基于 KEDA 实现 Job 任务动态扩缩容

背景说明
随着 Kubernetes 的广泛使用,在很多场景中都有 Kubernetes 动态扩缩容的诉求,比如 Pod 级别的动态扩缩容、Node 级别的动态扩缩容。这些场景的实现,对业务弹性至关重要。如何利用好 Kubernetes 的这些能力,成为企业必须要关注的话题。本文将以一个具体的场景入手,详细介绍使用 KEDA 调度 Job 任务的原理、优势以及收益。
场景:
业务系统部署在本地数据中心,由自建 Kubernetes 集群承载,包括 2 台控制平面节点和 8 台数据平面节点。在自建 Kubernetes 集群中部署了 Kafka、自建 Airflow 调度平台和任务 Pod。
通过调度平台下发和拆解任务,并由 Kafka 存储已拆解的子任务,任务 Pod 先同商业授权软件交互得到授权,然后从 Kafka 中获取待处理子任务进行计算。这种架构存在一个致命问题,无法根据任务数量和负载情况动态调整计算资源规模。
借助亚马逊云科技的海量资源以及 KEDA 和 Karpenter 的组件能力,可以轻松解决上述挑战。

当前的业务流程是:
1:发起新的任务至调度平台
2:调度平台对任务进行拆解,并将子任务存储到 Kafka 消息队列
3:任务 Pod 从 Kafka 消息队列中获取子任务并进行计算
解决方案
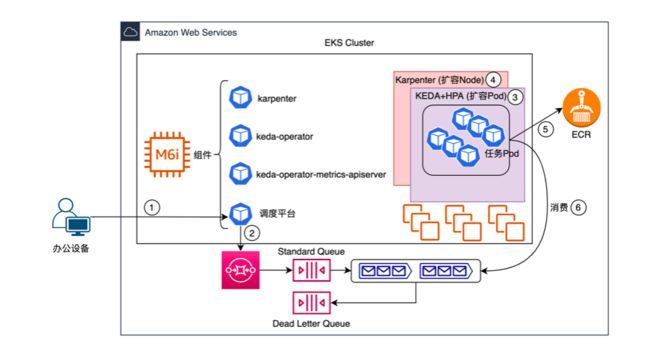
为了解决本地数据中心架构面临的挑战,我们按照无服务器和弹性扩缩容的角度设计了如上解决方案。其中,引入并替换了部分组件。
Amazon SQS 替换自建 Kafka:Amazon SQS 是无服务器消息队列,按照 Requests 进行收费。无需关心底层资源的维护,只需关注如何实现业务逻辑。
Amazon EKS 替换自建 Kubernetes 集群:Amazon EKS 控制平面由 Amazon 进行托管,以运行时长进行收费。无需关注控制节点可用性,只需对计算节点进行维护。
任务 Pod 类型替换:长期运行的一次性任务更适合 Job 任务,避免缩容时误删除未运行完成的 Deployment 任务 Pod。
引入基于事件的扩缩容 KEDA 组件:KEDA 监控 Amazon SQS Queue,当有新的任务达到 Queue 时,启动 Job 任务进行处理。
引入 Node 节点扩缩容 Karpenter 组件:当有 Job 任务启动时,Karpenter 创建计算节点以承载 Job 任务,处理完成则删除计算节点,已节约成本。
注:Amazon SQS Queue 中没有任务时,EKS 集群中只有一个 m6i.large 节点,此节点用于承载组件 Pod,包括 karpenter、keda-operator、keda-operator-metrics-apiserver、调度平台。
上述解决方案业务处理逻辑和本地数据中心存在一定差异,因此进行简要梳理:
发起新的任务至调度平台
调度平台对任务进行拆解,并将子任务存储到 Amazon SQS Queue
KEDA 组件监控到 Amazon SQS Queue 中有新的子任务,创建任务 Pod
Karpenter 创建新的 Node,任务 Pod 被分配到新的 Node
任务 Pod 从 Amazon ECR 拉取镜像启动
任务 Pod 从 Amazon SQS Queue 中获取子任务并进行计算
组件介绍
Amazon SQS:适用于微服务、分布式系统和无服务器应用程序的完全托管的消息队列。解决方案中用到了 Standard Queue 和 Dead Letter Queue。
Standard Queue:存储子任务。应用程序消费完子任务后需要删除子任务,否则子任务将重新回到 Standard Queue。
Dead Letter Queue:设置一个阈值,当子任务重新回到 Standard Queue 的次数超过阈值时,消息进入 Dead Letter Queue。可以用于分析和排错。
KEDA (Kubernetes Event-driven Autoscaling):KEDA 是 Kubernetes 动态扩缩容组件,以可持续且经济高效的方式应用事件驱动缩放应用程序。由 Scaler、Controller 和 Metric Adapter 组成。
架构图和组件

通过定义 ScaledJob 和 Amazon SQS Trigger 两个对象,可以实现 KEDA 对 Amazon SQS Queue 的监控以及 Job 任务的动态扩缩容。
ScaledJob spec

Amazon SQS spec

Karpenter:Karpenter 是一个为 Kubernetes 构建的开源自动扩缩容项目。它提高Kubernetes 应用程序的可用性,而无需手动或过度配置计算资源。Karpenter 旨在通过观察不可调度的 Pod 的聚合资源请求并做出启动和终止节点的决策,以最大限度地减少调度延迟,从而在几秒钟内(而不是几分钟)提供合适的计算资源来满足您的应用程序的需求。
注:Karpenter 的具体介绍,请参考附录 2
环境搭建
1. 前提条件和组件版本
本篇文章所有命令都在ap-northeast-2中,一台拥有AdministratorAccess IAM Role的Amazon EC2上,使用ec2-user执行
EKS 1.23、KEDA 2.9.0、Karpenter 0.29.0、kubectl v1.25.6、eksctl 0.133.0、helm v3.10.2、awscli 2.9.5
2. 假设 EKS 集群已经 Ready,如果还未创建 EKS 集群,请参考附录 3
3. 创建 Demo 用 SQS
export QUEUE_NAME=keda-queue # 需要修改
export CLUSTER_NAME=$(eksctl get clusters -o json | jq -r '.[0].Name')
export ACCOUNT_ID=$(aws sts get-caller-identity --output text --query Account)
export AWS_REGION=$(curl -s 169.254.169.254/latest/dynamic/instance-identity/document | jq -r '.region')
export QueueURL=$(aws sqs create-queue \
--queue-name=$QUEUE_NAME \
--region=$AWS_REGION \
--output=text \
--query=QueueUrl)左滑查看更多
4. 生成 IRSA(IAM Roles for Service Account)
3.1 创建namespace
kubectl create namespace keda # 可以修改
3.2 创建IAM Policy
mkdir -p ~/environment/keda && cd ~/environment/keda
cat < ~/environment/keda/keda-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "sqs:*",
"Resource": "arn:aws:sqs:${AWS_REGION}:${ACCOUNT_ID}:${QUEUE_NAME}"
}
]
}
EoF
aws iam create-policy \
--policy-name AmazonSQSPolicy \
--policy-document file://~/environment/keda/keda-policy.json
3.3 创建KEDA SA
eksctl create iamserviceaccount \
--name keda-operator\
--namespace keda \
--cluster ${CLUSTER_NAME} \
--attach-policy-arn "arn:aws:iam::${ACCOUNT_ID}:policy/AmazonSQSPolicy" \
--role-name KEDA-SQS \
--approve \
--override-existing-serviceaccounts 左滑查看更多
5. 构建 Demo 用镜像
# Dockerfile
FROM amazonlinux
COPY consume_message.sh /root/
RUN chmod + x /root/consume_message.sh; yum install unzip -y; curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"; unzip awscliv2.zip; ./aws/install
CMD /root/consume_message.sh
# consume_message.sh
#!/bin/bash
#
receipt_handle=$(aws sqs receive-message --queue-url --query "Messages[].ReceiptHandle" --output text)
if [ "${receipt_handle}" != "None" ]; then
aws sqs delete-message --queue-url --receipt-handle "${receipt_handle}"
else
echo "1"
fi
# 确保Dockerfile和consume_message.sh在同一个目录,且目录中只包含这两个文件
docker build -t keda-demo:latest .
# 按照ECR的Push commands命令上传镜像,并记录镜像地址 左滑查看更多
6. 通过 Helm 安装 KEDA
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
KEDA_VERSION=2.9.0
helm install keda kedacore/keda \
--version ${KEDA_VERSION} \
--set serviceAccount.create=false \
--set serviceAccount.name=keda-operator \
--set podSecurityContext.fsGroup=1001 \
--set podSecurityContext.runAsGroup=1001 \
--set podSecurityContext.runAsUser=1001 \
--namespace keda左滑查看更多
7. 通过 Helm 安装 Karpenter
# 需要给子网和安全组打标签--->Key="karpenter.sh/discovery",Value="my-cluster"--->Value--->其中Value需要按照集群名称进行修改
# 设置环境变量
export AWS_PARTITION="aws"
export CLUSTER_NAME="$(eksctl get clusters -o json | jq -r '.[0].Name')"
export AWS_DEFAULT_REGION="$AWS_REGION"
export AWS_ACCOUNT_ID="$(aws sts get-caller-identity --query Account --output text)"
export TEMPOUT=$(mktemp)
export KARPENTER_VERSION=0.29.0
# 验证环境变量
echo $KARPENTER_VERSION $CLUSTER_NAME $AWS_DEFAULT_REGION $AWS_ACCOUNT_ID $TEMPOUT
# 执行Cloudformation模板,创建必要资源
curl -fsSL https://raw.githubusercontent.com/aws/karpenter/"${KARPENTER_VERSION}"/website/content/en/preview/getting-started/getting-started-with-karpenter/cloudformation.yaml > $TEMPOUT \
&& aws cloudformation deploy \
--stack-name "Karpenter-${CLUSTER_NAME}" \
--template-file "${TEMPOUT}" \
--capabilities CAPABILITY_NAMED_IAM \
--parameter-overrides "ClusterName=${CLUSTER_NAME}"
# 给实例授权使其可以使用之前创建的profile来连接eks集群
eksctl create iamidentitymapping \
--username system:node:{{EC2PrivateDNSName}} \
--cluster "${CLUSTER_NAME}" \
--arn "arn:aws:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}" \
--group system:bootstrappers \
--group system:nodes
# 检查AWS auth map
kubectl describe configmap -n kube-system aws-auth
# 创建IAM OIDC Identity Provider for the cluster
eksctl utils associate-iam-oidc-provider --cluster ${CLUSTER_NAME} --approve
# 创建并使用IAM Roles for Service Accounts (IRSA)
eksctl create iamserviceaccount \
--cluster "${CLUSTER_NAME}" --name karpenter --namespace karpenter \
--role-name "${CLUSTER_NAME}-karpenter" \
--attach-policy-arn "arn:aws-cn:iam::${AWS_ACCOUNT_ID}:policy/KarpenterControllerPolicy-${CLUSTER_NAME}" \
--role-only \
--approve
export CLUSTER_ENDPOINT="$(aws eks describe-cluster --name ${CLUSTER_NAME} --query "cluster.endpoint" --output text)"
export KARPENTER_IAM_ROLE_ARN="arn:aws:iam::${AWS_ACCOUNT_ID}:role/${CLUSTER_NAME}-karpenter"
# 创建可用于Spot实例的Service Linked Role
aws iam create-service-linked-role --aws-service-name spot.amazonaws.com || true
# 安装Karpenter
docker logout public.ecr.aws
helm upgrade --install karpenter oci://public.ecr.aws/karpenter/karpenter --version ${KARPENTER_VERSION} --namespace karpenter --create-namespace \
--set serviceAccount.annotations."eks\.amazonaws\.com/role-arn"=${KARPENTER_IAM_ROLE_ARN} \
--set settings.aws.clusterName=${CLUSTER_NAME} \
--set settings.aws.defaultInstanceProfile=KarpenterNodeInstanceProfile-${CLUSTER_NAME} \
--set settings.aws.interruptionQueueName=${CLUSTER_NAME} \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi \
--wait左滑查看更多
Demo 展示
本次实验将模拟向 Amazon SQS Queue 写入数据以触发 KEDA 和 Karpenter 的动态扩缩容,验证动态扩缩容方案可行性。
1. 部署 ScaledJob
~]$ cat < # 需要替换成”构建Demo用镜像”部分记录的镜像地址
resources:
requests:
cpu: 1
restartPolicy: Never
serviceAccountName: keda-operator
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: intent
operator: In
values:
- apps
EOF 左滑查看更多
2. 创建 Karpenter Provisioner—>按需求加上资源限制
~]$ cat <左滑查看更多
3. 查看 KEDA 和 Karpenter Pod 已经 Ready
~]$ kubectl get pods -n keda; kubectl get pods -n karpenter
NAME READY STATUS RESTARTS AGE
keda-operator-5b8c55cdb-hzdf6 1/1 Running 3 (11d ago) 25d
keda-operator-metrics-apiserver-66496446f7-8gtnb 1/1 Running 0 25d
NAME READY STATUS RESTARTS AGE
karpenter-9f7b5769f-8pvbc 1/1 Running 10 (6d14h ago) 20d左滑查看更多
4. 模拟调度平台向 Amazon SQS Queue 写入消息
~]$ for x in {1..20}; do aws sqs send-message --message-body="Test Message ${x}" --queue-url=$QueueURL --region=$AWS_REGION; done左滑查看更多
5. 验证扩容行为
~]$ kubectl logs -n karpenter -l app.kubernetes.io/name=karpenter -c controller # 可以看到Karpenter启动节点,图1
~]$ kubectl logs -n keda -l app.kubernetes.io/name=keda-operator # 可以看到KEDA创建了Job任务,图2
~]$ kubectl get pods -n keda # 可以看到启动并执行完成的Job任务,图3
~]$ aws sqs get-queue-attributes --queue-url $QueueURL --attribute-names ApproximateNumberOfMessages # 确认消息都已处理,图4左滑查看更多

图1

图2

图3

图4
总结
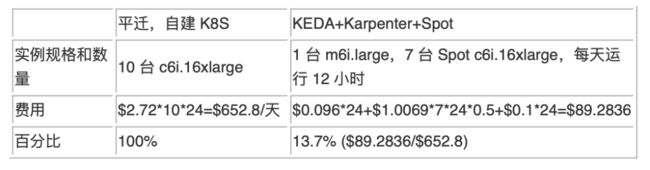
按照上面的 Demo 验证,使用无服务器消息队列 Amazon SQS 替换 Kafka、引入 KEDA 和 Karpenter,不仅可以利用云的弹性快速完成不同规模的任务,同时还可以有效降低云上成本。
环境清理
按顺序删除
iamidentitymapping 、iamserviceaccount 、IAM Role、IAM Policy、EKS 集群和 Amazon SQS Queue。
附录
https://github.com/kedacore/keda/pull/1227
https://aws.amazon.com/cn/blogs/china/karpenter-new-generation-kubernetes-auto-scaling-tools/
https://archive.eksworkshop.com/030_eksctl/
本篇作者

郑毅
西云数据解决方案架构师。曾就职于外企、互联网企业和央企,擅长系统交付、运维和解决方案设计,对于传统 IT 技术以及云计算技术有深入了解和丰富的实战经验。

孙亮
亚马逊云科技解决方案架构师,硕士毕业于浙江大学计算机系。在加入亚马逊云科技之前,拥有多年软件行业开发经验。目前在 Public Sector 部门主要服务于生命科学和医疗健康相关的行业客户,致力于提供有关 HPC、无服务器、数据安全等各类云计算解决方案的咨询与架构设计。
星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!
