Go中看似简单的WaitGroup源码设计,竟然暗含这么多知识?
Go语言提供的协程goroutine可以让我们很容易地写出多线程程序,但是,如何让这些并发执行的goroutine得到有效地控制,这是我们需要探讨的问题。正如小菜刀在《Golang并发控制简述》中所述,Go标准库为我们提供的同步原语中,锁与原子操作注重控制goroutine之间的数据安全,WaitGroup、channel与Context控制的是它们的并发行为。关于锁、原子操作、channel 的实现原理小菜刀均有详细地解析过。因此本文,我们将重点放在WaitGroup上。
初识WaitGroup
WaitGroup是sync包下的内容,用于控制协程间的同步。WaitGroup使用场景同名字的含义一样,当我们需要等待一组协程都执行完成以后,才能做后续的处理时,就可以考虑使用。
1func main() {
2 var wg sync.WaitGroup
3
4 wg.Add(2) //worker number 2
5
6 go func() {
7 // worker 1 do something
8 fmt.Println("goroutine 1 done!")
9 wg.Done()
10 }()
11
12 go func() {
13 // worker 2 do something
14 fmt.Println("goroutine 2 done!")
15 wg.Done()
16 }()
17
18 wg.Wait() // wait all waiter done
19 fmt.Println("all work done!")
20}
21
22// output
23goroutine 2 done!
24goroutine 1 done!
25all work done!
可以看到WaitGroup的使用非常简单,它提供了三个方法。虽然goroutine之间并不存在类似于父子关系,但是为了方便理解,本文会将调用Wait函数的goroutine称为主goroutine,调用Done函数的goroutine称呼为子goroutine。
1func (wg *WaitGroup) Add(delta int) // 增加WaitGroup中的子goroutine计数值
2func (wg *WaitGroup) Done() // 当子goroutine任务完成,将计数值减1
3func (wg *WaitGroup) Wait() // 阻塞调用此方法的goroutine,直到计数值为0
4
那么它是如何实现的呢?在源码src/sync/waitgroup.go中,我们可以看到它的核心源码只有100行不到,十分地精练,非常值得学习。
前置知识
代码少,不代表就实现简单,易于理解。相反,如果读者没有下述中的前置知识,想要真正理解WaitGroup的实现是会比较费力的。在解析源码之前,我们先过一遍这些知识(如果你都已经掌握,那就可以直接跳到后文的源码解析部分)。
信号量
在学习操作系统时,我们知道信号量是一种保护共享资源的机制,用于解决多线程同步问题。信号量s是具有非负整数值的全局变量,只能由两种特殊的操作来处理,这两种操作称为P和V。
P(s):如果s是非零的,那么P将s减1,并且立即返回。如果s为零,那么就挂起这个线程,直到s变为非零,等到另一个执行V(s)操作的线程唤醒该线程。在唤醒之后,P操作将s减1,并将控制返回给调用者。V(s):V操作将s加1。如果有任何线程阻塞在P操作等待s变为非零,那么V操作会唤醒这些线程中的一个,然后该线程将s减1,完成它的P操作。
在Go的底层信号量函数中
runtime_Semacquire(s *uint32)函数会阻塞goroutine直到信号量s的值大于0,然后原子性地减这个值,即P操作。runtime_Semrelease(s *uint32, lifo bool, skipframes int)函数原子性增加信号量的值,然后通知被runtime_Semacquire阻塞的goroutine,即V操作。
这两个信号量函数不止在WaitGroup中会用上,在《Go精妙的互斥锁设计》一文中,我们发现Go在设计互斥锁的时候也少不了信号量的参与。
内存对齐
对于以下的结构体,你能回答出它占用的内存是多少吗
1type Ins struct {
2 x bool // 1个字节
3 y int32 // 4个字节
4 z byte // 1个字节
5}
6
7func main() {
8 ins := Ins{}
9 fmt.Printf("ins size: %d, align: %d\n", unsafe.Sizeof(ins), unsafe.Alignof(ins))
10}
11
12//output
13ins size: 12, align: 4
按照结构体中字段的大小而言,ins对象占用内存应该是 1+4+1=6 个字节,但是实际上确实12个字节,这就是内存对齐所致。从《CPU缓存体系对Go程序的影响》一文中,我们知道CPU的内存读取并不是一个字节一个字节地读取的,而是一块一块的。因此,在类型的值在内存中对齐的情况下,计算机的加载或者写入会很高效。
在聚合类型(结构体或数组)的内存所占长度或许会比它元素所占内存之和更大。编译器会添加未使用的内存地址用于填充内存空隙,以确保连续的成员或元素相当于结构体或数组的起始地址是对齐的。
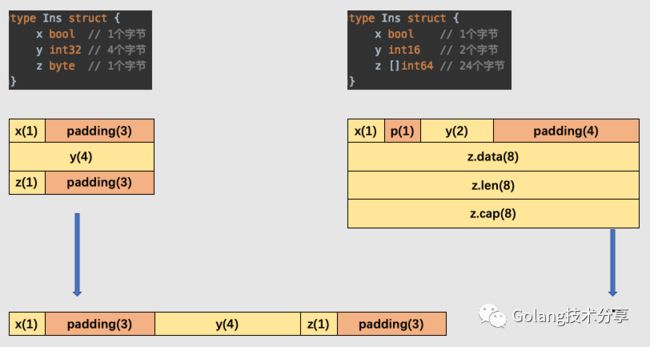
因此,在我们设计结构体时,当结构体成员的类型不同时,将相同类型的成员定义在相邻位置可以更节省内存空间。
原子操作CAS
CAS是原子操作的一种,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。关于Go中原子操作的底层实现,小菜刀在《同步原语的基石》一文中有详细介绍。
移位运算 >> 与 <<
在之前关于锁的文章《Go精妙的互斥锁设计》与《Go更细粒度的读写锁设计中》,我们能看到大量的位运算操作。灵活的位运算,能让一个普通的数字变化出丰富的含义,这里仅介绍下文中会用到的移位运算。
对于左移位运算 <<,按二进制形式将所有的数字向左移动对应的位数,高位舍弃,低位的空位补零。在数字没有溢出的前提下,左移一位相当于乘以2的1次方,左移n位就相当于乘以2的n次方。
对于右移位运算 >>,按二进制形式把所有的数字向右移动对应位数,低位移出,高位的空位补符号位。右移一位相当于除2,右移n位相当于除以2的n次方。这里是取商,余数就不要了。
移位运算也可以有很巧妙的操作,后文中我们会看到移位运算的高级运用。
unsafa.Pointer指针与uintptr
Go中的指针可以分为三类:1.普通类型指针*T,例如*int;2. unsafe.Pointer指针;3. uintptr。
*T:普通的指针类型,用于传递对象地址,不能进行指针计算。
unsafe.Pointer指针:通用型指针,任何一个普通类型的指针*T都可以转换为unsafe.Pointer指针,而且unsafe.Pointer类型的指针还可以转换回普通指针,并且它可以不用和原来的指针类型*T相同。但是它不能进行指针计算,不能读取内存中的值(必须通过转换为某一具体类型的普通指针才行)。
uintptr:准确来讲,uintptr并不是指针,它是一个大小并不明确的无符号整型。unsafe.Pointer类型可以与uinptr相互转换,由于uinptr类型保存了指针所指向地址的数值,因此可以通过该数值进行指针运算。GC时,不会将uintptr当做指针,uintptr类型目标会被回收。

unsafe.Pointer 是桥梁,可以让任意类型的普通指针实现相互转换,也可以将任意类型的指针转换为 uintptr 进行指针运算。但是,unsafe.Pointer和任意类型指针的转换可以让我们将任意值写入内存中,这会破坏Go原有的类型系统,同时由于不是所有的数值都是合法的内存地址,从uintptr到unsafe.Pointer的转换同样会破坏类型系统。因此,既然Go将该包定义为unsafe,那就不应该随意使用。
源码解析
本文基于Go源码1.15.7版本
结构体
sync.WaitGroup的结构体定义如下,它包括了一个 noCopy 的辅助字段,和一个具有复合意义的state1字段。
1type WaitGroup struct {
2 noCopy noCopy
3
4 // 64-bit value: high 32 bits are counter, low 32 bits are waiter count.
5 // 64-bit atomic operations require 64-bit alignment, but 32-bit
6 // compilers do not ensure it. So we allocate 12 bytes and then use
7 // the aligned 8 bytes in them as state, and the other 4 as storage
8 // for the sema.
9 state1 [3]uint32
10}
11
12// state returns pointers to the state and sema fields stored within wg.state1.
13func (wg *WaitGroup) state() (statep *uint64, semap *uint32) {
14 // 64位编译器地址能被8整除,由此可判断是否为64位对齐
15 if uintptr(unsafe.Pointer(&wg.state1))%8 == 0 {
16 return (*uint64)(unsafe.Pointer(&wg.state1)), &wg.state1[2]
17 } else {
18 return (*uint64)(unsafe.Pointer(&wg.state1[1])), &wg.state1[0]
19 }
20}
其中,noCopy字段是空结构体,它并不会占用内存,编译器也不会对其进行字节填充。它主要是为了通过go vet工具来做静态编译检查,防止开发者在使用WaitGroup过程中对其进行了复制,从而导致的安全隐患。关于这部分内容,可以阅读《no copy机制》详细了解。
state1字段是一个长度为3的uint32数组。它用于表示三部分内容:1. 通过Add()设置的子goroutine的计数值counter;2. 通过Wait()陷入阻塞的waiter数;3. 信号量semap。
由于后续是对 uint64 类型的statep进行操作,而64位整数的原子操作需要64位对齐,32位的编译器并不能保证这一点。因此,在64位与32位的环境下,state1字段的组成含义是不相同的。
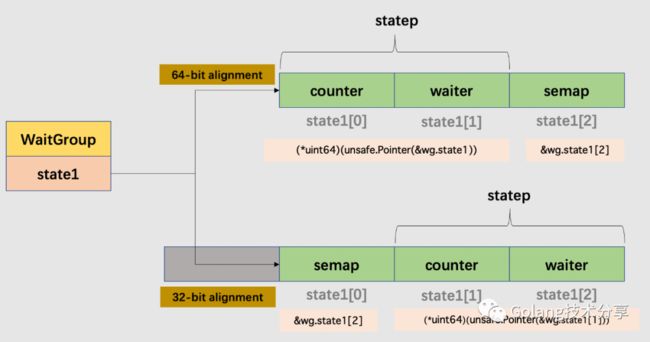
需要注意的是,当我们初始化一个WaitGroup对象时,其counter值、waiter值、semap值均为0。
Add函数
Add()函数的入参是一个整型,它可正可负,是对counter数值的更改。如果counter数值变为0,那么所有阻塞在Wait()函数的waiter将会被唤醒;如果counter数值为负值,将引起panic。
我们将竞态检测部分的代码去掉,Add()函数的实现源码如下
1func (wg *WaitGroup) Add(delta int) {
2 // 获取包含counter与waiter的复合状态statep,表示信号量值的semap
3 statep, semap := wg.state()
4 state := atomic.AddUint64(statep, uint64(delta)<<32)
5 v := int32(state >> 32)
6 w := uint32(state)
7
8 if v < 0 {
9 panic("sync: negative WaitGroup counter")
10 }
11
12 if w != 0 && delta > 0 && v == int32(delta) {
13 panic("sync: WaitGroup misuse: Add called concurrently with Wait")
14 }
15
16 if v > 0 || w == 0 {
17 return
18 }
19
20 if *statep != state {
21 panic("sync: WaitGroup misuse: Add called concurrently with Wait")
22 }
23
24 // 如果执行到这,一定是 counter=0,waiter>0
25 // 能执行到这,一定是执行了Add(-x)的goroutine
26 // 它的执行,代表所有子goroutine已经完成了任务
27 // 因此,我们需要将复合状态全部归0,并释放掉waiter个数的信号量
28 *statep = 0
29 for ; w != 0; w-- {
30 // 释放信号量,执行一次就将唤醒一个阻塞的waiter
31 runtime_Semrelease(semap, false, 0)
32 }
33}
代码非常精简,我们接下来对关键部分进行剖析。
1 state := atomic.AddUint64(statep, uint64(delta)<<32) // 新增counter数值delta
2 v := int32(state >> 32) // 获取counter值
3 w := uint32(state) // 获取waiter值
此时的statep是一个uint64数值,如果此时statep中包含的counter数为2,waiter为1,输入delta为1,那么这三行代码的逻辑过程如下图所示。
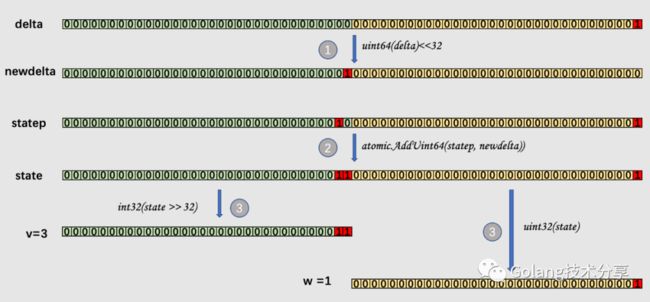
在得到当前counter数v与waiter数w后,会对它们的值进行判断,分几种情况。
1 // 情况1:这是很低级的错误,counter值不能为负
2 if v < 0 {
3 panic("sync: negative WaitGroup counter")
4 }
5
6 // 情况2:misuse引起panic
7 // 因为wg其实是可以用复用的,但是下一次复用的基础是需要将所有的状态重置为0才可以
8 if w != 0 && delta > 0 && v == int32(delta) {
9 panic("sync: WaitGroup misuse: Add called concurrently with Wait")
10 }
11
12 // 情况3:本次Add操作只负责增加counter值,直接返回即可。
13 // 如果此时counter值大于0,唤醒的操作留给之后的Add调用者(执行Add(negative int))
14 // 如果waiter值为0,代表此时还没有阻塞的waiter
15 if v > 0 || w == 0 {
16 return
17 }
18
19 // 情况4: misuse引起的panic
20 if *statep != state {
21 panic("sync: WaitGroup misuse: Add called concurrently with Wait")
22 }
关于 misuse 和 reused 引发 panic 的情况,如果没有示例错误代码,其实是比较难解释的。值得高兴的是,在Go源码中给出了错误使用示范,这些例子位于src/sync/waitgroup_test.go文件下,想深入了解的读者可以去看以下三个测试函数中的示例。
1func TestWaitGroupMisuse(t *testing.T)
2func TestWaitGroupMisuse2(t *testing.T)
3func TestWaitGroupMisuse3(t *testing.T)
4
Done函数
Done()函数比较简单,就是调用Add(-1)。在实际使用时,当子goroutine任务完成之后,就应该调用Done()函数。
1func (wg *WaitGroup) Done() {
2 wg.Add(-1)
3}
Wait函数
如果WaitGroup中的counter值大于0,那么执行Wait()函数的主goroutine会将waiter值加1,并阻塞等待该值为0,才能继续执行后续代码。
我们将竞态检测部分的代码去掉,Wait()函数的实现源码如下
1func (wg *WaitGroup) Wait() {
2 statep, semap := wg.state()
3 for {
4 state := atomic.LoadUint64(statep) // 原子读取复合状态statep
5 v := int32(state >> 32) // 获取counter值
6 w := uint32(state) // 获取waiter值
7 // 如果此时v==0,证明已经没有待执行任务的子goroutine,直接退出即可。
8 if v == 0 {
9 return
10 }
11 // 如果在执行CAS原子操作和读取复合状态之间,没有其他goroutine更改了复合状态
12 // 那么就将waiter值+1,否则:进入下一轮循环,重新读取复合状态
13 if atomic.CompareAndSwapUint64(statep, state, state+1) {
14 // 对waiter值累加成功后
15 // 等待Add函数中调用 runtime_Semrelease 唤醒自己
16 runtime_Semacquire(semap)
17 // reused 引发panic
18 // 在当前goroutine被唤醒时,由于唤醒自己的goroutine通过调用Add方法时
19 // 已经通过 *statep = 0 语句做了重置操作
20 // 此时的复合状态位不为0,就是因为还未等Waiter执行完Wait,WaitGroup就已经发生了复用
21 if *statep != 0 {
22 panic("sync: WaitGroup is reused before previous Wait has returned")
23 }
24 return
25 }
26 }
27}
总结
要看懂WaitGroup的源码实现,我们需要有一些前置知识,例如信号量、内存对齐、原子操作、移位运算和指针转换等。
但其实WaitGroup的实现思路还是蛮简单的,通过结构体字段state1维护了两个计数器和一个信号量,计数器分别是通过Add()添加的子goroutine的计数值counter,通过Wait()陷入阻塞的waiter数,信号量用于阻塞与唤醒Waiter。当执行Add(positive n)时,counter +=n,表明新增n个子goroutine执行任务。每个子goroutine完成任务之后,需要调用Done()函数将counter值减1,当最后一个子goroutine完成时,counter值会是0,此时就需要唤醒阻塞在Wait()调用中的Waiter。
但是,在使用WaitGroup时,有几点需要注意
通过
Add()函数添加的counter数一定要与后续通过Done()减去的数值一致。如果前者大,那么阻塞在Wait()调用处的goroutine将永远得不到唤醒;如果后者大,将会引发panic。Add()的增量函数应该最先得到执行。不要对WaitGroup对象进行复制使用。
如果要复用WaitGroup,则必须在所有先前的
Wait()调用返回之后再进行新的Add()调用。

机器铃砍菜刀
欢迎添加小菜刀微信
加入Golang分享群学习交流!
感谢你的点赞和在看哦~