Oracle 执行计划查看方法汇总及优劣比较

作者 | JiekeXu
来源 |公众号 JiekeXu DBA之路(ID: JiekeXu_IT)
如需转载请联系授权 | (个人微信 ID:JiekeXu_DBA)
大家好,我是 JiekeXu,很高兴又和大家见面了,今天和大家一起来学习 Oracle 执行计划查看方法汇总及优劣比较,欢迎点击上方蓝字关注我,标星或置顶,更多干货第一时间到达!
1)执行计划
执行计划是一条 SQL 语句在 Oracle 数据库中的执行过程或访问路径的描述。如下图所示,是一个比较完整的执行计划示意图。

如上执行计划一般包含三部分,SQL_ID,SQL 文本以及执行计划对应的 plan_hash_value。
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 3gkngf4wda0tz, child number 1
-------------------------------------
select e.empno,e.ename,b.job,d.dname from emp e,dept d, bonus b where
e.deptno=d.deptno and b.job=e.job
Plan hash value: 1315453310其次,则是执行计划主体,主要有内部执行步骤、执行顺序、谓词信息、列信息、预估行数 E-Rows、执行时间 Time、Cardinality、Cost 等。

最后 Note 部分,执行计划的额外补充信息,是否动态采用(dynamic sampling)、是否 Cardinality Feedback、是否 SQL Profile 等等。

2)执行计划主体模块解读
主体 Header
![]()
Id:序号
Operation:当前操作的内容
Rows:当前操作的 Cardinality,Oracle 估计当前操作的返回结果集。
Cost:SQL 执行的代价
Time:Oracle 估计当前操作的时间
Query Block Name

Query Block Name / Object Alias (identified by operation id): --这部分显示的为查询块名和对象别名
-------------------------------------------------------------
1 - SEL$1 --SEL$为select 的缩写,位于块1,相应的还有DEL$,INS$,UPD$等
3 - SEL$1 / DEPT@SEL$1 --DEPT@SEL$1,对应到执行计划中的操作ID为3上,即在表DEPT上的查询,DEPT为别名,下面类同
4 - SEL$1 / DEPT@SEL$1
6 - SEL$1 / EMP@SEL$1
7 - SEL$1 / J@SEL$1Outline Data

Outline Data --提纲部分,这部分将执行计划中的图形化方式以文本形式来呈现,即转换为提示符方式
-------------
/*+
BEGIN_OUTLINE_DATA
IGNORE_OPTIM_EMBEDDED_HINTS
OPTIMIZER_FEATURES_ENABLE('11.2.0.2')
DB_VERSION('11.2.0.2')
ALL_ROWS
OUTLINE_LEAF(@"SEL$1")
INDEX(@"SEL$1" "DEPT"@"SEL$1" ("DEPT"."DEPTNO")) --指明对于DEPT上的访问方式为使用索引
FULL(@"SEL$1" "EMP"@"SEL$1") --指明对于EMP上的访问方式为全表扫描
FULL(@"SEL$1" "J"@"SEL$1")
LEADING(@"SEL$1" "DEPT"@"SEL$1" "EMP"@"SEL$1" "J"@"SEL$1") --指明前导表
USE_MERGE(@"SEL$1" "EMP"@"SEL$1") --使用USE_MERGE提示,即MERGE SORT排序合并连接
USE_HASH(@"SEL$1" "J"@"SEL$1") --使用USE_HASH提示,即HASH连接
END_OUTLINE_DATA
*/Predicate Information

Access
通过某种方式定位了需要的数据,然后读取出这些结果集,叫做 Access。
表示这个谓词条件的值将会影响数据的访问路径(表还是索引)。
Filter
把所有的数据都访问了,然后过滤掉不需要的数据,这种方式叫做 filter 。
表示谓词条件的值不会影响数据的访问路劲,只起过滤的作用。
Column Projection Information
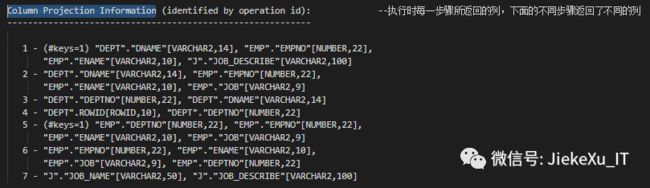
Column Projection Information (identified by operation id): --执行时每一步骤所返回的列,下面的不同步骤返回了不同的列
-----------------------------------------------------------
1 - (#keys=1) "DEPT"."DNAME"[VARCHAR2,14], "EMP"."EMPNO"[NUMBER,22],
"EMP"."ENAME"[VARCHAR2,10], "J"."JOB_DESCRIBE"[VARCHAR2,100]
2 - "DEPT"."DNAME"[VARCHAR2,14], "EMP"."EMPNO"[NUMBER,22],
"EMP"."ENAME"[VARCHAR2,10], "EMP"."JOB"[VARCHAR2,9]
3 - "DEPT"."DEPTNO"[NUMBER,22], "DEPT"."DNAME"[VARCHAR2,14]
4 - "DEPT".ROWID[ROWID,10], "DEPT"."DEPTNO"[NUMBER,22]
5 - (#keys=1) "EMP"."DEPTNO"[NUMBER,22], "EMP"."EMPNO"[NUMBER,22],
"EMP"."ENAME"[VARCHAR2,10], "EMP"."JOB"[VARCHAR2,9]
6 - "EMP"."EMPNO"[NUMBER,22], "EMP"."ENAME"[VARCHAR2,10],
"EMP"."JOB"[VARCHAR2,9], "EMP"."DEPTNO"[NUMBER,22]
7 - "J"."JOB_NAME"[VARCHAR2,50], "J"."JOB_DESCRIBE"[VARCHAR2,100]Note

动态采样(dynamic sampling)是 Oracle CBO 优化器的一种特性。如果相关数据表没有收集过统计信息,又要使用 CBO 的机制,就会引起动态采样。下面来看看执行计划的各种获取方法。
3) 执行计划六脉神剑explain plan for
set linesize 1000
set pagesize 2000
explain plan for select empno,ename,job,dname from emp,dept;
select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 2034389985
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 56 | 1568 | 10 (0)| 00:00:01 |
| 1 | MERGE JOIN CARTESIAN| | 56 | 1568 | 10 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL | DEPT | 4 | 40 | 3 (0)| 00:00:01 |
| 3 | BUFFER SORT | | 14 | 252 | 7 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | EMP | 14 | 252 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------/*
优点 :1. 无须真正执行 SQL,快捷方便。
缺点:1 .没有输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况);
2 . 无法判断处理了多少行;
3 . 无法判断表被访问了多少次。
确实啊,这毕竟都没有真正执行又如何得知真实运行产生的统计信息。
*/set autotrace on
set autot on
select e.empno,e.ename,b.job,d.dname from emp e,dept d, bonus b where e.deptno=d.deptno and b.job=e.job;
Execution Plan
----------------------------------------------------------
Plan hash value: 1315453310
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 40 | 6 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 1 | 40 | 6 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 1 | 40 | 6 (0)| 00:00:01 |
|* 3 | HASH JOIN | | 1 | 27 | 5 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | BONUS | 1 | 6 | 2 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL | EMP | 14 | 294 | 3 (0)| 00:00:01 |
|* 6 | INDEX UNIQUE SCAN | PK_DEPT | 1 | | 0 (0)| 00:00:01 |
| 7 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 13 | 1 (0)| 00:00:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("B"."JOB"="E"."JOB")
6 - access("E"."DEPTNO"="D"."DEPTNO")
Note
-----
- this is an adaptive plan
---优点。1. 可以输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况),
2 . 虽然必须要等语句执行完毕后才可以输出执行计划 , 但是可以有 traceonly 开关来控制返回结果不打屏输出。
---缺陷 1. 必须要等到语句真正执行完毕后,才可以出结果,
2. 无法看到表被访问了多少次。statistics_level=all
步骤 1: alter session set statistics_level=all ;
步骤 2 :在此处执行你的 SQL
步骤 3: select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
alter session set statistics_level=all;
select * from emp where empno=7788;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- ------------------ ---------- ---------- ----------
7788 SCOTT ANALYST 7566 19-APR-87 3000 20
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 2cv6qqj01b9wu, child number 0
-------------------------------------
select * from emp where empno=7788
Plan hash value: 2949544139
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | Reads |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 2 | 2 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 1 | 1 |00:00:00.01 | 2 | 2 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | 1 | 1 |00:00:00.01 | 1 | 1 |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7788)
另注
1. 如果你用 /*+ gather_plan_statistics */ 的方法,可以省略步骤 1 ,直接执行步骤 2 , 3 。
2 . 关键字解读,
Starts 为该 SQL 执行的次数。
E-Rows 为执行计划预计的行数。
A-Rows 为实际、返回的行数。A-Rows 和 E -Rows 做比较,就可以确定哪一步执行计划出了问题。
A-Time 为每一步实际执行的时间(HH:MM:SS.FF),根据这一行可以知道该 SQL 耗时在哪个地方。
Buffers 为每一步实际执行的逻辑读或致性读。Reads 为物理读。
OMem :当前操作完成所有内存工作区(Work Aera)操作所总共使用私有内存(PGA)中工作区的大小,
这个数据是由优化器统计数据以及前一次执行的性能数据估算得出的。
lMem :当工作区大小无法满足操作所需的大小时 , 需要将部分数据写入临时磁盘空间中(如果仅需要写入一次就可以
完成操作 , 就称一次通过,One-Pass;否则为多次通过,Multi-Pass )。该列数据为语旬最后一次执行中,单次写磁盘所需要的内存大小 , 这个是由优化器统计数据以及前一次执行的性能数据估算得出的。User -Mem :语旬最后一次执行中,当前操作所使用的内存工作区大小 , 括号里面为(发生磁盘交换的次数 , 1 次即为One-Pass,大于 1 次则为 Multi-Pass,如果没有使用滋盘,则显示 OPTIMAL)
OMem、 lMem 为执行所需的内存评估值,OMem 为最优执行模式所需内存的评估值, lMem 为 one-pass 模式所需内
存的评估值。0/1/M 为最优/one-pass/multipass 执行的次数。Used-Mem 为消耗的内存.*//*
--优点: 1. 可以清晰地从 ST阻TS 得出表被访问多少次;
2. 可以清晰地从 E-ROWS 和 A-ROWS 中得到预测的行数和真实的行数,从而可以准确判断 Oracle 评估是否准确;
3 . 虽然没有专门的输出运行时的相关统计信息,但是执行计划中的 BUFFERS 就是真实的逻辑读的数值。
--缺陷 1. 必须要等到语句真正执行完毕后,才可以出结果,
2 . 无法控制记录打屏输出,不像 autotrace 有 traceonly 可以控制不将结果打屏输出;
3 . 看不出递归调用的次数,看不出物理读的数值(不过逻辑读才是重点).dbms_xplan.display_cursor
步骤 l select * from table(dbms_xplan.display_cursor('&sql_id')); (该方法是从共享池里得到)
select sql_id,sql_text from v$sql where sql_text like '%7788%' and sql_text not like '%like%';
SQL_ID SQL_TEXT
------------- ---------------------------------------------------------------------------------------------------
5q3mc8n9pcz7a EXPLAIN PLAN SET STATEMENT_ID='PLUS27720015' FOR select * from emp where empno=7788
2cv6qqj01b9wu select * from emp where empno=7788
SYS@JiekeXu> select * from table(dbms_xplan.display_cursor('&sql_id'));
Enter value for sql_id: 2cv6qqj01b9wu
old 1: select * from table(dbms_xplan.display_cursor('&sql_id'))
new 1: select * from table(dbms_xplan.display_cursor('2cv6qqj01b9wu'))
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SQL_ID 2cv6qqj01b9wu, child number 0
-------------------------------------
select * from emp where empno=7788
Plan hash value: 2949544139
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 1 (100)| |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPNO"=7788)
注
1. 还有一个方法, select * from table(dbms_xplan.display_awr('&sql_id'); (这是从 awr 性能视图里获取)
2. 如果有多个执行计划,则可以用类似方法查出 :
select * from table(dbms_xplan.display_cursor(’cyzznbykb509s’,0));
select * from table(dbms_xplan.display_cursor('cyzznbykb509s’,1));
*//*
---优点,l.知道 sql_id 立即可得到执行计划,它和 explain plan for 一样无须执行,
2. 可以得到真实的执行计划。
---缺陷 1. 没有输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况)
2. 无法判断处理了多少行;
3. 无法判断表被访问了多少次。awrsqrpt.sql
步骤 1: @?/rdbms/admin/awrsqrpt.sql
步骤 2: 选择你要的断点( begin snap 和 end·snap)
步骤 3: 输入你的 sql_id
select max(snap_id) from dba_hist_snapshot;
Exec dbms_workload_repository.create_snapshot(); --手动生成快照
@?/rdbms/admin/awrsqrpt.sql
10046 trace
步骤 1: alter session set events '10046 trace name context forever,level 12'; (开启跟踪)
步骤 2 执行 SQL 语旬
步骤 3: alter session set events '10046 trace name context off'; (关闭跟踪)
步骤 4 找到跟踪后产生的文件
步骤 5: tkprof trc 文件 目标文件 sys=no sort=prsela,exeela , fchela (格式化命令)步骤 4:
select d.value || '/'
|| LOWER(RTRIM(i.INSTANCE,CHR(0)))
||'_ora_'
|| p.spid
||'.trc' trace_file_name
from (select p.spid
from v$mystat m, v$session s, v$process p
where m.statistic#=1 and s.sid=m.sid and p.addr=s.paddr) p,
(select t.INSTANCE
FROM v$thread t, v$parameter v
WHERE v.name='thread'
AND(v.VALUE=0 OR t.thread#=to_number(v.value)) ) i,
(select value from v$parameter where name='user_dump_dest') d;
tkprof /oracle/app/oracle/diag/rdbms/PROD/PRODSTB/trace/PROD_ora_7238.trc /tmp/10046_sql.log sys=no sort=prsela,exeela,fchela
cat /tmp/10046_sql.log
********************************************************************************
OVERALL TOTALS FOR ALL NON-RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 2 0.00 0.00 0 0 0 0
Execute 2 0.00 0.00 0 0 0 0
Fetch 2 1.08 1.78 9568 10117 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 6 1.09 1.79 9568 10117 0 1
Misses in library cache during parse: 1
Elapsed times include waiting on following events:
Event waited on Times Max. Wait Total Waited
---------------------------------------- Waited ---------- ------------
SQL*Net message to client 3 0.00 0.00
SQL*Net message from client 3 31.01 55.20
db file sequential read 130 0.01 0.13
db file scattered read 274 0.03 1.07
OVERALL TOTALS FOR ALL RECURSIVE STATEMENTS
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 0 0.00 0.00 0 0 0 0
Execute 0 0.00 0.00 0 0 0 0
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 0 0.00 0.00 0 0 0 0
Misses in library cache during parse: 0
2 user SQL statements in session.
0 internal SQL statements in session.
2 SQL statements in session.
********************************************************************************/*
---优点:1. 可以看出 SQL 语旬对应的等待事件,
2. 如果 SQL 语旬中有函数调用,函数中又有 SQL ,将会被列出,无处遁形,
3.可以方便地看出处理的行数,产生的物理逻辑读,
4 . 可以方便地看出解析时间和执行时间 i
5. 可以跟踪整个程序包。
---缺陷 1. 步骤烦琐,比较麻烦;
2. 无法判断表被访问了多少次,
3. 执行计划中的谓词部分不能清晰地展现出来。
*/
4) 如何选择
选择时一般遵循以下规则:
1.如果 sql 执行很长时间才出结果或返回不了结果,用方法1:explain plan for
2.跟踪某条 sql 最简单的方法是方法1:explain plan for,其次是方法2:set autotrace on
3.如果相关查询某个 sql 多个执行计划的情况,只能用方法4:dbms_xplan.display_cursor 或方法6:awrsqrpt.sql
4.如果 sql 中含有函数,函数中有含有 sql,即存在多层调用,想准确分析只能用方法5:10046 追踪
5.想法看到真实的执行计划,不能用方法1:explain plan for 和方法 2:set autotrace on
6.想要获取表被访问的次数,只能用方法 3:statistics_level = all
5) 获取执行计划的方法汇总
| 获取执行计划的方法 | ||||
|---|---|---|---|---|
| 方法 | 获取步骤 | 优点 | 缺点 | 应用场景 |
| explain plan for | 步骤1:explain plan for /跟上你要执行的SQL/ 步骤2:select * from table(dbms_xplan.display()); | 无需真正执行,快捷方便 | 1.没有输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况); 2.无法判断处理了多少行;3.无法判断表被访问了多少次 | 如果某SQL执行很长时间才出结果或返回不了结果 |
| set autotrace on | 步骤1:set autotrace on 步骤2:在此处执行你的SQL | 1.可以输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况);2.虽然必须要等语句执行完毕后才可以输出执行计划,但是可以有traceonly开关来控制返回结果不打屏输出 | 1.必须要等到语句真正执行完毕后,才可以出结果;2.无法看到表被访问了多少次 | 想粗略知道recursive calls递归调用次数的方法用这个,详细用10046trace 方法 |
| statistics_level=all | 步骤1:alter session set statistics_level=all ; 步骤2:在此处执行你的SQL 步骤3:select * from table(dbms_xplan.display_cursor(null,null,'allstats last')); | 1.可以清晰地从STARTS得出表被访问多少次;2.可以清晰的从E-ROWS和A-ROWS中得到预测的行数和真实的行数,从而可以准确判断Oracle评估是否准确。3.虽然没有专门的输出运行时的相关统计信息,但是执行计划中的BUFFERS就是真实的逻辑读的数值 | 1.必须要等到语句真正执行完毕后,才可以出结果。2.无法控制输出记录展现与否,而autotrace有 traceonly 可以控制不将输出记录打屏。 3.看不出递归调用的次数,看不出物理读的数值 | 要想获取表被访问的次数,只能使用方法3 |
| dbms_xplan.display_cursor | select * from table(dbms_xplan.display_cursor('&sq_id')); (该方法是从共享池里得到) | 1.知道sql_id立即可得到执行计划,和explain plan for 一样无需执行;2.可以得到真实的执行计划 | 1.没有输出运行时的相关统计信息(产生多少逻辑读,多少次递归调用,多少次物理读的情况);2.无法判断处理了多少行;3.无法判断表被访问了多少次 | 观察某条SQL有多条执行计划的情况 |
| 事件10046 trace 跟踪 | 步骤1:alter session set events '10046 trace name context forever,level 12'; (开启跟踪) 步骤2:执行你的语句 步骤3:alter session set events '10046 trace name context off'; (关闭跟踪) 步骤4:找到跟踪后产生的文件 步骤5:tkprof trc文件 目标文件 | 1.可以看出SQL语句对应的等待事件 2.如果SQL语句中有函数调用,SQL中有SQL,都将会被列出,无处遁形;3.可以方便的看出处理的行数,产生的物理逻辑读;4.可以方便地看出解析时间和执行时间;5.可以跟踪整个程序包 | 1.步骤繁琐,比较麻烦;2.无法判断表被访问了多少次;3.执行计划中的谓词部分不能清晰的展现出来 | 如果SQL中含函数,函数中又套SQL等,即存在多层调用,想准确分析只能用该方法 |
| awrsqrpt.sql | 步骤1:@?/rdbms/admin/awrsqrpt.sql 步骤2:选择你要的断点(begin snap 和end snap) 步骤3:输入你的sql_id | 可以方便地看到多个执行计划 | 获取的过程比较麻烦 | 想观察某条SQL多执行计划用该方法 |
6) SQLHC
和 explain plan for 一样的还可以使用 PL/SQL developer 工具的 F5 键也可查看执行计划,SQL Monitor 工具也可以查看,当然更高级的 sqlhc 工具,这里顺便说说 sqlhc 工具,这个工具收集的信息非常全面,值得大家尝试。
上传 sqlhc 文件,公众号后台回复【sqlhc】获取,输入 T 和 sqlid 即可生成。sqlhc 是 SQL health check的简称,能够收集sql相关的表、索引、统计信息、优化器参数、SQL执行情况、等待事件等信息,可以帮你检查SQL存在的问题并优化 SQL。
执行方法:sqlplus / as sysdba
SQL> @/home/oracle/tmp/sqlhc.sql T 9a4tv1dduu9u4
或者
SQL> @/home/oracle/tmp/sqlhc.sql
Parameter 1:
Oracle Pack License (Tuning, Diagnostics or None) [T|D|N] (required)
Enter value for 1: T
PL/SQL procedure successfully completed.
Parameter 2:
SQL_ID of the SQL to be analyzed (required)
Enter value for 2: 9a4tv1dduu9u4 <----输入 sql_id 等待 5 分钟左右有可能更长或者更短(根据 AWR 保存周期、字典表大小不同相差较大,一般系统应该在 5 分钟以内能够完成),对数据库没有影响。执行过程有 log,也有屏显。执行过程会 insert 数据到 plan_table 表,执行结束会 rollback。
结束后生成的文件名以 sqlhc 开头,依次是日期、时间、sql_id。类似这样:sqlhc_20211125_1810_9a4tv1dduu9u4.zip
其中 4 个 html 文件和 log.zip 是通常存在的。
10053 trace 文件的生成需要 11.2 版本以上,sql_id 仍在 library cache 内的情况下。
如果 sql_monitor.zip 也包含在 sqlhc 压缩包内,说明你的 SQL 执行时间超过了 5s,或者是并行的 SQL,而且收集 sqlhc 时仍保留在 sql monitor 的内存。sql monitor 对分析 sql 执行计划有很大帮助,如果遇到问题收集 sqlhc 信息及时,就非常有可能收集到 sql monitor 文件。如果一个 sql 执行完后超过半小时没有收集 sqlhc,sql monitor 信息就就非常有可能被刷出内存。
主要分析的的 3 个 html 文件是:
*_health_check.html
*_diagnostics.html
*_execution_plan.html内容非常丰富,可以多收集一些看看,那么今天就到这里啦。
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
❤️ 欢迎关注我的公众号,一起学习新知识!!!————————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
腾讯云:https://cloud.tencent.com/developer/user/5645107
————————————————————————————
Oracle 表碎片检查及整理方案
OGG|Oracle GoldenGate 基础2021 年公众号历史文章合集整理
2020 年公众号历史文章合集整理
我的 2021 年终总结和 2022 展望Oracle 19c RAC 遇到的几个问题
利用 OGG 迁移 Oracle11g 到 19COGG|Oracle GoldenGate 微服务架构Oracle 查询表空间使用率超慢问题一则国产数据库|TiDB 5.4 单机快速安装初体验Oracle ADG 备库停启维护流程及增量恢复Linux 环境搭建 MySQL8.0.28 主从同步环境