一文深入理解高并发服务器性能优化

我们现在已经搞定了 C10K并发连接问题 ,升级一下,如何支持千万级的并发连接?你可能说,这不可能。你说错了,现在的系统可以支持千万级的并发连接,只不过所使用的那些激进的技术,并不为人所熟悉。
要了解这是如何做到的,我们得求助于Errata Security的CEO Robert Graham,看一下他在 Shmoocon 2013 的绝对奇思妙想的演讲,题目是 C10M Defending The Internet At Scale。
Robert以一种我以前从来没有听说过的才华横溢的方式来搭建处理这个问题的架构。他的开场是一些历史,关于Unix最初为什么不是设计成一个通用的服务器的OS,而是为电话网络的控制系统设计的。真正传输数据的是电话网络,因而控制层和数据层有非常清晰的区分。问题是,我们现在用的Unix服务器还是数据层的一部分,虽然并不应当是这样的。如果一台服务器只有一个应用程序,为这样的系统设计内核,与设计一个多用户系统的内核的区别是非常大的。
关键问题:
- 不要让内核去做所有繁重的处理。把数据包处理,内存管理以及处理器调度从内核移到可以让他更高效执行的应用程序中去。让Linux去处理控制层,数据层由应用程序来处理。
结果就是成为一个用200个时钟周期处理数据包,14万个时钟周期来处理应用程序逻辑,可以处理1000万并发连接的系统。而作为重要的内存访问花费300个时钟周期,这是尽可能减少编码和缓存的设计方法的关键。
用一个面向数据层的系统你可以每秒处理1000万个数据包。用一个面向控制层的系统每秒你只能获得1百万个数据包。
这貌似有点极端,你不能局限于操作系的性能,你必须自己去实现。
现在,让我们学习Robert是怎样创作一个能处理1000万并发连接的系统……
C10K的问题——过去十年
十年前,工程师在处理C10K可扩展性问题时,都尽可能的避免服务器处理超过10,000个的并发连接。通过修正操作系统内核以及用事件驱动型服务器(如Nginx和Node)替代线程式的服务器(如Apache)这个问题已经解决。从Apache转移到可扩展的服务器上,人们用了十年的时间。在过去的几年中,(我们看到)可扩展服务器的采用率在大幅增长。
Apache的问题
Apache的问题是,(并发)连接数越多它的性能会越低下。
关键问题:(服务器的)性能和可扩展性并不是一码事。它们指的不是同一件事情。当人们谈论规模的时候往往也会谈起性能的事情,但是规模和性能是不可同日而语的。比如Apache。
在仅持续几秒的短时连接时,比如快速事务处理,如果每秒要处理1,000个事务,那么大约有1,000个并发连接到服务器。如果事务增加到10秒,要保持每秒处理1,000个事务就必须要开启10K(10,000个)的并发连接。这时Apache的性能就会陡降,即使抛开DDos攻击。仅仅是大量的下载就会使Apache宕掉。
如果每秒需要处理的并发请求从5,000增加到10,000,你会怎么做?假使你把升级硬件把处理器速度提升为原来的两倍。会是什么情况?你得到了两倍的性能,但是却没有得到两倍的处理规模。处理事务的规模或许仅仅提高到了每秒6,000个(即每秒6,000个并发请求)。继续提高处理器速度,还是无济于事。甚至当性能提升到16倍时,并发连接数还不能达到10,000个。由此,性能和规模并不是一回事。
问题在于Apache总是创建了一个进程然后又把它关闭了,这并不是可扩展的。为什么?因为内核采用的O(n^2) 算法导致服务器不能处理10,000个并发连接。
- 内核中的两个基本问题:
- 连接数 = 线程数/进程数。当一个包(数据包)来临时,它(内核)会遍历所有的10,000个进程以决定由哪个进程处理这个包。
- 连接数= 选择数/轮询次数(单线程情况下)。同样的扩展性问题。每个包不得不遍历一遍列表中的socket。
- 解决方法:修正内核在规定的时间内进行查找
- 不管有多少线程,线程切换的时间都是恒定的。
- 使用一个新的可扩展的epoll()/IOCompletionPort在规定的时间内做socket查询。
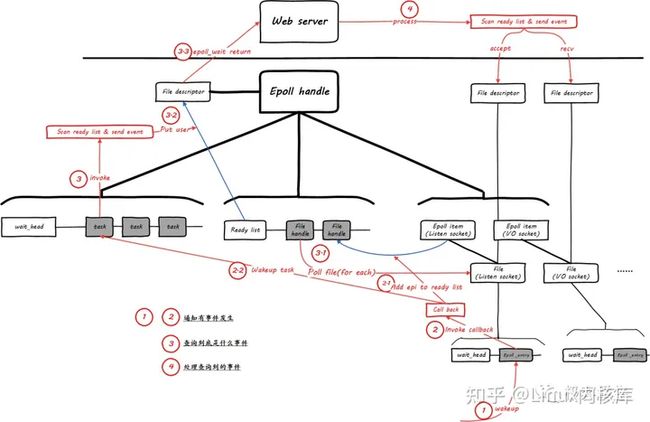
由于线程调度依然没有被扩展,因此服务器对socket大规模的采用epoll,导致需要使用异步编程模式,然而这正是Node和Nginx所采用的方式。这种软件迁移会得到(和原来)不一样的表现(指从apache迁移到ngix等)。即使在一台很慢(配置较低)的服务器上增加连接数性能也不会陡降。介于此,在开启10K并发连接时,一台笔记本电脑(运行ngix)的速度甚至超越了一台16核的服务器(运行Apache)。
C10M问题 —— 下一个十年
在不久的将来,服务器将需要处理数百万的并发连接。由于IPV6普及,连接到每一个服务器的潜在可能连接数目将达到数百万,所以我们需要进入下一个可扩张性阶段。
示例应用程序将会用到这类可扩张性方案:IDS/IPS,因为他们是连接到一台服务器的主干。另一个例子:DNS根服务器、TOR节点、Nmap互联网络、视频流、银行业务、NAT载体、网络语音电话业务PBX、负载均衡器、web缓存、防火墙、邮件接收、垃圾邮件过滤。
通常人们认为互联网规模问题是个人计算机而不是服务器,因为他们销售的是硬件+软件。你买的设备连接到你的数据中心。这些设备可能包含英特尔主板或网络处理器和用于加密的芯片、数据包检测,等等。
2013年2月40gpbs、32核、256gigs RAM X86在新蛋的售价为$5000。这种配置的服务器能够处理10K以上的连接。如果不能,这不是底层的硬件问题,那是因为你选错了软件。这样的硬件能够轻而易举的支持千万的并发连接。
10,000,000个并发连接挑战意味着什么
1. 10,000,000个并发连接
2. 每秒1,000,000个连接——每个连接大约持续10秒
3. 10千兆比特/每秒——快速连接到互联网。
4. 10,000,000包/每秒——预期当前服务器处理50,000包/每秒,这将导致更高的级别。服务器能够用来处理每秒100,000个中断和每个包引发的中断。
5. 10微秒延迟——可扩张的服务器也许能够处理这样的增长,但是延迟将会很突出。
6. 10微秒上下跳动——限制最大延迟
7. 10个一致的CPU内核——软件应该扩张到更多内核。典型的软件只是简单的扩张到四个内核。服务器能够扩张到更多的内核,所以软件需要被重写以支持在拥有更多内核的机器上运行。
我们学的是Unix而不是网络编程(Network Programming)
- 一代代的程序员通过W. Richard Stevens所著的《Unix网络编程》(Unix Networking Programming)学习网络编程技术。问题是,这本书是关于Unix的,并不是网络编程。它讲述的是,你仅需要写一个很小的轻量级的服务器就可以让Unix做一切繁复的工作。然而内核并不是规模的(规模不足)。解决方案是,将这些繁复的工作转移到内核之外,自已处理。
- 一个颇具影响的例子,就是在考虑到Apache的线程每个连接模型(is to consider Apache’s thread per connection model)。这就意味着线程调度器根据到来的数据(on which data arrives)决定调用哪一个(不同的)read()函数(方法)。把线程调度系统当做(数据)包调度系统来使用(我非常喜欢这一点,之前从来没听说过类似的观点)。
- Nginx宣称,它并不把线程调度当作(数据)包调度来用使用,它自已做(进行)包调度。使用select来查找socket,我们知道数据来了,于是就可以立即读取并处理它,数据也不会堵塞。
- 经验:让Unix/Linux处理网络堆栈,之后的事情就由你自已来处理。
你怎么编写软件使其可伸缩?
你怎么改变你的软件使其可伸缩?有大量的经验规则都是假设硬件能处理多少。我们需要真实的执行性能。
要进入下一个等级,我们需要解决的问题是:
- 包的可扩展性
- 多核的可扩展性
- 内存的可扩展性
精简包-编写自己的定制驱动来绕过内核堆栈
- 数据包的存在的问题是它们要通过Unix的内核。网络堆栈复杂又慢。你的应用程序需要的数据包的路径要更加直接。不要让操作系统来处理数据包。
- 做到这一点的方法是编写自己的驱动程序。所有驱动程序要做到是发送数据包到你的应用程序而不是通过内核协议栈。你可以找得到驱动有:PF_RING,Netmap,Interl DPDK(数据层开发套件)。
- 有多快呢?Inter有一个基准是在一个轻量级的服务器上每秒可以处理8000万的数据包(每个数据包200个时钟周期)。这也是通过用户模式。数据包通过用户模式后再向下传递。当Linux获得UDP数据包后通过用户模式在向下传递时,它每秒处理的数据包不会超过100万个。客户驱动对Linux来说性能比是80:1。
- 如果用200个时间周期来每秒获得1000万个数据包,那么可以剩下1400个时钟周期来实现一个类似DNS/IDS的功能。
- 用PF_RING/DPDK来获得原始的数据包的话,你必须自己去做TCP协议栈。人们正在做用户模式的堆栈。对于Inter来讲已有一个提供真正可扩展性能的可用的TCP堆栈。
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linuxc/c++高级开发【直播公开课】
零声白金VIP体验卡:零声白金VIP体验卡(含基础架构/高性能存储/golang/QT/音视频/Linux内核)
多核的可扩展性
多核的可扩展性和多线程可扩展性是不一样的。我们熟知的idea处理器不在渐渐变快,但是我们却拥有越来越多的idea处理器。
大多数代码并不能扩展到4核。当我们添加更多的核心时并不是性能不变,而是我们添加更多的核心时越来越慢。因为我们编写的代码不好。我们期望软件和核心成线性的关系。我们想要的是添加更多的核心就更快。
多线程编程不是多核编程
多线程:
- 每个CPU有多个线程
- 锁来协调线程(通过系统调用)
- 每个线程有不同的任务
多核:
- 每个CPU核心一个线程
- 当两个核心中的两个不同线程访问同一数据时,它们不用停止来相互等待
- 所有线程是同一任务的一部分
我们的问题是如何让一个程序能扩展到多个核心。Unix中的锁是在内核中实现的,在4核心上使用锁会发生什么? 大多数软件会等待其他线程释放一个锁,这样的以来你有更多的CPU核心内核就会耗掉更多的性能。
我们需要的是一个像高速公路的架构而不是一个像靠红绿灯控制的十字路口的架构。我们想用尽可能少的小的开销来让每个人在自己的节奏上而没有等待。
解决方案:
- 保持每一个核心的数据结构,然后聚集起来读取所有的组件。
- 原子性. CPU支持的指令集可以被C调用。保证原子性且没有冲突是非常昂贵的,所以不要期望所有的事情都使用指令。
- 无锁的数据结构。线程间访问不用相互等待。不要自己来做,在不同架构上来实现这个是一个非常复杂的工作。
- 线程模型。线性线程模型与辅助线程模型。问题不仅仅是同步。而是怎么架构你的线程。
- 处理器族。告诉操作系统使用前两个核心。之后设置你的线程运行在那个核心上。你也可以使用中断来做同样的事儿。所以你有多核心的CPU,但这不关Linux事。
内存的可扩展性
假设你有20G内存(RAM),第个连接占用2K,假如你只有20M三级缓存(L3 cache),缓存中没有数据。从缓存转移到主存上消耗300个时钟周期,此时CPU处于空闲状态。想象一下,(处理)每个包要1400个时钟周期。切记还有200时钟周期/每包的开销(应该指等待包的开销)。每个包有4次高速缓存的缺失,这是个问题。
- 提高缓存效率,不要使用指针在整个内存中随便乱放数据。每次你跟踪一个指针都会造成一次高速缓存缺失:[hash pointer] -> [Task Control Block] -> [Socket] -> [App]。这造成了4次高速缓存缺失。将所有的数据保持在一个内存块中:[TCB | Socket | App]. 为每个内存块预分配内存。这样会将高速缓存缺失从4降低到1。
- 分页,32G的数据需要占用64M的分页表,不适合都放在高速缓存上。所以造成2个高速缓存缺失,一个是分页表另一个是它指向的数据。这些细节在开发可扩展软件时是不可忽略的。解决:压缩数据,使用有很多内存访问的高速架构,而不是二叉搜索树。NUMA加倍了主内存的访问时间。内存有可能不在本地,而在其它地方
- 内存池 , 在启动时立即分配所有的内存。在对象(object)、线程(thread)和socket的基础上分配(内存)。
- 超线程,提高CPU使用率,减少延迟,比如当在内存访问中一个线程等待另一个全速线程,这种情况,超线程CPU可以并行执行,不用等待。
- 大内存页, 减小页表的大小。从一开始就预留内存,并且让应用程序管理内存。
选择合适的语言
go语言这种天生为并发而生的语言,完美的发挥了服务器多核优势,很多可以并发处理的任务都可以使用并发来解决,比如go处理http请求时每个请求都会在一个goroutine中执行,C和C++语言当然也可以实现高并发系统,总之:怎样合理的压榨CPU,让其发挥出应有的价值,是优化一直需要探索学习的方向。
推荐开源项目学习:
F-Stack 开发框架
F-Stack 是一款兼顾高性能、易用性和通用性的网络开发框架,传统上 DPDK 大多用于 SDN、NFV、DNS 等简单的应用场景下,对于复杂的 TCP 协议栈上的七层应用很少,市面上已出现了部分用户态协议栈,如 mTCP、Mirage、lwIP、NUSE 等,也有用户态的编程框架,如 SeaStar 等,但统一的特点是应用程序接入门槛较高,不易于使用。
F-Stack 使用纯 C 实现,充当胶水粘合了 DPDK、FreeBSD 用户态协议栈、Posix API、微线程框架和上层应用(Nginx、Redis),使绝大部分的网络应用可以通过直接修改配置或替换系统的网络接口即可接入 F-Stack,从而获得更高的网络性能。
F-Stack 架构

F-Stack 总体架构如上图所示,具有以下特点:
- 使用多进程无共享架构。
- 各进程绑定独立的网卡队列和 CPU,请求通过设置网卡 RSS 散落到各进程进行处理。
- 各进程拥有独立的协议栈、PCB 表等资源。
- 每个 NUMA 节点使用独立的内存池。
- 进程间通信通过无锁环形队列(rte_ring)进行。
- 使用 DPDK 作为网络 I/O 模块,将数据包从网卡直接接收到用户态。
- 移植 FreeBSD Release 11.0.1 协议栈到用户态并与 DPDK 对接。
http://www.f-stack.org
Nginx :
一个高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。
http://nginx.org/
Redis :
一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型。
https://redis.io/
Fasthttp :
Fasthttp是一个高性能的web server框架。Golang官方的net/http性能相比fasthttp逊色很多。根据测试,fasthttp的性能可以达到net/http的10倍。所以,在一些高并发的项目中,我们经常用fasthttp来代替net/http。
https://github.com/savsgio/atreugo
Oat++:
oat++ 是一个轻量级高性能 Web 服务开发框架,采用纯 C++ 编写而成。
https://gitee.com/mirrors/oatpp
Undertow,jetty,Tomcat等:
java语言的高并发框架。
https://undertow.io/
https://gitee.com/mirrors/jetty
https://tomcat.apache.org/
性能测试对比(排行榜):
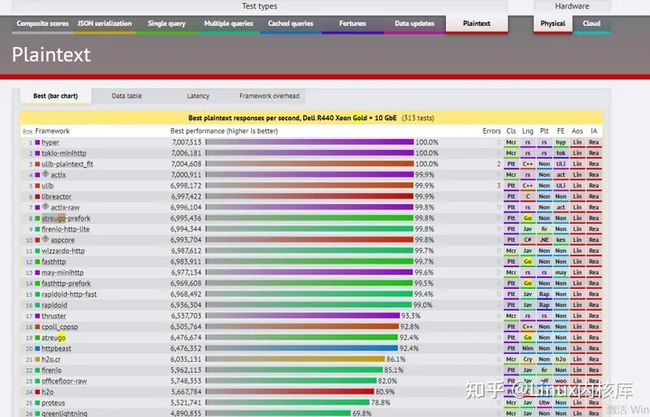
https://www.techempower.com/benchmarks/
有兴趣同学可以试一试你的极限优化,让你们的程序上榜!这个是简历和项目推荐里面的最有力的说明。
原文作者:极客星球
