论文阅读之《Learn to see in the dark》
Learning to See in the Dark-CVPR2018
Chen ChenUIUC(伊利诺伊大学厄巴纳-香槟分校)
Qifeng Chen, Jia Xu, Vladlen Koltun Intel Labs(英特尔研究院)
文章链接:https://arxiv.org/pdf/1805.01934.pdf https://arxiv.org/pdf/1805.01934.pdf源码地址:
https://arxiv.org/pdf/1805.01934.pdf源码地址:
GitHub - cchen156/Learning-to-See-in-the-Dark: Learning to See in the Dark. CVPR 2018Learning to See in the Dark. CVPR 2018. Contribute to cchen156/Learning-to-See-in-the-Dark development by creating an account on GitHub.https://github.com/cchen156/Learning-to-See-in-the-Dark
研究背景
在暗光条件下,受到低信噪比和低亮度的影响,图片的质量会受到很大的影响。此外,低曝光率的照片会出现很多噪声,而长曝光时间会让照片变得模糊、不真实。目前很多关于去噪、去模糊、图像增强等技术在极端光照条件下作用很有限。论文中主要解决关注的问题是极端低光条件下的图像成像问题,提出了一种在黑暗中也能快速、清晰的成像系统。
主要工作
论文提出一种通过全卷积神经网络(FCN)方法将在黑暗环境中进行的拍摄还原的方法,通过控制变量法来对比不同的去噪方法,增加信噪比,并找到一个较好的解决方案。
创新点
本文的主要创新点为:
1.提出了一个新的照片数据集,包含原始的short-exposure low-light图像,并附有long-exposure reference图像作为Ground truth,以往类似的研究使用的都是合成的图像;
2.与以往方法使用相机拍摄出RGB图像进行复原不同,使用原始的传感器数据作为网络输入。
3.提出了一种端到端学习方法,通过训练一个全卷积网络来直接处理快速成像系统中低亮度图像。
已有工作回顾 
传统图像处理过程会应用一系列模块,例如白平衡、去马赛克、去噪、增加图像锐度、 伽马矫正等等。而这些图像处理模块针对不同的相机需要特定的去设计。一些研究提出使用局部线性、可学习的L3 过滤器来模拟现代成像系统中复杂的非线性流程,但是这些方法都无法成功解决在低光条件中快速成像的问题,也无法解决极低的SNR 问题。此外,通过智能手机相机拍摄的照片,利用bursting imaging破裂成像方法,结合多张图像也可以生成效果较好的图像,但是这种方法的复杂程度较高。
提出的方法
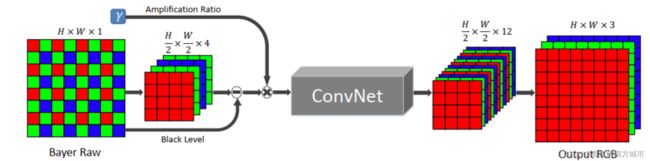 这是一种端到端的学习方法,训练一个全卷积网络FCN 来直接处理快速成像系统中的低亮度图像。纯粹的FCN 结构可以有效地代表许多图像处理算法,用原始传感器数据作为输入。对于 Bayer 数组,将输入打包为四个通道并在每个通道上将空间分辨率降低一半。原始数据以6×6排列块组成;通过交换相邻通道元素的方法将36个通道的数组打包成9个通道。消除黑色像素并按照期望的倍数缩放数据,将处理后数据作为 FCN 模型的输入,输出是一个带12通道的图像,其空间分辨率只有输入的一半。这个一半大小的输出被子像素层处理,以恢复原始分辨率。
这是一种端到端的学习方法,训练一个全卷积网络FCN 来直接处理快速成像系统中的低亮度图像。纯粹的FCN 结构可以有效地代表许多图像处理算法,用原始传感器数据作为输入。对于 Bayer 数组,将输入打包为四个通道并在每个通道上将空间分辨率降低一半。原始数据以6×6排列块组成;通过交换相邻通道元素的方法将36个通道的数组打包成9个通道。消除黑色像素并按照期望的倍数缩放数据,将处理后数据作为 FCN 模型的输入,输出是一个带12通道的图像,其空间分辨率只有输入的一半。这个一半大小的输出被子像素层处理,以恢复原始分辨率。
两个标准的 FCN 作为模型的核心:用于快速图像处理的多尺度上下文聚合网络 (CAN) 和U-net 网络,最终选用的是U-net网络。放大比率决定了模型的亮度输出,在外部指定并作为输入提供给模型,这类似于相机中的 ISO 设置。模型使用L1损失和Adam优化器,网络输入为原始短曝光图像,对应的真实数据是长曝光图像,他们之间的曝光时间的倍数差作为放大因子,训练中随机裁剪512x512的补丁用于训练,用翻转,旋转等操作来做数据增强,初始学习率设为0.0001,2000次迭代后降为0.00001,共进行4000次迭代。
FCN网络
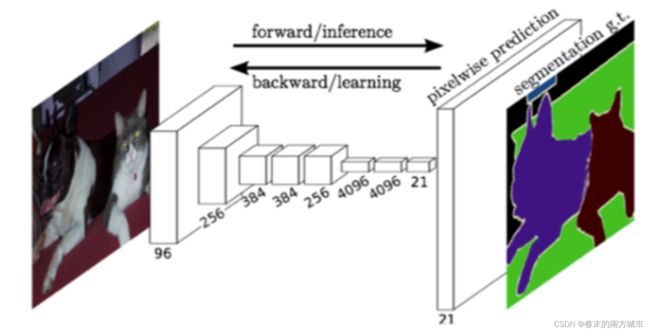
FCN和CNN的区别:CNN卷积层之后连接的是全连接层;FCN卷积层之后仍连接卷积层,输出的是与输入大小相同的特征图。FCN将传统CNN中的全连接层转化成一个个的卷积层。FCN多次卷积图像越来越小,像素越来越低。
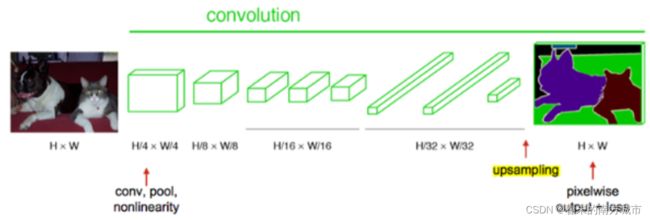 在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率。FCN将这3层表示为卷积层,卷积核的大小(通道数,宽,高)分别为(4096,7,7)、(4096,1,1)、(1000,1,1)。所有的层都是卷积层,称为全卷积网络。
在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率。FCN将这3层表示为卷积层,卷积核的大小(通道数,宽,高)分别为(4096,7,7)、(4096,1,1)、(1000,1,1)。所有的层都是卷积层,称为全卷积网络。

Unet网络
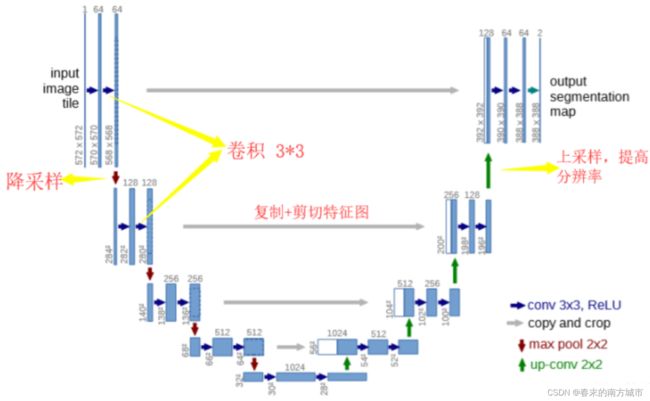 U-Net整体的流程是编码和解码,可用于分割,压缩图像和去噪声。也可以用在原图像去噪,做法就是训练的阶段在原图人为的加上噪声,然后放到编码解码器中,下采样可以增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,和增加感受野的大小。上采样把抽象的特征再还原解码到原图的尺寸,得到输出。
U-Net整体的流程是编码和解码,可用于分割,压缩图像和去噪声。也可以用在原图像去噪,做法就是训练的阶段在原图人为的加上噪声,然后放到编码解码器中,下采样可以增加对输入图像的一些小扰动的鲁棒性,比如图像平移,旋转等,减少过拟合的风险,降低运算量,和增加感受野的大小。上采样把抽象的特征再还原解码到原图的尺寸,得到输出。
复制+剪切特征图可以使浅层网络会保留明显的内容信息,网络层变深,内容会减少,特征会增多,在深层网络添加内容的信息。简单来说就是前期不断的卷积池化来进行下采样,然后再不断卷积上采样,形成一个U形。而下采样的结果还会合成至对应的上采样结果,实现抽象与细节的结合。
CAN卷积

作者提出一个新颖的卷积方式:膨胀卷积-CAN:MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS。通过膨胀卷积实现多尺度语义信息融合,增长感受野的区域,从而获得更好的稠密分类结果。目前FCN通过pooing的方式增大感受野代价是空间分辨率降低,这种方式浪费了很多空间信息。相比原来的标准卷积膨胀卷积多了一个超参数-扩张率,指的是kernel各点之前的间隔数量。这样在不丢失分辨率的前提下拥有了更大的感受野。
数据集
See in the dark(SID)数据集包含5094张原始的短曝光图像,每一张都有一个参考的长曝光图像。图像由两台相机(顶部和底部)采集,包含室内和室外。比较有价值的一点就是数据集合都是在极其暗的光照条件下进行拍摄的,是第一个建立的有groundtruth的低光照数据集合。

实验结果
传统的图像处理方法在极端低光条件下容易受到严重的噪声影响,该方法能够有效地抑制图像噪声,生成色彩均衡、逼真的图像。
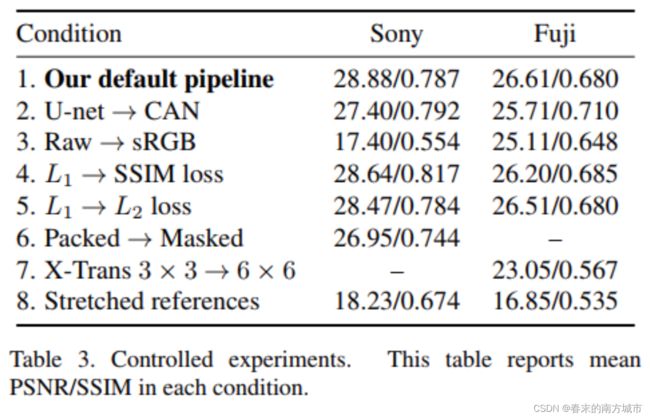
总结
论文创建了一个黑暗的图像数据集 (SID) 以支持数据驱动方法的研究。利用 SID 数据集,提出一种基于 FCN 模型(以U-net为核心),通过端到端训练,改善了传统的处理低光图像的方法。可以抑制噪声并正确地实现颜色转换。