Linux系统编程:makefile以及文件系统编程
增量编译概念
首先回顾一下我们之前写的各种gcc指令用来执行程序:

可以看见非常繁琐,两个文件就要写这么多,那要是成百上千岂不完蛋。
所以为了简化工作量,很自然的想到了将这些命令放在一起使用脚本文件来一键执行,每回要编译运行就调用这个脚本文件把这些命令从头到尾执行一遍即可。
但有问题,这个脚本文件是按顺序执行的,有一种可能是main.c和add.c是两个人写的,如果一个文件更改了另外一个没有,但是执行脚本的时候依然会将没有修改过的代码重复编译,这会浪费大量的时间,而对于企业里的编译,动辄都是几十个小时起步,所以这个时间是必须要减少的。
我们力求没有改动的代码文件就不要浪费时间去编译了,这就叫做增量编译。
makefile工程项目管理器
makefile原理
为了实现具有增量编译这种特性的脚本文件,makefile应运而生。
那么makefile是怎么实现增量编译生成代码的呢?
makefile依靠“目标-依赖”这种关系去管理程序编译运行的各个文件之间的关系,因为其实仔细看如上图所示每个最终程序的可执行文件都是由若干个子文件编译而来,组成的关系就很像一种树形结构,那么我们就可以通过对比如文件更新时间的早晚或者其它的什么特性来决定该文件是不是应该再次被编译,这就是makefile的工作原理。
makefile实现
首先,makefile的名字必须是Makefile或者makefile,不能是其它名字。
其次,makefile本质是一种规则的集合,目标文件只能有一个,而依赖文件可以有0到多个,即“目标——依赖”关系。那么我们就必须要写清楚从某一个依赖到达某一个目标文件之间需要通过什么命令达到,每个命令之前必须要用一个
举例:如上图中main就是目标文件,而add.o和main.o就是依赖文件;而对于add.o文件和add.c文件来说,add.o就是目标文件,而add.c就是依赖文件,很明显从add.c到达add.o要通过gcc -c的命令到达,这个就必须要在脚本文件里写清楚。
但是命令很多从哪儿开始写?
首先,把最终生成的文件作为第一个规则的目标。
其它的随便写都一样。
makefile实战
还是我们之前的老代码:
main.c:
#include add.c:
1 int add(int lhs,int rhs){
2 return lhs + rhs;
3 }
现在这两个文件都有了,来写一个makefile文件:
1 main:main.o add.o
2 gcc main.o add.o -o main
3 main.o:main.c
4 gcc -c main.c -o main.o
5 add.o:add.c
6 gcc -c add.c -o add.o
对makefile文件编写的语法要求说明:
首先肯定是写最终要生成的可执行程序作为第一个规则的目标,本例中是main,所以main:main.o add.o
冒号表示目标文件与依赖文件之间的关系,中间没有空格,依赖文件是用来编译生成main的,所以由main.o 和 add.o
然后空一个tab键的长度,写上对应的依赖与目标之间对应的编译命令。
剩下的以此类推,除了第一个目标规则,剩下的文件顺序都是随便写,谁先谁后都无所谓。
现在我们执行编译程序,就不用再写那么多命令,只要当前目录存在这么一个makefile文件,我们就直接输入make就可以完成编译:


可以看见程序正确执行。
我们再次make:

是不是符合我们之前说的,因为并没有更新依赖的子文件,比如main.c和main.o之间是有依赖关系的,但是因为main.o是由main.c编译过来的,所以肯定是main.o更新一些,目标文件比依赖文件更新所以这里并没有再次编译(add.c与add.o同理)。
那如果我们改一下add.c的文件修改时间呢?用touch命令摸一下它就会触发该文件的时间更新,此时我们再来make一下:

从上图可以看到,因为我们更新了add.c文件,这意味着add.c比目标文件add.o更新,所以这里触发编译,而编译后的add.o比main更新,所以这里一样要触发编译,而main.c和main.o以及main三者之间并未触发编译,这就实现了我们的增量编译要求。
make命令后面可跟参数
make后面可以跟参数,为一个文件名,不写的话make默认会以最终的目标文件作为最终生成的终点,要写的话则可以指定以其它文件作为根从而进行操作,以上面的例子为例的话:

以main.o为参数名的话就表示从mian.o开始进行操作,观察各个文件之间的编译顺序很自然只会执行该一条命令语句。
伪目标
我们之前说的形式都是:目标:依赖
命令
这里要提一个完全不同的概念,即一种目标并不存在也就是执行命令生成不了目标的这么一种机制,称为伪目标。
伪目标的作用是用来实现每次make都一定会执行的指令。
举个例子:
1 main:main.o add.o
2 gcc main.o add.o -o main
3 main.o:main.c
4 gcc -c main.c -o main.o
5 add.o:add.c
6 gcc -c add.c -o add.o
7 clean:
8 rm -f main.o add.o main
这里要注意,clean并不包含在最终生成的程序main的编译体系中,所以执行make的时候clean并不影响main的生成,相当于现在makefile里面有两棵树组成了一个森林嘛。
因为我们现在的文件系统中并不存在clean这个文件,所以执行make clean的时候一定会去生成该clean文件,生成它时就会执行下面的rm的命令,但是执行完是肯定没有clean文件生成的(依赖文件都没有咋生成,而且它下面的命令也和它一毛钱关系都没有),所以每一次执行相当于clean文件都处于待生成的状态,也就是永远都是最新的状态,那么其对应下面的命令就会每一次make clean都执行:

其作用就是如果我们有希望每一次make的时候都执行的命令的时候,就把它弄成一个伪目标就行。
注意伪目标的前提是该文件在当前文件系统中不能存在嗷!
如果我们当前的文件系统中有了clean:

那clean目标就丧失了伪目标的特性了。
伪目标的代码风格
像我们刚刚写的makefile可读性是很差的,因为光看代码我们根本分不清哪些是伪目标哪些是目标,所以我们用.PHONEY的方法来说明哪些目标是伪目标,该方法的作用和注释差不多,对我们的代码完全不影响,只是用来提高可读性:
1 main:main.o add.o
2 gcc main.o add.o -o main
3 main.o:main.c
4 gcc -c main.c -o main.o
5 add.o:add.c
6 gcc -c add.c -o add.o
7.PHONY:clean
8 clean:
9 rm -f main.o add.o main
上面的代码就告诉了我们clean是伪目标。
变量(了解)



通配符和模式匹配(了解)

内置函数(了解)

循环(了解)

杂项(了解)

第二种makefile写法(单独编译链接)
这种makefile的写法就是当我们要编译的若干文件并非像之前的各个文件之间的“目标-依赖”关系那么强,都是可以或者说需要分开编译链接的,这种时候我们也可以写makefile来执行,比如下面这种情况三个文件各自都有main函数,也就是说各自都是独立的程序:

我们来试一下,首先是1.c文件如下:
1#include <stdio.h>
2
3 int main(){
4 puts("1\n");
5 }
2.c和3.c内容差不多,只不过另外两个各自输出2和3。
这是三个不一样的程序,没有一个共同的目标,那么怎么写makefile?
肯定还是会用伪目标啊!
所以makefile如下:
1 all:1 2 3
2 1:1.c
3 gcc 1.c -o 1
4 2:2.c
5 gcc 2.c -o 2
6 3:3.c
7 gcc 3.c -o 3
但这样的拓展性不是很好,耦合性太高,我们可以用之前学的那些知识把它打造成更加通用的方式。
1 SRCS:=$(wildcard *.c)
2 EXES:=$(patsubst %.c,%,$(SRCS))
3 all:$(EXES)
4 %:%.c
5 gcc $^ -o $@

一样是一键执行。
makefile总结
首先最重要的就是变量之前的所有内容,特别是要知道什么是增量编译,以及简单的makefile文件编写,后面的了解内容知道有这回事就行,如果用到了再去查就可以,公司里面一般会有专门的人写这个文件,一般我们开发都用不到。
Linux系统编程引论
为什么要学习文件系统编程
回顾我们之前学习过的Linux的系统架构图:
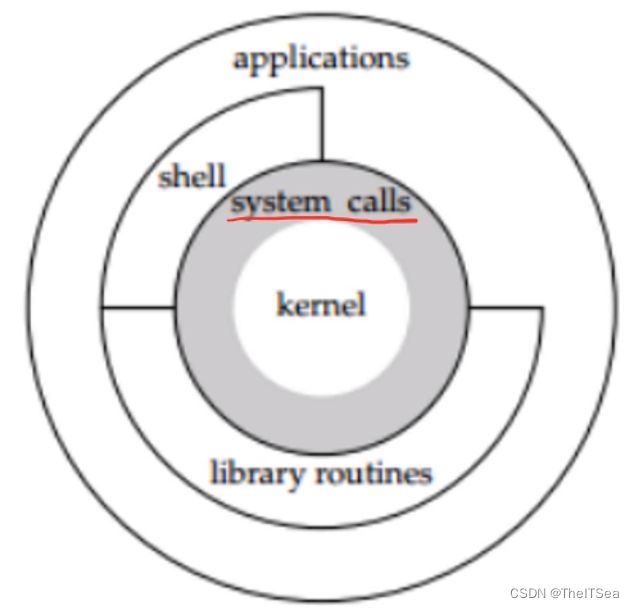
然后下图展示了我们使用的库函数和我们即将要学的系统调用之间的关系:

可以看到我们平常使用的库函数都是建立在系统调用的封装之上的,也就是使用库函数如printf的时候底层还要再去调用OS的系统调用,这显然是要浪费掉一些性能优势的,所以我们学习系统编程就是要学会如何跳过库函数直接去调用底层的系统调用来完成我们的程序。
如何学习系统编程
阅读man手册是最具权威的学习,因为man手册不会骗你,用man man打开其详细介绍:

可以看见我们之前学的命令都是位于man(1)分区的,也就是些shell的基本指令。
现在我们要学的系统调用System calls是位于man(2)分区的。
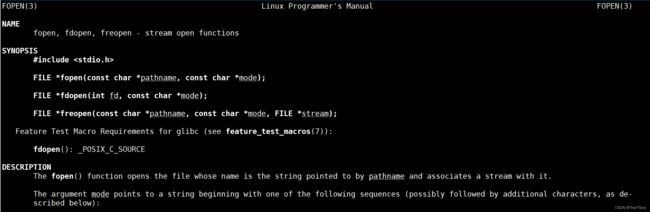
阅读每一个系统调用man手册的时候,基本都有如下格式,以printf函数为例,因为printf是库函数所以位于man分区3中,用man 3 printf命令打开:

基本每个手册都有如下几个部分:
名字、声明、细节、返回值。
阅读方法:
1、首先阅读名字
2、看声明和返回值,特别注意要看一下该函数位于哪个头文件中,还有指针类型的参数(看清楚有没有const)以及指针类型的返回值。
对于指针类型的参数,我们要注意的点除了有无const修饰还要注意调用该函数时其参数的内存空间是由主调函数分配的(显然是这样的,假如main调用该函数那main函数里面肯定要定义声明该变量传入到该函数的参数列表中)。
而对于指针类型的返回值的话,我们就要注意一下主调函数是不是要去释放掉该指针所指向的内存。
比如上面的fopen系统调用,就会返回一个FILE* 类型的指针,我们显然要在调用了该函数的函数里面进行释放掉该指针所指向的内存。
传入参数也是能看到,const修饰表示传进去的参数不会被改变。

这就是学习每一个系统的调用接口的方式。
Linux系统文件编程
文件系统基本概念
狭义上:就是指存储在外部存储介质上的数据集合。
广义上:其实就是指读写速度慢、容量大且需要持久化存储的内容,这很符合Linux万物皆文件的说法。

fopen库函数
写代码前的一些准备工作
准备好一个文件夹,并将之前写的通用makefile文件放进来,这样就可以不用写冗长的编译命令了:

然后写一个fopen.c:
1 #include<stdio.h>
2 int main(int argc,char* argv[]){
3 //因为使用命令行参数的话
4 //我们想要实现直接输入./fopen file1就运行程序
5 //那么我们肯定需要两个参数即可
6 if(argc != 2){
7 fprintf(stderr,"args error\n");
8 return -1;
9 }
10 }
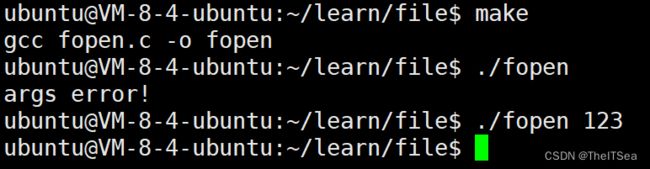
测试,先make编译再输入参数,参数值会直接传入到main函数的参数列表中:

可以看见测试结果是如果参数的数量不为2就会报参数错误。
但是有一个问题,封装性不够,因为这样在程序里面写判断代码,那我们以后的其它程序也同样需要判断是否是两个参数的时候就还得写一次或者判断过程,封装性不够,除了封装成一个函数的方法外,我们还可以使用带参数的宏定义来完成这个事情。
即然是宏定义,那我们就放到头文件中,我们cd到/usr/include/,这是我们的系统搜索目录,只要我们的#include后面跟的是尖括号比如
在该文件中写上我们程序需要的头文件,那我们的fopen.c文件的头文件就只需要包含我们的43func.h即可,因为fopen.c所需要的头文件都被我们写在了43func.h里面了嘛:
43func.h文件中的内容:
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4
5 #define ARGS_CHECK(argc,num) {if(argc != num){fprintf(stderr,"args error!\n"); return -1;}}
原来fopen.c中的内容:
1 #include<43func.h>
2 int main(int argc,char* argv[]){
3 //因为使用命令行参数的话
4 //我们想要实现直接输入./fopen file1就运行程序
5 //那么我们肯定需要两个参数即可
6 ARGS_CHECK(argc,2);
7 }
编译测试,效果一模一样:
那现在我们继续写fopen.c文件,此时如果参数检查正确的话,我们就打开使用fopen库函数去打开一个文件,打开完之后肯定要立马检查是否打开成功,这个检查打开文件是否成功一样是每个程序都会使用的内容,所以我们继续用刚刚的方式将它定义成带参数的宏定义:
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4
5 #define ARGS_CHECK(argc,num) {if(argc != num){fprintf(stderr,"args error!\n"); return -1;}}
6 #define ERROR_CHECK(ret,num,msg){if(ret == num){perror(msg); return -1;}}
那我们的fopen.c文件就可以改写如下:
1 #include<43func.h>
2 int main(int argc,char* argv[]){
3 //因为使用命令行参数的话
4 //我们想要实现直接输入./fopen file1就运行程序
5 //那么我们肯定需要两个参数即可
6 ARGS_CHECK(argc,2);
7 FILE* fp = fopen(argv[1],"r");//以只读方式打开
8 ERROR_CHECK(fp,NULL,"fopen");//告诉是fopen函数这一步出了问题
9 fclose(fp);//关闭文件缓冲区
10 }
编译运行结果:

完全是我们要的效果。
准备工作就结束了。
fopen库函数追加模式
首先说明一下在文件缓冲区(或者说文件流)内部,其实应该有三个指针:

base指针指向文件内容开头,end指向末尾,而ptr指针作为读写指针用来标志读写位置,每次读写都自动后移。
"a"只写追加模式,只在文件末尾进行追加:
1 #include<43func.h>
2 int main(int argc,char* argv[]){
3 //因为使用命令行参数的话
4 //我们想要实现直接输入./fopen file1就运行程序
5 //那么我们肯定需要两个参数即可
6 ARGS_CHECK(argc,2);
7 FILE* fp = fopen(argv[1],"a");//以追加方式打开
8 ERROR_CHECK(fp,NULL,"fopen");//告诉是fopen函数这一步出了问题
9 fwrite("howareyou",1,9,fp); //往里面写入内容
10 fclose(fp);//关闭文件缓冲区
11 }
测试:

追加howareyou到文件底部。在文件流内部ptr现在已经移动到了文件尾部,只要继续往里面追加内容,那么ptr指针也会继续往后跳。
"a+"读写追加的方式追加读取文件:
1 #include<43func.h>
2 int main(int argc,char* argv[]){
3 //因为使用命令行参数的话
4 //我们想要实现直接输入./fopen file1就运行程序
5 //那么我们肯定需要两个参数即可
6 ARGS_CHECK(argc,2);
7 FILE* fp = fopen(argv[1],"a+");//以读写追加的方式打开
8 //如果不读取该文件内容的话,该模式就是简单的a追加模式
9 ERROR_CHECK(fp,NULL,"fopen");//告诉是fopen函数这一步出了问题
10 char buf[10] = {0};
11 fread(buf,1,9,fp);//如果进行读取操作的话
12 puts(buf);
13 fwrite("howareyou",1,9,fp); //往里面写入内容
14 fclose(fp);//关闭文件缓冲区
15 }
测试运行:
![]()

我们先在file1内写入内容,然后再进行读取,测试结果如上,能够读取到数据。
此时我们查看file1,因为在c代码中我们先是读取了文件然后又写入了文件:
![]()
这里是首先ptr是在上一次写完文件之后应该在文件内容尾部的,但是因为这次先读文件,所以读写指针ptr移动到了开头并且读取了九个字符之后跳到了中间下一个howareyou开头的位置,但因为"a+"是读写追加的模式,所以接下来又要进行写操作的时候ptr指针会直接跳到文件末尾进行追加写。
为什么没有可能是读完之后写操作继续跟在了ptr读写指针读位置处开始进行写操作而变成四个howareyou呢?
因为如果是在上次读位置开始进行写操作的话,写操作并不会重新写一个howareyou而是会覆盖掉原来的一个howareyou导致变成三个howareyou,所以我们断定其是跳到了文件末尾进行了追加写操作。
改变文件属性的相关系统调用
chmod系统调用改变文件权限
这个chmod和我们之前学的chmod指令没有一点关系:
这里我们使用man手册查看位于man分区2的该系统调用命令:

从手册中可以看出,要使用该命令我们需要带有sys/stat.h的头文件,因此在我们的工具文件当中加上该文件:
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <sys/stat.h>
5 #define ARGS_CHECK(argc,num) {if(argc != num){fprintf(stderr,"args error!\n"); return -1;}}
6 #define ERROR_CHECK(ret,num,msg){if(ret == num){perror(msg); return -1;}}
注意这个头文件在Windows上面是没有的,只有Linux有。
阅读过手册之后写代码验证一下这个事情:
1 #include <43func.h>
2
3 int main(int argc,char* argv[]){
4 //我们的命令行参数形式: ./chmod 777 dir1
5 ARGS_CHECK(argc,3); //因为需要三个参数
6 //通过阅读手册我们知道,调用chmod系统调用需要两个参数
7 //chmod(argv[2],argv[1]);
8 //一个是所要修改权限的文件夹,还要一个是所要修改的权限
9 //但该权限是八进制的,所以我们需要用一个函数来帮我们进行进制转换
10 mode_t mode;//这个mode_t是一个无符号整数的数据类型,用来接收权限值
11 sscanf(argv[1],"%o",&mode);
12
13 int ret = chmod(argv[2],mode);
14 //但不一定就能调用成功,因此需要进行判断
15 ERROR_CHECK(ret,-1,"chmod");
16
17 }
我们来创建一个文件,查看其权限:
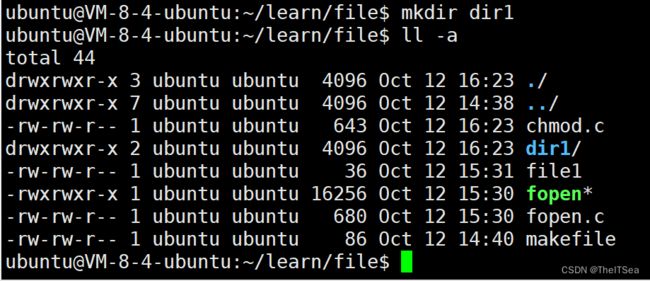
可以看见dir1的权限为rwx rwx r-x,即111 111 101,对应十进制为775.
接下来我们通过chmod系统调用来改变其权限为777:

可以看见其权限已经被修改为777.
getcwd系统调用获得当前工作路径
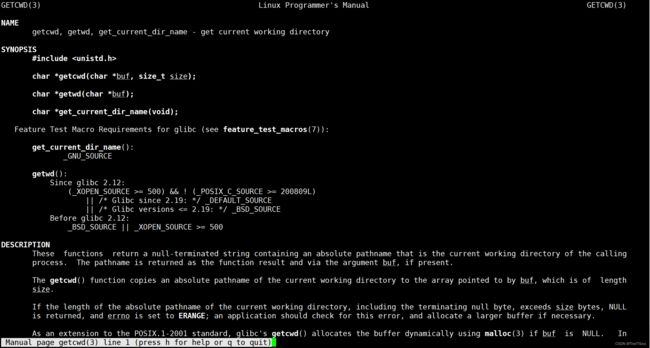
可以看到该函数参数有两个,一个char类型的指针,其实就是个字符串,还有一个是size_t该字符串的长度(因为光靠首地址无法判断其长度),返回值是个char,如果buf存在,则返回buf的地址,如果不存在就是返回空指针:

来验证一下这个事情:
依然是加上我们的头文件:
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <sys/stat.h>
5 #include <unistd.h>
6 #define ARGS_CHECK(argc,num) {if(argc != num){fprintf(stderr,"args error!\n"); return -1;}}
7 #define ERROR_CHECK(ret,num,msg){if(ret == num){perror(msg); return -1;}}
然后编写程序测试:
第一种情况:buf不为空,直接返回buf。
1 #include <43func.h>
2
3 int main(){
4 char buf[30] = {0};
5 char* ret = getcwd(buf,sizeof(buf));
6 printf("ret = %p,ret = %s\n",ret,ret);
7 printf("buf = %p,buf = %s\n",buf,buf);
8 }
~
编译运行:

可以看见如果buf存在的话,那么返回的地址就是buf。
但是如果分配的buf太小(毕竟有些工作目录字数很多)就会存不完工作路径,此时就会报错:

所以最好直接分配大一点,比如1024大小就不错。
getcwd的作者也给我们提供了如下的方式来使用getcwd:

这种方式可以不写大小,因为此时这个getcwd的内存空间是从堆空间开辟的,所以在调用完之后必须记得free掉该空间,不然就会内存泄露。
chdir系统调用改变当前工作目录

测试:
1 #include <43func.h>
2
3 int main(int argc,char* argv[]){
4 ARGS_CHECK(argc,2);
5 //./chdir dir1
6 printf("before chdir,cwd = %s\n",getcwd(NULL,0));
7 int ret = chdir(argv[1]);
8 ERROR_CHECK(ret,-1,"chidr");
9 printf("after chdir,cwd = %s\n",getcwd(NULL,0));
10 }
编译运行如下:

但是我们发现我们的当前目录呢并没有发生改变,这是因为当前其实有两个进程在执行,其中一个是我们的命令窗口这是一个Shell进程,一直在负责解释我们的每一条指令,而另一个进程就是刚刚我们使用./chdir命令创建出来的子进程,在该进程中其目录已经改变了只是我们这里没有体现而已。
rmdir和mkdir系统调用:
这里一样,因为有同名的系统命令也叫这两个,所以我们查看man手册时要在man分区2里面进行查看。

因为出现了没用过的头文件,去加一下:
1 #include <stdio.h>
2 #include <string.h>
3 #include <stdlib.h>
4 #include <sys/stat.h>
5 #include <unistd.h>
6 #include <sys/types.h>
7 #define ARGS_CHECK(argc,num) {if(argc != num){fprintf(stderr,"args error!\n"); return -1;}}
8 #define ERROR_CHECK(ret,num,msg){if(ret == num){perror(msg); return -1;}}
测试:
1 #include <43func.h>
2
3 int main(int argc,char* argv[]){
4 ARGS_CHECK(argc,2);
5 int ret = mkdir(argv[1],0777); //第二个参数依然是mode_t的类型,传数字的八进制即可
6 ERROR_CHECK(ret,-1,"mkdir");
7 }
编译运行:

rmdir顾名思义了就,贴个图就完事了:

目录流
除了我们之前说的文件具有流结构(还记得吗,就是之前说的ptr自动读写指针那个东西),文件目录本身也是个流结构,也是有标记指针的。
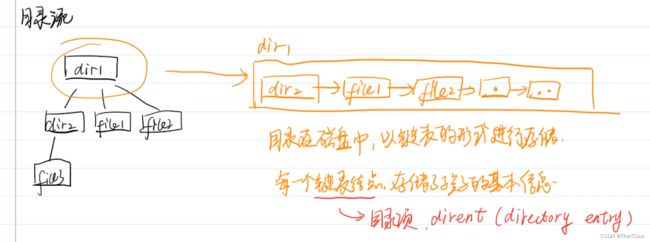
在我们的文件系统中也就是上图左侧,是一个很明显的树状结构,因为我们对目录做的最多的操作就是增加删除,所以其在外存中的物理存储形式被定义成了链式的结构,每一个链表结点都被称为一个目录项,dirent(directory entry),存储了其所有孩子结点的基本信息。
因为文件目录肯定是存放在磁盘里面的,在系统运行时才被调入内存中,文件目录被调用进内存的形式就是目录流,即将目录中的链表加载到内存中来。
同时目录流也就是目录文件在内存中的缓冲区,和之前的文件流一样具有流的特点,就是具有一个指示位置的ptr指针,该指针每读取一个目录就自动往后移动一个结点(就和水流一样):

与之相关的几个系统调用分别是:readdir、opendir、closedir。
opendir、readdir和closedir
先来看一下三个系统调用的man手册:

注意自己验证函数的时候要注意加它的头文件嗷。
下面是readdir的man说明:

对于另外两个系统函数比较简单,这里说一下这个readdir的一些细节:

该函数传入一个目录地址,返回一个struct dirent* 指针,那么我们就必须清楚该指针的空间是主调函数分配的还是readdir函数分配的。
直接给出:这个空间是readdir分配的,它指向数据段(静态区)中的某一块内存,man手册中也给出了对应的struct dirent的设计细节,其中d_reclen存的是该结构体的大小,这说明该结构体大小是可变的,这是由于文件名字有长有短的原因。
当调用readdir时会产生一个目录流,会有一个ptr指针指向最开始的目录项,当调用readdir时会将ptr所指向的目录项内容放到静态区中,然后ptr指针自动后移,所以从侧面说明了静态区中的目录项(struct dirent)的内存空间是由readdir系统调用自行分配的。
我们的主调函数并不是申请了struct dirent的内存空间,只是声明了一个以struct dirent类型的指针变量指向由readdir系统调用申请的struct dirent的内存空间。
还有closedir:

接下来我们组合这三个系统调用,实现一个ls,代码如下:
1 #include <43func.h>
2
3 int main(int argc,char* argv[]){
4 // ./myLs dir
5 ARGS_CHECK(argc,2);
6 DIR* dirp = opendir(argv[1]);
7 ERROR_CHECK(dirp,NULL,"opendir");
8 struct dirent* pdirent;
9 pdirent = readdir(dirp);
10 //借助ptr指针循环打印目录流内容
11 while((pdirent = readdir(dirp)) != NULL){
12 printf("inode = %ld,reclen = %d, type = %d, name = %s\n",
13 pdirent->d_ino,pdirent->d_reclen,pdirent->d_type,pdirent->d_name);
14 }
15 closedir(dirp);
16 }
编译运行结果如下:

上面可以看到有些reclen为32有些为24,这是因为它们的文件名长短不一样。
ls效果如下:

可以发现二者还是很相似的,基本实现了ls的功能。
telldir和seekdir系统调用:定位目录流
telldir:获得目录流中的ptr所指的位置
这里先回忆一下上面提到的readdir会读取某目录下面的目录流的事情:
编写代码测试:
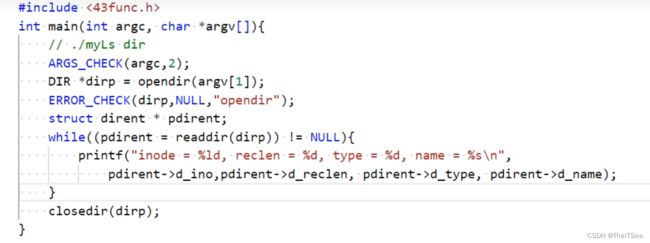
编译运行结果:

因为readdir的读取目录顺序就是其内置的目录流顺序,所以我们通过上述代码打印dir1的目录流就如图所示。
那现在再来看一下telldir的man说明:

我们结合下面要说的seekdir来组合说明telldir的作用。
seekdir:获得telldir所保存的位置之后回退到该位置

组合使用:实现回到目录流的过去某目录

测试发现:

上面的代码帮我们定位到了…目录,这并不是我们想要的file1目录,这是为什么?
其实是我们的代码逻辑导致的,我们已经知道该文件的目录流:
因为ptr指针每一次执行readdir系统调用之后都会往后移动一个单位,且我们又是先进行readdir的,所以第一次while判断结束时ptr指向的实际是file1,此时readdir返回dirp 指向的是file1,在进行if(strcmp(pdirent->d_name,“file1” == 0))判断时不满足条件因为此时的pdirent->d_name指向的是.目录,所以进行第二次while循环时,d_name指向的是file1了,可惜因为while循环时readdir又被调用了此时ptr指向…目录了,所以返回的dirp指向的是…目录,loc当然记录下来的就是…目录的位置啦。
如果要让其正确输出答案的话,只要对循环结构进行优化即可,这里不再赘述。
rewinddir系统调用:把ptr指针定位到目录流的最开始
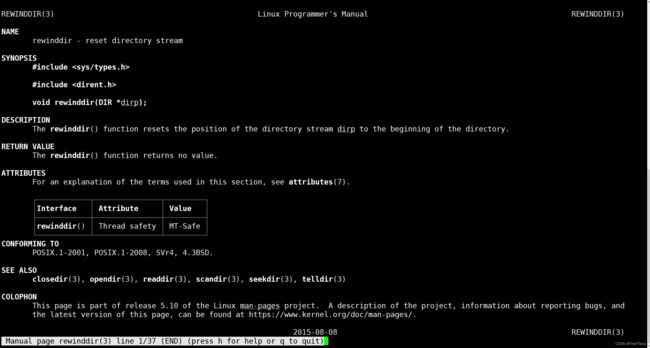
改一下上面之前写的代码:

可以看见与之前的区别就是rewinddir系统调用将dirp目录流的ptr指针给重新定位到目录流开头了,此时再readdir(dirp)自然定位到的就是目录流最开始的目录位置.目录啦:

stat系统调用:获取文件状态信息

我们介绍的stat系统调用,那么可以看到该系统调用有两个参数,其中第二个是比较陌生的,看名字就知道是系统自定义的一个结构体,我们可以下拉到下面看到细节:

自然我们可以通过该系统调用获取到该结构体内的信息。
stat配合目录流实现ls -al

如图所示,当我们输入ls -l命令的时候出现的每一条记录都如上图右侧的内容所示,而这些内容我们都是可以通过stat系统调用的参数struct stat拿到的,上图不同颜色对应了不同的取值变量,其中最后一个文件名可以通过我们之前学过的dirent拿到。
#include <43func.h>
int main(int argc, char *argv[]){
// ./myLs dir
ARGS_CHECK(argc,2);
DIR *dirp = opendir(argv[1]);
ERROR_CHECK(dirp,NULL,"opendir");
struct dirent * pdirent;
struct stat statbuf;
int ret = chdir(argv[1]);
ERROR_CHECK(ret,-1,"chdir"); //防止切换目录出现bug
while((pdirent = readdir(dirp)) != NULL){
ret = stat(pdirent->d_name,&statbuf);//文件名只有在当前目录下才是路径
ERROR_CHECK(ret,-1,"stat");
printf("%6o %ld %s %s %8ld %s %s\n",
statbuf.st_mode,
statbuf.st_nlink,
getpwuid(statbuf.st_uid)->pw_name,//注意使用getpwuid需要头文件pwd.h,这是将statbuif打印的数字转换成人能看得懂的字符串
getgrgid(statbuf.st_gid)->gr_name,//使用getgrgid需要头文件grp.h
statbuf.st_size,
ctime(&statbuf.st_mtime),//该日期转换需要用到time.h头文件,下面会有补充日历时间的系统调用
pdirent->d_name);
}
closedir(dirp);
}
然后就可以实现一个粗糙的ls -al命令的效果:

来看一下ll的效果:

基本上差不多,我们只要将myLs中的数字形式的文件类型以及权限格式改成对应的字符串表示形式就可以了,这里不再赘述。
补充:日历时间系统调用

具体的就查man手册吧。
实现tree命令
效果:

思路:

代码实现:
#include <43func.h>
int DFSprint(char *path, int width);
int main(int argc, char *argv[]){
ARGS_CHECK(argc,2);
puts(argv[1]);
DFSprint(argv[1],4);
}
int DFSprint(char *path, int width){
DIR* dirp = opendir(path);
ERROR_CHECK(dirp,NULL,"opendir");
struct dirent *pdirent;
char newPath[1024] = {0};
while((pdirent = readdir(dirp)) != NULL){
if(strcmp(pdirent->d_name,".") == 0 ||
strcmp(pdirent->d_name,"..") == 0){
continue;
}
//printf("├"); 我觉得不加这些比较好看,用空格表示层次结构即可
for(int i = 1; i < width; ++i){
// printf("─");
printf(" ");
}
puts(pdirent->d_name);
if(pdirent->d_type == DT_DIR){
sprintf(newPath,"%s%s%s",path,"/",pdirent->d_name);
//printf("newPath = %s\n", newPath);
DFSprint(newPath,width+4);
}
}
}
最终效果:
