golang-文章翻译-go高效编程
背景:这篇博客主要是对 Effective Go 原文的翻译,再加上自己的一些理解,帮助 初学 gopher们 更好地理解 go 的高级特性,并将其更好地运用在业务项目中。
原文地址
文章目录
- 背景
- 格式化
- 注释和godoc
- 命名规范
-
- 一、包命名
- 二、getter
- 三、Interface
- 分号
- 条件控制语句
-
- 一、if
- 二、再声明和再赋值(Redeclaration and Reassignment)
- 三、for
-
- 1、常见for 循环格式
- 2、使用下划线忽略不需要关注的对象
- 3、其他细节
- 四、switch
-
- 1、特点
- 2、switch 中的 break
- 3、实战:通过switch 实现更美观的字符串对比方法
- 4、实战:type switch
- 方法定义
-
- 一、多个返回值
- 二、返回值命名
- 三、defer
- 对象操作(声明、初始化等)
-
- 一、new
- 二、make
- 三、数组(array)
- 四、slice
- 五、二维数组
- 六、map
-
- 1、key
- 2、添加value
- 3、获取
- 七、打印
-
- 1、基本用法
- 2、其他常用format:
- 3、小技巧:arbitrary type 的用法
- 4、扩展:日志包的选用
- 八、append
- 初始化
-
- 1、常量(constant)
- 2、变量
- 3、init
- 方法
-
- pointer receiver 和 value receiver
- Interface
-
- 一、概述
- 二、struct 类型强转
- 三、Interface 类型判断和指定类型强转
- 四、抽象的规范
- 五、抽象和业务实现
- 空白标识符(下划线 blank identifier)
-
- 一、介绍
- 二、使用:忽略不需要关注的返回值
- 三、使用:提醒功能:临时不用的变量
- 四、使用:仅执行init 的 空import
- 五、使用:类型检查
- 内嵌(embedded)
- 并发
-
- 一、设计理念:通过通信实现共享内存
- 二、启动 routine
- 三、channel
-
- 1、定义方式
- 2、生产和消费示例
- 3、使用场景:设定最大的请求处理数
- 4、使用场景:channels of channels
- 五、并行(parallelization)
- 6、实战:生产-消费模型
- 错误处理
-
- 一、error:自定义错误的方式
- 二、 panic
- 三、recover - panic 的捕获方式
-
- 1、恢复 routine 的方式
- 2、一个更实用的例子:封装公共方法的错误,常在框架中使用
背景
首先需要明确:要写好go ,绝对不是一件简单的事情,不是把 C++、Java 等其他语言的编码规范照搬过来就好的。go 自己有独特的命名、对象设计、程序构造等规范,只有按照go 本身的规范写好了,才能算把 go 这门语言写好了。
任何语言的学习过程其实都要大致经过 入门、了解高级用法、项目实践和性能优化 这几个过程。go官方的这篇文章基本把go语言原生特性都很好地讲了一遍,我们能在很多框架、优秀开源项目中看到这些用法,确实值得一学。
格式化
工具:go 自带的gofmt,使用参考博客
下面3种情况,gofmt 不会自动处理,需要开发自己留意:
1 分隔符
默认是tab,如果需要设置成空格,需要通过两个参数一起指定:
-tabwidth: 设置缩进空格数量,默认为8
-tabs: 是否使用tab 来表示缩进,默认为true,需要设置成false
2 单行长度不超过120
接下来会说到,go 的分号是编译器自动加上的,因此换行还不能随便换,gofmt 本身也不会帮我们处理行长度超长的问题,需要我们平时自己写代码的时候养成习惯,自己换行
3 括号
Go的设计思想中包括尽量减少括号,简化代码,因此空格有的时候是用来区分优先级的,比如:
x<<8 + y<<16
注释和godoc
godoc 使用参考博客
注释风格:和c++一致
特别注意:package comment
每一个包 都应该有对其基本介绍
但是只要在其中一个文件中写好就可以了
功能复杂的包 最好是有多行注释
参考:fmt包本身的注释
其他细节:
需要尽量保证注释本身的格式就是比较美观的,比如合理的空行、单行长度不超过120个字符等
必须要注释的:对外可见的方法、变量和属性
分组注释:同一类型的变量(比如错误码、枚举类型)可以放到一起,不加空行。第一行的注释也可以放简短描述,能够对所有变量生效
示例:
// Error codes returned by failures to parse an expression.
var (
ErrInternal = errors.New("regexp: internal error")
ErrUnmatchedLpar = errors.New("regexp: unmatched '('")
ErrUnmatchedRpar = errors.New("regexp: unmatched ')'")
...
)
命名规范
一、包命名
1、路径规范
路径中应该全用小写,包括文件名本身
2、包命名细节规范
使用方import之后,可以使用最后一级,或者自己对包另外加别名,因此不需要担心最后一级重复的问题。
不过也正因为如此,包的完整路径应该去体现包的完整功能。要简洁,但是不能不完整。
另外,也是因为使用包方法的时候要带上包的最后一级,所以 包内对象不应该再包含包名,比如 io.Reader 而不是 io.IOReader
二、getter
建议:Getter 前面最好不要带上Get, 直接用对象名即可,更加简洁
owner := obj.Owner()
if owner != user {
obj.SetOwner(user)
}
三、Interface
和刚才Getter 的定义思路类似:Interface 中的方法定义,如果方法返回的对象非常明确,建议直接就使用对象名,而不要再加上表示动作的前缀。
另外,Interface 本身的命名也应该尽量简短,直接表示出这个对象是什么。
反例:所有的对象,都带上什么Interface、Controller 之类的后缀,导致对象类型本身非常长。如:SchoolController 。建议直接定义成:student.Controller
分号
从一个问题引入:go 确实不需要分号么?
如果你是使用goland 编写go 代码,你就可以发现,其实在行尾加上分号是不会编译操作的,只是会提醒:redundant semicolon
其实和C 语言一样,go 在编译的时候也是需要分号的,但是源代码中并不需要写,词法分析器(lexer)会自动帮我们加上
那么什么时候加呢?go lexer 会在结束符尾自动加上,常见的结束符有:
break continue fallthrough return ++ -- ) }
这的确帮我们节省了一些工作量,不过同样,这会导致go 对语法本身也是有一些要求的,比如 左大括号 必须写在行最后,不能新起一行,否则会导致上一行行尾 自动被加上分号,导致编译错误。
if i < f() {
g()
} else {
h()
}
条件控制语句
一、if
格式:建议多行、如果只是if 内部用,变量可以和if 语句在同一行初始化、尽量减少else 的使用(if 里面放异常情况,一般是直接退出)
示例代码:
f, err := os.Open(name)
if err != nil {
return err
}
d, err := f.Stat()
if err != nil {
f.Close()
return err
}
codeUsing(f, d)
二、再声明和再赋值(Redeclaration and Reassignment)
参考:考虑下面两行语句,第二行中的err 虽然是通过 := 设置的,但是也只是赋值
达到这种再赋值(reassignment) 需要2个条件:
1)之前已经声明过这个变量
2)重新赋值的时候至少还有另一个新创建的变量
示例:
f, err := os.Open(name)
...
d, err := f.Stat()
三、for
1、常见for 循环格式
// Like a C for
for init; condition; post { }
// Like a C while
for condition { }
// Like a C for(;;)
for { }
2、使用下划线忽略不需要关注的对象
在编译map/slice 的时候还是很有用的,比如slice 大部分时候其实我们只关系值,不关心下标,就可以用 下划线 忽略下标:
sum := 0
for _, value := range array {
sum += value
}
3、其他细节
for 循环遍历字符串,会按照具体编码的格式来展示,比如中文,就是一个个汉字;
++、-- 是语句而不是表达式,本身没有返回值
四、switch
1、特点
和 C 的switch 不同,go 的 switch 不仅可以写 bool 类型的表达式,还可以设置 equal 的条件,甚至还可以通过逗号分隔,用“或”的方式判断多个条件是否满足其一,如下:
func shouldEscape(c byte) bool {
switch c {
case ' ', '?', '&', '=', '#', '+', '%':
return true
}
return false
}
2、switch 中的 break
由于 switch 中 走具体分支之后,其他的分支就不会走了(包括default),因此break 的使用场景其实不多,一般就用在刚才在介绍if 的时候说的:异常场景提前退出的时候才需要用到
3、实战:通过switch 实现更美观的字符串对比方法
这里其实就只是代码风格的问题了,见仁见智,如果有else if 这样的条件出现,确实switch 开起来会更美观一些,单个if…else 就不是特别必要
// Compare returns an integer comparing the two byte slices,
// lexicographically.
// The result will be 0 if a == b, -1 if a < b, and +1 if a > b
func Compare(a, b []byte) int {
for i := 0; i < len(a) && i < len(b); i++ {
switch {
case a[i] > b[i]:
return 1
case a[i] < b[i]:
return -1
}
}
switch {
case len(a) > len(b):
return 1
case len(a) < len(b):
return -1
}
return 0
}
4、实战:type switch
go 的type 由于也是一个变量,可以通过.(type) 的方式强转来获取。也正因为switch 可以放任何类型的变量,所以对type 的多分支判断也可以使用switch:
var t interface{}
t = functionOfSomeType()
switch t := t.(type) {
default:
fmt.Printf("unexpected type %T\n", t) // %T prints whatever type t has
case bool:
fmt.Printf("boolean %t\n", t) // t has type bool
case int:
fmt.Printf("integer %d\n", t) // t has type int
case *bool:
fmt.Printf("pointer to boolean %t\n", *t) // t has type *bool
case *int:
fmt.Printf("pointer to integer %d\n", *t) // t has type *int
}
方法定义
一、多个返回值
背景:C语言去定义需要返回异常的场景的时候会遇到一个问题:比如从数据库获取一个实例对象,本来是可以直接返回这个对象,但是因为存在数据为空的情况,变成只能返回指针了。上层解析又要针对特殊情况做处理,以及对象转换。
Go的方法可以直接定义多个返回值,常见的格式如下:
func (file *File) Write(b []byte) (n int, err error)
代码规范:方法主要返回放在前面,错误信息error 放最后
也正是因为这种可以返回error的设计,go不需要异常处理机制(再结合刚才说的if 对错误的处理,以及后面要说到的defer recover)
除了返回 业务数据+error,还有一种场景是返回当前数据+下一个标志位,类似redis的 scanner
参考代码(最好用官方库的代码)
func nextInt(b []byte, i int) (int, int) {
for ; i < len(b) && !isDigit(b[i]); i++ {
}
x := 0
for ; i < len(b) && isDigit(b[i]); i++ {
x = x*10 + int(b[i]) - '0'
}
return x, i
}
二、返回值命名
是一种设置返回值的特殊形式:不通过return,而是直接给返回值变量赋值。其实就是简化代码,比较取巧的一种方式,个人不是很推荐使用,加大了源代码理解成本,只有很特殊的场景才比较有可能用到
func ReadFull(r Reader, buf []byte) (n int, err error) {
for len(buf) > 0 && err == nil {
var nr int
nr, err = r.Read(buf)
n += nr
buf = buf[nr:]
}
return
}
三、defer
最经典的用法就是资源释放,资源类对象在申请之后就紧接着defer,也是代码规范要求的
// Contents returns the file's contents as a string.
func Contents(filename string) (string, error) {
f, err := os.Open(filename)
if err != nil {
return "", err
}
defer f.Close() // f.Close will run when we're finished.
var result []byte
buf := make([]byte, 100)
for {
n, err := f.Read(buf[0:])
result = append(result, buf[0:n]...) // append is discussed later.
if err != nil {
if err == io.EOF {
break
}
return "", err // f will be closed if we return here.
}
}
return string(result), nil // f will be closed if we return here.
}
其他使用场景:耗时计算(defer一个方法并执行)、调用链
特别注意: defer对方法传参的存储
for i := 0; i < 5; i++ {
defer fmt.Printf("%d ", i)
}
最后输出:4,3,2,1,0
因为defer 存入是一个栈的模式,因此FILO(先进后出)
还有一点要留意:由于defer 中保留的局部变量是存值(其实和方法传参一样,指针类型就传地址),所以for 循环中释放局部变量对应的资源其实是不合理的,资源类对象往往都有指针类型的对象,for each 循环定义的都是同一个临时变量,因此可能会导致最后defer 释放的是同一个资源。
我们在最后讲channel 的时候还会回来看这个defer + channel 的用法,并说明正确的释放资源方式。
对象操作(声明、初始化等)
一、new
按传入的对象类型申请空间,并返回这个类型的对象对应的指针。
和直接通过var 初始化的结果一样,这个对象里面的成员都会被初始化成0值,指针类型的话是空,但是诸如sync包、bytes.Buffer对象,初始化0值之后是可以直接使用的,因为它们没有指针类型的属性。
比如下面这个syncedbuffer对象,new之后可以直接使用,内部对象不需要再初始化一样
type SyncedBuffer struct {
lock sync.Mutex
buffer bytes.Buffer
}
// mutex
type Mutex struct {
state int32
sema uint32
}
// buffer
type Buffer struct {
buf []byte
off int
lastRead readOp(int8)
}
不过对于一些本身初始化就需要比较多参数的变量,还是应该通过var 方式初始化,相比new 来说,格式更简洁
func NewFile(fd int, name string) *File {
if fd < 0 {
return nil
}
return &File{fd, name, nil, 0}
}
二、make
New一般用来初始化struct对象,但是对于 slice、map和channel 这种容器对象来说,它们内部是有指针对象的,因此直接用new 初始化肯定不行,不能直接使用。需要通过make 来初始化
顺便来了解一下slice和map 的结构:
Slice 结构:
type slice struct {
array unsafe.Pointer
len int
cap int
}
map 结构:
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
make 的源码可以参考 makeslice、makemap,过程还是挺复杂的,感兴趣可以了解一下
三、数组(array)
数组相当于刚才看到的slice 数据结构中的内部对象 array
和slice 不同的地方:
1)必须在声明的时候初始化大小
2)不能扩容
3)对数组赋另一个数组,直接拷贝所有元素,两个数组的实际地址不同。同样传递到方法中也会拷贝一份
4)数组的大小在Type 中体现,因此[10]int 和 [20]int 类型不同,不能相互赋值
实际使用array 的场景其实不多,slice 更多一些(扩容更方便)
但是还是有一个跟GC 相关的优化细节:如果只要用到 超长Slice 的一部分元素,可以通过子array 来拷贝一份数组出来,而不是用子slice (子slice 会导致原大slice 依然被引用,不会被GC)
使用示例如下:
touselist = make([]int, 3)
copy(touselist, sublist)
四、slice
相比较array 在类型上的限制,slice 的使用就比较灵活了:不限大小、可以自动扩容、类型统一。因此go 底层传递数组 绝大多数都是 slice 实现的,而不是array
另外slice 是通过指针管理实际的数组的,因此slice 可以传递到方法中,并且方法内部对元素的修改在外部可见。
最后是 slice 最长用的append 方法,由于添加元素之后 slice 可能会扩容,导致后续的 slice 和原来的 slice 地址不同,因此需要接收 append 返回的新slice。
当然,效率更高的方式还是要预先给数组申请足够的capacity
arr = make([]int, 0, cap);
arr = append(arr, ele...)
五、二维数组
初始化:常见的方式依然是使用slice,只指定首层的大小,第二层先不初始化,同时这样每一层的数组大小也可以不同。
在 图像处理 类似的数据处理场景可以用到
text := LinesOfText{
[]byte("Now is the time"),
[]byte("for all good gophers"),
[]byte("to bring some fun to the party."),
}
六、map
map 也是go 里面的基本容器数据类型之一
1、key
类型可以是任何按 == 可比较的对象(比如基本类型、指针、interface 和 属性都是可比较的struct 其实都可以),slice 虽然可对比,但是== 其实是浅对比,并不是对比内部所有的元素,因此不适合作为key
注:切片 或者是包含了切片的 struct 如果要对比,可以使用reflect.DeepEqual 方法来比较,这个方法本质上就是对slice、array、struct 等复合结构体进行递归匹配所有属性是否相同,感兴趣可以直接看源码或者参考博客
2、添加value
map 虽然和slice 都是复合结构,但是和 slice 不同,扩容之后存储的地址还是不变的,因此可以放心地传递到方法内部并修改
3、获取
用法:和其他语言基本一致,也是分直接打印(print)、按format打印(printf)和指定流打印(fprint)这几种
因此如果value 是基础类型,不能直接从返回值直接确认到底key 是否存在,而应该通过这种方式判断:
_, ok := testMap[myFooVar]
if !ok {
log.Printf("[test] get value failed")
}
或者是直接通过 if 判断:
if attended[person] { // will be false if person is not in the map
fmt.Println(person, "was at the meeting")
}
更常见的其实是第一种,这种方式在go 中叫“comma ok”写法,类似的写法还有类型强转:
fooVar, ok := barVar.(Foo)
七、打印
1、基本用法
用法:和其他语言基本一致,也是分直接打印(print)、按format打印(printf)和指定流打印(fprint)这几种
fmt.Printf("Hello %d\n", 23)
fmt.Fprint(os.Stdout, "Hello ", 23, "\n")
fmt.Println("Hello", 23)
fmt.Println(fmt.Sprint("Hello ", 23))
其中,fPrint的第一个参数必须实现io.Writer接口
Printf和C语言的不同:由于go的对象类型是可以直接获取的,因此数字类型不需要指定长度。具体可参考 fmt/print.go 中的实现。
var x uint64 = 1<<64 - 1
fmt.Printf("%d %x; %d %x\n", x, x, int64(x), int64(x))
所有对象都可以通过%v来format。对于struct类型的对象,默认打印其所有对象;
2、其他常用format:
%T:对象类型
%g:浮点数和整数,不设精度
%q:按各个字符打印字符串,不会按特殊字符截断,比如换行符也会按转义前格式来打印
%s:一般用来打印字符串或者是实现了String方法的struct,如果未实现就按照%v 方式打印对象。后面还会更详细讲到String 这种 pointer receiver的用法
3、小技巧:arbitrary type 的用法
来看看printf的方法定义:
func Printf(format string, v …interface{}) (n int, err error) {
其中,v就是arbitrary type,表示不定长参数,只能作为方法的最后一个参数传入
什么场景下会用到呢?比如printf 需要传递多个format参数,但是不确定参数个数,传递数组有点麻烦,在调用之前还得再多声明一个变量。
类似的,马上要说到的append方法也用到了这种类型。
到了方法内部,arbitrary type的用法就和数组没有区别了,可以直接用for遍历
4、扩展:日志包的选用
官方提供的log包没有日志等级区分,真的不能算好用。开源项目中推荐使用 uber/zap 来定制化自己的logger
参考博客
八、append
slice 专用的添加元素方法,直接看示例:
// example 1
x := []int{1,2,3}
x = append(x, 4, 5, 6)
fmt.Println(x)
// example 2
x := []int{1,2,3}
y := []int{4,5,6}
x = append(x, y...)
fmt.Println(x)
初始化
1、常量(constant)
类型要求:由于go 的常量都是在编译期间就先分配好空间了,因此只能是基础类型(而且不能包含其他需要执行的方法)
定义整形枚举常量还有一个很特别的方式: 通过 iota 设定计算公式,然后连续的下一个constant 会递增。这样就不需要每一行都重复写类似的公式了
type FileSize uint64
const (
_ FileSize = iota // 第一行定义类型
KB FileSize = 1 << (10 * iota) // 第二行定义计算公式
MB
GB
TB
)
2、变量
这里指的是pkg 的变量,声明方式和位置都和const 类似,只不过会在运行时才初始化,顺序:会在pkg 的 init 方法之前被初始化
var (
home = os.Getenv("HOME")
user = os.Getenv("USER")
gopath = os.Getenv("GOPATH")
)
3、init
参考博客
func init() {
mode := os.Getenv(EnvGinMode)
SetMode(mode)
}
但是,经过实践,建议还是不要过于依赖init 方法,特别是一个web 后台,需要依赖很多资源的时候,如果资源之间又有依赖关系,那么init 的顺序就容易错乱了。还是主动初始化的方式更加合理。
方法
pointer receiver 和 value receiver
go 中,定义一个struct 的内部方法,或者是下面准备说到的:实现一个interface 的方法,主要是通过pointer receiver 和 value receiver 两种方式
先说一下这两种方式的不同:
| 类型\特性 | 拷贝对象 | 通过value 调用 | 通过pointer 调用 |
|---|---|---|---|
| value receiver | 会 | 可以 | 可以 |
| pointer receiver | 不会 | 可以,会自动将对象先用& 转成指针 | 可以 |
了解完这个对比,我们应该大致了解了pointer receiver 是更加常用的方式,因为它依然复用调用的对象,于是可以在 pointer receiver 中直接对对象做修改。
示例:
// int array 类型
type IntArray [3]int
// pointer receiver
func (arr *IntArray) Modify(index, value int) {
(*arr)[index] = value
}
// value receiver
func (arr IntArray) Print() {
log.Printf(fmt.Sprint(arr))
}
// 测试两种 receiver 的方式对比
func TestReceiver(t *testing.T) {
myArr := IntArray{1, 2, 3}
myArr.Modify(0, 112233)
myArr.Print()
}
Interface
一、概述
Interface一般是用来定义实现哪些方法,就是属于什么类型的定义
官方例子:个人认为很清楚地说明了interface在接口定义和实现的基本用法了:只需要实现 Interface 中定义的所有方法,struct 就算是“实现”了这个 Interface
type Sequence []int
// Methods required by sort.Interface.
func (s Sequence) Len() int {
return len(s)
}
func (s Sequence) Less(i, j int) bool {
return s[i] < s[j]
}
func (s Sequence) Swap(i, j int) {
s[i], s[j] = s[j], s[i]
}
// Copy returns a copy of the Sequence.
func (s Sequence) Copy() Sequence {
copy := make(Sequence, 0, len(s))
return append(copy, s...)
}
// Method for printing - sorts the elements before printing.
func (s Sequence) String() string {
s = s.Copy() // Make a copy; don't overwrite argument.
sort.Sort(s)
str := "["
for i, elem := range s { // Loop is O(N²); will fix that in next example.
if i > 0 {
str += " "
}
str += fmt.Sprint(elem)
}
return str + "]"
}
一个对象可以实现多个Interface的方法,类似java的多继承
二、struct 类型强转
刚才的例子中,在最后的字符串拼接部分,由于要组装新的字符串,会导致时间复杂度变成(O(N^2))
更高效的方式是直接将Sequence转换成原始类型:[]int,然后直接转换即可
func (s Sequence) String() string {
s = s.Copy()
sort.Sort(s)
return fmt.Sprint([]int(s))
}
那么可能有人会问:强转不是也是产生新的对象?其实不是的,因为 Sequence 的原始格式就是 []int,强转只会将内部的类型对象(Type)替换,原始数据用的还是同一份
三、Interface 类型判断和指定类型强转
通过刚才的例子我们了解到了一些go的类型系统的细节:任何变量底层都是有一个type 属性的。其实很多底层工具或者框架的源代码,都是通过类型系统,在做数据处理之前区分不同的处理方式。
对于一些 Interface 类型传参的方法来说,往往需要针对不同的类型走不同的分支处理。
示例如下:打印一个字符串对象(类似Printf 底层实现)
type Stringer interface {
String() string
}
var value interface{} // Value provided by caller.
switch str := value.(type) {
case string:
return str
case Stringer:
return str.String()
}
那么如果确定一个interface的实际类型的时候,怎么强转呢?类似上面提取type的方式转换即可。(注意括号的强转是要严格类型匹配的,interface 类型不能直接这么强转,一定要用 .(type) 的方式转)
但是要注意如果类型不匹配,强转会抛出运行时错误,因此comma, ok格式又派上了用场:
str, ok := value.(string)
if ok {
fmt.Printf("string value is: %q\n", str)
} else {
fmt.Printf("value is not a string\n")
}
当interface 的实际类型不确定的时候,尽量才用 comma, ok 的方式来保证程序不panic。
四、抽象的规范
实体对象要具体使用之前,需要先强转成实际的类型,那么接口、驱动类对象呢?
我们知道,一般一个框架类的interface都是只定义方法(约束行为),然后给外部提供多种实现类,让用户自己选择。
比如数据库连接池,只提供需要实现的方法(prepare、exec等),至于你是用什么类型的数据库,要用的时候指定驱动类型就行了。其实官方的sql.DB就是通过这种思路实现的:
import (
......
"gorm.io/driver/mysql"
"gorm.io/gorm"
)
func GetDBConnection(dbName string) *gorm.DB {
......
db, err := gorm.Open(mysql.Open(GetConfigFromJson(dbName)), &gorm.Config{})
......
}
常见的方式,用户自定义,返回一个框架内部初始化的对象,外部
面向对象的语言其实基本都有这种实现思路。而且应用在实际项目中,可以让我们的代码更加规范,可扩展性更高。
类似的思想,之前我已经在自己的项目重构的过程中大概讲过了:资源类的对象都要封装。感兴趣也可以稍微了解一下:博客地址
五、抽象和业务实现
接下来我们结合 http.Handler 来看interface 的方法定义和实践的具体用法:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
实现了 ServeHTTP 的对象,都可以直接作为对外接口的handler:
// Simple counter server.
type Counter struct {
n int
}
func (ctr *Counter) ServeHTTP(w http.ResponseWriter, req *http.Request) {
ctr.n++
fmt.Fprintf(w, "counter = %d\n", ctr.n)
}
// main
import "net/http"
...
ctr := new(Counter)
http.Handle("/counter", ctr)
甚至,都不一定非得是struct,基础类型也可以,只需要type def 一下:
// Simpler counter server.
type Counter int
func (ctr *Counter) ServeHTTP(w http.ResponseWriter, req *http.Request) {
*ctr++
fmt.Fprintf(w, "counter = %d\n", *ctr)
}
接下来重头戏来了:刚接触go 的同学,很难想到func 也可以作为 value receiver,http.HandlerFunc 是一个很好的切入点:
前面两种方式都需要定义一个新的type,如果我们需要定义的handler 功能比较简单,就只是一个方法而已,那么就没必要了。
这时候就可以用到定义http.Handler最简便的方式:http 包中也很贴心地定义了一个HandlerFunc 对象,就是为了方便我们直接对 一个func 做转换,并直接作为 http.Handler 设置到请求处理器中:
// The HandlerFunc type is an adapter to allow the use of
// ordinary functions as HTTP handlers. If f is a function
// with the appropriate signature, HandlerFunc(f) is a
// Handler object that calls f.
type HandlerFunc func(ResponseWriter, *Request)
// ServeHTTP calls f(w, req).
func (f HandlerFunc) ServeHTTP(w ResponseWriter, req *Request) {
f(w, req)
}
诸如 /health、/stat 等比较简单的GET 接口,可以直接强转成 HandlerFunc 之后传入接口定义中,非常方便:
// Argument server.
func ArgServer(w http.ResponseWriter, req *http.Request) {
fmt.Fprintln(w, os.Args)
}
// main.go
http.Handle("/args", http.HandlerFunc(ArgServer))
关于 http.HandlerFunc 的更多用法可以参考 golang wrapper 的设计思想,参考博客
空白标识符(下划线 blank identifier)
一、介绍
空白占位符的常见用途其实就是忽略不需要关注的信息,比如for循环遍历数组,或者是map
二、使用:忽略不需要关注的返回值
if _, err := os.Stat(path); os.IsNotExist(err) {
fmt.Printf("%s does not exist\n", path)
}
除了之前提到的for 循环之外,比如一个文件写入操作,基本通过是否返回error,就能判断出操作是否成功了。前面的写入多少个字符,其实不一定要关心
但是有一些规范要注意:error要作为方法的最后一个入参,而且不建议忽略
三、使用:提醒功能:临时不用的变量
由于go对不允许在方法内部定义未使用的变量,所以如果是开发一个功能,即使是提交初版,也难免要为了编译不操作,而临时 print 一下变量
但是有了下划线就没必要打印了,如下:一般和TODO结合使用
package main
import (
"fmt"
"io"
"log"
"os"
)
var _ = fmt.Printf // For debugging; delete when done.
var _ io.Reader // For debugging; delete when done.
func main() {
fd, err := os.Open("test.go")
if err != nil {
log.Fatal(err)
}
// TODO: use fd.
_ = fd
}
四、使用:仅执行init 的 空import
和Java不同,未显式使用过的import在go中就和未使用过的局部变量一样,会编译不过。
但是go的import使用有两种场景:除了要引入可直接声明的对象,或者要使用的方法之外,还有另一种用途:执行init 方法:只要引入了pkg,这个pkg内部的init方法就会在使用前被执行
因此就有了下面的用途:pprof 是go的性能数据对外展示用的包,但是我们并不需要显式使用,只需要空import进来就可以了
// main.go
import _ "net/http/pprof"
// pprof.go
func init() {
http.HandleFunc("/debug/pprof/", Index)
http.HandleFunc("/debug/pprof/cmdline", Cmdline)
http.HandleFunc("/debug/pprof/profile", Profile)
http.HandleFunc("/debug/pprof/symbol", Symbol)
http.HandleFunc("/debug/pprof/trace", Trace)
}
同理数据库驱动也可以这样import进来
五、使用:类型检查
通过 comma ok 的示例,我们学到了interface 类型的转换方式,这种检查是在运行时进行的。不过对于interface 类型,我们还可以通过 空白标识符,在编译期间就进行类型检查,保证运行时期不报错,或者说能准确执行对应的实现方法。
举个例子:通过 json.Marshal 反序列化一个对象的时候,会优先检查这个对象本身是否实现了 MarshalJSON() ([]byte, error) 方法,如果实现了,就优先使用这个方法。因此如果要求一个对象必须定义自己的反序列化方法,可以这么检查:
type foo struct {
Name string
}
func (f *foo) MarshalJSON() ([]byte, error) {
// TODO: implement
}
// 测试类型检查
func TestVerifyInterfaceType(t *testing.T) {
var _ json.Marshaler = (*foo)(nil)
}
其中json.Marshaler 对象就是一个只实现了MarshalJson 的interface。
在编译期间就检查出interface 类型的错误,还有一个好处:如果依赖的是第三方仓库的interface,这个第三方interface变动了,就能够直接在编译期间就检查出来
内嵌(embedded)
对 interface 的嵌入式实现(embedded)应该是go 对多继承的一种独特实现方式。但是Java 中的多继承只能继承接口,不能继承具体的实现类。go 通过更简便的定义方式(类似前面说的继承,通过行为来说明,而不是通过继承的关键字说明),可以继承多个实现类。
比如io 流的基本操作,主要有两个接口类:reader 和 writer
type Reader interface {
Read(p []byte) (n int, err error)
}
type Writer interface {
Write(p []byte) (n int, err error)
}
那么如果要定义一个具有完整操作的ReadWriter 类,就可以通过 内嵌 的方式定义:
// io/io.go
type ReadWriter interface {
Reader
Writer
}
具体实现类 需要如何定义初始化呢?
直接定义 实现struct 名称,注意和interface 一样,也不需要加上属性名
type Job struct {
Command string
*log.Logger
}
初始化:通过 实现类变量名.被继承的interface名字,会自动找到对应的实现类
func NewJob(command string, logger *log.Logger) *Job {
return &Job{command, logger}
}
func (job *Job) Printf(format string, args ...interface{}) {
job.Logger.Printf("%q: %s", job.Command, fmt.Sprintf(format, args...))
}
内嵌还有几个值得留意的细节:
1、循环内嵌了同一个方法,最终会以最外层定义的方法更优先
2、同层方法冲突:“懒提醒”。比如在一个printer类中 嵌入了 多个logger,这些logger 都实现了底层的print 方法,定义是不会编译报错的,只有使用了具体的interface method 才会报错
参考代码
并发
一、设计理念:通过通信实现共享内存
想象现在有 a、b 两个进程之间需要相互通信,通常想到的方式是在a 中调用b 的对外方法,然后把需要传入的数据通过参数传递给b。这就是典型的通过共享内存实现通信的思想。
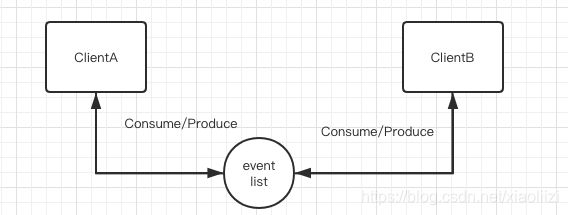
但是go 的理念就是通过 通信本身来完成数据的交换,这点在很多框架设计上都能看到:http 请求接收器 和 请求处理,一般都是分开的两个协程去完成的,它们之间会通过channel来完成通信。
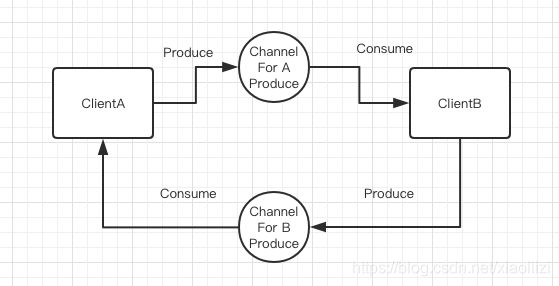
其实最后达到的效果是完全一样的,后者在结构上会更加清晰,两个客户端之间相互解耦,而且也减少了共享内存同步的编码成本。
总之,牢记官方的slogan,我们会在学习go 的过程中多次看到这条法则的具体实现:
Do not communicate by sharing memory; instead, share memory by communicating.
二、启动 routine
routine 为什么相比线程 更轻量,网上已经有非常多的介绍,这里不再赘述。
启动一个协程的方式非常简单:直接 go 方法名 就可以了。或者是在需要执行的时候才说明 协程的具体任务,如下:
func Announce(message string, delay time.Duration) {
go func() {
time.Sleep(delay)
fmt.Println(message)
}() // Note the parentheses - must call the function.
}
但是注意:协程运行的形式 都是 类似Java 的守护线程,它不会阻塞主协程的结束。
三、channel
routine 之间的数据交换,肯定要通过一个消息通道来完成,而且这个消息通道的消费和生产 必须是原子性的。这就是channel 的由来。
1、定义方式
和 slice 类似,channel 也是通过make 初始化的 ,而且可以指定通道缓冲大小,默认为0,生产和消费都是直接进入阻塞状态
ci := make(chan int) // unbuffered channel of integers
cj := make(chan int, 0) // unbuffered channel of integers
cs := make(chan *os.File, 100) // buffered channel of pointers to Files
2、生产和消费示例
c := make(chan int) // Allocate a channel.
// Start the sort in a goroutine; when it completes, signal on the channel.
go func() {
list.Sort()
c <- 1 // Send a signal; value does not matter.
}()
doSomethingForAWhile()
<-c // Wait for sort to finish; discard sent value.
3、使用场景:设定最大的请求处理数
前面我们了解到,空buffer 的 channel 一般直接用于生产-消费者之间的通信
但是对于web 框架,往往我们还是会给一定的buffer 大小,用于批量处理HTTP 请求。因此更常见的场景应该是这样的:
var sem = make(chan int, MaxOutstanding)
func handle(r *Request) {
sem <- 1 // Wait for active queue to drain.
process(r) // May take a long time.
<-sem // Done; enable next request to run.
}
func Serve(queue chan *Request) {
for {
req := <-queue
go handle(req) // Don't wait for handle to finish.
}
}
一个http 请求进来的顺序就是:Serve -> handle
但是上面的程序有个小问题:就是Serve 并没有感知 请求处理队列(sem)当前的状态,这会导致即使队列满了,Serve 方法依然会去创建一个新的协程,如果 处理队列的buffer 扛不住 实际请求压力,可能会导致程序资源不够(创建太多协程)
因此更合理的方式应该是在Serve 中将消息(或者是一条记录)存入待处理队列中:
func Serve(queue chan *Request) {
for req := range queue {
sem <- 1
go func() {
process(req) // Buggy; see explanation below.
<-sem
}()
}
}
看上去上面的代码逻辑是ok了,其实是有一个使用上的大问题:留意到在 执行业务逻辑的协程中用到了外面 for 循环的局部变量 req,这个局部变量在for 循环中其实是共用的,因此虽然创建的时候,传给process 的req 确实是当前的req, 但是这个req 实际指向的请求是会随着遍历过程变化的。
这个是在 go for 循环编写过程中一定要特别留意的问题。我们可以利用go 开启协程执行的其实是一个方法,可以给这个方法定义入参,来修正程序:
func Serve(queue chan *Request) {
for req := range queue {
sem <- 1
go func(req *Request) {
process(req)
<-sem
}(req)
}
}
4、使用场景:channels of channels
上一节的例子展示了一个简单的 http 请求处理器,它完成了请求从接收到处理的整个过程,但是请求处理的结果 我们没有处理,其实对于 http handler 来说,确实返回结果并不是很重要,一般都是直接返回给请求端的。
但是如果有需要处理异步结果的场景,比如同一个服务中,从controller 层提交到service 层,需要把job 提交到 service 的channel。然后service 处理 job 完成之后,又要把 结果 返回给controller 的channel,这就是 channels of channels 的基本设计了:
// 请求model 定义
type Request struct {
args []int
f func([]int) int
resultChan chan int
}
// 求和Request 定义
func sum(a []int) (s int) {
for _, v := range a {
s += v
}
return
}
request := &Request{[]int{3, 4, 5}, sum, make(chan int)}
// Send request
clientRequests <- request
// Wait for response.
fmt.Printf("answer: %d\n", <-request.resultChan)
// 请求处理方法
func handle(queue chan *Request) {
for req := range queue {
req.resultChan <- req.f(req.args)
}
}
五、并行(parallelization)
说到并行,首先我们必须理解它和并发的不同:并发只是操作系统用户层开启了多个并行任务,而并行是cpu上的同时运行,充分利用了机器的资源。
前面我们看到的开启协程来运行任务的方式,其实只是并发,真正能同时运行的协程数受限于机器的cpu核数。
因此对于不相互依赖的多任务,我们可以这样让资源更加被充分使用:
var numCPU = runtime.NumCPU()
func (v Vector) DoAll(u Vector) {
c := make(chan int, numCPU) // Buffering optional but sensible.
for i := 0; i < numCPU; i++ {
go v.DoSome(i*len(v)/numCPU, (i+1)*len(v)/numCPU, u, c)
}
// Drain the channel.
for i := 0; i < numCPU; i++ {
<-c // wait for one task to complete
}
// All done.
}
而go runtime(运行环境,类似虚拟机)中的全局变量GOMAXPROCS,表示可同时运行的routine数,默认就是cpu核数。这个值可以通过 runtime.GOMAXPROCS 方法设置
更多关于并行和并发的官方讲解
6、实战:生产-消费模型
// 生产者
var freeList = make(chan *Buffer, 100)
var serverChan = make(chan *Buffer)
func client() {
for {
var b *Buffer
// Grab a buffer if available; allocate if not.
select {
case b = <-freeList:
// Got one; nothing more to do.
default:
// None free, so allocate a new one.
b = new(Buffer)
}
load(b) // Read next message from the net.
serverChan <- b // Send to server.
}
}
// 消费者
func server() {
for {
b := <-serverChan // Wait for work.
process(b)
// Reuse buffer if there's room.
select {
case freeList <- b:
// Buffer on free list; nothing more to do.
default:
// Free list full, just carry on.
}
}
}
这里有几个数据结构:freeList 用来缓存消费者处理完成的结果,serverChan 保存处理中的请求,它的大小决定了任务的并发程度。
因此一个经典的生产-消费模型至少都需要一个 任务等待队列、任务处理队列 和 结果队列。通过channel 来进行数据通信。
错误处理
一、error:自定义错误的方式
自定义error 其实很简单,只需要按 error interface 的定义,实现了Error 方法就可以了:
// builtin/builtin.go
// The error built-in interface type is the conventional interface for
// representing an error condition, with the nil value representing no error.
type error interface {
Error() string
}
来看一个具体的例子:读取文件的失败原因有很多种,如何让文件读取失败的时候,带上文件的具体信息,最好的方式就是自定义error:
// os/error.go
// PathError records an error and the operation and file path that caused it.
type PathError struct {
Op string
Path string
Err error
}
func (e *PathError) Error() string { return e.Op + " " + e.Path + ": " + e.Err.Error() }
最后是 校验错误类型和错误信息的方式:可以通过前面提到的 switch 或者是 类型强转(type switch or a type assertion)来判断
for try := 0; try < 2; try++ {
file, err = os.Create(filename)
if err == nil {
return
}
if e, ok := err.(*os.PathError); ok && e.Err == syscall.ENOSPC {
deleteTempFiles() // Recover some space.
continue
}
return
}
二、 panic
panic 和 error 都体现了程序在运行时期的错误,error 一般是可处理的,但是如果不处理也会升级成panic,导致程序直接退出。
捕获方式上也能体现两者的不同,当然捕获方式其实也是由两种错误的性质不同决定的:
error 主要是程序运行期间,比如连接 数据库资源失败,或者是校验用户的接口传参失败,都是单次任务的问题;而 panic 是系统问题,一般发生的时候是整个系统都不可用了。比如空指针错误、数组下标越界、类型强转失败。
主动 panic 的一种常见场景:容器内服务初始化的时候,检查容器名是否存在,容器名需要作为服务的标识,在进行服务注册的时候使用:
var user = os.Getenv("CONTAINER")
func init() {
if user == "" {
panic("no value for $CONTAINER")
}
}
三、recover - panic 的捕获方式
1、恢复 routine 的方式
一个routine 在触发panic之后,会层层退出调用链,最后执行defer 方法之后彻底退出routine
但是对于一些定时任务,有的时候我们仍然希望触发panic 之后,再恢复执行,并通知开发,而不是直接退出
这就是 defer recover 的用途:它能够将触发panic 作为参数 ,传递给上层,然后再由上层决定处理方式
一个简单的示例:
func server(workChan <-chan *Work) {
for work := range workChan {
go safelyDo(work)
}
}
func safelyDo(work *Work) {
defer func() {
if err := recover(); err != nil {
log.Println("work failed:", err)
}
}()
do(work)
}
这个例子中,recover 只是将panic简单打印了之后直接退出。
几个疑问:
1)多个同层defer 之间的执行顺序?以及如果多个defer 都执行了recover,是哪个会拿到最终的panic? – 因为defer 相当于栈,是一个FILO 的结构,因此第一个defer会拿到panic
2)defer recover 本身抛出panic,其他的defer 是否还会执行? – 不会了,程序将直接退出,因此要尽量保证recover 的代码不要出问题
2、一个更实用的例子:封装公共方法的错误,常在框架中使用
这里还用到了之前提到的设置返回的参数名称,可以在defer 中重新对返回值进行重新赋值:
// Error is the type of a parse error; it satisfies the error interface.
type Error string
func (e Error) Error() string {
return string(e)
}
// error is a method of *Regexp that reports parsing errors by
// panicking with an Error.
func (regexp *Regexp) error(err string) {
panic(Error(err))
}
// Compile returns a parsed representation of the regular expression.
func Compile(str string) (regexp *Regexp, err error) {
regexp = new(Regexp)
// doParse will panic if there is a parse error.
defer func() {
if e := recover(); e != nil {
regexp = nil // Clear return value.
err = e.(Error) // Will re-panic if not a parse error.
}
}()
return regexp.doParse(str), nil
}
同时,在defer 中还可以对错误类型进行检查,如果不是业务自定义的错误(即未在预料范围内的错误,程序的其他异常)这种情况将会继续抛出panic。因为这种情况其实没必要由业务来处理错误,就应该让程序终止,及时在测试阶段被感知到。