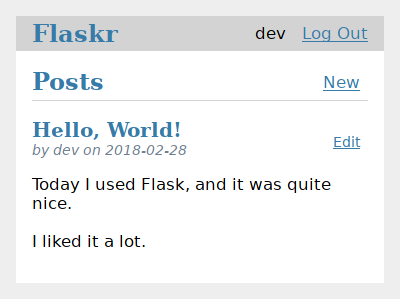
{{ post['title'] }}
by {{ post['username'] }} on {{ post['created'].strftime('%Y-%m-%d') }}
{{ post['body'] }}
英文原文地址:http://flask.pocoo.org/docs/1.0/tutorial/
若有翻译错误或者不尽人意之处,请指出,谢谢~
本章节将带你创建一个叫做Flaskr的基础博客应用程序。用户可以注册、登录、创建文章以及修改或者删除他们自己的文章。你也可以打包以及安装这个应用程序到其他电脑上。
这里假设你已经对Python很熟悉了。如果没有学习或者有些遗忘了,学习或者复习一下Python的官方导读文档是一个不错的方式。
虽然设计的初衷是很不错的,但是本章节并没有覆盖Flask的所有特性。请前往快速入门章节,浏览一下Flask能做什么,然后你需要投身于相应的文档进行更加细致的学习。这一章节仅仅使用Flask和Python所提供的内容。在其他项目中,你可能决定使用扩展或者其他库来实现某些功能。
Flask是灵活多变的。它不需要你使用很多特别的项目或者代码的布局。然而,刚开始的时候,使用更结构化的方法是更有帮助的。这意味着,这一章节会需要一些预制样板,但这是为了避免新的开发人员遇到常见的陷阱,并且它创建了一个易于扩展的项目。一旦你对Flask越来越适应,你可以跳出这个结构并且充分利用Flask的灵活性。
如果你想要对比最终的程序与你跟着这一章节实现的程序有什么区别,请前往这里获取源码。
创建一个项目目录,并且跳转到其内部:
mkdir flask-tutorial
cd flask-tutorial接着跟随安装说明建立一个Python的虚拟环境,并且为你的项目安装Flask。
我们假设你从现在开始使用的目录就叫做flask-tutorial。每个代码块顶部的文件名都与这个目录有关。
一个Flask应用程序可以简单到只有一个文件,比如这个hello.py:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello():
return 'Hello, World!'然而,随着项目的增大,将所有代码保存到一个文件中变得越加困难。Python项目使用包(package)的概念来组织代码到不同的模块中,当你需要使用这些模块式只需要一个导入工作即可。我们在这里将使用这个概念。
这个项目的目录会包含:
● flaskr/,一个Python包,包含你的应用程序代码和文件。
● tests/,一个包含测试模块的目录。
● venv/,一个Python的虚拟环境,Flask和其他依赖集也会安装在这里。
● 安装文件,用于告诉Python如何来安装你的项目。
● 版本控制文件,比如git。你应该养成在项目中使用某种版本控制工具的习惯,不管这玩意儿到底有多大。
● 其他你可能在未来添加的项目文件。
最终,你的项目结构看起来就会像在这个样子:
/home/user/Projects/flask-tutorial
├── flaskr/
│ ├── __init__.py
│ ├── db.py
│ ├── schema.sql
│ ├── auth.py
│ ├── blog.py
│ ├── templates/
│ │ ├── base.html
│ │ ├── auth/
│ │ │ ├── login.html
│ │ │ └── register.html
│ │ └── blog/
│ │ ├── create.html
│ │ ├── index.html
│ │ └── update.html
│ └── static/
│ └── style.css
├── tests/
│ ├── conftest.py
│ ├── data.sql
│ ├── test_factory.py
│ ├── test_db.py
│ ├── test_auth.py
│ └── test_blog.py
├── venv/
├── setup.py
└── MANIFEST.in如果你使用了版本控制,那么在运行你的项目时生成的文件应该被忽略。可能还有其他基于你使用的编辑器的文件。一般来说,要忽略的文件都不需要你来书写。举个栗子,git会在.gitignore文件中写入需要忽略的文件:
venv/
*.pyc
__pycache__/
instance/
.pytest_cache/
.coverage
htmlcov/
dist/
build/
*.egg-info/ 一个Flask应用程序时一个Flask类的实例。任何关于应用程序的内容,比如说配置文件以及URL,都将使用这个类进行注册。
创建一个Flask应用程序最直接的方式是,在你的代码顶部直接创建一个全局的Flask实例,就像上一节中的“Hello, World!”示例那样。虽然这样做是简单且可用的,但随着项目的增长,这样做会带来一些棘手的问题。
抛弃创建一个全局Flask实例的想法吧,你应该在一个方法内部创建它。这个方法就是我们常说的应用程序工厂(application factory)。任何配置文件,注册,以及其他建立应用程序的条件,都将在这个方法内实现,然后返回应用程序对象。
是时候开始编码了。创建flaskr文件夹并且在其下添加一个__init__.py文件。这个__init__.py文件肩负了两个职责:它将包含应用程序工厂,并且它会告诉Python应该把flaskr文件夹当做一个包来对待。
mkdir flaskrflaskr/__init__.py
import os
from flask import Flask
def create_app(test_config=None):
# create and configure the app
app = Flask(__name__, instance_relative_config=True)
app.config.from_mapping(
SECRET_KEY='dev',
DATABASE=os.path.join(app.instance_path, 'flaskr.sqlite'),
)
if test_config is None:
# load the instance config, if it exists, when not testing
app.config.from_pyfile('config.py', silent=True)
else:
# load the test config if passed in
app.config.from_mapping(test_config)
# ensure the instance folder exists
try:
os.makedirs(app.instance_path)
except OSError:
pass
# a simple page that says hello
@app.route('/hello')
def hello():
return 'Hello, World!'
return app create_app是应用程序工厂方法。
1. app = Flask(__name__, instance_relative_config=True)创建了Flask实例。
○ __name__表示的是当前Python模块的名称。应用程序需要知道它所处的位置来设置一些路径,而__name__是一个方便的方式来告诉它所处的位置。
○ instance_relative_config=True是用来告诉应用程序,配置文件是与实例文件夹(instance folder)相关联的。这个实例文件夹位于flaskr包的外部,并且它可以保存不应该提交到版本控制的本地数据,比如配置密钥和数据库文件。
2. app.config.from_mapping()设置一些应用程序会用到的默认配置:
○ SECRET_KEY 被Flask和扩展组件用于保证数据的安全。它被设置为‘dev’,在开发期间能帮助我们排查某些问题,但在实际部署的时候,这个值应该被重写为一个随机值。
○ DATABASE 表示SQLite数据库文件的路径。它在app.instance_path路径下,这是Flask为实例文件夹选择的路径。在下一小节你可以获取到更多关于数据库的知识。
3. app.config.from_pyfile()覆盖了默认配置的某些值,前提是实例文件夹下存在一个叫做config.py的文件。举个栗子,在部署阶段,这可以被用来设置一个真正的SECRET_KEY:
○ test_config 也可以被传递到这个工厂,并且能被用于代替这个实例配置。这个主要永远本章节随后讲到的有关测试的内容,你可以通过这个test_config修改任何你在测试时想使用的值。
4. os.makedirs()确保app.instance_path存在。Flask不会自动创建实例文件夹,但是这个文件夹是需要被创建的,因为在你的程序中使用的SQLite数据库文件就放在这里。
5. @app.route()创建了一个简单的路由,因此你可以在继续本章节后续内容的学习之前看到本示例的运行情况。它在URL(/hello)与一个方法之间创建了一个连接,使其能返回一个响应——在这里是一个“Hello, World!”字符串。
现在你可以使用flask命令来运行你的应用程序了。在终端告诉Flask哪里可以找到你的应用程序,然后在开发模式下运行它。
开发模式会在页面抛出一个异常时显示一个交互式的调试器,并且当你修改了代码后会自动重启服务器。你可以运行它,后续跟着本章节修改代码后,在你的浏览器刷新你的页面即可。
在Linux和Mac上:
export FLASK_APP=flaskr
export FLASK_ENV=development
flask run 在Windows控制台,使用set替代export:
set FLASK_APP=flaskr
set FLASK_ENV=development
flask run 在Windows获取了管理员权限的控制台,使用$env:替代export:
$env:FLASK_APP = "flaskr"
$env:FLASK_ENV = "development"
flask run 你会看到类似于下面内容的输出:
* Serving Flask app "flaskr"
* Environment: development
* Debug mode: on
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 855-212-761 在你的浏览器中访问http://127.0.0.1:5000/hello,你会看到“Hello, World!”的信息。恭喜你,你现在已经成功运行了你的Flask Web应用程序了。
这个应用程序将使用SQLite数据库来存储用户信心和文章信息。Python在sqlite3模块中内置了对SQLite的支持。
SQLite是很方便的,因为它不需要安装单独的数据库服务,并且它在Python中是内置的。然而,如果并发请求在同一时间尝试写数据库,它们会因为写入顺序的缘故而慢下来。小型应用程序不会注意到这些。一旦程序规模变大,你可能希望转换到不同的数据库。
本章节不会涉及SQL的细节。如果你不熟悉它,SQLite的文章中是描述了SQL语言的。
当使用SQLite数据库(当然也包括大多数Python数据库)的第一件事就是对数据库创建一个连接。任何查询和操作都是使用连接来执行的,连接在工作完成之后将被关闭。
在Web应用程序中,这种连接通常是与请求绑定在一起的。它是在处理一个请求时创建的,而在响应回执之前关闭的。
flaskr/db.py
import sqlite3
import click
from flask import current_app, g
from flask.cli import with_appcontext
def get_db():
if 'db' not in g:
g.db = sqlite3.connect(
current_app.config['DATABASE'],
detect_types=sqlite3.PARSE_DECLTYPES
)
g.db.row_factory = sqlite3.Row
return g.db
def close_db(e=None):
db = g.pop('db', None)
if db is not None:
db.close() g是一个特别的对象,对于每个请求来说它都是唯一的。在请求期间,它被用来存储多个方法可能要访问的数据。数据库连接被存储到g对象中,并且第二次访问同样的请求时,如果get_db被调用了,将重新使用g对象中存储的数据库连接,而不是创建一个新的数据库连接。
current_app是另一个特殊的对象,它指向了Flask应用程序对象,用于处理请求(其实就是个代理对象)。由于你使用一个应用程序工厂,在你编写剩余的代码时并没有一个应用程序对象。在应用程序被创建且处理一个请求时将调用get_db,因此current_app可以被使用。
sqlite3.connect()与配置项DATABASE指定的文件建立一个连接。目前这个文件还并不存在,稍后在你初始化之前我将告诉你怎么创建这个数据库。
sqlite3.Row告诉连接返回行为类似于字典的行。它允许使用名称来访问列。
close_db通过检查g.db是否被设置来确定是否创建了一个连接。如果连接存在则关闭它。下一步你需要告诉应用程序,在应用程序工厂内存在一个close_db,以便在每个请求之后都调用这个close_db(用于关闭连接)。
在SQLite中,数据被存储在数据表(tables)和列(columns)中。它们需要在你存储和取出数据之前被创建。Flaskr能在user表中存储用户信息,在post表中存储文章信息。创建一个包含创建空表的SQL命令文件:
flaskr/schema.sql
DROP TABLE IF EXISTS user;
DROP TABLE IF EXISTS post;
CREATE TABLE user(
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT UNIQUE NOT NULL,
password TEXT NOT NULL,
);
CREATE TABLE post(
id INTEGER PRIMARY KEY AUTOINCREMENT,
author_id INTEGER NOT NULL,
created TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
title TEXT NOT NULL,
body TEXT NOT NULL,
FOREIGN KEY (author_id) REFERENCES user (id),
); 在db.py文件中添加可以运行这些SQL命令的Python方法:
flaskr/db.py
def init_db():
db = get_db()
with current_app.open_resource('schema.sql') as f:
db.executescript(f.read().decode('utf-8'))
@click.command('init-db')
@with_appcontext
def init_db_command():
""" Clear the existing data and create new tables. """
init_db()
click.echo('Initialized the database.') open_resource()打开一个相对于flaskr包的文件,这是很有用的方法,因为在部署了应用程序之后,你也不必关心这个文件到底存放在哪里的。get_db返回一个数据库连接,这个连接将用于执行从文件中读取到的命名。
click.command()定义了一个叫做“init-db”的命令行命令,它调用init_db方法,并且给用户显示一条成功的信息。
close_db和init_db_command方法需要在应用程序实例中注册,否则它们将不能被该程序所使用。然而,由于你使用了一个工厂方法,因此当你编写函数时无法使用这个实例。因此,在你的注册函数中需要传入一个应用程序对象。
flaskr/db.py
def init_app(app):
app.teardown_appcontext(close_db)
app.cli.add_command(init_db_command)app.teardown_appcontext()告诉Flask,在返回响应后进行清理时调用这里注册的方法。
app.cli.add_command()添加一条新的命令,可以用flask命令进行调用。
在工厂中导入并调用这个方法。在工厂方法中的返回app对象之前写入下面的代码:
flask/__init__.py
def create_app():
app = ...
# existing code omitted
from . import db
db.init_app(app)
return app 现在已经在app中注册了init-db命令,我们能通过使用flask命令来调用这个命令,就像上一节中运行run这个命令一样。
注意:
如果你依然运行着上一节中编写的服务器,你可以停止服务器,也可以在一个新的终端运行这条命令。如果你使用一个新的终端,请记住要更改你的项目目录,并且激活环境(安装一章有讲过)。当然你也需要像上一章那样设置FLASK_APP和FLASK_ENV环境变量。
运行init-db命令:
flask init-db
Initialized the database. 现在,在项目中的instance文件夹下,会生成一个flaskr.sqlite的文件。
一个视图方法就是用于响应应用程序请求的代码。Flask使用模式来匹配进来的请求URL和应该处理它的视图。视图返回一个Flask转换为传出响应的数据。Flask也能选择另外的方向,并根据它的名称和参数来为一个视图生成一个URL。
蓝图(Blueprint)是一个组织一组相关视图和其他代码的方法。相较于使用一个应用程序对象来注册视图和其他代码,我们更应该使用一个蓝图。然后,在工厂方法中当应用程序对象可用时,我们在对蓝图进行注册。
Flaskr将会有两个蓝图,一个用于身份验证方法,一个用户博客帖子方法。每个蓝图的代码都将在一个单独的模块中。由于博客需要知道身份验证的信息,你需要首先完成身份验证的功能。
flaskr/auth.py
import functools
from flask import Blueprint, flash, g, redirect, render_template, \
request, session, url_for
from werkzeug.security import check_password_hash, \
generate_password_hash
from flaskr.db import get_db
bp = Blueprint('auth', __name__, url_prefix='/auth') 这里创建了一个叫做‘auth’的蓝图(Blueprint)。就像应用程序对象一样,蓝图需要知道它在哪里被定义的,因此__name__被当做第二个参数。url_prefix会被预置到与这个蓝图关联的所有URL中。
通过在工厂中使用app.register_blueprint()方法,可以导入和注册蓝图。在工厂方法返回app对象之前加入下面的代码:
flaskr/__init__.py
def create_app():
app = ...
# existing code omitted
from . import auth
app.register_blueprint(auth.bp)
return app 身份验证的蓝图将包括用于注册新用户以及登录和登出的视图。
当用户访问URL地址/auth/register时,register视图将会返回HTML表单供用户填写。当它们提交这个表单时,程序将验证用户的输入,以及当有错误输入时再次返回这个表单,还是创建一个新用户并跳转到登录页面。
现在,你仅需要编写视图代码。在下一节,你将编写用于生成HTML表单的模板。
flaskr/auth.py
@bp.route('/register', methods=['GET', 'POST'])
def register():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
db = get_db()
error = None
if not username:
error = 'Username is required.'
elif not password:
error = 'Password is required.'
elif db.execute(
'SELECT id FROM user WHERE username = ?', (username, )
).fetchone() is not None:
error = 'User {} is already registered.'.format(username)
if error is None:
db.execute(
'INSERT INTO user (username, password) VALUES (?, ?)',
(username, generate_password_hash(password))
)
db.commit()
return redirect(url_for('auth.login'))
flash(error)
return render_template('auth/register.html') 下面描述了register视图方法做了什么:
1. @bp.route将URL地址/register与register视图方法联系起来。当Flask接收到一个跳转到到/auto/register的请求时,它会调用register视图方法并使用其返回值作为响应。
2. 如果用户提交表单,request.method会变成‘POST’。在这种情形下,将开始验证输入。
3. request.form时一个特殊的字典类型,用于映射提交的表单的键和值。在这里,用户将输入他们的username和password。
4. 验证username和password不为空。
5. 通过查询数据库和检查是否返回了结果,来验证username是不是已经被注册。后面使用的db.execute执行一条SQL查询,这条SQL查询中携带有?占位符,用来替换用户的输入值。数据库的库会将这些值进行转义,这样就能避免受到SQL注入攻击(SQL injection attack)的危害。
fetchone()从查询结果中返回一行。如果查询没有结果返回,它将返回None。稍后我们还会使用到fetchall(),表示返回一个结果列表。
6. 如果验证成功,插入一条新的用户数据到数据库中。为了安全起见,永远不要将密码直接存储到数据库中。应该使用generate_password_hash()方法为密码生成hash值,并将这个hash值存储到数据库中。由于这个查询修改了数据,db.commit()需要随后被调用,用于保存改变后的数据。
7. 在存储用户数据之后,它们将重定向到登录页面,url_for()根据视图方法的名称来生成登录视图的URL。这比直接硬编码URL更可取,应为它允许你在不更改相应连接的所有代码的情况下更改对应的URL。redirect()生成了一个对生成的URL的重定向响应。
8. 如果验证失败,错误信息将被呈现给用户。flash()存储了在渲染模板时可以被获取到的信息。
9. 当用户最初导航到auto/register,或者这里有一个验证错误时,将展现一个带有注册表单的HTML页面。render_template()将渲染包含这个HTML的模板,这个模板的内容将在下一节中细谈。
这个视图遵从与上面所述的register视图同样的模式。
flaskr/auth.py
@bp.route('/login', methods=('GET', 'POST'))
def login():
if request.method == 'POST':
username = request.form['username']
password = request.form['password']
db = get_db()
error = None
user = db.execute(
'SELECT * FROM user WHERE username = ?', (username, )
).fetchone()
if user is None:
error = 'Incorrect username.'
elif not check_password_hash(user['password'], password):
error = 'Incorrect password.'
if error is None:
session.clear()
session['user_id'] = user['id']
return redirect(url_for('index'))
flash(error)
return render_template('auth/login.html') 这里与register视图有一些不同:
1. 首先查询指定username的用户数据,并将其存储到一个变量user中以便稍后使用。
2. check_password_hash()将提交的密码进行哈希加密,并将其与数据库中的密码进行对比,以实现安全操作。如果它们匹配,则密码通过验证。
3. session是一个字典(dict),用于在请求期间存储数据。当验证通过时,用户的id将被存储到一个新的session中。这个数据被存储到一个cookie,而这个cookie是发送给了浏览器,并且这个浏览器稍后会将其随着后来的请求一起发送回来。Flask安全地标记(signs)了这个数据,以防它被篡改。
现在,用户的id被存储到了session中,它在后来的请求中也是可用的。在每个请求的开头,如果一个用户被登录了,那么他的信息就应该被加载,并且其他视图也可以使用这些信息。
flaskr/auth.py
@bp.before_app_first_request
def load_logged_in_user():
user_id = session.get('user_id')
if user_id is None:
g.user = None
else:
g.user = get_db().execute(
'SELECT * FROM user WHERE id = ?', (user_id, )
).fetchone() bp.before_app_request()注册了一个方法,这个方法在视图方法之前运行,而不管被请求的URL是什么。load_logged_in_user检查了一个用户id是否被存储在session中,并且从数据库中获取这个用户的数据,然后将其存储到g.user中,g.user将在整个请求周期内一直存在。如果这里没有用户id,或者如果id并不存在,g.user将设置为None。
为了实现注销,你需要从session中移除用户id。然后load_logged_in_user将不能在随后的请求中加载一个用户数据。
flaskr/auth.py
@bp.route('/logout')
def logout():
session.clear()
return redirect(url_for('index')) 创建,编辑以及删除博客帖子,会需要一个在登录状态的用户。为了将其运用到每个视图上,可以使用装饰器(decorator)来实现。
flaskr/auth.py
def login_required(view):
@functools.wraps(view)
def wrapped_view(**kwargs):
if g.user is None:
return redirect(url_for('auth.login'))
return view(**kwargs)
return wrapped_view 这个装饰器返回一个新的视图方法,这个视图方法包裹了它所使用的原始视图。这个新方法检查了一个用户是否被加载了,并且重定向到登录页面。如果一个用户被加载,原始视图被调用并且继续正常地运行。当你编写博客视图时,你将会用到这个装饰器。
url_for()方法根据一个名称和参数来为视图生成URL。与视图关联的名称也被称为端点(endpoint),并且在默认情况下,它与视图函数的名称相同。
举个栗子,在前面小节的应用程序工厂中添加的hello()视图的名称就叫做‘hello’,并且它可以使用url_for('hello')进行链接。如果它携带一个参数,后面你会看到,它可以通过使用url_for('hello', who='World')来实现链接。
当使用一个蓝图,蓝图的名称被预置为该方法的名称,因此login方法的端点,在上面的代码中被写为‘auth.login’,因为你是将login视图添加到名为‘auth’的蓝图中。
你已经完成了身份验证的视图,但是如果你运行了服务器,并且尝试访问任何的URL,你会看到一个TemplateNotFound的错误。这是因为视图调用了render_template(),但是到目前为止你并没有实现任何的模板。模板文件会在flaskr包中存储到templates目录下。
模板是包含了静态数据同时也包含了动态数据占位符的文件。用特定的数据去渲染模板,以便生成一个最终文档。Flask使用Jinja模板库来渲染模板。
在你的应用程序中,你会使用模板来渲染HTML,以便呈现到用户的浏览器中。在Flask中,Jinja被配置为自动转义(autoescape)在HTML模板中渲染的任何数据。这意味着,它可以安全地渲染用户的输入;用户输入任何可能会扰乱HTML的字符,比如‘<’和‘>’都会被转义为安全的值,这个值在浏览器中看起来是一样的,但是不会造成不必要的影响。
Jinja的外表和行为大多都像Python。在模板中,使用特殊分隔符使Jinja语法与静态数据分隔开来。任何介于“{{”和“}}”之间的东西都是输出到最终文档的表达式。“{%”和“%}”表示类似于if和for的控制流语句。与Python不同的是,由于静态文件的块可以更改索引,因此Jinja的块使用start和end标签表示,而不是使用缩进。
在应用程序的每个页面都会有相同的基础布局,而在基础布局上进行不同内容的修改。为了不在每个模板中重复书写一次基础布局,因为我们将每个模板继承于一个基础模板,并且重写特定的部分。
flaskr/templates/base.html
{% block title %}{% endblock %} - Flaskr
{% block header %}{% endblock %}
{% for message in get_flashed_messages() %}
{{ message }}
{% endfor %}
{% block content %}{% endblock %}
g是由模板自动提供的。如果g.user被设置(在load_logged_in_user中),那么就显示用户名和一个注销链接,否则显示注册链接和登录链接。url_for()也是自动可用的,并且被用来为视图生成URL,而不是手动编写它们。
在页的标题之后,并且在内容之前,模板循环遍历get_flashed_messages()返回的每条信息。你在这个视图中使用了flash()来显示错误信息。
这里定义了三个块,它们将在其他模板中被重写:
1. {% block title %} 会改变在浏览器的页签中显示的标题以及窗体的标题。
2. {% block header %} 是类似于title,但会改变页面上的标题显示。
3. {% block content %} 是每个页面的内容所在,比如登录表单或者博客文章。
基础模板是直接存放在templates文件夹下面。为了保持其他组织,一个蓝图的模板会被放在与蓝图同样名字的文件夹下面。
flaskr/templates/auth/register.html
{% extends 'base.html' %}
{% block header %}
{% block title %}Register{% endblock %}
{% endblock %}
{% block content %}
{% endblock %} {% extends 'base.html' %}告诉Jinja,这个模板应该替换这个从基础模板继承来的块。所有渲染内容必须出现在从基础模板覆盖的块{% block %}标签内。
在这里使用了一个有用的模式,是在{% block header %}内放置了{% block title %}。这会设置title块并且随后输出它的值到header块中,因此在窗体和页面中共享了相同的title,而不是重写两次这个值到title块和header块中。
input标签使用了required属性。这是告诉浏览器不要提交表单,除非这些字段都被填充了数据。如果用户正在使用一个旧的浏览器,那么将不会支持这个属性;或者如果用户使用浏览器以外的方式来发送请求,你仍然需要在Flask视图中进行数据的验证。总是在服务器充分验证数据的行为是很重要的,即使客户端已经做过了验证。
除了title和提交按钮,其他的与注册模板相同。
flaskr/templates/auth/login.html
{% extends 'base.html' %}
{% block header %}
{% block title %}Log In{% endblock %}
{% endblock %}
{% block content %}
{% endblock %} 现在身份验证的模板已经完成,你可以注册一个用户了。确保服务器依然正在运行(如果没有运行则使用flask run),然后跳转到http://127.0.0.1:5000/auth/register。
尝试在没有填充完表单数据时,点击“Register”按钮,然后你会看到浏览器会显示一个错误信息。尝试移除register.html模板中的required属性,然后再点击“Register”按钮。这时候浏览器不再显示一个错误,而是页面会重新加载,并且视图中使用flash()设置的错误会显示出来。
填充完用户名和密码,你会重新跳转到登录页面。试着输入一个错误的用户名,或者正确的用户名和错误的密码。如果你登录成功,你会得到一个错误,因为到目前为止我们还没有设置index的视图页面。
身份验证的视图和模板已经能够工作,但是它们看起来非常难看。可以使用一些CSS来为你构建的HTML布局添加样式。这些样式不会变更,因此相比于当做一个模板,将它当做一个静态文件更加合适。
Flask会自动地添加一个静态视图,该视图路径与flaskr/static目录相对应,并且能够为它服务。base.html模板已经设置好了一个执行style.css文件的链接。
{{ url_for('static', filename='style.css') }} 除了CSS以外,其余的静态文件类型还可能是,拥有JavaScript方法的文件,或者一个logo图片等等。它们都存储在flaskr/static文件夹下面,并且它们的引用方式均为:url_for('static', filename='...')。
本章节并不关注如何编写CSS,因此你仅需要复制下面的代码到flaskr/static/style.css文件中:
flaskr/static/style.css
html { font-family: sans-serif; background: #eee; padding: 1rem; }
body { max-width: 960px; margin: 0 auto; background: white; }
h1 { font-family: serif; color: #377ba8; margin: 1rem 0; }
a { color: #377ba8; }
hr { border: none; border-top: 1px solid lightgray; }
nav { background: lightgray; display: flex; align-items: center; padding: 0 0.5rem; }
nav h1 { flex: auto; margin: 0; }
nav h1 a { text-decoration: none; padding: 0.25rem 0.5rem; }
nav ul { display: flex; list-style: none; margin: 0; padding: 0; }
nav ul li a, nav ul li span, header .action { display: block; padding: 0.5rem; }
.content { padding: 0 1rem 1rem; }
.content > header { border-bottom: 1px solid lightgray; display: flex; align-items: flex-end; }
.content > header h1 { flex: auto; margin: 1rem 0 0.25rem 0; }
.flash { margin: 1em 0; padding: 1em; background: #cae6f6; border: 1px solid #377ba8; }
.post > header { display: flex; align-items: flex-end; font-size: 0.85em; }
.post > header > div:first-of-type { flex: auto; }
.post > header h1 { font-size: 1.5em; margin-bottom: 0; }
.post .about { color: slategray; font-style: italic; }
.post .body { white-space: pre-line; }
.content:last-child { margin-bottom: 0; }
.content form { margin: 1em 0; display: flex; flex-direction: column; }
.content label { font-weight: bold; margin-bottom: 0.5em; }
.content input, .content textarea { margin-bottom: 1em; }
.content textarea { min-height: 12em; resize: vertical; }
input.danger { color: #cc2f2e; }
input[type=submit] { align-self: start; min-width: 10em; } 你也可以在示例代码中找到样式不那么紧凑的style.css文件。
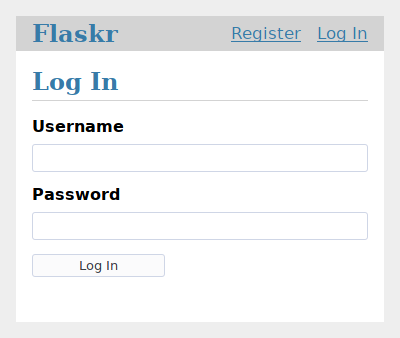
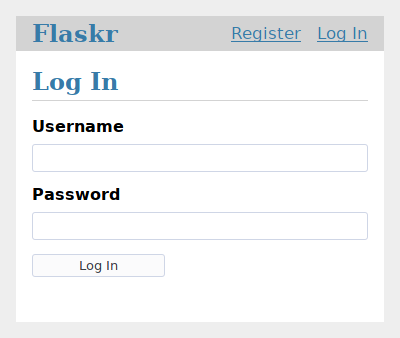
现在,跳转到http://127.0.0.1:5000/auth/login,然后你可以看到类似于下面截图的页面。
你可以在Mozilla's documentation获取到更多关于CSS的知识。如果你更改了一个静态文件,只需要刷新浏览器页面即可。如果更改并没有显现出来,尝试清除你的浏览器缓存。
你将使用身份验证蓝图同样的技术来实现博客蓝图。博客应该列出所有的文章,运行登录用户创建自己的文章,并且允许文章的作者对该文章进行修改或者删除。
正如你实现每个视图那样,保持开发服务器正在运行。如果你保存了源码的更改,尝试在浏览器中跳转到对应的URL,并且测试它们的功能与预期是否一致。
在应用程序工厂内定义蓝图并且注册它。
flaskr/blog.py
from flask import Blueprint, flash, g, redirect, render_template, \
request, url_for
from werkzeug.exceptions import abort
from flaskr.auth import login_required
from flaskr.db import get_db
bp = Blueprint('blog', __name__) 在工厂中使用app.register_blueprint()来导入和注册蓝图。在工厂方法中,返回app对象之前编写下面的代码。
flaskr/__init__.py
def create_app():
app = ...
# existing code omitted
from . import blog
app.register_blueprint(blog.bp)
app.add_url_rule('/', endpoint='index')
return app 与身份验证蓝图不同的是,博客蓝图没有url_prefix。因此index视图将是‘/’,create视图在‘/create’,等等。博客是Flaskr程序的主要特性,因此博客索引成为主要索引是有意义的。
然而,在blog下面index视图的端点定义将会变成blog.index。之前我们在身份验证视图解释过为什么会这样。app.add_url_rule()将名称为‘index’的端点与URL为‘/’关联了起来,因此url_for('index')或者url_for('blog.index')都能正常运作,两种方式都生成了同样的URL——‘/’。
在其他应用程序中,你可能会给博客蓝图一个url_prefix,并且在应用程序工厂中定义一个单独的index视图,这个index视图就像hello视图那样。然后这个index和blog.index端点以及它们的URL都不是一致的。
索引页面将显示所有的文章,最近的文章显示在最顶部。使用JOIN连接符将与user表相关的数据一同进行筛选出来。
flaskr/blog.py
@bp.route('/')
def index():
db = get_db()
posts = db.execute(
'SELECT p.id, title, body, created, author_id, username'
' FROM post p JOIN user u on p.author_id = u.id'
' ORDER BY created DESC'
).fetchall()
return render_template('blog/index.html', posts=posts)flaskr/templates/blog/index.html
{% extends 'base.html' %}
{% block header %}
{% block title %}Posts{% endblock %}
{% if g.user %}
New
{% endif %}
{% endblock %}
{% block content %}
{% for post in posts %}
{{ post['title'] }}
by {{ post['username'] }} on {{ post['created'].strftime('%Y-%m-%d') }}
{% if g.user['id'] == post['author_id'] %}
Edit
{% endif %}
{{ post['body'] }}
{% if not loop.last %}
{% endif %}
{% endfor %}
{% endblock %} 当一个用户登录后,header块添加一个create视图的链接。当用户是某个文章的作者,它们就能看到一个“Edit”链接,这个连接用于跳转到修改这个文章的视图。loop.last在Jinja for loops里,是一个特别的变量。它被用来在除了最后一个链接的其他链接后面加上换行。
创建视图与身份验证的注册视图的工作相同。它们的页面都是显示一个表单,需要验证要传输的数据,并且显示一个错误信息或者添加数据到数据库。
在之前写的login_required装饰器,现在就可以用于blog视图中。一个用户必须在登录状态下才能访问这些视图,否则它们会重定向到登录页面。
flaskr/blog.py
@bp.route('/create', methods=('GET', 'POST'))
@login_required
def create():
if request.method == 'POST':
title = request.form['title']
body = request.form['body']
error = None
if not title:
error = 'Title is required.'
if error is not None:
flash(error)
else:
db = get_db()
db.execute(
'INSERT INTO post (title, body, author_id)'
' VALUES (?, ?, ?)',
(title, body, g.user['id'])
)
db.commit()
return redirect(url_for('blog.index'))
return render_template('blog/create.html')flaskr/templates/blog/create.html
{% extends 'base.html' %}
{% block header %}
{% block title %}New Post{% endblock %}
{% endblock %}
{% block content %}
{% endblock %} 修改和删除视图都需要通过一个id获取到post对象,并且检查在g.user中存储的登录用户是否与当前文章的用户一致。为了避免重复代码,你可以使用一个方法来获取post对象并且在这两个视图中调用这方法。
flaskr/blog.py
def get_post(post_id, check_author=True):
post = get_db().execute(
'SELECT p.id, title, body, created, author_id, username'
' FROM post p JOIN user u ON p.author_id = u.id'
' WHERE p.id = ?',
(post_id, )
).fetchone()
if post is None:
abort(404, "Post id {0} doesn't exist.".format(post_id))
if check_author and post['author_id'] != g.user['id']:
abort(403)
return post abort()会抛出返回一个HTTP状态码的异常。abort()接受一个可选的消息参数用于显示错误信息,若没有设置则显示一个默认消息。404意味着“Not Found”,403意味着“Forbidden”。(401意味着“Unauthorized”,但是你在这里重定向到了登录页面,而不是使用这个状态码。)
定义check_author参数的目的,是因为方法可以被用来,在没有检测用户的情况下获取一个post对象。如果你写了一个视图,用来在一个页面上显示一个单独的文章,那么这个参数是很有用的。因为在这个页面你只能浏览文章而不能进行修改。
flaskr/blog.py
@bp.route('//update', methods=('GET', 'POST'))
@login_required
def update(post_id):
post = get_post(post_id)
if request.method == 'POST':
title = request.form['title']
body = request.form['body']
error = None
if not title:
error = 'Title is required.'
if error is not None:
flash(error)
else:
db = get_db()
db.execute(
'UPDATE post SET title = ?, body = ?'
' WHERE id = ?',
(title, body, post_id)
)
db.commit()
return redirect(url_for('blog.index'))
return render_template('blog/update.html', post=post) 与其他你写过的视图不同,update方法携带了一个参数——post_id。它对应于路由中的
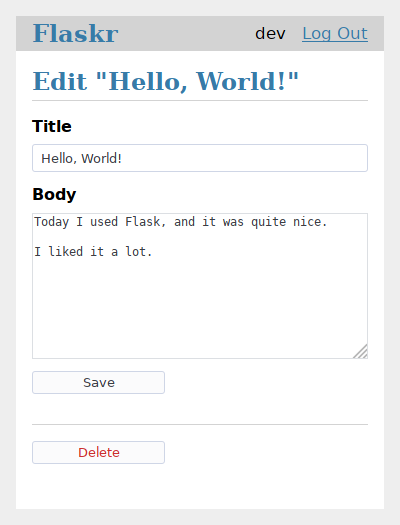
创建和修改视图看起来非常相似。它们主要的区别在于,修改视图使用一个post对象并且在SQL命令中使用了UPDATE而不是INSERT。因为区别不大,因此你可以让创建和修改视图都使用同一份模板。但为了清晰,这里还是将两个视图的模板分别放在单独的文件中。
flaskr/templates/blog/update.html
{% extends 'base.html' %}
{% block header %}
{% block title %}Edit "{{ post['title'] }}"{% endblock %}
{% endblock %}
{% block content %}
{% endblock %} 这个模板有两个表单。第一个将被编辑的数据发送到当前页面(/
{{ request.form['title'] or post['title'] }}模式被用来选择在表单中出现的数据。当表单没有被提交,原始post数据会出现;但是如果未通过验证的表单数据被提交了,你应该显示该数据以便用户可以以此为依据进行错误的修复,因此这里使用的是request.form。request是模板中自动提供了另一个可用变量。
删除视图没有它自己的模板,删除按钮是update.html的一部分,并且可以post到URL地址/
flaskr/blog.py
@bp.route('//delete', methods=('POST',))
@login_required
def delete(post_id):
get_post(post_id)
db = get_db()
db.execute('DELETE FROM post WHERE id = ?', (post_id, ))
db.commit()
return redirect(url_for('blog.index')) 祝贺你,你现在已经完成了这个应用程序。花一点时间来试着在浏览器中验证这个程序。然而,在项目完结之前,这里仍然还有许多事情等着我们去做。
使你的项目可安装化,意思是,你可以创建一个distribution文件并且可以在其他环境下安装它,就像是你在你的项目环境中安装Flask一样。这使得部署你的项目就像是安装任何其它库一样,因此你能使用所有标准Python工具来管理所有东西。
安装也附带了其他好处,这些好处可能在本教程或者对一个新的Python用户来说并不明显,好处包括:
● 当前,Python和Flask知道怎样只使用flaskr包,因为你是从你的项目目录下运行的。安装意味着,你可以导入它,不管你是从哪里开始运行的。
● 你可以管理你的项目依赖集,就像其他包一样,因此pip install yourproject.whl就能安装它们。
● 测试工具能够使你的测试环境与你的开发环境分离开来。
注意:
在后续的章节中会慢慢介绍这些知识,但是未来在你的项目中,你最好总是遵从这些。
setup.py文件描述了你的项目,并且标注了什么文件是属于它的。
setup.py
from setuptools import find_packages, setup
setup(
name='flaskr',
version='1.0.0',
packages=find_packages(),
include_package_data=True,
zip_safe=False,
install_requires=[
'flask',
],
) packages告诉Python包含了哪些包目录(以及它们包含的Python文件)。find_packages()自动查找了这些目录,因此你不必特别指出它们。为了包含其他文件,比如static文件夹和templates文件夹,include_package_data被设置了。Python需要其他叫做MANIFEST.in的文件来告诉它,其他数据有哪些。
MANIFEST.in
include flaskr/schema.sql
graft flaskr/static
graft flaskr/templates
global-exclude *.pyc 这样就告诉了Python需要把static和templates文件夹下的所有东西都拷贝过来,并且还需要schema.sql文件,但是要排除所有字节码文件。
有关文件和选项使用的另一种解释,请参阅official packaging guide。
在虚拟环境中,使用pip来安装你的项目。
pip install -e . 这样做告诉pip去寻找当前目录下的setup.py文件,并且在可编辑模式(editable mode)或者开发模式(development mode)下安装它。可编辑模式意味着,当你本地代码有变更时,你只需要对项目中你更改的元数据重新安装,比如它的依赖项。
你可以使用pip list来观察项目当前是否被安装。
pip list
Package Version Location
------------ ------- ----------------------------------------
click 6.7
Flask 1.0.2
flaskr 1.0.0 /home/du/Work/test/testPy/flask-tutorial
itsdangerous 0.24
Jinja2 2.10
MarkupSafe 1.0
pip 10.0.1
setuptools 39.1.0
Werkzeug 0.14.1
wheel 0.31.0 到目前为止,你一直在运行你的程序,并没有任何修改。FLASK_APP依旧被设置为falskr并且flask run依然能运行这个应用程序。
为你的应用程序编写单元测试,可以让你检查代码工作情况是否符合你的预期。Flask提供了一个测试客户端,它为应用程序模拟了请求,并且能返回响应数据。
你应该尽可能多地测试你的代码。函数中的代码只有在函数被调用时才会运行,但是代码分支(比如if语句块)只有当条件触发时才会运行。你应该确保每个函数都携带数据进行测试,并且测试能覆盖到每个分支。
你越是趋近于100%的覆盖测试,你越会觉得修改了代码并不会引起其他非预期行为。然而,100%覆盖并不能确保你的代码不会有bug的出现。特别是,它不会测试用户与浏览器中的应用程序如何交互。尽管如此,覆盖测试在开发期间依旧是一个很重要的工具。
注意:
在后续的章节中会慢慢介绍这些知识,但是未来在你的项目中,你最好总是遵从这些。
你可以使用pytest和coverage来测试和估量你的代码。安装它们方式如下:
pip install pytest coverage。。。。。。由于楼主安装不上pytest和coverage,因此罢工不干了,请自行前往这里查看原文。待我研究成功后再继续看这一节。
假定你有一个想要部署的服务器,那么接下来将概述如何创建分发文件和安装它,但是不会特定到什么服务或者软件。你可以在你的开发电脑上建立一个新的环境来尝试下面的介绍,但是这不要用它来承载真正的公共应用程序。有关托管应用程序的不同方法的列表,后面会讲到。
当你想要部署你的应用程序到任何地方,你需要创建分发文件(distribution file)。当前Python的发行版是wheel格式,后缀为.whl。首先要确保wheel库已经安装:
pip install wheel Python提供了一个命令行工具来运行setup.py,以便发布与创建相关的命令。bdist_wheel命令能创建一个wheel发布文件。
python setup.py bdist_wheel 你可以找到dist/flaskr-1.0.0-py3-none-any.whl文件。文件名是项目名+版本号+其他能安装的文件的标签。
复制这个文件到另外的机器,创建一个新的虚拟环境,然后使用pip安装这个文件。
pip isntall flaskr-1.0.0-py3-none-any.whlpip会安装你的程序以及它的依赖项。
由于这是不同的机器,你需要运行init-db命名来创建数据库。
export FLASK_APP=flaskr
flask init-db 当Flask发现它被安装了(不是在可编辑模式下),它使用了一个不同的目录来作为实例文件夹(instance folder)。你可以在venv/var/flaskr-instance找到它。
在本章最初的时候,你设置了一个SECRET_KEY。在生产中,这个值应该变为一些随机的字节。否则,黑客能使用公有键‘dev’来修改会话cookie,或者其他数据。
你可以使用下面的命令来输出一个随机密钥:
python -c 'import os; print(os.urandom(16))'
b'_5#y2L"F4Q8z\n\xec]/' 在实例文件夹中创建config.py文件,记得吗,这个文件存在的话,工厂方法是会读取这个文件的。将上面生成的值拷贝到密钥配置项。
venv/var/flaskr-instance/config.py
SECRET_KEY = b'_5#y2L"F4Q8z\n\xec]/' 在这里,你也可以设置其他必要的配置项,尽管SECRET_KEY是Flaskr唯一需要的配置项。
当在公共场合运行而不是在开发环境运行,你不应该使用内置的开发服务器(flask run)。开发服务器是Werkzeug为了方便调试才提供的,因为它并没有被设计的特别高效、稳定或者安全。
因此,我们应该使用一个生产WSGI服务器。举个栗子,为了使用Waitress,首先应该在虚拟环境中安装它:
pip install waitress 你需要告诉Waitress关于你的应用程序的事,但是它没有像flask run那样使用FLASK_APP。你需要告诉它要导入什么,并且调用应用程序工厂来获取一个应用程序对象。
waitress-serve --call 'flaskr:create_app'
Serving on http://0.0.0.0:8080 Waitress只是一个示例,但它在Windows和Linux都是支持可用的。这里还有许多WSGI服务器和部署选项以供选择。后续会讲到,等不及的朋友请查阅原文。
通过这一章,你已经学习了一些Flask和Python的概念。记住,温故而知新,建议你再去原文网站阅读一下,因为作者水平有限,翻译的并不一定准确。你也可以在根据原文网站提供的代码与自己的代码进行对比,可以一小节一小节地对比代码。
虽然看到了Flask这么多的知识点,但是这还远远不够。即便如此,你也可以开始开发你自己的web应用程序了。你可以回头再去看看快速入门,顺便将里面提及的其他需要的知识点一起看一遍(如果有时间的话)。Flask使用的Jinja,Click,Werkzeug,ItsDangerous这些东西,也有自己相应的文档,建议你去瞧一瞧。你如果对扩展组件感兴趣,也可以去这里看一看。
如果你希望在这一章的项目的基础上,继续开发的话,这里有一些想法,你可以尝试一下:
● 一个用于显示单个文章的细节视图。点击文章的标题,就可以跳转到这篇文章。
● 对一篇文章点赞或者点踩。
● 评论功能。
● 标签。点击一个标签,可以显示跟这个标签有关的所有文章。
● 一个查询框,可以根据文章的名字进行筛选。
● 页面显示,比如每页只显示五篇文章。
● 在文章中上传一张图片。
● 使用Markdown来格式化文章。
● 新文章的RSS提要。
祝你玩得开心~~~顺便玩出一个了不起的程序出来!
注:以下是0.12版本的原文,舍不得删,保留,可以忽略。
看了之前的文章,你是否想开发一个使用了Python和Flask的应用程序?接下来的内容将是使用示例说明如何建立一个Flask的应用程序。我们将创建一个简单的微博客应用程序。这个程序仅仅支持一个用户,用户能够创建纯文本的内容,但是没有反馈和评论。虽然粗糙,但这些特性也足够让你开始入门。我们将使用Flask作为主体,SQLite作为数据库(Python自带),因此这里没有其他的你需要了解的知识。
如果你希望提前获取完整的代码或是进行代码比对,请前往example source下载(原网址下载,不坑你们积分了)。
这一章节将展示一个叫做Flaskr的博客应用程序。本质上,它将有如下功能:
1. 用户的登录和登出,凭证信息将存储在配置中。且仅仅支持一个用户。
2. 当用户登录后,他们可以在页面添加新的条目,这个条目包括纯文本的标题和一些HTML的文本内容。这里的HTML并没有经过验证,因为我们相信这里的用户是好人。。。
3. 在首页将显示所有的条目,这些条目都是按照时间进行倒序排序的(用于显示最新的条目),并且如果用户已经登录的话则可以从这里添加新的条目。
SQLite3将直接使用到这个应用程序中,因为SQLite3对于这种大小的应用程序来说已经足够使用。对于一些大型的应用程序,我们一般使用SQLAlchemy,它能够以更加智能的方式处理数据库的连接,也能允许你不断变更到不同的关系型数据库。你也可能会考虑使用当下比较流行的NoSQL数据库,如果你定义的数据关系适合NoSQL的话。
这里有一个完整的应用程序截图:

在开始动手之前,我们需要为这个应用程序创建它所需要的文件夹:
/flaskr
/flaskr
/static
/templates这个应用程序将会被创建,并且像Python的包一样运行。这是创建和运行Flask应用程序推荐的方式。后文中你将详细了解到如何运行flaskr。现在你需要做的是创建应用程序的目录结构。在下一节中你会看到在main模块中创建数据库架构。
这里简要说明下,在static文件夹中的文件可以通过HTTP被应用程序的用户使用。这是放置CSS和JavaScript文件的好去处啊。在templates文件夹中,Flask会寻找Jinja2模板。待会儿你会看到示例的。
这一小节将会介绍创建数据库架构。这个应用程序仅需要一个数据表,并且这个应用程序仅支持SQLite。你所需要做的就是将下面的内容复制粘贴到一个叫做schema.sql的文件中,而这个文件存储在flaskr/flaskr文件夹下:
drop table if exists entries;
create table entries (
id integer primary key autoincrement,
title text not null,
'text' text not null
);这个架构中只有一个叫做entires的数据表。数据表的字段包括id、title、text。id是一个自动增长的整型,且是一个主键。另外两个字段是string类型并且不能为空。
数据库架构已经就绪了,现在你应该创建应用程序模块flaskr.py。这个文件应该存储在flaskr/flaskr文件夹下。在这个应用程序模块的开头几行,你需要书写导入模块的语句。在这之后你需要书写一些配置代码。像一些小型的应用程序比如flaskr,你可以直接将配置写入到模块内。然而,真正的做法应该是创建一个.init文件,然后在.py文件中加载init文件。
这里列出flaskr.py文件中一些重要的语句:
# all the imports
import os
import sqlite3
from flask import Flask, request, session, g, redirect, url_for, abort, \
render_template, flash接下来创建示例的应用程序对象,并且在初始化的同时,从flaskr.py文件中加载配置:
app = Flask(__name__) # create the application instance
app.config.from_object(__name__) # load config from this file, flaskr.py
# Load default config and override config from an environment variable
app.config.update(dict(
DATABASE=os.path.join(app.root_path, 'flaskr.db'),
SECRET_KEY='development.key',
USERNAME='admin',
PASSWORD='default',
))
app.config.from_envvar('FLASKR_SETTINGS', silent=True)Config对象的工作原理类似于一个字典,所以它可以修改值。
数据库路径:
理论上操作系统是知道每个进程当前的工作目录的。不幸的是,在这个web应用程序中你不能依赖于这点,因为在同一个进程中你可能拥有不止一个应用程序。
因为这个原因,app.root_path属性可以被用来获取应用程序的路径。与os.path模块一起使用,文件可以被轻易找到。在这个示例中,我们把数据库文件与应用程序放在一起。
对于一个真实的应用程序而言,我们推荐使用Instance Folders。
通常,最好的设计方式是加载一个单独的、环境指定的配置文件。Flask允许你导入多个配置文件并且它将使用最后导入的配置中的定义。这样就能够支持健壮的配置方式。from_envvar()可以实现上述内容。
app.config.from_envvar('FLASKR_SETTINGS', silent=True)在这里,我们简单地定义一个叫做“FLASKR_SETTINGS”的环境变量,来指向一个可以被加载的配置文件。silent关键字变量仅仅是为了告诉Flask不要抱怨没有设置环境变量的情况(即没有设置环境变量则from_envvar方法不起作用)。
除此之外,你还可以调用config对象的from_object()方法,并且为它提供一个导入模块的名称。这样做,Flask随后会从指定的模块中初始化变量。注意,只考虑使用大写的变量名。
这里的SECRET_KEY被用来保持客户端会话的安全性。变量的命名需要明确,不要使变量变得难猜或者以很复杂的形式出现。
最后,你将添加一个方法用于连接到指定的数据库。这可以被用来在请求上打开一个连接,也可以从Python shell的交互窗口或者一个脚本。这些迟早都会用到的。你可以创建一个SQLite的简单连接,然后告诉它,我们使用sqlite3.Row对象来表示所有行。这样做就可以将所有行当做字典而不是元组。
def connect_db():
""" Connects to the specific database. """
rv = sqlite3.connect(app.config['DATABASE'])
rv.row_factory = sqlite3.Row
return rv在下一节你将看到如何运行这个应用程序。
Flask现在内置支持Click。Click为Flask提供了增强版且可扩展的命令行工具。这一小节你会看到如何扩展flask的命令行接口(command line interface,简称CLI)。
管理Flask应用程序进行安装你的app的一个有用的模式参见Python Packaging Guide。目前,这涉及创建两个新文件:setup.py和MANIFEST.in,文件存放在项目的根目录下。你还需要添加一个__init__.py文件用于将flaskr/flaskr目录作为一个包。经历了这一系列改变,你的代码结构应该像这样:
/flaskr
/flaskr
__init__.py
/static
/templates
flaskr.py
schema.sql
setup.py
MANIFEST.insetup.py文件的内容如下:
from setuptools import setup
setup(
name='flaskr',
packages=['flaskr'],
include_package_data=True,
install_requires=[
'flask',
],
)当使用setuptools的时候,也应该在MANIFEST.in文件中指定需要包含在包中的所有特殊文件。在这里,static文件夹、templates文件夹以及数据库架构是需要被包含进去的。创建一个MANIFEST.in文件并且添加下列行:
graft flaskr/templates
graft flaskr/static
include flaskr/schema.sql为了容易定位到应用程序,在flaskr/__init__.py文件中添加如下导入语句:
from .flaskr import app这条导入语句非常重要,它将应用程序的实例对象放在了应用程序包的最顶层。当应用程序运行的时候,Flask开发服务需要app示例的实际位置。这个导入语句简化了定位过程。如果没有这个导入语句,你需要做额外的事:
export FLASK_APP=flaskr.flaskr现在,你需要安装这个应用程序。通常推荐在虚拟环境(virtualenv)安装你的Flask应用程序。安装命名如下:
pip install --editable .(不要看漏了最后有一个表示当前目录的小句点。)
这里的所有安装命令都假设是在项目的根目录(flaskr/.)运行的,--editable表示允许编辑源码而不用每次有修改都重新安装Flask app。现在flaskr已经在你的虚拟环境中安装成功了(见pip的输出)。
有了这些操作,你可以运行你的应用程序了。依次键入如下命名行:
export FLASK_APP=flaskr
export FLASK_DEBUG=true
flask run(在Windows操作系统,你需要将export替换为set)。FLASK_DEBUG标志是用来开启或者关闭交互调试器。永远不要在生产系统中激活调试模式,因为这允许用户在服务器上执行代码。
你会看到一个信息,它告诉你服务已经启动,并且告诉你一个你可以访问它的地址。
当你在浏览器中前往你的服务地址,你会得到一个404错误,因为当前我们没有任何的视图。稍后这个问题会得到解决。但是首先,你应该让数据库工作起来。
外部可见的服务器:
想要让你的服务器在公网上也能访问?请前往外部可见的服务器部分获取更多的信息。
现在你有一个connect_db的方法用于建立一个数据库连接,但就其本身而言,它并不是特别有用。一直创建和关闭数据库连接是非常低效的,因此你需要将连接保持更长的时间。因为数据库连接封装了一个事务,你将需要确保每次只有一个请求在使用连接。更加智能的办法是使用应用程序上下文(application context)。
Flask提供了两种上下文:应用程序上下文和请求上下文(request context)。就目前而言,你需要知道的是有一些特殊的变量可以使用这些。举个栗子,request变量是当前请求相关联的请求对象,然而g是当前应用程序上下文相关联的一个通用变量。后续会有更加详细的说明。
目前,你需要知道的是你可以使用g对象进行安全地存储信息。
在这里该怎么运用g对象呢?为了坐到这点你可以创建一个帮助方法。当这个方法被调用时,它会为当前上下文创建一个数据库连接,并且成功调用后会返回一个已经建立好的连接:
def get_db():
""" Opens a new database connection if there is none yet for the
current application context
"""
if not hasattr(g, 'sqlite_db'):
g.sqlite_db = connect_db()
return g.sqlite_db现在你知道如何连接,但是该怎么断开连接?为了实现断开连接,Flask为我们提供了teardown_appcontext()装饰器。每当应用程序上下文销毁的时候都会执行其修饰的方法:
@app.teardown_appcontext
def close_db(error):
""" Closes the database again at the end of the request. """
if hasattr(g, 'sqlite_db'):
g.sqlite_db.close()当应用程序上下文tears down的时候,被teardown_appcontext()标记的方法都会被调用。这意味着什么?本质上,应用程序上下文在请求到来之前被创建,而当这个请求结束的时候被销毁(torn down)。销毁会发生是因为两个原因:不是一切顺利(这里的error参数的值为None)就是发生了一个异常,在这种情况下,error值就会传给teardown方法(比如这里的close_db方法)。
好奇这里的上下文意味着什么?你可以前往应用程序上下文文档获取更多相关内容。
正如前面所说的,Flaskr是一个数据库驱动的应用程序,更准确地说,它是一个关系型数据库系统驱动的应用程序。这种系统需要一个框架来告诉它们怎样存储信息。在启动服务器之前,最重要的是创建我们所说的框架。
我们可以使用sqlite3命令来使用schema.sql文件创建数据库:
sqlite3 /tmp/flaskr.db < schema.sql(注意,没有安装sqlite3的,请参见SQLite安装)
这样做的缺点在于,需要安装sqlite3命令,而sqlite3在每个操作系统来说并不一定存在,因此需要自行安装。而且在导入数据库的时候,需要你提供数据库的路径,这是很容易导致错误的。最好的办法是添加一个方法来为应用程序初始化数据库。
你可以创建一个方法用于创建并且将其注入到flask的命令中。我们注意观察下面的代码,这是一种不错的添加这个方法以及命令的办法,这段代码在flaskr.py文件的connect_db方法下面:
def init_db():
db = get_db()
with app.open_resource('schema.sql', mode='r') as f:
db.cursor().executescript(f.read())
db.commit()
@app.cli.command('initdb')
def initdb_command():
""" Initializes the database. """
init_db()
print('Initialized the database.')app.cli.command()修饰符在flask脚本中注册了一个新的命令(initdb)。当这个命令执行的时候,Flask会自动创建一个应用程序上下文并将其绑定到正确的应用程序上。在这个方法中,你可以访问flask.g或者其他的数据。当这个脚本结束的时候,应用程序上下文会自动销毁并且数据库连接也会释放。
你需要保持一个实际的方法来初始化数据库,这样,我们在以后的单元测试中就可以轻松地创建数据库。(想要了解更多信息,参见Testing Flask Applications。)
应用程序对象的open_resource()函数,是一个方便的帮助方法,可以用来打开应用程序提供的资源。在这里,open_resource()从资源位置(flasrk/flaskr文件夹)打开了一个文件并且允许你读取这个文件。在这里主要为了基于数据库连接来执行一个sql脚本。
SQLite提供的连接对象会为你提供一个游标对象(cursor object)。使用游标,你可以执行一个完整的脚本。最后,你仅仅需要做的事就是提交这些变更。SQLite3和其他事务型数据库不会主动提交变更,除非你明确地告诉它需要这么做。
现在,你可以使用flask脚本来创建一个数据库:
flask initdb
Initialized the database.故障排除:
如果在稍后应用程序执行中你发现一个错误显示为"a table cannot be found",请检查你是否执行了initdb命令,并且检查你的数据表名称是否正确(比如,名称是单数还是复数)。
当前数据库连接已经能够正常工作,你可以开始着手于视图方法的建立了。
这个视图将显示所有存储在数据库中的条目。它在应用程序的根部进行监听,并且会从数据库中筛选出标题和文本进行显示。id数值最大(表示最新的数据)的数据将显示在顶部。从游标中返回的数据行看起来有点像是字典,这是因为我们使用了sqlite3.Row的行工厂。
这个视图方法会将数据传递给show_entries.html模板,并且返回经过渲染的这个模板。
@app.route('/')
def show_entries():
db = get_db()
cur = db.execute('select title, text from entries order by id desc')
entries = cur.fetchall()
return render_template('show_entries.html', entries=entries) 这个视图可以让登录的用户添加一个新的数据。这个方法仅能响应POST请求;实际的表单是显示在show_entries页面。如果顺利的话,它将flash()一个信息给下一个请求,并且重定向到show_entries页面:
@app.route('/add', methods=['POST'])
def add_entry():
if not session.get('logged_in'):
abort(401)
db = get_db()
db.execute('insert into entries (title, text) values(?, ?)',
[request.form['title'], request.form['text']])
db.commit()
flash('New entry was successfully posted')
return redirect(url_for('show_entries'))需要注意的是,视图需要检查用户是否登录(即logged_in关键字当前是否在session中且值是否为True)。
安全注意事项:
在构建SQL语句的时候一定要使用问号,如上例所示。否则,当你使用字符串来构建SQL语句时,你的应用程序将很容易受到SQL注入的影响。详情参见Using SQLite3 With Flask。
这些方法被用来让用户登录和登出。登录时需检查用户名和密码是否与配置中的一致,并且设置logged_in关键字到session中。如果用户登录成功,这个关键字就设为True,并且这个用户将重定向回show_entries页面。此外,还会有一条额外的信息用于通知用户,他(她)登录成功。如果有错误发生,模板会接收到这个错误,并且会再次询问用户:
@app.route('/login', methods=['GET', 'POST'])
def login():
error = None
if request.method == 'POST':
if request.form['username'] != app.config['USERNAME']:
error = 'Invalid username'
elif request.form['password'] != app.config['PASSWORD']:
error = 'Invalid password'
else:
session['logged_in'] = True
flash('You were logged in')
return redirect(url_for('show_entries'))
return render_template('login.html', error=error)logout方法用于从session中移除logged_in关键字。这里有个小技巧:如果你使用字典的pop()方法并且对其第二个参数进行传参(默认),这个方法会从字典中删除存在的指定键值,或者键不存在就不做任何动作。这是很有用的,因为你现在不必去检查用户是否登录了:
@app.route('/logout')
def logout():
session.pop('logged_in', None)
flash('You were logged out')
return redirect(url_for('show_entries'))安全注意事项:
在生产系统中,密码永远不要存储在一个没有加密的文本中。这里使用没有加密的文本作为密码是为了演示用,这样很方便罢了。如果你计划将本示例作为一个项目对外发布,那么密码在存储到数据库或者文件之前需要进行哈希算法加密。
幸运的是,Flask有很多扩展可以用来加密密码并且验证密码是否正确,因此添加这些功能是非常简单直观的。而Python库也有很多方法可以实现这些功能。
你可以在这里找到推荐的Flask扩展。
是时候着手于模板的建设了。你可能注意到,如果你现在运行应用程序,并且进行一些请求,那么你会得到一个叫做Flask无法找到指定模板的异常。模板使用了Jinja2的语法,并且在默认情况下是开启了自动转义的功能。这意味着除非你在代码中使用Markup对一个值进行标记,或者模板中使用|safe过滤器,否则Jinja2将确保诸如“<”或者“>”之类的特殊字符与它们的XML等价物一起进行转义。
我们也可以使用继承模板,这样可以在网站的所有页面中重复使用某一种样式。
接下来将列出templates目录中所有的模板文件。
这个模板将包含HTML页面的骨架,标题和登录的连接(如果用户已经登录则是登出的连接)。这里也能够显示推送的消息。{% block body %}块可以被子模板中同样命名(body)的块给代替。
可以在模板中直接使用session字典,你可以使用session来检查用户是否登录。注意,在Jinja中你可以访问缺失的属性和对象的项(或者字典的项),因此下面的代码是可以执行的,即使在session中并没有“logged_in”关键字:
Flaskr
Flaskr
{% for message in get_flashed_messages() %}
{{ message }}
{% endfor %}
{% block body %}{% endblock %}
这个模板继承于layout.html模板用来显示消息。注意,for循环迭代出了我们通过render_template()方法传递过来的参数的所有信息。请注意,表单被配置成了可以提交add_entriy视图功能,并且可以使用POST方法:
{% extends "layout.html" %}
{% block body %}
{% if session.logged_in %}
{% endif %}
{% for entry in entries %}
{{ entry.title }}
{{ entry.text|safe }}
{% else %}
- Unbelievable. No entries here so far
{% endfor %}
{% endblock %} 这是登录模板:
{% extends "layout.html" %}
{% block body %}
Login
{% if error %}Error: {{ error }}{% endif %}
{% endblock %} 现在需要为应用程序添加一些样式。在static文件夹中创建一个叫做style.css的样式表:
body { font-family: sans-serif; background: #eee; }
a, h1, h2 { color: #377ba8; }
h1, h2 { font-family: 'Georgia', serif; margin: 0; }
h1 { border-bottom: 2px solid #eee; }
h2 { font-size: 1.2em; }
.page { margin: 2em auto; width: 35em; border: 5px solid #ccc;
padding: 0.8em; background: white; }
.entries { list-style: none; margin: 0; padding: 0; }
.entries li { margin: 0.8em 1.2em; }
.entries li h2 { margin-left: -1em; }
.add-entry { font-size: 0.9em; border-bottom: 1px solid #ccc; }
.add-entry dl { font-weight: bold; }
.metanav { text-align: right; font-size: 0.8em; padding: 0.3em;
margin-bottom: 1em; background: #fafafa; }
.flash { background: #cee5F5; padding: 0.5em;
border: 1px solid #aacbe2; }
.error { background: #f0d6d6; padding: 0.5em; } 现在你已经完成了我们预期的应用程序的所有功能,接下来我们添加一些自动化测试,用来简化未来修改后的验证工作。在Testing Flask Applications一文中,你可以看到我们之前的应用程序进行单元测试是多么的简单。
假设你已经看过了Testing Flask Applications部分,并且也为你自己的flaskr写过你自己的测试代码或者跟着示例写过测试,你可能想知道如何组织这个项目。
一种可能并且推荐的项目结构如下:
flaskr/
flaskr/
__init__.py
static/
templates/
tests/
test_flaskr.py
setup.py
MANIFEST.in现在请创建一个tests文件夹并且在其下创建一个test_flaskr.py文件。
在这里你将了解到如何运行这个测试,需要用到pytest。
注意:
确定在flaskr所在的虚拟环境中已经安装了pytest工具。否则pytest测试就不能导入需要的组件来进行应用程序的测试工作:
pip install -e .
pip install pytest在flaskr顶层目录中,运行并观察测试通过情况:
py.test 处理测试的一种方法是将其与setuptools结合起来。在这里需要在setup.py文件中添加几行并且创建一个叫做setup.cfg的文件。以这种方式运行测试的好处是,你不需要安装pytest。更新setup.py文件内容如下:
from setuptools import setup
setup(
name='flaskr',
packages=['flaskr'],
include_package_data=True,
install_requires=[
'flask',
],
setup_requires=[
'pytest-runner',
],
tests_require=[
'pytest',
],
)现在创建setup.cfg文件在项目的根目录下(与setup.py同级):
[aliases]
test=pytest现在你可以这样运行:
python setup.py test这就调用setup.py脚本中的setup.cfg的别名,以用来通过pytest-runner来运行pytest。遵循这个标准的test-discovery规则,你的测试就可以被发现、运行,帮助你的程序通过验证。
这是运行和管理测试的一种可能方法。这里使用了pytest,但也有其他的选项,比如nose。将测试与setuptools集成起来是很方便的,因为没有必要下载pytest或任何可能使用到的其他测试框架。