MySQL操作合集
数据库的操作
创建数据库
create database [if not exists] db_name
[character set utf8]
[collate utf8_general_ci];
查看所有数据库
show databases;
查看数据库的创建语句
show create database db_name;
修改数据库
alter database db_name
character set utf8
collate utf8_bin;
删除数据库
drop database [if exists] db_name;
- 里面所有的表都会被删除
备份和恢复
备份:
在操作系统的shell中完成
mysqldump -P3306 -uroot -p密码 -B数据库名 > 备份储存的文件路径
还原:
在mysql中完成
source 备份储存的文件路径
可以使用相对路径,默认当前路径为mysql客户端打开的路径
注意事项:
-
备份数据库下的表
mysqldump -uroot -p 数据库名 表1 表2 > 备份储存的文件路径 -
备份多个数据库
mysqldump -uroot -p -B 数据库1 数据库2 >备份储存的文件路径 -
如果备份一个数据库没有
-B,恢复时需要先进入一个数据库再source
表的操作
创建表
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
) [character set 字符集] [collate 校验规则] [engine 存储引擎];
存储引擎:
show engines;
- MyISAM:数据目录中由三种不同的文件
- .frm:表结构
- .MYD:表数据
- .MYI:表索引
- InnoDB:由两种不同的文件
- .ibd:索引和数据
- .frm:表结构
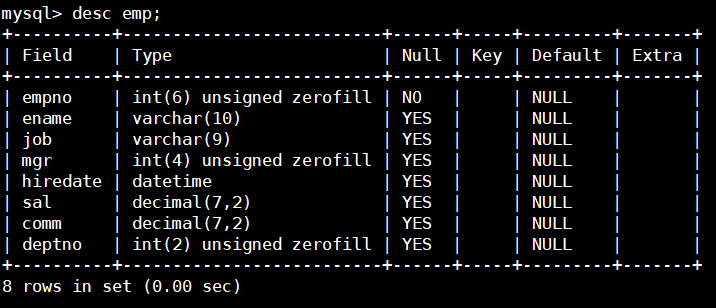
查看表结构
desc 表名;
修改表
alter table tablename add column datatype [after column] [not null][default expr],column...
alter table tablename modify column datatype ...
alter table tablename drop column;
删除表
drop temporary table [if exists] tb_name,...
关于字符集和校验集
查看所有的字符集和校验集:
show character set [like 'utf8%'];
show collation [like 'utf8%'];
查看当前数据库的默认字符集和校验集:
show variables like 'character_set_database';
show variables like 'collation_database';
实际上有很多character_set 和collation ,mysql服务器的、客户端的、数据库的…它们具有一定继承关系
在当前数据库下建表的默认字符集和校验集从上面继承而来
表的字符集和校验集:
--创建时指定
create table table_name(
...
)character set utf8 collate utf8_bin;
--修改
alter table table_name character set utf8 collate utf8_bin;
指定某一列的字符集和校验集:
--创建时指定
create table table_name(
name varchar(30) character set utf8 collate utf8_bin;
);
--修改某一列
alter table table_name modify name varchar(30) character set utf8 collate utf8_bin;
两个常用的校验方式:
utf8_general_ci;//不区分大小写
utf8_bin;//区分大小写
DML
插入
插入冲突解决
insert过程可能发生主键冲突或唯一键冲突
-
更新:
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师') ON DUPLICATE KEY UPDATE sn = 10010, name = '唐大师';当主键冲突发生,直接把当前主键对应的
sn和name进行更新 -
替换:
REPLACE INTO students (sn, name) VALUES (20001, '曹阿瞒');不冲突则插入,冲突则删除后重新插入
查询
别名
SELECT column [AS] alias_name [...] FROM table_name;
SELECT id, name, chinese + math + english 总分 FROM exam_result;
去重
SELECT DISTINCT math FROM exam_result;
where条件
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
|---|---|
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
where后面的表达式可以出现select字句,如:
where sal = (select max(sal) from emp);
子查询如果是多行,可能会用到如下关键词:
| IN | where column in (select …) 存在即返回true |
|---|---|
| ALL | where column > all(select …) 大于所有即返回true |
| ANY | where column > all(select …) 大于任意一个即返回true |
如果是多个元素的对应,即子查询是多列,可以用如下方式:
where (colum1,colum2,…) = (select colum1,colum2,… from emp);
子查询
像上面的子查询不仅可以出现在如上的where后面的表达式中
还可以直接将子查询当作一张临时的表,出现在from后:
select * from [子查询] where [exp]
或者做笛卡尔积
select * from table1,[子查询] where [exp]
排序
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
-- column 可以是前面定义的别名
分页
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
更新
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]
找到对应的行,对响应的列元素进行替换
与插入冲突的两个语法比较:
插入冲突解决实际是查找 + 判断是否成功 + 更新的过程
删除
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
找到相应的行,进行删除
截断
TRUNCATE [TABLE] table_name
- 删除整表的所有数据
- 不经过事务,无法回滚
- 会重置AUTO_INCREMENT为0
插入查询的结果
从一个表中查询出n条数据,将这些数据插入一个表
这两个表可以是同一个
INSERT INTO table_name [(column [, column ...])] SELECT ...
聚合
聚合函数
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
|---|---|
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
- distinct用于将数据去重后再统计
group by
select column1, column2, .. from table group by column [having expr];
显示平均工资低于2000的部门和它的平均工资 :
select avg(sal) as myavg from EMP group by deptno having myavg<2000;
having和where的区别
语法顺序:
where出现在group by前,having出现在group by后
执行顺序:
- where先进行筛选
group by进行分组- 调用前面的聚合函数
- having筛选聚合函数
表的内外链接
内连接
前面我们将两个表进行笛卡尔积,并在后面使用where进行筛选,我们可以将其结合成一个内连接的语法
select 字段 from 表1 inner join 表2 on 连接条件 and 其它条件;
外连接
内连接相当于取两张表的交集,连接条件一定要满足
外连接分为两种
- 左外连接
- 右外连接
如果是左外连接则表示需要完全显式左边的表,如果连接条件没有成立,右表的字段会为空
右连接反之
select 字段名 from 表名1 left/right join 表名2 on 连接条件
索引操作
索引创建
-
表定义时指定:
--列后指定id为主键,name为唯一键 create table user(id int primary key, name varchar(30) unique); --最后指定id为主键,name为唯一键,email为普通索引 create table user(id int, name varchar(30), email varchar(30), primary key(id), unique(name), index(email)); -
创建表后再添加
--主键索引 alter table user add primary key(id); --唯一键索引 alter table user add unique(name); --普通索引(2种) alter table user add index(email); create index idx_name on user(email);
- 主键索引值不能为空,唯一键索引可以为空
-
全文索引的创建及使用
当对文章字段或有大量文字的字段进行检索时,会使用到全文索引。MySQL提供全文索引机制,但是有
要求,要求表的存储引擎必须是MyISAM,而且默认的全文索引支持英文,不支持中文。如果对中文进
行全文检索,可以使用sphinx的中文版(coreseek)- 表定义时创建主键索引:
CREATE TABLE articles ( id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY, title VARCHAR(200), body TEXT, FULLTEXT (title,body) )engine=MyISAM;- 创建表后再添加
alter table articles add fulltext(title,body);使用全文索引
不可如下方式进行模糊匹配
select * from articles where body like ‘%databases%’
正确使用方法:
select * from articles where match(title,body) against('database');
查询索引
- show keys from user;
- show index from user;
- desc user;
删除索引
- 删除主键索引:alter table user drop primary key;
- 删除其它索引:alter table user drop index 索引名;
- 方法二: drop index 索引名 on 表名
视图操作
创建视图:
create view 视图名 as select ...;
- 修改视图对基表数据又影响
- 修改基表对视图数据有影响
- 视图不能添加索引
删除视图:
drop view 视图名;
用户管理
基本操作
查询用户信息:
use mysql;
select host,user,authentication_string from user;
- host:表示这个用户可以从那个主机登陆
- user:用户名
- authentication_string:用户密码通过
password()函数加密之后 - *_priv:用户拥有的权限
创建用户:
create user '用户名'@'登陆主机/ip' identified by '密码'
删除用户:
drop user '用户名'@‘主机名’
修改密码:
set password=password('新的密码');
set password for '用户名'@‘主机名’=password('新的密码');
数据库权限
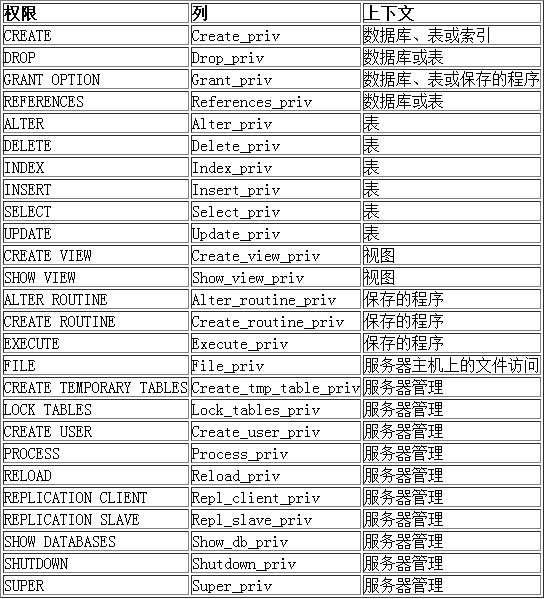
给用户授权
grant 权限列表 on 库.对象 to '用户名'@'登陆位置' [identified by '密码']
- 权限列表:select, delete, create,…;或者
all [privileges] - *.*:代表本数据库的所有对象(表、视图、存储过程)
- 库.*:某个数据库的所有对象
- 如果加了identified,会同时修改密码,如果用户不存在,会直接创建用户
查看权限
show grants for '用户名'@'%';
回收权限
revoke 权限列表 on 库.对象 from '用户名'@'登陆位置';
查看连接情况
show processlist;
使用C语言连接数据库
#include
#include
using namespace std;
int main()
{
cout << "mysql client version: " << mysql_get_client_info() << endl;
// 初始化mysql对象
MYSQL *mfp = mysql_init(nullptr);
if (mfp == nullptr)
{
cerr << "mysql_init error" << endl;
return 0;
}
// 设置字符集(中文编码问题)
mysql_set_character_set(mfp, "utf8");
// 登陆认证:
mfp = mysql_real_connect(mfp, "127.0.0.1", "root", "yue2983383631,", "db_test", 3306, nullptr, 0);
if (mfp == nullptr)
{
cerr << "mysql_real_connect error" << endl;
return 0;
}
// 向数据库发送sql语句
string sql = "select * from account";
int n = mysql_query(mfp, sql.c_str()); // 成功返回0,否则返回1
if (n == 0)
{
cout << "mysql_query success" << endl;
}
else
{
cout << "mysql_query error" << endl;
return 0;
}
// 提取数据库的返回结果
// 初始化结果存储对象
st_mysql_res *res = mysql_store_result(mfp);
if (res == nullptr)
{
return 0;
}
int rows = mysql_num_rows(res); // 获取行数
int fields = mysql_num_fields(res); // 获取列数
MYSQL_FIELD *fname = mysql_fetch_fields(res); // 获取列名(返回一个数组)
// 打印列名
for (int i = 0; i < fields; i++)
{
cout << fname[i].name << "\t|";
}
cout << endl;
// 按行列读取信息
for (int i = 0; i < rows; i++)
{
MYSQL_ROW row = mysql_fetch_row(res); // 获取一行信息,行数会自动迭代
for (int j = 0; j < fields; j++) // 获取当前行的每列信息
{
cout << row[j] << "\t|";
}
cout << endl;
}
cout << endl;
// 释放结果存储对象
mysql_free_result(res);
// 关闭mysql对象
mysql_close(mfp);
}
makefile:
test:test.cc
g++ -o $@ $^ -L/lib64/mysql -lmysqlclient