系列七、Redis持久化
一、是什么
将内存中的数据写入到硬盘的过程。
二、持久化方式
RDB、AOF
2.1、RDB(Redis Database)
2.1.1、概述
在指定的时间间隔,执行数据集的时间点快照。实现类似照片记录效果的方式,就是把某一时刻的数据和状态以文件的形式写到磁盘上,也就是快照。这样一来即使机器因故障宕机,快照文件也不会丢失,数据的可靠性就得到了保证。这个快照文件就被称为RDB文件(dump.rdb)。
2.1.2、能干嘛
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot内存快照,它恢复时再将硬盘中的数据直接读回到内存中。
一锅端:Redis的数据都在内存中,保存备份时它执行的是全量快照,也就是说,把内存中的所有数据都记录到磁盘中,一锅端。
RDB保存的是dump.rdb文件。

2.1.3、触发时机
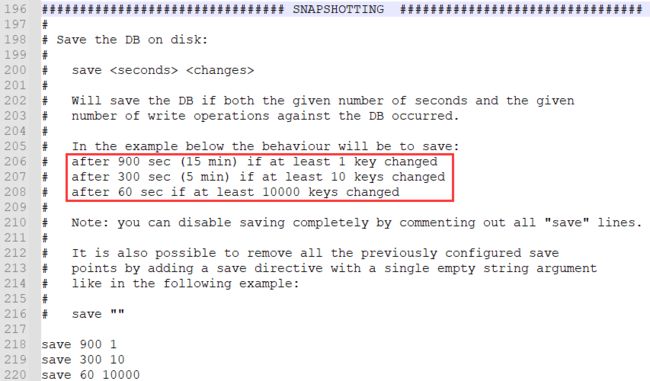
自动触发:在redis.conf配置文件中的 SNAPSHOTTING 下配置save参数,来触发redis的RDB持久化条件,格式:save m n,表示m秒内数据集存在n次修改,自动触发bgsave
save 900 1 :每隔900s(15min),如果有超过1个key发生变化,就写一份新的RDB文件
save 300 10 :每隔300s(5min),如果有超过10个key发生变化,就写一份新的RDB文件
save 60 10000 : 每隔60s(5min),如果有超过10000个key发生变化,就写一份新的RDB文件
2.1.4、案例演示(自动触发)
步骤:
(1)修改redis.conf SNAPSHOTTING/save 配置
(2)本次案例5秒2次修改,即触发自动保存

(3)修改dump文件的保存路径
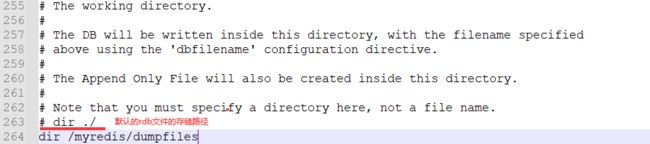
注意事项:/myredis/dumpfiles文件夹需要提前在 / 目录建好,命令为:mkdir -p myredis/dumpfiles
(4)修改dump文件名称

(5)重启redis服务
(6)触发备份
①初始条件 /myredis/dumpfiles 目录没有任何rdb文件
②5s内执行了两次set操作,/myredis/dumpfiles 目录的文件情况
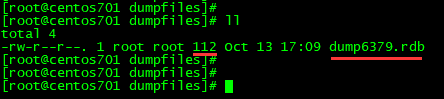
③5s内只执行一次set操作,观察/myredis/dumpfiles 目录的文件情况
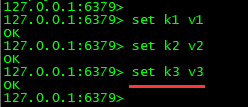
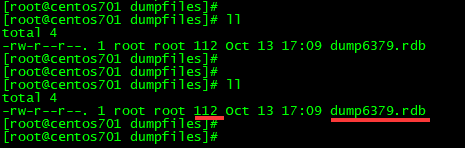
(7)恢复
①备份 /myredis/dumpfiles 目录的 dump6379.rdb文件,指令:cp dump6379.rdb dump6379.rdb.bak

②清空当前库,flushdb,观察/myredis/dumpfiles 目录的文件情况
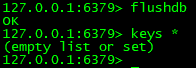

结论:执行情况库的操作时,也会生成dump.rdb文件
③删除/myredis/dumpfiles 目录的dump6379.rdb文件
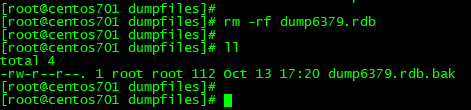
④关闭redis服务,观察/myredis/dumpfiles 目录的文件情况

结论:关闭redis服务时,也会生成dump.rdb文件
⑤再次删除 /myredis/dumpfiles 目录的dump6369.rdb文件,并拷贝dump6369.rdb.bak文件进行恢复
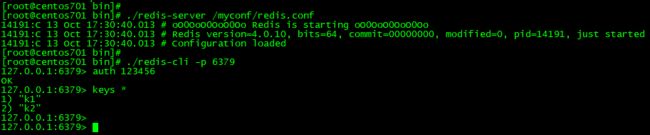
⑥重启redis服务,观察数据是否恢复
⑦注意事项
不可以把备份文件dump.rdb文件和生成redis服务器放在同一台机器上,必须分开各自存储!以防生产机物理损坏后,备份文件也挂了,那就无法恢复了。
2.1.5、案例演示(手动触发)
实现方式:bgsave、save
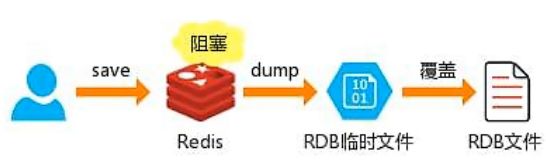
bgsave(默认):redis会在后台异步进行快照操作,不阻塞快照,同时还可以响应客户端的请求,该触发方式会fork一个子进程,由子进程在后台完成持久化过程,这就允许主进程同时可以修改数据。
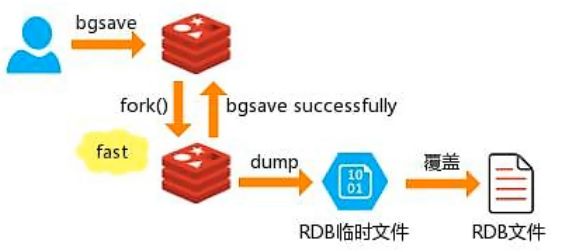
save:在主程序中执行会阻塞当前redis服务器,直到持久化工作完成,在执行save命令期间,redis不能处理其他命令,线上禁止使用
2.1.6、查看最近一次快照保存时间
lastsave:得到一串时间戳
date -d @时间戳:格式化时间戳,年月日 星期 十分秒
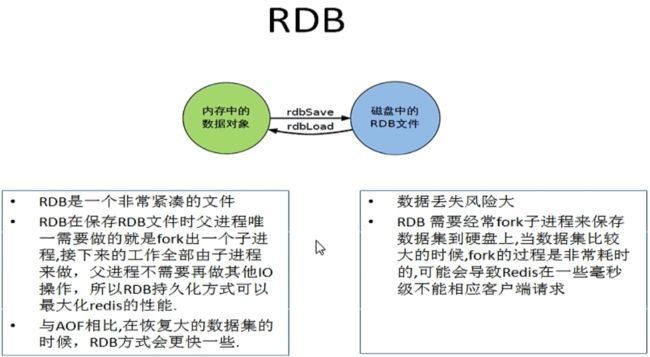
2.1.7、RDB的优势
- 适合大规模的数据恢复
- 按照业务定时备份
- 对数据完整性和一致性要求不高
- RDB文件在内存中的加载速度要比AOF快得多
2.1.8、RDB的劣势
- 在一定间隔时间做一次备份,所以如果redis意外宕机的话,就会丢失从当前至最近一次快照期间的数据
- 由于同步是全量同步,如果数据量太大的话,会导致大量IO,严重影响服务器的性能
- RDB依赖于主进程的fork进程,即子进程,在更大的数据集中,这可能会导致服务请求的瞬间延迟
- fork的时候,内存中的数据被克隆了一份,将会出现大致2倍的膨胀性,需要考虑
2.1.9、如何检查修复dump.rdb文件
redis-check-rdb /myredis/dumpfiles/dump6379.rdb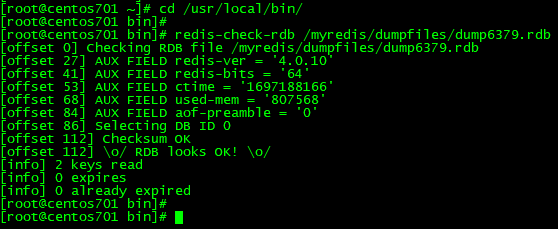
2.1.10、什么时候会触发RDB快照
- 配置文件中默认的快照配置
- 手动执行 save/bgsave 命令
- 执行 flushdb/flushall 命令时也会产生dump.rdb文件,但是里面是空的,无意义
- 执行shutdown且没有设置开启AOF持久化
- 主从复制时,主节点自动触发
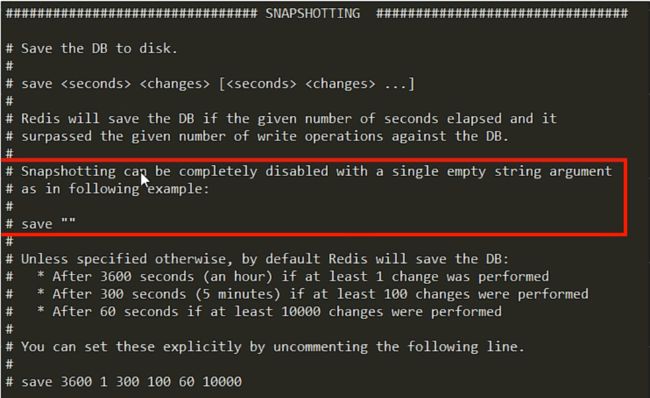
2.1.11、如何禁用快照
方式一:动态停止所有RDB保存规则
redis-cli config set save ""方式二:快照禁用
2.1.12、RDB优化配置项详解
redis.conf SNAPSHOTTING 模块
(1)save
(2)dbfilename
(3)dir
(4)stop-writes-on-bgsave-error
默认yes(推荐),如果配置成no,表示你不在乎数据不一致或者有其他的手段发现和控制这种不一致,那么在快照写入失败时,也能确保redis继续接受新的写请求。
(5)rdbcompression
默认yes(推荐),对于存储到磁盘中的快照,可以设置是否进行压缩存储,如果是的话,redis会采用LZF算法进行压缩,如果你不想消耗CPU的性能来进行压缩的话,可以设置为no,关闭此功能,
(6)rdbchecksum
默认yes(推荐),在存储快照后,还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大性能的提升,可以关闭此功能。
(7)rdb-del-sync-files(redis7及以上版本支持)
在没有持久性的情况下,删除复制中使用的RDB文件启用,默认情况下no,此选项是禁用的。
2.1.13、小总结
2.2、AOF(Append Only File)
2.2.1、概述
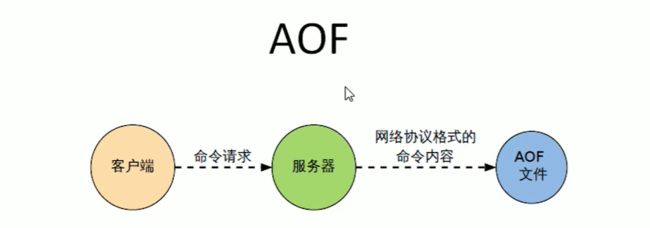
以日志的形式来记录每个写操作,将redis执行过程中的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,redis启动之初会读取该文件重新构建数据,换言之,redis重启的话就根据日志文件的内容将写指令从前到后执行一次,以完成数据的恢复工作。默认情况下,redis是没有开启AOF的,开启AOF功能需要设置配置:appendonly yes
2.2.2、AOF持久化工作流程
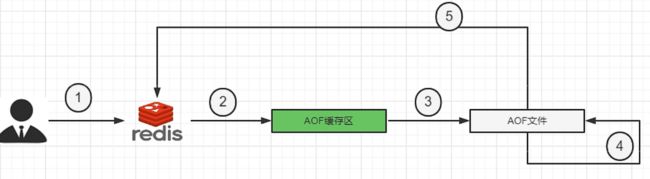
第一步:Client作为命令的来源,会有多个源头以及源源不断的请求命令;
第二步:在这些命令到达Redis Server后并不是直接写入AOF文件,而是将这些命令先放入AOF缓存中进行保存。这里AOF缓冲区实际上是内存中的一片区域,存在的目的是当这些命令达到一定量后再写入磁盘,避免频繁的IO操作;
第三步:AOF缓冲会根据AOF缓冲区同步文件的三种回写策略将命令写入磁盘上的AOF文件;
第四步:随着写入AOF内容的增加,为避免文件膨胀,会根据规则进行命令的合并(又称AOF重写),从而起到AOF文件压缩的目的
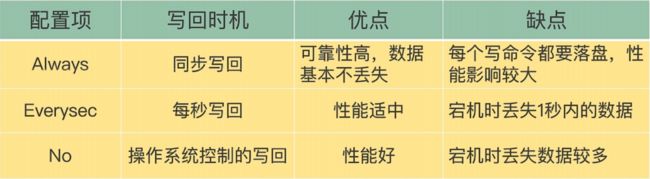
2.2.3、三种回写策略
redis.conf/appendfsync
always:同步写回,每个写命令执行完后,立刻同步地将日志写回磁盘
everysec(默认):每秒写回,每个写命令执行完,只是先将日志写到AOF文件的内存缓冲区,每隔1s把缓冲区的内容写入磁盘
no:操作系统控制写回,每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
2.2.4、AOF案例演示
#1、删除/myredis目录的子文件夹dumpfiles
#2、拷贝/myredis目录的redis.conf文件
[root@centos701 myconf]# cp redis.conf redis_aof.conf
#3、修改redis_aof.conf文件配置,修改项如下
dir /myredis
appendonly no ==> appendonly yes
#4、重启redis服务
#5、执行操作,观察/myredis目录文件的变化情况
#6、flushdb,关闭redis服务,模拟机器宕机,删除/myredis目录的dump6379.rdb文件(防止干扰),然后再重新启动redis服务,观察数据是否恢复
#7、结果
数据没有恢复
#8、原因
执行flushdb指令时,该操作也会被记录在appenonly.aof文件中,所以当重新启动redis服务时,虽然将写命令重新执行了一遍,但是最后又执行了一次flushdb,所以重启之后数据还是空的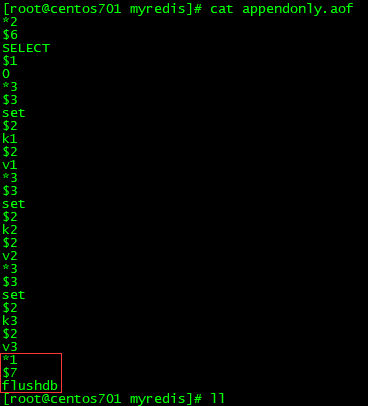
#9、解决
删除appendonly.aof文件中,flushdb相关指令,然后再重新启动redis服务,即可恢复数据
2.2.5、appendonly.aof和dump.rdb文件的加载顺序
问题:当前redis_aof.conf文件中既配置了rdb方式的持久化,又配置了aof方式的持久化,那么当redis服务出现宕机需要进行数据恢复时,优先加载哪个配置文件?
# 思路
编辑当前appendonly.aof文件,在末尾随便填写一些"乱七八糟"的数据,破坏该文件,然后重新启动redis服务,接着使用redis-cli客户端工具进行连接,观察能否连接上,如果能够连接的上,说明redis服务启动时,优先加载的是rdb文件,否则说明优先加载的是appendonly.aof文件# 1、破坏appendonly.aof文件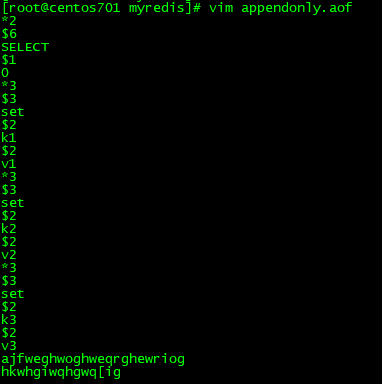
# 2、重启redis服务
# 3、使用redis-cli客户端连接
# 4、结果
连接被拒绝
# 5、结论
redis服务宕机,进行数据恢复时,优先加载的文件是appendonly.aof文件2.2.6、aof文件的修复
场景:当开启aof的持久化方式后,默认情况下,会每隔1s种记录一次写操作,极端情况下,在这1s钟会出现数据没有写完,即只写了一部分数据的情况,这种情况下,如何修复appendonly.aof文件?可以使用redis给我们提供的redis-check-aof指令进行修复。
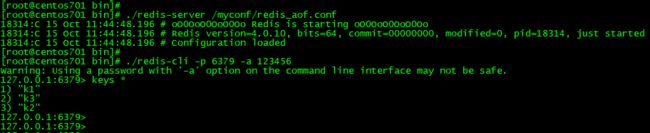
./redis-check-aof --fix /myredis/appendonly.aof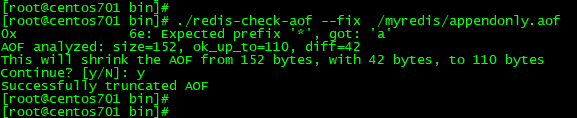
2.2.7、Rewrite
是什么
AOF采用文件追加的方式,文件会越来越大,为了避免出现此种情况,新增加了重写机制,当AOF文件的大小超过了所设定的阈值时,redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集,可以使用命令 bgrewriteaof。
重写原理
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件,最后再rename),遍历新进程的内存中的数据,每条记录有一条set语句,重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一份新的aof文件,这点儿和快照有点类似。
触发机制
redis会记录上次重写时的aof文件大小,默认配置是当aof文件的大小是上次rewrite后大小的一倍,且文件大于64MB时触发。

2.2.8、优势
每秒同步(appendfsync always):同步持久化,每次发生数据变更会被立即记录到磁盘,性能较差但是数据完整性比较好
每修改同步(appendfsync everysec):异步操作,每秒记录,如果1s内宕机,会丢失这1s中的数据
不同步(appendfsync no):从不同步
2.2.9、劣势
- 对于相同数据集的数据而言,aof文件要远大于rdb文件,恢复速度慢于rdb
- aof运行效率要慢于rdb,每秒同步策略效率较好,不同步效率和rdb相同
2.2.10、小总结

三、怎么选择
3.1、分析
RDB持久化方式:能够在指定的时间间隔内对你的数据进行快照存储
AOF持久化方式:记录每次对服务器的写操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,aof命令以redis协议追加每次的写操作至文件末尾,redis还能对AOF文件进行后台重写,使得AOF文件的大小不至于过大
3.2、只做缓存
如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式
3.3、同时开启两种持久化方式
在这种情况下,当redis服务重启的时候会优先加载aof文件来恢复原始数据,因为在通常情况下aof文件保存的数据集要比rdb文件保存的数据集更完整。rdb的数据不实时,同时使用两者时服务器也只会找aof文件。那要不要只使用aof文件呢?作者建议不要,因为rdb文件更适合于备份数据库(aof文件不断变化,不好备份),建议留着作为一个万一的手段。
3.4、性能建议
因为rdb文件只用作后备用途,建议只在slave上持久化rdb文件,而且只要15分钟备份一次就够了,只保留save 900 1这条规则即可。
如果开启了aof的持久化,好处是在恶劣情况下也只会丢失不会超过2s的数据,启动脚本比较简单,只加载自己的aof文件就可以了。代价是带来了持续的IO,二是aof rewrite过程中产生的新数据写到新文件造成的阻塞几乎是不可避免的,只要硬盘许可,应该尽量减少aof rewrite的频率,aof重写的基础大小默认为64MB太小了,可以设置到5GB以上。默认超过原大小100%时重写。
如果没有开启aof的持久化,仅靠Master-Slave Replication实现高可用性也可以。能省掉一大笔IO,也减少了rewrite时带来的系统波动。代价是如果Master、Slave同时宕机,将会丢失十几分钟的数据,启动脚本也要比较Master/Slave中的rdb文件,加载最新的那个。新浪微博采用的就是这种架构。