mybatis缓存源码分析
mybatis缓存源码分析
背景
在java程序与数据库交互的过程中永远存在着性能瓶颈,所以需要一直进行优化.而我们大部分会直接将目标放到数据库优化,其实我们应该先从宏观上去解决问题进而再去解决微观上的问题.性能瓶颈体现在什么地方呢?第一网络通信开销,网络数据传输通信.一般jdbc的连接和创建一个个线程都需要网络开销.第二我们常用的比如mysql.Oracle这样的数据库数据都是存储在硬盘中的,硬盘中大量的数据不利于读写.第三关于java对象的复用.在jdbc中的Connection对象可以通过连接池进行复用,Statement对象的复用.
那么想要解决上述问题,基本都需要从数据库本身出发进行数据库优化,但是这些性能瓶颈我们是不好优化的.因为数据库是由厂商驱动来决定的. 所以缓存应运而生.
缓存的本质就是内存,缓存在我们现在应用的价值是程序与数据库之间搭建的一个桥梁,提高用户的查询效率,尽量避免数据库的硬盘查询.
换出策略
比如缓存中可以存1000个对象,每一个对象对应可以存对应数据库中的一页数据.那么要存1001页的时候,就会将多出来的对象采用序列化的方式存储在硬盘空间.而序列化必须要实现Serializable接口,还有json的方式也可以实现.但是传统的序列化是二进制的方式,而json是字符串在传输上面明显性能很差(字符串格式没有二进制占用空间小),一般不采用.
换出算法
LRU: 最不常用的对象会被换出到硬盘中(或者说最少使用的对象),通过给每个对象记录使用次数可以实现.
FIFO:先入先出,第一个进来的对象第一个将会被换出到硬盘中
缓存的分类
1.ORM框架集成缓存
Hibernate Mybatis JDO(Hive) 缓存
基于DAO层框架为业务提供缓存
将缓存存储在jvm的内存中,速度比较快不像第三方中间件会有网络开销
2.第三方中间件充当缓存
Redis Memcache
直接为java程序提供缓存服务
mybatis中如何使用缓存
使用动态代理实现缓存操作
下面看下关于操作数据库的一段代码
UserDAOImpl{
public List<User> queryAllUsers(){
//对缓存的操作
//--->Redis 获取 取到 直接返回
//没取到 访问数据库 执行JDBC
JDBC----> DB
}
public User queryUserById(int id){
//对缓存的操作
//--->Redis 获取 取到 直接返回
//没取到 访问数据库 执行JDBC
JDBC----> DB
}
}
上面是一个查询所有用户的操作,可以发现这里会先通过缓存去获取数据,没有取到才会向数据库获取数据.但是下面的通过id查询用户还会重复这种对缓存的操作.这样很明显虽然可以实现功能但是明显代码冗余,可以通过动态代理的方式对需要缓存的接口进行方法增强,mybatis这里是使用的AOP当然俩种方法都是没什么问题.下面通过代码来演示动态代理进行操作
创建ProductDAO接口
public interface ProductDAO {
public void save();
public Product queryProductById(int id);
public List<Product> queryAllProducts();
}
创建ProductDAOImpl实现类
public class ProductDAOImpl implements ProductDAO {
@Override
public void save() {
System.out.println("jdbc 的方式操作 数据库 完成 插入的操作");
}
@Override
public Product queryProductById(int id) {
System.out.println("jdbc 的方式基于ID 进行查询 " + id);
return new Product();
}
@Override
public List<Product> queryAllProducts() {
System.out.println("jdbc 的方式进行全表查询 ");
return new ArrayList();
}
}
创建代理类
public class TestMybaits2 {
/**
* 用于测试:创建DAO接口的代理
*/
@Test
public void test() {
ProductDAO productDAO = new ProductDAOImpl();
ProductDAO productDAOProxy = (ProductDAO) Proxy.newProxyInstance(TestMybaits2.class.getClassLoader(), new Class[]{ProductDAO.class}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//方法 只有以query开头,在进行缓存的处理 如果不是以query开头,就直接运行
if (method.getName().startsWith("query")) {
System.out.println("连接redis 查看数据是否 存在 如果存在 则直接返回 return data");
return method.invoke(productDAO, args);
}
//非查询方法
return method.invoke(productDAO, args);
}
});
//进行测试
productDAOProxy.save();
System.out.println("---------------------------------");
productDAOProxy.queryProductById(10);
System.out.println("---------------------------------");
productDAOProxy.queryAllProducts();
}
}
可以发现通过动态代理可以实现缓存,但是上面的代码只能将方法名中带有query的方法进行缓存,这样太过于死板不够灵活.下面采用注解的方式将其优化一下.
创建注解@Cache
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Cache {
}
将需要使用缓存的查询方法都在方法上加@Cache注解
public interface ProductDAO {
public void save();
public Product queryProductById(int id);
@Cache
public List<Product> queryAllProducts();
}
将代理测试类的业务逻辑修改为判断方法上是否有@Cache注解
public class TestMybaits2 {
/**
* 用于测试:创建DAO接口的代理
*/
@Test
public void test() {
ProductDAO productDAO = new ProductDAOImpl();
ProductDAO productDAOProxy = (ProductDAO) Proxy.newProxyInstance(TestMybaits2.class.getClassLoader(), new Class[]{ProductDAO.class}, new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//方法 只有以query开头,在进行缓存的处理 如果不是以query开头,就直接运行
// if (method.getName().startsWith("query")) {
// System.out.println("连接redis 查看数据是否 存在 如果存在 则直接返回 return data");
// return method.invoke(productDAO, args);
// }
Cache cache = method.getDeclaredAnnotation(Cache.class);
if (cache != null) {
System.out.println("连接redis 查看数据是否 存在 如果存在 则直接返回 return data");
return method.invoke(productDAO, args);
}
//非查询方法
return method.invoke(productDAO, args);
}
});
productDAOProxy.save();
System.out.println("---------------------------------");
productDAOProxy.queryProductById(10);
System.out.println("---------------------------------");
productDAOProxy.queryAllProducts();
}
mybatis封装的缓存
直接进入mybatis的cache接口源码,来看看定义了哪些方法
/**
* Copyright 2009-2015 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.ibatis.cache;
import java.util.concurrent.locks.ReadWriteLock;
/**
* SPI for cache providers.
*
* One instance of cache will be created for each namespace.
*
* The cache implementation must have a constructor that receives the cache id as an String parameter.
*
* MyBatis will pass the namespace as id to the constructor.
*
*
* public MyCache(final String id) {
* if (id == null) {
* throw new IllegalArgumentException("Cache instances require an ID");
* }
* this.id = id;
* initialize();
* }
*
*
* @author Clinton Begin
*/
//定义为一个借口,看看下面定义了哪些方法
public interface Cache {
/**官方注释上写的是这是一个缓存的标识符
* @return The identifier of this cache
*/
String getId();
/**向缓存中存储数据
* @param key Can be any object but usually it is a {@link CacheKey}
* @param value The result of a select.
*/
void putObject(Object key, Object value);
/**从缓存中获取数据
* @param key The key
* @return The object stored in the cache.
*/
Object getObject(Object key);
/**
* As of 3.3.0 this method is only called during a rollback
* for any previous value that was missing in the cache.
* This lets any blocking cache to release the lock that
* may have previously put on the key.
* A blocking cache puts a lock when a value is null
* and releases it when the value is back again.
* This way other threads will wait for the value to be
* available instead of hitting the database.
*
*
* @param key The key
* @return Not used
*/
Object removeObject(Object key);
/**
* Clears this cache instance
*/
void clear();
/**
* Optional. This method is not called by the core.
*
* @return The number of elements stored in the cache (not its capacity).
*/
int getSize();
/** 已经废除
* Optional. As of 3.2.6 this method is no longer called by the core.
*
* Any locking needed by the cache must be provided internally by the cache provider.
*
* @return A ReadWriteLock
*/
ReadWriteLock getReadWriteLock();
}
通过上述Cache接口源码中可以发现,这个缓存的存储结构很像Java语言中的Map集合.都有put方法根据key进行插入,和get方法通过key去获取数据.如果我们要使用Cache这一套缓存操作,那么就需要实现这个接口.
自定义实现缓存接口
定义MyMybatisCache实现Cache接口
/**
* 1. 存数据 存多个数据
* 2. key value
*/
public class MyMybatisCache implements Cache {
//定义一个map来进行缓存的存储
private Map<Object,Object> internalCache = new HashMap();
@Override
public String getId() {
//获取类名来做为缓存标识符
return getClass().getName() ;
}
@Override
public void putObject(Object key, Object value) {
//这里以下方法直接使用map集合的常用方法实现
internalCache.put(key,value);
}
@Override
public Object getObject(Object key) {
return internalCache.get(key);
}
@Override
public Object removeObject(Object key) {
return internalCache.remove(key);
}
@Override
public void clear() {
internalCache.clear();
}
@Override
public int getSize() {
return internalCache.size();
}
@Override
public ReadWriteLock getReadWriteLock() {
//废弃方法一般不实现,直接返回null.这里我们为了实现接口的完整性new了一个ReadWriteLock的实现类
return new ReentrantReadWriteLock();
}
}
可以发现通过map的方式可以实现Cache接口,那么还有另外一种可以直接使用redis来进行存储,这里只需要引入redis的java客户端也就是jedis来进行key/value的存储就可以实现.这里就不过多演示了.
mybatis实现的缓存接口
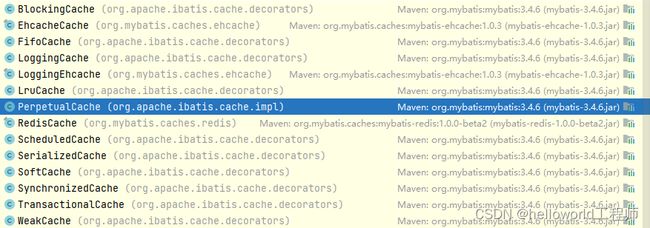
上述图片为mybatis中对Cache接口的实现,可以发现只有PerpetualCache是属于impl包下,其他的实现类都是在decorators包下.因为Cache的实现使用了装饰器设计模式,decorators包下的实现类都是来对PerpetualCache进行功能增强所以说最终还是通过PerpetualCache为主.下面直接来看看PerpetualCache源码,看看跟我们自己实现的有什么区别.
public class PerpetualCache implements Cache {
private final String id;
//可以发现源码中也是通过hashMap来实现的
private Map<Object, Object> cache = new HashMap<Object, Object>();
//这里的id是通过构造方法也就是初始化的时候由用户传入的
public PerpetualCache(String id) {
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public int getSize() {
return cache.size();
}
@Override
public void putObject(Object key, Object value) {
cache.put(key, value);
}
@Override
public Object getObject(Object key) {
return cache.get(key);
}
@Override
public Object removeObject(Object key) {
return cache.remove(key);
}
@Override
public void clear() {
cache.clear();
}
@Override
public ReadWriteLock getReadWriteLock() {
//这里废弃的方法也是并没有去做实现
return null;
}
@Override
public boolean equals(Object o) {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
if (this == o) {
return true;
}
if (!(o instanceof Cache)) {
return false;
}
Cache otherCache = (Cache) o;
return getId().equals(otherCache.getId());
}
@Override
public int hashCode() {
if (getId() == null) {
throw new CacheException("Cache instances require an ID.");
}
return getId().hashCode();
}
}
可以看出基本跟我们实现的方式一样,并没有什么区别.
装饰器的增强功能
FifoCache
增强换出功能使用先入先出的方式进行换出操作
LruCache
最少使用的缓存将被换出 (默认的装饰器)
LoggingCache
Cache增加日志功能
BlockingCache
保证同一时间只有一个线程到缓存中查找对应key的数据
ScheduledCache
设置一个时间间隔来清空缓存
SerializbledCache
自动完成key/value的序列化和反序列化操作
TransactionalCache
只有在事务操作成功时,把对应的数据防止在缓存中
装饰器的使用方法
/**
* 用于测试:Cache 与 装饰器
*/
@Test
public void test2() {
//创建PerpetualCache对象传入参数id
PerpetualCache perpetualCache = new PerpetualCache("sunshuai");
//将PerpetualCache对象作为参数提供给LruCache
LruCache lruCache = new LruCache(perpetualCache);
//也可以使用套娃将LRU换出算法作为参数提供给LoggingCache,使其拥有日志功能
LoggingCache loggingCache = new LoggingCache(lruCache);
}
关于设计模式区分
Mybatis大量增加装饰器设计模式
作用:为目标拓展功能(本职工作 核心功能)
装饰器 代理 类图 都一样
本质的区别:
装饰器:增加核心功能 和被装饰的对象做的是一件事
代理:增加额外功能 和被代理的对象做的是不同的事
无中生有
接口 --- 动态代理(动态字节码技术)自动创建接口实现类
Cache在Mybaits运行过程中如何进行应用
1.Mybatis缓存二层的体系
1)一级缓存 (默认开启)
注意事项:一级缓存只对本SqlSession生效,换SqlSession,不能在利用原有SqlSession对应的一级缓存
查询操作也是有事务操作的,在一些特殊场景如:加悲观锁(需要通过加锁将查询的数据锁住让别人不能影响数据),二级缓存(只有加上事务myabtis的二级缓存才会有效果)
一级缓存相关源码分析
mybatis查询流程:
sqlSession.getMapper() ------->UserDAO接口的实现类(代理)
sqlSession.selectAll()
executor
|-statementHandler
|- …
.selectOne()
之前我们学过executor接口实现是通过BaseExecutor接口,然后有三个实现类,下面展示下executor的类图
executor
|
BaseExecutor
| | |
SimpleExecutor ReuseExecutor BatchExecutor
这是一个标准的适配器设计模式,在实现接口的过程中,只想或者只能实现其部分方法可以考虑适配器设计模式.那么缓存操作肯定实在BaseExcutor中去体现的,因为不可能每个实现类都去实现一级缓存的操作.下面我们直接进入BaseExecutor源码
public abstract class BaseExecutor implements Executor {
private static final Log log = LogFactory.getLog(BaseExecutor.class);
protected Transaction transaction;
protected Executor wrapper;
protected ConcurrentLinkedQueue<DeferredLoad> deferredLoads;
//缓存的数据存储在hashmap中 (对应mybatis的基本操作)
protected PerpetualCache localCache;
//缓存存储过程
protected PerpetualCache localOutputParameterCache;
protected Configuration configuration;
protected int queryStack;
private boolean closed;
protected BaseExecutor(Configuration configuration, Transaction transaction) {
this.transaction = transaction;
this.deferredLoads = new ConcurrentLinkedQueue<DeferredLoad>();
this.localCache = new PerpetualCache("LocalCache");
this.localOutputParameterCache = new PerpetualCache("LocalOutputParameterCache");
this.closed = false;
this.configuration = configuration;
this.wrapper = this;
}
那么缓存肯定是在查询操作中去介入的,继续看源码中的查询方法.
//查询中抽象方法由适配器实现类实现,所以我们只需要关注query()方法
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//获取sql语句
BoundSql boundSql = ms.getBoundSql(parameter);
//创建缓存的key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
//重载进入下面的query()方法
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
//查询返回结果list
List<E> list;
try {
queryStack++;
//缓存相关操作--如果从缓存中没有获取到数据执行else内容直接查询数据库,查询到直接返回list
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
//这个操作是处理存储过程中的输出参数
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//正常查询数据库操作
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
//抽象方法会交给适配器的实现类来进行实现
protected abstract <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql)
throws SQLException;
protected abstract <E> Cursor<E> doQueryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds, BoundSql boundSql)
throws SQLException;
继续进入queryFromDatabase()方法查看数据库操作如何执行
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
//向缓存中存储一个枚举类型的占位符
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//执行数据库查询操作,这里我们就不继续往下看源码了因为是由simlpeExecutor去执行
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
//将查询到的数据存储在缓存中
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
2)二级缓存(全局缓存)
默认关闭
激活二级缓存
1.mybatis-config.xml中加入setting的配置(现在版本已经不需要进行配置了,默认开启)
2.mapper文件中引入二级缓存Cache标签(必须要配置)
3.查询时需要加上 userCache=true属性(也是可以不用配置的)
4.事务存在
核心装饰器:目标增强核心功能
CachingExecutor ---- SimpleExecutor ReuseExecutor 增强缓存功能(通过套娃)
CachingExecutor ce = new CachingExecutor(simpleExecutor)
上述代码 在mybatis源码中的哪个位置体现呢
通过在idea直接搜索new CachingExecutor(),可以发现在Configuration类中有这一操作,下面见源码
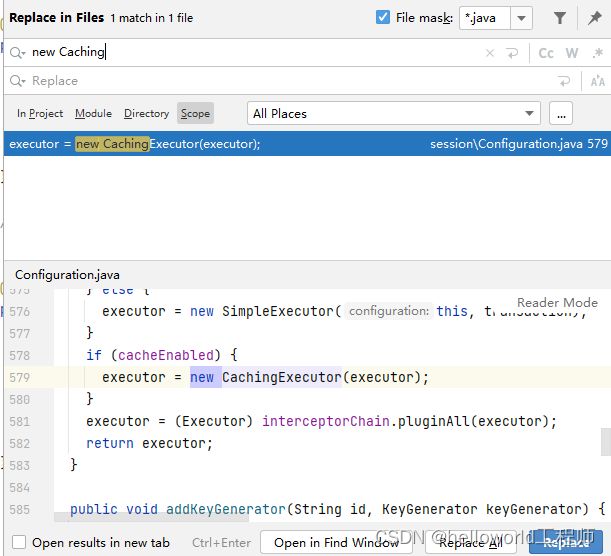
可以发现通过上面的cacheEnabled属性会使用套娃给executor增强缓存的功能,而这个cacheEnabled属性正是对应的我们mybatis-config配置文件中setting标签的配置.默认为true,这就是我们为什么现在不需要对setting进行配置的原因.按理论上来说mybatis的全局缓存也就是二级缓存应该也是默认开启的,但是需要在mapper文件中进行配置才会生效.继续追溯 CachingExecutor()构造方法看看CachingExecutor是如何提供缓存操作的.
//可以发现CachingExecutor中有很多方法,那么缓存操作肯定是为查询来提供的所以直接看到CachingExecutor中的query()方法
public class CachingExecutor implements Executor {
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
public CachingExecutor(Executor delegate) {
this.delegate = delegate;
delegate.setExecutorWrapper(this);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
//这里创建了缓存的key
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
//然后是一个方法重载进入到下面的query方法
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> Cursor<E> queryCursor(MappedStatement ms, Object parameter, RowBounds rowBounds) throws SQLException {
flushCacheIfRequired(ms);
return delegate.queryCursor(ms, parameter, rowBounds);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//首先从mappedStatement中获取缓存
Cache cache = ms.getCache();
//如果缓存不为空,那么判断mappedStatement中是否添加了isUserCache=true的属性,然后从缓存中获取数据.如果数据为空,则认为是第一次查询那么就会直接查询数据库然后将查询到的数据put到缓存中,最后返回list数据.
if (cache != null) {
//这里是如果sql语句加上了清除缓存的属性才会进行清除,查询默认为false也就是默认查询不清除缓存,增删改默认为true,这个默认值是在MappedStatement创建时赋值的
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//如果没有获取到缓存那么直接查询数据库
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
...
}
以上俩种查询数据库的操作虽然代码是一样的,但是最初设计是完全不同,缓存不为空时,并且在查询语句上加了Cache标签时,才会查询.而下面的是没有在mapper文件中写上Cache标签的查询.然后继续看增删改的执行流程
@Override
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
//因为默认设置为true,所以会清除缓存主要是怕读到脏数据
flushCacheIfRequired(ms);
return delegate.update(ms, parameterObject);
}
2.缓存类的创建
直接搜索useNewCache()方法,进入他的源码
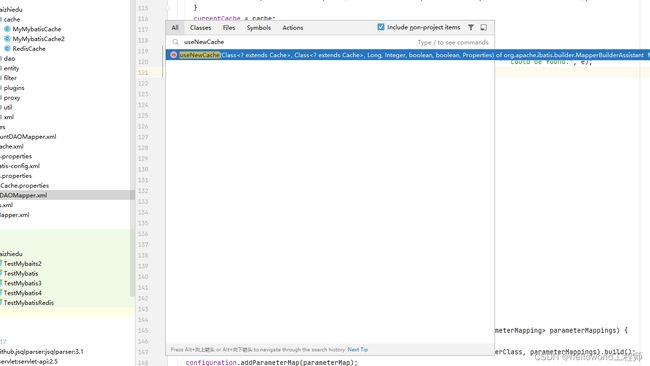
可以查看这个方法被哪里调用过

一个是xml的方式,另外一个是使用注解的方式.分别对应了俩种方式去开启缓存操作,通过快捷键Ctrl +Alt+H对着useNewCache()方法可以查看方法的调用以及重载调用结构图
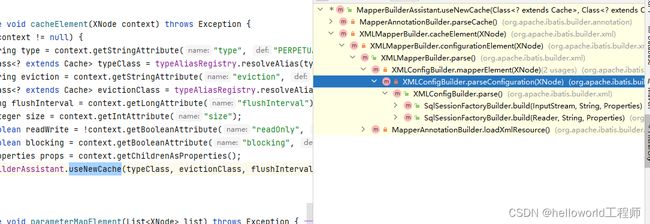
因为我们还是主要分析XML文件的方式,所以直接看看configurationElement()这个方法
private void configurationElement(XNode context) {
try {
String namespace = context.getStringAttribute("namespace");
if (namespace == null || namespace.equals("")) {
throw new BuilderException("Mapper's namespace cannot be empty");
}
builderAssistant.setCurrentNamespace(namespace);
cacheRefElement(context.evalNode("cache-ref"));
//当解析到配置文件的cache标签后,便会为我们在ms中创建cache也就是会调用useNewCache()方法
cacheElement(context.evalNode("cache"));
parameterMapElement(context.evalNodes("/mapper/parameterMap"));
resultMapElements(context.evalNodes("/mapper/resultMap"));
sqlElement(context.evalNodes("/mapper/sql"));
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
} catch (Exception e) {
throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);
}
}
缓存的创建流程
Mybatis解析XML配置文件
---|Mybatis-config.xml
---|Mapper 读取mapper.xml文件
---|
---|useNewCache()
Mybatis创建二级缓存时
使用构建者Builder设计模式创建对象
对比构建者与工厂创建对象
工厂 创建对象
一般为XXXFactory只注重最终的结果
构建者 创建对象
一般为 new XXXBuilder().build()注重零件组装成最后的产品
下面来看看build()方法如何来构建Cache的,首先继续看到useNewCache()这个方法
public Cache useNewCache(Class<? extends Cache> typeClass,
Class<? extends Cache> evictionClass,
Long flushInterval,
Integer size,
boolean readWrite,
boolean blocking,
Properties props) {
//可以看到这里使用构建者设计模式将零件组装创建对象
Cache cache = new CacheBuilder(currentNamespace)
.implementation(valueOrDefault(typeClass, PerpetualCache.class))
.addDecorator(valueOrDefault(evictionClass, LruCache.class))
.clearInterval(flushInterval)
.size(size)
.readWrite(readWrite)
.blocking(blocking)
.properties(props)
.build();
configuration.addCache(cache);
currentCache = cache;
return cache;
}
这里直接进入build()方法看看具体做了什么操作
public Cache build() {
//设置默认的实现
setDefaultImplementations();
Cache cache = newBaseCacheInstance(implementation, id);
setCacheProperties(cache);
if (PerpetualCache.class.equals(cache.getClass())) {
for (Class<? extends Cache> decorator : decorators) {
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
cache = setStandardDecorators(cache);
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
cache = new LoggingCache(cache);
}
return cache;
}
继续看看这个方法 setDefaultImplementations()
private void setDefaultImplementations() {
if (implementation == null) {
//默认实现为PerpetualCache和下面的LruCache
implementation = PerpetualCache.class;
if (decorators.isEmpty()) {
//LruCache为PerpetualCache的装饰器
decorators.add(LruCache.class);
}
}
}
重新回到build()方法看到下面这一行
Cache cache = newBaseCacheInstance(implementation, id);
进入newBaseCacheInstance()中查看源码
//可以发现传入的implementation参数是一个Cache的实现类
private Cache newBaseCacheInstance(Class<? extends Cache> cacheClass, String id) {
Constructor<? extends Cache> cacheConstructor = getBaseCacheConstructor(cacheClass);
try {
//通过反射创建Cache对象设置一个id
return cacheConstructor.newInstance(id);
} catch (Exception e) {
throw new CacheException("Could not instantiate cache implementation (" + cacheClass + "). Cause: " + e, e);
}
}
继续回到build()中,这行代码主要是为二级缓存设置一些参数例如cache标签中的一些Properties
setCacheProperties(cache);
继续往下看这个if判断
public Cache build() {
setDefaultImplementations();
Cache cache = newBaseCacheInstance(implementation, id);
setCacheProperties(cache);
//如果没有对缓存进行拓展也就是拓展其他的装饰器那么执行以下代码
if (PerpetualCache.class.equals(cache.getClass())) {
for (Class<? extends Cache> decorator : decorators) {
//可以进行自定义装饰器
cache = newCacheDecoratorInstance(decorator, cache);
setCacheProperties(cache);
}
//直接使用默认的装饰器
cache = setStandardDecorators(cache);
//如果拓展了日志功能那么将日志功能套进cache
} else if (!LoggingCache.class.isAssignableFrom(cache.getClass())) {
cache = new LoggingCache(cache);
}
return cache;
}
让我们来看看setStandardDecorators()这个方法具体是什么作用,进入源码
private Cache setStandardDecorators(Cache cache) {
try {
//获取相关参数(根据cache标签中是否增加对应的属性来判断添加对应的装饰器)
MetaObject metaCache = SystemMetaObject.forObject(cache);
if (size != null && metaCache.hasSetter("size")) {
metaCache.setValue("size", size);
}
if (clearInterval != null) {
cache = new ScheduledCache(cache);
((ScheduledCache) cache).setClearInterval(clearInterval);
}
if (readWrite) {
cache = new SerializedCache(cache);
}
cache = new LoggingCache(cache);
cache = new SynchronizedCache(cache);
if (blocking) {
cache = new BlockingCache(cache);
}
return cache;
} catch (Exception e) {
throw new CacheException("Error building standard cache decorators. Cause: " + e, e);
}
}
通过以上源码得知useNewCache创建缓存的具体流程应该是
useNewCache()
1.创建默认缓存---> PerpetualCache和 LruCache
2.创建新的实现---> Cache cache = newBaseCacheInstance(implementation, id);
3.读取整合cache的property标签增加额外的参数(内置缓存不用,主要用于自定义缓存 如redis ,OsCache,EhCache)
4.增加装饰器----->cache标签上的属性如size,clearInterval,readWrite,blocking等