机器学习初探:(十一)主成分分析
主成分分析(Principal Component Analysis)

图片出处
文章目录
- 主成分分析(Principal Component Analysis)
-
- 导论
- 主成分分析
-
- 什么是主成分分析
- 主成分分析可以做什么
- 理论推理
- 如何选择主元
- 主成分分析步骤
- 案例详解
-
- 零均质化
- 求解协方差矩阵
- 进行奇异值分解
- 求解两个新的基向量和新的数据坐标
- 小结
- 参考文献
导论
王小明就读的M市某高中举行了一次数学、英语学科的新生摸底测试,学校想通过400名学生的测试成绩将新生分进合适的班级中。
教务老师需要将二维的考试成绩转化为一维的有区分度的评估指标,以便于给学生们分班。我们要寻找的这个评估指标,需要能尽可能保留原始成绩中包含的信息;同时,这一评估指标对整体的400名学生来说,要具有足够的区分度。所以,我们可以使用一种常见的降维方法:主成分分析(Principal Component Analysis) 求解这个评估指标。
为了方便说明,从400个学生中, 随机抽取了20个学生的成绩如下:
| 学生编号 | 数学/150 | 英语/150 |
|---|---|---|
| 1 | 51 | 78 |
| 2 | 142 | 122 |
| 3 | 130 | 102 |
| 4 | 60 | 55 |
| 5 | 23 | 95 |
| 6 | 112 | 110 |
| 7 | 126 | 122 |
| 8 | 120 | 103 |
| 9 | 117 | 90 |
| 10 | 43 | 119 |
| 11 | 48 | 68 |
| 12 | 56 | 56 |
| 13 | 64 | 103 |
| 14 | 70 | 82 |
| 15 | 76 | 91 |
| 16 | 92 | 120 |
| 17 | 108 | 116 |
| 18 | 10 | 90 |
| 19 | 80 | 108 |
| 20 | 85 | 65 |
主成分分析
什么是主成分分析
主成分分析(Principal Component Analysis,PCA), 是最重要的降维方法之一。 在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。1
顾名思义,其基本思想就是“总结”出数据里最主要的特点,用数据里最主要的特点来代替原始数据。
具体的,假如我们的数据集是 n n n 维的,共有 m m m 个数据 ( x 1 , x 2 , … , x m ) (x_1, x_2, …, x_m) (x1,x2,…,xm)。现在对这些点进行压缩,我们希望将这 m m m 个数据的维度从 n n n 维降到 k k k 维 ( k < n ) (k
有趣的是,PCA“总结”数据特点时,并不是从 n n n 个特征中选出 k k k 个然后丢弃其余。相反,它基于原始特征的线性组合构建一些新特征,结果这些新特征能够很好地总结我们的数据。
那么这 k k k 个新特征具体指什么?又是如何构建的呢?以前述的例子来看,不妨从以下两个角度来考虑2:第一,不同学生对两门课程内容掌握的程度不一样,新特征要能够尽可能体现学生成绩间的差异。事实上,想象你得到了一个对于大多数学生而言都一样的特性。那不会很有用的,对不对?第二,基于原本的数据特征"重构"新特征。同样,想象你得出了一个和原本成绩没什么关系的新特征,你不可能重构原本的特征!这又将是个不好的“总结”。
令人惊讶的是,结果这两个目标是等效的,所以PCA可以一箭双雕。
以下图12为例来进行说明,假设坐标轴分别代表了两门课程的成绩,不同学生的散点图可能是这样的:

在这片“成绩云”的中央画一条直线,将所有点投影到这条直线上,我们可以构建一个新的特征。这一新特征将由原始特征的线性组合定义,即 ω 1 x 1 + ω 2 x 2 \omega_1 x_1 + \omega_2 x_2 ω1x1+ω2x2, 其中, x 1 x_1 x1 和 x 2 x_2 x2 即为两门课程的成绩(即,原始特征), ω 1 \omega_1 ω1 和 ω 2 \omega_2 ω2 的取值定义不同直线。
观察,下图22中,随着直线的旋转(即改变 ω 1 \omega_1 ω1 和 ω 2 \omega_2 ω2 的取值),不同直线上的投影是如何变化的(红点是蓝点的投影):
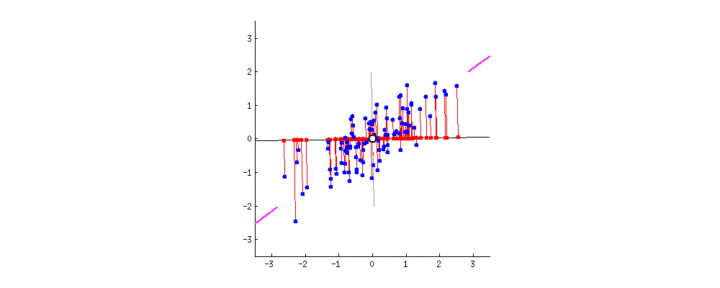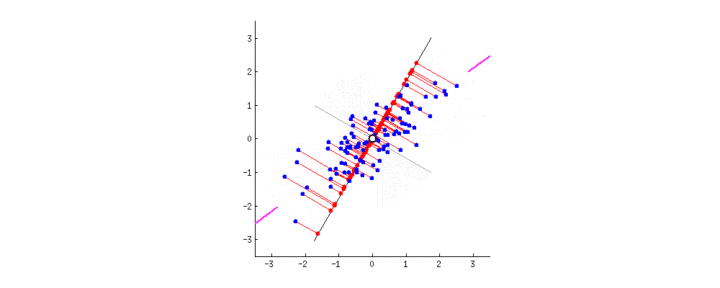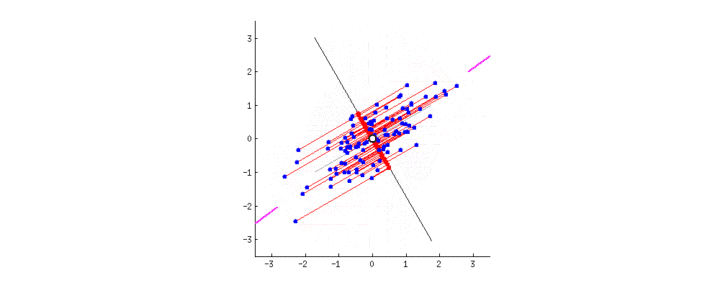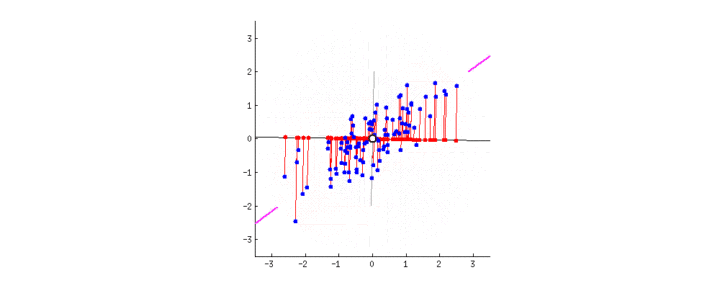
正如我们前面介绍的,PCA会从两个角度出发找到”最佳“的直线(在三维及以上的特征空间中,这条直线表示为超平面)。首先,这条直线上的点应差异最大化。注意观察当直线旋转的时候,红点是何时达到”散布“(我们称之为“方差”)最大化的。其次,如果我们基于新特征(红点的位置)重构原本的两个特征(蓝点的位置),连接红线的长度代表了重构误差。注意观察当直线旋转的时候,红线的总长度是何时达到最小的。
如何你凝视图2中的动画有一会儿的话,你会注意到”最大方差“和”最小误差“将同时达到。 即,旋转的直线运动到玫红色标记处时,同时能满足这两点。玫红色直线代表的这个新属性称为”第一主成分“,相对应的,与其垂直的灰色直线代表”第二主成分“。
主成分分析中的超平面应该有两个特质:
- 最近重构性:重构后的样本映射回原空间,与原样本的距离都足够的近;
- 最大可分性:样本在这个超平面上的投影尽可能分开。
主成分分析可以做什么
主成分分析主要被用于数据降维、特征重构、噪音消除等领域3。
- 数据降维,从 n n n 维降至 k k k 维( k < n k \lt n k<n),如下图34示例。在经济、金融等领域中,需要处理的高维数据通常非常多,就比较适合用主成分分析法进行数据降维。此外,在图像处理领域,也可以通过数据降维的方式进行图片压缩。
- 特征重构:将 n n n 维特征映射到 k k k 维上,称这 k k k 维特征为主成分。在原始特征之间相互有关的情况下,重构后的特征之间相互无关。如下图45就是用不同数量的主成分重构出的人脸。

- 噪音消除:能剔除和类标签无关的特征,减少噪音和冗余,如下图56所示。

理论推理
下面,我们来看一下PCA实现过程的数学原理7。
二维坐标系总有各自的标准正交基(也就是两两相交、模长为1的基),一般用 e 1 e_1 e1 和 e 2 e_2 e2 表示,如下图6中所示。在某坐标系有一个点, a = ( x y ) a = \binom{x}{y} a=(yx),它可以表示为该坐标系下标准正交基 e 1 e_1 e1, e 2 e_2 e2 的线性组合(只是在不同坐标系中, x x x, y y y 的值会有所不同):
a = ( x y ) = x e 1 + y e 2 a = \binom{x}{y} = xe_1 + ye_2 a=(yx)=xe1+ye2
下图6中,设样本数据离散地分布在二维空间内,且进行了零均值化的数据预处理,即所有点的中心是 ( 0 , 0 ) (0,0) (0,0)。如果数据点在一种比较特殊的情况下,即所有的点在一条直线上,那一条能穿过所有样本数据点的直线,就能反映它们最主要的特征。
以原点为圆心,旋转坐标轴,不会使得数据点到原点的距离产生变化,所以,在某坐标系下分配给 x x x 较多,那么分配给 y y y 的就必然较少,反之亦然。于是我们可以一直旋转坐标轴,直到新的 x ′ x' x′ 轴穿过这些点,如图6所示。此时, y ′ y' y′ 轴上的分量为0, y ′ y' y′ 轴没有传达任何信息就可以略去。那么在这个坐标系中,就可以降维了,去掉 y ′ y' y′ 并不会丢失信息。

但是更多时候,数据点并不总是在一条通过原点的直线上,如下图7中所示。现在二维平面上有两个数据点 a = ( a 1 b 1 ) a = \binom{a_1}{b_1} a=(b1a1) 与 b = ( a 2 b 2 ) b = \binom{a_2}{b_2} b=(b2a2),为了降维,我们希望在新的坐标系下, e 1 e_1 e1上的分量尽可能大,而 e 2 e_2 e2上的分量尽可能小。对应到图7中,也就是 a a a 点在 x ′ x' x′ 上的分量红色线 x 1 x_1 x1 、 b b b 点在 x ′ x' x′ 上的分量蓝色线 x 2 x_2 x2 尽可能长,而两点在 y ′ y' y′ 上的分量紫色线尽可能短。
术语上,这个旋转后的坐标系 x ′ x' x′ 被称作“主成分1(或,主元1)”、 y ′ y' y′ 被称为“主成分2(或,主元2)”。

设新的坐标轴基向量 e 1 = ( e 11 e 12 ) e_1=\left( \begin{matrix} e_{11}\\e_{12} \end{matrix} \right) e1=(e11e12), e 2 = ( e 21 e 22 ) e_2=\left( \begin{matrix} e_{21}\\e_{22} \end{matrix} \right) e2=(e21e22),(图7中黑色的一组基向量),是我们需要求解的变量。在新的坐标系下,样本点 a a a、 b b b 低维空间的坐标为: x 1 = a ⋅ e 1 = ( a 1 b 1 ) ( e 11 e 12 ) = a 1 e 11 + b 1 e 12 x_1=a·e_1=\left( \begin{matrix} a_{1}\\b_{1} \end{matrix} \right)\left( \begin{matrix} e_{11}\\e_{12} \end{matrix} \right)=a_1e_{11}+b_1e_{12} x1=a⋅e1=(a1b1)(e11e12)=a1e11+b1e12, x 2 = b ⋅ e 2 = ( a 2 b 2 ) ( e 21 e 22 ) = a 2 e 21 + b 2 e 22 x_2=b·e_2=\left( \begin{matrix} a_{2}\\b_{2} \end{matrix} \right)\left( \begin{matrix} e_{21}\\e_{22} \end{matrix} \right)=a_2e_{21}+b_2e_{22} x2=b⋅e2=(a2b2)(e21e22)=a2e21+b2e22。
问题等价于使样本点在低维空间上的投影之间方差最大,即 x 1 2 + x 2 2 = ∑ i = 1 2 x i 2 x_1^2+x_2^2=\sum\limits_{i=1}^{2}{x_i^2} x12+x22=i=1∑2xi2最大。这两个新的坐标轴基向量(或称新的主元)不能直接求解,而是需要一点技巧。下面我们利用数学方法,推导一下求解 e 1 e_1 e1, e 2 e_2 e2的过程。
x 1 2 + x 2 2 = ( a 1 e 11 + b 1 e 12 ) 2 + ( a 2 e 21 + b 2 e 22 ) 2 = e 1 T ( a 1 2 + a 2 2 a 1 b 1 + a 2 b 2 a 1 b 1 + a 2 b 2 b 1 2 + b 2 2 ) ⏟ C e 1 \begin{aligned} x_1^2+x_2^2&=(a_1e_{11}+b_1e_{12})^2+(a_2e_{21}+b_2e_{22})^2\\ &=e_1^{T}\underbrace{\left( \begin{matrix} a_1^2+a_2^2 & a_1b_1+a_2b_2\\a_1b_1+a_2b_2 & b_1^2+b_2^2 \end{matrix} \right)}_{C}e_1 \end{aligned} x12+x22=(a1e11+b1e12)2+(a2e21+b2e22)2=e1TC (a12+a22a1b1+a2b2a1b1+a2b2b12+b22)e1
在以上的计算过程中,矩阵 C C C 是求解 e 1 e_1 e1、 e 2 e_2 e2 的关键。不难发现,这里的矩阵 C C C是一个对称矩阵,可以进行奇异值分解(关于如何进行奇异值分解,请参考奇异值分解8):
C = U Σ U T C=U{\Sigma}U^T C=UΣUT
其中, U U U为正交矩阵,即 U U T = I UU^T = I UUT=I, Σ \Sigma Σ 是对角矩阵:
Σ = ( σ 1 0 0 σ 2 ) \Sigma = \left( \begin{matrix} \sigma_1 & 0\\ 0 & \sigma_2 \end{matrix} \right) Σ=(σ100σ2)
σ 1 \sigma_1 σ1, σ 2 \sigma_2 σ2是奇异值,且 σ 1 > σ 2 \sigma_1>\sigma_2 σ1>σ2。
由此得到:
x 1 2 + x 2 2 = ( U T e 1 ) T Σ ( U T e 1 ) \begin{aligned} x_1^2+x_2^2&=(U^Te_1)^T\Sigma(U^Te_1) \end{aligned} x12+x22=(UTe1)TΣ(UTe1)
令 n = U T e 1 n=U^Te_1 n=UTe1,所得的 n n n也是单位向量,即:
n = ( n 1 n 2 ) , n 1 2 + n 2 2 = 1 n = \left( \begin{matrix} n_1\\n_2\end{matrix} \right), \quad n_1^2+n_2^2=1 n=(n1n2),n12+n22=1
至此,最终可以将求解 x 1 2 + x 2 2 x_1^2+x_2^2 x12+x22的最大值的问题,转化为求解 x 1 2 + x 2 2 = σ 1 n 1 2 + σ 2 n 2 2 x_1^2+x_2^2=\sigma_1n_1^2+\sigma_2n_2^2 x12+x22=σ1n12+σ2n22 的最大值的问题。
总结一下,现在我们要求解的优化问题是:
max σ 1 n 1 2 + σ 2 n 2 2 s t . n 1 2 + n 2 2 = 1 σ 1 > σ 2 \begin{aligned} \max_{} \quad & \sigma_1n_1^2+\sigma_2n_2^2 \\ st. \quad &n_1^2+n_2^2=1\\ &\sigma_1>\sigma_2 \end{aligned} maxst.σ1n12+σ2n22n12+n22=1σ1>σ2
这个问题可以通过拉格朗日乘数法求解,感兴趣的可以参考拉格朗日乘数法9。经过计算分析,上式可以在 n 1 = 1 , n 2 = 0 n_1=1,n_2=0 n1=1,n2=0 时取到极值。
因此,可以推导出要寻找的主元1,即最大奇异值 σ 1 \sigma_1 σ1对应的奇异向量:
n = ( 1 0 ) = U T e 1 → e 1 = U ( 1 0 ) n = \left( \begin{matrix} 1\\0\end{matrix} \right) = U^T e_1 \rightarrow e_1 = U\left( \begin{matrix} 1\\0\end{matrix} \right) n=(10)=UTe1→e1=U(10)
同理,可以推导出要寻找的主元2,即最小奇异值 σ 2 \sigma_2 σ2对应的奇异向量:
n = ( 0 1 ) = U T e 2 → e 2 = U ( 0 1 ) n = \left( \begin{matrix} 0\\1\end{matrix} \right) = U^T e_2 \rightarrow e_2 = U\left( \begin{matrix} 0\\1\end{matrix} \right) n=(01)=UTe2→e2=U(01)
实践中,求矩阵 C C C 的奇异值分解,计算较为复杂。通常,采用计算其协方差矩阵 Q Q Q 的奇异值分解使计算更简单(关于如何理解协方差矩阵,可以参考如何直观地理解「协方差矩阵」?10)。
因为 C = ( a 1 2 + a 2 2 a 1 b 1 + a 2 b 2 a 1 b 1 + a 2 b 2 b 1 2 + b 2 2 ) = ( X ⋅ X X ⋅ Y X ⋅ Y Y ⋅ Y ) C=\left( \begin{matrix} a_1^2+a_2^2 & a_1b_1+a_2b_2\\a_1b_1+a_2b_2 & b_1^2+b_2^2 \end{matrix} \right)=\left( \begin{matrix} X·X &X·Y\\ X·Y &Y·Y\end{matrix} \right) C=(a12+a22a1b1+a2b2a1b1+a2b2b12+b22)=(X⋅XX⋅YX⋅YY⋅Y)。
对于“零均值化”后的样本( m m m 代表样本数量):
V a r ( X ) = 1 m ∑ i = 1 m X i 2 = 1 m X ⋅ X Var(X) = \frac{1}{m}\sum_{i = 1}^m X_i^2 = \frac{1}{m} X \cdot X Var(X)=m1i=1∑mXi2=m1X⋅X
样本协方差为:
C o v ( X , Y ) = 1 m ∑ i = 1 m X i Y i = 1 m X ⋅ Y Cov(X,Y) = \frac{1}{m} \sum_{i=1}^m X_i Y_i = \frac{1}{m} X \cdot Y Cov(X,Y)=m1i=1∑mXiYi=m1X⋅Y
两相比较可以得到一个新的矩阵,也就是协方差矩阵: Q = 1 m C = ( V a r ( X ) C o v ( X , Y ) C o v ( X , Y ) V a r ( Y ) ) Q=\frac{1}{m}C=\left( \begin{matrix} Var(X) & Cov(X,Y)\\Cov(X,Y) & Var(Y) \end{matrix} \right) Q=m1C=(Var(X)Cov(X,Y)Cov(X,Y)Var(Y))。协方差矩阵 Q Q Q的奇异值分解和 C C C相差无几,只是奇异值缩小了 m m m倍,但是不妨碍奇异值之间的大小关系。
以上,我们在 n = 2 n = 2 n=2 的情况下,大致了解了PCA实现过程的数学原理。更一般地,推广至 n n n 维降至 k k k 维的情形, Q Q Q 奇异值分解的结果可以这样解读:
如下图8中所示, U U U 是一个 n × n n×n n×n矩阵,每一列都是一个 1 × n 1×n 1×n向量,称为奇异向量(也即,基向量,对应主成分),其中 n n n 为特征数量。 Σ \Sigma Σ 为对角矩阵,对角线上的值为奇异值,且 σ 1 ≥ σ 2 ≥ ⋯ ≥ σ n \sigma_1 \ge \sigma_2 \ge \cdots \ge \sigma_n σ1≥σ2≥⋯≥σn。两者的对应关系为, U U U 中第1个列向量(第1个基向量),对应 Σ \Sigma Σ中的第一个奇异值 σ 1 \sigma_1 σ1,第2个列向量,对应 Σ \Sigma Σ中的第二个奇异值 σ 2 \sigma_2 σ2,以此类推。

选择 U U U中的前 k k k列组成矩阵 P P P,实现从 n n n维到 k k k维的降维,主成分 U U U和原始数据 X X X的关系为 Y = P X Y=PX Y=PX。
如何选择主元
接下来,如何根据奇异值分解的结果,选择保留哪几个主成分呢?
- 在一些场景下,我们可以指定希望降至的维度 k k k。比如,如果我们想要保留两个维度,则只需要保留 σ 1 \sigma_1 σ1和 σ 2 \sigma_2 σ2对应的 e 1 e_1 e1和 e 2 e_2 e2两个主元。
- 有些场景下,我们不指定降维后的 k k k 值,而是换种方式,指定一个降维到的主成分比重阈值 t t t,这个阈值 t t t 在 ( 0 , 1 ] (0,1] (0,1] 之间。假如我们的 n n n 个奇异值为 σ 1 ≥ σ 2 ≥ ⋯ ≥ σ n \sigma_1 \ge \sigma_2 \ge \cdots \ge \sigma_n σ1≥σ2≥⋯≥σn ,则 k k k 可以通过下式得到:
∑ i = 1 k σ i ∑ i = 1 n σ i ≥ t \frac{\sum_{i=1}^k \sigma_i}{\sum_{i=1}^n \sigma_i} \ge t ∑i=1nσi∑i=1kσi≥t
其中, ∑ i = 1 k σ i ∑ i = 1 n σ i \frac{\sum_{i=1}^k \sigma_i}{\sum_{i=1}^n \sigma_i} ∑i=1nσi∑i=1kσi 表示前 k k k 个主元可以保留的原始数据的信息量比例。
上式可以这样来理解,举个例子,如果原始数据有五个维度,我们希望保留98%的信息,则可以依次计算 σ 1 σ 1 + ⋯ + σ 5 \frac{\sigma_1}{\sigma_1+\cdots+\sigma_5} σ1+⋯+σ5σ1, σ 1 + σ 2 σ 1 + ⋯ + σ 5 \frac{\sigma_1+\sigma_2}{\sigma_1+\cdots+\sigma_5} σ1+⋯+σ5σ1+σ2,直至保留的信息量达到98%。比如说, σ 1 = 8 \sigma_1=8 σ1=8, σ 2 = 2 \sigma_2=2 σ2=2, σ 3 = 1 \sigma_3=1 σ3=1, σ 4 = 0.5 \sigma_4=0.5 σ4=0.5, σ 5 = 0.2 \sigma_5=0.2 σ5=0.2,要想保留98%的信息,则在算到 σ 4 \sigma_4 σ4时, σ 1 + ⋯ + σ 4 σ 1 + ⋯ + σ 5 ≈ 98.3 % > 98 % \frac{\sigma_1+\cdots+\sigma_4}{\sigma_1+\cdots+\sigma_5}≈98.3\%>98\% σ1+⋯+σ5σ1+⋯+σ4≈98.3%>98%,符合我们的要求。
以上介绍的内容可以推广至 n n n 维降至 k k k 维的情形。 需要注意的是,
-
原始的 m × n m×n m×n 矩阵在经过处理后,会变成 m × k m×k m×k 矩阵,数据量 m m m 是不变的。就像我们的案例中,对 20个学生的2门课成绩进行了处理,得到的最终结果是一个 20 × 1 20×1 20×1的矩阵,最后还是有20条数据,不会变成10条。
-
新的 k k k 个主成分也不是从 n n n 个原始特征中挑选的,而是从 n n n 个原始特征中重构的。
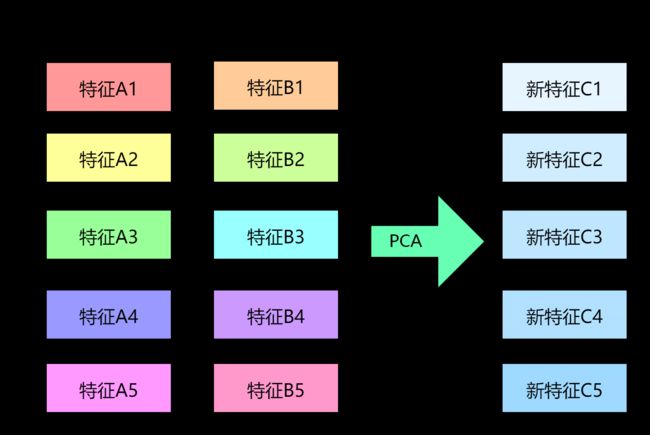
图9 特征重构示意图
主成分分析步骤

案例详解
如果采用主成分分析法分析,为学生们分班,会得到怎样的分班结果呢?我们采用上面介绍的主成分分析步骤,来动手实践一下!
零均质化
求取两列各自的平均数,再用原值减去平均数,得到零均值化后的数据如图11所示。

求解协方差矩阵
Q = ( V a r ( X ) C o v ( X , Y ) C o v ( X , Y ) V a r ( Y ) ) = 1 20 ( X ⋅ X X ⋅ Y X ⋅ Y Y ⋅ Y ) = [ 1437.17 447.1875 447.1875 359.7625 ] \begin{aligned} Q&=\left( \begin{matrix} Var(X) & Cov(X,Y)\\ Cov(X,Y) & Var(Y)\\ \end{matrix} \right) \\ &=\frac{1}{20}\left( \begin{matrix} X·X & X·Y\\ X·Y & Y·Y\\ \end{matrix} \right) \\ &=\left[ \begin{matrix} 1437.17 & 447.1875 \\ 447.1875& 359.7625 \end{matrix} \right] \end{aligned} Q=(Var(X)Cov(X,Y)Cov(X,Y)Var(Y))=201(X⋅XX⋅YX⋅YY⋅Y)=[1437.17447.1875447.1875359.7625]
进行奇异值分解
Q = U Σ U T Q=U{\Sigma}U^T Q=UΣUT
通过代码实现奇异值分解,得到如下结果:
U = [ 0.939864 0.341550 0.341550 − 0.939864 ] , Σ = [ 1437.17 0.00 0.00 316.45 ] , U T = [ 0.939864 0.341550 0.341550 − 0.939864 ] U=\left[ \begin{matrix} 0.939864 & 0.341550\\ 0.341550 &-0.939864\\ \end{matrix} \right] ,\Sigma=\left[ \begin{matrix} 1437.17 & 0.00\\ 0.00 & 316.45\\ \end{matrix} \right],U^T=\left[ \begin{matrix} 0.939864 & 0.341550\\ 0.341550 &-0.939864\\ \end{matrix} \right] U=[0.9398640.3415500.341550−0.939864],Σ=[1437.170.000.00316.45],UT=[0.9398640.3415500.341550−0.939864]
矩阵有两个特征根(即奇异值): x 1 = 1437.17 x_1=1437.17 x1=1437.17 和 x 2 = 316.45 x_2=316.45 x2=316.45。
求解两个新的基向量和新的数据坐标
因为 e 1 e_1 e1是最大奇异值对应的奇异向量, e 2 e_2 e2是最小奇异值对应的奇异向量,所以不难得出 e 1 = ( 0.939864 0.341550 ) e_1=\left( \begin{matrix} 0.939864\\0.341550 \end{matrix} \right) e1=(0.9398640.341550), e 2 = ( 0.341550 − 0.939864 ) e_2=\left( \begin{matrix} 0.341550\\-0.939864 \end{matrix} \right) e2=(0.341550−0.939864)。
相应的,第一个学生的成绩对应的新坐标为: x 1 ′ = ( − 29.65 ) × 0.939864 + ( − 16.75 ) × ( 0.341550 ) ≈ − 33.59 x'_1=(-29.65)×0.939864+(-16.75)×(0.341550)≈-33.59 x1′=(−29.65)×0.939864+(−16.75)×(0.341550)≈−33.59, y 1 ′ = ( − 29.65 ) × 0.341550 + ( − 16.75 ) × ( − 0.939864 ) ≈ 5.62 y'_1=(-29.65)×0.341550+(-16.75)×(-0.939864)≈5.62 y1′=(−29.65)×0.341550+(−16.75)×(−0.939864)≈5.62。
同理可得20个点的新坐标如下:
| x’ | y’ |
|---|---|
| -33.5879 | 5.615765 |
| 66.96789 | -4.6572 |
| 48.85853 | 10.04148 |
| -32.9848 | 30.30659 |
| -54.0978 | -19.9253 |
| 34.67337 | -3.62533 |
| 51.93007 | -10.122 |
| 39.80144 | 5.686115 |
| 32.54169 | 16.8797 |
| -27.1033 | -35.6511 |
| -39.823 | 13.98975 |
| -36.4027 | 28.00052 |
| -12.8309 | -13.4407 |
| -14.3643 | 8.345759 |
| -5.65118 | 1.936283 |
| 19.29159 | -19.855 |
| 32.96322 | -10.6307 |
| -68.0238 | -19.6662 |
| 3.914626 | -12.6752 |
| -6.0727 | 29.4467 |
可以看出,实行主成分分析后,第二列的数据相对第一列传达的信息很少。我们希望将二维数据降成一维,此时显然可以舍弃 e 2 e_2 e2对应的维度,保留 e 1 e_1 e1对应的维度。此处我们选择了 e 1 e_1 e1,对应奇异值 σ 1 \sigma_1 σ1,保留了 σ 1 σ 1 + σ 2 = 1437.17 1437.17 + 316.45 ≈ 81.95 % \frac{\sigma_1}{\sigma_1+\sigma_2}=\frac{1437.17}{1437.17+316.45}≈81.95\% σ1+σ2σ1=1437.17+316.451437.17≈81.95%的信息。
图12中,蓝点为20个点的新坐标值散点图,对应的红点为略去 e 2 e_2 e2,所有的点投影到 e 1 e_1 e1上的结果。略去 e 2 e_2 e2传达的数据后,我们成功地实现了非理想情况下的降维。现在我们可以仅用第一列的数据值,来刻画学生的学习水平信息了。

通过主成分分析,我们按照 e 1 e_1 e1为学生按由强到弱分班,这二十个学生新的分班结果如图13所示:
班级1:2、7、3、8号学生(蓝色);班级2:6、17、9、16号学生(橙色);班级3:19、15、20、13号学生(黄色);班级4:14、10、4、1号学生(紫色);班级5:12、11、5、18号学生(绿色)。

我们使用主成分分析法完成了分班任务。这一个任务也可以使用K-means方法或其他方法完成。选择什么样的方法来解决问题,主要取决于实际情况与需求。
小结
此篇我们介绍了一种能将数据降维的分析方法:主成分分析。主成分分析是找出数据里最主要的特点,用数据里最主要的特点来代替原始数据的一种统计方法。
- 对于一组 n n n维的数据,主成分分析法可以重构出 k k k个特征,将它降至 k k k维( k < n k
k<n )。 - 这 k k k个特征可以最大区分原始样本
- 这组数据可以反映原始样本最主要的特征
- 可以将与样本信息无关的,冗余的信息剔除
需要注意的是,原始的 m × n m×n m×n矩阵在经过处理后,会变成 m × k m×k m×k矩阵,数据量 m m m是不变的;新的 k k k个主成分不是从 n n n个原始特征中挑选的,而是从 n n n个原始特征中重构的。
主成分分析法常用于处理高维数据,可以实现降噪、图像压缩、手写识别等功能,在经济、金融、图像处理、人脸识别等样本数据维度较多的领域有广泛的应用。
参考文献
PCA主成分分析学习总结 ↩︎
Making sense of principal component analysis, eigenvectors & eigenvalues ↩︎ ↩︎ ↩︎
主成分分析(PCA)原理详解 ↩︎
Würsch, C., MSE MachLe Dimensionality Reduction, V10 ↩︎
deep learning PCA(主成分分析)、主份重构、特征降维 ↩︎
Lehtinen, J., Munkberg, J., Hasselgren, J.,.et al.Noise2Noise: Learning Image Restoration without Clean Data ↩︎
如何通俗易懂地讲解什么是 PCA 主成分分析? ↩︎
奇异值分解 ↩︎
拉格朗日乘数法 ↩︎
如何直观地理解「协方差矩阵」? ↩︎