LightM-UNet(2024 CVPR)
| 论文标题 | LightM-UNet: Mamba Assists in Lightweight UNet for Medical Image Segmentation |
|---|---|
| 论文作者 | Weibin Liao, Yinghao Zhu, Xinyuan Wang, Chengwei Pan, Yasha Wang and Liantao Ma |
| 发表日期 | 2024年01月01日 |
| GB引用 | > Weibin Liao, Yinghao Zhu, Xinyuan Wang, et al. LightM-UNet: Mamba Assists in Lightweight UNet for Medical Image Segmentation[J]., 2024. > [1]Weibin Liao, Yinghao Zhu, Xinyuan Wang, et al. LightM-UNet: Mamba Assists in Lightweight UNet for Medical Image Segmentation[J]. Arxiv E-prints, 2024, abs/2403.05246. |
| DOI | 10.48550/arXiv.2403.05246 |
摘要
UNet及其变体在医学图像分割中得到了广泛的应用。然而,这些模型,特别是基于Transformer架构的模型,由于参数数量众多和计算负担重,给移动健康应用带来了挑战。最近,以Mamba为代表的State Space Models(SSMs)作为CNN和Transformer架构的有力竞争者出现。基于此,我们采用Mamba作为UNet中CNN和Transformer的轻量级替代品,旨在解决真实医疗环境中计算资源限制带来的挑战。为此,我们引入了轻量级的Mamba UNet(LightM-UNet),它在一个轻量级框架中集成了Mamba和UNet。具体来说,LightM-UNet以纯粹的Mamba方式利用残差视觉Mamba层提取深层语义特征和建模长距离空间依赖关系,具有线性计算复杂度。在两个真实世界的2D/3D数据集上进行的广泛实验表明,LightM-UNet超越了现有的最先进文献。值得注意的是,与著名的nnU-Net相比,LightM-UNet在显著降低参数和计算成本116倍和21倍的同时,实现了更优越的分割性能。这突显了Mamba在促进模型轻量化方面的潜力。我们的代码实现公开可访问于https://github.com/MrBlankness/LightM-UNet。
研究问题
基于Transformer架构的模型,由于参数数量众多和计算负担重,给移动健康应用带来了挑战。
- 残差视觉Mamba层(RVM Layer):用于提取深层语义特征,同时几乎不增加新的参数和计算复杂度。
- Vision State-Space Module(VSS Module):用于长距离空间建模,通过并行分支和Hadamard乘积来聚合特征。
- 编码器和解码器块:编码器块仅包含Mamba结构,解码器块用于解码特征图并恢复图像分辨率。
研究方法
论文通过以下主要方法解决了医疗图像分割模型的轻量化问题:
- 引入Mamba模型:Mamba是一种状态空间模型(SSM),它能够有效地建立长距离依赖关系,并且具有线性的输入大小复杂度。论文中提出使用Mamba作为UNet中的轻量级替代方案,以减少模型的参数数量和计算负担。
- 设计LightM-UNet架构:LightM-UNet结合了UNet的架构和Mamba的特点,创建了一个轻量级的网络。这个网络在保持UNet的对称U形结构的同时,通过集成Mamba来提取深层语义特征和建模长距离空间依赖。
- 提出残差视觉Mamba层(RVM Layer):为了在不增加额外参数和计算复杂度的情况下增强SSM的能力,论文提出了RVM Layer。这一层利用残差连接和调整因子来提取图像的深层特征,并增强对长距离空间依赖的建模能力。
- 实现Vision State-Space Module(VSS Module):VSS Module用于长距离空间建模,它通过两个并行分支处理特征,并通过Hadamard乘积聚合特征,以生成具有相同形状的输出。
- 优化编码器和解码器块:LightM-UNet的编码器块仅包含Mamba结构,以最小化参数和计算成本。解码器块则用于解码特征图并恢复图像分辨率,同时利用跳跃连接提供多级特征图。
- 实验验证:通过在LiTs和Montgomery&Shenzhen数据集上的实验,论文验证了LightM-UNet在2D和3D分割任务中的性能。实验结果表明,LightM-UNet在参数数量和计算成本上显著低于现有的最先进模型,同时在性能上达到了或超过了这些模型。
- 消融研究:为了证明所提出模块的有效性,论文进行了消融研究,分析了在UNet框架中CNN、Transformer和Mamba的表现,并验证了RVM Layer中调整因子和残差连接的重要性。
通过这些方法,论文成功地开发了一个轻量级且高效的医疗图像分割模型,该模型在保持高性能的同时,显著降低了模型的参数数量和计算成本。
LightM-UNet以纯Mamba的方式利用Residual Vision Mamba Layer来**提取深度语义特征,并建模长期空间依赖关系,具有线性计算复杂度**。
技术上,我们提出了残差视觉Mamba层(RVM层),以纯Mamba方式从图像中提取深度特征。通过引入最少的新参数和计算开销,我们**利用残差连接和调整因子,进一步增强了SSM模拟视觉图像中长距离空间依赖的能力**。
(以3D版本为例的方法论)
总体架构
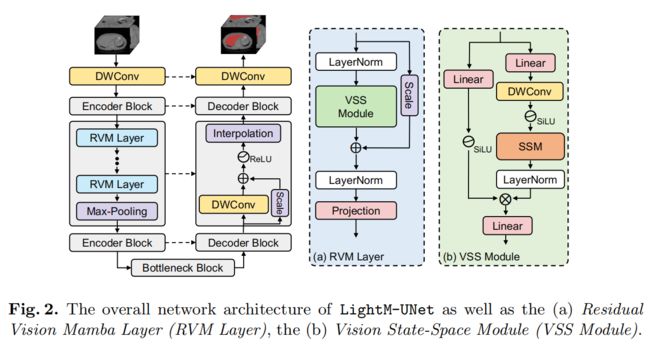
提出的LightM-UNet的整体架构如图2所示。
给定一个输入图像 I ∈ R C × H × W × D I\in\mathbb{R}^{C\times H\times W\times D} I∈RC×H×W×D ,其中 C C C、 H H H、 W W W 和 D D D分别表示 3 D 3D 3D医学图像的通道数、高度、宽度和切片数。LightM-UNet首先使用深度卷积(DWConv)层进行浅层特征提取,生成浅层特征图 F S ∈ R 32 × H × W × D F_S\in\mathbb{R}^{32\times H\times W\times D} FS∈R32×H×W×D,其中32表示固定的滤波器数量。
为什么使用深度卷积(DWConv)层进行浅层特征提取?
- DWConv可以有效地降低网络的复杂度,减少训练参数的数目。它通过局部连接、权值共享及池化操作等特性,使得网络更轻量级。
- DWConv使模型对平移、扭曲、缩放具有一定程度的不变性,并具有强鲁棒性和容错能力。这有利于浅层特征提取。
- DWConv层可以提取图像的局部特征,保留空间信息。这对于后续深层特征提取和语义建模非常有用。
- 在LightM-UNet中,使用DWConv层进行浅层特征提取,可以减少参数和计算量,使得整个网络更轻量级。这与LightM-UNet的设计目标一致。
- DWConv层输出的特征图,可以直接作为后续Encoder Block的输入,参与深层特征提取和建模。
综上所述,使用DWConv层进行浅层特征提取,可以有效地降低网络复杂度,同时保留有用的局部特征信息,为深层特征建模打下良好基础。这与LightM-UNet的轻量化和高性能目标是一致的。
相对于其他卷积(如普通卷积、点卷积、空洞卷积等),有什么优势吗?
- 参数数量减少:DWConv通过分离输入通道和输出通道的卷积操作,只对输入的每个通道单独进行卷积,大大减少了参数数量。对于输入通道数为C的图像,普通卷积的参数数量为C×C×k×k(k为卷积核大小),而DWConv的参数数量仅为C×k×k。这降低了模型的复杂度和内存占用。
- 计算效率提高:由于参数数量减少,DWConv的计算效率相比普通卷积更高。这对于移动设备和边缘计算等资源受限的场景尤为重要。
- 保持空间信息:DWConv保留了输入特征图的空间信息,因为每个输入通道的卷积操作都是独立的。这有助于在后续的神经网络层中保持位置信息。
- 易于集成:DWConv可以很容易地集成到现有的神经网络架构中,作为单独的层使用,或者与其他类型的卷积层组合使用。
相比于其他卷积的劣势:
- 普通卷积:相比DWConv,普通卷积的参数数量多,计算量大,但在某些情况下能够更好地捕捉多通道之间的交互信息。
- 点卷积:点卷积(Pointwise Convolution)实际上是一种1×1的卷积,用于实现跨通道的交互。它的参数数量比DWConv多,但能够灵活地融合不同通道的信息。
- 空洞卷积:空洞卷积(Atrous Convolution)通过引入空洞来扩大感受野,但不增加参数数量。它在某些任务中能够提供更大的感受野,但相比DWConv,空洞卷积的计算效率可能较低。
总的来说,DWConv在轻量化和计算效率方面具有优势,适合用于构建轻量级的神经网络模型,尤其是在资源受限的设备上。然而,具体使用哪种卷积操作还需要根据具体的应用场景和任务需求来决定。
那在实际应用中怎么选择呢?
任务需求:
如果任务需要模型具有很高的空间分辨率和细节捕捉能力,可能会倾向于使用普通卷积。 如果任务需要模型具有较宽的视野和捕捉长期依赖关系,可能会选择空洞卷积。 对于轻量级模型或移动设备上的实时任务,深度卷积可能是更好的选择。
资源限制:
在资源受限的环境(如移动设备、嵌入式系统)中,深度卷积由于其较低的参数数量和计算复杂度而更具优势。 如果计算资源不是限制因素,可以使用普通卷积或点卷积来构建更复杂的模型。
模型性能:
需要评估不同卷积类型对模型性能的影响。有时,虽然深度卷积减少了参数和计算量,但可能会牺牲一些性能。需要通过实验来确定最佳的平衡点。 可以通过消融研究来比较不同卷积类型对模型性能的影响。
训练时间:
深度卷积通常训练速度更快,因为它有更少的参数需要优化。 普通卷积和空洞卷积的训练时间可能更长,因为它们有更多的参数。
模型集成:
考虑到模型是否需要与其他组件或网络层集成。例如,深度卷积可以很容易地与其他类型的卷积层组合使用,形成混合卷积层。
实际应用场景:
对于实时应用,如自动驾驶、视频监控等,需要快速响应,因此轻量级模型和深度卷积可能更合适。 对于需要高精度和复杂特征提取的任务,如医学图像分析,可能会使用普通卷积或空洞卷积。
最终,选择哪种卷积类型通常需要通过实验来确定。可以尝试不同的卷积类型,并使用验证集来评估模型的性能,从而找到最适合当前任务和资源限制的卷积类型。
随后,LightM-UNet结合三个连续的编码器块(Encoder Blocks)来从图像中提取深度特征。在每个编码器块之后,特征图的通道数翻倍,而分辨率减半。因此,在第 l l l个编码器块中,LightM-UNet提取深度特征 F l D ∈ R ( 32 × 2 l ) × ( H / 2 l ) × ( W / 2 l ) × ( D / 2 l ) F_l^D\in \mathbb{R}^{(32\times2^l)\times(H/2^l)\times(W/2^l)\times(D/2^l)} FlD∈R(32×2l)×(H/2l)×(W/2l)×(D/2l),其中 I ∈ { 1 , 2 , 3 } I\in\{1,2,3\} I∈{ 1,2,3}。
在此之后,LightM-UNet使用一个瓶颈块(Bottleneck Block)来模拟长距离空间依赖,同时保持特征图的大小不变。接着,LightM-UNet整合了三个连续的解码器块(Decoder Blocks)进行特征解码和图像分辨率恢复。在每个解码器块之后,特征图的通道数减半,分辨率翻倍。最后,最后一个解码器块的输出达到与原始图像相同的分辨率,包含32个特征通道。LightM-UNet使用深度卷积(DWConv)层将通道数映射到分割目标的数量,并应用SoftMax激活函数来生成图像掩码。与UNet的设计一致,LightM-UNet也采用跳跃连接(skip connections)为解码器提供多级特征图。
Encoder Block
为了最小化参数数量和计算成本
LightM-UNet采用仅包含Mamba结构的编码器块(Encoder Blocks)来从图像中提取深度特征。具体来说,给定一个特征图 F l ∈ R C ~ × H ~ × W ~ × D ~ F_l\in\mathbb{R}^{\widetilde{C}\times\widetilde{H}\times\widetilde{W}\times\widetilde{D}} Fl∈RC ×H ×W ×D <