sklearn机器学习(七)
Task07
本次学习参照Datawhale开源学习:https://github.com/datawhalechina/machine-learning-toy-code/tree/main/ml-with-sklearn
内容安排如下,主要是一些代码实现和部分原理介绍。

7. 集成学习
上一章中我们谈到维度灾难照成模型效果下降问题,处理这样的高维问题除了使用降维方法,还有一个常用的方法是子空间方法。集成是子空间思想中常用的方法之一,它将多个在子空间表现较好的算法或基检测器的输出结合起来。集成学习通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统。集成学习的一般策略:先产生一组“个体学习器”,再用某种策略将他们结合起来。
最简单的集成方法就是投票法。投票法是一种遵循少数服从多数原则的集成学习模型,通过多个模型的集成降低方差,从而提高模型的鲁棒性。在理想情况下,投票法的预测效果应当优于任何一个基模型的预测效果。
投票法在回归模型与分类模型上均可使用:
- 回归投票法:预测结果是所有模型预测结果的平均值。
- 分类投票法:预测结果是所有模型种出现最多的预测结果。
分类投票法又可以被划分为硬投票与软投票:
- 硬投票:预测结果是所有投票结果最多出现的类。
- 软投票:预测结果是所有投票结果中概率加和最大的类。
7.1. Bagging
与投票法不同的是,Bagging不仅仅集成模型最后的预测结果,同时采用一定策略来影响基模型训练。
Bagging的核心在于自助采样(bootstrap)这一概念,即有放回的从数据集中进行采样,也就是说,同样的一个样本可能被多次进行采样。首先我们随机取出一个样本放入采样集合中,再把这个样本放回初始数据集,重复K次采样,最终我们可以获得一个大小为K的样本集合。同样的方法, 我们可以采样出T个含K个样本的采样集合,然后基于每个采样集合训练出一个基学习器,一共T个学习器。再将这些基学习器进行结合,这就是Bagging的基本流程。
Sklearn为我们提供了BaggingRegressor与BaggingClassifier 两种Bagging方法的API。用两个官方例子解释应用:
'''BaggingRegressor'''
from sklearn.svm import SVR
from sklearn.ensemble import BaggingRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100, n_features=4,n_informative=2, n_targets=1,random_state=0, shuffle=False) # 生成数据
regr = BaggingRegressor(base_estimator=SVR(),n_estimators=10, random_state=0).fit(X, y) # 选十个SVR模型作为基模型
regr.predict([[0, 0, 0, 0]])
array([-2.87202411])
'''BaggingClassifier'''
from sklearn.svm import SVC
from sklearn.ensemble import BaggingClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=100, n_features=4,n_informative=2, n_redundant=0,random_state=0, shuffle=False)# 生成数据
clf = BaggingClassifier(base_estimator=SVC(),n_estimators=10, random_state=0).fit(X, y)# 选十个SVR模型作为基模型
clf.predict([[0, 0, 0, 0]])
array([1])
7.2. Boosting
Bagging主要通过降低方差的方式减少预测误差。而Boosting思想提高最终的预测效果是通过不断减少偏差的形式。换句话说:Bagging是对许多强分类器求平均,Boosting是把许多弱的分类器组合成一个强的分类器。
Boosting先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本进行调整,使得先前基学习器做错的样本再后续获得更多关注,然后基于调整后的样本分布来训练下一个基学习器。如此重复进行,直至基学习器数目达到事先指定的值T,最后将这T个基学习器进行加权结合。
Boosting常用的两种Boosting方式:Adaptive Boosting 和 Gradient Boosting 以及它们的变体Xgboost、LightGBM以及Catboost。
'''AdaBoostRegressor'''
from sklearn.ensemble import AdaBoostRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_features=4, n_informative=2,random_state=0, shuffle=False)
regr = AdaBoostRegressor(random_state=0, n_estimators=100)# 生成数据
regr.fit(X, y)
AdaBoostRegressor(n_estimators=100, random_state=0)# 选100个boosting基模型
regr.predict([[0, 0, 0, 0]])
array([4.79722349])
'''AdaBoostClassifier'''
from sklearn.ensemble import AdaBoostClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=4,n_informative=2, n_redundant=0,random_state=0, shuffle=False)# 生成数据
clf = AdaBoostClassifier(n_estimators=100, random_state=0)# 选100个boosting基模型
clf.fit(X, y)
clf.predict([[0, 0, 0, 0]])
array([1])
7.3. Blending和Stacking
Stacking严格来说并不是一种算法,而是一种模型集成策略。Stacking集成算法可以理解为一个两层的集成,第一层含有多个基础分类器,把预测的结果提供给第二层, 而第二层的分类器通常是逻辑回归,他把一层分类器的结果当做特征做拟合输出预测结果。Blending与Stacking原理基本相同,只是少了一层交叉验证环节,可以算是简化版的Stacking。
'''Blending'''
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
data, target = make_blobs(n_samples=10000, centers=2, random_state=1, cluster_std=1.0 )
## 创建训练集和测试集
X_train1,X_test,y_train1,y_test = train_test_split(data, target, test_size=0.2, random_state=1)
## 创建训练集和验证集
X_train,X_val,y_train,y_val = train_test_split(X_train1, y_train1, test_size=0.3, random_state=1)
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
# 设置第一层分类器
clfs = [SVC(probability = True),RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),KNeighborsClassifier()]
# 设置第二层分类器
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# 输出第一层的验证集结果与测试集结果
val_features = np.zeros((X_val.shape[0],len(clfs))) # 构造验证数据预测矩阵,存放验证数据各个模型预测结果,每一列为一个模型始化验证集结果
test_features = np.zeros((X_test.shape[0],len(clfs))) # 构造测试数据预测矩阵,存放测试数据各个模型预测结果,每一列为一个模型
for i,clf in enumerate(clfs):
clf.fit(X_train,y_train) # 训练模型
val_feature = clf.predict_proba(X_val)[:, 1] # 获得各基模型在验证集的结果
test_feature = clf.predict_proba(X_test)[:,1] # 获得各基模型在测试集的结果
val_features[:,i] = val_feature # 将各基模型在验证集的结果记录下来
test_features[:,i] = test_feature # 将各基模型在测试集的结果记录下来
# 将第一层的验证集的结果输入第二层训练第二层分类器
lr.fit(val_features,y_val)
# 输出测试数据预测的结果
from sklearn.model_selection import cross_val_score
scores = cross_val_score(clf, X_test, y_test, cv=3, scoring='accuracy')
print(scores.mean())
1.0
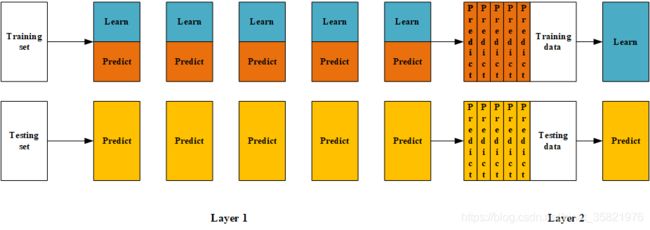
Blending过程可以用下图表示,结合代码了解过程:
'''Stacking'''
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
data, target = make_blobs(n_samples=10000, centers=2, random_state=1, cluster_std=1.0 )
## 创建训练集和测试集
X_train1,X_test,y_train1,y_test = train_test_split(data, target, test_size=0.2, random_state=1)
# ## 创建训练集和验证集
# X_train,X_val,y_train,y_val = train_test_split(X_train1, y_train1, test_size=0.3, random_state=1)
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
# 设置第一层分类器
clfs = [SVC(probability = True),RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),KNeighborsClassifier()]
# 设置第二层分类器
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# 输出第一层的验证集结果与测试集结果
val_features = np.zeros((X_train1.shape[0],len(clfs))) # 构造验证数据预测矩阵,存放验证数据各个模型预测结果,每一列为一个模型始化验证集结果
test_features = np.zeros((X_test.shape[0],len(clfs))) # 构造测试数据预测矩阵,存放测试数据各个模型预测结果,每一列为一个模型
from sklearn.model_selection import StratifiedKFold
n_splits = 5
skf = StratifiedKFold(n_splits)
skf = skf.split(X_train1,y_train1) #将训练数据分为5折
for j, clf in enumerate(clfs): # 第j个模型
#依次训练各个单模型
test_features_j = np.zeros((X_test.shape[0], 5)) # 构造验证数据预测矩阵(每一折),存放验证数据单个模型每一折预测结果,每一列为一折验证数据训练的模型
for i, (train, val) in enumerate(skf): # 第i折,共5折
#5-Fold交叉训练,使用第i个部分作为预测,剩余的部分来训练模型,获得其预测的输出作为第i部分的新特征。
X_train, y_train, X_val, y_val = X_train1[train], y_train1[train], X_train1[val], y_train1[val] # 将训练数据分为训练数据和验证数据,5折交叉验证
clf.fit(X_train, y_train) # 训练模型
y_submission = clf.predict(X_val) # 预测验证数据。将预测类型记录进y_submission
val_features[val, j] = y_submission # 将第j个模型第i折验证数据(验证数据来源于训练数据,占训练数据1/5)的预测结果,按照5折拆分时的index放入训练模型预测矩阵
test_features_j[:, i] = clf.predict(X_test) # 将第j个模型第i折测试数据的预测结果,放入该折测试数据预测矩阵
# 将第一层的验证集的结果输入第二层训练第二层分类器
lr.fit(val_features,y_train1)
# 输出测试数据预测的结果
from sklearn.model_selection import cross_val_score
scores = cross_val_score(clf, X_test, y_test, cv=3, scoring='accuracy')
print(scores.mean())
1.0
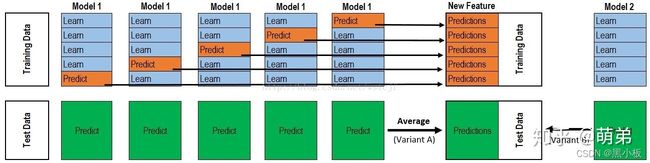
Stacking过程可以用下图表示,结合代码了解过程:
此外,我们也可以直接用mlxtend工具包(pip install mlxtend)实现stacking模型。
'''Stacking(使用mlxtedn工具包实现)'''
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
data, target = make_blobs(n_samples=10000, centers=2, random_state=1, cluster_std=1.0 )
## 创建训练集和测试集
X_train1,X_test,y_train1,y_test = train_test_split(data, target, test_size=0.2, random_state=1)
# ## 创建训练集和验证集
# X_train,X_val,y_train,y_val = train_test_split(X_train1, y_train1, test_size=0.3, random_state=1)
from mlxtend.classifier import StackingCVClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
# 设置第一层分类器
clfs = [SVC(probability = True),RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),KNeighborsClassifier()]
# 设置第二层分类器
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
sclf = StackingCVClassifier(classifiers=clfs, # 第一层分类器
meta_classifier=lr, # 第二层分类器
random_state=42)
# 输出测试数据预测的结果
from sklearn.model_selection import cross_val_score
scores = cross_val_score(clfs[0], X_test, y_test, cv=3, scoring='accuracy')
print(scores.mean())
1.0