(〇)CUDA10.1+VS2019的开发环境
(〇)CUDA10.1+VS2019的开发环境
- 一、Microsoft Visual Studio 2019 的安装与配置
-
-
-
- 1. 首先到微软官网下载VS2019的下载器。[链接地址](https://visualstudio.microsoft.com/vs/#visual-studio-2019-launch-videos)
- 2. 运行已经下载好的VS2019的管理器(由于本人PC已经安装VS,所以部分内容不予截图)
-
-
- 二、cuda10.1+cudnn10.1的安装
- 三、cuda10.1在VS2019中的配置与使用
水平有限,若有错误,请不吝赐教: [email protected]。
文章中的代码均上传至博主 Gitee主页
书写不易,跪求点赞支持
一、Microsoft Visual Studio 2019 的安装与配置
1. 首先到微软官网下载VS2019的下载器。链接地址
个人用户选择Community版本,商业用途请选择购买其他版本。
2. 运行已经下载好的VS2019的管理器(由于本人PC已经安装VS,所以部分内容不予截图)
- a. 点击"继续",等待安装器完成初次运行配置;
- b. 选择"工作负载"标签页下的"使用C++"的桌面开发;
- c. 点击进入"单个组件" 标签页,增选其中的 “Help Viewer”,“Nuget包管理器”;
- d. 选择右下角下滑菜单中的"下载时安装"选项,后点击"安装"。
- e. 估计只要一杯茶的时间,就可以享受地表最强IDE了。(注:VS2019的其他组件视情况安装,不建议更改默认的安装路径)
二、cuda10.1+cudnn10.1的安装
- cuda软件的安装并不复杂,可以算的上是简单。可以参考NVIDIA的官方文档,或者其他一些博主的文章。
- 推荐一些目测靠谱的文章链接:1 (注意安装之前一定要确认自己的计算机支持CUDA编程。)
- 为了下一步的方便,展示一下本人为CUDA建立的环境变量:
a. 在系统变量中建立的环境变量:“变量名:CUDA_PATH;变量值:D:\CUDA\NVIDIA GPU Computing Toolkit\CUDA\v10.1” 或者“CUDA_PATH_V10_1;变量值:D:\CUDA\NVIDIA GPU Computing Toolkit\CUDA\v10.1”
b. 在系统变量PATH下建立的环境变量:
%CUDA_PATH%\bin
%CUDA_PATH%\lib\x64
%CUDA_PATH%\include


然后win+R输入nvcc -V,检查是否安装正常。
三、cuda10.1在VS2019中的配置与使用
这一部分最为麻烦。
- 创建一个空项目
- a. 运行VS2019,选择“空项目”,然后点击“下一步”;
- b. 项目名称填写"cudaEnvironmentTest"(除中文及特殊字符外,随意),位置选择桌面,勾选“将解决方案与项目放在同一目录中”,点击“创建”。静等项目创建完毕。
- 创建cuda源文件
- a. 展开IDE最右边的“解决方案资源管理器”,右键项目名,选择“生成依赖项”中的“生成自定义”选项。
- b. 勾选“CUDA10.1”,然后点击“确定”。
- c. 右键“源文件”,选择“添加”中的“新建项”。
- d. 选择"NVIDIA CUDA 10.1"标签页下的"Code"选项,然后在右侧窗口点击选中"CUDA C/C++ File",在名称中输入“main”。
- e. 右键"main.cu"文件,单击属性。将“项类型”选择为"CUDA C/C++"。
- 配置CUDA10.1依赖
- a. 将在IDE菜单栏下面,点击“Debug”右边的下拉菜单,调整成"x64";(务必记得)
- b. 然后在菜单栏中点击“视图”下拉菜单,选择“其他窗口”中的“属性管理器”
- c. 在属性管理器中,单击展开“项目名”,再单击展开“Debug|x64”.
- d. 右键单击“Debug|x64”,选择“添加新项目属性表”,选中“属性表”选项。在“名称”栏中,为属性表起一个容易分辨的名字。这里我选择的是“CudaEnvironmentForPC.proc”,然后“添加”。(点击并且记住下面的路径。等会儿要来找他。)
- e. 选中“CudaEnvironmentForPC”,Ctrl+S保存一下。然后右键,“CudaEnvironmentForPC”,点击“属性”。
- f. 先添加头文件的路径:(.h)
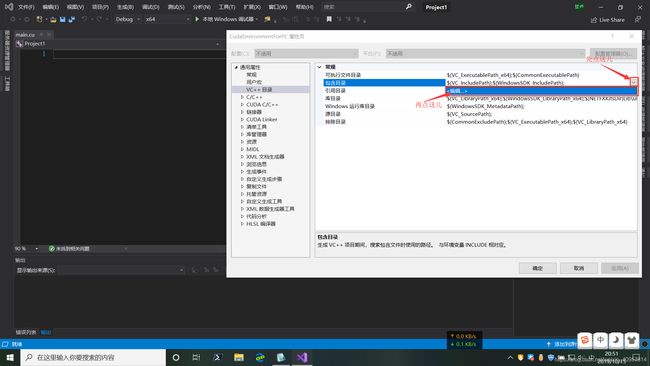
展开右侧边栏中的“通用属性”,选中“VC++目录”。然后点击包含目录右侧格子的下拉菜单,然后点击“编辑”。
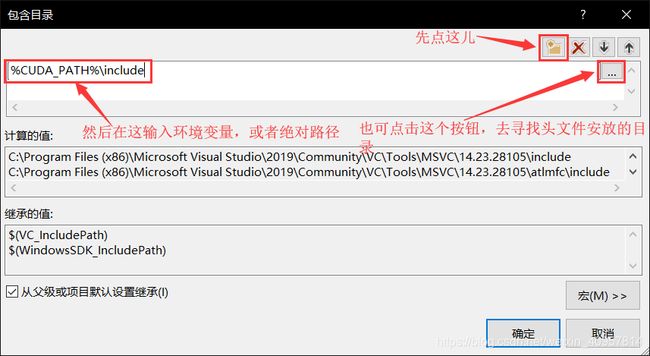
然后,点击右上角四个按钮中的左边数第一个,然后在下边新建的表格中输入刚才的环境变量:$(CUDA_PATH)\include,或者CUDA include目录的绝对路径(包含目录的添加方式大致是这样)
- g. 再添加库文件的路径:(.lib)
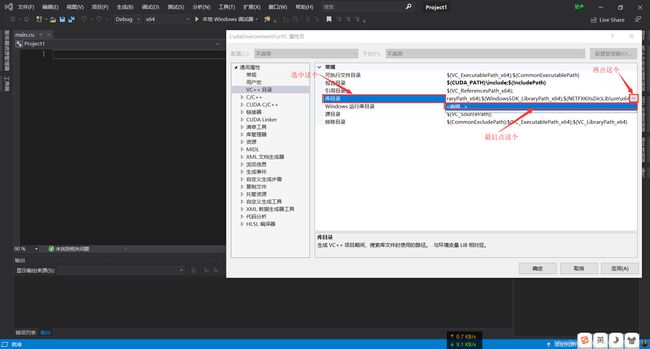
点击“包含目录”下方的“库目录”,点击“库目录”右侧格子的下拉菜单,然后点击“编辑”
然后点击右上角四个按钮中的左边数第一个,然后在下边新建的表格中输入刚才的环境变量:$(CUDA_PATH)\lib\x64,或者CUDA lib目录的绝对路径(库文件目录的添加方式大致是这样)
- h. 最后完成链接器的配置:
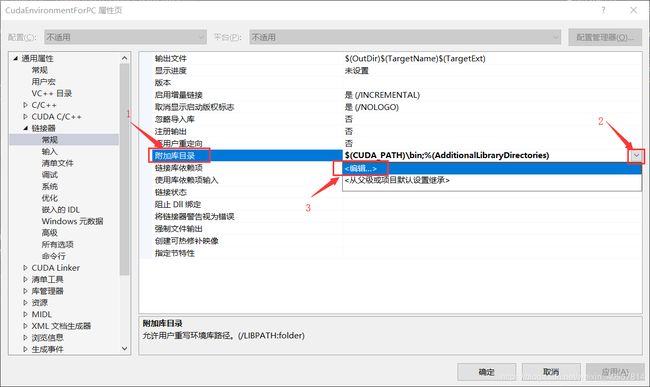
展开左侧栏中的“链接器”目录,选中“常规”项。在右侧选中“附加库目录”,点击右侧格子的下拉菜单,然后单击“编辑”
然后点击右上角四个按钮中的左边数第一个,然后在下边新建的表格中输入刚才的环境变量:$(CUDA_PATH)\bin,或者CUDA bin目录的绝对路径
选中左侧栏中的“链接器”目录下的“输入”,在右侧栏中选中附加依赖项 点击右侧格子的下拉菜单,然后单击“编辑”
然后在白框中输入lib\x64文件夹下所有.lib文件名用";“隔开。(这里有个小技巧,win+R输入cmd回车后打开cmd窗口,切换到lib\x64文件夹下.输入dir /B > a.txt.最后将用word将a.txt文档中的段落标记替换成”;"即可)

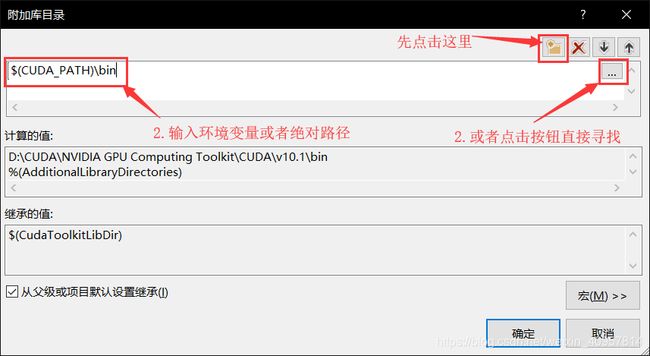

- I. 点击右下角的“应用”,然后点击“确定”。大功告成,最后在main.cu粘入代码测试
注意:要运行此文件需要在cuda安装时,选择NVIDIA Corporation。并且在项目配置时引用这个包的
包含目录(…\NVIDIA Corporation\CUDA Samples\v10.1\common\inc)和
库目录(…\NVIDIA Corporation\CUDA Samples\v10.1\common\lib\x64)
#include
#include
#include
#include
#include
int* pArgc = NULL;
char** pArgv = NULL;
#if CUDART_VERSION < 5000
#include
template
inline void getCudaAttribute(T* attribute, CUdevice_attribute device_attribute,
int device) {
CUresult error = cuDeviceGetAttribute(attribute, device_attribute, device);
if (CUDA_SUCCESS != error) {
fprintf(
stderr,
"cuSafeCallNoSync() Driver API error = %04d from file <%s>, line %i.\n",
error, __FILE__, __LINE__);
exit(EXIT_FAILURE);
}
}
#endif /* CUDART_VERSION < 5000 */
int main(int argc, char** argv) {
pArgc = &argc;
pArgv = argv;
printf("%s Starting...\n\n", argv[0]);
printf(
" CUDA Device Query (Runtime API) version (CUDART static linking)\n\n");
int deviceCount = 0;
cudaError_t error_id = cudaGetDeviceCount(&deviceCount);
if (error_id != cudaSuccess) {
printf("cudaGetDeviceCount returned %d\n-> %s\n",
static_cast(error_id), cudaGetErrorString(error_id));
printf("Result = FAIL\n");
exit(EXIT_FAILURE);
}
if (deviceCount == 0) {
printf("There are no available device(s) that support CUDA\n");
}
else {
printf("Detected %d CUDA Capable device(s)\n", deviceCount);
}
int dev, driverVersion = 0, runtimeVersion = 0;
for (dev = 0; dev < deviceCount; ++dev) {
cudaSetDevice(dev);
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("\nDevice %d: \"%s\"\n", dev, deviceProp.name);
cudaDriverGetVersion(&driverVersion);
cudaRuntimeGetVersion(&runtimeVersion);
printf(" CUDA Driver Version / Runtime Version %d.%d / %d.%d\n",
driverVersion / 1000, (driverVersion % 100) / 10,
runtimeVersion / 1000, (runtimeVersion % 100) / 10);
printf(" CUDA Capability Major/Minor version number: %d.%d\n",
deviceProp.major, deviceProp.minor);
char msg[256];
#if defined(WIN32) || defined(_WIN32) || defined(WIN64) || defined(_WIN64)
sprintf_s(msg, sizeof(msg),
" Total amount of global memory: %.0f MBytes "
"(%llu bytes)\n",
static_cast(deviceProp.totalGlobalMem / 1048576.0f),
(unsigned long long)deviceProp.totalGlobalMem);
#else
snprintf(msg, sizeof(msg),
" Total amount of global memory: %.0f MBytes "
"(%llu bytes)\n",
static_cast(deviceProp.totalGlobalMem / 1048576.0f),
(unsigned long long)deviceProp.totalGlobalMem);
#endif
printf("%s", msg);
printf(" (%2d) Multiprocessors, (%3d) CUDA Cores/MP: %d CUDA Cores\n",
deviceProp.multiProcessorCount,
_ConvertSMVer2Cores(deviceProp.major, deviceProp.minor),
_ConvertSMVer2Cores(deviceProp.major, deviceProp.minor) *
deviceProp.multiProcessorCount);
printf(
" GPU Max Clock rate: %.0f MHz (%0.2f "
"GHz)\n",
deviceProp.clockRate * 1e-3f, deviceProp.clockRate * 1e-6f);
#if CUDART_VERSION >= 5000
// This is supported in CUDA 5.0 (runtime API device properties)
printf(" Memory Clock rate: %.0f Mhz\n",
deviceProp.memoryClockRate * 1e-3f);
printf(" Memory Bus Width: %d-bit\n",
deviceProp.memoryBusWidth);
if (deviceProp.l2CacheSize) {
printf(" L2 Cache Size: %d bytes\n",
deviceProp.l2CacheSize);
}
#else
int memoryClock;
getCudaAttribute(&memoryClock, CU_DEVICE_ATTRIBUTE_MEMORY_CLOCK_RATE,
dev);
printf(" Memory Clock rate: %.0f Mhz\n",
memoryClock * 1e-3f);
int memBusWidth;
getCudaAttribute(&memBusWidth,
CU_DEVICE_ATTRIBUTE_GLOBAL_MEMORY_BUS_WIDTH, dev);
printf(" Memory Bus Width: %d-bit\n",
memBusWidth);
int L2CacheSize;
getCudaAttribute(&L2CacheSize, CU_DEVICE_ATTRIBUTE_L2_CACHE_SIZE, dev);
if (L2CacheSize) {
printf(" L2 Cache Size: %d bytes\n",
L2CacheSize);
}
#endif
printf(
" Maximum Texture Dimension Size (x,y,z) 1D=(%d), 2D=(%d, "
"%d), 3D=(%d, %d, %d)\n",
deviceProp.maxTexture1D, deviceProp.maxTexture2D[0],
deviceProp.maxTexture2D[1], deviceProp.maxTexture3D[0],
deviceProp.maxTexture3D[1], deviceProp.maxTexture3D[2]);
printf(
" Maximum Layered 1D Texture Size, (num) layers 1D=(%d), %d layers\n",
deviceProp.maxTexture1DLayered[0], deviceProp.maxTexture1DLayered[1]);
printf(
" Maximum Layered 2D Texture Size, (num) layers 2D=(%d, %d), %d "
"layers\n",
deviceProp.maxTexture2DLayered[0], deviceProp.maxTexture2DLayered[1],
deviceProp.maxTexture2DLayered[2]);
printf(" Total amount of constant memory: %lu bytes\n",
deviceProp.totalConstMem);
printf(" Total amount of shared memory per block: %lu bytes\n",
deviceProp.sharedMemPerBlock);
printf(" Total number of registers available per block: %d\n",
deviceProp.regsPerBlock);
printf(" Warp size: %d\n",
deviceProp.warpSize);
printf(" Maximum number of threads per multiprocessor: %d\n",
deviceProp.maxThreadsPerMultiProcessor);
printf(" Maximum number of threads per block: %d\n",
deviceProp.maxThreadsPerBlock);
printf(" Max dimension size of a thread block (x,y,z): (%d, %d, %d)\n",
deviceProp.maxThreadsDim[0], deviceProp.maxThreadsDim[1],
deviceProp.maxThreadsDim[2]);
printf(" Max dimension size of a grid size (x,y,z): (%d, %d, %d)\n",
deviceProp.maxGridSize[0], deviceProp.maxGridSize[1],
deviceProp.maxGridSize[2]);
printf(" Maximum memory pitch: %lu bytes\n",
deviceProp.memPitch);
printf(" Texture alignment: %lu bytes\n",
deviceProp.textureAlignment);
printf(
" Concurrent copy and kernel execution: %s with %d copy "
"engine(s)\n",
(deviceProp.deviceOverlap ? "Yes" : "No"), deviceProp.asyncEngineCount);
printf(" Run time limit on kernels: %s\n",
deviceProp.kernelExecTimeoutEnabled ? "Yes" : "No");
printf(" Integrated GPU sharing Host Memory: %s\n",
deviceProp.integrated ? "Yes" : "No");
printf(" Support host page-locked memory mapping: %s\n",
deviceProp.canMapHostMemory ? "Yes" : "No");
printf(" Alignment requirement for Surfaces: %s\n",
deviceProp.surfaceAlignment ? "Yes" : "No");
printf(" Device has ECC support: %s\n",
deviceProp.ECCEnabled ? "Enabled" : "Disabled");
#if defined(WIN32) || defined(_WIN32) || defined(WIN64) || defined(_WIN64)
printf(" CUDA Device Driver Mode (TCC or WDDM): %s\n",
deviceProp.tccDriver ? "TCC (Tesla Compute Cluster Driver)"
: "WDDM (Windows Display Driver Model)");
#endif
printf(" Device supports Unified Addressing (UVA): %s\n",
deviceProp.unifiedAddressing ? "Yes" : "No");
printf(" Device supports Compute Preemption: %s\n",
deviceProp.computePreemptionSupported ? "Yes" : "No");
printf(" Supports Cooperative Kernel Launch: %s\n",
deviceProp.cooperativeLaunch ? "Yes" : "No");
printf(" Supports MultiDevice Co-op Kernel Launch: %s\n",
deviceProp.cooperativeMultiDeviceLaunch ? "Yes" : "No");
printf(" Device PCI Domain ID / Bus ID / location ID: %d / %d / %d\n",
deviceProp.pciDomainID, deviceProp.pciBusID, deviceProp.pciDeviceID);
const char* sComputeMode[] = {
"Default (multiple host threads can use ::cudaSetDevice() with device "
"simultaneously)",
"Exclusive (only one host thread in one process is able to use "
"::cudaSetDevice() with this device)",
"Prohibited (no host thread can use ::cudaSetDevice() with this "
"device)",
"Exclusive Process (many threads in one process is able to use "
"::cudaSetDevice() with this device)",
"Unknown",
NULL };
printf(" Compute Mode:\n");
printf(" < %s >\n", sComputeMode[deviceProp.computeMode]);
}
if (deviceCount >= 2) {
cudaDeviceProp prop[64];
int gpuid[64]; // we want to find the first two GPUs that can support P2P
int gpu_p2p_count = 0;
for (int i = 0; i < deviceCount; i++) {
checkCudaErrors(cudaGetDeviceProperties(&prop[i], i));
if ((prop[i].major >= 2)
#if defined(WIN32) || defined(_WIN32) || defined(WIN64) || defined(_WIN64)
&& prop[i].tccDriver
#endif
) {
// This is an array of P2P capable GPUs
gpuid[gpu_p2p_count++] = i;
}
}
int can_access_peer;
if (gpu_p2p_count >= 2) {
for (int i = 0; i < gpu_p2p_count; i++) {
for (int j = 0; j < gpu_p2p_count; j++) {
if (gpuid[i] == gpuid[j]) {
continue;
}
checkCudaErrors(
cudaDeviceCanAccessPeer(&can_access_peer, gpuid[i], gpuid[j]));
printf("> Peer access from %s (GPU%d) -> %s (GPU%d) : %s\n",
prop[gpuid[i]].name, gpuid[i], prop[gpuid[j]].name, gpuid[j],
can_access_peer ? "Yes" : "No");
}
}
}
}
printf("\n");
std::string sProfileString = "deviceQuery, CUDA Driver = CUDART";
char cTemp[16];
sProfileString += ", CUDA Driver Version = ";
#if defined(WIN32) || defined(_WIN32) || defined(WIN64) || defined(_WIN64)
sprintf_s(cTemp, 10, "%d.%d", driverVersion / 1000, (driverVersion % 100) / 10);
#else
snprintf(cTemp, sizeof(cTemp), "%d.%d", driverVersion / 1000,
(driverVersion % 100) / 10);
#endif
sProfileString += cTemp;
sProfileString += ", CUDA Runtime Version = ";
#if defined(WIN32) || defined(_WIN32) || defined(WIN64) || defined(_WIN64)
sprintf_s(cTemp, 10, "%d.%d", runtimeVersion / 1000, (runtimeVersion % 100) / 10);
#else
snprintf(cTemp, sizeof(cTemp), "%d.%d", runtimeVersion / 1000,
(runtimeVersion % 100) / 10);
#endif
sProfileString += cTemp;
sProfileString += ", NumDevs = ";
#if defined(WIN32) || defined(_WIN32) || defined(WIN64) || defined(_WIN64)
sprintf_s(cTemp, 10, "%d", deviceCount);
#else
snprintf(cTemp, sizeof(cTemp), "%d", deviceCount);
#endif
sProfileString += cTemp;
sProfileString += "\n";
printf("%s", sProfileString.c_str());
printf("Result = PASS\n");
exit(EXIT_SUCCESS);
}
运行结果:
