aws在云上保存数据(3)
相关资源文档:https://docs.aws.amazon.com/index.html

1.存储对象S3和Glacier
- 1.1对象存储概念
- 1.2Amazon S3
- 1.3Amazon Glacier
- 1.4以程序的方式存储对象
- 1.5使用S3来实现静态网站托管
- 1.6对象存储的内部机制
2.在硬盘上存储数据:EBS和实例存储
3.使用关系数据库服务:RDB
4.使用NoSQL数据库服务:DynamoDB
1.存储对象S3和Glacier
对象存储可以帮助用户存储:图片,文档,视频,可执行文件。
AWS提供对象存储服务Amazon S3 和 备份及归档的存储服务Amazon Glacier。
对象存储概念
在对象存储里,数据存储为对象。
每个对象由以下三个部分组成:
- 一个全球唯一的标识符
- 元数据
- (内容)对象本身组成。
对象的全球唯一的标识符成为键,有了这个全球唯一的标识符,才可以使用分布式文件系统中的不同设备和机器访问每个对象。
元数据和数据的分离使客户可以直接操作元数据来管理和查询数据,只有在必要时才加载数据本身。
Amazon S3
文档:https://docs.aws.amazon.com/zh_cn/s3/?id=docs_gateway
Amazon Simple Storage Service (Amazon S3) 是一种面向 Internet 的存储服务。您可以通过 Amazon S3 随时在 Web 上的任何位置存储和检索的任意大小的数据。您可以使用 AWS 管理控制台简单而直观的 web 界面来完成这些任务。
S3是一个典型的Web服务,让用户可以通过HTTPS和API来存储和访问数据。
S3提供了无限的存储空间,让用户的数据高可用和高度持久化的保存。
用户可以保存任何类型的数据,如:图片,文档和二进制文件,只要单个对象的容量不超过5TB。
用户需要为保存在S3的每GB的容量付费,同时还有少量的成本花费在每个数据请求和数据传输流量上。
可以通过管理控制台使用HTTPS协议访问S3,通过CLI,SDK和第三方工具来上传和下载对象。
S3使用存储桶组织对象。
存储桶是对象的容器。
用户最多可以创建100个存储桶,每个存储桶都有全球唯一的名字。
典型的使用场景:
- 使用S3和AWS CLI来备份和恢复文件
- 归档对象到Amazon Glacier比归档到S3更节省成本
- 使用AWS SDK集成Amazon S3到应用程序,以保存和读取图片这样的文件
- 托管静态网站的内容,让所有人都可以访问到
使用CLI上传数据和从S3下载数据:
aws CLI命令使用:
aws[key Value...]
aws help:显示所有可用服务
aws:显示对该服务所有可用操作help
aws:显示特定服务特定操作的所有选项help
1.首先要为数据创建一个S3存储桶,存储桶的名字必须全球唯一
aws s3 mb s3://
2.上传自己的数据:选择一个我们想要备份的目录,如桌面目录。
尽量选择一个合适的目录,其中的文件大小不超过1GB,且文件数量不少于1000个,这样既不会等待太长时间,也不会超过免费使用的用量
aws s3 sync $LocalPath s3:///<桶中的目录名>
sync命令比较本地目录和s3存储桶中的目录,然后只上传新的或修改过的文件
3.下载上传的数据:
aws s3 cp --recursive s3:///<桶中的目录名> $LocalPath
4.删除上传的文件
rb:remove bucket
force选项将在删除存储桶之前,强制删除桶里的每个对象
aws s3 rb --force s3://
5.移除存储桶造成BucketNotEmpty报错
如果激活了存储桶的版本控制功能,删除存储桶时将报错BucketNotEmpty错误。
这种情况下不适用CLI来删除存储桶,而是使用Web GUI界面来删除存储桶:
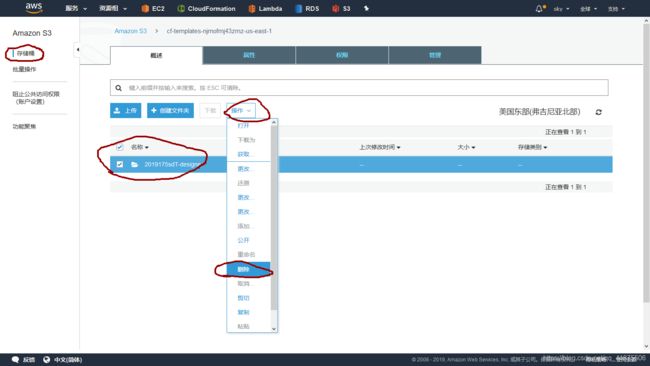
【管理控制台】—【s3服务】----【存储桶】----【操作】----【删除存储桶】
对象的版本
默认情况下,S3存储桶禁用了版本功能:即相同主键的数据只能存在一份。
可以为存储桶激活版本控制功能来保护数据。
aws s3api put-bucket-versioning --bucket--versioning-configuration Status=Enable
使用下面的命令获取所有的对象和版本
aws s3api list-object-versions --bucket
注意:需要付费的存储桶的容量将随新版本的增加而增加
我们不需要担心存储在s3上的数据的丢失,s3默认具有持久性。
Amazon Glacier
文档:https://docs.aws.amazon.com/zh_cn/glacier/?id=docs_gateway
Amazon Glacier 是一种针对不常用的数据(“冷数据”)而经过了优化的存储服务。 这项服务为数据存档和备份提供了持久且成本极低的存储解决方案及安全功能。使用 Amazon Glacier,您可以将数据经济高效地存储数月、数年,甚至数十年。Amazon Glacier 可让您将存储扩展到 AWS 并卸下操作以及管理负担,这样,您就不必担心容量规划、硬件配置、数据复制、硬件故障检测和恢复,或者耗时的硬件迁移等问题。
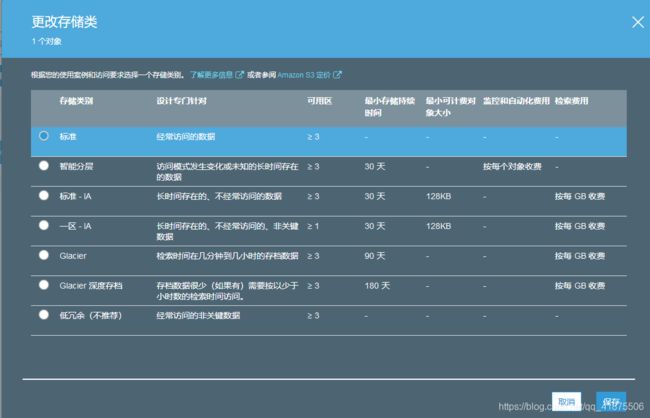
如果希望降低备份存储的成本,应该考虑使用Glacier服务。
在Glacier中存储数据的成本大约是S3中的1/3.
使用S3和Glacier存储数据的区别:
| S3 | Glacier | |
|---|---|---|
| 每GB容量成本 | 0.003美元 | 0.001美元 |
| 数据访问速度 | 立即可以访问 | 在提交请求3-5h后 |
| 持久性 | 设计为年度99.999999999%的数据持久性 | 设计为年度99.999999999%的数据持久性 |
用户可以通过HTTPS直接使用Glacier服务,或者集成S3一起使用。
创建S3存储桶配合Glacier一起使用:如何集成S3和Glacier来降低数据的存储成本
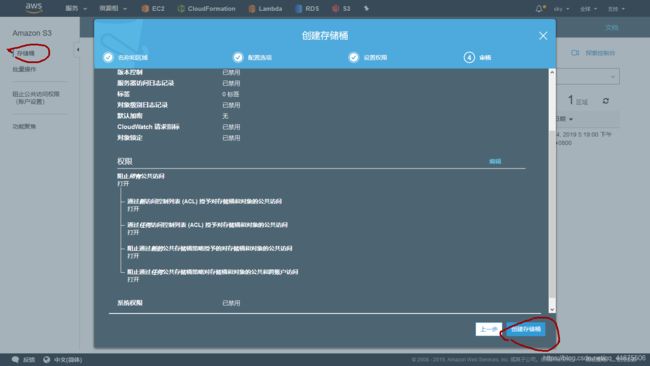
1.首先创建一个新的S3存储桶:此次使用Web GUI而不是CLI创建
【管理控制台】----【s3服务】----【创建存储桶】----输入唯一的桶名,选择区域----点击【创建】
为已经创建好的存储桶添加生命周期规则:
可以添加一条或多条生命周期规则到存储桶,以管理对象的生命周期。
生命周期规则可以用来在给定的日期之后归档或者删除对象,可以帮助把S3对象归档到Glacier。
添加一条生命周期规则来移动对象到Glacier:
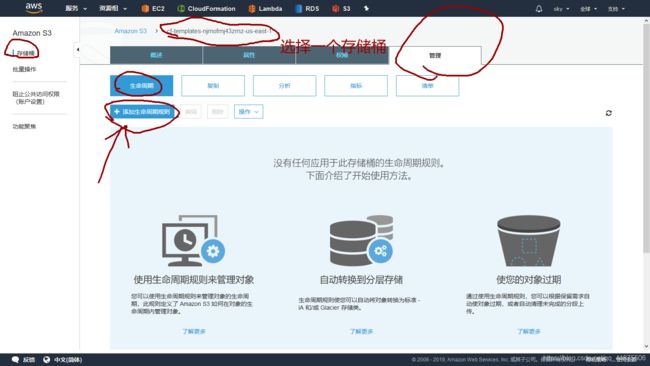
1.【s3】—选择一个已经创建好的存储桶-----【管理】----【生命周期】-----【添加生命周期规则】
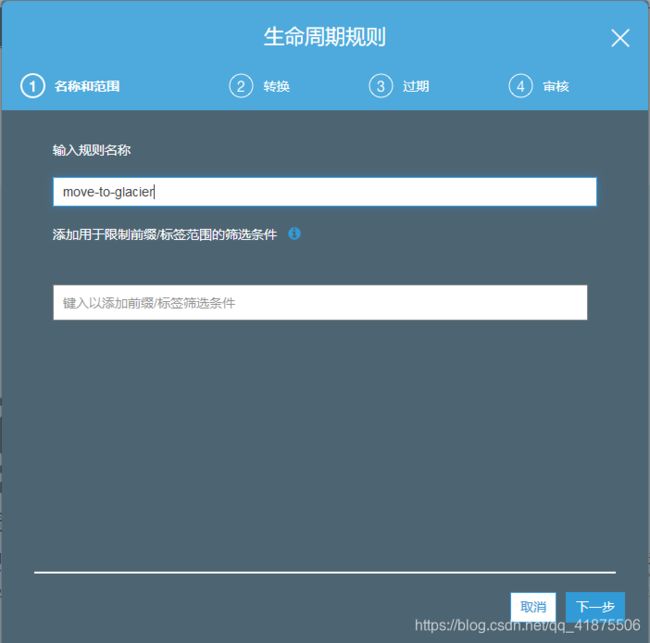
2.完成生命周期规则的向导设置:
第一步:选择生命周期规则的目标,输入规则名称,在筛选条件的文本框保持空白,以将生命周期规则应用到整个存储桶,点击下一步
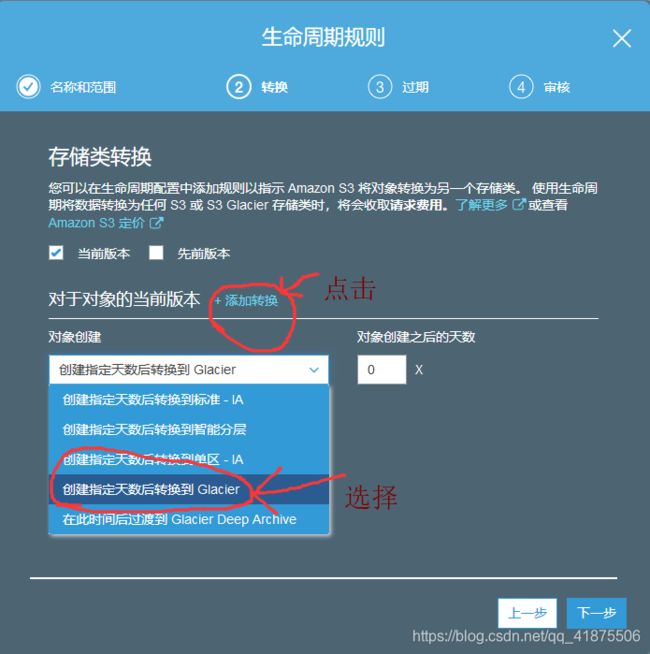
第二步:配置生命周期规则,选择【当前版本】为配置的转换目标,点击【添加转换】,选择【转换到Glacier前经过…】。为了尽快触发生命周期规则转化来让对象一旦创建就归档,选择在对象创建0天后进行转换
第三步:跳过,直接点击下一步
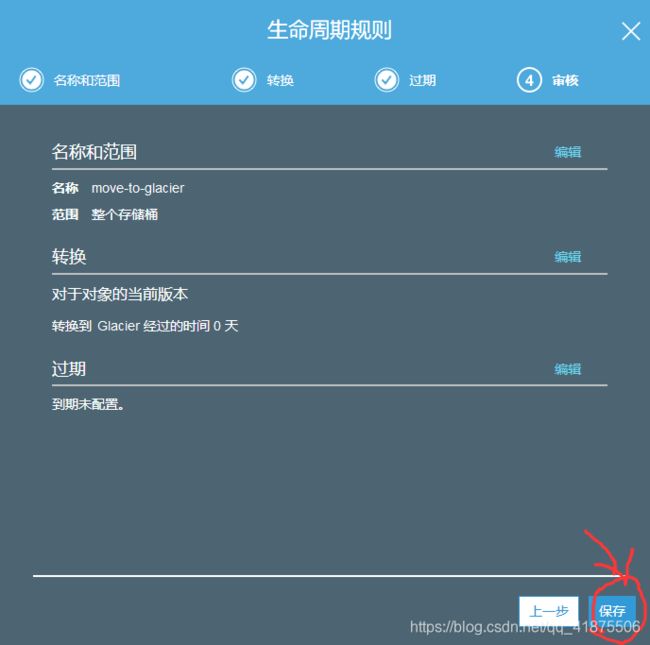
第四步:检查规则细节无误后,点击【保存】
测试Glacier和生命周期规则
测试刚刚创建的生命周期管理规则,它将自动把对象从S3存储桶转移至Glacier。
注意:移动对象到Glacier大概会花费24h左右的时间,从Glacier恢复数据到S3大概需要3-5h。
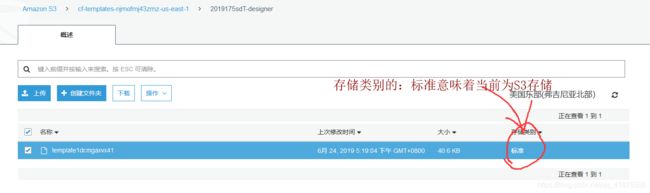
选择一个存储桶,点击【上传】来上传文件到存储桶。
默认情况下,所有文件都保存在【标准】存储类别,这意味着它们目前保存在S3中。
生命周期规则将移动对象到Glacier。但是即使把时间设为0天,移动过程仍会需要24h左右。
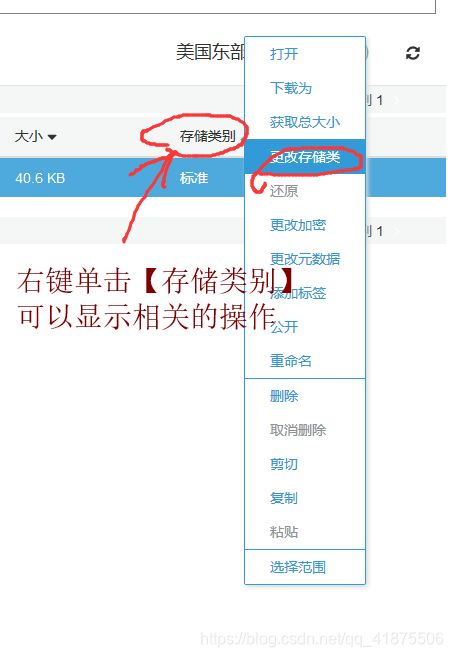
在对象移动到Glacier后,存储类别会切换为Glacier。
用户无法直接下载存储在Glacier中的文件,但是可以触发一个【恢复存储】的过程来从Glacier恢复对象到S3。
使用如下步骤在管理控制台触发恢复操作:
【s3存储桶】—选择希望从Glacier恢复的对象并点击【更多】----选择【启动还原】—在弹出的对话框了选择对象从Glacier恢复后要保留在S3的天数,选择要检索的速度项(标准检索3-5h)—点击【还原】来发起恢复----恢复对象大概需要3-5h,在恢复完成后,可以下载对象
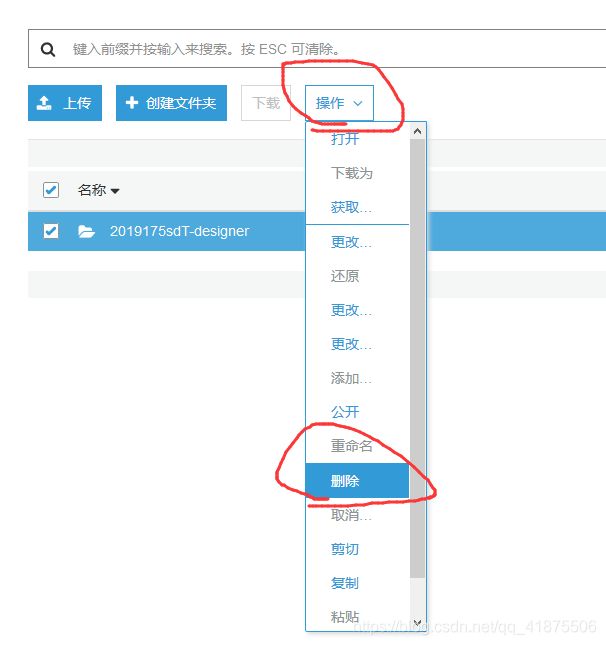
利用Web GUI进行资源清理:删除自己的存储桶
以程序的方式存储对象
S3可以通过HTTPS和API访问,这意味着用户可以集成S3到应用程序当中,用程序调用API来提交请求到S3。
Amazon S3 REST API Introduction :https://docs.aws.amazon.com/zh_cn/AmazonS3/latest/API/Welcome.html
使用S3来实现静态网站托管
可以使用S3来服务一个静态的网站,并且服务静态的内容,如:HTML,CSS,图片(PNG,JPG,JIF),音频,视频等。
不能在S3执行服务器端脚本(如PHP或JSP),但是可以在客户端执行存储在S3上的客户端脚本文件(如Javascript)。
通过CDN(Content Delivery Network,内容分发网络)来提高网站速度:
使用CDN帮助减少静态网站内容的加载时间。
CDN在全球范围内分发HTML,CSS和图片这样的静态内容。
一旦用户请求访问静态内容,CDN可以从最近的位置以最低的延迟返回结果给用户。
Amazon S3不是一个CDN,但是可以让S3作为AWS的CDN服务器:Amazon CloudFront的源服务器。
Amazon CloudFront 可加快分发静态和动态 Web 内容(例如,.html、.css、.php、图像和媒体文件)的过程。当用户请求内容时,CloudFront 通过可提供低延迟和高性能的全球边缘站点网络交付相应内容。
文档:https://docs.aws.amazon.com/zh_cn/cloudfront/?id=docs_gateway
S3还提供了一些服务静态网站的功能:
- 指定自定义的index文档和error文档
- 定义对所有或者特定的页面请求进行重定向
- 为S3存储桶设置自定义的域名
使用S3托管静态网站内容
后续可以使用S3作为CloudFront的源服务器,利用CDN加速静态网站的访问速度。
1.创建存储桶并上传一个静态网站
通过CLI创建一个新的存储桶:
aws s3 mb s3://
现在存储桶是空的,接下来保存一个HTML文档进去。
使用CLI(也可以使用Web GUI,即管理控制台)
aws s3 cp $LocalPath/s3:// /
2.配置存储桶来实现静态网站托管
默认情况下,只有文件的拥有者可以访问S3存储桶的文件。
使用S3来提供静态网站服务的话,就需要允许所有人查看或下载存储桶里的文件。
存储桶策略 可以用来在全局控制存储桶里的对象的访问权限。
存储桶策略类似于IAM策略。
IAM策略:使用JSON定义权限,它包含了一个或多个声明,并且一个声明里允许或者拒绝特定操作对某个资源的访问。
存储桶策略源码:https://s3.amazonaws.com/awsinaction/chapter7/bucketpolicy.json{ "Version":"2012-10-17", "Statement":[ { "Sid":"AddPerm", "Effect":"Allow", //允许访问 "Principal": "*", //任何人 "Action":["s3:GetObject"], //去下载对象 "Resource":["arn:aws:s3:::$BucketName/*"] //从你的存储桶里 } ] }使用下面的命令添加桶策略到存储桶:
aws s3api put-bucket-policy --bucket $BucketName --policy file://$PathToPolicy/bucketpolicy.json
现在存储桶里的所有对象可以被任何人下载。
接下来需要激活和配置S3服务静态网站:
aws s3 website s3://$BucketName --index-document helloworld.html
存储桶现在已经配置为一个静态网站,使用helloworld作为索引页面。
3.访问S3上托管的静态网站
可以通过浏览器访问静态网站。
要现选择正确的端点,根据存储桶所在区域的不同,S3静态网站的端点也可能不相同:
$BucketName.s3-website-$Region.amzonaws.com
现在这个存储桶创建在默认的区域us-east-1,所以输入$BucketName来组成存储桶的端点,替换$Region为us-east-1
$BucketName.s3-website-us-east-1.amazonaws.com
使用浏览器打开这个URL可以看到一个Hello World网站。
4.关联一个自定义的域名到s3存储桶
如果用户不想使用$BucketName.s3-website-$Region.amazonaws.com这样的域名作为静态网站的域名,用户可以关联一个自定义的域名到S3存储桶。
用户只需要为自己的域名添加一个CNAME别名记录,让该记录指向S3存储桶的端点即可。
CNAME别名记录只在满足下面条件的时候生效:
- 存储桶名必须和别名记录一样。例如:要创建一个CNAME给static.yourdomain.com,存储桶名也必须是static.yourdomain.com。
- CNAME别名记录不适用于主域名。可以给子域名创建别名记录的资源,如static或www这样前缀的域名。如果想关联主域名到s3存储桶,需要使用AWS提供的Route53的DNS服务。
5.资源清理
完成示例后为了不产生额外的费用,使用如下代码清理所用的资源:
aws s3 rb --force s3://$BucketName
对象存储的内部机制
S3存储是最终一致的。
确保数据的一致性
在s3上创建,更新或是删除对象的操作是原子操作:即如果用户在创建,更新或删除之后读取这个对象,永远不会读到失效的或是一半的数据。但是有可能读取操作会在一段时间里只返回旧的数据。
s3提供的是最终一致性:如果上传一个已有对象的新的版本,并且s3对该请求返回成功代码,意味着数据已经安全的保存在s3,但是,立即去下载更新后的对象仍可能返回旧的版本。过一段时间后才可以获取到更新后的版本。
在上传新对象后,立即提交的读请求会读到一致的数据,但是更新或删除之后的读请求将返回一个最终一致的结果。
选择合适的键
为存储在S3上的对象选择合适的键:键的命名决定了该键保存在哪一个分区。
为所有对象的键在开头的部分使用相同的字符串将限制s3存储桶的最大I/O性能。
应该为对象选择开头不同的字符串作为键,这会带来最大的I/O性能。
即:为了改善I/O性能,不要使用开头相同的字符串作为键
通过为每个对象的键添加 散列前缀 的方式可以使每个键的开头字符串尽可能的不同,这样有助于分配对象键到不同的分区,从而达到最优的I/O性能。
在键中使用一个斜线(/)的效果就像为对象创建目录一样。 如果用户创建的对象的键为folder/object.png,在通过管理控制台这样的图形化界面浏览存储桶时,用户会看到目录。但是从技术的本质看,对象的键仍是folder/object.png。
2.在硬盘上存储数据:EBS和实例存储
用户就像在个人电脑上那样,可以使用磁盘文件系统(FAT32,NTFS,ext3,ext4,XFS等)和块级别的存储来存储文件。
块是顺序的字节和最小的寻址单位。
OS位于需要访问文件的应用程序和底层的文件系统和块存储的中间。
FS负责管理文件放在底层的块级别存储的具体哪个位置(哪个块的地址)。
块级别的存储只能在运行OS的EC2实例上使用。
OS通过打开,写,读 系统调用来提供对块级别存储的访问。
简化后的读请求操作流程:
- 应用程序想要读取文件/path/to/file.txt,然后提交了一个读系统调用
- OS转发读请求给FS
- FS把/path/to/file.txt翻译成具体存储数据的磁盘的数据块
数据库这样的应用程序通过使用系统调用的方式来读写文件,它们必须能够访问块级别的存储来持久化的保存数据。因为MySQL必须使用系统调用访问文件,所以不能把MySQL的DB的文件保存在对象存储里(如S3,Glacier)。
AWS提供两种级别的块存储:
- 网络附加存储(高可用):通过网卡附加到EC2实例
- 实例存储(高性能):提供你的EC2实例的主机系统提供的正常的物理磁盘
大多数情况下,网络附加存储是最好的选择,因为它提供了99.999%的可用性,但是实例存储提供更好的性能,因为实例存储不需要网络,直接使用EC2实例自带的物理磁盘。
网络附加存储
EBS(Elastic Block Storage)弹性块存储提供网络附加的,数据块级别的存储,并且提供99.999%的可用性。
如何在EC2实例上使用EBS卷
EBS卷:
- EBS卷是独立的资源,不是EC2实例的一部分,但是可以挂载到一个EC2实例上使用,它们通过网卡附加到EC2实例。如果终结了EC2实例,EBS卷仍然存在。
- 可以独立存在或者挂载到一个EC2实例上
- 可以像普通磁盘一样使用
- 类似于RAID1,在后台把数据保存到多块磁盘上
- 不能同时挂载一块EBS卷到多台EC2实例
1.创建EBS卷并挂载到服务器
EBS卷是一个独立的资源,这意味着它可以独立于EC2实例存在,但是需要一台EC2服务器才能使用EBS卷。
下面为如在CloudFormation的帮助下创建一个EBS卷,并挂载到一个EC2实例。"Server": { "Type": "AWS::EC2::Instance", "Properties": { [...] } }, "Volume": { "Type": "AWS::EC2::Volume", //EBS卷描述 "Properties": { "AvailabilityZone": {"Fn::GetAtt" ["Server", "AvailabilityZone"]}, "Size": "5", //5GB容量 "VolumeType": "gp2" //基于SSD } }, "VolumeAttachment": { //附加EBS卷到EC2实例(服务器) "Type": "AWS::EC2::VlomeAttachment", "Properties": { "Device": "/dev/xvdf", //设备名,通常EBS卷可以在/dev/xvdf到/dev/xvdp下面找到。 "instanceId": {"Ref": "Server"}, "VolumeId": {"Ref": "Volume"} } }2.使用弹性数据块存储
https://s3.amazonaws.com/awsinaction/chapter8/ebs.json 的CloudFormation模板,基于该模板创建一个堆栈,设置AttachVolume参数为yes,然后复制Public-Name输出,并且通过SSH进行连接。
使用fdisk命令可以看到已经附加的EBS卷。
通常EBS卷可以在/dev/xvdf到/dev/xvdp下面找到。
根卷/dev/xvda是一个例外:在启动EC2实例时,它基于选择的AMI创建,并且包含了所有用于引导实例的信息(操作系统文件)。
sudo fdisk -l
创建一个新的EBS卷时,必须在上面创建一个文件系统。
你还可以在EBS卷上创建不同的分区,但是分区不是使用EBS卷的最佳实践。
应创建和需求相同容量大小的卷,在需要两个单独的分区的情况下,直接创建两个卷更合适。
在Linux中,可以使用mkfs命令来创建文件系统。
下面的例子创建了一个ext4的文件系统:
sudo mkfs -t ex4 /dev/xvdf
文件系统创建完成后,就可以挂载文件系统到一个目录:
sudo mkdir /mnt/volume/
sudo mount /dev/xvdf /mnt/volume/
使用df -h命令可以查看已经挂载的卷
EBS卷最大的一个优势:他们不属于EC2实例,是独立的资源(利用此项特性可以实现无状态的服务器)。
我们可以保存文件到EBS卷,然后去掉挂载,并从EC2上摘掉该卷,这样就可以了解到它独立于EC2的特性:
sudo touch /mnt/volume/testfile
sudo umount /mnt/volume/
现在更新CloudFormation堆栈,修改AttachVolume参数为no,这个操作将从EC2上摘掉EBS卷,在堆栈更新完成后,EC2上只剩下系统根卷。
sudo fdisk -l
/mnt/volume/中的测试文件也没有了:ls /mnt/volume/
现在重新挂载EBS卷到EC2实例:更改CloudFormation堆栈,并修改AttachVolume参数为yes。
在更新完成后,/dev/xvdf重新可以访问:
sudo mount /dev/xvdf /mnt/volume/
ls /mnt/volume/testfile
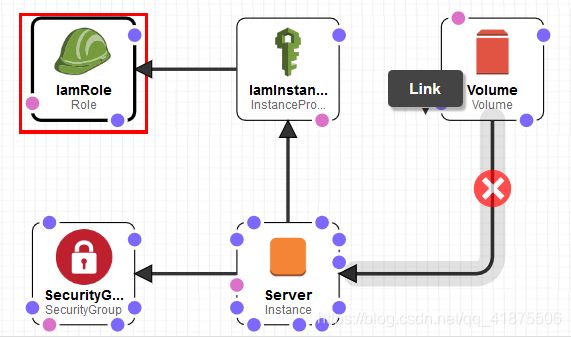
CloudFormation
设计图:
IamRole(AWS::IAM::Role)"IamRole": { "Type": "AWS::IAM::Role", "Properties": { "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "ec2.amazonaws.com" ] }, "Action": [ "sts:AssumeRole" ] } ] }, "Path": "/", "Policies": [ { "PolicyName": "ec2", "PolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeVolumes", "ec2:CreateSnapshot", "ec2:DescribeSnapshots", "ec2:DeleteSnapshot" ], "Resource": "*" } ] } } ] }, "Metadata": { "AWS::CloudFormation::Designer": { "id": "c4bf970b-5ecd-429f-96f9-af91bfe1f21d" } } },IamInstanceProfile(AWS::IAM::InstanceProfile)
"IamInstanceProfile": { "Type": "AWS::IAM::InstanceProfile", "Properties": { "Path": "/", "Roles": [ { "Ref": "IamRole" } ] }, "Metadata": { "AWS::CloudFormation::Designer": { "id": "09d2b1eb-9208-4747-bc95-77f1dbf00e16" } } },SecurityGrop(AWS::EC2::SecurityGroup)
"SecurityGroup": { "Type": "AWS::EC2::SecurityGroup", "Properties": { "GroupDescription": "My security group", "VpcId": { "Ref": "VPC" }, "SecurityGroupIngress": [ { "CidrIp": "0.0.0.0/0", "FromPort": 22, "IpProtocol": "tcp", "ToPort": 22 } ] }, "Metadata": { "AWS::CloudFormation::Designer": { "id": "0e2bac9c-7411-4e1f-a69e-e0ac3d7f2b64" } } },Server(AWS::EC2::Instance)
"Server": { "Type": "AWS::EC2::Instance", "Properties": { "IamInstanceProfile": { "Ref": "IamInstanceProfile" }, "ImageId": { "Fn::FindInMap": [ "EC2RegionMap", { "Ref": "AWS::Region" }, "AmazonLinuxAMIHVMEBSBacked64bit" ] }, "InstanceType": "t2.micro", "KeyName": { "Ref": "KeyName" }, "SecurityGroupIds": [ { "Ref": "SecurityGroup" } ], "SubnetId": { "Ref": "Subnet" } }, "Metadata": { "AWS::CloudFormation::Designer": { "id": "1c8d95d3-6952-4c57-a08d-3ae4cbe0fd7b" } } },Volume(AWS::EC2::Volume)
"Volume": { "Type": "AWS::EC2::Volume", "Properties": { "AvailabilityZone": { "Fn::GetAtt": [ "Server", "AvailabilityZone" ] }, "Size": "5", "VolumeType": "gp2" }, "Metadata": { "AWS::CloudFormation::Designer": { "id": "a59cfe7b-622c-4a85-a281-c3aeae14d395" } } },3.性能
硬盘的测试性能通常分为读操作和写操作测试。
用户可以使用许多不同的工具进行测试,一个简单的工具是dd,它可以通过指定数据源if=/到源路径和目标of=/到目标路径来进行数据块级别的读写测试。
sudo dd if=/dev/zero of=/mnt/volume/tempfile bs=1M count=1024 conv=fdatasync,notrunc每次写1M,进行1024次写测试
echo 3 | sudo tee /proc/sys/vm/drop_caches缓存清空至磁盘
sudo dd if=/mnt/volume/tempfile of=/dev/null bs=1M count=1024每次读1M,进行1024次读测试
EBS卷更加复杂:存储性能取决于EC2的实例类型和EBS卷的类型。
根据工作负载的要求,你需要选择一个能够提供足够带宽的EC2实例类型,另外EBS卷必须能够充分使用EC2提供的带宽。
不管使用了多少容量,EBS卷都按照卷容量的大小来收费。
如果使用的是物理磁盘,则需要为每次I/O操作付费。
如果使用预配置IOPS性能的EBS卷(SSD磁盘),还需要为预先配置的IOPS性能付费。
建议默认使用通用的SSD磁盘,如果工作负载需要更多的IOPS性能,推荐使用预先配置IOPS性能的SSD磁盘。
用户可以附加多个EBS卷到一个EC2实例来增加容量或总体的性能,但是一个EBS卷只能同时挂载到一个EC2实例。
可以把多个EBS卷挂载到同一台EC2实例,并使用软件RAID0来提升性能。RAID0技术让数据分散到多块磁盘,但是同一数据仅存储在一块磁盘上,在Linux中可以使用mdadm来创建软件RAID
4.备份数据
EBS卷提供99.999%的可用性,但是仍然需要不时的备份数据(对于银行系统来说尤为重要)
EBS卷提供了优化的易于使用的快照功能来备份EBS卷的数据。
快照是存储在S3上的块级别的数据复制。
EBS卷的快照收费取决于你使用的GB容量。
如果卷的大小是5GB,并且上面保存了1GB的数据,第一个快照的大小是1GB左右,在创建第一个快照后,只有更改过的数据才会被保存在S3,以节省备份的容量。
快照的创建:
在创建快照之前需要获取EBS卷的ID,可以在CloudFormation的输出内容里找到VolumeId卷ID,或者通过CLI运行下面的命令:
aws --region us-east-1 ec2 describe-volumes --filters "Name=size,Values=5" --query "Volumes[].VolumeId" --output text
有了卷ID,接下来就可以创建一个快照:
aws --region us-east-1 ec2 create-snapshot --volume-id $VolumeId
根据卷的容量大小和改变的数据量的不同,创建快照的时间也不一样,使用下面的命令查看快照的状态:
aws --region us-east-1 ec2 describe-snapshots --snapshot-ids $SnapshotId
可以在一个已经挂载并且正在使用的EBS卷上创建快照,但是如果内存缓存中还有尚未写入磁盘的数据,这可能会带来一些问题,如果必须在EBS卷使用的时候创建快照,可以使用下面的步骤来安全的创建快照:
- 在服务器上运行
fsfreeze -f /mnt/volume命令来冻结所有写操作- 创建快照
- 使用
fsfreeze -u /mnt/volume命令来恢复写操作- 等待快照操作完成
用户只需要在开始请求创建快照时冻结I/O。
从一个AMI(AMI是一个快照)创建EC2的时候,AWS使用EBS快照来创建一个新的EBS卷(根卷)
要恢复快照里的数据,你必须基于快照来创建一个新的EBS卷。当用户从AMI来创建一台EC2实例时,AWS基于快照来创建一个新的EBS卷。
快照的删除:
aws --region us-east-1 ec2 delete-snapshot --snapshot-id $SnapshotId
在完成这一部分的时候还需要删除整个堆栈以清理所有用过的资源,否则会为用到的资源付费。
实例存储
实例存储像物理磁盘一样提供块级别的存储。
实例存储是EC2的一部分(故不能实现无状态的服务器),并且只有在EC2实例正常运行的时候才可用。如果停止或终结实例,上面的数据不会持久化保存,所以不需要为实例存储单独付费,实例存储的价格包含在EC2实例价格里面。
和通过网络挂载在EC2上的EBS卷不同,实例存储包含在虚拟服务器中,没有虚拟服务器就不在存在。
不要使用实例存储来存放不能丢失的数据,把它用来存放缓存,临时数据和一些在多个节点间复制数据的应用如某些DB。如果使用NoSQL DB,应用很有可能负责复制数据,这样用户可以安全的使用实例存储来获得最高的I/O性能。
注意:如果用户停止或终结自己的EC2实例,实例存储上的数据就会丢失,这意味着用户的数据会被删除并且无法恢复。
AWS提供SSD和物理磁盘的实例存储。
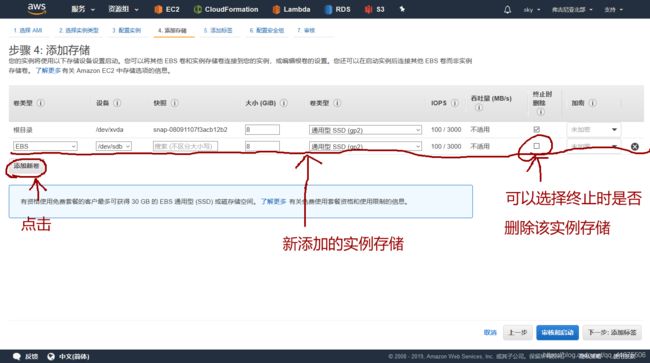
通过Web GUI(AWS console,AWS控制台)来创建一个提供实例存储的EC2实例:
- 打开控制台,运行EC2实例创建向导
- 完成1-3步
- 在第4步为配置实例存储:点击【添加新卷】,其余使用默认设置即可。
- 完成5-7步:为实例打标签,配置安全组,检查并启动实例
现在EC2实例可以使用实例存储了。
使用CloudFormation来创建实例存储
如果用户启动EBS卷为根卷的EC2实例(默认)用户必须定义BlockDeviceMappings来映射EBS卷和实例存储到特定的设备名。
和创建EBS卷的模板不同,实例存储不是标准的独立资源,实例存储是EC2的一部分:根据实例类型的不同,可以选择【0-n】个实例存储作为映射。"Server": { "Type": "AWS::EC2::Instance", "Properties": { "InstanceType": "m3.medium", [...] "BlockDeviceMappings": [{ "DeviceName": "/dev/xvda", //EBS根卷,存放OS文件 "Ebs": { "VolumeSize": "8", "VolumeType": "gp2" } },{ "DeviceName": "/dev/xvdb", //实例存储会显示为/dev/xvdb设备文件 "VirtualName": "ephemeral0" //实例存储的虚拟名称为ephemeral0或ephemeral1 }] } }1.使用实例存储
https://s3.amazonaws.com/awsinaction/chapter8/instance_store.json 使用该CloudFormation模板创建堆栈,复制PublicName的输出,并使用SSH登录到EC2实例,可以使用fdisk命令查看挂载的实例存储。通常实例存储可以在/dev/xvdb到/dev/xvde设备文件中找到。
sudo fdisk -l查看挂载的实例
df -h查看挂载的卷
实例存储将自动挂载到/media/ephemeral0目录下。
如果EC2实例有多个实例存储,将会分别挂载到ephemeral1,ephemeral2等目录下。
2.性能测试
使用相同的性能测试来比较实例存储和EBS卷
sudo dd if=/dev/zero of=/media/ephemeral0/temfile bs=1M count=1024 conv=fdatasync,notruncEBS三倍的读性能
sudo dd if=/media/ephemeral0/tempfile of=/dev/null bs=1M count=1024EBS四倍的写性能
实例存储就像一个普通的磁盘,性能也和一个普通的磁盘相近。
3.备份数据
实例存储卷没有内建的方法来备份数据,可以使用liunx中的定时任务cron命令及AWS S3结合来定期备份数据。
aws s3 sync /path/to/data s3:///
如果需要备份实例存储的数据,很可能持久化的EBS卷会是更合适的选择,实例存储更适合对数据持久化要求不高的数据。
比较块存储解决方案:S3,EBS(网络附加存储),实例存储
| S3 | EBS | 实例存储 | |
|---|---|---|---|
| 常见的使用场景 | 集成到应用程序当中以保存用户上传的内容 | 为需要块级别存储的DB或传统应用程序提供持久化 | 提供临时数据存储或者为内建复制技术来防止数据丢失的应用程序提供高性能的存储 |
| 独立的资源 | 是 | 是 | 否 |
| 如何访问数据 | HTTPS API | EC2实例/系统调用 | EC2实例/系统调用 |
| 是否有文件系统FS | 无 | 有 | 有 |
| 防止数据丢失 | 很高 | 高 | 低 |
| 每GB容量成本 | 中 | 高 | 低 |
| 运维成本 | 无 | 低 | 中 |
使用实例存储和EBS卷提供共享FS
仅使用AWS提供的块级别存储解决方案无法解决下面的问题:同时在多个EC2实例之间共享块存储。
用户可以使用网络文件系统NFS(Network File System)协议来解决这个问题。
Amazon Elastic File System
文档:https://docs.aws.amazon.com/zh_cn/efs/?id=docs_gateway
EFS是一个分布式的文件存储系统,基于网络文件系统第四版(Network File System Version 4,NFSv4)协议。用户可以使用EFS来解决在多台服务器之间共享数据块的需求。
3.使用关系数据库服务:RDB
*====*
4.使用NoSQL数据库服务:DynamoDB
*====*