽限制等原因,可能导致数据包的分割和合并出现错误,从而产生半包和粘包问题。
-
多路复用引起的混淆:在一条 TCP 连接上会同时传输多个请求或响应,当数据包多路复用到达接收方时,可能会发生多个数据包混杂在一起的情况。
解决半包和粘包问题的方法有以下几种:
-
定长包协议:发送端将数据划分为固定长度的包进行发送,接收端根据固定长度来解析数据包。这种方式简单直接,但对于不同长度的数据会造成空间浪费。
-
分隔符协议:发送端在数据包之间添加特定的分隔符,接收端根据分隔符来区分不同的数据包。常用的分隔符有换行符、回车符等。这种方式灵活性较高,可以适应不同长度的数据。
-
消息头部包含长度信息:在数据包的消息头部包含表示数据长度的字段,接收端先根据长度信息读取数据包的长度,然后再根据长度读取相应的数据。这种方式较为常用,但需要考虑字节序的问题。
-
使用消息边界:发送端在每个数据包之前添加特定的标识符,接收端根据标识符来识别数据包的边界。常见的做法是在数据包之前添加一个特殊字符或者特定长度的字节序列作为边界标识。
15、网络连接常见的问题有哪些?
1、网络的分包问题是怎么解决的?
- 一个包1460Bit,如果一个包太大的话,需要分成很多个包去处理。
- 一个包有可能比1460Bit小,取发送方和接收方中最小MSS值,作为包的大小。
2、流量控制问题是怎么解决的?
- 接收方:发送方发包的过程不要太快,让我能接受到。
- 保障接收发有序,不造成接收方数据的丢失,为了达到这个目的,甚至还会为发送空包,保障一个速率。
3、 丢包和重传问题:在数据传输过程中,可能会发生数据包丢失或损坏,需要进行重传。丢包和重传会导致网络拥塞、延迟增加、带宽浪费等问题。为了解决这个问题,可采用可靠传输协议(如TCP),通过确认机制、超时重传等方式来保证数据的完整性和可靠性。
4、延迟问题和速度问题:网络延迟会导致数据传输的时延增加,影响应用的实时性和用户体验。为了降低延迟,可以优化网络拓扑结构、使用加速技术(如CDN)等。而速度问题可能涉及到网络带宽限制、服务端性能等因素,需要对这些因素进行优化和提升。
5、连接失效和超时问题:网络连接在传输过程中可能会因为各种原因断开或失效,导致数据传输中断。为了解决这个问题,可以设置心跳机制、重连机制等来保持连接的稳定性和可靠性。
6、网络安全问题:网络连接可能存在数据泄露、数据篡改、中间人攻击等安全问题。为了保障连接的安全性,可以使用加密传输(如SSL/TLS)、身份验证等安全手段来防止恶意攻击和数据泄露。
7、网络拥塞和瓶颈问题:在高负载情况下,网络连接可能会出现拥塞和瓶颈,导致数据传输速度下降甚至中断。为了解决这个问题,可以通过流量控制、拥塞控制等方式来优化网络资源分配和利用,提升连接的性能和稳定性。
16、在服务写数据之后我们会发出多个0呢?原因是什么呢?
发送多个0的原因可能是为了进行流量控制。
流量控制是一种机制,用于控制数据的发送速率,以避免发送方发送数据过快,导致接收方处理不过来或缓冲区溢出。在某些情况下,为了实现流量控制,发送方需要发送一些空的数据包或特定格式的数据,以保持一个较低的发送速率。
发送多个0作为空包的一种实现方式之一。发送方在数据写入后,发送一系列的0,这样可以使接收方知道发送方仍然活跃,但没有实际数据需要发送。接收方根据接收到的0信息,可以判断发送方的状态并进行调整,避免数据的丢失或过载。
需要注意的是,具体的流量控制机制和数据格式可能会因应用程序、协议或网络环境的不同而有所差异。因此,发送多个0的具体原因和含义可能会因情况而异,需要根据具体的实现和环境来进行分析和理解。

17、单线程服务端角度这种流量控制有什么问题?
在单线程服务端角度下,对于发送多个0的流量控制机制可能存在以下问题:
-
额外的处理开销:发送多个0作为空包需要服务器额外的处理开销,包括调用操作系统的写操作、数据包的封装和发送等,这些操作会增加服务器的负载和资源消耗。
-
延迟增加:发送多个0会增加网络传输的数据量,从而增加了传输延迟,使得实际数据的传输速率下降。
-
资源浪费:由于发送多个0没有实际的数据内容,这样做可能会占用网络带宽和产生不必要的数据传输,从而浪费了服务器的资源和网络资源。
为了解决这些问题,可以考虑以下方法:
-
监控状态:在服务器端,可以通过监控连接状态、接收缓冲区状态或者其他相关的状态信息,来判断是否继续发送数据。只有当接收方的状态表明可以接收数据时,才发送实际的数据,避免发送无意义的0数据。
-
动态调整发送速率:根据服务器的负载情况和网络条件,动态调整数据发送的速率。通过评估服务器的处理能力和网络的带宽,灵活控制发送的数据量,以保证发送和接收的平衡,避免资源的浪费和延迟的增加。
-
使用更有效的流量控制机制:考虑使用更高级的流量控制机制,如滑动窗口协议、拥塞控制算法等,这些机制可以根据网络的状况和实时的反馈信息,更精确地控制数据的发送速率,并减少对服务器资源和网络资源的浪费。
18、OP_WRITE在什么情况下会使用?
在网络编程中,OP_WRITE是指通道可写的操作。它通常与非阻塞IO一起使用,以确保在写操作可用时不会阻塞其他任务。以下情况下会使用OP_WRITE:
1.写操作准备就绪:当写缓冲区不满并且可以写入数据时,OP_WRITE事件被触发。
2.避免阻塞:使用非阻塞IO的程序可以通过监听OP_WRITE事件来避免阻塞写操作。在使用selector监听通道的时候,使用interestOps(OP_WRITE)方法将OP_WRITE事件添加到感兴趣的操作中。
3.提高效率:通过监听OP_WRITE状态,可以避免不必要的写操作,减少系统资源的浪费和延迟。
总的来说,OP_WRITE在使用非阻塞IO进行写操作时起到了重要的作用,它可以让程序在写操作可用时进行写入,并避免阻塞和资源浪费。
19、怎么知道ByteBuffer有没有写完?
通过判断buffer.hasRemaining()方法可以确定ByteBuffer是否写完。该方法返回一个布尔值,如果Buffer中还有剩余的可写入空间,则返回true;如果Buffer已经写满,没有剩余可写入空间,则返回false。
在使用ByteBuffer进行写操作时,可以首先判断buffer.hasRemaining()的返回值,如果为true,则表示还有剩余空间可以写入数据;如果为false,则表示已经写满,无法继续写入数据。
通过这种方式,可以确保不会向已经写满的ByteBuffer写入数据,避免写入数据溢出或造成数据丢失。在使用ByteBuffer进行写操作时,建议在写入之前先判断buffer.hasRemaining(),以确保写入的数据量不超过Buffer的容量限制。
20、Nio写数据的完整流程是什么?
NIO(非阻塞IO)的写数据流程如下:
-
创建一个Selector对象,并将感兴趣的操作注册到Selector上,例如OP_WRITE。
-
创建一个SocketChannel或ServerSocketChannel对象,并将其设置为非阻塞模式。
-
连接到服务器(如果是客户端)或绑定本地地址(如果是服务器)。
-
调用Selector的select()方法进行事件的监听,该方法会阻塞直到有感兴趣的事件发生。
-
通过selectKeys()方法获取到可写事件的集合,遍历集合进行处理。
-
对于每个可写事件,首先判断是否是可连接的事件(如果是客户端),如果是则调用finishConnect()方法完成连接。
-
如果连接已建立(或是服务器,无需连接),就可以开始写入数据。
-
创建一个ByteBuffer用来存储要写入的数据,并将数据写入到ByteBuffer中。
-
调用SocketChannel的write()方法将数据从ByteBuffer写入到通道中。
-
检查返回值,判断是否已经将所有数据写入通道。如果未写完,则需要继续写入。
-
重复步骤8和9,直到所有数据被写入。
-
关闭通道和Selector。
这是一个简单的NIO写数据的流程,可以根据具体的需求进行适当的调整和扩展。通过使用非阻塞IO和选择器(Selector),可以实现高效的IO操作,提高系统的并发处理能力。

21、单线程版的reactor
查看视频
22、如何在两个线程中保证运行顺序呢?
- 放在一个线程中,通过队列衔接。
- 情况一:worker线程先阻塞,然后主线程往队列中添加注册任务,然后主线程唤醒worker线程,worker线程从队列中取出注册任务 完成注册
- wakeup()执行后,select()就不会发生阻塞了。
- 情况一:worker线程先阻塞,然后主线程往队列中添加注册任务,然后主线程唤醒worker线程,worker线程从队列中取出注册任务 完成注册
- 2、使用锁,作为原子操作。
23、多线程版Reactor
查看视频
24、NioEventLoopGroup是什么?
NioEventLoopGroup是Netty框架中的一个重要组件,它是一个线程池,用于管理多个NioEventLoop线程。
在Netty中,所有的网络操作都是异步非阻塞的,这意味着它们不会直接在调用线程上执行,而是由NioEventLoop线程处理。NioEventLoop是Netty的核心组件,它负责处理网络事件,如接收连接、读写操作和定时任务等。
NioEventLoopGroup实际上是NioEventLoop的集合,它会根据系统的CPU核心数或者通过用户指定的参数来创建一定数量的NioEventLoop线程。每个NioEventLoop线程都有一个独立的Selector对象,用于监听和处理IO事件。
NioEventLoopGroup的主要作用是提供了一种可靠和高效的方式来管理NioEventLoop线程,并充分利用多核CPU的优势,实现并行处理网络事件。在Netty应用程序中,通常会创建一个或多个NioEventLoopGroup实例,用于管理服务器端和客户端的NioEventLoop线程。
通过合理地配置NioEventLoopGroup,可以实现高性能、高并发的网络应用程序。同时,NioEventLoopGroup也提供了一些辅助方法,如优雅地关闭所有线程,管理TCP参数等。
25、NioEventLoop和DefaultEventLoop有什么区别?
NioEventLoop和DefaultEventLoop是Netty框架中的两种不同类型的事件循环。
-
NioEventLoop:NioEventLoop是Netty框架中专门用于处理网络IO的事件循环。它基于Java NIO的Selector机制,负责监听和处理连接、读写等网络事件。NioEventLoop使用非阻塞的IO模型,可以高效地处理大量并发连接。每个NioEventLoop都有一个独立的Selector,用于监听和处理IO事件,并且通过多线程技术实现并发处理。
-
DefaultEventLoop:DefaultEventLoop是Netty框架中的一个普通事件循环,它并不直接与网络IO相关。与NioEventLoop相比,DefaultEventLoop更适合在没有网络IO需求的场景下使用。开发人员可以自定义DefaultEventLoop,根据需要执行一系列的任务或逻辑,它可以被视为一个普通的线程池。
在Netty开发中,如果需要处理网络IO事件(如读写数据、接收连接等),一般会使用NioEventLoop。而如果只需要进行一些计算或处理其他非IO相关的任务,可以使用DefaultEventLoop。
总的来说,NioEventLoop是Netty框架中专门用于处理网络IO的事件循环,而DefaultEventLoop是一个普通的线程或线程池,用于处理其他非IO相关的任务。选择使用哪种类型的事件循环取决于具体的需求和场景。
26、当netty的work线程做比较耗时的操作怎么办?
当Netty的工作线程需要执行比较耗时的非IO操作时,一种常见的解决方案是创建额外的线程来处理这些操作,而不是将其直接放在Netty的工作线程中。
具体的做法是使用DefaultEventLoopGroup,它是Netty框架提供的一个普通的事件循环线程池。通过将耗时的非IO操作提交给DefaultEventLoopGroup中的线程进行处理,可以保持Netty的工作线程的高效执行网络IO操作,避免被耗时任务阻塞。
示例代码如下:
EventLoopGroup workerGroup = new NioEventLoopGroup(); // Netty的工作线程池
EventLoopGroup additionalGroup = new DefaultEventLoopGroup(); // 额外的线程池
try {
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
// 添加网络IO相关的处理器
// ...
// 添加耗时的非IO操作处理器,使用additionalGroup
pipeline.addLast(additionalGroup, new YourTimeConsumingHandler());
}
});
// 继续配置和启动服务器...
} finally {
workerGroup.shutdownGracefully();
additionalGroup.shutdownGracefully();
}
在上述代码中,通过传入additionalGroup参数,将耗时的非IO操作处理器(YourTimeConsumingHandler)添加到ChannelPipeline中,使用DefaultEventLoopGroup来处理该处理器的任务。这样就能确保耗时操作不会阻塞Netty的工作线程,提高系统的并发性能和响应性。
需要注意的是,在使用额外的线程处理耗时操作时,要确保线程的合理使用和资源的正确释放,避免出现资源竞争、内存泄漏等问题。同时,根据实际需求和性能测试结果,合理调整线程池的大小和配置,以达到最佳性能。
27、异步和多线程有什么关系?有什么区别呢?
异步和多线程之间确实存在关系,但它们也有一些区别:
-
关系:
- 异步编程通常使用多线程技术来实现。异步操作将任务委托给其他线程来执行,从而实现非阻塞的执行方式。
- 多线程编程可以用于实现同步和异步的操作,不仅限于异步编程。
-
区别:
-
多线程编程:多线程编程是一种并发编程的方式,其中多个线程在同一时间可以并行执行不同的任务。这些线程通常是相互独立的,具有相等的优先级,可以同时访问共享资源。每个线程都有独立的执行路径和上下文。
-
异步多线程:异步编程是一种特殊的多线程编程方式,其中主线程在遇到复杂的、耗时的或阻塞的任务时,将其委托给其他线程异步执行。主线程可以继续执行其他任务,而无需等待异步任务完成。异步线程将执行结果返回给主线程,主线程可以继续处理这些结果。
-
异步多线程的特点在于主线程和异步线程之间的合作关系。主线程可以通过委托异步线程来进行辅助任务的处理,而异步线程负责执行任务的一部分,并且将结果传递给主线程。这种方式可以提高系统的并发性能和响应性。
总的来说,多线程编程是一种通用的并发编程方式,而异步多线程是一种特殊的多线程编程方式,用于实现非阻塞的、具有主线程和异步线程协作的任务执行模型。
28、Netty的Promise和原生Future有什么差别吗
Netty的Promise和原生的Future在功能上有一些差别。
Future是Java标准库中提供的接口,用于表示一个异步操作的结果。它通常用于异步处理的结果的获取和处理。Future提供了同步阻塞和异步监听两种处理方式。同步阻塞方式通过调用get()方法来获取异步操作的结果,该方法会阻塞当前线程直到结果可用。异步监听方式则通过注册回调函数(Listener)来在异步操作完成后进行处理,不会阻塞。
Promise是Netty框架中对Future的扩展,它继承了Future接口,并添加了一些额外的方法。Promise具有异步监听和结果获取的功能,相比于原生的Future,它多了一个可以主动设置结果的能力。这意味着在使用Promise时,不仅可以通过异步监听方式获取结果,还可以主动将执行结果设置到Promise中。
Promise的扩展功能使其更加灵活和强大。使用Promise,可以在异步操作完成后主动将结果设置给它,并通知监听者进行处理。而原生的Future只能依赖异步操作将结果返回。
总的来说,Netty的Promise在使用方式上扩展了原生的Future接口,增加了可以主动设置结果的能力。这使得在某些场景下,使用Promise更加灵活和方便。
29、Netty的Promise主要是解决了什么问题?
Netty的Promise主要解决了以下几个问题:
-
异步处理结果的获取:在传统的异步处理中,使用Runnable作为任务执行单元,无法直接获取异步处理的结果。Promise提供了一个可以主动设置异步操作结果的机制,使得在异步操作完成后可以通过Promise获取结果。
-
表示异步操作的成功或失败:使用Runnable或Callable时,无法直接知道异步操作是成功还是失败。Promise通过设置异步操作的结果,可以明确表示异步操作的成功或失败。通过Promise的状态或异常信息,可以准确地知道异步操作的执行情况。
-
统一异步操作的处理方式:Promise提供了统一的异步操作处理接口,可以通过添加监听器(Listener)来处理操作完成的结果,无论是成功还是失败。这样可以方便地对异步操作进行统一的处理和错误处理。
总体来说,Netty的Promise解决了在异步处理中无法直接获取结果和无法准确表示成功或失败的问题。通过Promise,可以更好地管理和处理异步操作的结果,提高代码的可读性和可维护性。
30、runable和callable异步处理的两个问题?为什么使用promise就没有问题?
使用Runnable接口和Callable接口进行异步处理可能会遇到两个问题:
-
Runnable接口:Runnable接口是一个没有返回值的任务执行单元,无法直接获得异步处理的结果。在主线程(调用者线程)中无法通过Runnable接口获取异步处理的结果。
-
Callable接口:Callable接口是有返回值的任务执行单元,通过使用Callable可以获取异步操作的返回结果。然而,即使通过Callable接口获得了结果,也无法准确地表达结果是成功还是失败。即使使用异常来表示失败,仍然需要拿到结果来判断。
Promise的优势在于它能够解决这两个问题并提供更多的功能:
-
异步处理结果的获取:通过Promise可以获取异步操作的结果。通过Promise的get()方法或添加监听器来获取操作的结果。
-
准确表达异步操作的状态:Promise不仅能够返回异步操作的结果,还可以明确表示异步操作的成功或失败。通过Promise的状态或异常信息,可以准确地知道异步操作的执行情况。
-
封装异步处理的数据:Promise可以封装异步处理的数据,这样可以更清晰地表示异步操作的意图和结果。通过Promise可以统一管理和处理异步操作的数据。
综上所述,使用Promise可以有效解决无法直接获取结果和无法准确表示成功或失败的问题,并且能够更好地封装异步处理的数据。这使得Promise成为处理异步操作的一种强大工具。
31、Netty异步设计的原理

Netty的异步设计原理可以通过以下步骤来理解:
-
异步操作的触发:在Netty的异步设计中,通常由某个事件触发异步操作的执行,例如接收到新的连接、读写数据等。
-
创建Promise对象:在异步操作触发时,会创建相应的Promise对象,用于管理异步操作的状态和结果。Promise是一种可以获取异步操作结果的特殊对象,可以理解为异步操作的承诺。
-
执行异步操作:异步操作会在后台的其他线程或线程池中执行,不会阻塞主线程。在执行异步操作的过程中,可能会有一些回调函数或监听器用于处理异步操作的结果。
-
设置异步操作结果:在异步操作执行结束后,会将结果通过Promise对象返回。如果异步操作成功完成,Promise对象的状态将标记为成功,并包含相应的结果。如果异步操作失败,Promise对象的状态将标记为失败,并包含相应的异常信息。
-
异步结果的处理:可以通过多种方式来处理异步操作的结果。使用Promise的同步阻塞方式可以通过Promise的get()方法来获取结果,这将会阻塞当前线程直到结果可用。使用异步监听方式可以通过添加回调函数或监听器来在异步操作完成后进行处理,不会阻塞主线程。
总的来说,Netty的异步设计利用了Promise对象来管理和传递异步操作的状态和结果。通过Promise,可以以同步阻塞或异步监听的方式获取异步操作的结果,并进行相应的处理。这种设计使得Netty能够高效地处理并发和异步操作,并提供灵活的异步编程模型。
32、关于写业务是否会使用到Promise呢?
在业务代码中,使用Promise的情况相对较少。因为在Netty中,Promise主要用于在底层处理网络、IO等操作时进行异步编程和结果管理。在业务代码中,通常是通过自定义的ChannelHandler来处理业务逻辑。
在业务代码中,主要关注的是业务逻辑的处理,通常不需要直接使用Promise。而是通过ChannelHandler的回调方法,如channelRead()、channelWrite()等,处理业务逻辑。
然而,在Netty内部的实现中,大量使用了Promise来管理异步操作的结果。比如网络连接的建立、数据的读写等都会使用Promise来表示异步操作的完成和结果。通过Promise,Netty可以在异步操作完成后通知相应的监听器进行处理,或者通过Promise的同步阻塞方式等待结果的返回。
因此,虽然在业务代码中使用Promise的情况相对较少,但在Netty内部的底层实现中,Promise是非常重要的工具之一,用于实现异步编程和结果管理。
33、当bootstrap.connect()时,为什么future.sync阻塞了,还需要去异步处理呢,这个步骤是不是多余的
当调用bootstrap.connect()时,使用future.sync()会阻塞当前线程,直到连接成功或发生异常。这样可以确保在连接成功之前,后续的代码不会继续执行,从而保证了连接的同步性。
异步处理的目的是为了在连接建立的过程中,当前线程可以继续执行其他的操作,而不必一直等待连接的完成。这样可以充分利用线程资源,提高系统的并发能力。
虽然future.sync()会阻塞当前线程,但在某些特定场景下,例如在启动阶段或初始化过程中,需要确保连接成功后才能进行下一步的操作。此时,使用future.sync()可以简化代码,避免需要手动处理连接成功后的相关操作。
总的来说,使用future.sync()并不是多余的,它是为了需要保证连接建立的同步性。而异步处理则是为了在连接建立的过程中不阻塞当前线程,提高系统的并发能力。具体使用哪种方式取决于具体的业务场景和需求。
34、添加监听的顺序是否会影响到future的监听?
添加监听的顺序不会影响Future的监听。Future是一个表示异步操作结果的对象,当异步操作完成后,注册的监听器将被触发。
无论监听器是先注册的还是后注册的,只要异步操作完成,所有注册的监听器都会被触发。这意味着,无论监听器的注册顺序如何,它们都有机会接收到异步操作的结果。
这种设计使得Future可以支持多个监听器同时对异步结果进行处理,而不会受到注册顺序的影响。每个监听器都可以独立地处理异步操作完成后的结果,保证了代码的灵活性和可扩展性。
因此,无论在注册监听器时的顺序如何,Future的监听顺序不会受到影响。所有注册的监听器都有机会接收到异步操作的结果。
35、Netty为什么要自己再封装一套Channel?
Netty为什么要自己再封装一套Channel有以下几个原因:
-
统一Channel的编程模型:通过自己封装一套Channel,Netty可以提供一致的编程模型,使得用户在使用不同类型的网络通信(如SocketChannel、ServerSocketChannel等)时不需要进行额外的区分和处理。用户只需要关注业务逻辑的处理,而不必关心底层的网络通信细节,这样提高了开发效率和代码的可读性。
-
更好地与Netty框架结合:Netty的核心是基于事件驱动和异步IO的框架,通过自己封装的Channel,可以更好地与Netty的框架结合起来。Netty的内部实现会根据不同类型的Channel进行相应的处理和优化,例如配置底层的TCP Socket缓冲区大小、滑动窗口等,以提高网络通信的性能和吞吐量。
-
I/O pipeline的支持:Channel是Netty中I/O处理的基本单元,并且Channel可以被组合成I/O pipeline,这样可以实现复杂的事件流处理,如解码、编码、压缩、加密等。通过封装自己的Channel,Netty可以更好地支持整个I/O pipeline的构建和管理,简化了用户在处理复杂的数据流时的编程难度和复杂度。
总的来说,Netty自己再封装一套Channel的目的是为了统一Channel的编程模型、更好地与Netty框架结合,并支持复杂的I/O pipeline的构建和管理,从而提高开发效率、简化代码逻辑,并提供更好的网络通信性能和灵活性。
36、Netty封装channel提供哪些API(方法)
Netty封装的Channel提供了以下常用的API(方法):
-
writeAndFlush(Object msg):将指定的消息写入Channel并刷新缓冲区,使其立即发送出去。 -
write(Object msg):将指定的消息写入Channel,但不会立即发送出去。消息会被存储在内部的缓冲区中,需要手动调用flush()方法刷新缓冲区,将消息发送出去。 -
flush():刷新缓冲区,将已经写入Channel但未发送的数据立即发送出去。 -
close():关闭Channel,释放相关的资源,并断开与远程端口的连接。
这些API使得用户可以方便地进行数据的读写操作和连接的管理。通过write()方法可以将数据写入Channel的缓冲区中,通过flush()方法可以手动触发缓冲区的刷新,将数据发送出去。而writeAndFlush()方法则实现了写入数据后立刻刷新缓冲区的操作,方便快捷。
另外,通过close()方法可以关闭Channel,释放相关资源,关闭与远程端口的连接。这是经常用到的一个方法,用于合理地关闭网络连接,释放占用的资源。
除了以上提到的方法,Netty的Channel还提供了更多的API来支持不同的网络操作需求,例如bind()、writeAndFlush()等,可以根据具体的业务需求进行使用。
37、调用channel.close需要注意什么?
当调用channel.close()方法关闭Channel时,需要注意以下几点:
-
异步操作:关闭Channel是一个异步的操作,即方法调用并不会立即关闭Channel,而是通过事件驱动的方式在后台进行关闭操作。这意味着在调用
channel.close()后,不会立即触发Channel关闭事件,需要等待异步操作完成。 -
同步等待关闭完成:如果希望在关闭操作完全完成后再继续执行后续代码,可以使用
channel.closeFuture().sync()方法进行同步等待。这会阻塞当前线程,直到Channel关闭操作完成或发生异常。同步等待可以确保在关闭操作完成后再继续执行后续的业务逻辑。 -
添加关闭监听器:另一种方式是通过添加关闭监听器来处理关闭完成后的逻辑。可以使用
channel.closeFuture().addListener(ChannelFutureListener)方法来添加监听器,当Channel关闭操作完成时,监听器会被回调执行相应的逻辑。 -
处理关闭事件:在Netty中,关闭Channel会触发相应的事件,例如
channelInactive和channelUnregistered事件。可以通过在ChannelPipeline中添加对应的ChannelHandler来处理这些关闭事件,进行一些必要的资源释放和清理工作。
综上所述,当调用channel.close()关闭Channel时,需要注意异步操作的特性,并根据需求选择合适的方式来确保操作的完成,如同步等待或添加关闭监听器。同时,可以在ChannelPipeline中添加相应的ChannelHandler来处理关闭事件,进行资源的释放和清理工作。
38、为什么channel.close程序客户端还是未结束运行?
当调用channel.close()关闭Channel时,仅仅是关闭了通道,但不会直接导致程序客户端的结束运行。因为在开发网络应用程序时,通常存在多个线程和事件循环来处理网络相关的操作。
关闭Channel只是关闭了与远程端口的连接,释放了相关的资源,但不会直接影响主线程的执行。如果主线程没有其他的阻塞操作或条件来终止运行,程序会继续执行下去,直到达到程序的结束点。
要让程序客户端结束运行,通常需要考虑以下几个方面:
-
关闭事件循环:如果程序中使用了事件循环(EventLoop),需要手动停止事件循环的执行。可以通过调用
eventLoopGroup.shutdownGracefully().sync()方法,关闭事件循环并等待其执行完成,以确保所有的任务都已完成。 -
终止主线程:如果程序中存在一个主线程用于运行核心逻辑,可以通过设置标志变量或发送指定的信号来终止主线程的执行。可以在某个条件或标志变量满足时,通过
System.exit(0)或抛出异常等方式来终止程序。 -
合理设计程序结构:在程序设计时,需要合理设计程序的结构和逻辑,确保在完成所需的操作后,能够优雅地结束程序运行。避免出现无限循环或长时间阻塞的情况,以确保程序能够顺利地结束运行。
总结来说,关闭Channel并不会直接导致程序客户端的结束运行。需要根据具体的情况,通过关闭事件循环、终止主线程或合理的程序设计来确保程序能够正确地结束运行。
39、请你说下你handler的作用,pipeline是什么呢?pipeline和handler以及ChannelHandlerContext他们之间的关系又是什么?
-
Handler在Netty中扮演着处理数据的角色,负责实现具体的业务逻辑。它可以被分为入站(Inbound)和出站(Outbound)两种类型。
-
入站Handler(ChannelInboundHandler)用于处理从网络中接收到的数据,如读取数据、解码数据和处理业务逻辑等。入站Handler接收到的数据从底层的网络层(例如TCP)传递给上层的应用层。
-
出站Handler(ChannelOutboundHandler)用于处理向网络中发送的数据,如编码数据、发送数据和处理业务逻辑等。出站Handler将要发送的数据从应用层传递到底层的网络层。
-
Pipeline(ChannelPipeline)是Netty中用于组织和管理Handler的容器。它通过ChannelHandlerContext来装载和管理Handler。Pipeline类似于一个拦截链,当数据在Channel中流动时,会依次经过Pipeline中的各个Handler进行处理。
-
ChannelHandlerContext是Handler的上下文对象,与具体的Channel和Pipeline相关联。它提供了一些用于操作Channel和Pipeline的方法,以及与其他Handler进行交互的功能。通过ChannelHandlerContext,Handler可以访问Channel和Pipeline的相关方法,并与其他Handler进行数据传递和操作。
-
Pipeline、Handler和ChannelHandlerContext之间的关系是:Pipeline是由一系列的Handler构成的,按照添加的顺序组成了一个处理链。当数据在Channel中流动时,会依次经过Pipeline中的每个Handler进行处理。每个Handler可以通过ChannelHandlerContext与其他Handler进行交互,并操作Channel和Pipeline的状态。
-
需要注意的是,同一类型的Handler在Pipeline中的顺序非常重要,它决定了数据处理的先后顺序。而不同类型的Handler则不需要关注顺序问题,因为它们代表了不同的处理阶段。
-
综上所述,Handler用于处理数据,Pipeline是用于管理Handler的容器,ChannelHandlerContext用于在Handler中进行操作和交互。Pipeline中的Handler按照添加的顺序构成了处理链,数据会依次经过每个Handler进行处理。
40、请你说下handler之间是如何传递数据的?
在Handler之间传递数据,通常使用的是ChannelHandlerContext的相关方法。以下是一种常见的传递数据的方式:
-
在当前Handler中处理数据:当一个Handler接收到数据后,可以在其中对数据进行处理。处理完成后,可以将数据传递给下一个Handler。这可以通过调用
ctx.fireChannelRead(msg)来实现,其中ctx是当前Handler的ChannelHandlerContext对象,msg是要传递的数据。 -
传递给下一个Handler:当调用
ctx.fireChannelRead(msg)时,会触发Pipeline中的下一个Handler的channelRead方法。这样就将数据传递给了下一个Handler进行处理。这个过程会一直沿着Pipeline中的Handler顺序进行,直到最后一个Handler。 -
数据传递的顺序:数据在Pipeline中的传递是按照Handler添加的顺序逐个进行的。当一个Handler调用
ctx.fireChannelRead(msg)后,会将数据传递给下一个Handler。如果有多个Handler,数据会被依次传递给每个Handler进行处理。 -
信号的传递:除了数据,Handler之间还可以通过发送信号来进行交互。例如,在某个Handler中处理某个条件时,可以通过调用
ctx.fireUserEventTriggered(event)来触发Pipeline中的下一个Handler的相关逻辑。
需要注意的是,数据的传递和信号的传递是通过事件驱动的方式进行的,不是直接的方法调用。当一个Handler调用相关的方法后,触发相应的事件,通过事件循环机制将数据或信号传递给下一个Handler。
总结来说,在Netty中,Handler之间通过调用ChannelHandlerContext的相关方法来实现数据的传递。通过触发Pipeline中的下一个Handler的处理逻辑,数据会在Pipeline中顺序传递给每个Handler进行处理。同时,还可以通过发送信号来进行交互和通知。
41、如果handler无需传递数据又该怎么办呢?
如果Handler无需传递数据,可以直接结束当前Handler的处理逻辑,不调用super.channelRead()或ctx.fireChannelRead(msg)方法。
当一个Handler不需要处理接收到的数据,并且不需要将数据传递给下一个Handler时,可以直接结束当前Handler的执行。这意味着在当前Handler中不做任何处理或直接返回,不调用上述的数据传递方法即可。
例如,在channelRead方法中,如果当前Handler不需要处理接收到的消息msg,可以直接结束方法的执行:
public void channelRead(ChannelHandlerContext ctx, Object msg) {
// 不需要处理消息,直接返回
return;
}
这样,数据不会被传递给Pipeline中的下一个Handler,处理链会在当前Handler中结束。
需要注意的是,由于Netty的设计机制,通常情况下每个Handler都会有一些业务逻辑需要处理或将数据传递给下一个Handler。如果某个Handler不需要处理数据,那么可以考虑是否需要在Pipeline中添加这个Handler。只添加必要的Handler能够提高程序的效率和简化代码结构。
总结来说,如果Handler无需传递数据,可以直接返回或结束当前Handler的处理逻辑,不调用super.channelRead()或ctx.fireChannelRead(msg)方法。这样数据不会被传递给Pipeline中的下一个Handler。
42、pipeline有几个默认的handler分别是什么?
在Netty的Pipeline中,确实有两个默认的Handler,分别是HeadContext和TailContext。
-
HeadContext(头部上下文):HeadContext是Pipeline的开始位置,它是第一个处理入站数据的Handler。它负责处理入站事件,并将其传递给后续的Handler。
-
TailContext(尾部上下文):TailContext是Pipeline的结束位置,它是最后一个处理出站数据的Handler。它负责处理出站事件,并将其发送到网络。
除了这两个默认的Handler,Pipeline中的其他Handler都是用户自定义的。这些Handler按照添加的顺序连接在HeadContext和TailContext之间,形成一个完整的处理链。
以一个示例Pipeline为例:
HeadContext -> Handler1 -> Handler2 -> Handler3 -> TailContext
当数据流经这个Pipeline时,数据会从HeadContext开始,逐个经过Handler1、Handler2和Handler3进行处理,最后到达TailContext,然后发送到网络中。每个Handler都可以对数据进行处理或者将数据传递给下一个Handler。
需要注意的是,Pipeline中的Handler的添加顺序非常重要,它决定了数据在Pipeline中的流动顺序。因此,在构建Pipeline时需要注意按照业务逻辑的要求,将Handler以正确的顺序添加到Pipeline中。
总结来说,Pipeline中有两个默认的Handler,分别是HeadContext和TailContext。其他的Handler都是用户自定义的,按照添加的顺序形成一个处理链。数据从HeadContext开始流动,经过各个Handler的处理,最后到达TailContext。数据的处理顺序由Handler的添加顺序决定。
43、handler和childrenHandler有什么区别吗
在Netty中,有两种类型的Handler,分别是Handler和ChildHandler。
-
Handler:Handler是用于处理ServerSocketChannel的连接建立和监听的。它负责接收客户端的连接请求,并将请求转发给对应的ChildHandler处理。Handler通常被添加到ServerBootstrap的ChannelPipeline中,用于处理ServerSocketChannel相关的操作。
-
ChildHandler:ChildHandler是用于处理SocketChannel的数据读写操作的。它负责实际处理客户端与服务端之间的通信。ChildHandler通常被添加到ServerBootstrap的ChildHandler配置中,用于处理每个客户端连接的SocketChannel。
区别:
- Handler负责处理ServerSocketChannel,主要负责接收连接请求。它在ServerBootstrap的ChannelPipeline中,用于处理ServerSocketChannel相关的操作。
- ChildHandler负责处理每个连接的SocketChannel,主要负责实际的数据读写操作。它在ServerBootstrap的ChildHandler配置中,用于处理每个客户端连接的SocketChannel。
在服务端启动时,首先通过ServerSocketChannel接受客户端请求建立连接,在建立连接后,再通过SocketChannel进行实际的IO通信。Handler用于处理ServerSocketChannel,而ChildHandler用于处理SocketChannel。
需要注意的是,每个SocketChannel都会有一个独立的ChannelPipeline,也就是说,每个连接的SocketChannel都会有一份独立的ChildHandler处理器。这样可以确保每个连接的业务逻辑独立处理,互不干扰。
总结来说,Handler负责处理ServerSocketChannel,而ChildHandler负责处理每个连接的SocketChannel。Handler负责建立连接和监听请求,ChildHandler负责实际的数据读写操作。
44、为什么NettyClinet的bootstrap的handler不能设置NioServerSocketChannel只能设置NioSocketChannel呢?而NettyServer的ServerBootStrap可以设置NioServerSocketChannel以及childrenHandler可以设置NioServerSocketChannel呢?
这是由于Netty中的原理和设计决策所导致的。
在Netty中,Bootstrap和ServerBootstrap都是引导或启动网络应用程序的工具类,它们都用于配置和设置Channel以及相关的参数。它们之间的主要区别在于适用的场景和用途。
-
Bootstrap:
- 适用于客户端应用程序。
- 配置和使用的是SocketChannel,用于和服务器进行通信。
- 通过
handler()方法配置Handler,用于处理SocketChannel的事件和数据。
-
ServerBootstrap:
- 适用于服务端应用程序。
- 配置和使用的是ServerSocketChannel,用于监听和接受客户端的连接。
- 通过
handler()方法配置Handler,用于处理ServerSocketChannel的事件和数据(一般情况下不需要设置)。 - 通过
childHandler()方法配置ChildHandler,用于处理每个客户端连接的SocketChannel的事件和数据。
引导一个Netty客户端需要设置的是用于与服务器通信的SocketChannel(比如NioSocketChannel),而不是用于监听的ServerSocketChannel(比如NioServerSocketChannel)。因此,在客户端的Bootstrap中只能设置和使用SocketChannel。
而在服务端,ServerBootstrap允许配置并设置用于监听和接受客户端连接的ServerSocketChannel,即NioServerSocketChannel。所以,ServerBootstrap中的handler()方法可以设置处理ServerSocketChannel事件和数据的Handler,同时childHandler()方法可以设置处理每个客户端连接的SocketChannel事件和数据的ChildHandler。
这样的设计目的是为了使Bootstrap和ServerBootstrap能够更好地适应客户端和服务端不同的使用场景,提供更精细的配置和处理能力。
总结来说,Netty的Bootstrap主要用于客户端应用程序,因此只能设置用于与服务器通信的SocketChannel。而ServerBootstrap作为ServerSocketChannel的扩展,在处理服务端应用程序时,提供了额外的功能,可以设置和配置用于监听和接受客户端连接的ServerSocketChannel。
45、请你说下整个netty的服务端运行过程
Netty的服务端运行过程可以分为以下步骤:
- 创建ServerBootstrap对象:ServerBootstrap是Netty服务端启动的入口类,用于配置和启动服务端。
- 配置Channel参数:通过ServerBootstrap对象的方法设置TCP参数、线程模型及其他相关配置,例如端口号、线程数、TCP参数等。
- 添加Handler和ChannelInitializer:通过ServerBootstrap对象的方法添加Handler和ChannelInitializer。Handler是在服务端Channel的Pipeline最前面执行的处理器,而ChannelInitializer则负责添加业务处理的Handler到Pipeline中。
- 绑定端口并启动服务端:通过ServerBootstrap的bind()方法绑定服务端的监听端口,并调用bind()方法启动服务端。
- 等待服务端关闭:启动后,服务端会一直等待客户端的连接请求,直到接收到关闭信号。
当客户端发起连接请求时,服务端会执行以下操作:
- 接受连接:服务端接收到客户端的连接请求后,会创建一个新的Channel对象来表示该连接,并分配一个EventLoop线程来处理后续的IO操作。
- 初始化ChannelPipeline:每个连接都会创建一个新的ChannelPipeline对象,用于处理该连接的所有事件,包括读取数据、写入数据和异常处理等。由于每个连接可能需要不同的处理逻辑,所以可以在ChannelInitializer中动态地添加或修改ChannelPipeline中的Handler。
- 事件处理:一旦连接建立并初始化完成,服务端会根据事件的类型和顺序,将事件依次传递给ChannelPipeline中的Handler进行处理。例如,当有数据可读时,服务端会调用ChannelPipeline中的ReadHandler来处理数据读取操作。
- 发送响应:如果需要向客户端发送响应,服务端可以通过Channel对象进行写操作,将响应数据写入到对应的连接中。
在整个运行过程中,Netty的EventLoop负责处理IO事件和任务,避免了线程切换的开销。同时,Netty的异步、非阻塞的设计能够高效地处理并发连接和大量的并发IO操作。
46、如何方便的测试Netty的Handler
要方便地测试Netty的Handler,可以使用Netty提供的EmbeddedChannel类。EmbeddedChannel是一个用于测试Netty ChannelHandler的特殊Channel实现。
以下是使用EmbeddedChannel来测试Netty的Handler的步骤:
-
导入依赖:
<dependency> <groupId>io.nettygroupId> <artifactId>netty-testing-commonartifactId> <version>4.1.66.Finalversion> <scope>testscope> dependency> -
创建EmbeddedChannel对象:
EmbeddedChannel channel = new EmbeddedChannel(new YourHandler());在这里,将YourHandler替换为要测试的具体Handler类。
-
构造测试数据:
Object input = // 构造测试数据,可以是ByteBuf、POJO对象等 -
写入数据到Channel:
channel.writeInbound(input); // 写入入站数据 -
断言期望的处理结果:
Object output = channel.readOutbound(); // 读取处理后的出站数据 // 进行断言判断,检查处理结果是否符合预期 -
清理资源:
channel.finish(); // 通知Channel处理完成,释放资源
使用EmbeddedChannel可以模拟测试Netty的Handler的入站和出站操作,通过断言判断处理结果是否符合预期。它提供了便捷的方法来模拟和验证数据在Handler中的处理过程,是一种方便且常用的方式来测试Netty的Handler。
请注意,使用EmbeddedChannel进行测试时仍需注意编写合适的测试用例和断言,以覆盖到Handler的各种逻辑和边界情况。
47、输入时会走head和tail吗,输出时会走head和tail吗
输入数据时,数据会经过Pipeline的HeadContext,然后流经各个Handler进行处理,最终到达Pipeline的TailContext。因此,在输入时会经过HeadContext和TailContext。
输出数据时,数据只会经过Pipeline的HeadContext,然后流出网络。输出数据不会经过Pipeline的各个Handler,因此在输出时只会经过HeadContext。
这是因为在Netty中,Pipeline的作用是对输入数据进行处理和传递,而输出数据的处理通常是由底层网络层直接发送出去。因此,输出数据不需要经过Pipeline的各个Handler。
总结来说,在输入数据时会经过Pipeline的HeadContext和TailContext,而在输出数据时只会经过Pipeline的HeadContext。
48、ByteBuf相对于java原生的ByteBuffer的优势
相对于Java原生的ByteBuffer,Netty的ByteBuf具有以下优势:
-
自动扩容:ByteBuf在申请内存时会自动进行扩容,无需手动调整容量。这使得开发者可以更方便地处理动态长度的数据。
-
读写指针:ByteBuf使用了读写指针的概念,允许开发者更方便地进行读写操作。相比之下,ByteBuffer需要手动调用flip、clear、rewind等方法切换读写模式或重置位置指针。
-
内存池化:Netty的ByteBuf支持内存池化,即可以重复利用已经申请过的内存空间。这种机制可以有效地减少内存的分配和释放操作,减轻了垃圾回收的负担。
-
零拷贝(Zero-copy):Netty的ByteBuf在进行数据传输时,可以通过零拷贝技术来提高性能和效率。零拷贝技术使得数据在网络传输或文件读写过程中,可以避免不必要的数据拷贝操作,减少了CPU的消耗和数据复制带来的延迟。
- 非Netty的零拷贝:非Netty的零拷贝通常指操作系统级别的零拷贝技术,依赖于操作系统的一些特性,能够在数据传输时避免把数据从内核缓冲区拷贝到用户空间。
- Netty的零拷贝:Netty在数据传输中也实现了一些零拷贝的技巧,减少了用户空间和内核空间之间的数据拷贝次数,提高了数据的传输效率。
需要注意的是,Netty的ByteBuf并不是完全不占内存,而是尽可能少地占用内存。它通过内存池化和零拷贝等技术手段,减少了内存的分配和拷贝操作,提高了对内存的利用率和性能。
49、如何获得ByteBuf
可以通过Netty的ByteBufferAllocator来获取ByteBuf。ByteBufferAllocator是一个用于分配ByteBuffer或ByteBuf的工厂类。
获取ByteBuf的方式如下:
ByteBufAllocator allocator = ByteBufAllocator.DEFAULT;
ByteBuf byteBuf = allocator.buffer(initialCapacity);
在上述代码中,我们首先通过ByteBufAllocator.DEFAULT获得了一个默认的ByteBufferAllocator实例。然后,通过调用allocator.buffer(initialCapacity)方法来分配一个新的ByteBuf。其中,initialCapacity参数用于指定初始容量,可以根据实际需求进行设定。
需要注意的是,获取的ByteBuf没有明确指定类型(Direct或Heap),它会根据初始化容量和缓冲区是否需要直接内存来自动选择合适的实现。
使用完ByteBuf后,需要及时释放它的资源。可以通过以下方式来释放ByteBuf:
byteBuf.release();
以上是使用Netty的ByteBufAllocator来获取ByteBuf的方法,它提供了灵活、高效的方式来管理和分配ByteBuf。
50、ByteBuf最大的内存空间Integer最大值是多少?
ByteBuf的最大容量取决于索引的范围。在Netty中,使用一个整数索引来引用ByteBuf中的数据,该索引是由32位有符号整数表示的。
因此,ByteBuf的最大容量为整数类型的最大值,即Integer.MAX_VALUE。在Java中,Integer类型的最大值是2^31-1。这意味着,单个ByteBuf的最大容量约为2GB。
需要注意的是,ByteBuf的最大容量也受到具体的操作系统或硬件限制。在实际使用中,可能受到可用内存大小和其他系统限制的影响。此外,通常建议根据实际需求和性能考虑,选择合适大小的ByteBuf,避免过大的内存开销。
52、如何获得ByteBuf,ByteBuf有什么特点?
在Netty中,可以通过以下方式获取ByteBuf实例:
- 使用Unpooled工具类创建ByteBuf:可以使用Unpooled工具类的静态方法,如
Unpooled.buffer()、Unpooled.directBuffer()来创建堆上或直接内存上的ByteBuf。
ByteBuf buf = Unpooled.buffer(10); // 创建一个堆上的ByteBuf,初始容量为10
- 通过Channel获取ByteBuf:在Netty的IO操作中,读取或写入数据时,会通过Channel的
alloc()方法来获取一个合适的ByteBuf实例。这样创建的ByteBuf会自动与对应的EventLoop关联,以便进行高效的内存管理。
Channel channel = ... // 获取Channel实例
ByteBuf buf = channel.alloc().buffer(10); // 通过Channel获取一个ByteBuf
- 使用CompositeByteBuf:CompositeByteBuf是一种特殊的ByteBuf,它可以组合多个ByteBuf,形成一个逻辑上的连续字节序列。
CompositeByteBuf compBuf = channel.alloc().compositeBuffer();
ByteBuf的主要特点如下:
- 高效的内存分配:Netty的ByteBuf采用了池化的内存管理机制,能够高效地重用已分配的内存,减少内存碎片和频繁的GC操作。
- 零拷贝:ByteBuf支持零拷贝操作,例如可以直接将数据传输到操作系统的缓冲区或从文件中读取数据到内存,避免了不必要的数据拷贝。
- 高级API支持:ByteBuf提供了丰富的API来进行字节数据的读写操作,例如按索引读写、逐字节读写、批量读写,以及各种类型的数据的读写。
- 支持多种数据类型:除了可以存储字节数据外,ByteBuf还提供了对其他常用数据类型(如整型、浮点型)的读写支持,方便进行数据转换和处理。
- 可以使用池化的Direct ByteBuf:Netty还提供了用于直接访问操作系统内存的Direct ByteBuf,适用于特定场景下需要直接操作内存的情况。
这些特点使得Netty的ByteBuf在网络编程中成为一个高性能、灵活和易用的字节缓冲区实现。
53、自动扩容的规律是什么呢?
在Netty的ByteBuf中,自动扩容的规律如下:
-
初始容量为64字节。当创建一个新的ByteBuf时,初始容量会被设置为64字节。如果写入的数据超过了初始容量,ByteBuf会自动进行扩容。
-
扩容的过程是按照一定规律进行的。具体规律如下:
- 前16次扩容:每次扩容增加16字节。也就是说,容量会分别为64、80、96、…、240字节。
- 容量达到512字节后:每次扩容增加的字节数会翻倍,即为512、1024、2048等。也就是说,容量会分别为512、1024、2048、…字节。
- 达到一定阈值:当容量达到一定阈值(默认为16MB)后,容量的增长速度会放慢。这是为了避免过多的内存分配,以提高内存的利用率和性能。
通过按照以上规律进行自动扩容,Netty的ByteBuf可以根据实际数据大小动态调整容量,避免内存的浪费,并提供高效的内存管理能力。
54、堆内存和直接内存的关系,以及特点
堆内存和直接内存是两种常见的内存分配方式,它们在创建和销毁的代价、读写效率和GC压力等方面具有不同的特点。
-
堆内存:
- 创建和销毁代价相对较小:堆内存的分配和释放由Java虚拟机自动管理,相对较为简单和高效。
- 读写效率较低:堆内存的访问需要通过Java虚拟机的内存管理系统,需要进行一定的内存拷贝操作,因此读写效率较低。
- GC(垃圾回收)压力较大:当堆内存中的对象无法被引用时,会由GC负责回收释放。GC的过程需要遍历对象图并进行标记、清除等操作,对于大量对象的堆内存分配和释放,会增加GC的压力。
-
直接内存:
- 创建和销毁代价较大:直接内存的分配和释放需要较为复杂的操作,涉及到操作系统的系统调用。因此,相对于堆内存,创建和销毁直接内存的代价较大。
- GC压力较小:因为直接内存不受Java虚拟机的管理,也不参与Java的垃圾回收机制,所以不会增加GC的压力。
- 读写效率较高:直接内存可以直接在内存和IO设备之间进行数据传输,无需进行额外的内存拷贝,因此读写效率较高。
总的来说,堆内存适合存储大量的动态对象,并且在读写较为频繁的场景下,其创建和销毁的代价相对较小。而直接内存适合处理IO操作以及需要较高读写效率和较少GC压力的场景。根据具体的使用需求和性能考虑,选择合适的内存分配方式。
55、池化的好处
池化是一种常见的内存管理技术,它的好处主要体现在以下几个方面:
-
减少内存分配和释放的次数:通过使用对象池来重用已经分配的对象,可以减少频繁的内存分配和释放操作。这样可以降低内存管理的开销,并提高程序的性能。
-
缓解内存碎片化问题:频繁的内存分配和释放操作容易导致内存碎片的产生,即一块使用完毕的内存无法被重新利用,从而造成内存空间的浪费。通过使用对象池进行对象的重用,可以有效地缓解内存碎片化问题,提高内存的利用效率。
-
提供更好的可预测性:对象池可以提供更稳定和可预测的内存分配行为。由于对象已经预先分配并存储在池中,可以避免由于频繁的内存分配而造成的动态内存分配开销和不可预测的性能问题。这样可以使程序的性能更加可靠和一致。
综上所述,使用池化技术可以有效地减少内存分配和释放的次数,缓解内存碎片化问题,并提供更好的可预测性。这些好处可以显著提高程序的性能和稳定性,尤其在对内存管理要求较高的应用场景中,池化是一个非常有价值的技术手段。
56、netty默认开启池化吗?
是的,Netty默认情况下开启了池化(Pooled)功能。在Netty中,默认使用PooledByteBufAllocator作为默认的ByteBuf分配器。
PooledByteBufAllocator是Netty提供的基于池化技术的ByteBuf分配器。它通过重用已经分配的ByteBuf实例,减少内存分配和释放的开销,同时也可以缓解内存碎片化问题。
当创建Channel时,Netty会自动为每个Channel分配一个独立的ByteBuf分配器,这个分配器就是默认的PooledByteBufAllocator。通过使用PooledByteBufAllocator,可以为每个Channel提供独立的池化功能,实现更高效的内存管理和使用。
需要注意的是,虽然Netty默认开启了池化功能,但也可以根据实际需求自定义分配器或禁用池化功能。可以通过配置选项或代码方式进行相应的设置。
57、被废弃的数据在Bytebuf还存在吗?
在ByteBuf中,被标记为废弃的数据仍然存在,只是处于不可达的状态。当有新的数据写入到ByteBuf中时,新的数据会覆盖掉被标记为废弃的数据,实际上相当于原有的数据被替换掉了。
相比于删除数据后再进行添加操作,使用ByteBuf的追加方式可以更为方便。通过追加方式,可以在不删除、查询与删除数据的情况下,直接将新的数据写入到已有的ByteBuf末尾。
需要注意的是,废弃的数据并不会被自动清理或从内存中释放。如果需要清理废弃的数据,可以通过调用相应的ByteBuf的释放(release())方法来手动释放内存。这样可以确保废弃的数据不会占用过多的内存空间。
总的来说,使用ByteBuf的追加方式可以简化数据的管理和操作,但需要注意废弃数据的释放,以避免内存空间的浪费。
58、如何重复读一个ByteBuf?

要重复读一个ByteBuf,可以使用mark()和reset()方法。
- 使用
mark()方法标记当前读取的位置:
ByteBuf buffer = ...; // 假设已经有一个 ByteBuf 实例
buffer.mark(); // 标记当前读取的位置
- 进行读取操作:
// 读取数据
while (buffer.isReadable()) {
byte b = buffer.readByte();
// 处理读取的数据
}
- 使用
reset()方法将读取的位置重置到标记的位置:
buffer.reset(); // 将读取的位置重置到标记的位置
经过以上操作后,ByteBuf会重新从标记的位置开始读取数据。
需要注意的是,使用mark()和reset()方法时需要确保ByteBuf支持这些操作。并且当调用reset()方法时,标记的位置会被清除,所以在调用reset()方法之前必须先调用mark()方法进行标记。
另外,如果需要多次重复读取ByteBuf中的数据,也可以考虑使用duplicate()方法创建一个新的ByteBuf实例,这样可以避免使用mark()和reset()方法。使用duplicate()方法创建的ByteBuf实例会共享底层数据,相互之间的读写操作不会相互影响。
59、ByteBuf read和get的区别是什么?
在ByteBuf中,read和get是两种不同的操作方法,它们的主要区别如下:
-
读取位置的影响:
read操作会将读取指针向后移动,以便下一次读取操作从下一个位置开始。例如,使用readInt()方法读取一个整数后,读取指针会自动增加4。get操作则不会影响读取指针的位置,每次读取操作都会从当前的读取指针位置开始。例如,使用getInt()方法获取一个整数,读取指针不会移动。
-
数据访问的方式:
read操作主要用于按顺序连续读取ByteBuf中的数据,将读取的数据读取到一个变量中,然后将读取指针向后移动。get操作主要用于根据指定的索引位置读取指定类型的数据,与读取指针位置无关,可以随机访问ByteBuf中的数据。
需要注意的是,无论是使用read还是get操作,都需要确保在读取之前ByteBuf中有足够的可读数据,否则会抛出IndexOutOfBoundsException。可以使用readableBytes()方法来检查ByteBuf中剩余的可读字节数。
综上所述,read操作用于按顺序连续读取数据并推进读取指针,而get操作用于根据指定的索引位置随机访问数据,不会改变读取指针的位置。选择使用哪种操作方法取决于具体的需求和数据访问的模式。
60、ByteBuf内存释放 是不是回收,清空,销毁?
对于ByteBuf的内存释放,具体的行为取决于是否使用了池化(Pooled)和内存类型(堆内存或直接内存)。
-
池化的情况:
- 如果
ByteBuf是池化的,即使用PooledByteBufAllocator进行分配,那么内存释放的操作是将ByteBuf实例放回对应的ByteBuf池中,以供下次重用。这样可以减少内存分配和释放的开销,并缓解内存碎片化问题。 - 释放后的
ByteBuf实例可以重新从池中获取,并用于后续的读写操作。这样可以提高性能和内存利用率。
- 如果
-
非池化的情况:
- 如果
ByteBuf没有使用池化,即使用非池化的分配器,如Unpooled等,那么内存释放的行为会有所不同。 - 对于堆内存类型的
ByteBuf,释放的操作只是将ByteBuf实例的引用计数减少。当引用计数减少到0时,垃圾回收机制会最终回收这块堆内存。 - 对于直接内存类型的
ByteBuf,释放的操作将使得ByteBuf的内存被立即回收,并且不会涉及垃圾回收机制。
- 如果
需要注意的是,无论是池化还是非池化,对于已经释放的ByteBuf实例,不能再对其进行读写操作,否则会引发错误。要确保在不需要使用ByteBuf实例时正确释放内存,避免出现内存泄漏和错误的内存管理。
61、Netty是如何释放内存的?
在 Netty 中,内存的释放是通过 ByteBufAllocator 接口以及相关的方法来进行管理和实现的。Netty 中的 ByteBufAllocator 提供了统一的内存分配和释放机制。
ByteBufAllocator 接口定义了以下两个方法用于内存的分配和释放:
ByteBufAllocator.buffer():用于分配一个新的ByteBuf实例。ByteBuf.release():用于释放ByteBuf实例所占用的内存空间。
ByteBufAllocator 的实现根据不同情况和需求,可能使用不同的内存分配和释放策略。例如,可以使用池化的策略(PooledByteBufAllocator)来重复利用内存,或者使用非池化的策略(UnpooledByteBufAllocator)来临时分配和释放内存。
具体的内存释放操作包括以下几个步骤:
- 当一个
ByteBuf实例不再被引用时,其引用计数会减少,当引用计数减少到 0 时,ByteBuf实例会进入可回收的状态。 - 如果
ByteBuf是池化的,它会被返回到对应的ByteBuf池中,以供下次重用。 - 如果
ByteBuf是非池化的,底层内存会直接被释放。 - 对于直接内存类型的
ByteBuf,底层内存会被立即回收,而对于堆内存类型的ByteBuf,垃圾回收机制会最终回收其所占用的堆内存。
Netty 的内存释放机制通过 ByteBufAllocator 提供了统一的接口,使得可以方便地管理和释放内存,从而提高内存的利用率和性能。同时,根据具体的使用场景和需求,可以选择不同的内存分配和释放策略,以满足不同的优化目标。
62、Netty是通过什么释放内存的?
Netty 是通过实现 ReferenceCounted 接口来管理和释放内存的。
ReferenceCounted 接口定义了两个重要的方法:
retain():将对象的引用计数加一。release():将对象的引用计数减一。
具体的内存释放机制如下:
- 当创建一个
ByteBuf实例时,引用计数为 1。 - 当需要使用该
ByteBuf实例时,可以调用retain()方法来增加引用计数。引用计数加一表示有一个新的地方引用了它。 - 在使用完
ByteBuf实例后,调用release()方法来减少引用计数。引用计数减一表示不再有地方引用它了。 - 当引用计数减少到 0 时,表示没有地方引用该
ByteBuf实例了。此时,Netty 会自动触发释放操作。具体的释放操作可能根据使用的分配器(如池化分配器或非池化分配器)而有所不同:- 如果使用的是池化分配器(如
PooledByteBufAllocator),则会将ByteBuf实例放回对应的池中,以供下一次重用。 - 如果使用的是非池化分配器(如
UnpooledByteBufAllocator),则会直接释放底层内存。
- 如果使用的是池化分配器(如
通过实现 ReferenceCounted 接口,Netty 可以实现高效的内存管理和自动释放。通过增加和减少引用计数,可以追踪对象的引用情况,并在引用计数减少到 0 时,自动触发释放操作,从而避免内存泄漏和错误的内存管理。
63、ByteBuf什么时候需要释放呢?
对于 ByteBuf 的释放,一般需要注意以下几个情况:
- 在使用
ByteBuf的场景中,如 Netty 的 pipeline 的 handler 中,应该负责创建和销毁ByteBuf。通常情况下,创建和释放ByteBuf的工作都应该在 handler 中完成。 - 在读取数据时,
tailContext或者SimpleChannelHandler会对读取到的ByteBuf进行释放。在写入数据时,headContext会对准备写入的ByteBuf进行释放。这是因为在网络通信中,读取和写入操作通常由相应的组件负责。 - 最后一次使用
ByteBuf的时候,需要确保进行ByteBuf的释放。这意味着在使用完ByteBuf后,手动调用release()方法对ByteBuf进行释放。 - 需要注意的是,
ByteBuf应该只在处理网络通信的代码中使用,不应该传递到其他开发业务代码(如 service、dao 等)。因为对于ByteBuf的释放,应该是在网络通信相关的组件中完成的,而不是在业务代码中。
综上所述,需要保证在最后一次使用 ByteBuf 的时候进行释放,并且不要将 ByteBuf 传递到业务代码中。合理地管理 ByteBuf 的创建和释放,可以避免内存泄漏和错误的内存管理问题。
64、什么情况下会使用切片?使用切片需要注意什么?
在以下情况下可以使用切片(slice)操作:
当你有一个较大的 ByteBuf,但你只需要使用其中一部分数据时,可以使用切片来避免额外的内存拷贝。
使用 ByteBuf.slice() 方法可以创建一个新的 ByteBuf,其底层内存与原始 ByteBuf 共享,但只包含指定的部分数据。通过切片,你可以创建一个新的 ByteBuf,并且不用复制原始数据,从而节省内存和时间。
需要注意以下几点:
- 切片后的
ByteBuf与原始ByteBuf共享底层内存。任何对切片和原始ByteBuf的操作都会影响到共享的内存。 - 切片的
ByteBuf和原始ByteBuf共享引用计数。这意味着引用计数的增减会影响到共享的ByteBuf。 - 在使用切片后的
ByteBuf时,需要调用retain()方法来增加引用计数,确保内存不会被提前释放。 - 当不再需要使用切片后的
ByteBuf时,需要调用release()方法来减少引用计数,并在引用计数减少到 0 时释放内存。
综上所述,使用切片操作可以避免额外的内存拷贝,提高效率,但需要注意共享底层内存和引用计数的关系,确保正确地管理内存的生命周期。
65、数据传输过程
数据传输过程通常涉及以下几个关键步骤:
-
用户态缓冲区(应用程序):
- 数据首先被应用程序写入用户态缓冲区,即应用程序内存中的缓冲区。
- 应用程序可以使用适当的 API(如 Netty)将数据放入缓冲区。
- 在数据传输过程中,应用程序可以对数据进行处理和操作。
-
内核态socket缓冲区:
- 操作系统内核提供了一个或多个内核态socket缓冲区,作为应用程序和网络硬件之间的中间缓冲区。
- 当应用程序要发送数据时,数据被从用户态缓冲区复制到内核态socket缓冲区。
- 内核态socket缓冲区通常是一个环形缓冲区,其中数据被按待发送的顺序排列。
-
硬件网卡:
- 硬件网卡(网络接口卡)负责处理数据的物理传输。
- 硬件网卡将数据从内核态socket缓冲区复制到发送端的物理网络介质上,例如以太网或无线网络。
- 物理传输过程中,数据可能需要进行分组、封装和编码等处理。
-
接收端的硬件网卡:
- 数据从发送端的硬件网卡经过网络传输到接收端的硬件网卡。
- 接收端的硬件网卡负责接收数据,并将数据放入接收端的网络缓冲区。
-
内核态socket缓冲区(接收端):
- 接收端的内核态socket缓冲区接收到的数据存储在其中。
- 接收端的操作系统会从硬件网卡读取数据,并将数据复制到内核态socket缓冲区。
- 内核态socket缓冲区通常是一个环形缓冲区,其中数据按接收顺序排列。
-
用户态缓冲区(接收端应用程序):
- 接收端的应用程序可以通过适当的 API(如 Netty)从内核态socket缓冲区中读取数据。
- 接收端应用程序从内核态socket缓冲区中读取数据并进行处理。
- 数据最终到达接收端应用程序,完成整个数据传输过程。
这个是一般情况下的数据传输过程,具体的实现和步骤可能会因操作系统、网络协议和应用程序框架等因素而有所不同。
66、发送方内核态Socket缓冲区和接收方Socket内核区一样吗?
发送方的内核态 Socket 缓冲区和接收方的内核态 Socket 缓冲区不同。
发送方的内核态 Socket 缓冲区通常被称为 SNDSocketBuffer(Send Socket Buffer),它用于存储发送方即将发送的数据。当应用程序将数据写入发送方的 Socket 缓冲区时,数据会暂时保存在 SNDSocketBuffer 中,然后通过网络传输到接收方。
接收方的内核态 Socket 缓冲区通常被称为 REVSocketBuffer(Receive Socket Buffer),它用于存储接收方接收到的数据。当网络传输的数据到达接收方的网络接口卡后,数据会被复制到 REVSocketBuffer 中,然后等待接收方应用程序读取。
SNDSocketBuffer 和 REVSocketBuffer 在内部实现上可能有所不同,因为它们用于不同的目的。SNDSocketBuffer 着重于存储发送方即将发送的数据,而 REVSocketBuffer 着重于存储接收方已接收到的数据。这两个缓冲区的具体实现细节可能会因操作系统和网络协议而有所差异。
67、用户缓存区大 还是 Socket缓冲区大?
在原则上,Socket 缓冲区的大小应该大于用户缓冲区。
用户缓冲区是指应用程序中存储待发送数据或接收数据的缓冲区。当应用程序要发送数据时,数据会先被写入到用户缓冲区。当应用程序要接收数据时,数据会先被读取到用户缓冲区。
Socket 缓冲区是位于操作系统内核中的缓冲区,用于存储待发送或接收的数据。当应用程序将数据写入 Socket 缓冲区时,数据会从用户缓冲区复制到 Socket 缓冲区以供发送。当接收到数据时,数据会从 Socket 缓冲区复制到用户缓冲区以供应用程序使用。
因为数据的发送和接收可能存在延迟、网络拥塞等原因,当数据从用户缓冲区传输到 Socket 缓冲区时,可能会造成数据在 Socket 缓冲区中滞留一段时间。为了避免数据丢失或发送延迟过大,以及为了处理大量数据的情况, Socket 缓冲区的大小一般会配置较大,能够容纳更多的数据。
总之,为了更好地管理数据发送和接收,Socket 缓冲区的大小通常应大于用户缓冲区。这样可以确保在网络延迟或拥塞的情况下,数据能够及时进入 Socket 缓冲区,并且有足够的空间进行存储和处理。考虑到网络环境、数据量和性能等因素,合理配置和调整缓冲区大小非常重要。
68、Socket缓冲区和滑动窗口的区别
Socket 缓冲区(Socket Buffer)是位于操作系统内核中的缓冲区,用于存储待发送或接收的数据。应用程序通过向 Socket 缓冲区写入数据来发送数据,或从 Socket 缓冲区读取数据来接收数据。Socket 缓冲区通常有发送方的 SNDSocketBuffer 和接收方的 REVSocketBuffer。
滑动窗口(Sliding Window)是在网络通信中用于流量控制的概念。它是一种基于接收方告知发送方能够接收的数据量的机制。滑动窗口的大小可以动态调整,它控制了发送方可以连续发送的数据量,以避免接收方无法及时处理或存储过多数据从而导致数据丢失或缓冲区溢出。
滑动窗口可以应用于不同的网络协议和传输层协议,如 TCP。在 TCP 中,滑动窗口大小的动态调整是通过 TCP 协议的窗口字段实现的。接收方使用窗口字段告知发送方它的可接收缓冲区大小。发送方根据接收方的窗口大小来控制发送数据的速率和窗口大小。
虽然 Socket 缓冲区和滑动窗口都是与数据传输相关的概念,但它们所处的层次不同。Socket 缓冲区是在传输层中的内核态,用于在应用程序和网络之间传输数据。而滑动窗口是在网络层中的发送端网关硬件和接收端网关硬件之间通过数据帧传输而产生的一种流量控制机制。
69、流量控制->滑动窗口是什么?
滑动窗口是在网络通信中用于流量控制的一种机制。它是通过动态调整发送方可以连续发送的数据量来避免接收方无法及时处理或存储过多数据的情况。
在滑动窗口机制中,发送方和接收方都维护一个窗口大小,表示在一次数据传输中允许发送或接收的数据量。发送方根据接收方的窗口大小来调整发送的数据量,以确保接收方能够及时处理和存储数据。发送方每发送一段数据,会等待接收方发送回一个确认(ACK)信号,该确认信号表示接收方已成功接收到数据。发送方根据接收到的确认信号来更新自己的窗口大小,允许发送更多的数据。
滑动窗口大小有两个关键的概念:
- 初始窗口大小:流量控制的初始窗口大小是指发送方在建立连接时初始化的窗口大小。它通常等同于发送方的 Socket 缓冲区大小,表示发送方在连接刚建立时可以连续发送的最大数据量。
- 剩余窗口大小:剩余窗口大小表示发送方在连续发送数据后,接收方返回的ACK信号所确认的数据已成功接收并处理,发送方可以再次发送的数据量。它等同于发送方的 Socket 缓冲区剩余空间的大小。
设置 Socket 缓冲区大小可以间接地控制滑动窗口的大小。较大的 Socket 缓冲区大小可以容纳更多的数据,从而允许发送方一次性发送更多的数据。这样可以提高发送效率,但也要确保接收方能够及时处理和存储这些数据,并根据实际情况调整窗口大小。
总结起来,滑动窗口机制通过动态调整发送方可以连续发送的数据量来达到流量控制的目的。发送方和接收方都具有自己的 Socket 缓冲区大小,这些缓冲区大小决定了滑动窗口的初始大小和剩余大小。通过灵活调整窗口大小,滑动窗口可以在不同的网络环境下提供适当的流量控制。
————————
- 一次性发多条数据过去
- 原本都是一条数据一次ACK
- 滑动窗口大小?
- 等同于Socket缓冲区的大小【初始】
- 等同于Socket缓冲区【剩余空间】大小
- 设置了Socket缓冲区大小就相当于设置了滑动窗口的大小。
- 发送端有Socket缓冲区大小,接收端也有Socket缓冲区大小
70、Socket缓冲区数据是如何到达网卡呢?
是的,数据从 Socket 缓冲区到达网卡通过 DMA(Direct Memory Access)技术进行拷贝。
在传输过程中,数据从应用程序写入 Socket 缓冲区,然后操作系统内核控制网卡使用 DMA 技术,直接从内存中读取数据。DMA 是一种数据传输技术,它允许外部设备(如网卡)直接与系统内存进行数据传输,而无需 CPU 的干预。这样可以提高数据传输的效率,减少 CPU 的负载。
当网卡接收到要发送的数据时,它会通过 DMA 技术将数据从内存中读取到网卡的发送缓冲区。然后,网卡将数据封装成数据帧,并通过物理介质(如网线)发送到目标设备。
类似地,当网卡接收到从其他设备发送过来的数据帧时,它会通过 DMA 技术将数据从网卡的接收缓冲区复制到系统内存的 Socket 缓冲区中。然后,操作系统内核将数据从 Socket 缓冲区移交给目标应用程序进行处理。
通过使用 DMA 技术,数据可以在网卡和内存之间直接传输,减少了 CPU 的介入,提高了数据传输的效率和带宽利用率。这样,数据可以高效地从 Socket 缓冲区到达网卡,从而进行网络的发送和接收。
71、write()返回值含义是什么呢?
write() 函数用于将数据写入文件描述符(包括 Socket 描述符)。它的返回值表示成功写入的字节数或错误信息。下面是 write() 函数返回值的含义:
- 正整数(大于0):返回实际成功写入的字节数。这意味着给定字节数的数据已经成功写入了文件描述符所对应的缓冲区(如内核 Socket 缓冲区)。
- 0:在非阻塞模式下,如果写入的缓冲区已满,
write()可能返回0。这意味着当前的写操作不能立即完成,需要等待一段时间后再次尝试写入。 - -1:表示写入过程发生了错误,并且错误代码存储在
errno变量中。常见的错误可能包括:EINTR:写入被信号中断。EAGAIN或EWOULDBLOCK:写入操作被阻塞,因为缓冲区已满,需要等待数据被消耗或发送。EBADF:无效的文件描述符。EFAULT:指针参数指向无效的内存地址。EPIPE:写入操作的管道或 Socket 已经被关闭。
需要注意的是,write() 方法在将数据写入到文件描述符所对应的缓冲区时,并不会立即检查网络状态。即使网络断开,数据仍然会成功写入到内核 Socket 缓冲区中。实际上,这意味着 write() 方法并不受网络断开的影响。但是,当尝试从写入缓冲区将数据发送到网络时,可能会遇到其他错误。在发送数据时,才会真正检查网络连接状态,并且可能会遇到发送失败的情况。
72、Socket缓冲区 默认大小是多少?
对于大多数操作系统和网络协议栈,Socket 缓冲区的默认大小通常是根据操作系统的设置和网络协议的要求而定,并且可能会因操作系统和协议版本的不同而有所变化。在实际应用中,可以使用系统函数或套接字选项来获取或修改默认的 Socket 缓冲区大小。
对于TCP套接字来说,在大多数情况下,其发送和接收缓冲区的默认大小通常是由操作系统内核决定的,并且可以通过套接字选项进行配置。一般情况下,TCP套接字发送缓冲区和接收缓冲区的默认大小都是取决于操作系统的设置,通常是比较合理的值。
对于Linux系统,其默认的TCP套接字缓冲区大小(发送和接收缓冲区大小)是由net.core.wmem_default和net.core.rmem_default内核参数来控制的。一般情况下,发送缓冲区大小默认为 212992 字节,接收缓冲区大小默认为 212992 字节。但这些数值在不同的发行版本和内核版本可能会有所变化。
需要注意的是,Socket 缓冲区的大小可以根据应用程序的需求进行调整,以确保适当的数据传输效率和性能。例如,通过设置套接字选项来调整发送和接收缓冲区的大小,或通过系统函数(如setsockopt())来修改默认的缓冲区大小。具体的操作方法和可调整的范围可能因操作系统和协议栈的不同而有所差异。
73、Netty如何获得ByteBuf?
在 Netty 中,可以通过自定义的适配器(ChannelInboundHandlerAdapter)或其他实现了 ChannelInboundHandler 接口的类来获得 ByteBuf。
当 Netty 接收到数据时,会通过流水线(pipeline)将数据传递给相应的处理器(handler)。在 ChannelInboundHandler 的实现类中,可以覆盖 channelRead 方法来处理接收到的数据。该方法的参数中包含了接收到的数据以及与之相关的 ByteBuf。通过读取和操作 ByteBuf,可以获得数据的内容。
以下是一个示例代码,展示了如何通过 ChannelInboundHandler 获得 ByteBuf:
public class MyInboundHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof ByteBuf) { // 检查接收到的数据类型
ByteBuf byteBuf = (ByteBuf) msg;
// 在这里可以对 byteBuf 进行读取和操作
try {
// 读取 byteBuf 中的数据
while (byteBuf.isReadable()) {
System.out.print((char) byteBuf.readByte());
}
} finally {
// 释放 ByteBuf 资源
byteBuf.release();
}
}
// ...
}
// ...
}
在上述示例中,channelRead 方法的参数中的 msg 参数代表接收到的数据。通过检查 msg 的类型是否为 ByteBuf,可以确认数据类型,并进一步对 ByteBuf 进行读取和操作。在读取完成后,记得释放 ByteBuf 的资源,以避免内存泄漏。
请注意,Netty 的数据传递是基于事件和回调机制的,多个处理器可以以流水线的方式进行串联和处理。当数据经过 ChannelInboundHandler 链时,每个处理器可以对数据进行相应的操作和转换,以满足业务需求。
74、如何修改Netty创建的ByteBuf默认大小?
在 Netty 中,可以通过修改 ChannelOption.RCVBUF_ALLOCATOR 选项来调整创建的 ByteBuf 的默认大小。
默认情况下,Netty 使用的是适用于大多数场景的堆缓冲区(heap buffer),其默认大小为 1024 字节。如果需要修改默认的 ByteBuf 大小,可以在创建 ServerBootstrap 或 Bootstrap 实例后,通过 childOption 方法设置 ChannelOption.RCVBUF_ALLOCATOR 选项,并指定一个新的 ByteBufAllocator 对象。例如:
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new MyChannelInitializer())
.childOption(ChannelOption.RCVBUF_ALLOCATOR, new FixedRecvByteBufAllocator(16))
.bind(port);
在上述示例中,通过 childOption 方法设置 ChannelOption.RCVBUF_ALLOCATOR 选项为 FixedRecvByteBufAllocator,并指定一个新的 FixedRecvByteBufAllocator 对象。这个对象的构造器可以传入两个参数,分别是初始容量和最大容量。这里示例中将初始容量设置为 16 字节。
使用 FixedRecvByteBufAllocator 可以将 ByteBuf 的初始大小和最大大小固定为指定的值。当然,你也可以根据业务需求,选择适合的 ByteBufAllocator 实现类。
需要注意的是,这里设置的是 childOption,因此是针对每个客户端连接的 ByteBuf 大小进行设置,而不是服务器全局的默认大小。如果需要修改服务器全局的默认大小,可以使用 option 方法来设置 ChannelOption.RCVBUF_ALLOCATOR 选项。
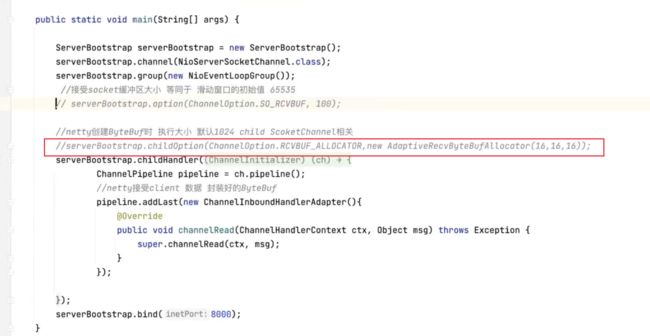
75、Netty 封装了channel 可以设置TCP 接受缓冲区大小参数
这是全局改变
76、半包粘包如何解决?
1. FixedLengthFrameDecoder 固定长度的解码器
2. LineBasedFrameDecoder 要求你每一个完成的消息必须有个分割符 \n \r\n
3. LengthFieldBasedFrameDecoder
lengthFieldOffset 从第几个字节开始找 length 位
lengthFieldLength length位的长度
lengthAdjustment length位后面第几个字节是内容
initailByteToStrip 去头 白话:开头到真正内容的字节数
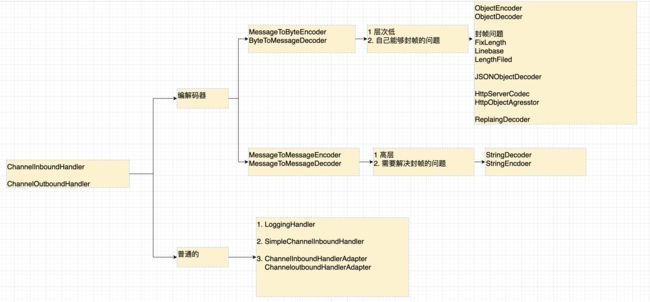
77、什么是编解码器?
编解码器(Codec)是在网络通信中负责将数据在传输层和应用层之间进行转换的组件。编解码器的主要作用是将原始的数据转换为特定的数据格式,以便在网络中传输或在接收端进行处理。
在网络通信中,数据需要经过多个层级和协议进行封装和解封装,例如从应用层到传输层(如 TCP 或 UDP),再到网络层以及链路层。在每个层级中都会对数据进行一定的处理和封装,而编解码器就是在应用层和传输层之间进行数据格式的转换。
编解码器通常根据特定的协议规范来实现,以确保数据在不同端点之间的正确传输和解析。常见的编解码器包括:JSON 编解码器、XML 编解码器、Protobuf 编解码器等。这些编解码器可以将数据序列化为特定的格式,在传输过程中编码为二进制流,然后在接收端解码并还原为原始的数据格式。
编解码器在网络通信中起到了重要的作用,它们可以简化数据的处理和传输过程,提高数据传输的效率和可靠性。同时,使用编解码器可以实现不同编程语言和平台之间的互操作性,使得不同系统之间可以正确地解析和处理相同的数据格式。
78、codec是什么?
是的,codec 是指编码(Encode)和解码(Decode)的结合。在计算机领域中,codec 通常用于表示编码器(Encoder)和解码器(Decoder)的组合,也可称为编解码器。
编码器负责将原始数据转换为特定的编码格式,以便在传输或存储中使用。它将原始数据转换为二进制形式,可以是字节流或其他表示形式。编码过程可能包括压缩、加密和数据格式转换等操作。
解码器是编码器的逆过程,它负责将编码后的数据重新解码为原始数据形式。解码器将二进制数据转换回原始的数据格式,以供接收端进行处理和使用。解码器可能包括解压缩、解密和数据格式转换等操作。
codec 可以用于各种应用场景,例如音视频编解码、数据传输和存储等。它们是通信和数据处理的关键组件,确保数据在不同系统之间的正确传输和解析。
在网络编程中,codec 也经常使用,例如在使用 Netty 进行网络通信时,我们可以通过添加合适的编码器和解码器来处理数据的编解码,以满足特定的通信协议和数据格式要求。
总而言之,codec 是编码和解码的组合,它们一起工作以实现数据的转换、传输和解析。通过使用适当的编码器和解码器,我们可以在不同的环境中高效地处理和传输数据。
79、Netty中编解码的体现
在 Netty 中,编码和解码是通过编解码器(Codec)来实现的,这些编解码器负责将数据在传输层和应用层之间进行转换。
编码(Encode)的过程是将 Java 对象转换为二进制数据(字节流)。这个过程通常发生在数据从应用层发送到传输层之前。通过编码器,可以将 Java 对象序列化为特定的数据格式,如 JSON、XML、Protocol Buffers 等,并将其编码为字节流以便在网络中传输。编码器将 Java 对象转换为二进制数据的形式,使其能够被发送到接收端。
解码(Decode)的过程是将接收到的二进制数据(字节流)还原为 Java 对象。这个过程通常发生在数据从传输层接收到之后,被传递到应用层进行处理之前。通过解码器,可以将接收到的字节流解码为原始的 Java 对象格式,以供应用程序进行相应的处理。解码器将字节流还原为相应的对象表示,使应用程序能够正确地处理接收到的数据。
这种编解码的体现可以在 Netty 中通过添加合适的编码器和解码器来实现。Netty 提供了很多内置的编解码器,也可以自定义编解码器来满足特定的通信协议和数据格式要求。通过使用这些编解码器,我们可以轻松地将 Java 对象与二进制数据之间进行转换,并在网络中进行传输和处理。
总结起来,在 Netty 中,编码和解码通过编解码器实现,编码器将 Java 对象转换为字节流进行传输,解码器将接收到的字节流转换回相应的 Java 对象以供应用程序处理。这样的编解码机制可以简化网络通信的实现,提高通信的效率和可靠性。
80、有哪些编解码方式呢?以及各自的优缺点1、java序列化 和 反序列化
在数据编解码的方式中,常见的包括:
-
Java 序列化和反序列化:使用 Java 的内置序列化机制,让类实现
Serializable接口进行标识。对象可以被转换为二进制形式,并进行存储或传输。优点是简单易用,不需要手动编写编解码逻辑。缺点包括无法跨语言、可读性差、数据大小较大和序列化操作的时间延迟。 -
XML:使用标记语言 XML 进行编码和解码,通过定义标签、元素和属性来表示数据。XML 具有良好的可读性,但由于其冗余的标签和元素,数据体积较大,解析和处理的性能相对较低。
-
JSON:使用 JavaScript 对象表示法(JSON)进行编码和解码。JSON 具有良好的可读性和可解析性,对于 Web 应用和跨平台通信广泛应用。相对于 XML,JSON 的数据体积较小,但仍然比二进制形式的数据大。
-
Msgpack:一种二进制的编码格式,类似于 JSON。Msgpack 具有较高的编码和解码效率,数据体积小,同时支持多种编程语言。
-
Protocol Buffers(protobuf):Google 开发的一种二进制编码协议。与其他编码方式相比,protobuf 具有更小的数据体积和更高的编解码效率,支持多种编程语言。protobuf 使用自己的编译器将数据格式编译成中间语言。
-
BSON:一种二进制 JSON 格式,主要用于 MongoDB 数据库存储。BSON 相对于 JSON 具有更高的性能和更小的数据体积。
选择适当的编解码方式取决于具体的应用需求,包括数据体积、可读性、跨语言支持和编解码性能等方面的考虑。不同的编解码方式在不同的应用场景中有各自的优劣势。
81、具体的编解码器是那两个?
在 Netty 中,具体的编解码器包括:
-
ByteToMessageDecoder:字节到消息解码器。它是ChannelInboundHandler的子类,用于将输入的字节流解码为消息对象。通过继承ByteToMessageDecoder并重写decode方法,可以实现自定义的解码逻辑。 -
MessageToByteEncoder:消息到字节编码器。它是ChannelOutboundHandler的子类,用于将消息对象编码为字节流。通过继承MessageToByteEncoder并重写encode方法,可以实现自定义的编码逻辑。
这两个编解码器可以用于实现不同的协议和数据格式的编解码。在 Netty 应用程序中,首先会添加相应的解码器(继承自 ByteToMessageDecoder),负责将输入的字节流解码为消息对象。然后,再添加相应的编码器(继承自 MessageToByteEncoder),负责将消息对象编码为字节流进行发送。
通过使用这些编解码器,Netty 可以轻松地处理消息的编解码操作。编解码器的选择取决于具体的协议和数据格式要求,可以使用 Netty 提供的内置编解码器,也可以自定义编解码器以满足特定的应用需求。
82、 Netty常见的编解码器 有哪些?它们有啥特殊的地方吗?
在 Netty 中,常见的编解码器包括:
-
StringDecoder和StringEncoder:用于字符串的编解码器。StringDecoder将字节流解码为字符串,StringEncoder将字符串编码为字节流。 -
ObjectEncoder和ObjectDecoder:用于 Java 对象的序列化和反序列化编解码器。ObjectEncoder将 Java 对象编码为字节流,ObjectDecoder将字节流解码为 Java 对象。ObjectDecoder使用了LengthFieldBasedFrameDecoder,可以处理半包和粘包的情况。 -
JSON 相关的编解码器:Netty 提供了多个与 JSON 相关的编解码器,如
JsonEncoder和JsonDecoder,用于将对象转换为 JSON 格式和将 JSON 格式转换为对象。同时,还有JsonObjectEncoder和JsonObjectDecoder,针对 JSON 数据进行封帧处理,处理半包和粘包的情况。
这些编解码器具有特定的功能和优化:
ObjectEncoder和ObjectDecoder使用了长度字段来进行帧解析,可以处理半包和粘包的情况,确保数据的完整性。- JSON 相关的编解码器针对 JSON 格式的数据进行了优化,可以方便地将对象转换为 JSON 格式或将 JSON 格式转换为对象。
- 部分编解码器如
LengthFieldBasedFrameDecoder和JsonObjectDecoder都提供了解决半包和粘包问题的能力,确保数据在网络中可靠传输。
使用这些编解码器,可以简化编解码的操作,提高程序的可维护性和可读性。根据具体的需求,选择适当的编解码器可以大大简化开发过程,并确保数据在网络中的有效传输。
83、MessageToMessage门派编解码器与ByteToMessage&&MessageToByte的区别有哪些?
MessageToMessage 门派编解码器和 ByteToMessage、MessageToByte 体系的编解码器在实现和功能上存在一些区别。
-
方法参数:在编码器和解码器的实现中,
ByteToMessage体系的编解码器的decode方法的参数是ByteBuf,表示要解码的数据。而MessageToMessage门派的编解码器的encode和decode方法的参数可以是任意类型的对象,表示要编码或解码的消息对象。 -
封帧问题处理:
ByteToMessage体系的编解码器通常会处理封帧的问题,也就是半包和粘包的问题。通过解析字节流中的长度字段,确保读取和处理的数据完整。相对而言,MessageToMessage门派的编解码器通常不会处理封帧问题,需要额外的手段来解决。 -
使用场景:
ByteToMessage、MessageToByte体系的编解码器适合在底层进行字节流的处理,特别是涉及到封帧问题时。而MessageToMessage门派的编解码器更适合处理特定类型的消息对象,进行自定义的消息转换和处理。
需要根据具体的需求和场景选择适当的编解码器体系。如果需要底层的字节流处理和封帧问题的考虑,可以选择使用 ByteToMessage 和 MessageToByte 体系的编解码器。如果需要对特定类型的消息对象进行转换和处理,可以选择使用 MessageToMessage 门派的编解码器。
84、封帧相关的有哪些Handler
封帧相关的 Handler 在 Netty 中有以下几种:
-
FixedLengthFrameDecoder:固定长度帧解码器。它会按照指定的固定长度将收到的字节流进行切割,每个帧的长度都是相同的。适用于每个消息都是固定长度的情况。 -
LineBasedFrameDecoder:按行切割帧解码器。它会根据换行符(\n或\r\n)将收到的字节流进行切割,每行为一个帧。适用于文本协议中每行为一条消息的情况。 -
LengthFieldBasedFrameDecoder:基于长度字段的帧解码器。它通过读取指定位置的长度字段来确定帧的长度,并对收到的字节流进行切割,包含长度字段本身。这种帧解码器适用于复杂的消息格式,可以处理可变长度的帧。
这些帧解码器可以用于处理数据包的封帧问题,防止出现半包和粘包的情况。根据具体的协议和数据格式要求,选择适当的帧解码器可以确保数据的完整性,并方便后续的消息处理和解析。需要根据实际情况选择最适合的帧解码器,并根据需要进行定制和扩展。
85、序列化和编解码区别
序列化和编解码是相关但不完全相同的概念。
序列化(Serialization)是将对象转换为一种特定格式,使其可以在不同的系统之间进行传输或存储。在序列化过程中,对象的状态被转换为字节流,以便于传输和持久化。序列化通常用于将对象持久化到磁盘或通过网络传输。
编解码(Encoding and Decoding)是将数据转换为字节码或从字节码还原为数据的过程。编码可以将数据转换为字节码表示,而解码则是将字节码转换回原始数据。编解码通常用于在不同的数据表示之间进行转换,例如将文本字符串编码为字节流进行传输或存储,然后再将字节流解码为文本字符串以进行读取或处理。
总结来说,序列化是将对象转换为特定格式,编解码是将数据转换为字节码或从字节码还原为数据。序列化的主要目的是将对象转换为可传输或存储的形式,而编解码的主要目的是在不同的数据表示之间进行转换。在实际应用中,序列化和编解码可能会结合使用,例如将对象进行序列化,然后使用编解码器将序列化的字节流进行编码和解码。
86、那些编解码自带封帧呢?
在 Netty 中,ObjectDecoder 和 JsonObjectDecoder 编解码器是自带封帧功能的。
-
ObjectDecoder:ObjectDecoder是一个 Java 序列化相关的编解码器,用于将 Java 对象转换为字节流进行传输。它通过LengthFieldBasedFrameDecoder解码器自动处理了封帧问题,包括半包和粘包的情况。LengthFieldBasedFrameDecoder可以通过读取长度字段来确定帧的长度,并进行精确的解码。这样可以确保在传输过程中,每个对象都能被完整地读取和解码。 -
JsonObjectDecoder:JsonObjectDecoder是一个专为 JSON 数据设计的编解码器,它可以将 JSON 数据转换为对象进行处理。它也可以通过LengthFieldBasedFrameDecoder解码器来处理封帧问题,保证在传输过程中,每个 JSON 数据块都能被正确地解码和处理。
这些编解码器的自带封帧功能可以帮助我们在网络传输中解决半包和粘包的问题,确保数据的完整性和准确性。使用这些编解码器,我们可以更方便地处理序列化和 JSON 数据的编解码,并减少开发过程中对封帧问题的考虑。
87、使用StringDecoder或者StringEncoder需要注意什么呢?
在使用 StringDecoder 和 StringEncoder 进行编解码时,需要注意以下几点:
-
字符串转换:
StringDecoder和StringEncoder主要用于将字符串数据转换为字节流或将字节流转换为字符串数据。在使用时,需要注意输入和输出的数据类型要匹配,避免类型转换错误或数据损失。 -
内存管理:使用
StringDecoder和StringEncoder进行编解码时,生成的字符串对象是不可变的,即每次解码后会生成一个新的字符串对象。在处理大量字符串数据时,要注意及时释放字符串对象的引用,防止内存泄漏。 -
封帧处理:
StringDecoder和StringEncoder不会自动处理封帧问题,也就是半包和粘包的情况。这意味着在使用这些编解码器时,需要自行处理消息的封帧。可以结合使用其他的帧解码器(例如LineBasedFrameDecoder或LengthFieldBasedFrameDecoder)来解决封帧问题,确保数据的完整性。
使用 StringDecoder 和 StringEncoder 需要根据具体的业务需求和场景进行正确的配置和使用,以保证编解码的正确性和性能。同时,还需要注意内存管理和消息封帧的处理,以免出现潜在的问题。
88、pipeline的调用与Message个数相关
在 Netty 中,Pipeline 是用于处理消息的处理链。当消息从一个 ChannelHandler 传递到另一个 ChannelHandler 时,会按照 Pipeline 中的顺序依次经过每个 ChannelHandler 进行处理。
对于一条消息,Pipeline 的调用与消息个数相关。在 Netty 中,默认情况下,每个消息都会按顺序经过 Pipeline 中的每个 ChannelHandler 进行处理。也就是说,如果 Pipeline 中包含了多个 ChannelHandler,那么每个 ChannelHandler 都会对每条消息进行处理。
无论是接收到的消息还是发送的消息,都会沿着 Pipeline 依次经过每个 ChannelHandler 进行处理。每个 ChannelHandler 都有机会对消息进行处理、修改或者传递给下一个 ChannelHandler。
需要注意的是,每经过一个 ChannelHandler,都会给 Pipeline 中的下一个 ChannelHandler 发送一个新的消息对象。因此,Pipeline 调用与消息个数相关,每个消息都会经历 Pipeline 中的每个 ChannelHandler,并且会生成/传递给下一个 ChannelHandler 新的消息对象。
要根据业务需求来配置和使用 Pipeline 中的 ChannelHandler,以确保消息能够得到正确的处理和转发。
89、如何限定handler中msg的类型呢?
要限定 Handler 中 msg 的类型,可以使用 SimpleChannelInboundHandler。
SimpleChannelInboundHandler 是一个抽象的 ChannelInboundHandler,它会自动释放处理完的消息,并且只处理特定类型的消息。在实现自定义的 Handler 时,可以继承 SimpleChannelInboundHandler,并指定要处理的消息类型。
下面是一个使用 SimpleChannelInboundHandler 来限定消息类型的示例:
public class MyHandler extends SimpleChannelInboundHandler<String> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception {
// 处理 String 类型的消息
// ...
}
}
在这个示例中,MyHandler 继承了 SimpleChannelInboundHandler,表示该 Handler 只处理 String 类型的消息。当有消息到达时,会自动调用 channelRead0 方法来处理消息。
在 channelRead0 方法的参数中,msg 的类型就是指定的 String,所以不需要在方法内部进行类型转换。同时,当 channelRead0 方法执行完毕后,SimpleChannelInboundHandler 会负责释放消息。
通过使用 SimpleChannelInboundHandler,可以方便地限定 Handler 中 msg 的类型,避免了手动类型转换的麻烦,并提供了自动释放消息的功能。
90、SimpleChannelInBound作用
SimpleChannelInboundHandler 是 Netty 提供的用于处理入站消息的抽象类,它具有以下作用:
- 限定消息类型:通过泛型参数来指定具体的消息类型,只处理指定类型的消息。继承
SimpleChannelInboundHandler时,可以通过指定泛型来限制msg的类型,避免了手动类型转换的麻烦。 - 自动释放:
SimpleChannelInboundHandler在处理完消息后会自动释放消息,无需手动调用ReferenceCountUtil.release(msg)进行释放。这样可以提高开发效率,避免因忘记释放而导致的内存泄漏问题。
通过继承 SimpleChannelInboundHandler,可以快速实现消息的处理,并且免去了手动处理消息类型和释放消息的繁琐步骤。
91、channelRead和channelRead0的区别?
channelRead 和 channelRead0 都是用于处理入站消息的方法,它们的区别在于:
- 底层调用关系:
channelRead是ChannelInboundHandler接口中定义的方法,而channelRead0则是SimpleChannelInboundHandler中的抽象方法。在SimpleChannelInboundHandler中,channelRead0是由 Netty 自动调用的,而channelRead是底层调用channelRead0的方法。 - 参数处理:
channelRead方法的参数是ChannelHandlerContext和Object,需要手动进行类型转换。而channelRead0方法的参数根据具体的泛型类型指定了消息的对象类型,无需进行类型转换,直接使用即可。
在使用 SimpleChannelInboundHandler 时,由于 channelRead0 方法会自动调用并传入正确的消息对象,因此通常只需重写 channelRead0 方法即可。如果需要直接使用底层的 channelRead 方法,需要手动进行类型转换和其他额外的处理。
总而言之,channelRead0 是 SimpleChannelInboundHandler 提供的用于处理指定类型消息的抽象方法,而 channelRead 则是其底层调用方法,一般情况下我们只需要重写 channelRead0 方法即可。
92、HTTP编解码器相关有哪些?
在 Netty 中,有一些常用的 HTTP 编解码器,用于对 HTTP 协议进行编解码。以下是一些常见的 HTTP 编解码器:
-
HttpServerCodec:HttpServerCodec是一个综合的编解码器,它包含了HttpRequestDecoder和HttpResponseEncoder。它在进行解码操作时,会将一个完整的 HTTP 协议解码成两个消息对象:HttpRequest和HttpContent。HttpServerCodec可以方便地将 Netty 作为 HTTP 服务器使用。 -
HttpObjectAggregator:HttpObjectAggregator是一个聚合器,将HttpRequest和HttpContent聚合在一起,形成一个完整的FullHttpRequest或FullHttpResponse。它在处理完一个完整的 HTTP 请求或响应之后,可以将多个消息合并成一个完整的消息对象,便于后续的处理。
除了上述编解码器之外,还有其他一些与 HTTP 相关的编解码器,例如:
HttpResponseEncoder:将 HTTP 响应编码成字节流。HttpRequestDecoder:将字节流解码成 HTTP 请求。HttpContentCompressor:对 HTTP 请求或响应的内容进行压缩。
这些编解码器可以用于构建 HTTP 服务器或客户端,以便于处理 HTTP 请求和响应。使用这些编解码器可以简化开发过程,高效地处理 HTTP 协议相关的消息。
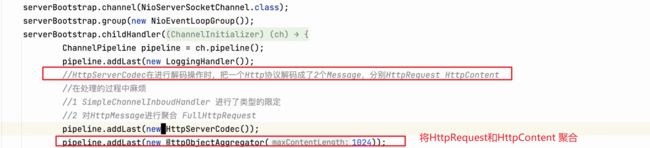
93、Http协议的解码器,会出现半包粘包问题么?
在 Netty 中,HTTP 协议的解码器通常不会出现半包粘包问题。这是因为 HTTP 协议的请求和响应中,通过 Content-Length 头部字段来明确指定消息体的长度。
当 Netty 的 HTTP 解码器解析到 Content-Length 头部字段时,会根据指定的长度准确地读取和解析消息体,避免了半包和粘包的问题。
此外,Netty 提供的 HTTP 编解码器(例如 HttpServerCodec)本身继承了 ByteToMessageCodec,它会处理字节流的拆包和封包问题,确保将接收到的字节流按照正确的方式分割并传递给下一个处理器。
所以,如果使用 Netty 自带的 HTTP 解码器以及其他自定义的处理器,往往可以避免半包和粘包的问题,而且能够按照规范解析和处理 HTTP 协议的请求和响应。

94、编解码器合二为一如何自定义?
如果你想要将编码器和解码器合二为一,可以自定义一个类,并继承 ByteToMessageCodec。ByteToMessageCodec 是一个抽象类,它既实现了编码逻辑,也实现了解码逻辑。
在自定义的类中,你需要重写 decode 方法和 encode 方法来实现解码和编码的逻辑。decode 方法将输入的 ByteBuf 解码为消息对象,encode 方法将消息对象编码为 ByteBuf。
下面是一个示例,演示了如何自定义一个合并编解码器的类:
public class MyCodec extends ByteToMessageCodec<Message> {
@Override
protected void encode(ChannelHandlerContext ctx, Message msg, ByteBuf out) throws Exception {
// 将消息对象编码为 ByteBuf
// ...
}
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
// 将 ByteBuf 解码为消息对象,并将解码后的对象添加到 out 列表中
// ...
}
}
在上述示例中,MyCodec 继承了 ByteToMessageCodec,并通过泛型参数指定了消息对象的类型为 Message。在 encode 方法中,你需要实现将 Message 对象编码为 ByteBuf 的逻辑;而在 decode 方法中,你需要实现将 ByteBuf 解码为 Message 对象的逻辑,并将解码后的对象添加到 out 列表中。
通过自定义一个继承 ByteToMessageCodec 的类,你可以方便地将编码器和解码器合二为一,在 Netty 中进行统一的数据处理。
95、ReplayingDecoder有什么作用吗?
ReplayingDecoder 是 Netty 提供的一个特殊的解码器,它的作用是简化解码器的实现,并且可以在不满足输入条件时进行等待。
普通的解码器需要预先知道输入数据的长度或者其他条件,才能进行解码操作。但是在某些场景下,我们可能无法提前获取到完整的解码信息或者需要在解码过程中等待更多的输入数据。这时候,ReplayingDecoder 就派上了用场。
ReplayingDecoder 可以让你像编写阻塞式代码一样编写解码器,而实际上是通过非阻塞方式实现等待。它在解码器的实现中提供了一系列的方法,例如 channelRead、channelRead0、state 等,可以方便地控制解码器的逻辑以及等待输入的行为。
当输入数据不足或者不完整时,ReplayingDecoder 会阻塞解码线程,等待更多的输入数据。一旦满足了解码的条件,即可继续进行解码操作。
总结一下,ReplayingDecoder 的作用是简化解码器的实现,同时在不满足解码条件时进行等待,从而更灵活地进行解码操作。它允许你以阻塞式的编码方式进行解码器的开发,并且通过非阻塞方式实现等待。
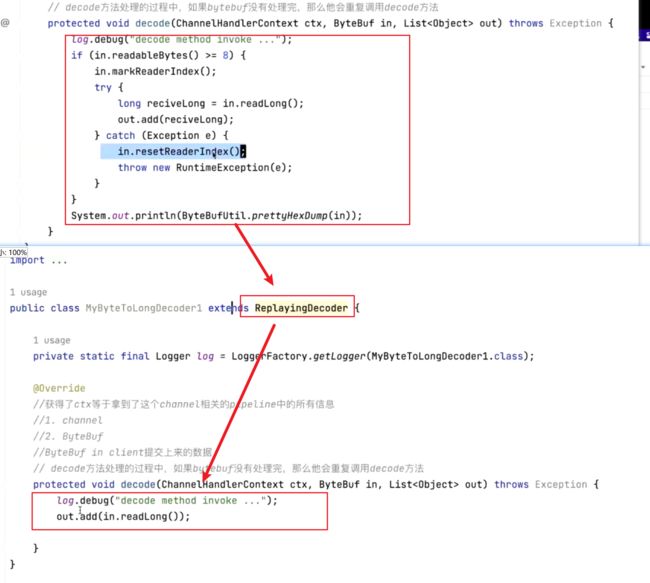
96、编码器ByteBuf数据 一次处理不完有什么后果吗?
如果ByteBuf的数据一次解码没有处理完成,则Netty会重复调用decode方法
97、如何自定义系统的通信协议?
自定义系统的通信协议需要以下步骤:
1. 设计协议头:协议头包含一些重要的字段,用于标识和识别通信协议。常见的字段有:
- 幻数(魔术):一段特定的字符或数字,用于标识协议的开始,防止数据的重复或错误解析。
- 版本号:指示协议的版本,确保通信双方使用的是兼容的协议版本。
- 指令类型:标识当前通信的目的和操作,例如登录、注册、业务操作的编号等。
- 序列化方式:指示数据的序列化方式,常见的有 JSON、Protocol Buffers、Hessian 等。
- 正文长度:表示协议正文的长度,用于辅助解析数据。
2. 设计协议正文(协议体):协议正文是通信协议中用于传输具体数据的部分。它可以是一个结构化的对象,也可以是特定形式的消息体。根据你的需求,可以自定义字段和数据格式。在你给出的示例中,协议正文是一个 json 对象,包含了 name 和 password 两个字段。
在协议的设计过程中,需要考虑以下几点:
- 数据格式:选择合适的数据格式,例如 JSON、XML、Protocol Buffers 等。
- 字段定义:根据业务需求定义协议字段,确保数据的完整性和准确性。
- 数据加密:如果需要对数据进行加密,可以在协议设计中考虑加入加密算法。
- 数据压缩:如果数据传输时需要进行压缩以节省带宽,可以在协议设计中考虑加入压缩算法。
在实际实现时,可以选择相应的编程语言和框架,使用协议设计相关的库/工具进行开发和解析,以便更轻松地处理自定义通信协议。
99、Pipeline里面到底有几个Handler呢?
在一个典型的网络通信中,Pipeline 是一个用于处理入站和出站事件的通道。通常,在 Pipeline 中至少会有一个 ChannelInitializer 和一个尾部(tail)Handler。
ChannelInitializer 用于在 Channel 创建时,将一组用户自定义的 Handler 添加到 Pipeline 中。这些自定义的 Handler 可以按照特定的顺序添加到 Pipeline 中。
在 Pipeline 中,每一个添加的自定义 Handler 都会作为一个节点存在。当数据进来或出去时,这些节点会依次执行对应的逻辑(处理事件)。因此,Pipeline 中的 Handler 的数量除了 ChannelInitializer 外,还包括添加的自定义 Handler 的数量。
当数据进入 Pipeline 时,会首先经过 ChannelInitializer,然后按照添加的顺序依次经过每个自定义 Handler,最后到达尾部(tail)Handler 进行处理。
所以,Pipeline 中的 Handler 的数量一般为添加的自定义 Handler 的数量加上一个 ChannelInitializer 和一个尾部(tail)Handler。
100、channel的生命周期方法都有哪些?
channel的生命周期方法包括:
1. addHandler:向Channel的Pipeline中添加一个Handler。
2. channelRegistered:当连接(Channel)被分配到具体的worker线程上时,回调此方法。用于通知Channel注册完成。
3. channelActive:在Channel准备就绪,所有的Pipeline上的Handler添加完成后被回调。这意味着Channel可以进行通信了,可以通过此方法向另一方写数据。
4. channelRead:接收数据的操作,每次接收到数据都会回调此方法。
5. channelReadComplete:读操作结束时被回调。用于释放资源,类似于finally代码块。
6. channelInactive:当Channel连接断开时被回调。表示TCP连接已经关闭。
7. channelUnregistered:当Channel被关闭时被回调。表示将Channel分配给我们的worker线程返回给EventLoopGroup。
8. removeHandler:从Channel的Pipeline中移除一个Handler。
这些方法提供了对Channel生命周期不同阶段的回调,可以在这些方法中执行相应的业务逻辑,以便更好地管理Channel和处理相应的事件。
101、异常的处理是如何处理的?
在处理网络通信过程中,异常处理是非常重要的一部分。Netty 提供了一种机制来处理异常,即使用异常处理器(exception handler)来捕获和处理发生在处理器中的异常。常见的异常处理方式包括使用 ChannelHandler 的 `exceptionCaught` 方法以及设置日志记录。
1. `exceptionCaught` 方法:每个 ChannelHandler 都可以实现 `exceptionCaught` 方法来处理发生在自身或前面的处理器中的异常。当异常发生时,这个方法就会被调用,可以在这个方法中编写自定义的异常处理逻辑,例如打印异常信息、关闭相关资源等。这个方法是最后一个能捕获异常的机会,通常应该在这个方法中处理未被前面处理器捕获的异常。
2. 设置日志记录:在开发过程中,设置日志记录非常重要,可以通过日志记录工具(例如Log4j、SLF4J等)来记录异常的发生情况。日志记录可以帮助开发者追踪和定位异常,以便进行适当的处理和调试。
在异常处理过程中,应该注意以下几点:
- 当判断可能发生异常的地方,应该在代码中使用 try-catch 语句进行捕获。
- 在捕获到异常后,应该根据具体情况选择适当的处理方式,例如记录异常日志、关闭相关资源或者发送错误响应等。
- 尽量避免在异常处理逻辑中抛出新的异常,以免引发连锁反应和异常溢出。
- 开发过程中,务必设置日志记录,以便在出现异常时能够追踪和排查问题。
通过合理的异常处理机制,能够提高系统的健壮性和稳定性,并帮助开发者及时发现和解决问题。
102、总结handler
103、IdleStateHandler
IdleStateHandler 是 Netty 提供的一个用于处理空闲状态的处理器。它可以用于检测连接的读写空闲时间,当连接在一定时间内没有进行读写操作时,会触发相应的事件回调。
使用 IdleStateHandler 主要有两个作用:
1. 空闲检查:通过设置空闲时间,可以检测连接在一段时间内是否有读写操作。当连接处于读或写空闲状态时,会触发相应的 IdleStateEvent 事件。
2. 心跳机制:空闲检查的一个主要应用场景就是实现心跳机制。通过定期发送心跳消息,如果一段时间内没有接收到心跳回复,就表明网络可能不通畅或者连接已经断开。
使用 IdleStateHandler 需要指定三个参数:
- readerIdleTime:读空闲时间,即在指定时间内如果没有读取到数据,就会触发 READER_IDLE 空闲事件。
- writerIdleTime:写空闲时间,即在指定时间内如果没有写入数据,就会触发 WRITER_IDLE 空闲事件。
- allIdleTime:读写空闲时间,即在指定时间内如果既没有读取也没有写入数据,就会触发 ALL_IDLE 空闲事件。
当一个空闲事件发生时,相应的事件回调方法会被调用,通常在这些回调方法中,我们可以执行一些特定的业务逻辑,例如关闭连接、发送心跳消息等。
总结来说,IdleStateHandler 是用于处理空闲状态的处理器,主要应用于检测连接的读写空闲时间并触发相应的事件回调,常见的应用场景是实现心跳机制。
104、如何应对当客户端没有问题但是服务器把客户端的链接给关掉这种情况?
在客户端面对服务器关闭客户端连接的情况,可以采取以下几种应对策略:
-
重试机制:在客户端的代码中,可以实现一个重试机制。当客户端发现连接被关闭时,可以在
channelInactive方法中进行处理。在处理前,可以设置一个重试次数,并记录已重试的次数。当连接关闭时,可以尝试重新连接服务器。如果重试次数未达到上限,可以进行重试。如果重试次数超过设定的上限,则可以进行相应的处理,例如显示错误信息或者退出程序。 -
建立心跳机制:通过建立心跳机制,客户端可以定期向服务器发送心跳消息以维持连接。如果客户端检测到连接断开,可以立即进行重连,并重新建立心跳机制。这样可以及时发现连接问题,并保持客户端与服务器之间的通信。
-
错误处理和日志记录:当客户端连接被关闭时,可以捕获异常并进行错误处理。可以根据具体业务需求,选择适当的策略处理异常,例如重试、重新连接或者退出程序。同时,建议在客户端代码中添加日志记录,以便排查问题和分析连接关闭的原因。
需要注意的是,在实现重试机制或者心跳机制时,应合理设置重试次数、重试间隔时间等参数,以平衡连接的恢复速度和系统资源消耗。
总之,在服务器关闭客户端连接的情况下,客户端可以通过重试机制、建立心跳机制以及错误处理等措施来应对并处理这种情况,以保障客户端与服务器之间的通信稳定性。
105、WebSocketServerProtocalHandler有什么作用?
WebSocketServerProtocolHandler 是 Netty 提供的一个处理器,主要用于增强 Netty 对 WebSocket 的支持能力。
WebSocket 是一种在 Web 应用中实现双向通信的协议。与传统的 HTTP 协议相比,WebSocket 具有实时性好、支持双向通信、更小的网络开销等特点。
WebSocketServerProtocolHandler 的作用主要包括以下几个方面:
-
握手:WebSocketServerProtocolHandler 能够处理 WebSocket 的握手流程,包括客户端发起 WebSocket 连接请求、服务器接收并解析请求,然后进行握手响应等操作。简化了握手过程的处理和管理。
-
帧处理:WebSocket 通信是通过帧(Frame)进行的,而不是传统的请求-响应模式。WebSocketServerProtocolHandler 能够自动将接收到的数据按照帧的格式进行解析和处理,将数据转换成完整的消息进行传递,省去了开发者手动解析和拼装帧的工作。
-
路由:WebSocketServerProtocolHandler 可以根据请求的 URI 进行路由处理。根据不同的 URI,可以将请求分发到不同的处理器中,实现根据路径进行消息分发和处理的能力。
-
心跳:WebSocketServerProtocolHandler 还支持心跳机制,可以根据预设的时间间隔发送心跳消息,确保长连接的稳定性。当客户端和服务器之间没有任何数据收发时,心跳机制可以检测到连接是否仍然有效,并及时发现断开连接的情况。
总结来说,WebSocketServerProtocolHandler 的作用是增强 Netty 对 WebSocket 的支持能力,包括处理握手流程、帧解析与处理、路由分发和支持心跳机制等功能,使得开发者可以更方便地使用 Netty 来处理 WebSocket 通信。
106、 WebSocket干什么用的?
WebSocket 是一种在 Web 应用中实现全双工通信的协议。它能够在服务器端发生变化时主动通知客户端,实现实时性强、低延迟的双向通信。
传统的 Web 应用中,客户端与服务器之间的通信是通过 HTTP 协议的请求-响应模式实现的。客户端发送请求,服务器返回响应。这种模式在一些场景下存在一些限制,如实时聊天、股票行情推送等。
而 WebSocket 协议通过在客户端与服务器之间建立一条持久的双向通信通道,使得服务器能够主动向客户端推送消息,而不需要客户端主动发起请求。这样就实现了服务器端发生变化时能够即时通知客户端的功能。
WebSocket 的特性包括:
-
全双工通信:客户端和服务器之间可以同时进行双向的通信,实现实时的消息传递。
-
长连接:WebSocket 通过建立一条持久的连接,在连接保持期间可以进行多次通信,减少了建立和关闭连接的开销。
-
低延迟:由于建立了长连接,服务器端可以实时向客户端推送消息,实现了实时性强、低延迟的通信。
-
与 HTTP 兼容:WebSocket 协议通过 HTTP 进行握手,使用 HTTP 的 80 端口或者 443 端口进行通信。
WebSocket 协议的使用能够广泛应用于一些实时性要求较高的场景,如在线聊天、实时数据推送、多人协同编辑等。它相比于传统的轮询和长轮询等技术,能够提供更好的性能和用户体验。
需要注意的是,要使用 WebSocket 协议,服务器端和客户端都需要支持 WebSocket,常见的开发框架和库都提供了对 WebSocket 的支持。
107、WebSocket发送消息过程中需要注意什么?
在 WebSocket 发送消息的过程中,需要注意以下几点:
-
消息封装:WebSocket 发送的消息需要进行适当的封装。对于文本消息,可以使用 TextWebSocketFrame 将字符串内容封装成 WebSocket 帧;对于二进制消息,可以使用 BinaryWebSocketFrame 将字节数据封装成 WebSocket 帧。根据实际需求和协议规范,选择适当的封装方式。
-
编码问题:在发送消息前,要确保消息内容以及编码格式是正确的。如果发送的是文本消息,可以指定消息的字符编码,确保消息在传输过程中的正确解析和显示。
-
分片传输:如果消息内容较大,超过了 WebSocket 协议规定的消息长度限制,需要进行分片传输。将消息分成多个小块,并分多次发送,接收方在接收到所有分片后再进行拼装。这需要在协议设计和消息处理中进行相应的处理。
-
阻塞和异步:WebSocket 发送消息是非阻塞的,也就是不会等待消息发送完成后再返回。发送消息是一种异步操作,发送方法会立即返回,不会阻塞线程。如果需要在消息发送完成后获取发送结果,可以使用回调函数或者 Future 等机制进行处理。
-
错误处理:在发送消息的过程中,可能会遇到一些异常情况,如连接断开、网络异常等。在实际应用中,需要对这些异常情况进行捕获和处理,以保证消息的可靠性和稳定性。
-
消息顺序:由于 WebSocket 是全双工通信,消息的发送和接收可能不按顺序进行。在实际应用中,可能需要对消息进行标识或者排序,保证消息的顺序性。
以上是在 WebSocket 发送消息过程中需要注意的一些方面。具体的实现和处理方式,还需要根据具体的业务需求和框架使用进行调整和优化。
108、Handler处理过程中 什么情况下可以被多个pipeline共用【使用Shareable 】?
在 Nsetty 中,Handler 可以通过标记 @Sharable 注解来指定是否可以被多个 Pipeline 共用。
下面是可以被多个 Pipeline 共用的情况:
-
无状态的 Handler:如果 Handler 是无状态的,即它不包含任何实例变量,也不会修改其所处理的消息,那么它可以被多个 Pipeline 共用。无状态的 Handler 在多个 Pipeline 中会被并发调用,因此需要保证线程安全。
-
使用锁的 Handler:有些 Handler 可能会包含一些实例变量,但是在处理消息时使用了锁机制来保证线程安全。在这种情况下,可以使用
@Sharable注解将这些处理器标记为可共用的,使一个实例可以被多个 Pipeline 共享。由于使用了锁进行同步,所以在多个 Pipeline 中调用时会有一定的性能影响。 -
MessageToMessageDecoder:MessageToMessageDecoder是一个用于将一种类型的消息转换为另一种类型的消息的特殊处理器。它可以被多个 Pipeline 共用,并且不需要加锁或采取其他线程同步措施。
以下情况下不能被多个 Pipeline 共用:
-
ByteToMessageDecoder及其子类:ByteToMessageDecoder是在解码字节流到消息对象时使用的处理器,它的解码状态会与具体的 Pipeline 相关,因此不应该被多个 Pipeline 共用。 -
ByteToMessageEncoder:ByteToMessageEncoder是用于将消息对象编码为字节流的处理器,它也不应该被多个 Pipeline 共用,因为编码状态与具体的 Pipeline 相关。
在实际开发中,我们需要根据业务需求和处理器的特性来确定是否将处理器设置为可共用的 @Sharable。同时,需要注意处理器的并发安全性和线程同步,保证在多个 Pipeline 中的正确使用。
109、关于公用Handler需要注意什么地方?
在使用可共用的 Handler(带有 @Sharable 注解)时,需要注意以下几个方面:
-
线程安全性:由于可共用的 Handler 可能会被多个 Pipeline 共享,并且在多个线程中同时调用,因此需要确保其线程安全性。避免在 Handler 中使用实例变量或共享资源,或者使用同步机制(如锁)来保证线程安全。
-
并发调用:多个 Pipeline 可能会同时调用共用的 Handler,因此需要确保在并发调用时不会出现线程竞争或资源争用的问题。理解并发调用时代码的执行顺序和可能存在的问题,并进行合适的线程同步。
-
上下文信息:共用的 Handler 可能会被多个不同的 Pipeline 调用,它们之间可能存在不同的上下文信息。确保在处理消息时,不会依赖于 Pipeline 特定的上下文信息,而是根据消息本身进行处理。
-
有状态的 Handler:如果共用的 Handler 是有状态的(含有实例变量),需要谨慎处理状态的正确性。确保状态不会被跨 Pipeline 污染或篡改,并考虑线程同步的需求。
-
解码和编码:一些特殊的 Handler,如
ByteToMessageDecoder和ByteToMessageEncoder,通常不应该被共用,因为它们的解码和编码状态与具体的 Pipeline 相关。在需要解码和编码的处理中,可以通过自定义实现来避免共用问题。
总之,使用可共用的 Handler 可以提高代码的复用性和效率,但需要注意线程安全、并发调用、上下文信息和有状态处理等问题。根据具体的业务场景和需求,合理地选择和设计可共用的 Handler,或者在不适合共用的情况下使用独立的 Pipeline 创建处理器。
110、如何公用?以及公用Handler的含义?
公用 Handler 意味着多个 Pipeline 可以共享同一个 Handler 实例,从而避免在每个 Pipeline 中创建新的 Handler 实例。
要实现公用 Handler,可以通过以下步骤:
-
创建一个可共用的 Handler:确保 Handler 是无状态的,或者在有状态的情况下实现了线程安全。可以使用
@Sharable注解来标记一个 Handler 可以被多个 Pipeline 共享。 -
在创建 Pipeline 之前实例化 Handler:不要在每个 Pipeline 中单独创建 Handler 实例,而是在创建 Pipeline 之前提前创建好 Handler 的实例。
-
将共用的 Handler 添加到多个 Pipeline 中:将之前创建好的 Handler 实例添加到各个 Pipeline 的 ChannelPipeline 中,使它们共享同一个 Handler。
这样,多个 Pipeline 就可以共用同一个 Handler 实例,从而共享其状态和行为,提高代码的复用性和性能。
值得注意的是,当一个 Handler 被多线程访问时,需要确保其线程安全性。这包括避免在 Handler 中使用实例变量、合理使用同步机制(如锁)来保证线程安全,以及处理并发调用可能带来的问题。同时,需要在处理消息时,不依赖于特定的 Pipeline 上下文信息,而是根据消息本身进行处理。
公用 Handler 的含义在于通过共享同一个 Handler 实例,避免了每个 Pipeline 都创建新的 Handler 实例带来的性能消耗和资源浪费。同时,减少了代码的重复性,提高了代码的可维护性和可扩展性。但需要注意并发访问的线程安全性和处理器的状态一致性。
111、Channel什么时候关闭?
在网络编程中,Channel 的关闭时机通常由以下几个因素决定:
-
处理器回调:在处理器的回调方法(例如
channelRead()、exceptionCaught())中,可以根据特定的业务逻辑决定何时关闭 Channel。例如,在读取到特定的消息后,可以选择关闭 Channel。处理器可以使用ChannelHandlerContext调用close()方法来关闭 Channel。 -
IdleStateHandler 处理:IdleStateHandler 是一个常用的处理器,用于检测 Channel 的空闲状态。当 Channel 达到空闲状态(如读空闲、写空闲或读写空闲)时,可以通过此处理器进行处理并关闭 Channel。
-
异常发生:当发生异常情况无法恢复时,可以选择关闭 Channel。例如,遇到无法处理的协议错误、网络中断等情况,可以通过异常处理机制关闭 Channel,以防止进一步的异常传播和资源泄漏。
-
程序正常退出:在程序正常退出时,可以选择关闭所有打开的 Channel,以确保资源的正确释放和系统的安全关闭。可以在程序的退出回调或关闭钩子中关闭所有的 Channel。
需要注意的是,一旦关闭了 Channel,就不能再使用它进行读写操作或发送消息。关闭 Channel 后,它所关联的套接字和其他底层资源将被释放,并且无法再重新打开或使用。
关闭 Channel 的时机需要根据具体的业务逻辑和需求来决定,确保在合适的时机关闭 Channel,以避免资源泄漏和不必要的开销。同时,需要处理关闭 Channel 的异常和后续操作,以保证程序的稳定性和可靠性。
112、netty客户端的参数是怎么设置的?服务端的参数是怎么设置的?
在 Netty 中,客户端和服务端的参数可以通过设置特定的选项来实现。具体而言:
-
客户端参数设置:
- 创建一个
Bootstrap实例,并通过option()方法设置客户端的参数选项。 - 使用
option()方法可以设置底层套接字的参数,例如连接超时时间、TCP参数等。例如,可以使用bootstrap.option(ChannelOption.CONNECT_TIMEOUT_MILLIS, timeout)设置连接超时时间。 - 可以根据具体需求设置其他参数选项,例如
SO_KEEPALIVE、SO_RCVBUF、SO_SNDBUF等。 - 最后,调用
connect()方法连接到服务器。
- 创建一个
-
服务端参数设置:
- 创建一个
ServerBootstrap实例,并通过option()方法设置服务端的参数选项。 - 使用
option()方法可以设置 ServerSocketChannel 的底层套接字参数。例如,可以使用serverBootstrap.option(ChannelOption.SO_BACKLOG, backlog)设置连接请求的队列大小。 - 使用
childOption()方法设置服务端监听的 SocketChannel 的参数。例如,可以使用serverBootstrap.childOption(ChannelOption.SO_RCVBUF, rcvBufSize)设置 SocketChannel 的接收缓冲区大小。 - 可以根据具体需求设置其他参数选项,例如
SO_KEEPALIVE、SO_REUSEADDR、SO_TIMEOUT等。 - 调用
bind()方法绑定服务器监听的端口。
- 创建一个
需要注意的是,在设置参数选项时,应该根据具体的需求和网络环境选择合适的参数值。同时,还应该考虑到系统资源的限制和性能需求,避免设置过大或过小的参数值导致不必要的开销或性能问题。
另外,还可以通过使用 ChannelInitializer 在客户端和服务端的管道初始化过程中进行更灵活的参数设置和处理。这样可以根据具体的需求,逐个设置和配置每个 Channel 的参数,包括编解码器、处理器等。
113、RCVBUF_ALLOCATOR设置的内容以及作用?
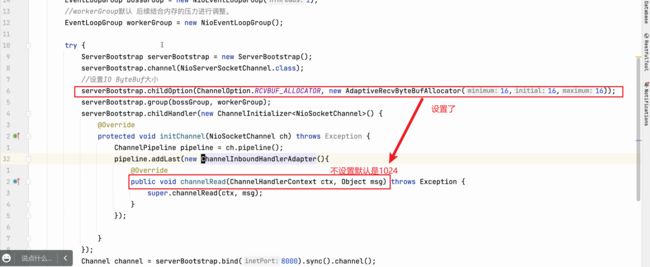
在 Netty 中,RCVBUF_ALLOCATOR 是一个重要的选项,用于设置服务端接收缓冲区的分配器,即 ByteBuf 的缓冲区大小和分配方式。它的作用是控制服务端接收数据的性能和内存的使用。
具体来说,RCVBUF_ALLOCATOR 的设置包括以下内容:
-
设置缓冲区大小:通过选择不同的分配器类型,可以决定服务端接收缓冲区的大小。通常有两种分配器可供选择:
PooledByteBufAllocator:使用内存池来分配 ByteBuf,可以重用已经分配的内存块,提高内存使用效率。可以通过设置PooledByteBufAllocator.DEFAULT_MAX_CAPACITY和PooledByteBufAllocator.DEFAULT_MAX_COMPOSITE_BUFFER_COMPONENTS来控制内存池的最大容量和复合缓冲组件的最大数量。UnpooledByteBufAllocator:每次请求都会分配一个新的 ByteBuf 对象,不使用内存池。适用于临时数据或数据量较小的场景。
-
直接内存分配:Netty 的设计中,接收数据的 ByteBuf 默认是直接内存。直接内存分配不占用 JVM 堆内存,可以提高网络传输的效率。可以通过设置
preferDirect参数为true或false来决定是否使用直接内存分配器。
设置 RCVBUF_ALLOCATOR 的目的是在服务端接收数据时,控制缓冲区的大小和内存的使用,确保系统在高并发场景下具有更好的性能和稳定性。
需要根据实际的业务需求和系统资源情况,选择合适的缓冲区大小和分配方式。同时要注意,过大的缓冲区大小可能会导致内存占用过高,而过小的缓冲区大小可能会导致频繁的内存分配和复制操作。因此,需要进行合理的测试和调优,找到适合自己业务场景的最佳配置。
作用:设置服务端 Bytebuf缓冲区大小,这个IO ByteBuf在netty设计中,只能是直接内存。
114、RCVBUF_ALLOCATOR如何主动设置?
要主动设置 RCVBUF_ALLOCATOR,可以使用 Netty 提供的 AdaptiveRecvByteBufAllocator 类。以下是设置示例:
serverBootstrap.childOption(ChannelOption.RCVBUF_ALLOCATOR, new AdaptiveRecvByteBufAllocator(16, 16, 16));
在上述示例中,AdaptiveRecvByteBufAllocator 构造函数接受三个参数:
minimum: 最小缓冲区大小(单位:字节),即初始分配的缓冲区大小。initial: 每次扩容所增加的缓冲区大小,通过动态调整缓冲区大小,以适应实际接收数据的情况。maximum: 最大缓冲区大小,限制缓冲区的最大容量,以防止过大的内存占用。
AdaptiveRecvByteBufAllocator 根据实际的接收数据情况在 newBuffer() 方法中动态计算缓冲区大小。它会根据历史接收到的数据量、接收速率和系统负载情况进行自适应调整,以保证缓冲区的大小适应实际需求。
通过将 AdaptiveRecvByteBufAllocator 设置给服务端的 childOption(),可以使服务端在接收数据时动态调整缓冲区大小,达到更好的性能和内存利用效率。
需要根据具体的业务场景和需求,合理设置 minimum、initial 和 maximum 参数,以及其他相关的配置选项,进行性能优化和内存调优。
115、SO_RCVBUF & SNDBUF的作用
`SO_RCVBUF` 和 `SO_SNDBUF` 是用于设置 TCP 套接字接收缓冲区和发送缓冲区的选项。
具体作用如下:
1. `SO_RCVBUF`(ServerSocketChannel 的 `option()`):用于设置服务端套接字的接收缓冲区大小。接收缓冲区用于存储从网络接收到的数据,直到应用程序读取处理。较大的接收缓冲区可以容纳更多的数据,减少了丢包和数据拥塞的可能性,提高了接收数据的效率和性能。
2. `SO_SNDBUF`(SocketChannel 的 `option()`):用于设置客户端套接字的发送缓冲区大小。发送缓冲区用于存储将要发送到网络的数据,直到网络设备准备好发送。较大的发送缓冲区可以容纳更多的数据,减少了发送频率和复制操作,提高了发送数据的效率和性能。
通过调整 `SO_RCVBUF` 和 `SO_SNDBUF` 的大小,可以根据通信要求和系统资源情况优化 TCP 套接字的接收和发送性能。较大的缓冲区可以减少网络传输中的延迟,并提供更稳定和高效的数据传输。
要注意的是,缓冲区大小应该根据实际需求和系统资源进行合理的配置。过小的缓冲区可能导致网络阻塞或数据丢失,而过大的缓冲区可能导致内存占用过高。需要根据具体的业务场景和需求,进行适当的测试和调优,找到最佳的缓冲区大小。
116、SO开头的参数有什么意义呢?
以 "SO_" 开头的参数都是与操作系统底层 TCP 协议相关的选项。它们可以通过 Netty 的参数设置来间接地修改对应操作系统的设置。
"SO_" 是 Socket Options(套接字选项)的缩写,这些选项可以影响套接字的行为和性能。通过设置这些选项,可以对 TCP 套接字进行更精确地控制和优化。
一些常见的以 "SO_" 开头的选项包括:
1. `SO_RCVBUF`:设置接收缓冲区大小。
2. `SO_SNDBUF`:设置发送缓冲区大小。
3. `SO_KEEPALIVE`:开启保活机制,检测长时间无数据交互的连接是否仍然有效。
4. `SO_REUSEADDR`:允许立即重用处于 TIME_WAIT 状态的端口。
5. `SO_LINGER`:设置关闭套接字时的行为,控制是否将未发送完成的数据发送完毕后再关闭套接字。
6. `SO_TIMEOUT`:设置阻塞操作的超时时间。
7. `SO_BACKLOG`:设置监听套接字的等待连接队列的最大长度。
这些选项的具体意义和使用方法可以在操作系统和网络编程相关的文档或手册中找到。通过设置这些选项,可以根据应用程序的具体需求实现更高效、稳定的网络通信。需要注意的是,在使用这些选项时,应确保了解其含义和影响,并进行适当的测试和调优。
117、Socket缓冲区大小如何修改呢?它和滑动窗口是什么关系呢?
-
修改 Socket 缓冲区大小:可以通过
option()函数来设置SO_RCVBUF(接收缓冲区)和SO_SNDBUF(发送缓冲区)的大小。具体的设置方式和范围可能取决于所使用的网络编程框架和操作系统。通过增大或减小缓冲区大小,可以对网络传输性能进行优化。 -
关系:
- 初始化时大小等于滑动窗口:在 TCP 连接建立时,滑动窗口的大小通常会初始化为接收缓冲区的大小。这是因为接收端需要将接收到的数据存储在缓冲区中,滑动窗口大小决定了发送端可以连续发送的数据量。
- 使用后滑动窗口大小等同于 Socket 缓冲区【剩余空间】大小:随着数据的传输,接收端会不断处理接收到的数据,滑动窗口会滑动,只有滑动窗口中的剩余空间才能接收新的数据。因此,滑动窗口的大小会随着接收缓冲区中剩余空间的大小而改变。
- Socket 缓冲区指的是内存级别的,滑动窗口指的是传输层的:Socket 缓冲区是操作系统内核中用于存储网络数据的内存空间,通过设置缓冲区大小可以影响数据的接收和发送。而滑动窗口是在 TCP 传输层使用的一种流量控制机制,用于协调发送端和接收端的数据传输速率。
需要注意的是,Socket 缓冲区和滑动窗口虽然在一些方面有关联,但是它们属于不同的概念和层次。Socket 缓冲区是在操作系统内存中的数据存储空间,而滑动窗口是在 TCP 协议传输层进行流量控制的机制。它们的调整和优化都可以对网络传输性能产生影响,但是它们是在不同的层次上进行操作。
118、RCVBUF_ALLOCATOR 和 SO_RCVBUF & SNDBUF的区别是什么?
RCVBUF_ALLOCATOR、SO_RCVBUF 和 SO_SNDBUF 都与网络传输中的缓冲区有关,但有一些区别和应用场景:
-
RCVBUF_ALLOCATOR:是 Netty 中用于分配ByteBuf内存缓冲区的分配器。它主要用于修改 Netty 创建的ByteBuf对象的大小。通过设置自定义的分配器,可以控制ByteBuf的初始大小或自动扩容的策略,以便更好地适应应用程序的需求。RCVBUF_ALLOCATOR是 Netty 框架提供的一种优化方式,用于提高内存使用效率和性能。 -
SO_RCVBUF:是 Socket 的一个选项,用于设置接收缓冲区的大小。这个选项通常在服务端的ServerSocketChannel中使用,通过option()函数来设置。它定义了操作系统的接收缓冲区大小,用于存储从网络接收到的数据。设置较大的接收缓冲区可以提高接收数据的能力,但也会消耗更多的内存。 -
SO_SNDBUF:是 Socket 的一个选项,用于设置发送缓冲区的大小。这个选项通常在客户端的SocketChannel中使用。它定义了发送数据时操作系统的发送缓冲区大小,用于存储待发送的数据。设置较大的发送缓冲区可以一次性发送更多的数据,提高发送效率,但也会占用更多的内存。
总结来说,RCVBUF_ALLOCATOR 是 Netty 提供的用于分配 ByteBuf 内存缓冲区的分配器,用于优化内存使用和性能。而 SO_RCVBUF 和 SO_SNDBUF 是 Socket 的选项,用于设置操作系统的接收和发送缓冲区大小,用于控制网络传输的接收和发送速度以及内存的使用情况。
119、如何控制是池化内存还是非池化内存?
要控制是使用池化内存还是非池化内存,可以在使用 Netty 时通过设置适当的选项来指定。
-
池化内存:使用池化内存可以重用已分配的内存块,以减少内存分配和释放的开销。在 Netty 中,可以通过设置
ChannelOption.ALLOCATOR选项为PooledByteBufAllocator.DEFAULT来启用池化内存。例如:serverBootstrap.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT); -
非池化内存:非池化内存表示每次都要分配新的内存块,而不会重用已分配的内存。在 Netty 中,可以通过设置
ChannelOption.ALLOCATOR选项为UnpooledByteBufAllocator.DEFAULT来使用非池化内存。例如:serverBootstrap.childOption(ChannelOption.ALLOCATOR, UnpooledByteBufAllocator.DEFAULT);
通过选择适当的分配器,可以根据具体的应用需求来控制内存的分配方式。池化内存适用于频繁地进行内存分配和释放的场景,可以减少内存碎片和提高性能。非池化内存适用于内存使用较少或者不频繁进行内存分配和释放的场景。
需要注意,上述示例中的 serverBootstrap 是 Netty 的 ServerBootstrap 对象,根据具体的代码实现可能会有所不同。另外,是否使用池化内存还是非池化内存还取决于系统的内存使用情况和实际的性能需求。
120、如何控制netty使用直接内存还是非直接内存?
要控制 Netty 是否使用直接内存(Direct Memory),可以通过设置系统属性来实现。
-
非直接内存:如果希望 Netty 使用非直接内存,可以设置系统属性
-Dio.netty.noPreferDirect=true。这将告诉 Netty 在可能的情况下不使用直接内存。 -
直接内存:如果希望 Netty 使用直接内存,可以设置系统属性
-Dio.netty.noPreferDirect=false。这将告诉 Netty 尽可能地使用直接内存。
直接内存是一种通过绕过 JVM 堆内存分配和释放的方式来直接操作系统内存的内存模式。它通常适用于需要经常进行零拷贝操作或者需要更高性能的场景。与直接内存相反,非直接内存则是使用 JVM 堆内存来存储数据。
需要注意的是,以上的系统属性设置是在启动应用程序时通过命令行参数或脚本设置的,具体设置方式可能会根据不同的操作系统和应用程序的启动方式而有所不同。确保在应用程序启动时正确设置系统属性以控制 Netty 的内存使用方式。
121、TCP_NODELAY的作用
TCP_NODELAY是TCP协议的一个选项,它的作用是控制是否启用 Nagle 算法。
Nagle 算法是一种网络优化算法,默认情况下是关闭的。当TCP_NODELAY选项被启用时,TCP连接上的小封包将会立即发送而不用等待发送缓冲区被填满。这样可以降低延迟,但是可能会增加网络流量。
TCP_NODELAY的作用可以总结为以下两点:
- 提高实时性:当发送小块数据时,启用TCP_NODELAY可以立即发送数据,减小网络传输的延迟,适用于实时性要求较高的应用场景(例如游戏、实时音视频等)。
- 控制网络流量:当发送大块数据时,可以禁用TCP_NODELAY以将多个小块数据合并成一个大的缓冲区,以减少网络负载,提高网络吞吐量。
需要注意的是,启用TCP_NODELAY可能会增加网络流量,并且在某些情况下可能引入更大的延迟。因此,在选择是否启用TCP_NODELAY时,需要根据具体的应用场景和需求进行权衡。
122、CONNECT_TIMEOUT_MILLIS的作用
CONNECT_TIMEOUT_MILLIS是一个用于设置连接超时时间的参数。
在Netty中,可以通过设置ChannelOption.CONNECT_TIMEOUT_MILLIS来指定客户端建立连接的超时时间。如果连接的建立超过了指定的时间,将会抛出连接超时的异常。
CONNECT_TIMEOUT_MILLIS的作用是确保在与目标服务器建立连接时,连接操作不会无限期地等待下去。通过设置合适的连接超时时间,可以避免长时间的等待,并及时检测和处理连接建立失败的情况。
需要根据具体的网络环境和系统要求来设置CONNECT_TIMEOUT_MILLIS的值。较短的超时时间可以提高连接失败的检测速度,但可能会增加连接失败的误报率;较长的超时时间可以确保更高的连接成功率,但可能会导致连接建立的延迟。
123、SO_BACKLOG的作用
SO_BACKLOG是一个用于配置ServerSocketChannel的参数,它决定了在进行3次握手之后,全连接队列的大小。
在TCP/IP协议中,当ServerSocketChannel接受一个连接请求,它会创建一个新的SocketChannel与客户端进行通信。而在进行3次握手的过程中,ServerSocketChannel将会在一个全连接队列中维护这些尚未与客户端建立连接的连接。
SO_BACKLOG参数的作用是设置全连接队列的大小。全连接队列即使完成了3次握手的连接,但还没有被accept调用接受的连接,即处于半连接状态。此参数表示允许保持的最大未完成连接数。
需要注意的是,SO_BACKLOG参数并不是设置半连接队列的最大值,而是设置全连接队列的最大值。半连接队列的大小是一个无限大的概念,不需要考虑设置具体的最大值。
通过合理设置SO_BACKLOG参数的值,可以根据实际需要控制服务器接受连接的并发数。较大的SO_BACKLOG值可以提高服务器接受连接的并发能力,但也可能增加队列中等待连接的连接数,导致连接被拒绝或延迟。而较小的SO_BACKLOG值则可能限制并发连接数。
124、三次握手四次挥手
一、三次握手和四次挥手的过程:
三次握手:
TCP建立连接的过程我们称之为3次握手。
(1)第一次握手
PC1使用一个随机的端口号向PC2的80端口发送连接请求,此过程的典型标志为SYN控制位为1,其他五位为0。
(2)第二次握手
这次握手实际上是分为2个步骤完成的。
首先,PC2收到PC1请求,向PC1回复确认信息。
并且,PC2也向PC1发送建立连接请求。
(3)第三次握手
PC1收到PC2回复,也要向PC2回复一个确认信息。
四次挥手:
TCP断开连接得过程分为4步,我们称之为四次挥手。
(1)服务器向客户端发送FIN,ACK位置1的TCP报文段。
(2)客户端向服务器返回ACK位置1的TCP报文段。
(3)客户端向服务器发送FIN,ACK位置1的TCP报文段。
(4)服务器向客户端返回ACK位置1的 TCP报文段。
在TCP断开连接的过程中,有一个半关闭得概念。TCP一端可以中止发送数据,但是仍然可以接收数据,称之为半关闭:
(1)客户端发送FIN,半关闭了这个链接。服务器发送ACK接受半关闭。
(2)服务器继续发送数据,而客户端只发送ACK确认,不发送任何数据。
(3)当服务器所有数据传输完毕,就发送FIN报文段,客户再发送ACK报文段,这样就关闭了TCP连接。
125、三次握手和四次挥手的本质是什么?
三次握手的本质是确认通信双方收发数据的能力 。
四次挥手的目的是关闭一个连接 。
126、为什么TCP连接的时候是3次?2次不可以吗?
因为需要考虑连接时丢包的问题,如果只握手2次,第二次握手时如果服务端发给客户端的确认报文段丢失,此时服务端已经准备好了收发数(可以理解服务端已经连接成功)据,而客户端一直没收到服务端的确认报文,所以客户端就不知道服务端是否已经准备好了(可以理解为客户端未连接成功),这种情况下客户端不会给服务端发数据,也会忽略服务端发过来的数据。
如果是三次握手,即便发生丢包也不会有问题,比如如果第三次握手客户端发的确认ack报文丢失,服务端在一段时间内没有收到确认ack报文的话就会重新进行第二次握手,也就是服务端会重发SYN报文段,客户端收到重发的报文段后会再次给服务端发送确认ack报文。
127、为什么TCP连接的时候是3次,关闭的时候却是4次?
因为只有在客户端和服务端都没有数据要发送的时候才能断开TCP。而客户端发出FIN报文时只能保证客户端没有数据发了,服务端还有没有数据发客户端是不知道的。而服务端收到客户端的FIN报文后只能先回复客户端一个确认报文来告诉客户端我服务端已经收到你的FIN报文了,但我服务端还有一些数据没发完,等这些数据发完了服务端才能给客户端发FIN报文(所以不能一次性将确认报文和FIN报文发给客户端,就是这里多出来了一次)。
128、三、为什么客户端发出第四次挥手的确认报文后要等2MSL的时间才能释放TCP连接?即为什么客户端在TIME-WAIT阶段要等2MSL?
MSL 指的是 Maximum Segment Lifetime:一段 TCP 报文在传输过程中的最大生命周期。
2MSL 即是服务器端发出为 FIN 报文和客户端发出的 ACK 确认报文所能保持有效的最大时长。
这里同样是要考虑丢包的问题,如果第四次挥手的报文丢失,服务端没收到确认ack报文就会重发第三次挥手的报文,这样报文一去一回最长时间就是2MSL,所以需要等这么长时间来确认服务端确实已经收到了。
129、如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP设有一个保活计时器,客户端如果出现故障,服务器不能一直等下去,白白浪费资源。服务器每收到一次客户端的请求后都会重新复位这个计时器,时间通常是设置为2小时,若两小时还没有收到客户端的任何数据,服务器就会发送一个探测报文段,以后每隔75秒钟发送一次。若一连发送10个探测报文仍然没反应,服务器就认为客户端出了故障,接着就关闭连接。
130、SO_REUSEADDR的理解
- 1、配置对象:ServerScoketChannel参数
- 2、如何设置:通过option()
- 3、作用:是让端口释放后立即就可以被再次使用
131、为什么需要SO_REUSEADDR这个方式?
- Server非正常关闭,或者正常关闭过程中出现意外,都有可能导致端口被占用,后续需要重新启动服务时,就会出现端口被占用异常。
- 为了解决这个问题,需要端口复用
- tcp关闭连接4次握手,都是等到Close之后才释放的端口。
-

132、SO_KeepAlive有使用场景吗?
SO_KEEPALIVE是一个TCP套接字选项,用于启用或禁用TCP的保活机制。
TCP的保活机制用于检测长时间处于非活动状态的连接,以确定连接是否仍然有效。通过周期性地在空闲连接上发送探测报文段,并等待对端的响应,可以检测连接是否断开或失效,并及时释放资源。
在某些特定的场景下,SO_KEEPALIVE可以有一些使用场景,例如:
- 应用层心跳:如果应用程序需要保持连接的活跃性,可以使用SO_KEEPALIVE来实现基于TCP的应用层心跳。通过启用SO_KEEPALIVE机制,可以避免应用层自行实现心跳。
- 当网络环境不稳定或存在防火墙设备时,启用SO_KEEPALIVE可以帮助及时发现连接中断的情况,并采取相应的处理措施。
但是需要注意的是,SO_KEEPALIVE并不是一种强制的机制,具体的实现和触发时间会根据操作系统和网络设备的配置而有所不同。在某些操作系统中,默认情况下可能并没有启用SO_KEEPALIVE选项,或者使用默认的较长的超时时间。
总的来说,目前的开发中,通常会采用应用层的心跳机制来保持连接的活跃性,而不是依赖于TCP的保活机制。因此,在一般情况下,SO_KEEPALIVE的使用场景相对较少,可以根据具体的应用需求来决定是否使用该选项。
133、SO_KeepAlive工作过程
SO_KEEPALIVE是一个TCP套接字选项,用于启用或禁用TCP的保活机制。保活机制用于检测长时间处于非活动状态的连接,以确定连接是否仍然有效。
当启用SO_KEEPALIVE选项后,操作系统会自动周期性地发送心跳包(Keep-Alive Probe)给对端,用于检测连接的可用性。下面是SO_KEEPALIVE的工作过程:
-
应用程序通过设置套接字选项SO_KEEPALIVE来启用保活机制。
-
当连接处于空闲状态(没有数据传输)超过一段时间后,操作系统会自动开始进行保活流程。
-
首先,操作系统发送一个称为Keep-Alive Probe的TCP探测报文段给对端,该报文段是一个特殊的TCP数据包,其中标记为保活探测的标志位。
-
对端收到Keep-Alive Probe后,如果连接仍然有效,则应答一个特殊的ACK报文段。
-
如果对端没有响应或应答,则可以认为连接已断开或失效。
-
如果在一定次数的探测尝试后对端仍然没有响应,则操作系统会认为连接已经断开,并关闭该连接。
需要注意的是,SO_KEEPALIVE的具体工作方式和参数设置可能因操作系统和网络设备而有所不同。在一般情况下,默认的Keep-Alive Probe发送周期是2小时,每次发送9次探测,并且每次发送的时间间隔为75秒。
可以通过操作系统的参数设置来修改Keep-Alive Probe的周期、次数和时间间隔。例如,在Linux系统中,可以通过修改sysctl参数 “net.ipv4.tcp_keepalive_time” 来设置保活时间间隔,单位为秒。
总结起来,SO_KEEPALIVE的工作过程是通过周期性地发送特殊的探测报文段来检测连接的可用性,并根据对端的响应情况来确定连接的有效性。这样可以在连接断开或失效时及时释放资源。
134、为什么有了KeepAlive还需要心跳?
保活机制(KeepAlive)和心跳功能(Heartbeat)都是用于保持连接的活跃性,但是它们解决的问题和作用的层次略有不同。
KeepAlive是TCP协议层面的机制,通过定期发送心跳包(Keep-Alive Probe)来检测连接的可用性。当连接处于空闲状态超过一段时间后,操作系统会自动发送心跳包给对端,以确定连接是否仍然有效。如果对端没有响应或应答,则可以认为连接已断开或失效,操作系统会关闭该连接。
心跳是应用层的概念,通常在应用程序中实现。应用层心跳是通过应用程序定期发送自定义的心跳消息给对端,以确认对端是否还在活跃状态。应用层心跳主要用于保持应用程序级别的状态同步,或者检测对端应用程序的可用性。如果对端没有及时回应心跳消息,则可以认为连接已经断开或对端应用程序出现故障。
虽然KeepAlive和心跳都可以用于保持连接的活跃性,但是它们作用的层次不同。KeepAlive操作在TCP协议层面,可以时刻检测连接的可用性并及时释放资源,适用于检测底层网络故障或连接断开的情况。而心跳操作在应用程序层面,更多地用于确认上层应用程序的状态或检测对端应用程序的可用性。
因此,尽管有了KeepAlive机制,应用程序仍然需要使用应用层心跳来解决特定的问题,如保持状态同步、确认远程应用程序的可用性等。两者可以结合使用,以提高连接的健壮性和可靠性。
135、Http协议1.1,保证 有限长连接 KeepAlive头 60秒和Tcp的keepAlive有什么区别呢?
Http协议1.1中的Keep-Alive头和TCP的KeepAlive机制是两个不同的概念,它们之间确实没有任何直接关系。
Http协议1.1中的Keep-Alive头是一种机制,用于在单个的TCP连接上发送多个HTTP请求和响应。它通过在请求头中指定Connection字段为"keep-alive"来告知服务器保持连接的状态。这样可以避免频繁地建立和关闭TCP连接,提高性能和效率。Keep-Alive头中还可以设置一个可选的参数,表示客户端希望保持连接的时间,一般默认为60秒。
而TCP的KeepAlive机制是TCP协议层面的一种机制,用于检测长时间处于非活动状态的连接的可用性。当启用TCP的KeepAlive机制后,操作系统会周期性地发送Keep-Alive Probe给对端,以确定连接是否仍然有效。TCP的KeepAlive机制与Http的Keep-Alive头是完全独立的,操作系统会在TCP层面自动处理TCP连接的保活工作,无需应用程序进行干预。
所以,Http协议1.1中的Keep-Alive头主要是用于复用TCP连接,减少建立和关闭连接的开销。而TCP的KeepAlive机制则是用于在TCP层面检测连接的可用性,避免因长时间的非活动状态而导致的连接断开。它们的实现方式和作用的层面不同,且没有直接的关联。
136、HTTP和TCP的关系
HTTP和TCP是两个不同的协议,但它们之间存在着密切的关系。
HTTP(Hypertext Transfer Protocol)是一种应用层协议,用于在客户端和服务器之间传输超文本数据。它基于TCP(Transmission Control Protocol)来实现可靠的数据传输。
TCP是一种传输层协议,负责在网络上可靠地传输数据。它提供了连接的建立、断开和数据分段重组的功能,保证数据的完整性和顺序。HTTP使用TCP作为其传输层协议,利用TCP的可靠性来传输HTTP消息,确保数据的可靠传输。
在HTTP与TCP之间的关系中,HTTP位于TCP之上,它通过TCP来实现数据的传输。HTTP利用TCP的连接模式,建立起客户端和服务器之间的连接,然后在该连接上传输HTTP请求和响应。TCP负责将HTTP消息分段并进行可靠的传输,确保消息的完整性和顺序,以及处理拥塞和丢包等网络问题。
因此,TCP为HTTP提供了可靠的数据传输基础,保证了HTTP通信的可靠性和稳定性。HTTP依赖于TCP来建立连接、发送和接收数据,而TCP通过提供可靠的数据传输服务,满足了HTTP传输超文本数据的需求。