Learn to See in the Dark 论文
摘要
在暗光条件下,受到低信噪比和低亮度的影响,图片的质量会受到很大的影响。此外,低曝光率的照片会出现很多噪点,而长曝光时间会让照片变得模糊、不真实。目前,很多关于去噪、去模糊、图像增强等技术的研究已被相继提出,但是在一些极端条件下,这些技术的作用就很有限了。为了发展基于学习的低亮度图像处理技术,我们提出了一种在黑暗环境中也能快速、清晰成像的系统,效果令人惊讶。此外,我们引入了一个数据集,包含有原始的低曝光率、低亮度图片,同时还有对应的长曝光率图像。利用该数据集,我们提出了一种端到端训练模式的全卷积网络结构,用于处理低亮度图像。该网络直接使用原始传感器数据,并替代了大量的传统图像处理流程。最终,实验结果表明这种网络结构在新数据集上能够表现出出色的性能,并在未来工作中有很大前途。
简介
任何的图像成像系统都存在噪点,但这很大地影响在弱光条件下图像的质量。高 ISO 可以用于增加亮度,但它同时也会放大噪点。诸如缩放或直方图拉伸等图像后处理可以缓解这种噪点影响,但这并不能从根本上解决低信噪比 (SNR) 问题。在物理学上,这可以解释为在弱光条件下增加 SNR,包括开放光圈,延长曝光时间以及使用闪光灯等,但这些也都有其自身的缺陷。例如,曝光时间的延长可能会引起相机抖动或物体运动模糊。
众所周知,暗光条件下的快速成像系统一直都是计算摄影界的一大挑战,也是一直以来开放性的研究领域。目前,许多关于图像去噪,去模糊和低光图像增强等技术相继提出,但这些技术通常假设这些在昏暗环境下捕获到的图像带有中等程度的噪点。相反,我们更感兴趣的是在极端低光条件下,如光照严重受限 (例如月光) 和短时间曝光 等条件下的图像成像系统。在这种情况下,传统相机的处理方式显然已不适用,图像必须根据原始的传感器数据来重建。
为此,本文提出了一种新的图像处理技术:通过一种数据驱动的方法来解决极端低光条件下快速成像系统的挑战。具体来说,我们训练深度神经网络来学习低光照条件下原始数据的图像处理技术,包括颜色转换,去马赛克,降噪和图像增强等。我们通过端对端的训练方式来避免放大噪声,还能表征这种环境下传统相机处理的累积误差。
据我们所知,现有用于处理低光图像的方法,在合成数据或真实的低光图像上测试都缺乏事实根据。此外,用于处理不同真实环境下的低光图像数据集也相当匮乏。因此,我们收集了一个在低光条件下快速曝光的原始图像数据集。每个低光图像都有对应的长曝光时间的高质量图像用于参考。在新的数据集上我们的方法表现出不出色的结果:将低光图像放大 300 倍,成功减少了图像中的噪音并正确实现了颜色转换。我们系统地分析方法中的关键要素并讨论未来的研究方向。
下图 1 展示了我们的设置。我们可以看到,在 ISO 8,000 条件下,尽管使用全帧的索尼高光灵敏度相机,但相机仍会产生全黑的图像。在 ISO 409,600 条件下,图像仍会产生朦胧,嘈杂,颜色扭曲等现象。换而言之,即使是当前最先进的图像去噪技术也无法消除这种噪音,也无法解决颜色偏差问题。而我们提出的全卷积网络结构能够有效地克服这些问题。

图 1 卷积网络下的极端低光成像。 黑暗的室内环境::相机的照度 <0.1 lux。Sony α 7S II 传感器曝光 1/30 秒。左图:ISO 8,000 时相机产生的图像。中间:ISO 409,600 时相机产生的图像,图像受到噪声和颜色偏差的影响。右图:由我们的全卷积网络生生的图像。
数据集
表1. SID 数据集包含 5094 个原始的短曝光率图像,每张图像都有一个长曝光的参考图像。图像由顶部和底部两台相机收集得到。表中的指标参数分别是(从左到右):输入与参考图像之间的曝光时间率,滤波器阵列,输入图像的曝光时间以及在每种条件下的图像数量。

下图 2 显示了数据集中一部分的参考图像。在每种条件下,我们随机选择大约 20% 的图像组成测试集,另外选定 10% 的数据用于模型验证。

图2 SID 数据库的实例。前两行是 SID 数据集中室外的图像,底部两行是室内的图像。 长曝光时间的参考图像 (地面实况) 显示在前面。短曝光的输入图像(基本上是黑色) 显示在背部。室外场景下相机的亮度一般在 0.2 lux 到 5 lux,而室内的相机亮度在 0.03 lux 和 0.3 lux 之间。
数据采集时,相机固定在三脚架上。我们用无反光镜相机来避免由于镜面拍打引起的振动。在每个场景中,相机设置 (如光圈,ISO,焦距和焦距) 进行了调整,以最大限度地提高参考图像 (长曝光时间)的质量。此外,利用远程的智能手机 App 将曝光时间缩短为 1/300 至 1/100。该相机专门用于参考图像(长曝光时间)的拍摄,而没有触及短曝光的图像。我们收集了一系列短曝光的图像用于方法的比较和评估,以展现我们方法的优势。
虽然,数据集中的参考图像仍可能存在一些噪点,但感知质量足够高。我们目的是为了在光线不足的条件下产生在感知良好的图像,而不是彻底去除图像中所有噪点或最大化图像对比度。因此,这种参考图像的存在不会影响我们的方法评估。
模型方法
从成像传感器中得到原始数据后,传统图像处理过程会应用一系列模块,例如白平衡、去马赛克、去噪、增加图像锐度、 γ 矫正等等。而这些图像处理模块只在某些特定相机中才有。一些研究提出使用局部线性、可学习的 L3 过滤器来模拟现代成像系统中复杂的非线性流程,但是这些方法都无法成功解决在低光条件中快速成像的问题,也无法解决极低的 SNR 问题。此外,通过智能手机相机拍摄的照片,利用 bursting imaging 成像方法,结合多张图像也可以生成效果较好的图像,但是这种方法的复杂程度较高。
因此,我们提出了的端到端的学习方法,即训练一个全卷积网络 FCN 来直接处理快速成像系统中的低亮度图像。纯粹的 FCN 结构可以有效地代表许多图像处理算法。受此启发,我们调查并研究这种方法在极端低光条件下成像系统的应用。相比于传统图像处理方法使用的 sRGB 图像,在这里我们使用原始传感器数据。下图 3 展示了我们所提出的模型结构。
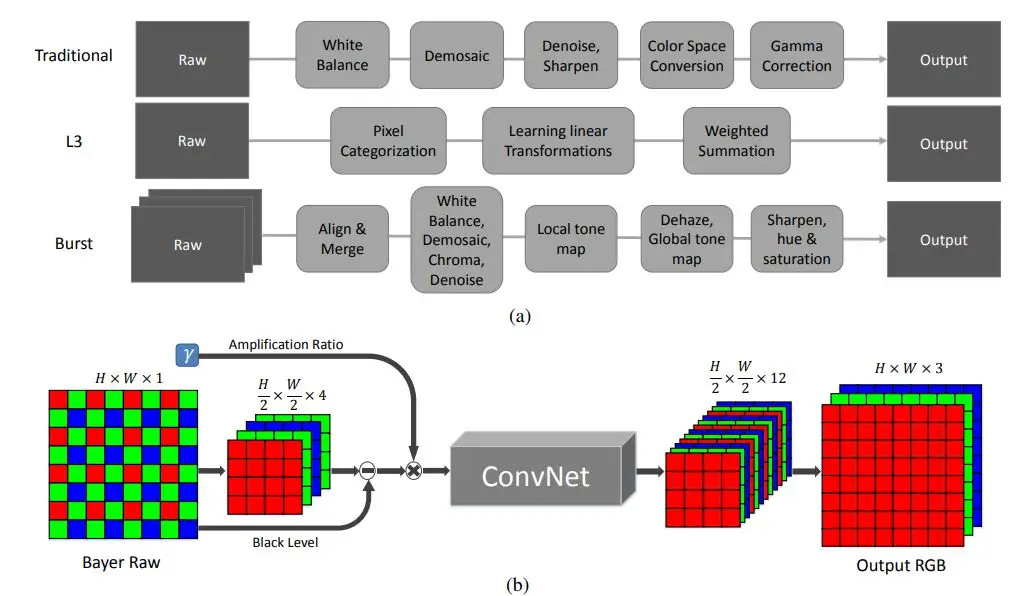
图3 本文提出的图像处理方法
对于 Bayer 数组,我们将输入打包为四个通道并在每个通道上将空间分辨率降低一半。对于 X-Trans 数组(图中未显示出),原始数据以 6×6 排列块组成;我们通过交换相邻通道元素的方法将 36 个通道的数组打包成 9 个通道。此外,我们消除黑色像素并按照期望的倍数缩放数据(例如,x100 或 x300)。将处理后数据作为 FCN 模型的输入,输出是一个带 12 通道的图像,其空间分辨率只有输入的一半。
我们将两个标准的 FCN 结构作为我们模型的核心架构:用于快速图像处理的多尺度上下文聚合网络 (CAN) 和 U-net 网络。影响我们模型选择的另一个因素是内存消耗:在 GPU 中,我们选择的模型结构可以处理全分辨率的图像(例如,在 4240×2832 或 6000×4000 分辨率)。同时,我们避免使用完全连接结构及模型集成方式。我们的默认架构是 U-net。
放大比率决定了模型的亮度输出。在我们的方法中,放大比率设置在外部并作为输入提供给模型,这类似于相机中的 ISO 设置。 下图 4 显示了不同放大比率的影响。用户可以通过设置不同的放大率来调整输出图像的亮度。在测试中,我们的方法能够抑制盲点噪声并实现颜色转换,并在 sRGB 空间网络直接处理图像,得到网络的输出。

图4 SID 数据集中放大系数对室内图像 (Sony x100子集) 的影响。 类似于摄像机中的ISO设置,这里的放大系数是作为外部输入提供给我们的模型。更高的放大倍数可以产生更明亮的图像。我们在我们的方法中引入了不同的放大因子,并展示了模型的输出图像。
模型训练
我们使用 L1 损失和 Adam 优化器,从零开始训练我们的网络。 在训练期间,网络输入是原始的短曝光图像,在 sRGB 空间中的真实数据是相应的长曝光时间图像(由一个原始图像处理库 libraw 处理过得参考图像)。 我们为每台相机训练一个网络,并将原始图像和参考图像之间曝光时间的倍数差作为我们的放大因子(例如,x100,x250,或 x300)。在每次训练迭代中,我们随机裁剪一个 512×512 的补丁用于训练并利用翻转、旋转等操作来随机增强数据。初始学习率设定为 0.0001,在 2000 次迭代后学习率降为 0.00001,训练一共进行 4000 次迭代。
实验结果分析
如图 5,6,7 所示,传统的图像处理方法在极端低光条件下容易受到严重的噪声影响,导致生成图像颜色失真。我们提出的方法能够有效地抑制图像噪声,生成色彩均衡、逼真的图像。此外,由于在数据集中对齐数据序列,我们的方法也更优于 post-hoc denoising、brust denoising 等图像去噪方法。

图5 (a) 由富士胶片 X-T2 相机拍摄的夜间图像,ISO 800,光圈 f / 7.1,曝光时间 1/30s,相机亮度约为1 lux。(b) 传统的图像处理方法不能有效处理原始数据中的噪声和颜色偏差。(c) 基于相同的数据,我们方法处理的结果。

图6 将 SID 数据集训练好的模型应用于用 iPhone 6s 智能手机拍摄的原始低光图像。(a) iPhone 6s 在夜间所拍摄的原始图像,ISO 400,光圈 f/2.2,曝光时间 0. 05s。经传统的图像处理方法处理后的图像及缩放到相匹配的亮度的参考图像。(b)我们提出的方法处理后的结果。

图7 Sony x300拍摄的图像。(a) 由传统图像处理方法处理的低光图像及其线性缩放的结果。(b) 同样用传统方法,并通过 BM3D 去噪方法处理后的结果。 (c) 我们提出的方法处理后的结果。
此外,我们还进行了一系列的控制实验,来分析方法中各组分对模型性能的影响,包括模型结构,输入的颜色空间,损失函数,数据排列,图像后处理等因素。
结语
由于图像低光子数和低信噪比的影响,快速低光成像系统是一个艰巨的挑战。黑暗中快速成像系统更是被认为是一种不切实际、与传统的信号处理相悖的技术。在本文中,我们创建了一个黑暗中的图像数据集 (SID) 以支持数据驱动方法的研究。利用 SID 数据集,我们提出一种基于 FCN 模型结构,通过端到端训练,改善了传统的处理低光图像的方法。实验结果表明我们的方法能够成功抑制噪点并正确地实现颜色转换,表现出不错的性能,并展现了不错的研究前景。未来的工作我们可以进一步研究低光成像网络的泛化能力。此外,对于模型的性能优化也是值得研究的一个热点方向。我们还将在未来的工作中进一步改善图像质量,如通过系统优化网络架构和训练过程。我们希望 SID 数据集和我们的实验结果可以支持并推动未来该领域的研究工作。