MFF论文笔记
论文名称:Improving Pixel-based MIM by Reducing Wasted Modeling Capability_发表时间:ICCV2023
作者及组织:上海人工智能实验室,西门菲沙大学,香港中文大学
问题与贡献
MIM(Model Maksed Model)方法可以分为两部分基于像素的图片掩码学习(pixel-based)和基于高位表征的图片掩码学习(tokenizer-based)。相对于后者,基于像素的图像掩码学习方法具有结构简单、计算开销小等优点。本文中,作者通过一系列实验验证了pixel-based MIM方法存在的局限性,并提出使用浅层的low-level features来辅助pixel重建任务。通过将该方法应用到MAE中,可以增强pixel-based MIM方法的模型建模能力,提高模型的收敛速度,并且在多种下游任务中取得了效果提升。
本文的主要贡献如下:
- 首先,将multi-level 特征融合策略应用到ViTs中,相对于之前的pixel-based MIM方法效果更好;
- 然后,通过实验从潜在特征和优化上分析了为什么multi-level 特征融合能提升模型精度;
- 最后,进行了大量丰富的消融实验,验证模型部件的有效性;
前置概念和理论
Pixel-based MIM存在的问题
对于tokenizer-based MIM方法,例如BEiT中,输入图像的40%被masked,模型通过重建DALL-E的输出特征来学习masked patchs的语义信息。而pixel-based MIM方法中,为了简化预训练和减少计算压力,MAE等方法只将有效的patchs输入到encoder中,让decoder来重建masked patchs的像素值。但是由于pixel-based MIM方法的目标是重建原始像素值,使其倾向于获取high-frequency细节(低级texture)信息,这样算法会浪费大量重要的建模能力,削弱获取low-frequency语义(高级semantic)信息能力。
为了减少建模能力的浪费,学习到高质量的特征表达,用于下游任务。基于此,作者利用MAE进行了两个重要的实验来揭示设计问题。
- **融合浅层(Fuse Shallow Layers):**相比于仅仅使用输出层来做像素重建,应用加权平均策略来融合输出层和之前所有的层。每一层的权重是经过归一化的,在预训练阶段是动态更新的,该值的绝对值表示每一层对于重建任务的重要性;其中每一层权重的变化如下下图所示,可以发现模型在训练过程中越来越依赖于浅层的特征。
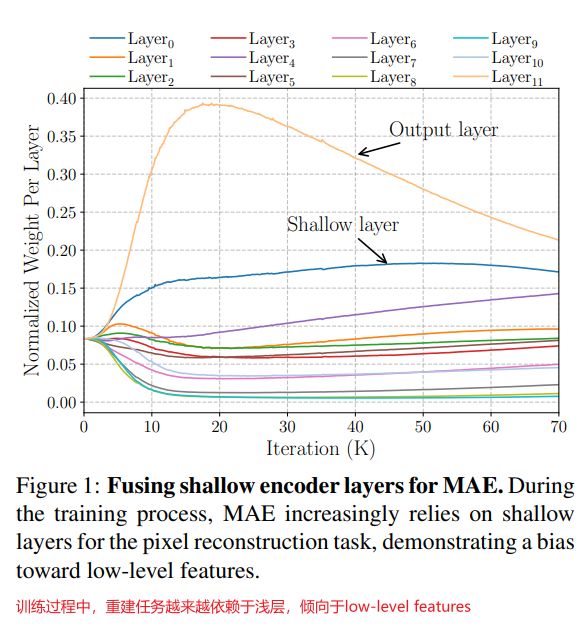
- **频率分析(Frequency Analysisi):**为了进一步理解MAE学习到的representation特性,分析了每一层特征的frequency response。作者将encoder的features从空间域转换到频域,观察其对数幅度如下图所示。正常来说,幅度越高证明该层生成的特征包含更high-frequency信息。可以发现,越浅层相对于高层包含更high-frequency分量;
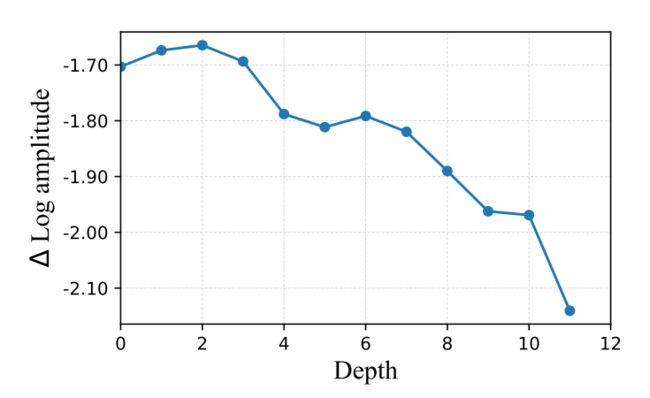
基于上面实验分析,作者认为像素重建任务会使得模型更倾向于学习低级细节信息。
feature pyramid
谈及到多级特征融合,自然而然会想到Feature Pyramid Network(FPN),该技术被广泛应用于目标检测和语义分割中来提升模型对目标不同尺度的学习。将FPN应用到很多已有的算法中都可以提升模型的性能。但是FPN中的多级l特征融合模块接受不同尺度的特征,限制其在ViTs中的应用,因为ViTs中不同层的特征尺度相同。
模型、理论和方法
为了解决Pixel-based MIM存在的问题,本文提出融合浅层生成低级细节特征到输出层中来实现像素重建任务。通过将浅层的低级特征合并到输出层,减轻模型过度关注低级细节的负担,使其能够更好地捕捉高级语义信息。
Multi-level Feature Fusion
本文提出地MFF方法是一种即插即用地方案,可以整合到现有的Pixel-based MIM方法中,并且不会引起过多地计算开销。MFF的整个框架如下图所示。
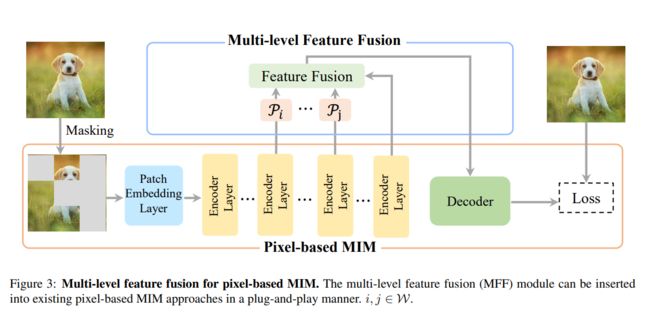
- 输入和编码
输入图像为 I ∈ R H × W × 3 I \in R^{H \times W \times 3} I∈RH×W×3,将其送入到encoder中,得到latent representations。
X = E ( I ) X=E(I) X=E(I)
latent representations,表示为 X = x 0 , x 1 , . . . x N − 1 X={x_0, x_1, ... x_{N-1}} X=x0,x1,...xN−1,ViT每个transformer layer的输出特征,其中 N N N表示encoder的深度。
- 选择融合层
单纯融合所有层将引入冗余使得模型更难优化,但是如何找到有效的层将引入搜索空间。为了简化layer选择步骤,作者按照如下的引导:
- 对所有的transformer layer输出进行频域分析,可以看到浅层包含低级细节特征,深层包含高级语义特征。结果显示使用浅层的特征能比深层的效果更好,直观分析和定量数字都表明浅层的特征应该被选择进行融合;
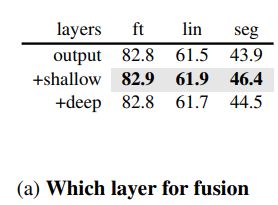
如上图所示,将deep layer的特征和输出层进行融合得到增益几乎可以忽略不记,融合浅层特征效果有较大的提升,使得模型更加注重于语义信息。因此将shallow layer加入进行特征融合。
- 对需要进行融合的层数进行分析。如下图所示,引入更多层的输出特征可以不断体征模型性能,因为它们各自都包含不同特征,可以帮助模型完成重建任务。当融合所有层时,可以看到在下游任务中性能的下降。这可能是由于这些层特征存在冗余,使得模型难以优化。
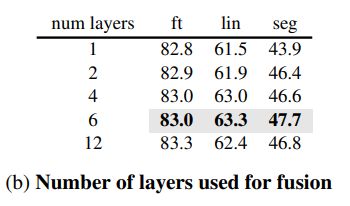
最终,选择额外 M = 5 M=5 M=5的特征层与最终输出层融合。
- 投影层
将选择层的indices标记为 W W W,对于每一个额外的层在进行融合之前会输入到一个projection layer P i P_i Pi,公式如下:
X ˇ = { P i ( x i ) } i ∈ W + { x N − 1 } \check{X}={\{P_i(x_i)\}_{i\in{W}}} + \{x_{N-1}\} Xˇ={Pi(xi)}i∈W+{xN−1}
通过projection层可以对齐不同level的特征。
- 融合层
最后,引入融合层来融合不同层级的特征:
O = F ( X ˇ ) O=F(\check{X}) O=F(Xˇ)
O O O将输入到decoder中用于像素重建。
投影和融合层地选择
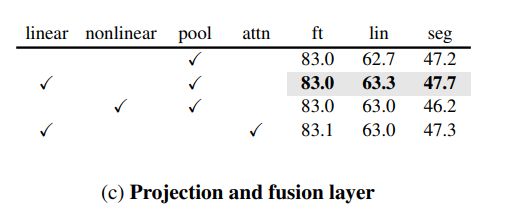
对于projection layer,有两种选择:linear projection 和 non-linear projection。具体使用的是Linear-GELU-Linear结构,实验表明在MFF框架中一个简单的linear层是有效且高效的。
fusion layer目的是为了从浅层特征中获取low-level信息,本文评估两种常用的融合方法:weighted average pooling和self-attention-based 融合。
weighted average pooling融合的公式如下,其中 w w w为对应层的权重比例,在训练过程中,所有的权重都会动态更新,加起来总和为1.
O = ∑ i ∈ W w i P i ( x i ) + w N − 1 x N − 1 O=\sum_{i\in{W}}w_iP_i(x_i) + w_{N-1}x_{N-1} O=i∈W∑wiPi(xi)+wN−1xN−1
self-attention融合使用transformer layer,公式如下。
O ^ = M u l t i H e a d A t t e n t i o n ( [ P i ( x i ) i ∈ W ] , x N − 1 ) \hat{O}=MultiHeadAttention([P_i(x_i)_{i\in{W}}], x_{N-1}) O^=MultiHeadAttention([Pi(xi)i∈W],xN−1)
经过multi-head attention层之后,会从 O ^ \hat{O} O^提取出 x N − 1 x_{N-1} xN−1对应的tokens用于像素重建。实验结果显示weighted average pooling策略和self-attention的结果相当,但是更加简单和计算高效。
实验与结论
实验分析
Frequency分析
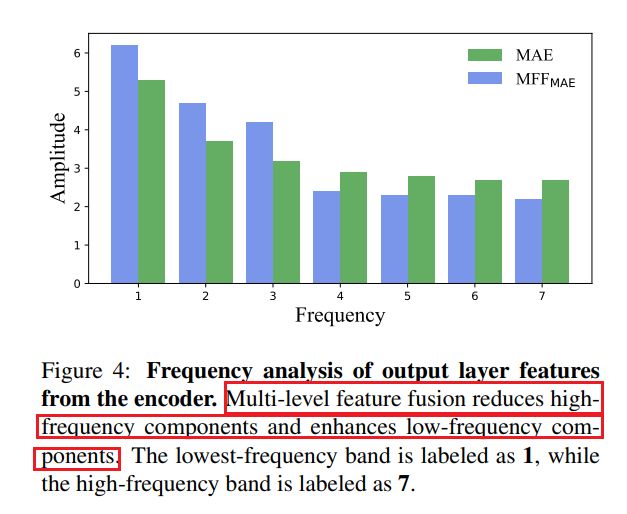
为了揭开多层特征融合有效的秘密,作者使用多层特征统合来增强MAE,得到 M F F M A E MFF_{MAE} MFFMAE。融合方法的目的是为了避免模型过度关注低级细节信息。为了研究融合前后的频率响应的变化,作者将编码器最后一层的特征转换到频域,并计算各频段的幅度。如下图所示,多层特征融合减少了高频响应并放大了属于低频范围的响应,这一结果支持了多层融合的有效性。
优化手段分析
作者还分析了Hessian的最大特征值谱,发现多层特征融合可以降低Hessian最大特征值的大小。如下图所示, M F F M A E MFF_{MAE} MFFMAE的Hessian 最大特征值要小于 M A E MAE MAE。Hessian 最大特征值表示重建loss函数的局部曲率,这个结果认为多层特征融合使潜在损失更加平坦。越大的特征值会阻碍神经网络训练。因此,多层特征融合可以帮助网络学习更好的特征表示通过抑制较大的特征值。
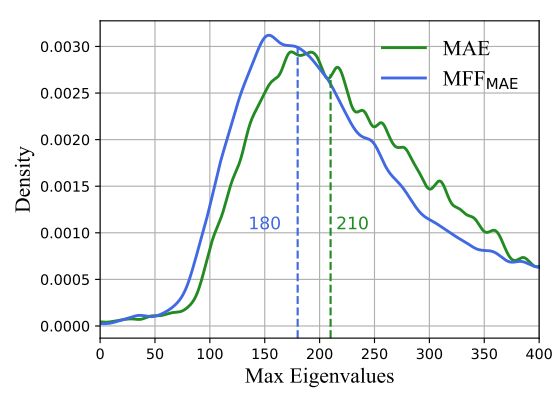
不同预训练方法的特征偏差
为了证明偏向于低级细节特征是否是pixel-based MIM的唯一固有缺陷,作者通过将多级特征融合引入到EVA和监督ViT。EVA是CLIP出品的专注于回归high-level特征的代表作品之一,supervised ViT要求模型将输入图像映射到语义标签。EVA和supervised ViT的目标是学习包含丰富语义信息的高级特征。
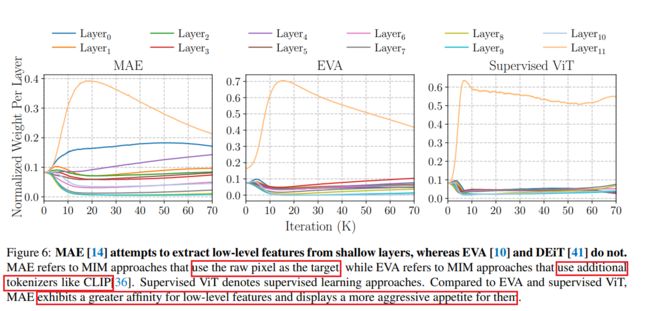
如上图所示,不同于MAE,EVA和supervised ViT的最后一层特征权重远大于浅层。结果显示pixel-based MIM方法出现低级特征偏差的主要原因是原始像素重建任务。
实验结果
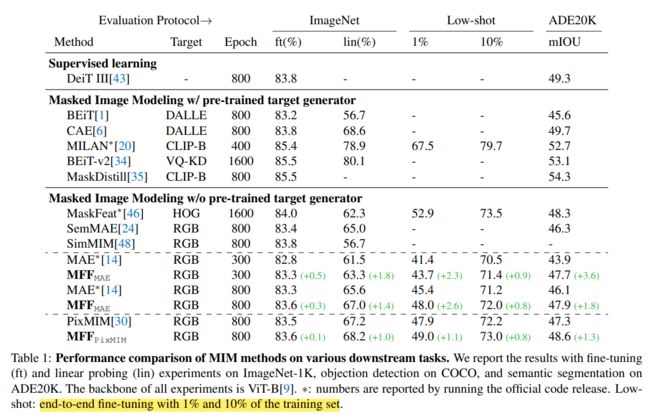
为了确保其设计方法和组件的有效性,作者在ImageNet上进行了一些图像分类实验,在COCO上进行目标检测实验,在ADE20K上进行语义分割任务。此外,还在参数量少的ViT-S进行少样本的微调实验。
对比实验
将MFF应用到MAE和PixMIM算法中,可以看到在不同的下游任务上效果都有提升。如下图所示,进行300个epoch训练之后,MFF相对于MAE在微调,线性探测和语义分割方面上分别提升了0.5%,1.8%和3.6%。
同时,通过分析表格可以发现微调(fine-tune)可能不是一个敏感的指标,原因可能在于预训练和微调的训练数据的分布相同,训练集的大小和模型容量足以抵消不同方法之间的性能差距。为了解决这个问题,作者只使用1%和10%的训练集对预训练模型进行微调。当进行少样本微调时,MFF与基本方法之间的性能差距增大,进一步验证了MFF的有效性。
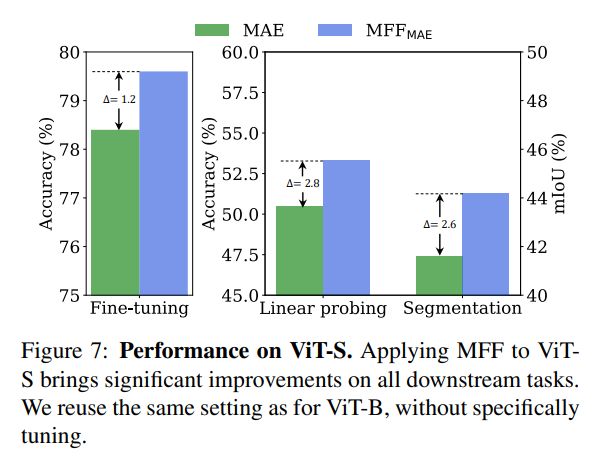
为了减轻模型复杂度带来的影响,使用ViT-S预训练MAE进行对比实验。由于ViT-S相对于ViT-B的复杂度更低,ViT-S需要更有效的预训练方法来学习语义特征。如下图所示,MFF 相对于基础模型提升明显,进一步验证了MFF的有效性。
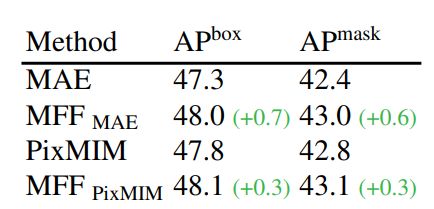
在 COCO 上作者采用 Mask R-CNN 方法同时生成边界框和实例,并以 ViT 作为主干。使用AP作为该任务的评价指标,实验对比如下图所示,MFF依然取得了不少的进步。
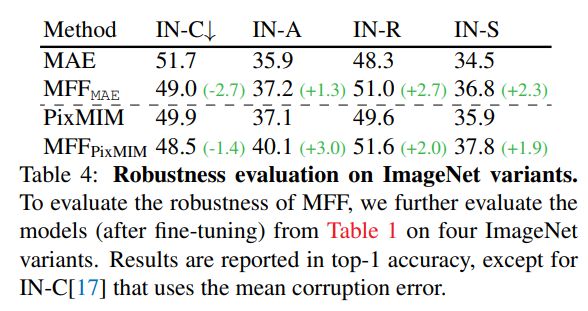
鲁棒性评估
通过在非同源数据集:ImageNet-Corruption,ImageNet-Adversarial,ImageNet-Rendition和ImageNet-Sketch。如下图所示,MFF极大的提升了MAE和PixMIM在所有数据集上的效果。
思考
在本文中,作者系统地探索了多层特征融合在MIM方案中的应用。通过一系列初步实验,揭示了浅层低级特征在像素重建任务中的重要性,并在 MAE 和 PixMIM 两种pixel-based MIM 方法中应用了MFF多层特征融合策略,实现了显著的性能提升。消融实验中进一步探索了层数选择和投影融合策略,并发现了MFF可以抑制高频信息并弱化损失。该工作为pixel-based MIM 方法提供了新的视角,推动了这种简单高效的自监督学习范式的发展。
参考链接
https://juejin.cn/post/7266299564344934419
https://zhuanlan.zhihu.com/p/652167613