2.SparkCore-RDD编程
二、 RDD编程
1、编程模型
在Spark中,RDD被表示为对象,通过对象上的方法调用来对RDD进行转换。经过一系列的transformations定义RDD之后,就可以调用actions触发RDD的计算,action可以是向应用程序返回结果(count, collect等),或者是向存储系统保存数据(saveAsTextFile等)。在Spark中,只有遇到action,才会执行RDD的计算(即延迟计算),这样在运行时可以通过管道的方式传输多个转换。
要使用Spark,开发者需要编写一个Driver程序,它被提交到集群(Application)以调度运行Worker,如下图所示。Driver中定义了一个或多个RDD,并调用RDD上的action,Worker则执行RDD分区计算任务。
| 术语 |
描述 |
| Application |
Spark的应用程序,包含一个Driver program和若干Executor |
| SparkContext |
Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor |
| Driver Program |
运行Application的main()函数并且创建SparkContext |
| Executor |
是为Application运行在Worker node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。 每个Application都会申请各自的Executor来处理任务 |
| ClusterManager |
在集群上获取资源的外部服务(例如:Standalone、Mesos、Yarn) |
| Worker Node |
集群中任何可以运行Application代码的节点,运行一个或多个Executor进程,每个节点可以起一个或多个Executor |
| Task |
运行在Executor上的工作单元,每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task,每个Task执行的结果就是生成了目标RDD的一个partiton |
| Job |
SparkContext提交的具体Action操作,常和Action对应 |
| Stage |
每个Job会被拆分很多组task,每组任务被称为Stage,也称TaskSet |
| RDD |
是Resilient distributed datasets的简称,中文为弹性分布式数据集;是Spark最核心的模块和类 |
| DAGScheduler |
根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler |
| TaskScheduler |
将Taskset提交给Worker node集群运行并返回结果 |
| Transformations |
是Spark API的一种类型,Transformation返回值还是一个RDD, 所有的Transformation采用的都是懒策略, 如果只是将Transformation提交是不会执行计算的 |
| Action |
是Spark API的一种类型,Action返回值不是一个RDD,而是一个scala集合;计算只有在Action被提交的时候计算才 被触发。 |
2、RDD创建
在Spark中创建RDD的创建方式大概可以分为三种:从集合中创建RDD;从外部存储创建RDD;从其他RDD创建。
(1)由一个已经存在的Scala集合创建,集合并行化。
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
而从集合中创建RDD,Spark主要提供了两种函数:parallelize和makeRDD。我们可以先看看这两个函数的声明:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T]
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T]
我们可以从上面看出makeRDD有两种实现,而且第一个makeRDD函数接收的参数和parallelize完全一致。其实第一种makeRDD函数实现是依赖了parallelize函数的实现,来看看Spark中是怎么实现这个makeRDD函数的:
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
我们可以看出,这个makeRDD函数完全和parallelize函数一致。但是我们得看看第二种makeRDD函数函数实现了,它接收的参数类型是Seq[(T, Seq[String])],Spark文档的说明是:
Distribute a local Scala collection to form an RDD, with one or more location preferences (hostnames of Spark nodes) for each object. Create a new partition for each collection item.
原来,这个函数还为数据提供了位置信息,来看看我们怎么使用:
scala> val bigdata1= sc.parallelize(List(1,2,3))
bigdata1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at
scala> val bigdata2 = sc.makeRDD(List(1,2,3))
bigdata2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[11] at makeRDD at
scala> val seq = List((1, List("slave01")),(2, List("slave02")))
seq: List[(Int, List[String])] = List((1,List(slave01)),
(2,List(slave02)))
scala> val bigdata3 = sc.makeRDD(seq)
bigdata3: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at makeRDD at
scala> bigdata3.preferredLocations(bigdata3.partitions(1))
res26: Seq[String] = List(slave02)
scala> bigdata3.preferredLocations(bigdata3.partitions(0))
res27: Seq[String] = List(slave01)
scala> bigdata1.preferredLocations(bigdata1.partitions(0))
res28: Seq[String] = List()
我们可以看到,makeRDD函数有两种实现,第一种实现其实完全和parallelize一致;而第二种实现可以为数据提供位置信息,而除此之外的实现和parallelize函数也是一致的,如下:
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), seq.size, indexToPrefs)
}
都是返回ParallelCollectionRDD,而且这个makeRDD的实现不可以自己指定分区的数量,而是固定为seq参数的size大小。
由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
scala> val bigdata = sc.textFile("hdfs://node01:8020/RELEASE")
bigdata: org.apache.spark.rdd.RDD[String] = hdfs:// hadoop102:9000/RELEASE MapPartitionsRDD[4] at textFile at
(2)读取文件生成
可以从Hadoop支持的任何存储源创建分布式数据集,包括本地文件系统,HDFS,Cassandra,HBase等
scala> val file = sc.textFile("/spark/hello.txt")

(3)其他方式
读取数据库等等其他的操作。也可以生成RDD。
RDD可以通过其他的RDD转换而来的。
3、TransFormation
RDD编程APISpark支持两个类型(算子)操作:Transformation和Action
Transformation主要做的是就是将一个已有的RDD生成另外一个RDD。Transformation具有lazy特性(延迟加载)。Transformation算子的代码不会真正被执行。只有当我们的程序里面遇到一个action算子的时候,代码才会真正的被执行。这种设计让Spark更加有效率地运行。
| 转换 |
含义 |
| map(func) |
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
| union(otherDataset) |
对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) |
对源RDD和参数RDD求交集后返回一个新的RDD(交集) |
| distinct([numTasks])) |
对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) |
先按分区聚合 再总的聚合 每次要跟初始值交流 例如:aggregateByKey(0)(_+_,_+_) 对k/y的RDD进行操作 |
| sortByKey([ascending], [numTasks]) |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) |
与sortByKey类似,但是更灵活 第一个参数是根据什么排序 第二个是怎么排序 false倒序 第三个排序后分区数 默认与原RDD一样 |
| join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD 相当于内连接(求交集) |
| cogroup(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable |
| cartesian(otherDataset) |
两个RDD的笛卡尔积 的成很多个K/V |
| coalesce(numPartitions) |
重新分区 第一个参数是要分多少区,第二个参数是否shuffle 默认false 少分区变多分区 true 多分区变少分区 false |
| repartition(numPartitions) |
重新分区 必须shuffle 参数是要分多少区 少变多 |
| foldByKey(zeroValue)(seqOp) |
该函数用于K/V做折叠,合并处理 ,与aggregate类似 第一个括号的参数应用于每个V值 第二括号函数是聚合例如:_+_ |
| combineByKey |
合并相同的key的值 rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) |
| partitionBy(partitioner) |
对RDD进行分区 partitioner是分区器 例如new HashPartition(2 |
| cache |
RDD缓存,可以避免重复计算从而减少时间,区别:cache内部调用了persist算子,cache默认就一个缓存级别MEMORY-ONLY ,而persist则可以选择缓存级别 |
| persist |
|
| Subtract(rdd) |
返回前rdd元素不在后rdd的rdd(差集) |
| leftOuterJoin |
leftOuterJoin类似于SQL中的左外关联left outer join,返回结果以前面的RDD为主,关联不上的记录为空。只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可。 |
| rightOuterJoin |
rightOuterJoin类似于SQL中的有外关联right outer join,返回结果以参数中的RDD为主,关联不上的记录为空。只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可 |
| subtractByKey |
substractByKey和基本转换操作中的subtract类似只不过这里是针对K的,返回在主RDD中出现,并且不在otherRDD中出现的元素 |
(1)map(func)
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
scala> var source = sc.parallelize(1 to 10)
source: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[8] at parallelize at
scala> source.collect()
res7: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> val mapadd = source.map(_ * 2)
mapadd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[9] at map at
scala> mapadd.collect()
res8: Array[Int] = Array(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
(2)mapPartitions(func)
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U]。假设有N个元素,有M个分区,那么map的函数的将被调用N次,而mapPartitions被调用M次,一个函数一次处理所有分区
scala> res0.mapPartitions(x=>Iterator(x.mkString("-"))).collect
res4: Array[String] = Array(1-2-3-4)
| rdd的mapPartitions是map的一个变种,它们都可进行分区的并行处理。 两者的主要区别是调用的粒度不一样:map的输入变换函数是应用于RDD中每个元素,而mapPartitions的输入函数是应用于每个分区。 假设一个rdd有10个元素,分成3个分区。如果使用map方法,map中的输入函数会被调用10次;而使用mapPartitions方法的话,其输入函数会只会被调用3次,每个分区调用1次。 |
(3) flatMap(func)
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
scala>val result: RDD[String] = sc.parallelize(Array("a b c","d e f"))
scala>println(result.collect().toBuffer)
scala>println(result.flatMap(_.split(" ")).collect().toBuffer)
(4)filter(func)
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成
scala>var sourceFilter = sc.parallelize(Array("xiaoming","xiaojiang","xiaohe","dazhi"))
sourceFilter: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[10] at parallelize at
scala> val filter = sourceFilter.filter(_.contains("xiao"))
filter: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[11] at filter at
scala> sourceFilter.collect()
res9: Array[String] = Array(xiaoming, xiaojiang, xiaohe, dazhi)
scala> filter.collect()
res10: Array[String] = Array(xiaoming, xiaojiang, xiaohe)
(5) mapPartitionsWithIndex(func)
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U]
scala>val rdd = sc.parallelize(List(("kpop","female"),("zorro","male"),("mobin","male"),("lucy","female")))
rdd: org.apache.spark.rdd.RDD[(String, String)] = ParallelCollectionRDD[18] at parallelize at
scala> :paste
// Entering paste mode (ctrl-D to finish)
def partitionsFun(index : Int, iter : Iterator[(String,String)]) : Iterator[String] = {
var woman = List[String]()
while (iter.hasNext){
val next = iter.next()
next match {
case (_,"female") => woman = "["+index+"]"+next._1 :: woman
case _ =>
}
}
woman.iterator
}
// Exiting paste mode, now interpreting.
partitionsFun: (index: Int, iter: Iterator[(String, String)])Iterator[String]
scala> val result = rdd.mapPartitionsWithIndex(partitionsFun)
result: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[19] at mapPartitionsWithIndex at
scala> result.collect()
res14: Array[String] = Array([0]kpop, [1]lucy)
(6) distinct([numTasks]))
对源RDD进行去重后返回一个新的RDD. 默认情况下,只有8个并行任务来操作,但是可以传入一个可选的numTasks参数改变它。
scala> val distinctRdd = sc.parallelize(List(1,2,1,5,2,9,6,1))
distinctRdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[34] at parallelize at
scala> val unionRDD = distinctRdd.distinct()
unionRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[37] at distinct at
scala> unionRDD.collect()
[Stage 16:> (0 + 4) [Stage 16:=============================> (2 + 2) res20: Array[Int] = Array(1, 9, 5, 6, 2)
scala> val unionRDD = distinctRdd.distinct(2)
unionRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[40] at distinct at
scala> unionRDD.collect()
res21: Array[Int] = Array(6, 2, 1, 9, 5)
(7) coalesce(numPartitions)
缩减分区数,用于大数据集过滤后,提高小数据集的执行效率。
scala> val rdd = sc.parallelize(1 to 16,4)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[54] at parallelize at
scala> rdd.partitions.size
res20: Int = 4
scala> val coalesceRDD = rdd.coalesce(3)
coalesceRDD: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[55] at coalesce at
scala> coalesceRDD.partitions.size
res21: Int = 3
(8) repartition(numPartitions)
根据分区数,从新通过网络随机洗牌所有数据。
scala> val rdd = sc.parallelize(1 to 16,4)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[56] at parallelize at
scala> rdd.partitions.size
res22: Int = 4
scala> val rerdd = rdd.repartition(2)
rerdd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[60] at repartition at
scala> rerdd.partitions.size
res23: Int = 2
scala> val rerdd = rdd.repartition(4)
rerdd: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[64] at repartition at
scala> rerdd.partitions.size
res24: Int = 4
(09) sortBy(func,[ascending], [numTasks])
用func先对数据进行处理,按照处理后的数据比较结果排序。
scala> val rdd = sc.parallelize(List(1,2,3,4))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[21] at parallelize at
scala> rdd.sortBy(x => x).collect()
res11: Array[Int] = Array(1, 2, 3, 4)
scala> rdd.sortBy(x => x%3).collect() //按照余数大小排序
res12: Array[Int] = Array(3, 4, 1, 2)
//增加案例
val rdd= sc.parallelize(List(("a",4),("c",2),("b",1)))
val rdd1: RDD[(String, Int)] = rdd.sortBy(_._2,false)
println(rdd1.collect().toBuffer)
(10)union(otherDataset)
对源RDD和参数RDD求并集后返回一个新的RDD 不去重
scala> val rdd1 = sc.parallelize(1 to 5)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[23] at parallelize at
scala> val rdd2 = sc.parallelize(5 to 10)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[24] at parallelize at
scala> val rdd3 = rdd1.union(rdd2)
rdd3: org.apache.spark.rdd.RDD[Int] = UnionRDD[25] at union at
scala> rdd3.collect()
res18: Array[Int] = Array(1, 2, 3, 4, 5, 5, 6, 7, 8, 9, 10)
(11) subtract (otherDataset)
计算差的一种函数,返回前rdd元素不在后rdd的rdd(差集)
scala> val rdd = sc.parallelize(3 to 8)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[70] at parallelize at
scala> val rdd1 = sc.parallelize(1 to 5)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[71] at parallelize at
scala> rdd.subtract(rdd1).collect()
res27: Array[Int] = Array(8, 6, 7)
(12) intersection(otherDataset)
对源RDD和参数RDD求交集后返回一个新的RDD,会对最后的数据去重
scala> val rdd1 = sc.parallelize(1 to 7)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[26] at parallelize at
scala> val rdd2 = sc.parallelize(5 to 10)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at parallelize at
scala> val rdd3 = rdd1.intersection(rdd2)
rdd3: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[33] at intersection at
scala> rdd3.collect()
res19: Array[Int] = Array(5, 6, 7)
(13)cartesian(otherDataset)
笛卡尔积
scala> val rdd1 = sc.parallelize(1 to 3)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[47] at parallelize at
scala> val rdd2 = sc.parallelize(2 to 5)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[48] at parallelize at
scala> rdd1.cartesian(rdd2).collect()
res17: Array[(Int, Int)] = Array((1,2), (1,3), (1,4), (1,5), (2,2), (2,3), (2,4), (2,5), (3,2), (3,3), (3,4), (3,5))
(14)partitionBy
对RDD进行分区操作,如果原有的partionRDD和现有的partionRDD是一致的话就不进行分区, 否则会生成ShuffleRDD。
scala> val rdd = sc.parallelize(Array((1,"aaa"),(2,"bbb"),(3,"ccc"),(4,"ddd")),4)
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[44] at parallelize at
scala> rdd.partitions.size
res24: Int = 4
scala> var rdd2 = rdd.partitionBy(new org.apache.spark.HashPartitioner(2))
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = ShuffledRDD[45] at partitionBy at
scala> rdd2.partitions.size
res25: Int = 2
(15) join(otherDataset, [numTasks])
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
scala> val rdd = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[32] at parallelize at
scala> val rdd1 = sc.parallelize(Array((1,4),(2,5),(3,6)))
rdd1: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[33] at parallelize at
scala> rdd.join(rdd1).collect()
res13: Array[(Int, (String, Int))] = Array((1,(a,4)), (2,(b,5)), (3,(c,6)))
(16) reduceByKey(func, [numTasks])
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,reduce任务的个数可以通过第二个可选的参数来设置。
scala> val rdd = sc.parallelize(List(("female",1),("male",5),("female",5),("male",2)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[46] at parallelize at
scala> val reduce = rdd.reduceByKey((x,y) => x+y)
reduce: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[47] at reduceByKey at
scala> reduce.collect()
res29: Array[(String, Int)] = Array((female,6), (male,7))
(17) groupByKey
groupByKey也是对每个key进行操作,但只生成一个sequence。
scala> val words = Array("one", "two", "two", "three", "three", "three")
words: Array[String] = Array(one, two, two, three, three, three)
scala> val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
wordPairsRDD: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[4] at map at
scala> val group = wordPairsRDD.groupByKey()
group: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[5] at groupByKey at
scala> group.collect()
res1: Array[(String, Iterable[Int])] = Array((two,CompactBuffer(1, 1)), (one,CompactBuffer(1)), (three,CompactBuffer(1, 1, 1)))
scala> val map = group.map(t => (t._1, t._2.sum))
map: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[7] at map at
scala> map.collect()
res4: Array[(String, Int)] = Array((two,2), (one,1), (three,3))
reduceByKey有map端的聚合操作,使得网络传输的数据量减小,效率要高于groupByKey
groupByKey 不会进行map端的聚合,而是讲map端的数据shuffle到reduce端,在reduce端进行数据的聚合操作
(18) sortByKey([ascending], [numTasks])
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
scala> val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[14] at parallelize at
scala> rdd.sortByKey(true).collect()
res9: Array[(Int, String)] = Array((1,dd), (2,bb), (3,aa), (6,cc))
scala> rdd.sortByKey(false).collect()
res10: Array[(Int, String)] = Array((6,cc), (3,aa), (2,bb), (1,dd))
(19) mapValues
针对于(K,V)形式的类型只对V进行操作
scala> val rdd3 = sc.parallelize(Array((1,"a"),(1,"d"),(2,"b"),(3,"c")))
rdd3: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[67] at parallelize at
scala> rdd3.mapValues(_+"|||").collect()
res26: Array[(Int, String)] = Array((1,a|||), (1,d|||), (2,b|||), (3,c|||))
| aggregateByKey aggregateByKey(3, seqFunc, combFunc) 其中第一个函数是初始值3代表每次分完组之后的每个组的初始值。 seqFunc代表combine的聚合逻辑,每一个mapTask的结果的聚合成为combine combFunc reduce端大聚合的逻辑 举例:val rdd2= sc.parallelize(List(1,2,3,4,5,6,7,8),2) 其中rdd2被分为两个分区,0分区的数据是1,2,3,4;1分区的数据是5,6,7,8 rdd2.aggregate(0)(math.max(_,_),_+_) 结果是12 分析:初始值0和第一个分区的数据比较,取最大值4,然后初始值0和第二个分区的数据比较,取最大值8,然后全局相加,全局相加的时候0也要加一次,所以 4+8+0=12 val rdd = sc.parallelize(List(("a",3),("a",2),("c",4),("b",3),("c",6),("c",8),("a",33),("c",6)),3) val res02 = rdd.aggregateByKey(0)(_+_,_+_).collect |
| combineByKey 是针对不同partition进行操作的。它的第一个参数用于数据初始化(后面着重讲),第二个是针对一个partition的combine操作函数,第三个是在所有partition都combine完毕后,针对所有临时结果进行combine操作的函数。 关于数据初始化 之前有人说,初始化是对每个数据进行操作,这其实是错误的。应该是针对每个partition中,每个key下的第一个数据进行操作。这句话怎么理解呢?看代码: val rdd1 = sc.parallelize(List(1,2,2,3,3,3,3,4,4,4,4,4), 2) val rdd2 = rdd1.map((_, 1)) val rdd3 = rdd2.combineByKey(-_, (x:Int, y:Int) => x + y, (x:Int, y:Int) => x + y) val rdd4 = rdd2.combineByKey(+_, (x:Int, y:Int) => x + y, (x:Int, y:Int) => x + y) rdd2.collect rdd3.collect rdd4.collect Array((1,1), (2,1), (2,1), (3,1), (3,1), (3,1), (3,1), (4,1), (4,1), (4,1), (4,1), (4,1)) Array((4,3), (2,0), (1,-1), (3,0)) Array((4,5), (2,2), (1,1), (3,4)) 在上述代码中,(1,1), (2,1), (2,1), (3,1), (3,1), (3,1) 被划分到第一个partition,(3,1), (4,1), (4,1), (4,1), (4,1), (4,1) 被划分到第二个。于是有如下操作: (1, 1):由于只有1个,所以在值取负的情况下,自然输出(1, -1) (2, 1):由于有2个,第一个取负,第二个不变,因此combine后为(2, 0) (3, 1):partition1中有3个,参照上述规则,combine后为(3, 1),partition2中有1个,因此combine后为(3, -1)。在第二次combine时,不会有初始化操作,因此直接相加,结果为(3, 0) (4, 1):过程同上,结果为(4, 3) |
4、Action
触发代码的运行,我们一段spark代码里面至少需要有一个action操作。
| 动作 |
含义 |
||
| reduce(func) |
通过func函数聚集RDD中的所有元素,这个功能必须是课交换且可并联的 |
||
| collect() |
在驱动程序中,以数组的形式返回数据集的所有元素 |
||
| count() |
返回RDD的元素个数 |
||
| first() |
返回RDD的第一个元素(类似于take(1)) |
||
| take(n) |
返回一个由数据集的前n个元素组成的数组 |
||
| takeSample(withReplacement,num, [seed]) |
返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
||
| takeOrdered(n, [ordering]) |
使用自然顺序或自定义比较器返回RDD 的前n个元素。 |
||
| saveAsTextFile(path) |
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
||
| saveAsSequenceFile(path) |
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
||
| saveAsObjectFile(path) |
使用Java序列化以简单格式编写数据集的元素,然后可以使用Java序列化加载SparkContext.objectFile()。 |
||
| countByKey() |
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
||
| foreach(func) |
在数据集的每一个元素上,运行函数func进行更新。 |
(1)reduce(func)
通过func函数聚集RDD中的所有元素,这个功能必须是可交换且可并联的
scala> val rdd1 = sc.makeRDD(1 to 10,2)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[85] at makeRDD at
scala> rdd1.reduce(_+_)
res50: Int = 55
scala> val rdd2 = sc.makeRDD(Array(("a",1),("a",3),("c",3),("d",5)))
rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[86] at makeRDD at
scala> rdd2.reduce((x,y)=>(x._1 + y._1,x._2 + y._2))
res51: (String, Int) = (adca,12)
(2) collect()
在驱动程序中,以数组的形式返回数据集的所有元素
(3)count()
返回RDD的元素个数
(4) first()
返回RDD的第一个元素(类似于take(1))
(5) take(n)
返回一个由数据集的前n个元素组成的数组
(6)takeOrdered(n)
返回前几个的排序
(7)saveAsTextFile(path)
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
(8) saveAsSequenceFile(path)
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。
(9) saveAsObjectFile(path)
用于将RDD中的元素序列化成对象,存储到文件中。
(10) countByKey()
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。
scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[95] at parallelize at
scala> rdd.countByKey()
res63: scala.collection.Map[Int,Long] = Map(3 -> 2, 1 -> 3, 2 -> 1)
(11) foreach(func)
在数据集的每一个元素上,运行函数func进行更新。
scala> var rdd = sc.makeRDD(1 to 10,2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[107] at makeRDD at
scala> var sum = sc.accumulator(0)
warning: there were two deprecation warnings; re-run with -deprecation for details
sum: org.apache.spark.Accumulator[Int] = 0
scala> rdd.foreach(sum+=_)
scala> sum.value
res68: Int = 55
scala> rdd.collect().foreach(println)
1
2
3
4
5
6
7
8
9
10
5、RDD持久化
1、RDD的缓存
Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存个数据集。当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他动作中重用。这使得后续的动作变得更加迅速。RDD相关的持久化和缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键。如果一个有持久化数据的节点发生故障,Spark 会在需要用到缓存的数据时重算丢失的数据分区。如果希望节点故障的情况不会拖累我们的执行速度,也可以把数据备份到多个节点上。
2、RDD缓存方式
RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM的堆空间中。
但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
通过查看源码发现cache最终也是调用了persist方法,默认的存储级别都是仅在内存存储一份,Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。

缓存有可能丢失,或者存储存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
注意:使用 Tachyon可以实现堆外缓存
scala> val rdd = sc.makeRDD(1 to 10)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[19] at makeRDD at
scala> val nocache = rdd.map(_.toString+"["+System.currentTimeMillis+"]")
nocache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[20] at map at
scala> val cache = rdd.map(_.toString+"["+System.currentTimeMillis+"]")
cache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[21] at map at
scala> cache.cache
res24: cache.type = MapPartitionsRDD[21] at map at
scala> nocache.collect
res25: Array[String] = Array(1[1505479375155], 2[1505479374674], 3[1505479374674], 4[1505479375153], 5[1505479375153], 6[1505479374675], 7[1505479375154], 8[1505479375154], 9[1505479374676], 10[1505479374676])
scala> nocache.collect
res26: Array[String] = Array(1[1505479375679], 2[1505479376157], 3[1505479376157], 4[1505479375680], 5[1505479375680], 6[1505479376159], 7[1505479375680], 8[1505479375680], 9[1505479376158], 10[1505479376158])
scala> nocache.collect
res27: Array[String] = Array(1[1505479376743], 2[1505479377218], 3[1505479377218], 4[1505479376745], 5[1505479376745], 6[1505479377219], 7[1505479376747], 8[1505479376747], 9[1505479377218], 10[1505479377218])
scala> cache.collect
res28: Array[String] = Array(1[1505479382745], 2[1505479382253], 3[1505479382253], 4[1505479382748], 5[1505479382748], 6[1505479382257], 7[1505479382747], 8[1505479382747], 9[1505479382253], 10[1505479382253])
scala> cache.collect
res29: Array[String] = Array(1[1505479382745], 2[1505479382253], 3[1505479382253], 4[1505479382748], 5[1505479382748], 6[1505479382257], 7[1505479382747], 8[1505479382747], 9[1505479382253], 10[1505479382253])
scala> cache.collect
res30: Array[String] = Array(1[1505479382745], 2[1505479382253], 3[1505479382253], 4[1505479382748], 5[1505479382748], 6[1505479382257], 7[1505479382747], 8[1505479382747], 9[1505479382253], 10[1505479382253])
cache.persist(org.apache.spark.storage.StorageLevel.MEMORY_ONLY)
6、RDD检查点机制
Spark中对于数据的保存除了持久化操作之外,还提供了一种检查点的机制,检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
cache 和 checkpoint 是有显著区别的,缓存把 RDD 计算出来然后放在内存中,但是RDD 的依赖链(相当于数据库中的redo 日志),也不能丢掉, 当某个点某个 executor 宕了,上面cache 的RDD就会丢掉, 需要通过依赖链重放计算出来,不同的是checkpoint 是把 RDD 保存在 HDFS中,是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链, 是通过复制实现的高容错。
如果存在以下场景,则比较适合使用检查点机制:
1)DAG中的Lineage过长,如果重算,则开销太大(如在PageRank中)。
2)在宽依赖上做Checkpoint获得的收益更大。
为当前RDD设置检查点。该函数将会创建一个二进制的文件,并存储到checkpoint目录中,该目录是用SparkContext.setCheckpointDir()设置的。在checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移出。对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
| import org.apache.spark.{SparkConf, SparkContext} |
scala> sc.setCheckpointDir("hdfs://node01:8020/checkpoint")
scala> val ch1 = sc.parallelize(1 to 2)
ch1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[33] at parallelize at
scala> val ch2 = ch1.map(_.toString+"["+System.currentTimeMillis+"]")
ch2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[36] at map at
scala> val ch3 = ch1.map(_.toString+"["+System.currentTimeMillis+"]")
ch3: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[37] at map at
scala> ch3.checkpoint
scala> ch2.collect
res62: Array[String] = Array(1[1505480940726], 2[1505480940243])
scala> ch2.collect
res63: Array[String] = Array(1[1505480941957], 2[1505480941480])
scala> ch2.collect
res64: Array[String] = Array(1[1505480942736], 2[1505480942257])
scala> ch3.collect
res65: Array[String] = Array(1[1505480949080], 2[1505480948603])
scala> ch3.collect
res66: Array[String] = Array(1[1505480948683], 2[1505480949161])
scala> ch3.collect
res67: Array[String] = Array(1[1505480948683], 2[1505480949161])
7、RDD依赖关系
由于RDD是粗粒度的操作数据集,每个Transformation操作都会生成一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系;RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。如图所示显示了RDD之间的依赖关系。
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
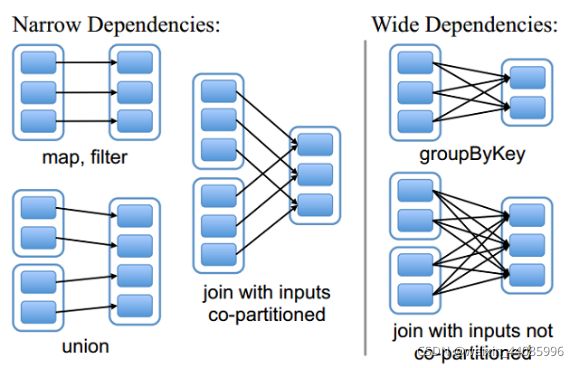
(1)窄依赖
窄依赖指的是每一个父RDD的Partition最多被子RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女
(2)宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle,总结:宽依赖我们形象的比喻为超生
需要特别说明的是对join操作有两种情况:
(1)图中左半部分join:如果两个RDD在进行join操作时,一个RDD的partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖,例如图1中左半部分的join操作(join with inputs co-partitioned);
(2)图中右半部分join:其它情况的join操作就是宽依赖,例如图1中右半部分的join操作(join with inputs not co-partitioned),由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。
总结:
在这里我们是从父RDD的partition被使用的个数来定义窄依赖和宽依赖,因此可以用一句话概括下:如果父RDD的一个Partition被子RDD的一个Partition所使用就是窄依赖,否则的话就是宽依赖。因为是确定的partition数量的依赖关系,所以RDD之间的依赖关系就是窄依赖;由此我们可以得出一个推论:即窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖。
一对固定个数的窄依赖的理解:即子RDD的partition对父RDD依赖的Partition的数量不会随着RDD数据规模的改变而改变;换句话说,无论是有100T的数据量还是1P的数据量,在窄依赖中,子RDD所依赖的父RDD的partition的个数是确定的,而宽依赖是shuffle级别的,数据量越大,那么子RDD所依赖的父RDD的个数就越多,从而子RDD所依赖的父RDD的partition的个数也会变得越来越多。
(3)依赖关系下的数据流视图

在spark中,会根据RDD之间的依赖关系将DAG图(有向无环图)划分为不同的阶段,对于窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,窄依赖就被spark划分到同一个stage中,而对于宽依赖,只能等父RDD shuffle处理完成后,下一个stage才能开始接下来的计算。
因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。因此在图2中RDD C,RDD D,RDD E,RDDF被构建在一个stage中,RDD A被构建在一个单独的Stage中,而RDD B和RDD G又被构建在同一个stage中。
在spark中,Task的类型分为2种:ShuffleMapTask和ResultTask;
简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中;也就是说上图中的stage1和stage2相当于mapreduce中的Mapper,而ResultTask所代表的stage3就相当于mapreduce中的reducer。
在之前动手操作了一个wordcount程序,因此可知,Hadoop中MapReduce操作中的Mapper和Reducer在spark中的基本等量算子是map和reduceByKey;不过区别在于:Hadoop中的MapReduce天生就是排序的;而reduceByKey只是根据Key进行reduce,但spark除了这两个算子还有其他的算子;因此从这个意义上来说,Spark比Hadoop的计算算子更为丰富。
(4)Lineage
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(即血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
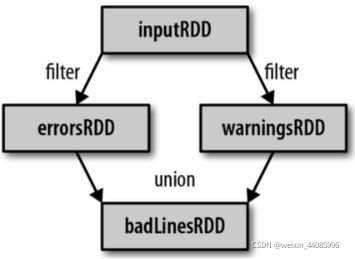
scala> val text = sc.textFile("README.md")
text: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[1] at textFile at :24
scala> val words = text.flatMap(_.split)
split splitAt
scala> val words = text.flatMap(_.split(" "))
words: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at flatMap at :26
scala> words.map((_,1))
res0: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[3] at map at :29
scala> res0.reduceByKey
reduceByKey reduceByKeyLocally
scala> res0.reduceByKey(_+_)
res1: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at :31
scala> res1.dependencies
res2: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@6cfe48a4)
scala> res0.dependencies
res3: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@6c9e24c4) 8、DAG的生成
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。

9、RDD相关概念关系

输入可能以多个文件的形式存储在HDFS上,每个File都包含了很多块,称为Block。当Spark读取这些文件作为输入时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件。随后将为这些输入分片生成具体的Task。InputSplit与Task是一一对应的关系。随后这些具体的Task每个都会被分配到集群上的某个节点的某个Executor去执行。
- 每个节点可以起一个或多个Executor。
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task。
- 每个Task执行的结果就是生成了目标RDD的一个partiton。
注意: 这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程。而 Task被执行的并发度 = Executor数目 * 每个Executor核数。至于partition的数目:
- 对于数据读入阶段,例如sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task。
- 在Map阶段partition数目保持不变。
- 在Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的。
RDD在计算的时候,每个分区都会起一个task,所以rdd的分区数目决定了总的的task数目。申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的task。
比如的RDD有100个分区,那么计算的时候就会生成100个task,你的资源配置为10个计算节点,每个两2个核,同一时刻可以并行的task数目为20,计算这个RDD就需要5个轮次。如果计算资源不变,你有101个task的话,就需要6个轮次,在最后一轮中,只有一个task在执行,其余核都在空转。如果资源不变,你的RDD只有2个分区,那么同一时刻只有2个task运行,其余18个核空转,造成资源浪费。这就是在spark调优中,增大RDD分区数目,增大任务并行度的做法。