LeetCode高频题刷题笔记(五)哈希表
基础知识
哈希表中的元素没有顺序、不会重复。
哈希表(unordered_map)元素格式 key+value 关不关心重复次数都可使用(如果需要有序,那么就用map)
迭代器 unordered_map
哈希集合(unordered_set)元素格式 key 不关心重复次数时可使用(如果需要集合是有序的,那么就用set)
基本操作:begin()、end()、empty()、size()、erase()、at()、clear()、find()、count()
题目
1.模拟行走机器人( LeetCode 874 )
难度: 中等
题目表述:
机器人在一个无限大小的 XY 网格平面上行走,从点 (0, 0) 处开始出发,面向北方。该机器人可以接收以下三种类型的命令 commands :
-2 :向左转 90 度
-1 :向右转 90 度
1 <= x <= 9 :向前移动 x 个单位长度
在网格上有一些格子被视为障碍物 obstacles 。第 i 个障碍物位于网格点 obstacles[i] = (xi, yi) 。
机器人无法走到障碍物上,它将会停留在障碍物的前一个网格方块上,但仍然可以继续尝试进行该路线的其余部分。返回从原点到机器人所有经过的路径点(坐标为整数)的最大欧式距离的平方。(即,如果距离为 5 ,则返回 25 )
代码(C++):
class Solution {
public:
int robotSim(vector<int>& commands, vector<vector<int>>& obstacles) {
//每个方向前进时的坐标增量
int dx[4] = {0, 1, 0, -1};
int dy[4] = {1, 0, -1, 0};
int x = 0, y = 0;
int di = 0;//方向 北0 东1 南2 西3
set<pair <int, int>> obstacleSet;
for (const auto &o: obstacles) {
obstacleSet.insert({o[0], o[1]});
}
int ans = 0;
for (int cmd: commands) {
if (cmd == -2) {
di = (di + 3) % 4;
} else if (cmd == -1) {
di = (di + 1) % 4;
} else {
for (int k = 0; k < cmd; k++) {
int tmp_x = x + dx[di];
int tmp_y = y + dy[di];
// 先尝试往前走,没遇到障碍物,才给x,y赋值,才真实地往前走一步
if (obstacleSet.find(make_pair(tmp_x, tmp_y)) == obstacleSet.end()) {
x = tmp_x;
y = tmp_y;
ans = max(ans, x * x + y * y);
} else { // 遇到障碍物停止
break;
}
}
}
}
return ans;
}
};
题解: 情景模拟
unordered_set
make_pair 可换 {}
⭐2.串联所有单词的子串( LeetCode 30 )
难度: 困难
题目表述:
给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。
s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。返回所有串联字串在 s 中的开始索引。你可以以 任意顺序 返回答案。
代码(C++):
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> ansL;
int n = words.size();
if (n == 0) return ansL;
int k = words[0].size();
int m = s.size();
unordered_map<string, int> ori;
for (const auto& w: words) {
ori[w]++;
}
for (int i = 0; i < k && i < m - n * k + 1; i++) {
// 可套用之前总结的滑动窗口模板
int r = i, l = i;
unordered_map<string, int> cnt;
while (r < m - k + 1) {
cnt[s.substr(r, k)]++;
if (cnt == ori) {
ansL.push_back(l);
}
if (r - l >= (n - 1) * k) {
cnt[s.substr(l, k)]--;
if (cnt[s.substr(l, k)] == 0) {
cnt.erase(s.substr(l, k));
}
l += k;
}
r += k;
}
}
return ansL;
}
};
题解: 滑动窗口
在化繁为简之后,可套用滑动窗口模板,重点是理解使用k次滑动窗口的原因。
记words 的长度为 n,words 中每个单词的长度为 k,s 的长度为 m。首先需要将 s 划分为单词组,每个单词的大小均为 k(首尾除外),这样的划分方法有 k 种,即滑动窗口的首字母有k种,那么对每种划分都使用一次完整的滑动窗口即可。
3.数组的度( LeetCode 697 )
难度: 简单
题目表述:
给定一个非空且只包含非负数的整数数组 nums,数组的 度 的定义是指数组里任一元素出现频数的最大值。你的任务是在 nums 中找到与 nums 拥有相同大小的度的最短连续子数组,返回其长度。
代码(C++):
class Solution {
public:
int findShortestSubArray(vector<int>& nums) {
unordered_map<int, vector<int>> hash;
for (int i = 0; i< nums.size(); i ++) {
if (hash.count(nums[i])) {
hash[nums[i]][0]++;
hash[nums[i]][2] = i;
} else {
hash[nums[i]] = {1, i, i};
}
}
int min_len = 0, max_degree = 0;
for (const auto& [_, h]: hash) {
if (h[0] > max_degree) {
max_degree = h[0];
min_len = h[2] - h[1] + 1;
} else if (h[0] == max_degree) {
min_len = min(min_len, h[2] - h[1] + 1);
}
}
return min_len;
}
};
题解:
使用哈希表实现该功能,每一个数映射到一个长度为 3 的数组,数组中的三个元素分别代表这个数出现的次数、这个数在原数组中第一次出现的位置和这个数在原数组中最后一次出现的位置。
4.子域名访问计数( LeetCode 811 )
难度: 中等
题目表述:
输入:cpdomains = [“9001 discuss.leetcode.com”]
输出:[“9001 leetcode.com”,“9001 discuss.leetcode.com”,“9001 com”]
代码(C++):
class Solution {
public:
vector<string> subdomainVisits(vector<string>& cpdomains) {
unordered_map<string, int> hash;
for (string &c: cpdomains) {
int space = c.find(' ');
int num = stoi(c.substr(0, space));
hash[c.substr(space + 1)] += num;
for (int i = space + 1; i < c.size(); i++) {
if (c[i] == '.') {
hash[c.substr(i + 1)] += num;
}
}
}
vector<string> res;
for (const auto& h: hash) {
res.push_back(to_string(h.second) + " " + h.first);
}
return res;
}
};
题解:
5.字母异位词分组( LeetCode 49 )
难度: 中等
题目表述:
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次。
代码(C++):
class Solution {
public:
// 排序
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> res;
unordered_map<string, vector<string>> cnts;
for (const auto &s: strs) {
string key = s;
sort(key.begin(), key.end());
cnts[key].emplace_back(s);
}
for (const auto &[_, str]: cnts) {
res.emplace_back(str);
}
return res;
}
// 计数
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>> res;
unordered_map<string, vector<string>> cnts;
for (const auto &s: strs) {
string cnt = string(26, '0');
for (const auto &c: s) {
cnt[c - 'a']++;
}
cnts[cnt].emplace_back(s);
}
for (const auto &[_, str]: cnts) {
res.emplace_back(str);
}
return res;
}
};
题解: 哈希表、字符串、排序
同一组字母异位词中的字符串具备相同点,可以使用相同点作为一组字母异位词的标志key,使用哈希表存储每一组字母异位词value。
6.有效的字母异位词( LeetCode 242 )
难度: 简单
题目表述:
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
代码(C++):
class Solution {
public:
bool isAnagram(string s, string t) {
if (s.length() != t.length()) return false;
vector<int> table(26, 0);
for (auto &c: s) {
table[c - 'a']++;
}
for (auto &c: t) {
table[c - 'a']--;
if (table[c - 'a'] < 0) {
return false;
}
}
return true;
}
};
题解:
由于字符串只包含 26 个小写字母,因此我们可以维护一个长度为 26 的频次数组 table。
7.查找共用字符( LeetCode 1002 )
难度: 简单
题目表述:
给你一个字符串数组 words ,请你找出所有在 words 的每个字符串中都出现的共用字符( 包括重复字符),并以数组形式返回。你可以按 任意顺序 返回答案。
代码(C++):
class Solution {
public:
vector<string> commonChars(vector<string>& words) {
vector<int> freq(26, 0), min_freq(26, INT_MAX);
for (auto& word: words) {
for (auto& c: word) {
freq[c - 'a']++;
}
for (int i = 0; i < 26; i++) {
min_freq[i] = min(min_freq[i], freq[i]);
}
freq = vector<int>(26, 0);
}
vector<string> ans;
for (int i = 0; i < 26; i++) {
while (min_freq[i]-- > 0) {
ans.emplace_back(1, i + 'a');
}
}
return ans;
}
};
题解:
找到字符 c 在所有字符串中出现次数的最小值。
emplace_back(1, i + ‘a’) 等价于 push_back(string(1, i + ‘a’))
构造函数 std::string(size_t n, char c);使用n个字符c初始化string对象。
此外,char转string还可以:
string s;
- s.push_back( c);
- s += c;
- s = c;
8.两个数组的交集( LeetCode 349 )
难度: 简单
题目表述:
给定两个数组 nums1 和 nums2 ,返回 它们的交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
代码(C++):
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> ans;
unordered_set<int> set1(nums1.begin(), nums1.end());
for (int x : nums2) {
if(set1.find(x) != set1.end()) {
ans.insert(x);
}
}
return vector<int>(ans.begin(), ans.end());
}
};
题解:
unordered_set只关心存在与否,不关心重复次数
9.快乐数( LeetCode 202 )
难度: 简单
题目表述:
编写一个算法来判断一个数 n 是不是快乐数。
代码(C++):
class Solution {
public:
int getNext(int n) {
int nn = 0;
while (n > 0) {
nn += (n % 10) * (n % 10);
n /= 10;
}
return nn;
}
// 哈希集合
bool isHappy(int n) {
unordered_set<int> st;
while (n != 1 && !st.count(n)){
st.insert(n);
n = getNext(n);
}
return n == 1;
}
// 快慢指针
bool isHappy(int n) {
int fast = n, slow = n;
while (fast != 1) {
slow = getNext(slow);
fast = getNext(getNext(fast));
if (slow == fast && fast != 1) {
return false;
}
}
return true;
}
};
题解:
1.用哈希集合检测循环
2.快慢指针(检测隐式链表是否有环)
10.三数之和( LeetCode 15 )
难度: 中等
题目表述:
nums[i] + nums[j] + nums[k] == 0
代码(C++):
class Solution {
public:
vector<vector<int>> threeSum(vector<int>& nums) {
sort(nums.begin(), nums.end());
int n = nums.size();
vector<vector<int>> res;
for (int i = 0; i < n - 2; i++) {
if (i > 0 && nums[i] == nums[i - 1]) continue;
if (nums[i] + nums[i + 1] + nums[i + 2] > 0) break;
if (nums[i] + nums[n - 2] + nums[n - 1] < 0) continue;
int l = i + 1, r = n - 1;
while (l < r) {
int sum = nums[i] + nums[l] + nums[r];
if (sum == 0) {
res.push_back({nums[i], nums[l], nums[r]});
while (l < r && nums[l] == nums[l + 1]) {
l++;
}
l++;
while (l < r && nums[r] == nums[r - 1]) {
r--;
}
r--;
} else if (sum > 0) r--;
else l++;
}
}
return res;
}
};
题解: 排序 + 双指针
11.四数之和( LeetCode 18 )
难度: 中等
题目表述:
nums[a] + nums[b] + nums[c] + nums[d] == target
代码(C++):
class Solution {
public:
vector<vector<int>> fourSum(vector<int>& nums, int target) {
vector<vector<int>> res;
sort(nums.begin(), nums.end());
int n = nums.size();
for (int i = 0; i < n - 3; i++) {
if (i > 0 && nums[i] == nums[i - 1]) continue;
if ((long) nums[i] + nums[i + 1] + nums[i + 2] + nums[i + 3] > target) break;
if ((long) nums[i] + nums[n - 3] + nums[n - 2] + nums[n - 1] < target) continue;
for (int j = i + 1; j < n - 2; j++) {
if (j > i + 1 && nums[j] == nums[j - 1]) continue;
if ((long) nums[i] + nums[j] + nums[j + 1] + nums[j + 2] > target) break;
if ((long) nums[i] + nums[j] + nums[n - 2] + nums[n - 1] < target) continue;
int l = j + 1, r = n - 1;
while (l < r) {
long sum = (long) nums[i] + nums[j] + nums[l] + nums[r];
if (sum == target) {
res.push_back({nums[i], nums[j], nums[l], nums[r]});
while (l < r && nums[l] == nums[l + 1]) {
l++;
}
l++;
while (l < r && nums[r] == nums[r - 1]) {
r--;
}
r--;
} else if (sum < target) l++;
else r--;
}
}
}
return res;
}
};
题解: 排序 + 双指针
12.四数相加 II( LeetCode 454 )
难度: 中等
题目表述:
nums1[i] + nums2[j] + nums3[k] + nums4[l] == 0
代码(C++):
class Solution {
public:
int fourSumCount(vector<int>& nums1, vector<int>& nums2, vector<int>& nums3, vector<int>& nums4) {
unordered_map<int, int> ab;
for (int a : nums1) {
for (int b : nums2) {
ab[a + b]++;
}
}
int count = 0;
for (int c : nums3) {
for (int d : nums4) {
count += ab[0 - c - d];
}
}
return count;
}
};
题解:
不用考虑有重复的四个元素
13.赎金信( LeetCode 383 )
难度: 简单
题目表述:
给你两个字符串:ransomNote 和 magazine ,判断 ransomNote 能不能由 magazine 里面的字符构成。
代码(C++):
class Solution {
public:
bool canConstruct(string ransomNote, string magazine) {
int record[26] = {0};
for (char &c: magazine) {
record[c - 'a']++;
}
for (char &c: ransomNote) {
if (record[c - 'a'] > 0) {
record[c - 'a']--;
} else return false;
}
return true;
}
};
题解:
小结
一般来说哈希表都是用来快速判断一个元素是否出现集合里。
接下来是常见的三种哈希结构:
-
数组: 是简单的哈希表,但是数组的大小是受限的!如果只包含小写字母(数组大小是26有限),那么使用数组来做哈希最合适不过。使用map的空间消耗要比数组大一些,因为map要维护红黑树或者符号表,而且还要做哈希函数的运算。所以数组更加简单直接有效!
-
set(集合): 没有限制数值的大小,就无法使用数组来做哈希表了。如果数组空间够大,但哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费。

-
map(映射):

注:红黑树就是一种二叉平衡搜索树
关键在于哈希表的key和value的选择
应用场景:不关心顺序,关心重复与否或重复次数
哈希表的 == 是判断key和value全部相同
其他C++知识点:
- 有名称的、可以获取到存储地址的表达式即为左值;反之则是右值
- 右值引用&&:指的是以引用传递(而非值传递)的方式使用 C++ 右值,和常量左值引用const auto& 不同的是,右值引用还可以对右值进行修改。C++11 标准新引入。
- 想要拷贝元素:for(auto x:range)
- 想要修改元素 : for(auto &&x:range) 右值引用
- 想要只读元素:for(const auto& x:range) 常量左值引用
- emplace_back和push_back的区别
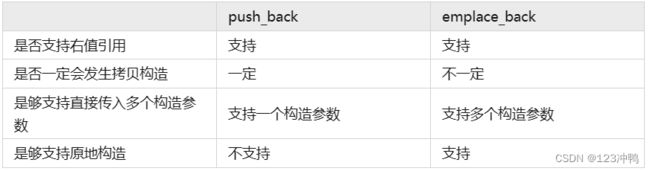
参考链接
玩转 LeetCode 高频 100 题
LeetCode 刷题攻略