07 | @Entity 之间的关联关系注解如何正确使用?
实体与实体之间的关联关系一共分为四种,分别为 OneToOne、OneToMany、ManyToOne 和 ManyToMany;而实体之间的关联关系又分为双向的和单向的。实体之间的关联关系是在 JPA 使用中最容易发生问题的地方,接下来我将一一揭晓并解释。我们先看一下 OneToOne,即一对一的关联关系。
@OneToOne 关联关系
@OneToOne 一般表示对象之间一对一的关联关系,它可以放在 field 上面,也可以放在 get/set 方法上面。其中 JPA 协议有规定,如果是配置双向关联,维护关联关系的是拥有外键的一方,而另一方必须配置 mappedBy;如果是单项关联,直接配置在拥有外键的一方即可。
举个例子:user 表是用户的主信息,user_info 是用户的扩展信息,两者之间是一对一的关系。user_info 表里面有一个 user_id 作为关联关系的外键,如果是单项关联,我们的写法如下:
复制代码
package com.example.jpa.example1;
import lombok.AllArgsConstructor;
import lombok.Builder;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
private String sex;
private String address;
}
User 实体里面什么都没变化,不需要添加 @OneToOne 注解。我们只需要在拥有外键的一方配置就可以,所以 UserInfo 的代码如下:
复制代码
package com.example.jpa.example1;
import lombok.*;
import javax.persistence.*;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "user")
public class UserInfo {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private Integer ages;
private String telephone;
@OneToOne //维护user的外键关联关系,配置一对一
private User user;
}
我们看到,UserInfo 实体对象里面添加了 @OneToOne 注解,这时我们写一个测试用例跑一下看看有什么效果:
复制代码
Hibernate: create table user (id bigint not null, address varchar(255), email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: create table user_info (id bigint not null, ages integer, telephone varchar(255), user_id bigint, primary key (id))
Hibernate: alter table user_info add constraint FKn8pl63y4abe7n0ls6topbqjh2 foreign key (user_id) references user
因为我们新建了两个实体,跑任何一个 @SpringDataTest 就会看到上面有三个 sql 在执行,分别创建了两张表,而在 user_info 表上面还创建了一个外键索引。
上面我们说了单项关联关系,那么双向关联应该怎么配置呢?我们保持 UserInfo 不变,在 User 实体对象里面添加这一段代码即可。
复制代码
@OneToOne(mappedBy = "user")
private UserInfo userInfo;
完整的 User 实体对象就会变成如下模样。
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
@OneToOne(mappedBy = "user")
private UserInfo userInfo;//变化之处
private String sex;
private String address;
}
我们跑任何一个测试用例,就会看到运行结果是一样的,还是上面三条 sql。那么我们再查看一下 @OneToOne 源码,看看其支持的配置都有哪些。
@interface OneToOne 源码解读
下面我列举了@OneToOne 的源码,并加以解读。通过这些你可以了解 @OneToOne 的用法。
复制代码
public @interface OneToOne {
//表示关系目标实体,默认该注解标识的返回值的类型的类。
Class targetEntity() default void.class;
//cascade 级联操作策略,就是我们常说的级联操作
CascadeType[] cascade() default {};
//数据获取方式EAGER(立即加载)/LAZY(延迟加载)
FetchType fetch() default EAGER;
//是否允许为空,默认是可选的,也就表示可以为空;
boolean optional() default true;
//关联关系被谁维护的一方对象里面的属性名字。 双向关联的时候必填
String mappedBy() default "";
//当被标识的字段发生删除或者置空操作之后,是否同步到关联关系的一方,即进行通过删除操作,默认flase,注意与CascadeType.REMOVE 级联删除的区别
boolean orphanRemoval() default false;
}
mappedBy 注意事项
只有关联关系的维护方才能操作两个实体之间外键的关系。被维护方即使设置了维护方属性进行存储也不会更新外键关联。
mappedBy 不能与 @JoinColumn 或者 @JoinTable 同时使用,因为没有意义,关联关系不在这里面维护。
此外,mappedBy 的值是指另一方的实体里面属性的字段,而不是数据库字段,也不是实体的对象的名字。也就是维护关联关系的一方属性字段名称,或者加了 @JoinColumn / @JoinTable 注解的属性字段名称。如上面的 User 例子 user 里面 mappedBy 的值,就是 UserInfo 里面的 user 字段的名字。
CascadeType用法
在 CascadeType 的用法中,CascadeType 的枚举值只有五个,分别如下:
- CascadeType.PERSIST 级联新建
- CascadeType.REMOVE 级联删除
- CascadeType.REFRESH 级联刷新
- CascadeType.MERGE 级联更新
- CascadeType.ALL 四项全选
其中,默认是没有级联操作的,关系表不会产生任何影响。此外,JPA 2.0 还新增了 CascadeType.DETACH,即级联实体到 Detach 状态。
了解了枚举值,下面我们来测试一下级联新建和级联删除。
首先,修改 UserInfo 里面的关键代码如下,并在 @OneToOne 上面添加
cascade ={CascadeType.PERSIST,CascadeType.REMOVE},如下:
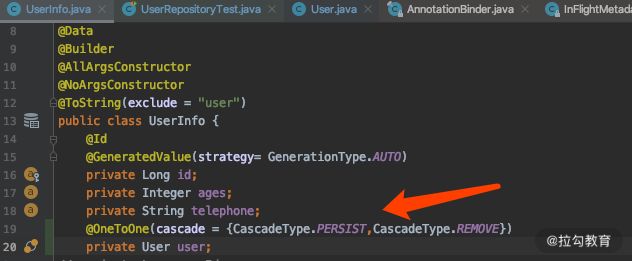
其次,我们新增一个测试方法。
复制代码
@Test
@Rollback(false)
public void testUserRelationships() throws JsonProcessingException {
User user = User.builder().name("jackxx").email("[email protected]").build();
UserInfo userInfo = UserInfo.builder().ages(12).user(user).telephone("12345678").build();
//保存userInfo的同上也会保存User信息
userInfoRepository.saveAndFlush(userInfo);
//删除userInfo,同时也会级联的删除user记录
userInfoRepository.delete(userInfo);
}
最后,运行一下看看效果。
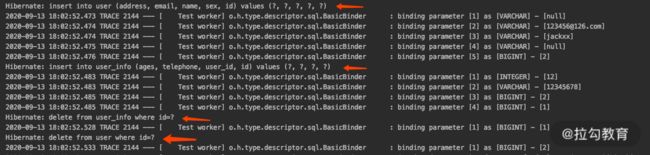
从上面的运行结果可以看到,上面的测试在执行了 insert 的时候,会执行两条 insert 的sql 和两条 delete 的 sql,这就体现出了 CascadeType.PERSIST 和 CascadeType.REMOVE 的作用。
上面讲了级联删除的场景,下面我们再说一下关联关系的删除场景该怎么做。
orphanRemoval 属性用法
orphanRemoval 表示当关联关系被删除的时候,是否应用级联删除,默认 false。什么意思呢?测试一下你就会明白。
首先,还沿用上面的例子,当我们删除 userInfo 的时候,把 User 置空,作如下改动。
复制代码
userInfo.setUser(null);
userInfoRepository.delete(userInfo);
其次,我们再运行测试,看看效果。
复制代码
Hibernate: delete from user_info where id=?
这时候你就会发现,少了一条删除 user 的 sql,说明没有进行级联删除。那我们再把 UserInfo 做一下调整。
复制代码
public class UserInfo {
@OneToOne(cascade = {CascadeType.PERSIST},orphanRemoval = true)
private User user;
....其他没变的代码省了
}
然后,我们把 CascadeType.Remove 删除了,不让它进行级联删除,但是我们把 orphanRemoval 设置成 true,即当关联关系变化的时候级联更新。我们看下完整的测试用例。
复制代码
@Test
public void testUserRelationships() throws JsonProcessingException {
User user = User.builder().name("jackxx").email("[email protected]").build();
UserInfo userInfo = UserInfo.builder().ages(12).user(user).telephone("12345678").build();
userInfoRepository.saveAndFlush(userInfo);
userInfo.setAges(13);
userInfo.setUser(null);//还是通过这个设置user数据为空
userInfoRepository.delete(userInfo);
}
这个时候我们看一下运行结果。

从中我们可以看到,结果依然是两个 inser 和两个 delete,但是中间多了一个 update。我来解释一下,因为去掉了 CascadeType.REMOVE,这个时候不会进行级联删除了。当我们把 user 对象更新成空的时候,就会执行一条 update 语句把关联关系去掉了。
而为什么又出现了级联删除 user 呢?因为我们修改了集合关联关系,orphanRemoval 设置为 true,所以又执行了级联删除的操作。这一点你可以仔细体会一下 orphanRemoval 和 CascadeType.REMOVE 的区别。
到这里,@OneToOne 关联关系介绍完了,接下来我们看一下日常工作常见的场景,先看场景一:主键和外键都是同一个字段的情况。
主键和外键都是同一个字段
我们假设 user 表是主表,user_info 的主键是 user_id,并且 user_id=user 是表里面的 id,那我们应该怎么写?
继续沿用上面的例子,User 实体不变,我们看看 UserInfo 变成什么样了。
复制代码
public class UserInfo implements Serializable {
@Id
private Long userId;
private Integer ages;
private String telephone;
@MapsId
@OneToOne(cascade = {CascadeType.PERSIST},orphanRemoval = true)
private User user;
}
这里的做法很简单,我们直接把 userId 设置为主键,在 @OneToOne 上面添加 @MapsId 注解即可。@MapsId 注解的作用是把关联关系实体里面的 ID(默认)值 copy 到 @MapsId 标注的字段上面(这里指的是 user_id 字段)。
接着,上面的测试用例我们跑一下,看一下效果。
复制代码
Hibernate: create table user (id bigint not null, address varchar(255), email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: create table user_info (ages integer, telephone varchar(255), user_id bigint not null, primary key (user_id))
Hibernate: alter table user_info add constraint FKn8pl63y4abe7n0ls6topbqjh2 foreign key (user_id) references user
在启动的时候,我们直接创建了 user 表和 user_info 表,其中 user_info 的主键是 user_id,并且通过外键关联到了 user 表的 ID 字段,那么我们同时看一下 inser 的 sql,也发生了变化。
复制代码
Hibernate: insert into user (address, email, name, sex, id) values (?, ?, ?, ?, ?)
Hibernate: insert into user_info (ages, telephone, user_id) values (?, ?, ?)
上面就是我们讲的实战场景一,主键和外键都是同一个字段。接下来我们再说一个场景,就是在查 user_info 的时候,我们只想知道 user_id 的值就行了,不需要查 user 的其他信息,具体我们应该怎么做呢?
@OneToOne 延迟加载,我们只需要 ID 值
在 @OneToOne 延迟加载的情况下,我们假设只想查下 user_id,而不想查看 user 表其他的信息,因为当前用不到,可以有以下几种做法。
第一种做法:还是 User 实体不变,我们改一下 UserInfo 对象,如下所示:
复制代码
package com.example.jpa.example1;
import lombok.*;
import javax.persistence.*;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "user")
public class UserInfo{
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private Integer ages;
private String telephone;
@MapsId
@OneToOne(cascade = {CascadeType.PERSIST},orphanRemoval = true,fetch = FetchType.LAZY)
private User user;
}
从上面这段代码中,可以看到做的更改如下:
- id 字段我们先用原来的
- @OneToOne 上面我们添加 @MapsId 注解
- @OneToOne 里面的 fetch = FetchType.LAZY 设置延迟加载
接着,我们改造一下测试类,完整代码如下:
复制代码
@DataJpaTest
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class UserInfoRepositoryTest {
@Autowired
private UserInfoRepository userInfoRepository;
@BeforeAll
@Rollback(false)
@Transactional
void init() {
User user = User.builder().name("jackxx").email("[email protected]").build();
UserInfo userInfo = UserInfo.builder().ages(12).user(user).telephone("12345678").build();
userInfoRepository.saveAndFlush(userInfo);
}
/**
* 测试用User关联关系操作
*
* @throws JsonProcessingException
*/
@Test
@Rollback(false)
public void testUserRelationships() throws JsonProcessingException {
UserInfo userInfo1 = userInfoRepository.getOne(1L);
System.out.println(userInfo1);
System.out.println(userInfo1.getUser().getId());
}
然后,我们跑一下测试用例,看看测试结果。
复制代码
Hibernate: insert into user (address, email, name, sex, id) values (?, ?, ?, ?, ?)
Hibernate: insert into user (address, email, name, sex, id) values (?, ?, ?, ?, ?)
两条inser照旧,而只有一个select
Hibernate: select userinfo0_.user_id as user_id3_6_0_, userinfo0_.ages as ages1_6_0_, userinfo0_.telephone as telephon2_6_0_ from user_info userinfo0_ where userinfo0_.user_id=?
最后你会发现,打印的结果符合预期。
复制代码
UserInfo(id=1, ages=12, telephone=12345678)
1
接下来介绍第二种做法,这种做法很简单,只要在 UserInfo 对象里面直接去掉 @OneToOne 关联关系,新增下面的字段即可。
复制代码
@Column(name = "user_id")
private Long userId;
第三做法是利用 Hibernate,它给我们提供了一种字节码增强技术,通过编译器改变 class 解决了延迟加载问题。这种方式有点复杂,需要在编译器引入 hibernateEnhance 的相关 jar 包,以及编译器需要改变 class 文件并添加 lazy 代理来解决延迟加载。我不太推荐这种方式,因为太复杂,你知道有这回事就行了。
以上我们掌握了这么多用法,那么最佳实践是什么?双向关联更好还是单向关联更好?根据最近几年的应用,我总结出了一些最佳实践,我们来看一下。
@OneToOne 的最佳实践是什么?
第一,我要说一种 Java 面向对象的设计原则:开闭原则。
即对扩展开放,对修改关闭。如果我们一直使用双向关联,两个实体的对象耦合太严重了。想象一下,随着业务的发展,User 对象可能是原始对象,围绕着 User 可能会扩展出各种关联对象。难道 User 里面每次都要修改,去添加双向关联关系吗?肯定不是,否则时间长了,对象与对象之间的关联关系就是一团乱麻。
所以,我们尽量、甚至不要用双向关联,如果非要用关联关系的话,只用单向关联就够了。双向关联正是 JPA 的强大之处,但同时也是问题最多,最被人诟病之处。所以我们要用它的优点,而不是学会了就一定要使用。
第二,我想说 CascadeType 很强大,但是我也建议保持默认。
即没有级联更新动作,没有级联删除动作。还有 orphanRemoval 也要尽量保持默认 false,不做级联删除。因为这两个功能很强大,但是我个人觉得这违背了面向对象设计原则里面的“职责单一原则”,除非你非常非常熟悉,否则你在用的时候会时常感到惊讶——数据什么时间被更新了?数据被谁删除了?遇到这种问题查起来非常麻烦,因为是框架处理,有的时候并非预期的效果。
一旦生产数据被莫名更新或者删除,那是一件非常糟糕的事情。因为这些级联操作会使你的方法名字没办法命名,而且它不是跟着业务逻辑变化的,而是跟着实体变化的,这就会使方法和对象的职责不单一。
第三,我想告诉你,所有用到关联关系的地方,能用 Lazy 的绝对不要用 EAGER,否则会有 SQL 性能问题,会出现不是预期的 SQL。
以上三点是我总结的避坑指南,有经验的同学这时候会有个疑问:外键约束不是不推荐使用的吗?如果我的外键字段名不是约定的怎么办?别着急,我们再看一下 @JoinColumn 注解和 @JoinColumns 注解。
@JoinCloumns & JoinColumn
这两个注解是集合关系,他们可以同时使用,@JoinColumn 表示单字段,@JoinCloumns 表示多个 @JoinColumn,我们来一一看一下。
我们还是先直接看一下 @JoinColumn 源码,了解下这一注解都有哪些配置项。
复制代码
public @interface JoinColumn {
//关键的字段名,默认注解上的字段名,在@OneToOne代表本表的外键字段名字;
String name() default "";
//与name相反关联对象的字段,默认主键字段
String referencedColumnName() default "";
//外键字段是否唯一
boolean unique() default false;
//外键字段是否允许为空
boolean nullable() default true;
//是否跟随一起新增
boolean insertable() default true;
//是否跟随一起更新
boolean updatable() default true;
//JPA2.1新增,外键策略
ForeignKey foreignKey() default @ForeignKey(PROVIDER_DEFAULT);
}
其次,我们看一下 @ForeignKey(PROVIDER_DEFAULT) 里面枚举值有几个。
复制代码
public enum ConstraintMode {
//创建外键约束
CONSTRAINT,
//不创建外键约束
NO_CONSTRAINT,
//采用默认行为
PROVIDER_DEFAULT
}
然后,我们看看这个注解的语法,就可以解答我们上面的两个问题。修改一下 UserInfo,如下所示:
复制代码
public class UserInfo{
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private Integer ages;
private String telephone;
@OneToOne(cascade = {CascadeType.PERSIST},orphanRemoval = true,fetch = FetchType.LAZY)
@JoinColumn(foreignKey = @ForeignKey(ConstraintMode.NO_CONSTRAINT),name = "my_user_id")
private User user;
...其他不变}
可以看到,我们在其中指定了字段的名字:my_user_id,并且指定 NO_CONSTRAINT 不生成外键。而测试用例不变,我们看下运行结果。
复制代码
Hibernate: create table user (id bigint not null, address varchar(255), email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: create table user_info (id bigint not null, ages integer, telephone varchar(255), my_user_id bigint, primary key (id))
这时我们看到 user_info 表里面新增了一个字段 my_user_id,insert 的时候也能正确 inser my_user_id 的值等于 user.id。
复制代码
Hibernate: insert into user_info (ages, telephone, my_user_id, id) values (?, ?, ?, ?)
而 @JoinColumns 是 JoinColumns 的复数形式,就是通过两个字段进行的外键关联,这个不常用,我们看一个 demo 了解一下就好。
复制代码
@Entity
public class CompanyOffice {
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumns({
@JoinColumn(name="ADDR_ID", referencedColumnName="ID"),
@JoinColumn(name="ADDR_ZIP", referencedColumnName="ZIP")
})
private Address address;
}
上面的实例中,CompanyOffice 通过 ADDR_ID 和 ADDR_ZIP 两个字段对应一条 address 信息,解释了一下@JoinColumns的用法。
如果你了解了 @OneToOne 的详细用法,后面要讲的几个注解就很好理解了,因为他们有点类似,那么我们接下来看看 @ManyToOne 和 @OneToMany 的用法。
@ManyToOne& @OneToMany
@ManyToOne 代表多对一的关联关系,而 @OneToMany 代表一对多,一般两个成对使用表示双向关联关系。而 JPA 协议中也是明确规定:维护关联关系的是拥有外键的一方,而另一方必须配置 mappedBy。看下面的代码。
复制代码
public @interface ManyToOne {
Class targetEntity() default void.class;
CascadeType[] cascade() default {};
FetchType fetch() default EAGER;
boolean optional() default true;
}
public @interface OneToMany {
Class targetEntity() default void.class;
//cascade 级联操作策略:(CascadeType.PERSIST、CascadeType.REMOVE、CascadeType.REFRESH、CascadeType.MERGE、CascadeType.ALL)
如果不填,默认关系表不会产生任何影响。
CascadeType[] cascade() default {};
//数据获取方式EAGER(立即加载)/LAZY(延迟加载)
FetchType fetch() default LAZY;
//关系被谁维护,单项的。注意:只有关系维护方才能操作两者的关系。
String mappedBy() default "";
//是否级联删除。和CascadeType.REMOVE的效果一样。两种配置了一个就会自动级联删除
boolean orphanRemoval() default false;
}
我们看到上面的字段和 @OneToOne 里面的基本一样,用法是一样的,不过需要注意以下几点:
- @ManyToOne 一定是维护外键关系的一方,所以没有 mappedBy 字段;
- @ManyToOne 删除的时候一定不能把 One 的一方删除了,所以也没有 orphanRemoval 的选项;
- @ManyToOne 的 Lazy 效果和 @OneToOne 的一样,所以和上面的用法基本一致;
- @OneToMany 的 Lazy 是有效果的。
我们看个例子,假设 User 有多个地址 Address,我们看看实体应该如何建立。
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
private String email;
private String sex;
@OneToMany(mappedBy = "user",fetch = FetchType.LAZY)
private List address;
}
上述代码我们可以看到,@OneToMany 双向关联并且采用 LAZY 的机制;这时我们新建一个 UserAddress 实体维护关联关系如下:
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "user")
public class UserAddress {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String address;
@ManyToOne(cascade = CascadeType.ALL)
private User user;
}
再新建一个测试用例,完整代码如下:
复制代码
package com.example.jpa.example1;
import com.fasterxml.jackson.core.JsonProcessingException;
import org.assertj.core.util.Lists;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.TestInstance;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import org.springframework.test.annotation.Rollback;
import javax.transaction.Transactional;
@DataJpaTest
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class UserAddressRepositoryTest {
@Autowired
private UserAddressRepository userAddressRepository;
@Autowired
private UserRepository userRepository;
/**
* 负责添加数据
*/
@BeforeAll
@Rollback(false)
@Transactional
void init() {
User user = User.builder().name("jackxx").email("[email protected]").build();
UserAddress userAddress = UserAddress.builder().address("shanghai1").user(user).build();
UserAddress userAddress2 = UserAddress.builder().address("shanghai2").user(user).build();
userAddressRepository.saveAll(Lists.newArrayList(userAddress,userAddress2));
}
/**
* 测试用User关联关系操作
* @throws JsonProcessingException
*/
@Test
@Rollback(false)
public void testUserRelationships() throws JsonProcessingException {
User user = userRepository.getOne(2L);
System.out.println(user.getName());
System.out.println(user.getAddress());
}
}
然后,我们看一下运行结果。
复制代码
Hibernate: create table user (id bigint not null, email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: create table user_address (id bigint not null, address varchar(255), user_id bigint, primary key (id))
Hibernate: alter table user_address add constraint FKk2ox3w9jm7yd6v1m5f68xibry foreign key (user_id) references user
接着我们创建两张表,并且创建外键。
复制代码
Hibernate: insert into user (email, name, sex, id) values (?, ?, ?, ?)
Hibernate: insert into user_address (address, user_id, id) values (?, ?, ?)
Hibernate: insert into user_address (address, user_id, id) values (?, ?, ?)
这时我们得到了符合预期的三条 inser 语句,可以看到 lazy 起作用了,说明了只有用到 address 的时候才会取重新加载 SQL。

综上,@ManyToOne 的 lazy 机制和用法,与 @OneToOne 的一样,我们就不过多介绍了。而 @ManyToOne 和 @OneToMany 的最佳实践,与 @OneToOne 的完全一样,也是尽量避免双向关联,一切级联更新和 orphanRemoval 都保持默认规则,并且 fetch 采用 lazy 延迟加载。
以上就是关于 @ManyToOne 和 @OneToMan 的讲解,实际开发过程中可以详细体会一下上面老师讲的用法。接下来我们介绍一下 @ManyToMany 多对多关联关系的用法。
@ManyToMany
@ManyToMany 代表多对多的关联关系,这种关联关系任何一方都可以维护关联关系。我们还是先看个例子感受一下。
我们假设 user 表和 room 表是多对多的关系,看看两个实体怎么写。
复制代码
package com.example.jpa.example1;
import lombok.*;
import javax.persistence.*;
import java.io.Serializable;
import java.util.List;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class User{
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
private String name;
@ManyToMany(mappedBy = "users")
private List rooms;
}
接着,我们让 Room 维护关联关系。
复制代码
package com.example.jpa.example1;
import lombok.*;
import javax.persistence.*;
import java.util.List;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "users")
public class Room {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String title;
@ManyToMany
private List users;
}
然后,我们跑一下测试用例,可以看到如下结果:
复制代码
Hibernate: create table room (id bigint not null, title varchar(255), primary key (id))
Hibernate: create table room_users (rooms_id bigint not null, users_id bigint not null)
Hibernate: create table user (id bigint not null, email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: alter table room_users add constraint FKld9phr4qt71ve3gnen43qxxb8 foreign key (users_id) references user
Hibernate: alter table room_users add constraint FKtjvf84yquud59juxileusukvk foreign key (rooms_id) references room
从结果上我们看到 JPA 帮我们创建的三张表中,room_users 表维护了 user 和 room 的多对多关联关系。其实这个情况还告诉我们一个道理:当用到 @ManyToMany 的时候一定是三张表,不要想着建两张表,两张表肯定是违背表的设计原则的。
那么我们看下 @ManyToMany 的语法。
复制代码
public @interface ManyToMany {
Class targetEntity() default void.class;
CascadeType[] cascade() default {};
FetchType fetch() default LAZY;
String mappedBy() default "";
}
源码里面字段就这么多,基本和上面雷同,我就不多介绍了。这个时候有的同学可能会问,我们怎么去掉外键索引?怎么改中间表的表名?怎么指定外键字段的名字呢?我们继续引入另外一个注解——@JoinTable。
我先看一下例子,修改一下 Room 里面的内容。
复制代码
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@ToString(exclude = "users")
public class Room {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String title;
@ManyToMany
@JoinTable(name = "user_room_ref",
joinColumns = @JoinColumn(name = "room_id_x"),
inverseJoinColumns = @JoinColumn(name = "user_id_x")
)
private List users;
}
接着,我们在 Room 里面添加了 @JoinTable 注解,看一下 junit 的运行结果。
复制代码
Hibernate: create table room (id bigint not null, title varchar(255), primary key (id))
Hibernate: create table user (id bigint not null, email varchar(255), name varchar(255), sex varchar(255), primary key (id))
Hibernate: create table user_room_ref (room_id_x bigint not null, user_id_x bigint not null)
Hibernate: alter table user_room_ref add constraint FKoxolr1eyfiu69o45jdb6xdule foreign key (user_id_x) references user
Hibernate: alter table user_room_ref add constraint FK2sl9rtuxo9w130d83e19f3dd9 foreign key (room_id_x) references room
到这里可以看到,我们创建了一张中间表,并且添加了两个在预想之内的外键关系。
复制代码
public @interface JoinTable {
//中间关联关系表明
String name() default "";
//表的catalog
String catalog() default "";
//表的schema
String schema() default "";
//维护关联关系一方的外键字段的名字
JoinColumn[] joinColumns() default {};
//另一方的表外键字段
JoinColumn[] inverseJoinColumns() default {};
//指定维护关联关系一方的外键创建规则
ForeignKey foreignKey() default @ForeignKey(PROVIDER_DEFAULT);
//指定另一方的外键创建规则
ForeignKey inverseForeignKey() default @Forei gnKey(PROVIDER_DEFAULT);
}
那么通过上面的介绍,你知道了 @ManyToMany 的用法,然而实际开发者对 @ManyToMany 用得比较少,一般我们会用成对的 @ManyToOne 和 @OneToMany 代替,因为我们的中间表可能还有一些约定的公共字段,如 ID、update_time、create_time等其他字段。
利用 @ManyToOne 和 @OneToMany 表达多对多的关联关系
我们修改一下上面的 Demo,来看一下通过 @ManyToOne 和 @OneToMany 如何表达多对多的关联关系。
我们新建一张表 user_room_relation 来存储双方的关联关系和额外字段,实体如下:
复制代码
package com.example.jpa.example1;
import lombok.*;
import javax.persistence.*;
import java.util.Date;
@Entity
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
public class UserRoomRelation {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private Date createTime,udpateTime;
@ManyToOne
private Room room;
@ManyToOne
private User user;
}
而 User 变化如下:
复制代码
public class User implements Serializable {
@Id
@GeneratedValue(strategy= GenerationType.AUTO)
private Long id;
@OneToMany(mappedBy = "user")
private List userRoomRelations;
....}
Room 变化如下:
public class Room {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@OneToMany(mappedBy = "room")
private List userRoomRelations;
...}
到这里我们再看一下 JUnit 运行结果。
复制代码
Hibernate: create table user_room_relation (id bigint not null, create_time timestamp, udpate_time timestamp, room_id bigint, user_id bigint, primary key (id))
Hibernate: create table room (id bigint not null, title varchar(255), primary key (id))
Hibernate: create table user (id bigint not null, email varchar(255), name varchar(255), sex varchar(255), primary key (id))
可以看到,上面我们依然创建了三张表,唯一不同的是 user_room_relation 里面多了很多字段,而外键索引也是如约创建,如下所示:
复制代码
Hibernate: alter table user_room_relation add constraint FKaesy2rg60vtaxxv73urprbuwb foreign key (room_id) references room
Hibernate: alter table user_room_relation add constraint FK45gha85x63026r8q8hs03uhwm foreign key (user_id) references user
好了,跑一下测试是不是就很容易理解了。下面我总结了关于 @ManyToMany 的最佳实践和你分享。
@ManyToMany 的最佳实践
- 上面我们介绍的 @OneToMany 的最佳实践同样适用,我为了说明方便,采用的是双向关联,而实际生产一般是在中间表对象里面做单向关联,这样会让实体之间的关联关系简单很多。
- 与 @OneToMany 一样的道理,不要用级联删除和 orphanRemoval=true。
- FetchType 采用默认方式:fetch = FetchType.LAZY 的方式。