一种结构和纹理感知 Retinex 模型 (2020 TIP) (1 of 2)
STAR: A Structure and Texture Aware Retinex Model

[PAPER] [GitHub]
一种结构和纹理感知 Retinex 模型 (2020 TIP) (2 of 2)

Fig. 1. An example to illustrate the applications of the proposed STAR model based on Retinex theory. (a) The input low-light and color-distorted image; (b) the estimated illumination component of (a); (c) the estimated reflectance component of (a); (d) the extracted structure and texture maps (half each) of (a); (e) the illumination enhanced low-light image of (a); (f) the color corrected image of (a).
Abstract
Retinex theory is developed mainly to decompose an image into the illumination and reflectance components by analyzing local image derivatives. In this theory, larger derivatives are attributed to the changes in reflectance, while smaller derivatives are emerged in the smooth illumination. In this paper, we utilize exponentiated local derivatives (with an exponent γ ) of an observed image to generate its structure map and texture map. The structure map is produced by been amplified with γ > 1, while the texture map is generated by been shrank with γ < 1. To this end, we design exponential filters for the local derivatives, and present their capability on extracting accurate structure and texture maps, influenced by the choices of exponents γ . The extracted structure and texture maps are employed to regularize the illumination and reflectance components in Retinex decomposition. A novel Structure and Texture Aware Retinex (STAR) model is further proposed for illumination and reflectance decomposition of a single image. We solve the STAR model by an alternating optimization algorithm. Each sub-problem is transformed into a vectorized least squares regression, with closed-form solutions. Comprehensive experiments on commonly tested datasets demonstrate that, the proposed STAR model produce better quantitative and qualitative performance than previous competing methods, on illumination and reflectance decomposition, low-light image enhancement, and color correction.
Introduction
The Retinex theory developed by Land and McCann [30], [32] models the color perception of human vision on natural scenes. It can be viewed as a fundamental theory for intrinsic image decomposition problem [3], which aims at decomposing an image into illumination and reflectance (or shading) components. A simplified Retinex model involves decomposing an observed image O into an illumination component I and a reflectance component R via
, where
denotes the element-wise multiplication. The illumination I expresses the color of the light striking the surfaces of objects in the scene O, while the reflectance R reflects the painted color of the surfaces of objects in O [68]. Retinex theory has been applied in many image processing tasks, such as low-light image enhancement [24], [51], [68] and color correction [9], [19] (please refer to Figure 1 for an example).
Retinex theory 背景简介:
Retinex theory 模拟了人类视觉对自然场景的颜色感知。它可以看作是本内在图像分解问题[3]的基本理论,其目的是将图像分解为光照和反射(或阴影)成分。一个简化的 Retinex 模型将观察到的图像 O 通过 ![]() 分解为光照分量I和反射率分量 R,其中表示元素相乘。光照 I 表示场景 O 中物体表面的光的颜色(color of the light),反射率 R 则反映了场景 O 中物体表面的彩绘颜色(painted color)[68 TPAMI 2012]。Retinex理论已经应用于许多图像处理任务,如微光图像增强[24],[51],[68]和色彩校正[9],[19](举例见图1)。
分解为光照分量I和反射率分量 R,其中表示元素相乘。光照 I 表示场景 O 中物体表面的光的颜色(color of the light),反射率 R 则反映了场景 O 中物体表面的彩绘颜色(painted color)[68 TPAMI 2012]。Retinex理论已经应用于许多图像处理任务,如微光图像增强[24],[51],[68]和色彩校正[9],[19](举例见图1)。
The Retinex theory introduces a useful property of derivatives [30], [32], [68]: larger derivatives are often attributed to the changes in reflectance, while smaller derivatives are likely from the smooth illumination. With this property, the Retinex decomposition can be performed by classifying the image gradients into the reflectance component and the illumination one [29 IJCV 2003]. However, binary classification of image gradients is unreliable since reflectance and illumination changes will coincide in an intermediate region [68].
Later, several methods are proposed to classify the edges or edge junctions, instead of gradients, according to some trained classifiers [4], [47 TPAMI 2005]. However, it is quite challenging to train classifiers considering all possible ranges of illumination and reflectance configurations. Besides, though these methods explicitly utilize the property of derivatives, they perform Retinex decomposition by analyzing the gradients of a scene [12] in a local manner, while ignoring the global consistency of the structure in that scene.
To alleviate this problem, several methods [19], [51], [68] perform global decomposition with the consideration of different regularization. However, these methods ignore the property of derivatives and cannot separate well illumination and reflectance components.
Retinex theory 与导数性质:
1). 较大的导数往往归因于反射率的变化,而较小的导数可能来自于平滑照明。
2). 根据 1) 的观察,Retinex 分解可以通过将图像的梯度分为反射分量和光照分量来进行 【29 IJCV 2003 A Variational Framework for Retinex】。
3). [29] 的问题在于图像梯度的二值分类是不可靠的,因为反射率和光照的梯度变化会在中间区域重合。
4). 为了缓解这一问题,根据一些训练好的分类器,提出了几种方法来分类边缘或边缘连接,而不是梯度 【47 TPAMI 2005 Recovering Intrinsic Images from a Single Image】。
5). [47] 中的问题是,1 训练分类器很难考虑到所有可能的照明和反射率配置范围;2 虽然方法明确地利用了导数的性质,但它是通过局部分析场景的梯度来进行 Retinex 分解,忽略了该场景结构的全局一致性。
6). 为了缓解这一问题,[19 TIP 2013],[51],[68] 等几种方法在考虑不同正则化的情况下进行全局分解 【68 TPAMI 2012 A Closed-Form Solution to Retinex with Nonlocal Texture Constraints】。
7). [68] 忽略了导数的性质,不能很好地分离光照和反射分量。
In this paper, we propose to utilize exponentiated local derivatives to better exploit the property of derivatives in a global manner. The exponentiated derivatives are determined by an introduced exponents γ on local derivatives, and generalize the local derivatives to extract global structure and texture maps. Given an observed scene (e.g., Figure 1 (a)), its derivatives are exponentiated by γ to generate a structure map (Figure 1 (d) up) when being amplified with γ > 1 and a texture map (Figure 1 (d) down) when being shrank with γ < 1. The extracted structure and texture maps are employed to regularize the illumination (Figure 1 (b)) and reflectance (Figure 1 (c)) components in Retinex decomposition, respectively. With meaningful structure and texture maps, we propose a Structure and Texture Aware Retinex (STAR) model to accurately estimate the illumination and reflectance components. We solve our STAR model by an alternating optimization algorithm [49], [60]. Each sub-problem is transformed into a vectorized least squares regression with closed-form solutions [57]. Comprehensive experiments on commonly tested datasets demonstrate that, the proposed STAR model obtains better performance than previous competing methods, on illumination and reflectance decomposition, low-light image enhancement, and color correction.
STAR 模型介绍:
本文提出利用取幂的局部导数在全局上更好地利用导数的性质。通过在局部导数上引入指数 γ 来确定幂次导数,并对局部导数进行推广,从而提取全局结构和纹理映射。
给定一个观察到的场景 (如图1 (a)),当用 γ > 1 放大时,对其导数取 γ 的幂,生成一个结构图 (图1 (d)上),当 γ < 1 缩小时,生成一个纹理图 (图1 (d)下)。
利用提取的结构图和纹理图分别对 Retinex 分解中的光照 (图1 (b)) 和反射率(图1 (c)) 分量进行正则化处理。
利用有意义的结构和纹理映射,本文提出了一种结构和纹理感知的 Retinex (STAR) 模型来精确估计光照和反射率成分。
用交叉优化算法 [49 TNNLS 2020 PID controller-based stochastic optimization acceleration for deep neural networks][60] 来求解 STAR 模型。
将每个子问题转化为一个具有封闭解的向量化最小二乘回归 [57 Scaled Simplex Representation for Subspace Clustering] 。
在常用测试数据集上的综合实验表明,本文提出的 STAR 模型在光照和反射率分解、微光图像增强、颜色校正等方面均优于以往的 SOTA 方法。
Related Work
Retinex Model
The Retinex model has been extensively studied in literature [9], [27], [31], which can be roughly divided into classical ones [7], [20], [41] and variational ones [9], [24], [51]. Besides, the Retinex decomposition methods can be applied into low-light image enhancement [37], [50], [64] and color correction [14], [21], [26].
Retinex Model 方法分类:传统版本和变分版本。
Retinex Model 视觉应用:弱光增强和颜色校正。
- Classical Retinex
Classical Retinex methods include path based methods [7], [16], [20], [31], Partial Differential Equation (PDE) based methods [41], and center/surround methods [27].
Early path based methods [7], [31] are developed based on the assumption that, the reflectance component can be computed by the product of ratios along some random paths. These methods demand careful parameter tuning and incur high computational costs. To improve the efficiency, later path-based methods of [16], [20] employ recursive matrix computation techniques to replace previous random path computation. However, their performance is largely influenced by the number of recursive iterations, and unstable for real applications.
PDE based methods [41] utilize the property that the Retinex solutions satisfy a discrete Poisson equation, which yields an efficient implementation of reflectance estimation using only two Fast Fourier Transformations (FFTs). However, the structure of illumination component will be degraded, since gradients derived by a divergence-free vector field often loss piece-wise smoothness.
The center/surround methods include the famous single-scale Retinex (SSR) [28] and multi-scale Retinex with color restoration (MSRCR) [27]. These methods simply assume the illumination component to be smooth, and the reflectance component to be non-smooth. However, due to lack of a reasonable structure-preserving restriction, MSRCR tends to produce halo artifacts around edges.
传统版本分类和不足:
1) 基于路径的方法:
概述:早期方法--基于早期路径的方法[7]和[31]是基于这样的假设发展起来的,即反射率成分可以通过沿一些随机路径的比值乘积来计算;后来方法--为了提高效率,后来的基于路径的[16]、[20]方法采用递归矩阵计算技术来代替之前的随机路径计算。
不足:早期方法--这些方法需要仔细的参数调优,并产生很高的计算成本;后来方法--它们的性能很大程度上受递归迭代次数的影响,并且对于实际应用程序来说是不稳定的。
2) 基于 PDE 的方法:
概述:基于 PDE 的方法[41]利用 Retinex 解满足离散泊松方程的性质,仅使用两个快速傅里叶变换(FFTs)就可以得到反射系数估计的有效实现。
不足:由于由无散度矢量场导出的梯度往往失去分段平滑性,照明组件的结构将会退化。
3)中心/环绕法:
概述:包括著名的单尺度 Retinex (SSR)[28]和基于颜色恢复的多尺度 Retinex (MSRCR)[27]。这些方法简单地假定光照组件是光滑的,而反射率组件是不光滑的。
不足:由于缺乏合理的结构保持限制,MSRCR 倾向于在边缘周围产生晕影。
- Variational methods
Variational methods [19], [34], [36] have been proposed for Retinex based illumination and reflectance decomposition.
In [29], the smooth assumption is introduced into a variational model to estimate the illumination component. But this method is slow and ignores to regularize the reflectance.
Later, an 1 variational model is proposed in [39] to focus on estimating the reflectance component. But this method ignores to regularize the illumination component.
The logarithmic transformation is also employed in [43] as a pre-processing step to suppress the variation of gradient magnitude in bright regions, but the reflectance component estimated with logarithmic regularization tends to be over-smoothed.
To consider both illumination and reflectance regularizations, a total variation (TV) model based method is proposed in [42]. But similar to [43], the reflectance is over-smoothed due to the side-effect of the logarithmic transformation.
Recently, Fu et al. [17] developed a probabilistic method for simultaneous illumination and reflectance estimation (SIRE) in the linear space instead of logarithmic one. This method preserves well the details and avoid to over-smooth the reflectance component, when compared to previous methods performed in the logarithmic space.
To alleviate the detail loss problem of the reflectance component in the logarithmic space, Fu et al. [19] proposed a weighted variational model (WVM) to enhance the variation of gradient magnitude in bright regions. However, the illumination component may instead be damaged by the unconstrained isotropic smoothness assumption.
By considering the properties of 3D objects, Cai et al. [9] proposed a Joint intrinsic-extrinsic Prior (JieP) model for Retinex decomposition. However, this model is prone to over-smoothing both the illumination and reflectance of a scene.
In [34], Li et al. proposed a Robust Retinex Method (RRM) by considering an additional noise map [55], [56]. But this method is effective especially for low-light images accompanied by intensive noise.
变分方法:
罗列了若干基于变分方法的 Retinex Mode,这里就不一一展开描述了。
【29 IJCV 2003 A Variational Framework for Retinex】
Intrinsic Image Decomposition
The Retinex model is in similar spirit with the intrinsic image decomposition model [1], [2], [35], which decomposes an observed image into Lambertian shading and reflectance (ignoring the specularity). The major goal of intrinsic image decomposition is to recover the shading and relectance terms from an observed scene, while the specularity term can be ignored without performance degradation [23]. However, the reflectance recovered in this problem usually loses the visual content of the scenes [24], and hence can hardly be used for simultaneous illumination and reflectance estimation. Therefore, intrinsic image decomposition does not satisfy the purpose of Retinex decomposition for low-light image enhancement, in which the objective is to preserve the visual contents of dark regions as well as keep its visual realism [24]. For more difference between Retinex decomposition and intrinsic image decomposition, please refer to [24 TIP 2016 LIME: Low-Light Image Enhancement via Illumination Map Estimation].
Retinex 分解和本征图像分解的区别(Retinex decomposition 和 Intrinsic image decomposition):
Retinex 模型与本征图像分解模型[1],[2],[35] 有相似之处。本征图像分解模型将观测图像分解为 Lambertian 遮光和反射率 (忽略镜面)。本征图像分解的主要目标是从观察到的场景中恢复阴影和关联项,而可以忽略高光项而不会导致性能下降[23]。然而,在这个问题中恢复的反射率通常会丢失场景[24]的视觉内容,因此很难同时用于光照和反射率的估计。因此,本征图像分解并不满足 Retinex 分解用于弱光图像增强的目的,Retinex 分解的目的是在保留黑暗区域的视觉内容的同时保持其视觉真实感[24]。关于 Retinex 分解与本征图像分解的更多差异,请参考[24]。
Method: Structure and Texture Awareness
Simplified Retinex Model
The Retinex model [30] is a color perception simulation of the human vision system. Its physical goal is to decompose an observed image O ∈ Rn×m into its illumination and reflectance components, i.e.,
where I ∈ Rn×m means the illumination component of the scene representing the brightness of objects, R ∈ Rn×m denotes the surface reflection component of the scene representing its physical characteristics, and
where
means element-wise division. In fact, we employ
and
to avoid zero denominators, where ε = 1-8.
To solve this inverse problem (2), previous Retinex methods usually employ an objective function that estimates illumination and reflectance components by
where R1 and R2 are two different regularization functions for illumination I and reflectance R, respectively. One implementation choice of R1 and R2 is the total variation (TV) [45], which is widely used in previous methods [19], [42].
Retinex model 定义中,I∈Rn×m 是表示物体亮度的场景光照分量,R∈Rn×m 是表示物体物理特征的场景表面反射分量。 是元素相乘。
I 和 R 通过(2)式估计,其中 表示元素除法。
先前的方法在求解公式(2)时,采用公式(3), R1 and R2 表示光照图像和反射率图像的正则化。过去常用的正则化方法是全变分法。
Structure and Texture Estimator
本节介绍了本文使用的 结构-边缘 滤波器 ETV 和 EMLV
The Retinex model (1) decomposes an observed scene into its illumination and reflectance components. This problem is highly ill-posed, and proper priors of illumination and re- flectance should be considered to regularize the solution space. Qualitatively speaking, the illumination should be piece-wisely smooth, capturing the structure of the objects in the scene, while the reflectance should present the physical characteristics of the observed scene, capturing its texture information. Here, texture refers to the small patterns in object surface, which are similar in local statistics [54].
光照和反射率在结构和纹理方面的先验假设:STAR 的物理先验基础
Retinex 模型 (1) 将观察到的场景分解为光照和反射分量。该问题是高度不适定的,为了使解空间规整,需要考虑适当的光照和反射率先验。定性地说,光照应该是分片平滑的,捕捉场景中物体的结构,而反射率应该呈现被观察场景的物理特征,捕捉其纹理信息。这里的纹理是指物体表面的小图案,在局部统计 [54 State of the Art in Example-based Texture Synthesis] 中类似。
Previous structure-texture decomposition methods often enforce the TV regularizers to preserve edges [36], [42], [62]. These TV regularizers simply enforce gradient similarity of the scene and extract the structure of the objects. There are two ways for structure-texture decomposition. One is to directly derive structure using structure-preserving techniques, such as edge-aware filters [65] and optimization based methods [9]. The other way is to extract structure from the estimated texture weights [62]. However, these techniques [9], [62], [65] are vulnerable to textures and produce ringing effect near edges. Moreover, the method [62] cannot extract scenes structures with similar appearances to those of the underlying textures.
先前全变分正则化在结构-纹理分解法中的问题:
先前的结构-纹理分解方法通常强制使用全变分正则化来保留边缘。这些全变分正则化只是简单地加强场景的梯度相似性,并提取物体的结构。结构-纹理分解有两种方法。
1. 使用结构保持技术直接推导结构,如边缘感知滤波器[65]和基于优化的方法[9]。
2. 从估计的纹理权重中提取结构 [62]。
问题:
这两种技术[9],[62],[65] 容易受到纹理的影响,并在边缘处产生振铃效应。此外,该方法[62]无法提取出与底层纹理外观相似的场景结构。
To better understand the power of these techniques for structure-texture extraction, we study two typical filters. The first is the TV filter [45], which computes the absolute gradients of an input image as a guidance map
The second is the mean local variance (MLV) [9], which can also be utilized for structure map estimation
where Ω is the local patch [13] around each pixel of O, |Ω| denotes the number of elements in Ω, and its size is set as 3 × 3 in all our experiments.
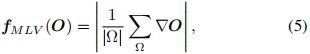
介绍本文结构-纹理滤波器的原版:TV 和 MLV
为了更好地理解这些技术在结构-纹理提取方面的力量,本文研究了两种典型的滤波器。
第一种是全变分滤波器 [45 Physica D: Nonlinear Phenomena 1992 Nonlinear total variation based noise removal algorithms],它计算作为导向图的输入图像的绝对梯度。
第二种是均值局部方差 (MLV)[9 ICCV 2017 A joint intrinsic-extrinsic prior model for Retinex],它也可以用于结构图估计。
To support that the TV and MLV filters can capture the structure of the scene, we visualize the effect of the two filters performed on extracting the structure/texture from an observed image. Here, the input RGB image (Figure 2 (a), up) is first transformed into the Hue-Saturation-Value (HSV) domain. Since the Value (V) channel (Figure 2 (a), down) reflects the illumination and reflectance information, we process this channel for the input image. It can be seen from Figure 2 (c) that, the TV and MLV filters can basically reflect the main structure of the input image. This point can be further validated by comparing the similarity of the two filtered image (Figure 2 (c)) with the edges extracted for the input image (Figure 2 (a)). To this end, we resort to a recently published edge detection method [38] to extract the main structure of the input image. By comparing the TV filtered image (Figure 3 (b)), MLV filtered image (Figure 3 (d)), and the edge extracted image (Figure 3 (c)), we observe that the TV and MLV filtered images already reflect the structure of the input image.
介绍 TV 和 MLV 在结构-纹理 提取的可视化效果:
为了支持 TV 和 MLV 滤波器能够捕捉场景的结构,本文将这两种滤波器在从观测图像中提取结构/纹理时的效果可视化。在这里,首先将输入的 RGB 图像 (图 2 (a), up) 转换为色调-饱和度-值 (HSV) 域。因为值 (V) 通道 (图 2 (a)向下) 反映了光照和反射率信息,对输入图像处理这个通道。从图 2 (c) 可以看出,TV 和 MLV 滤波器基本可以反映输入图像的主体结构。通过比较两个滤波后的图像 (图 2 (c)) 与为输入图像提取的边缘 (图 2 (a)) 的相似性,可以进一步验证这一点。为此,本文采用了最近发布的边缘检测方法 [ 38 CVPR 2017 / TPAMI 2019 Richer convolutional features for edge detection ] 来提取输入图像的主体结构。通过比较 TV 滤波后的图像 (图 3 (b))、MLV 滤波后的图像 (图 3 (d)) 和边缘提取图像 (图 3 (c)),们可以观察到 TV 和 MLV 滤波后的图像已经反映了输入图像的结构。

Fig. 2: Comparisons on the exponentiated total variation (ETV) and exponentiated mean local variance (EMLV) filters on structure and texture extraction. For an input RGB image (a), V refers to its Value channel in HSV space.

Fig. 3: Comparison of TV filtered image (b), MLV filtered image (d), and the edge extracted image (c) of the input image (a). It can be seen that the TV and MLV filtered images can roughly reflect the structure of the input image.
Existing TV and MLV filters described in Eqns. (4) and (5) cannot be directly utilized in our problem, since they are prone to capture structural information. As described in Retinex theory [30], [32], larger derivatives are attributed to the changes in reflectance, while smaller derivatives are emerged in the smooth illumination. Therefore, by exponential growth or decay, these local derivatives will reflect more clearly the corresponding content structure or detailed textures, as has been illustrated in Figure 2. To this end, we introduce an exponential version of local derivatives for flexible structure and texture estimation. Specifically, we add an exponent term to the TV and MLV filtering operations. By this way, we can make the two filters more flexible for separate structure and
and the exponentiated MLV (EMLV) filter as
where | | denotes the number of elements in and γ is the exponent determining the sensitivity to the gradients of O. Note that we evaluate the two exponentiated filters Eqns. (6) and (7) by visualizing their effects on a test image (i.e., Figure 2 (a), top). This RGB image is first transformed into the Hue-Saturation-Value (HSV) domain, and the decomposition is performed in the Value (V) channel. In Figure 2 (b)-(e), we plot the filtered images for the V channel of the input image. It is noteworthy that, with γ = 0.5, the ETV and EMLV filters roughly reveal the textures of the test image, while with γ
{1, 1.5, 2}, the ETV and EMLV filters tend to extract the structural edges.

提出本文采用的 结构-纹理 滤波器: ETV 和 EMLV(在 TV 和 MLV基础上,改成指数形式)
公式 (4) 和 (5) 中描述的现有 TV 和 MLV 滤波器。在我们的问题中不能直接使用,因为它们容易捕获结构信息。在 Retinex 理论 [30],[32] 中,较大的导数归因于反射率的变化,较小的导数出现在光滑照明下。因此,通过指数增长或衰减,这些局部导数将更清楚地反映相应的内容结构或详细的纹理,如图 2 所示。为此,引入了一种用于柔性结构和纹理估计的指数形式的局部导数。具体来说,我们在 TV 和 MLV 滤波操作中添加了一个指数项。通过这种方法,我们可以使两个滤波器在不同的结构,如公式 (6)和(7),其中  表示元素的数量,γ 是决定对 O 的梯度灵敏度的指数。注意,我们计算了两个指数滤波器公式 (6) 和 (7) 通过在测试图像上可视化它们的效果 (如图 2 (a),顶部)。首先将该 RGB 图像变换到色调-饱和度-值 (HSV) 域,在值 (V) 通道进行分解。在图 2 (b)-(e) 中,我们绘制了输入图像的 V 通道滤波后的图像。值得注意的是,当 γ = 0.5 时,ETV 和 EMLV 滤波器大致揭示了测试图像的纹理,而当 γ{1,1.5, 2} 时,ETV 和 EMLV 滤波器倾向于提取结构边缘。
表示元素的数量,γ 是决定对 O 的梯度灵敏度的指数。注意,我们计算了两个指数滤波器公式 (6) 和 (7) 通过在测试图像上可视化它们的效果 (如图 2 (a),顶部)。首先将该 RGB 图像变换到色调-饱和度-值 (HSV) 域,在值 (V) 通道进行分解。在图 2 (b)-(e) 中,我们绘制了输入图像的 V 通道滤波后的图像。值得注意的是,当 γ = 0.5 时,ETV 和 EMLV 滤波器大致揭示了测试图像的纹理,而当 γ{1,1.5, 2} 时,ETV 和 EMLV 滤波器倾向于提取结构边缘。
Motivated by this observation, we introduce a structure and texture aware weighting scheme for illumination and reflectance decomposition. Specifically, we set I_0 = R_0 = O^0.5, the ETV based weighting matrix as
and the EMLV based weighting matrix as:
where γ_s > 1 and γ_t < 1 are two exponential parameters to adjust the structure and texture awareness for illumination and reflectance decomposition. As will be demonstrated in V, the values of γ_s and γ_t influence the performance of the Retinex decomposition. Due to considering local variance information, the EMLV filter (Eqn. (9)) can reveal details and preserve structures better than the ETV filter (Figure 2). This point will also be validated in V.

基于此,本文引入了一种结构和纹理感知加权方案来分解光照和反射率。设 I_0 = R_0 = O^0.5,基于 ETV 的权重矩阵为公式(8),其中 γ_s > 1 and γ_t < 1 是调整结构和纹理感知的两个指数参数,用于照明和反射率分解。γ_s 和 γ_t 的值影响 Retinex 分解的性能。由于考虑了局部方差信息,EMLV 滤波器 (Eqn.(9)) 能够比 ETV 滤波器更好地揭示细节和保存结构 (图2)。
一种结构和纹理感知 Retinex 模型 (2020 TIP) (2 of 2)
https://blog.csdn.net/u014546828/article/details/114184641?spm=1001.2014.3001.5501
Method: Structure and Texture Aware Retinex Model
......