python学习笔记08:面向ArcGIS的python脚本编程
目录
1 引例
1.1 获取图层属性要素数目
1. 2 几点注意事项:
2 使用python进行地理处理
2.1 ArcPy包
2.1.1 import方式
2.1.2 from-import方式
2.1.3 from-import-as方式
2.2 使用地理工具
2.2.1 两种方式调用方式
2.2.2 参数属性分析--以裁切功能为例
2.2.3 GetParameterAsText()接受外部工具传参模式调用
2.2.4 导入自定义工具箱
2.2.5 获取工具语法
2.2.6 ArcPy函数
2.2.7 获取帮助
2.3 访问空间数据
2.3.1 检查数据的存在性--Exists
2.3.2 数据描述--Describe
2.3.3 列表函数
2.3.4 元组与字典
2.4 处理空间数据
2.4.1 游标
2.4.2 SQL的使用
2.4.3 处理表和字段名
2.5 处理文本文档
2.5.1 常用函数总结
2.5.2 经典文本读取方法总结
2.6 获取栅格信息
2.6.1 获取栅格数据:ListRasters()
2.6.2 栅格属性描述
2.6.3 处理栅格对象
2.6.4 Spatial Analyst模块
2.7 Numpy包
3 执行地理处理任务
3.1 制图脚本
3.1.1 典型流程
3.1.2 地图文档的属性和方法
3.1.3 图层
3.1.4 输出和打印地图
3.2 处理PDF文档
4 程序调试与错误处理
4.1 错误识别
4.2 程序调试
4.2.1 pythonWin调试
4.2.2 调试技巧
4.2.3 常见错误
本文为笔者学习赞德伯根《面向ArcGIS的Python脚本编程》的笔记总结
1 引例
1.1 获取图层属性要素数目
>>> arcpy.GetCount_management('road')
1. 2 几点注意事项:
- 加载已经写完的*.py文件,新建python窗口,右键单击Load(加载)已有脚本
- Python的官方网站包含大量的学习资源,适用于初学者的资源
- python官方命名规范《Style Guide for Python Code》,最好避免首字母使用下划线,因为它有特殊含义
- 列表使用方括号定义,元素以逗号隔开
- 方法的调用方式:
- 处理路径的三种方式:单斜杠(/)、两个反斜杠(\\)和路径前添加(r)
- 使用import导入外部模块
- 注释以#开头
- python每个对象包含三个特征:赋值标识(使用函数id(varName)查询)、类型(使用type(varName)查询)
>>> name = 'road'
>>> id(name)
355610048
>>> type(name)
>>> print name
road 2 使用python进行地理处理
2.1 ArcPy包
2.1.1 import方式
它包含多个模块,其中两个专业模块,自动化制图模块(arcpy.mapping)和地图代数模块(arcpy.sa);模块在导入之后才能使用
import arcpy
import arcpy.mappping
import arcpy.sa导入模块后,使用类型属性方式:arcpy.
import arcpy
arcpy.env.workspace = "d:/Work/"
2.1.2 from-import方式
使用from-import语句,导入模块的一部分,此时可以省略类名:
from arcpy import env
env.workspace = "d:/Work/"
2.1.3 from-import-as方式
使用from-import-as语句增强导入代码可读性:
from arcpy import env as myEnv
myEnv.workspace = "d:/Work/"
2.2 使用地理工具
2.2.1 两种方式调用方式
- arcpy.
( ) - arcpy.
. ( )
两种方法都对,可以任意选择,但必须保证语法正确
import arcpy
arcpy.env.workspace = "d:/Work/"
#方式一
arcpy.Clip_analysis("in_features.shp", "clip_feature.shp", "out_feature_class.shp")
#方式二
arcpy.analysis.Clip("in_features.shp", "clip_feature.shp", "out_feature_class.shp")
2.2.2 参数属性分析--以裁切功能为例
裁切功能官方帮助:
Clip_analysis (in_features, clip_features, out_feature_class, {cluster_tolerance})
| 参数 | 说明 | 数据类型 |
| in_features |
要裁剪的要素。 |
Feature Layer |
| clip_features |
用于裁剪输入要素的要素。 |
Feature Layer |
| out_feature_class |
待创建的要素类。 |
Feature Class |
| cluster_tolerance (可选) |
所有要素坐标之间的最小距离以及坐标可以沿 X 和/或 Y 方向移动的距离。如果此值设置得较高,则数据的坐标精度将会较低;如果此值设置得较低,则数据的坐标精度将会较高。 |
Linear unit |
每个参数都有四个属性:
- 名称:工具参数的唯一标识
- 类型:所需要的数据类型,如要素类、整型、字符串或栅格
- 方向:输入参数还是输出参数
- 必选:参数是必选参数还是可选参数,可选参数在官方文档中一般使用 {} 包着
地理信息处理工具语法基本模式:
- 先必选参数,再可选参数;通常第一个为输入数据集,随后是输出数据集,接着是其他必选参数,最后是可选参数
- 输入数据集以 in_ 前缀,输出数据集以 out_ 前缀
- 如果一些参数可选参数不需要,可以跳过;跳过方式以下两种:1)设置为("")或("#"),2)明确参数名及其参数值
官方文档--缓冲区分析工具:
Buffer_analysis(in_features, out_feature_class, buffer_distance_or_field, {line_side}, {line_end_type}, {dissolve_option}, {dissolve_field;dissolve_field...})
#方式一:""
arcpy.Buffer_analysis("road","buffer","100 METERS","","","LIST","FID")
#方式二:"#"
arcpy.Buffer_analysis("road","buffer","100 METERS","#","#","LIST","FID")
#方式三:参数名及其赋值
arcpy.Buffer_analysis("road","buffer","100 METERS",dissolve_option = "LIST",dissolve_field = "FID")2.2.3 GetParameterAsText()接受外部工具传参模式调用
增加代码的灵活性和可复用性
>>> import arcpy
>>> inFile = arcpy.GetParameterAsText(0)
>>> outFile = arcpy.GetParameterAsText(1)
>>> arcpy.Copy_management(inFile, outFile)多数工具都只有一个输出,如果有多个输出,可以使用getOutput(index)得到指定索引的输出结果
>>> import arcpy
>>> arcpy.env.workspace = "d:/Work/"
>>> buffer = arcpy.Buffer_analysis("road","buffer","100 METERS","","","LIST","FID")
>>> count = arcpy.GetCount_management(buffer).getOutput(0)
>>> print count2.2.4 导入自定义工具箱
ArcGIS的本地ToolBox文件路径:D:\Program Files (x86)\ArcGIS\Desktop10.1\ArcToolbox\Toolboxes(在你的安装目录里找)
自定义的*.tbx即使添加到ToolBox中,也必须使用ImportToolBox函数引入到开发环境中
>>> import arcpy
>>> arcpy.ImportToolBox("C:/mytool.tbx")
#也可以定义别名
>>> arcpy.ImportToolBox("C:/mytool.tbx", myTools)使用方式如2.2.1部分相同
2.2.5 获取工具语法
使用Usage获得所有工具语法
>>> import arcpy
>>> tools = arcpy.ListTools("*_analysis")
>>> for tool in tools:
print arcpy.Usage(tool)help方法查看工具语法:
>>> print help(arcpy.Clip_analysis)2.2.6 ArcPy函数
调用格式:arcpy.
所有工具都是函数,但是函数并一定的是工具;工具函数与非工具函数的区别在于:
- 帮助文档位置不同:ArcToolbox运行时得到工具帮助文档;非工具函数在ArcPy帮助文档中
- 工具依赖许可,非工具函数不依赖ArcGIS许可
- 工具处理得到地理信息可通过其他函数访问,非工具函数不生成地理处理信息
- 工具函数调用需要工具箱别名和模块名,非工具函数直接调用
- 工具函数返回结果对象,非工具函数不返回结果对象
2.2.7 获取帮助
![]()
在帮助文档中找到Geoprocessing > Python 和 Geoprocessing > ArcPy
每个工具都有帮助示例
地理处理工具的帮助文档位置Geoprocessing > Tool reference,可按照工具箱--工具集--工具方式访问
2.3 访问空间数据
2.3.1 检查数据的存在性--Exists
ArcPy中的两种路径类型:
- 系统目录:Windows可识别的类型,例如:"C:\data"
- 目录路径:仅ArcGIS可识别的路径类型,例如:"C:\data\study.gdb\final\street"
注:gdb表示文件地理数据库;mdb表示个人地理数据库;sde企业地理数据库
import arcpy
print arcpy.Exists("D:/data/country.shp")
#存在为true,不存在返回false2.3.2 数据描述--Describe
Describe函数可识别多种数据集的类型,获取要素类型、数据集类型、空间参考信息、栅格波段、栅格数据集、属性表等
rd = arcpy.Describe(r"E:\ArcGISlearn\全部章节源码\第六章\data\road.shp")
print rd.ShapeType
#输出结果:Polyline
print rd.datasetType
#FeatureClass
print rd.SpatialReference.name
#Unknown
print rd.path
#E:\ArcGISlearn\全部章节源码\第六章\data
print rd.CatalogPath
#E:\ArcGISlearn\全部章节源码\第六章\data\road.shp
print rd.name
#road.shp
print rd.file
#road.shp
print rd.baseName
#road,去除了文件的后缀,只保留了文件名称本体2.3.3 列表函数

print arcpy.ListFeatureClasses()
/*
[u'Sheet1_XYToLine', u'Point_PointsToLine1', u'Sheet1_XYToLine2', u'E34t_PointsToLine', u'Point_PointsToLine', u'Point_PointsToLine2', u'Point_PointsToLine3', u'Point_PointsToLine4', u'\u7f13\u51b2_\u9910\u996e_point', u'\u7f13\u51b2_\u9910\u996e_point_2']
*/
fl = arcpy.ListFields(r"E:\ArcGISlearn\全部章节源码\第六章\data\road.shp")
for f in fl:
... print f.name
...
/*
FID
Shape
Id
*/
#格式化字符串输出
for f in fl:
... print "{0} is a type of {1}".format(f.name, f.type)
...
/*
FID is a type of OID
Shape is a type of Geometry
Id is a type of Integer
*/
#列表函数的使用
len(fl)
#3u表示Unicode编码,在处理多语言时比较安全
2.3.4 元组与字典
元组的基本概念
- 逗号分割
- 元组中的元素不允许修改
- 元组切片操作可以得到新的元组
- 记数 count 和索引 index 可用于元组
字典的基本概念:
- 使用{ }括起来,元素间使用逗号隔开,每个元素由键值对以冒号连接
- 每个键值对必须是完整的,顺序随意
- 使用 [ ] 赋值语句添加新元素:di["key"]="value"
- 修改元素的值:di["key"]="newValue"
- 删除元素:del di[key]
- 以列表形式返回字典中的键值对信息,di.items()
install = arcpy.GetInstallInfo()
for key in install:
... print "{0},{1}".format(key, install[key])2.4 处理空间数据
2.4.1 游标
使用游标来遍历属性表中的每一条属性记录,或者添加新的记录
定义在ArcPy.da模块,主要包含三种功能:
- 搜索游标【SearchCursor】,用来检索行记录
- 插入游标【InsertCursor】,向表或要素类中添加行
- 删除游标【UpdateCursor】,从表或要素类中删除行
arcpy.da.SearchCursor(r"E:\ArcGISlearn\全部章节源码\第六章\data\road - 副本.shp", "FID")
arcpy.da.UpdateCursor(r"E:\ArcGISlearn\全部章节源码\第六章\data\road - 副本.shp", "FID")
arcpy.da.InsertCursor(r"E:\ArcGISlearn\全部章节源码\第六章\data\road - 副本.shp", "FID")
游标只能向前,使用next执行n次,抵达属性表的结尾部分,如果继续再向前调用next,会报StopIteration异常
创建游标后还得删除游标,否则会报错:
search = arcpy.da.SearchCursor(r"E:\ArcGISlearn\全部章节源码\第六章\data\road - 副本.shp", "FID")
for row in search:
... print "{0}".format(row)
del search
del row但是使用with语句后,可以不使用del语句:
with arcpy.da.SearchCursor(r"E:\ArcGISlearn\全部章节源码\第六章\data\road - 副本.shp", "FID") as myCursor:
... for row in myCursor:
... print "{0}".format(row)2.4.2 SQL的使用
ArcGIS中的SQL表达式的帮助信息:Building a query expression

2.4.3 处理表和字段名
arcpy.ValidateTableName:确定表名在给定的工作空间是否有效
print arcpy.ValidateTableName("road -副本.shp")
#road__副本_shp要素拷贝案例:

arcpy.ValidateFieldName:判断给定的名字是否是一个有效的字段名称
print arcpy.ValidateFieldName("FID")
#FIDAddField_management(in_table, field_name, field_type, {field_precision}, {field_scale}, {field_length}, {field_alias}, {field_is_nullable}, {field_is_required}, {field_domain}
添加字段的代码案例:
fc = r"E:\ArcGISlearn\全部章节源码\第六章\data\road - 副本.shp"
arcpy.AddField_management(fc,"Def", "TEXT", "", "",255)
fl = arcpy.ListFields(fc)
for f in fl:
... print "{0}".format(f.name)
存在性判断及处理方式:
- 对于字段,使用ListFields方法获取所有字段,判断字段是否存在
- 对于表,可以使用CreateUniqueName函数,创建唯一的名称
解析属性表和字段名:
- ParseTableName返回一个逗号隔开,包含数据库名、所有者名和表名的字符串的列表
- ParseFieldName返回一个逗号隔开,包含数据库名、所有者名、表名和字段名的字符串的列表
2.5 处理文本文档
2.5.1 常用函数总结
- open(path, mode),其中mode可表示为r、w、+、a、b
- write("要写入的内容")
- read()默认读取全部内容,也可以指定要读取的字符的个数;返回单一字符串,包含换行符\n
- seek()设置文件当前读取的位置
- readline()读取一行文本,返回字符串包含换行符\n
- readlines()读取所有行文本,以列表形式返回
- writelines()写入多行数据
- write()写入单行数据
- close()关闭文件

pathName = r"E:\ArcGISlearn\geoInfo.txt"
f = open(pathName, "r")
lines = f.readlines()
fw = open("E:/ou.txt", "w")
for l in lines:
tmp = l.split(" ")
fw.write("{0} {1} {2}".format(tmp[1], tmp[3],tmp[5])
f.close()
fw.close()原作者的实现思路是:将"ID:"、"Lat:"和"Lon:"替换为""
2.5.2 经典文本读取方法总结
(1)使用read函数读取文本所有字符
#方式一:
f = open("my.txt")
ch = f.read(1)
while ch:
<处理函数>
ch = f.read(1)
f.close()
#方式二
f = open("my.txt")
ch = f.read(1)
while True:
ch = f.read(1)
if ch not Char: break
<处理函数>
f.close()(2)按行读取模式
#方式一:
f = open("my.txt")
ch = f.read(1)
for line in f:
<处理函数>
f.close()
#方式二
f = open("my.txt")
ch = f.read(1)
for line in f.readlines():
if not line: break
<处理函数>
f.close()对于大文件使用readlines比较消耗内存,使用fileinput模块创建文件内容对象
#方式一:
import fileinput
for line in fileinput.input("my.txt"):
<处理函数>
2.6 获取栅格信息
2.6.1 获取栅格数据:ListRasters()
ListRasters({wild_card}, {raster_type})
第一个参数:通过名称限制要返回的结果;第二个参数:指定数据类型,如*.tif,*.img
示例代码:
>>> from arcpy import env
>>> env.workspace=r"E:\ArcGISlearn\全部章节源码\第十章\data"
>>> rl = arcpy.ListRasters()
>>> for r in rl:
... print r2.6.2 栅格属性描述
三种栅格元素类型:
- 栅格数据集:包含多种数据格式,可由单波段或多波段构成
- 栅格波段:栅格数据集中的某个图层,即某个光谱范围内的值
- 栅格目录:以表格形式存储的栅格数据集的集合,用于表示一组具有相邻、重叠或部分重叠关系的栅格数据集
栅格属性:


代码示例:
>>> from arcpy import env
>>> env.workspace=r"E:\ArcGISlearn\全部章节源码\第十章\data"
>>> raster = "ASTGTM_N32E118K.img"
>>> des = arcpy.Describe(raster)
>>> print des.datatype
#RasterLayer
>>> print des.bandcount
#1
>>> print des.compressionType
#RLE
>>> print des.format
#IMAGINE Image
>>> print des.sensorType
#
>>> print des.permanent
#True
>>> print des.height
#3741
>>> print des.width
#3185
>>> print des.IsInteger
#True
>>> print des.meanCellHeight
#30.0
>>> print des.meanCellWidth
#30.0
>>> print des.noDataValue
#32767
>>> print des.pixelType
#S16
>>> print des.pixeltype
#S16
>>> print des.primaryField
#1
>>> print des.tableType
#Index
获取栅格投影信息:
>>> spaRef = des.spatialReference
>>> print spaRef.name
#WGS_1984_UTM_Zone_50N
>>> print spaRef.linearUnitName
#Meter对于多波段栅格处理:
>>> env.workspace = r"E:\Amiee\ArcGISlearn"
>>> raster = "China.png"
>>> des1 = arcpy.Describe(raster)
>>> print des1.bandcount
#4
>>> rband1 = "China.png/Band_2"
>>> desb2 = arcpy.Describe(rband1)
>>> print desb2.width
#10862.6.3 处理栅格对象
- 创建栅格对象Raster,两种方式:
- 已有栅格文件创建
- 地图代数语句创建栅格对象
- 保存到本地磁盘save
使用地图代数方式创建,多波段栅格数据保存变成了单波段的坡度图:
>>> ouRaster = arcpy.sa.Slope("China.png")
>>> ouRaster.save("mch.tif")使用栅格创建,【保存正常】:
>>> ouRaster1 = arcpy.Raster("China.png")
>>> ouRaster1.save("ra.tif")2.6.4 Spatial Analyst模块
坡度提取代码及结果展示
>>> env.workspace = r"E:\ArcGISlearn\全部章节源码\第十章"
>>> inr = arcpy.Raster("ASTGTM_N32E118K.img")
>>> ou = arcpy.sa.Slope(inr)

使用地图代数将英尺转化为米
#方式二
ou1 = inr * 0.3048
#方式二
ou = arcpy.sa.Times(inr, "0.3048")2.7 Numpy包
栅格数据转化为Numpy数据的数据的脚本,然后使用SciPy包调用专门的函数处理成ArcGIS可识别的格式
两个函数分别是:NumPyArrayToRaster和RasterToNumPyArray

3 执行地理处理任务
3.1 制图脚本
3.1.1 典型流程
arcpy.mapping
典型的流程包括:打开地图文档,修改数据框属性,加载图层、编辑页面中的元素、将地图文档导出为PDF
mapdoc = arcpy.mapping.MapDocument(r"E:\ArcGISlearn\data.mxd")
#如果是在ArcGIS环境下打开了*.mxd文件,可使用CURRENT关键字;使用该关键字时,需在创建脚本时候选“Always run in foreground”
mapdoc = arcpy.mapping.MapDocument("CURRENT")
关键属性和方法:
- save()和saveACopy()分别为保存到当前文档或新文档,后者类似于另存为
- RsrefreshActiveView()和RsfreshTOC()可用于刷新
一个结构化的示例代码:

3.1.2 地图文档的属性和方法
获取文件路径、设置制图文档的标题、设置数据框
>>> mapdoc = arcpy.mapping.MapDocument("CURRENT")
>>> listdf = arcpy.mapping.ListDataFrames(mapdoc)
>>> for fd in listdf:
print fd.name
fd.scale = 24000
>>> del mapdocDataFrame对象地图范围、比例尺、旋转、空间参考;panToExtend保持比例尺不变的情况下,居中显示
3.1.3 图层
两种方式:
- Layer函数:
- ListLayers函数

从磁盘获取*.lyr文件,并获取他们的名字的例子:

注解:例子中*.lyr中包含了多个图层,故可将其作为ListLayers的参数
重要的属性和方法:
- ly.name 图层名称
- ly.showLabels 显示当前地图文档中所有图层的标注
- ly.dataSource获取图层的完整路径名称
- ly.datasetName获取图层的名称
- ly.support判断图层是否支持某一属性
>>> from arcpy import env
>>> env.workspace = r"E:\Amiee\ArcGISlearn\全部章节源码\十六章"
>>> mapd = arcpy.mapping.MapDocument("CURRENT")
>>> lry = arcpy.mapping.Layer(mapd)
>>> for ly in lyr:
... print ly.dataSource
... print ly.datasetName
... print ly.supports("LONGNAME")3.1.4 输出和打印地图
输出

打印
![]()
3.2 处理PDF文档
合并pdf文档:

打印地图文档的所有页面

4 程序调试与错误处理
4.1 错误识别
- 错误类型:拼写错误、标点错误、缩进错误
- for语句末尾的冒号:
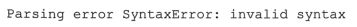
- pythonWin中可以使用Check进行语法检查,

- 没有语法错误的提示


- 显示行号:View>Options>Editer
- 缩进不一致:

- 空格检查:

- View>Whitespace显示脚本中的缩进字符
- 不建议从其他文件复制代码
- 虽然提示的某一行,但实际错误可能是在上一行
4.2 程序调试
分析错误、添加print语句输出、选择性注释代码、调试器
4.2.1 pythonWin调试


4.2.2 调试技巧
- 处理大文件时,尝试在一个性质相同且数据量较小的文件上运行代码
- 通过print语句或断点监视变量值的变化
- 在可能重复运行的地方设置断点
- 文件锁定,防止文件被覆盖
4.2.3 常见错误

