Ceph学习笔记二
五、RGW 对象存储
通过对象存储,将数据存储为对象,每个对象除了包含数据,还包含数据自身的元数据。
对象通过 Object ID 来检索,无法通过普通文件系统操作来直接访问对象,只能通过API来访问,或者第三方客户端(实际上也是对API的封装)。
对象存储中的对象不整理到目录树中,而是存储在扁平的命名空间中,Amazon S3将这个扁平命名空间称为 bucket。
5.1 部署rados gw
- 在node-1上部署rgw
[root@node-1 ceph-deploy]# ceph-deploy rgw create node-1
[node-1][INFO ] Running command: systemctl start ceph-radosgw@rgw.node-1
[node-1][INFO ] Running command: systemctl enable ceph.target
[ceph_deploy.rgw][INFO ] The Ceph Object Gateway (RGW) is now running on host node-1 and default port 7480
[root@node-1 ceph-deploy]#
- 验证rgw的状态
[root@node-1 ceph-deploy]# netstat -tunpl | grep 7480
tcp 0 0 0.0.0.0:7480 0.0.0.0:* LISTEN 12377/radosgw
tcp6 0 0 :::7480 :::* LISTEN 12377/radosgw
[root@node-1 ceph-deploy]# curl http://node-1:7480
<?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>[root@node-1 ceph-deploy]#
5.2 修改RGW默认端口
- 修改ceph.conf配置文件,在末尾增加两行配置
[root@node-1 ceph-deploy]# pwd
/root/ceph-deploy
[root@node-1 ceph-deploy]#
[root@node-1 ceph-deploy]# cat ceph.conf
[global]
fsid = ff22ec29-da80-4790-97b5-c6699433f0b0
public_network = 10.0.0.0/24
cluster_network = 10.211.56.0/24
mon_initial_members = node-1
mon_host = 10.0.0.201
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
[client.rgw.node-1]
rgw_frontends = "civetweb port=80"
- 把修改后的配置文件推送至node-1,node-2 ,node-3
[root@node-1 ceph-deploy]# ceph-deploy --overwrite-conf config push node-1 node-2 node-3
- 重启RGW服务
[root@node-1 ceph-deploy]# systemctl restart ceph-radosgw.target
- 访问验证
[root@node-1 ceph-deploy]# curl http://node-1
5.3 RGW 的S3接口使用
官方文档参考:https://docs.ceph.com/en/octopus/radosgw/admin/
- 创建用户
[root@node-1 ceph-deploy]# radosgw-admin user create --uid ceph-s3-user --display-name "Ceph S3 User Demo"
- 保存该用户的密钥信息,方便之后查看
[root@node-1 ceph-deploy]# cat > key.txt <
> "user": "ceph-s3-user",
> "access_key": "ZHTTSYSKPY6IMB4YLBWI",
> "secret_key": "DmAYwx1A9nR9q271F0lPS1QKgIGYRB5U4XTVOmRk"
> EOF
- 如果碰巧忘记了该密钥信息,可通过以下方法查看
[root@node-1 ceph-deploy]# radosgw-admin user list
[
"ceph-s3-user"
]
[root@node-1 ceph-deploy]# radosgw-admin user info --uid ceph-s3-user
{
"user_id": "ceph-s3-user",
"display_name": "Ceph S3 User Demo",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "ceph-s3-user",
"access_key": "ZHTTSYSKPY6IMB4YLBWI",
"secret_key": "DmAYwx1A9nR9q271F0lPS1QKgIGYRB5U4XTVOmRk"
}
- 通过编写S3风格的SDK 接口来访问Rdosgw
[root@node-1 ceph-deploy]# yum install python-boto
#编写python接口脚本生成bucket
[root@node-1 ceph-deploy]# cat s3client.py
import boto
import boto.s3.connection
access_key = 'ZHTTSYSKPY6IMB4YLBWI'
secret_key = 'DmAYwx1A9nR9q271F0lPS1QKgIGYRB5U4XTVOmRk'
conn = boto.connect_s3(
aws_access_key_id = access_key,
aws_secret_access_key = secret_key,
host = '10.0.0.201', port=80,
is_secure=False,
calling_format = boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket('my-first-s3-bucket')
for bucket in conn.get_all_buckets():
print "{name}\t{created}".format(
name = bucket.name,
created = bucket.creation_date,
)
# 未创建bucket前
[root@node-1 ceph-deploy]# ceph osd lspools
1 ceph-demo
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
[root@node-1 ceph-deploy]#
# 创建bucket后
[root@node-1 ceph-deploy]# python s3client.py
my-first-s3-bucket 2021-01-18T15:00:01.572Z
[root@node-1 ceph-deploy]# ceph osd lspools
1 ceph-demo
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
[root@node-1 ceph-deploy]#
5.4 RGW 的S3cmd接口使用
- 安装s3cmd命令行工具
[root@node-1 ceph-deploy]# yum install s3cmd.noarch -y
- 初始化s3cmd工具,填入以下信息,并把生成的 /root/.s3cfg 中的signature_v2 = False
改为True
Access Key: ZHTTSYSKPY6IMB4YLBWI
Secret Key: DmAYwx1A9nR9q271F0lPS1QKgIGYRB5U4XTVOmRk
Default Region [US]:
S3 Endpoint [s3.amazonaws.com]: 10.0.0.201:80
DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]: 10.0.0.201:80/%(bucket)s
Encryption password:
Path to GPG program [/usr/bin/gpg]:
Use HTTPS protocol [Yes]: no
HTTP Proxy server name:
Test access with supplied credentials? [Y/n] y
Save settings? [y/N] y
[root@node-1 ~]# vim /root/.s3cfg
signature_v2 = True
- 查看之前创建的bucket
[root@node-1 ~]# s3cmd ls
2021-01-18 15:00 s3://my-first-s3-bucket
[root@node-1 ~]#
- 使用s3cmd创建一个新的bucket
[root@node-1 ~]# s3cmd mb s3://s3cmd-demo
Bucket 's3://s3cmd-demo/' created
[root@node-1 ~]#
- 使用s3cmd的put方法上传本地文件至 radosgw,发现报错
[root@node-1 ~]# s3cmd put /etc/fstab s3://my-first-s3-bucket/s3c-demo
upload: '/etc/fstab' -> 's3://my-first-s3-bucket/s3c-demo' [1 of 1]
510 of 510 100% in 0s 633.53 B/s done
ERROR: S3 error: 416 (InvalidRange)
- 编辑 10.0.0.201服务器的 ceph.conf,添加如下两行配置
[root@node-1 ceph-deploy]# vim ceph.conf
[mon]
mon allow pool delete = true
mon_max_pg_per_osd = 300
- 把修改过后的ceph.conf文件推送到node-1,node-2, node-3
[root@node-1 ceph-deploy]# ceph-deploy --overwrite-conf config push node-1 node-2 node-3
- 在node-1 node-2 node-3 三台服务器上重启mon服务
[root@node-1 ceph-deploy]# systemctl restart ceph-mon.target
- 重新尝试上传文件
[root@node-1 ceph-deploy]# s3cmd put /etc/hosts s3://s3cmd-demo/s3cmd-demo
upload: '/etc/hosts' -> 's3://s3cmd-demo/s3cmd-demo' [1 of 1]
250 of 250 100% in 1s 171.75 B/s done
- 查看上传的文件
[root@node-1 ceph-deploy]# s3cmd ls s3://s3cmd-demo
2021-01-19 14:27 250 s3://s3cmd-demo/s3cmd-demo
[root@node-1 ceph-deploy]#
- 上传目录,把整个目录放在s3://s3cmd-demo/s3-etc/下
[root@node-1 ceph-deploy]# s3cmd put /etc s3://s3cmd-demo/s3-etc/ --recursive
- 此时会看到有7个pool,其中“default.rgw.buckets.data”是上传文件后生成的
[root@node-1 ~]# ceph osd lspools
1 ceph-demo
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
[root@node-1 ~]#
- 查看pool里的内容,有很多
[root@node-1 ~]# rados -p default.rgw.buckets.data ls
deea903a-1500-4c1b-a6ca-e7f1f4a94b81.54141.1_s3-etc/etc/selinux/targeted/active/modules/100/cloudform/cil
deea903a-1500-4c1b-a6ca-e7f1f4a94b81.54141.1_s3-etc/etc/selinux/targeted/active/modules/100/open/hll
deea903a-1500-4c1b-a6ca-e7f1f4a94b81.54141.1_s3-etc/etc/selinux/targeted/active/modules/100/secadm/hll
deea903a-1500-4c1b-a6ca-e7f1f4a94b81.54141.1_s3-etc/etc/selinux/targeted/active/modules/100/kmscon/lang_ext
deea903a-1500-4c1b-a6ca-e7f1f4a94b81.54141.1_s3-etc/etc/selinux/targeted/active/modules/100/minissdpd/hll
- 他们都有统一的前缀,而这个前缀(index)是通过下面的方式核查的
[root@node-1 ~]# rados -p default.rgw.buckets.index ls
.dir.deea903a-1500-4c1b-a6ca-e7f1f4a94b81.54141.1
.dir.deea903a-1500-4c1b-a6ca-e7f1f4a94b81.44133.1
5.5 Swift 风格的api接口
- 在原有账号的基础上建立swift的子账号
[root@node-1 ~]# radosgw-admin user list
[
"ceph-s3-user"
]
[root@node-1 ~]# radosgw-admin subuser create --uid=ceph-s3-user --subuser=ceph-s3-user:swift --access=full
{
"user_id": "ceph-s3-user",
"display_name": "Ceph S3 User Demo",
"email": "",
2.生成secret-key
[root@node-1 ~]# sudo radosgw-admin key create --subuser=ceph-s3-user:swift --key-type=swift --gen-secret
{
"user_id": "ceph-s3-user",
"display_name": "Ceph S3 User Demo",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [
{
"id": "ceph-s3-user:swift",
"permissions": "full-control"
}
],
"keys": [
{
"user": "ceph-s3-user",
"access_key": "ZHTTSYSKPY6IMB4YLBWI",
"secret_key": "DmAYwx1A9nR9q271F0lPS1QKgIGYRB5U4XTVOmRk"
}
],
"swift_keys": [
{
"user": "ceph-s3-user:swift",
"secret_key": "87y9HoU5o5YYSyPqenKev6cZwnzJz5YSO25wltUR"
}
]
- 安装对应工具包
[root@node-1 ~]# yum install python-setuptools -y
[root@node-1 ~]# yum install python-pip -y
# yum 安装的pip版本比较低,升级成最新版本,期间可能会因为网络原因多次失败,请多试几次
[root@node-1 ~]# pip install --upgrade pip
Collecting pip
Downloading https://files.pythonhosted.org/packages/54/eb/4a3642e971f404d69d4f6fa3885559d67562801b99d7592487f1ecc4e017/pip-20.3.3-py2.py3-none-any.whl (1.5MB)
100% |████████████████████████████████| 1.5MB 9.8kB/s
Installing collected packages: pip
Found existing installation: pip 8.1.2
Uninstalling pip-8.1.2:
Successfully uninstalled pip-8.1.2
Successfully installed pip-20.3.3
[root@node-1 ~]#
# 安装swift客户端
[root@node-1 ~]# pip install python-swiftclient
DEPRECATION: Python 2.7 reached the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 is no longer maintained. pip 21.0 will drop support for Python 2.7 in January 2021. More details about Python 2 support in pip can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support pip 21.0 will remove support for this functionality.
Collecting python-swiftclient
Downloading python_swiftclient-3.11.0-py2.py3-none-any.whl (86 kB)
|████████████████████████████████| 86 kB 233 kB/s
Requirement already satisfied: futures>=3.0.0; python_version == "2.7" in /usr/lib/python2.7/site-packages (from python-swiftclient) (3.1.1)
Requirement already satisfied: requests>=1.1.0 in /usr/lib/python2.7/site-packages (from python-swiftclient) (2.11.1)
Requirement already satisfied: six>=1.9.0 in /usr/lib/python2.7/site-packages (from python-swiftclient) (1.9.0)
Requirement already satisfied: urllib3==1.16 in /usr/lib/python2.7/site-packages (from requests>=1.1.0->python-swiftclient) (1.16)
Installing collected packages: python-swiftclient
Successfully installed python-swiftclient-3.11.0
[root@node-1 ~]#
- 用swiftclient来查看 bucket
[root@node-1 ~]# swift -A http://10.0.0.201:80/auth -U ceph-s3-user:swift -K 87y9HoU5o5YYSyPqenKev6cZwnzJz5YSO25wltUR list
my-first-s3-bucket
s3cmd-demo
[root@node-1 ~]#
- 创建环境变量,简化指令
[root@node-1 ~]# cat swift_openrc.sh
export ST_AUTH=http://10.0.0.201:80/auth
export ST_USER=ceph-s3-user:swift
export ST_KEY=87y9HoU5o5YYSyPqenKev6cZwnzJz5YSO25wltUR
[root@node-1 ~]#
[root@node-1 ~]# source swift_openrc.sh
# 简化后的指令
[root@node-1 ~]# swift list
my-first-s3-bucket
s3cmd-demo
[root@node-1 ~]#
- swift创建bucket
[root@node-1 ~]# swift post swift-demo
[root@node-1 ~]# swift list
my-first-s3-bucket
s3cmd-demo
swift-demo
[root@node-1 ~]#
- swift 上传本地文件至指定的bucket上,如果bucket不存在,则会自动创建bucket
[root@node-1 ~]# swift upload swift_demo /etc/fstab
etc/fstab
[root@node-1 ~]#
- swift 下载 文件到本地
root@node-1 ~]# swift download swift_demo etc/fstab
etc/fstab [auth 0.010s, headers 0.013s, total 0.013s, 0.157 MB/s]
[root@node-1 ~]# ls
anaconda-ks.cfg ceph-deploy-ceph.log Documents etc Music Pictures python-demo Templates
ceph-deploy Desktop Downloads initial-setup-ks.cfg mysql Public swift_openrc.sh Videos
[root@node-1 ~]# cat /etc/fstab
# /etc/fstab
# Created by anaconda on Fri Jul 10 23:25:02 2020
#
六、CephFS 文件系统
Ceph File System (CephFS) 是与 POSIX 标准兼容的文件系统, 能够提供对 Ceph 存储集群上的文件访问。 CephFS 需要至少一个元数据服务器 (Metadata Server - MDS) daemon (ceph-mds) 运行, MDS daemon 管理着与存储在 CephFS 上的文件相关的元数据, 并且协调着对 Ceph 存储系统的访问
6.1 安装部署MDS集群
- 将node-1 node-2 node-3 部署成 MDS集群服务
[root@node-1 ceph-deploy]# ceph-deploy --overwrite-conf mds create node-1
[root@node-1 ceph-deploy]# ceph-deploy --overwrite-conf mds create node-2
[root@node-1 ceph-deploy]# ceph-deploy --overwrite-conf mds create node-3
6.2 创建CephFS文件系统
- 创建ceph_metadata 和 ceph_data 的OSD pool
[root@node-1 ceph-deploy]# ceph osd pool create cephfs_data 16 16
[root@node-1 ceph-deploy]# ceph osd pool create cephfs_metadata 16 16
- 新建一个文件系统,并关联上面创建的两个pool
[root@node-1 ceph-deploy]# ceph fs new cephfs-demo cephfs_metadata cephfs_data
new fs with metadata pool 8 and data pool 9
[root@node-1 ceph-deploy]#
[root@node-1 ceph-deploy]# ceph fs ls
name: cephfs-demo, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[root@node-1 ceph-deploy]#
- 此时可看到mds集群已变成一个active ,两个standby的状态了
[root@node-1 ceph-deploy]# ceph -s
cluster:
id: ff22ec29-da80-4790-97b5-c6699433f0b0
health: HEALTH_WARN
too many PGs per OSD (288 > max 250)
services:
mon: 3 daemons, quorum node-1,node-2,node-3 (age 63m)
mgr: node-2(active, since 71m), standbys: node-1, node-3
mds: cephfs-demo:1 {0=node-1=up:active} 2 up:standby
6.3 内核挂载CephFS
- 创建挂载点
[root@node-1 ~]# mkdir /mnt/ceph-fs
- 挂载
[root@node-1 ~]# mount -t ceph 10.0.0.202:6789:/ /mnt/ceph-fs -o name=admin
[root@node-1 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 894M 0 894M 0% /dev
tmpfs 910M 0 910M 0% /dev/shm
tmpfs 910M 11M 900M 2% /run
tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root 50G 7.7G 43G 16% /
/dev/sr0 4.5G 4.5G 0 100% /media/cdrom
/dev/sda1 197M 163M 35M 83% /boot
tmpfs 910M 24K 910M 1% /var/lib/ceph/osd/ceph-0
tmpfs 182M 12K 182M 1% /run/user/42
tmpfs 182M 0 182M 0% /run/user/0
10.0.0.202:6789:/ 42G 0 42G 0% /mnt/ceph-fs
6.4 通过ceph-fuse 对cephfs进行内核态的挂载
- yum 安装ceph-fuse 软件
[root@node-1 ~]# yum install ceph-fuse -y
- 新建挂载点并挂载
[root@node-1 ~]# mkdir /mnt/ceph-fuse
[root@node-1 ~]# ceph-fuse -n client.admin -m 10.0.0.201:6789,10.0.0.201:6789 /mnt/ceph-fuse/
ceph-fuse[4106]: starting ceph client
2021-01-25 22:55:57.730 7ff1898c2f80 -1 init, newargv = 0x55a1b538ae20 newargc=9
ceph-fuse[4106]: starting fuse
[root@node-1 ~]#
- 查看挂载情况和挂载的文件格式
[root@node-1 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 894M 0 894M 0% /dev
tmpfs 910M 0 910M 0% /dev/shm
tmpfs 910M 11M 900M 2% /run
tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root 50G 7.8G 43G 16% /
/dev/sr0 4.5G 4.5G 0 100% /media/cdrom
/dev/sda1 197M 163M 35M 83% /boot
tmpfs 910M 24K 910M 1% /var/lib/ceph/osd/ceph-0
tmpfs 182M 12K 182M 1% /run/user/42
tmpfs 182M 0 182M 0% /run/user/0
ceph-fuse 42G 0 42G 0% /mnt/ceph-fuse
10.0.0.202:6789:/ 42G 0 42G 0% /mnt/ceph-fs
[root@node-1 ceph-fuse]# df -T
Filesystem Type 1K-blocks Used Available Use% Mounted on
devtmpfs devtmpfs 914500 0 914500 0% /dev
tmpfs tmpfs 931520 0 931520 0% /dev/shm
tmpfs tmpfs 931520 10444 921076 2% /run
tmpfs tmpfs 931520 0 931520 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 52403200 8124256 44278944 16% /
/dev/sr0 iso9660 4669162 4669162 0 100% /media/cdrom
/dev/sda1 xfs 201380 166056 35324 83% /boot
tmpfs tmpfs 931520 24 931496 1% /var/lib/ceph/osd/ceph-0
tmpfs tmpfs 186304 12 186292 1% /run/user/42
tmpfs tmpfs 186304 0 186304 0% /run/user/0
ceph-fuse fuse.ceph-fuse 43589632 0 43589632 0% /mnt/ceph-fuse
10.0.0.202:6789:/ ceph 43589632 0 43589632 0% /mnt/ceph-fs
[root@node-1 ceph-fuse]#
七、OSD扩容与换盘
7.1 osd纵向扩容
横向扩容(scale out):简单的理解,就是增加节点,通过增加节点来达到增加容量的目的
纵向扩容(scale up):通过增加现有节点的硬盘(OSD)来达到增加容量的目的
- 纵向扩容增加node-1节点的OSD
[root@node-1 ceph-deploy]# ceph-deploy osd create node-1 --data /dev/sdc
[node-1][INFO ] Running command: /bin/ceph --cluster=ceph osd stat --format=json
[ceph_deploy.osd][DEBUG ] Host node-1 is now ready for osd use.
[root@node-1 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.17569 root default
-3 0.07809 host node-1
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.02930 osd.3 up 1.00000 1.00000
-5 0.04880 host node-2
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host node-3
2 hdd 0.04880 osd.2 up 1.00000 1.00000
[root@node-1 ceph-deploy]#
7.2 数据 rebalancing 重分步
随着集群资源的不断增长,Ceph集群的空间可能会存在不够用的情况,因此需要对集群进行扩容,扩容通常包含两种:横向扩容和纵向扩容。横向扩容即增加台机器,纵向扩容即在单个节点上添加更多的OSD存储,以满足数据增长的需求,添加OSD的时候由于集群的状态(cluster map)已发生了改变,因此会涉及到数据的重分布(rebalancing),即 pool 的PGs数量是固定的,需要将PGs数平均的分摊到多个OSD节点上。
7.3 临时关闭rebalance
-
当在做rebalance的时候,每个osd都会按照osd_max_backfills指定数量的线程来同步,如果该数值比较大,同步会比较快,但是会影响部分性能;另外数据同步时,是走的cluster_network,而客户端连接是用的public_network,生产环境建议这两个网络用万兆网络,较少网络传输的影响;
-
同样,为了避免业务繁忙时候rebalance带来的性能影响,可以对rebalance进行关闭;当业务比较小的时候,再打开。
#关闭 rebalance
[root@node-1 ~]# ceph osd set norebalance
# 关闭 backfill
[root@node-1 ~]# ceph osd set nobackfill
[root@node-1 ~]# ceph osd set nobackfill
nobackfill is set
[root@node-1 ~]# ceph -s
cluster:
id: ff22ec29-da80-4790-97b5-c6699433f0b0
health: HEALTH_WARN
nobackfill,norebalance flag(s) set
services:
mon: 3 daemons, quorum node-1,node-2,node-3 (age 5m)
mgr: node-2(active, since 40m), standbys: node-3, node-1
mds: cephfs-demo:1 {0=node-3=up:active} 2 up:standby
osd: 4 osds: 4 up (since 40m), 4 in (since 57m)
flags nobackfill,norebalance
rgw: 1 daemon active (node-1)
task status:
data:
pools: 9 pools, 288 pgs
objects: 5.25k objects, 9.2 GiB
usage: 32 GiB used, 148 GiB / 180 GiB avail
pgs: 288 active+clean
[root@node-1 ~]#
八、 OSD坏盘更换
Ceph的osd是不建议做成raid10或者raid5的,一般建议单盘跑。在我们的环境中,为了充分利用raid卡的缓存,即使是单盘,我们还是将其挂在raid卡下做成raid0。
这样不可避免的问题就是磁盘的损坏,需要在ceph当中做一些摘除动作,同时还需要重建raid。
在更换完磁盘重建raid之后,需要重新添加osd。新的osd加入到集群后,ceph还会自动进行数据恢复和回填的过程。我们还需要通过调整一些数据恢复和回填的参数来控制其恢复速度
- 日常检查OSD磁盘有无坏道,一般有坏道,处于将坏未坏的时候,那块osd写入和读取数据延时会比较大
[root@node-1 ~]# ceph osd perf
osd commit_latency(ms) apply_latency(ms)
3 0 0
2 0 0
1 0 0
0 0 0
[root@node-1 ~]#
- 模拟osd损坏,更换osd的过程
#在node-2上停止 osd-4的服务,查看osd.4状态为down
[root@node-2 ~]# systemctl stop ceph-osd@4
[root@node-1 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.20499 root default
-3 0.07809 host node-1
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.02930 osd.3 up 1.00000 1.00000
-5 0.07809 host node-2
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.02930 osd.4 down 1.00000 1.00000
-7 0.04880 host node-3
2 hdd 0.04880 osd.2 up 1.00000 1.00000
[root@node-1 ceph-deploy]#
- 在ceph osd集群中把 osd.4移除
[root@node-1 ceph-deploy]# ceph osd out osd.4
marked out osd.4.
[root@node-1 ceph-deploy]#
- 等数据rebalancing完成后,开始一系列的移除工作(crush map )
[root@node-1 ceph-deploy]# ceph osd crush rm osd.4
removed item id 4 name 'osd.4' from crush map
[root@node-1 ceph-deploy]#
[root@node-1 ceph-deploy]# ceph osd rm osd.4
removed osd.4
[root@node-1 ceph-deploy]#
- 把对应的认证信息也删掉
[root@node-1 ceph-deploy]# ceph auth rm osd.4
updated
[root@node-1 ceph-deploy]#
九、Ceph集群运维
现在,所有支持 systemd 的发行版( CentOS 7 、 Fedora 、Debian Jessie 以及更高版、 SUSE )都用原生的 systemd 文件来管理 ceph 守护进程,不再使用原来的 sysvinit 脚本了。
9.1 Ceph 守护服务管理
- 查看与ceph相关的所有systemd进程
[root@node-1 ceph-deploy]# cd /usr/lib/systemd/system
[root@node-1 system]# ls | grep ceph
ceph-crash.service
ceph-fuse@.service
ceph-fuse.target
ceph-mds@.service
ceph-mds.target
ceph-mgr@.service
ceph-mgr.target
ceph-mon@.service
ceph-mon.target
ceph-osd@.service
ceph-osd.target
ceph-radosgw@.service
ceph-radosgw.target
ceph.target
ceph-volume@.service
[root@node-1 system]#
- 以查看mon 服务的状态为例,有以下两种方式
- 方式一
[root@node-1 system]# systemctl status ceph-mon.target
● ceph-mon.target - ceph target allowing to start/stop all ceph-mon@.service instances at once
Loaded: loaded (/usr/lib/systemd/system/ceph-mon.target; enabled; vendor preset: enabled)
Active: active since Sun 2021-01-31 15:28:18 CST; 5h 34min ago
Jan 31 15:28:18 node-1 systemd[1]: Reached target ceph target allowing to start/stop all ceph-mon@.service instances at once.
[root@node-1 system]#
- 方式二
[root@node-1 system]# systemctl status ceph-mon@node-1
● ceph-mon@node-1.service - Ceph cluster monitor daemon
Loaded: loaded (/usr/lib/systemd/system/ceph-mon@.service; enabled; vendor preset: disabled)
Active: active (running) since Sun 2021-01-31 15:28:18 CST; 5h 35min ago
Main PID: 1216 (ceph-mon)
CGroup: /system.slice/system-ceph\x2dmon.slice/ceph-mon@node-1.service
└─1216 /usr/bin/ceph-mon -f --cluster ceph --id node-1 --setuser ceph --setgroup ceph
Jan 31 16:21:25 node-1 ceph-mon[1216]: 2021-01-31 16:21:25.589 7fee31553700 -1 mon.node-1@0(leader) e3 get_health_metrics reporting 27 slow op... 483 v28)
Jan 31 16:21:31 node-1 ceph-mon[1216]: 2021-01-31 16:21:31.027 7fee31553700 -1 mon.node-1@0(leader) e3 get_health_metrics reporting 2 slow ops...9.048923)
Jan 31 16:21:36 node-1 ceph-mon[1216]: 2021-01-31 16:21:36.029 7fee31553700 -1 mon.node-1@0(leader) e3 get_health_metrics reporting 2 slow ops...9.048923)
Jan 31 16:46:02 node-1 ceph-mon[1216]: 2021-01-31 16:46:02.719 7fee3555b700 -1 Fail to open '/proc/5160/cmdline' error = (2) No such file or directory
Jan 31 16:46:02 node-1 ceph-mon[1216]: 2021-01-31 16:46:02.720 7fee3555b700 -1 received signal: Hangup from <unknown> (PID: 5160) UID: 0
Jan 31 16:46:02 node-1 ceph-mon[1216]: 2021-01-31 16:46:02.854 7fee3555b700 -1 Fail to open '/proc/5160/cmdline' error = (2) No such file or directory
Jan 31 16:46:02 node-1 ceph-mon[1216]: 2021-01-31 16:46:02.854 7fee3555b700 -1 received signal: Hangup from <unknown> (PID: 5160) UID: 0
Jan 31 17:36:33 node-1 ceph-mon[1216]: 2021-01-31 17:36:33.908 7fee31553700 -1 mon.node-1@0(electing) e3 get_health_metrics reporting 8 slow o...130, , 0)
Jan 31 17:37:08 node-1 ceph-mon[1216]: 2021-01-31 17:37:08.916 7fee31553700 -1 mon.node-1@0(electing) e3 get_health_metrics reporting 1 slow o...7.948367)
Jan 31 17:37:13 node-1 ceph-mon[1216]: 2021-01-31 17:37:13.923 7fee31553700 -1 mon.node-1@0(leader) e3 get_health_metrics reporting 4 slow ops...7.948367)
Hint: Some lines were ellipsized, use -l to show in full.
[root@node-1 system]#
3、同样,查看OSD的也有两种方式
[root@node-1 system]# systemctl status ceph-osd@0
● ceph-osd@0.service - Ceph object storage daemon osd.0
Loaded: loaded (/usr/lib/systemd/system/ceph-osd@.service; enabled-runtime; vendor preset: disabled)
Active: active (running) since Sun 2021-01-31 15:28:18 CST; 5h 39min ago
Main PID: 1233 (ceph-osd)
CGroup: /system.slice/system-ceph\x2dosd.slice/ceph-osd@0.service
└─1233 /usr/bin/ceph-osd -f --cluster ceph --id 0 --setuser ceph --setgroup ceph
[root@node-1 system]# systemctl status ceph-osd.target
● ceph-osd.target - ceph target allowing to start/stop all ceph-osd@.service instances at once
Loaded: loaded (/usr/lib/systemd/system/ceph-osd.target; enabled; vendor preset: enabled)
Active: active since Sun 2021-01-31 15:28:18 CST; 5h 40min ago
Jan 31 15:28:18 node-1 systemd[1]: Reached target ceph target allowing to start/stop all ceph-osd@.service instances at once.
[root@node-1 system]#
9.2 Ceph 服务日志分析
- 与Ceph相关的日志存储位置
[root@node-1 system]# cd /var/log/ceph/
[root@node-1 ceph]# ls
ceph.audit.log ceph-client.rgw.node-1.log ceph-mds.node-1.log ceph-mon.node-1.log-20210131.gz ceph-volume.log
ceph.audit.log-20210131.gz ceph.log ceph-mgr.node-1.log ceph-osd.0.log ceph-volume-systemd.log
ceph-client.admin.log ceph.log-20210131.gz ceph-mon.node-1.log ceph-osd.3.log
[root@node-1 ceph]#
9.3 Ceph 集群状态监控
- 查看集群状态
[root@node-1 ceph]# ceph -s
cluster:
id: ff22ec29-da80-4790-97b5-c6699433f0b0
health: HEALTH_OK
services:
mon: 3 daemons, quorum node-1,node-2,node-3 (age 3h)
mgr: node-2(active, since 5h), standbys: node-3, node-1
mds: cephfs-demo:1 {0=node-3=up:active} 2 up:standby
osd: 4 osds: 4 up (since 4h), 4 in (since 4h)
rgw: 1 daemon active (node-1)
task status:
data:
pools: 9 pools, 288 pgs
objects: 4.12k objects, 4.8 GiB
usage: 19 GiB used, 161 GiB / 180 GiB avail
pgs: 288 active+clean
[root@node-1 ceph]#
- 动态观察集群状态
[root@node-1 ceph]# ceph -w
- 资源池空间使用情况
[root@node-1 ceph]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 161 GiB 15 GiB 19 GiB 10.50
TOTAL 180 GiB 161 GiB 15 GiB 19 GiB 10.50
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
ceph-demo 1 64 4.7 GiB 1.24k 14 GiB 8.66 50 GiB
.rgw.root 2 32 1.2 KiB 4 768 KiB 0 50 GiB
default.rgw.control 3 32 0 B 8 0 B 0 50 GiB
default.rgw.meta 4 32 2.4 KiB 12 2.1 MiB 0 50 GiB
default.rgw.log 5 32 0 B 207 0 B 0 50 GiB
default.rgw.buckets.index 6 32 0 B 4 0 B 0 50 GiB
default.rgw.buckets.data 7 32 35 MiB 2.62k 562 MiB 0.37 50 GiB
cephfs_metadata 8 16 551 KiB 23 3.2 MiB 0 50 GiB
cephfs_data 9 16 2.5 KiB 1 192 KiB 0 50 GiB
[root@node-1 ceph]#
- 查看每块OSD的具体的存储使用情况
[root@node-1 ceph]# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.04880 1.00000 50 GiB 4.3 GiB 3.3 GiB 817 KiB 1023 MiB 46 GiB 8.50 0.81 171 up
3 hdd 0.02930 1.00000 30 GiB 2.7 GiB 1.7 GiB 0 B 1 GiB 27 GiB 9.14 0.87 117 up
1 hdd 0.04880 1.00000 50 GiB 6.0 GiB 5.0 GiB 833 KiB 1023 MiB 44 GiB 11.91 1.13 288 up
2 hdd 0.04880 1.00000 50 GiB 6.0 GiB 5.0 GiB 813 KiB 1023 MiB 44 GiB 11.91 1.13 288 up
TOTAL 180 GiB 19 GiB 15 GiB 2.4 MiB 4.0 GiB 161 GiB 10.50
MIN/MAX VAR: 0.81/1.13 STDDEV: 1.56
[root@node-1 ceph]#
9.4 Ceph 资源池管理
- 资源池pool的创建
[root@node-1 ceph]# ceph osd pool create pool-demo 16 16
pool 'pool-demo' created
[root@node-1 ceph]#
- 查看所有的资源池
[root@node-1 ceph]# ceph osd lspools
1 ceph-demo
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
8 cephfs_metadata
9 cephfs_data
10 pool-demo
[root@node-1 ceph]#
- 调整对应的资源池pool的副本数为2
[root@node-1 ceph]# ceph osd pool set pool-demo size 2
set pool 10 size to 2
[root@node-1 ceph]#
- 查看对应的资源池的pg和pgp数
[root@node-1 ceph]# ceph osd pool get pool-demo pg_num
pg_num: 16
[root@node-1 ceph]# ceph osd pool get pool-demo pgp_num
pgp_num: 16
[root@node-1 ceph]#
- 给对应的资源池pool划分用户类别(rbd\cephfs\rgw)
[root@node-1 ceph]# ceph osd pool application enable pool-demo rbd
enabled application 'rbd' on pool 'pool-demo'
[root@node-1 ceph]#
9.5 Ceph PG数据分布
9.6 Ceph 参数配置调整
- ceph集群默认不允许手动删除pool,如果要删,需要调整下面的参数(该方法只是临时有效,服务重启后会恢复原有参数)
ceph --admin-daemon /var/run/ceph/ceph-mon.node-1.asok config show | grep mon_allow_pool_delete
"mon_allow_pool_delete": "false",
[root@node-1 ceph]#
[root@node-1 ceph]# ceph --admin-daemon /var/run/ceph/ceph-mon.node-1.asok config set mon_allow_pool_delete true
{
"success": "mon_allow_pool_delete = 'true' "
}
[root@node-1 ceph]#
- 调整后可成功删除
[root@node-2 ~]# ceph osd pool rm pool-demo pool-demo --yes-i-really-really-mean-it
pool 'pool-demo' removed
[root@node-2 ~]#
- 永久生效模式–把“mon allow pool delete = true”写到配置文件里
[root@node-1 ceph-deploy]# cat ceph.conf
[global]
fsid = ff22ec29-da80-4790-97b5-c6699433f0b0
public_network = 10.0.0.0/24
cluster_network = 10.211.56.0/24
mon_initial_members = node-1
mon_host = 10.0.0.201
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
[client.rgw.node-1]
rgw_frontends = "civetweb port=80"
[mon]
mon allow pool delete = true
mon_max_pg_per_osd = 300
[root@node-1 ceph-deploy]#
- 把修改后的配置推送给node-1 node-2 node-3
[root@node-1 ceph-deploy]# ceph-deploy push config node-1 node-2 node-3
十、调整Crush Map
10.1 Crush Map 功能简介
CRUSH 算法通过计算数据存储位置来确定如何存储和检索。 CRUSH 授权 Ceph 客户端直接连接 OSD ,而非通过一个中央服务器或代理。数据存储、检索算法的使用,使 Ceph 避免了单点故障、性能瓶颈、和伸缩的物理限制。
CRUSH 需要一张集群的 Map,且使用 CRUSH Map 把数据伪随机地、尽量平均地分布到整个集群的 OSD 里。CRUSH Map 包含 OSD 列表、把设备汇聚为物理位置的“桶”列表、和指示 CRUSH 如何复制存储池里的数据的规则列表。
10.2 CRUSH Map 规则剖析
要激活 CRUSH Map 里某存储池的规则,找到通用规则集编号,然后把它指定到那个规则集。
1 查看crush map的整体规则
[root@node-1 ceph-deploy]# ceph osd crush dump
2.查看crush map 的规则rule
[root@node-1 ceph-deploy]# ceph osd crush rule ls
replicated_rule
[root@node-1 ceph-deploy]#
3.查看对应资源池pool的rule
[root@node-1 ceph-deploy]# ceph osd pool get ceph-demo crush_rule
crush_rule: replicated_rule
[root@node-1 ceph-deploy]#
10.3 定制Crush 拓扑架构
CRUSH Map 主要有 4 个段落。
设备:由任意对象存储设备组成,即对应一个 ceph-osd进程的存储器。 Ceph 配置文件里的每个 OSD 都应该有一个设备。
桶类型: 定义了 CRUSH 分级结构里要用的桶类型( types ),桶由逐级汇聚的存储位置(如行、机柜、机箱、主机等等)及其权重组成。
桶实例: 定义了桶类型后,还必须声明主机的桶类型、以及规划的其它故障域。
规则: 由选择桶的方法组成。

10.4 手动编辑crush map
CRUSH Map 支持“ CRUSH 规则”的概念,用以确定一个存储池里数据的分布。CRUSH 规则定义了归置和复制策略、或分布策略,用它可以规定 CRUSH 如何放置对象副本。对大型集群来说,你可能创建很多存储池,且每个存储池都有它自己的 CRUSH 规则集和规则。默认的 CRUSH Map 里,每个存储池有一条规则、一个规则集被分配到每个默认存储池。
- 下载crush map的二进制文件到本地
[root@node-1 ceph-deploy]# ceph osd getcrushmap -o crushmap.bin
[root@node-1 ceph-deploy]# file crushmap.bin
crushmap.bin: MS Windows icon resource - 8 icons, 1-colors
[root@node-1 ceph-deploy]#
- 把二进制文件编译成txt文本方便修改
[root@node-1 ceph-deploy]# crushtool -d crushmap.bin -o crushmap.txt
- 编辑crushmap.txt,修改成如下所示
# begin crush map
tunable choose_local_tries 0
tunable choose_local_fallback_tries 0
tunable choose_total_tries 50
tunable chooseleaf_descend_once 1
tunable chooseleaf_vary_r 1
tunable chooseleaf_stable 1
tunable straw_calc_version 1
tunable allowed_bucket_algs 54
# devices
device 0 osd.0 class hdd
device 1 osd.1 class hdd
device 2 osd.2 class hdd
device 3 osd.3 class ssd
device 4 osd.4 class ssd
device 5 osd.5 class ssd
# types
type 0 osd
type 1 host
type 2 chassis
type 3 rack
type 4 row
type 5 pdu
type 6 pod
type 7 room
type 8 datacenter
type 9 zone
type 10 region
type 11 root
# buckets
host node-1 {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.078
alg straw2
hash 0 # rjenkins1
item osd.0 weight 0.049
}
host node-2 {
id -5 # do not change unnecessarily
id -6 class hdd # do not change unnecessarily
# weight 0.068
alg straw2
hash 0 # rjenkins1
item osd.1 weight 0.049
}
host node-3 {
id -7 # do not change unnecessarily
id -8 class hdd # do not change unnecessarily
# weight 0.078
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.049
}
host node-1-ssd {
# weight 0.078
alg straw2
hash 0 # rjenkins1
item osd.3 weight 0.029
}
host node-2-ssd {
# weight 0.068
alg straw2
hash 0 # rjenkins1
item osd.5 weight 0.019
}
host node-3-ssd {
# weight 0.078
alg straw2
hash 0 # rjenkins1
item osd.4 weight 0.029
}
root default {
id -1 # do not change unnecessarily
id -2 class hdd # do not change unnecessarily
# weight 0.224
alg straw2
hash 0 # rjenkins1
item node-1 weight 0.039
item node-2 weight 0.034
item node-3 weight 0.039
}
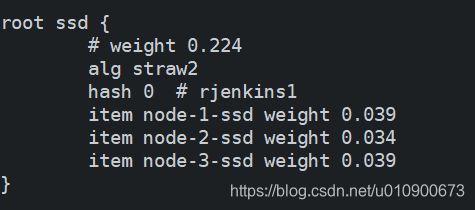
root ssd {
# weight 0.224
alg straw2
hash 0 # rjenkins1
item node-1-ssd weight 0.039
item node-2-ssd weight 0.034
item node-3-ssd weight 0.039
}
# rules
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
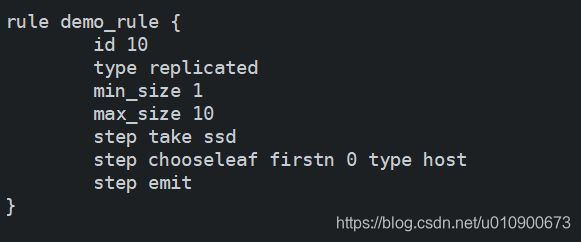
rule demo_rule {
id 10
type replicated
min_size 1
max_size 10
step take ssd
step chooseleaf firstn 0 type host
step emit
}
# end crush map
具体可拆分为:
-
修改device区域
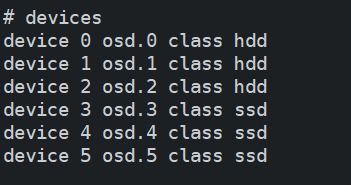
-
修改bucket区域,新增如下部分

-
新增root顶部配置
-
修改rule区域,新增demo-rule
4.将crushmap.txt重新编译成二进制文件
[root@node-1 ceph-deploy]# crushtool -c crushmap.txt -o crushmap-new.bin
- 应用新的crushmap
[root@node-1 ceph-deploy]# ceph osd setcrushmap -i crushmap-new.bin
20
[root@node-1 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-12 0.11197 root ssd
-9 0.03899 host node-1-ssd
3 ssd 0.02899 osd.3 up 1.00000 1.00000
-10 0.03400 host node-2-ssd
5 ssd 0.01900 osd.5 up 1.00000 1.00000
-11 0.03899 host node-3-ssd
4 ssd 0.02899 osd.4 up 1.00000 1.00000
-1 0.11197 root default
-3 0.03899 host node-1
0 hdd 0.04900 osd.0 up 1.00000 1.00000
-5 0.03400 host node-2
1 hdd 0.04900 osd.1 up 1.00000 1.00000
-7 0.03899 host node-3
2 hdd 0.04900 osd.2 up 1.00000 1.00000
[root@node-1 ceph-deploy]#
- 查看已新生成demo-rule规则
[root@node-1 ~]# ceph osd crush rule ls
replicated_rule
demo_rule
[root@node-1 ~]#
- 将 原有的ceph-demo 资源池 设置成新的demo_rule
[root@node-1 ~]# ceph osd pool set ceph-demo crush_rule demo_rule
set pool 1 crush_rule to demo_rule
[root@node-1 ~]#
- 往ceph-demo资源池新建文件,查看该文件的存储设备
[root@node-1 ~]# rbd create ceph-demo/crush-demo.img --size 5G
[root@node-1 ~]# ceph osd map ceph-demo crush-demo.img
osdmap e565 pool 'ceph-demo' (1) object 'crush-demo.img' -> pg 1.d267742c (1.2c) -> up ([5,4,3], p5) acting ([1,4], p1)
[root@node-1 ~]#
- 还原crushmap
[root@node-1 ~]# ceph osd crush rule ls
replicated_rule
demo_rule
[root@node-1 ~]# ceph osd pool set ceph-demo crush_rule replicated_rule
set pool 1 crush_rule to replicated_rule
[root@node-1 ceph-deploy]# ceph osd setcrushmap -i crushmap.bin
21
[root@node-1 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.22447 root default
-3 0.07809 host node-1
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.02930 osd.3 up 1.00000 1.00000
-5 0.06828 host node-2
1 hdd 0.04880 osd.1 up 1.00000 1.00000
5 hdd 0.01949 osd.5 up 1.00000 1.00000
-7 0.07809 host node-3
2 hdd 0.04880 osd.2 up 1.00000 1.00000
4 hdd 0.02930 osd.4 up 1.00000 1.00000
[root@node-1 ceph-deploy]# ceph osd map ceph-demo crush-demo.img
osdmap e658 pool 'ceph-demo' (1) object 'crush-demo.img' -> pg 1.d267742c (1.2c) -> up ([1,0,4], p1) acting ([1,0,4], p1)