python数据分析——数据预处理
数据预处理
- 前言
- 一、熟悉数据
-
- 1.1 数据表的基本信息查看
- 1.2查看数据表的大小
- 1.3数据格式的查看
- 1.4查看具体的数据分布
- 二、缺失值处理
-
- 2.1缺失值检查
- 2.2缺失值删除
- 2.3缺失值替换/填充
- 三、重复值处理
-
- 3.1发现重复值
- 四、异常值的检测和处理
-
- 4.1检测异常值
- 4.2处理异常值
- 五、数据类型的转化
- 六、索引设置
-
- 6.1添加索引
- 6.3重命名索引
- 七、其他
-
- 7.1大小写转换
- 7.2数据修改与替换
- 7.2数据修改与替换
- 7.3数据删除
- 总结
前言
数据预处理是数据分析和挖掘过程中至关重要的一步,其主要目的是将原始数据转换为可用于分析和建模的可靠数据。
一、熟悉数据
1.1 数据表的基本信息查看
【例】餐饮企业的决策者想要了解影响餐厅销量的一些因素,如天气的好坏、促销活动是否能够影响餐厅的销量,周末和非周末餐厅销量是否有大的差别。餐厅收集的数据存储在sales.csv中,前五行的数据如下所示。请利用Python查看数据集的基本信息。
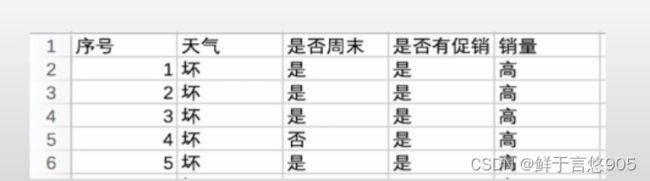
关键技术:使用info()方法查看数据基本类型。
在该例中,首先使用pandas库中的read_csv方法导入sales.csv文件,然后使用info()方法,查看数据的基本信息,代码及输出结果如下:
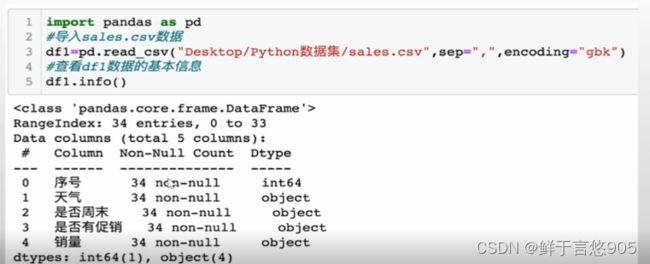
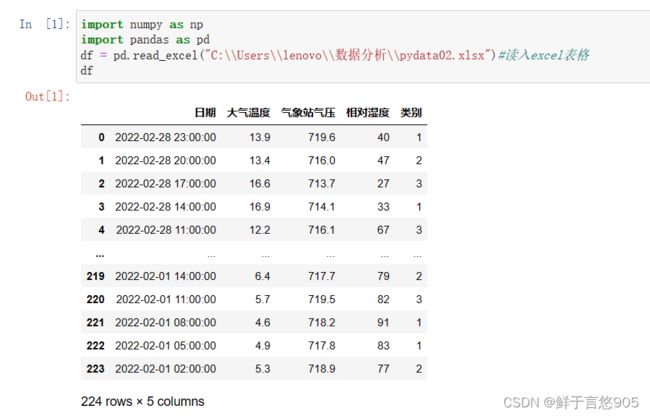
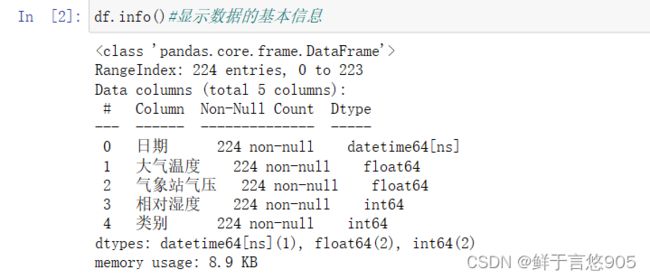
1.2查看数据表的大小
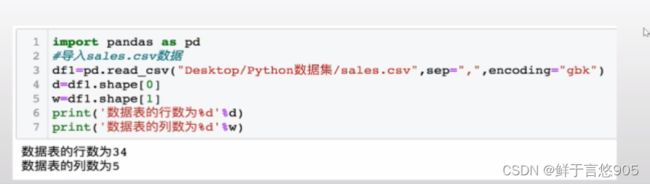
【例】请利用python查看上例中sales.csv文件中的数据表的大小,要求返回数据表中行的个数和列的个数。
关键技术:使用pandas库中DataFrame对象的shape()方法。

1.3数据格式的查看
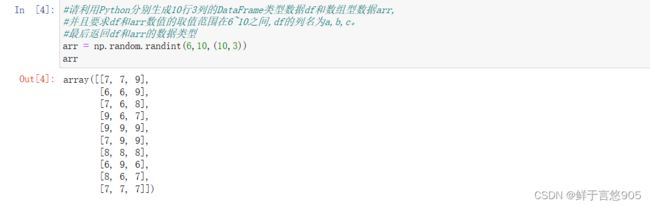
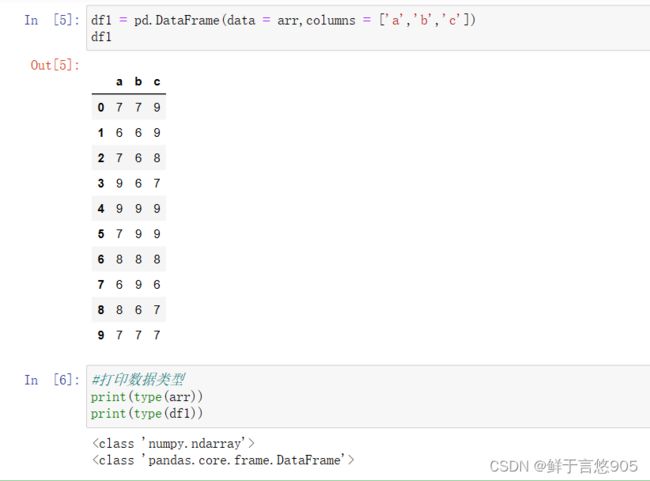
【例】请利用Python分别生成10行3列的DataFrame类型数据df和数组型数据arr,并且要求df和arr数值的取值范围在6~10之间,df的列名为a,b,c。最后返回df和arr的数据类型。
关键技术:type()方法。
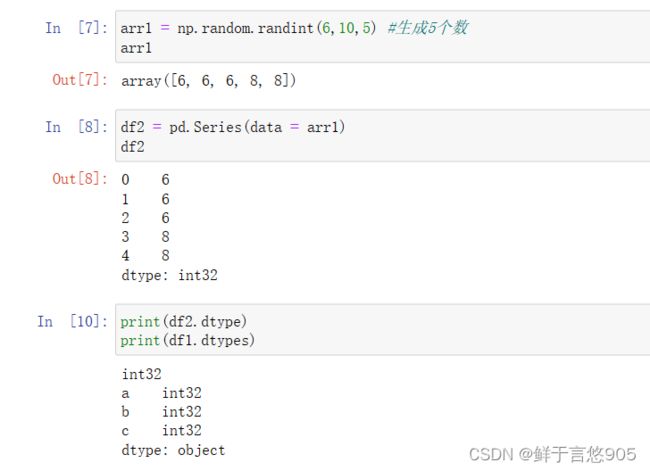
【例】同样对于前一个例题给定的数据文件,读取后请利用Python查看数据格式一是字符串还是数字格式。
关键技术: dtype属性和dtypes属性
在上例代码的基础上,对于series数据可以用dtype查看,对于dataframe数据可以用dtypes查看,程序代码如下所示:
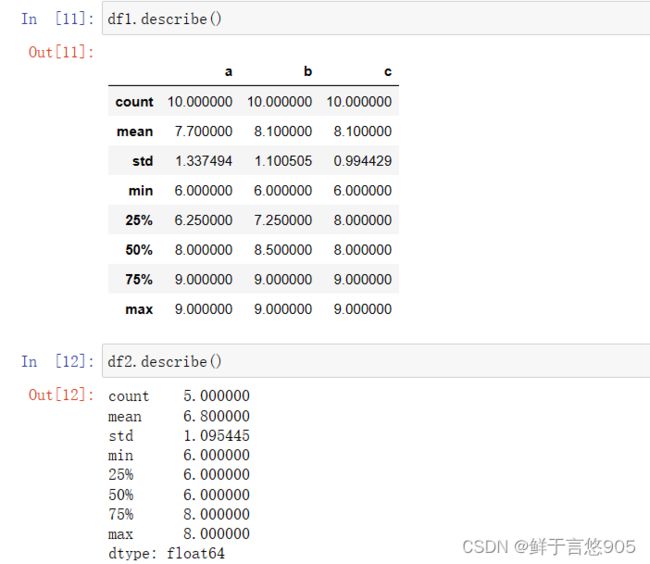
1.4查看具体的数据分布
在进行数据分析时,常常需要对对数据的分布进行初步分析,包括统计数据中各元素的个数,均值、方差、最小值、最大值和分位数。
关键技术: describe()函数。在做数据分析时,常常需要了解数据元素的特征,describe()函数可以用于描述数据统计量特征,其返回值count表示、mean表示数据的平均值、std表示数据的标准差、min表示数据的最小值、max表示数据的最大值、25%、50%、75%分别表示数据的一分位、二分位、三分位数。
count : 计数
mean :平均值
std : 标准差
min : 最小值
25% 一分位
50% 二分位
75% 三分位
max 最大值
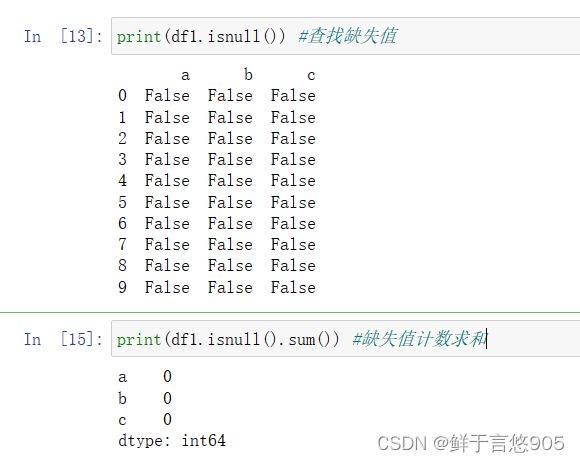
二、缺失值处理
2.1缺失值检查
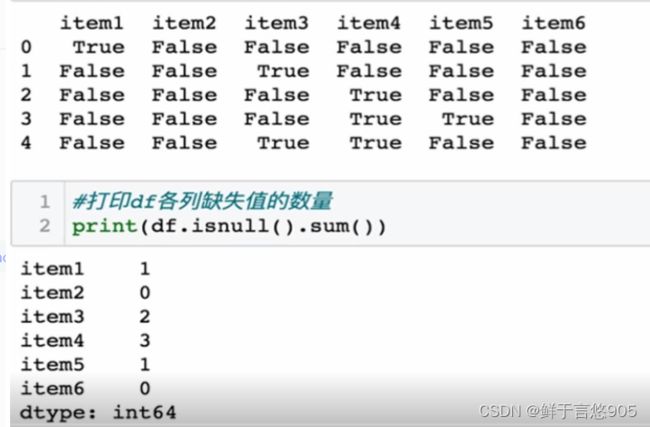
【例】若某程序员对淘宝网站爬虫后得到原始数据集items.csv,文件内容形式如下所示。请利用Python检查各列缺失数据的个数,并汇总。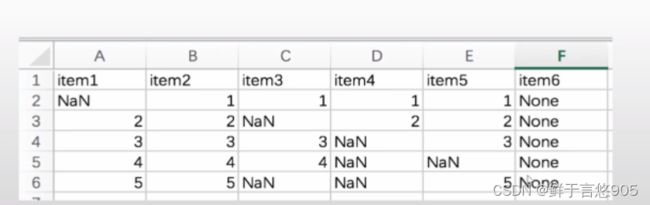
关键技术: isnull0方法。isnull()函数返回值为布尔值,如果数据存在缺失值,返回True;否则,返回False。
2.2缺失值删除
【例】假设对于上述items.csv数据集检查完缺失值后,要对缺失值进行删除处理。请用Python完成上述工作。
关键技术: dropna()方法。dropna()方法用于删除含有缺失值的行。
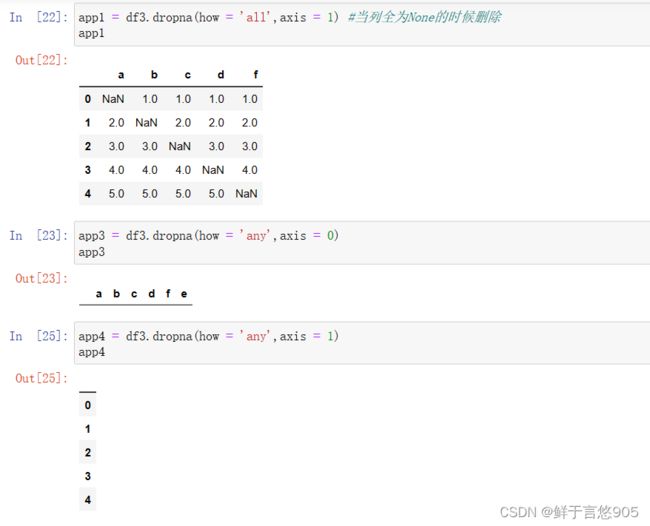
【例】当某行或某列值都为NaN时,才删除整行或整列。这种情况该如何处理?
关键技术: dropna()方法的how参数。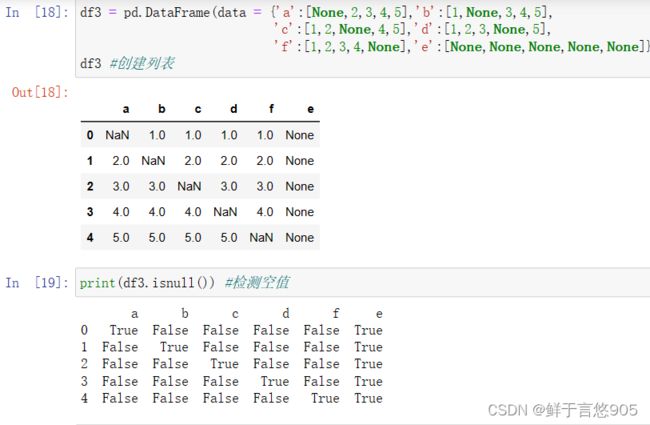

【例】当某行有一个数据为NaN时,就删除整行和当某列有一个数据为NaN时,就删除整列。遇到这两周种情况,该如何处理?
关键技术: dropna)方法的how参数dropna(how= ‘any’ )。
2.3缺失值替换/填充
对于数据中缺失值的处理,除了进行删除操作外,还可以进行替换和填充操作,如均值填补法,近邻填补法,插值填补法,等等。本小节介绍填充缺失值的fillna0方法。
本小节后续案例中所用的df数据如下,在案例中将不再重复展示。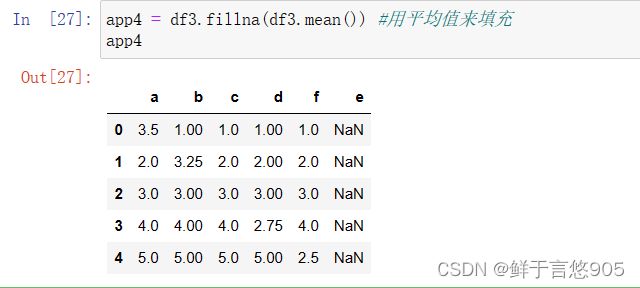
【例】使用近邻填补法,即利用缺失值最近邻居的值来填补数据,对df数据中的缺失值进行填补,这种情况该如何实现?
关键技术: fillna()方法中的method参数。
在本案例中,可以将fillna(方法的method参数设置为bfill,来使用缺失值后面的数据进行填充。代码及运行结果如下:
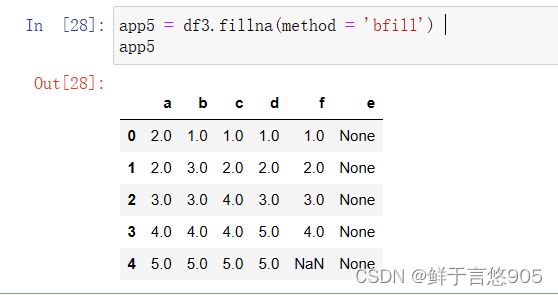
【例】若使用缺失值前面的值进行填充来填补数据,这种情况又该如何实现?
本案例可以将fillna()方法的method参数设置设置为ffill,来使用缺失值前面的值进行填充。代码及运行结果如下:在这里插入图片描述
【例】若使用缺失值前面的值进行填充来填补数据,这种情况又该如何实现?
本案例可以将fillna()方法的method参数设置设置为ffill,来使用缺失值前面的值进行填充。代码及运行结果如下:
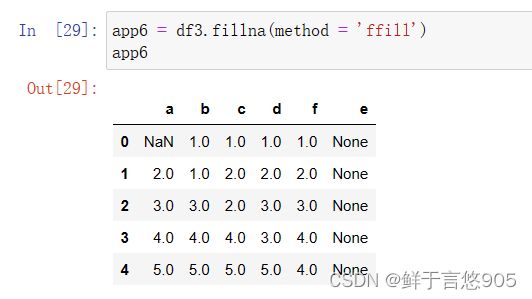
这里的前后指的是上下
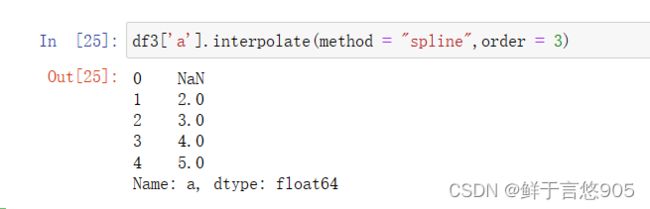
【例】请利用二次多项式插值法对df数据中item2列的缺失值进行填充。
关键技术: interpolate方法及其order参数。
在该案例中,将interpolate方法中的参数order设置为2即可满足要求。具体代码及运行结果如下: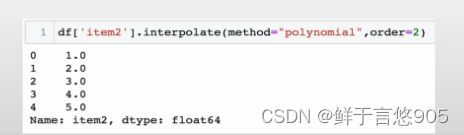
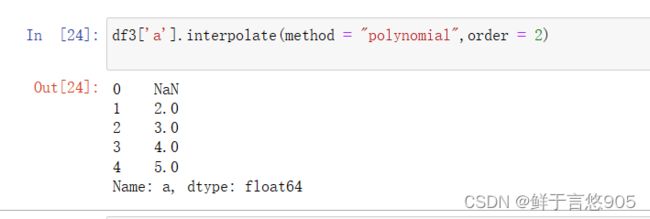
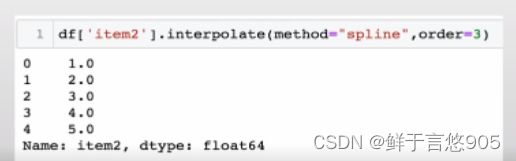
【例】请使用Python完成对df数据中item2列的三次样条插值填充。
关键技术:三次样条插值,即利用一个三次多项式来逼近原目标函数,然后求解该三次多项式的极小点来作为原目标函数的近似极小点。
在该案例中,将interpolate方法的method参数设置为spline,将order参数设置为3,具体代码及运行结果如下:
三、重复值处理
3.1发现重复值
在数据的采集过程中,有时会存在对同一数据进行重复采集的情况,重复值的存在会对数据分析的结果产生不良影响,因此在进行数据分析前,对数据中的重复值进行处理是十分必要的。本节主要从重复值的发现和处理两方面进行介绍。
本节各案例所用到的df数据如下,在各案例的代码展示中将不再重复这部分内容。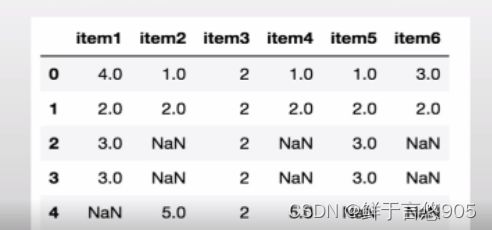
【例】请使用Python检查df数据中的重复值。
关键技术: duplicated方法。
利用duplicated()方法检测冗余的行或列,默认是判断全部列中的值是否全部重复,并返回布尔类型的结果。对于完全没有重复的行,返回值为False。对于有重复值的行,第一次出现重复的那一行返回False,其余的返回True。本案例的代码及运行结果如下: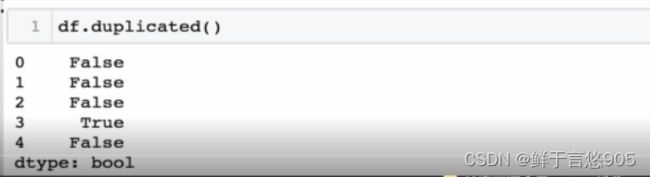

四、异常值的检测和处理
4.1检测异常值
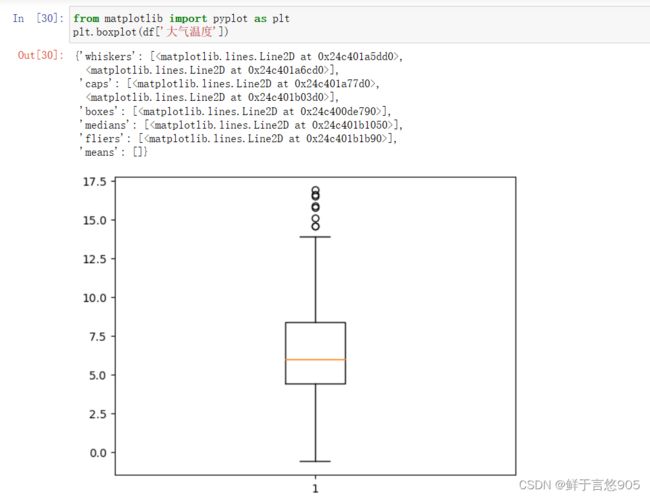
【例】某公司的年度业务数据work.csv,数据形式如下所示。其中年度销售量应大于1000,请分别用判断数据范围方法和箱形图方法检测数据中的异常值。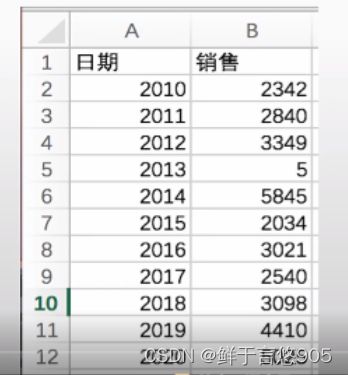
关键技术: query方法和boxplot方法。
在该案例中,首先使用pandas库中的query方法查询数据中是否有异常值。然后通过boxplot方法检测异常值。代码及运行结果如下: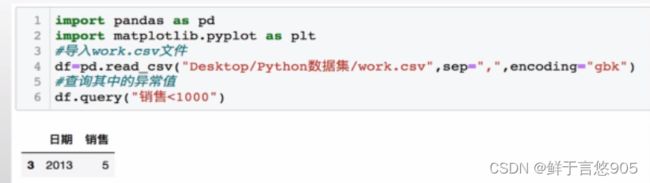
下面以箱形图的方法来进行异常值检测。
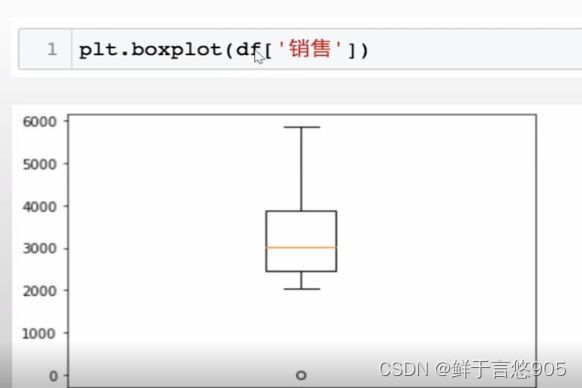
4.2处理异常值
了解异常值的检测后,接下来介绍如何处理异常值。在数据分析的过程中,对异常值的处理通常包括以下3种方法:
(1)最常用的方式是删除。
(2)将异常值当缺失值处理,以某个值填充。
(3)将异常值当特殊情况进行分析,研究异常值出现的原因。
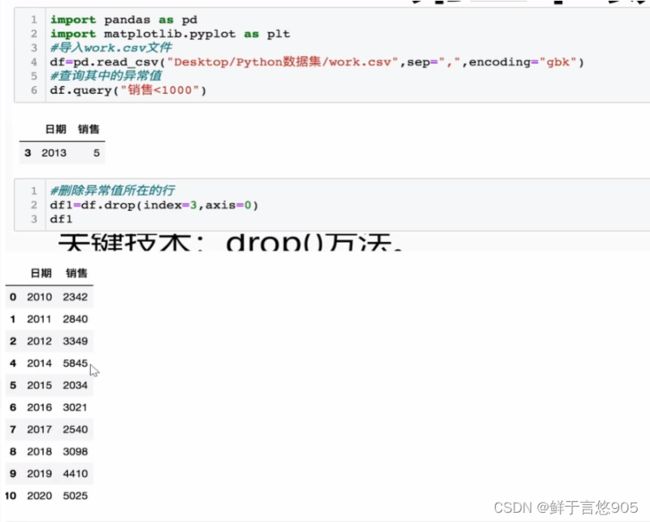
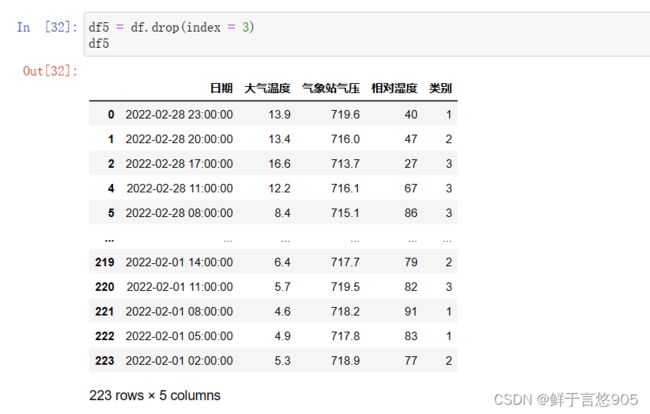
【例】对于上述业务数据work.csv,若已经检测出异常值,请问在此基础上,如何删除异常值?
关键技术:drop()方法。
利用drop()方法,对work.csv文件中的异常值进行删除操作,代码及运行结果如下:
五、数据类型的转化
1、数据类型检查
【例】利用numppy库的arange函数创建一维整数数组,并查
关键技术: dtype属性。
在本案例中,首先使用arange方法创建数组arr,然后通过打属性查看数组的数据类型。代码及运行结果如下:

【例】利用numpy库的arange函数创建一维浮点数数组arr1,然后将arr1数组的数据类型转换为整型。
关键技术: astype函数。

六、索引设置
索引能够快速查询数据,本节主要介绍索引的应用。索引的作用相当于图书的目录,可以根据目录中的页码快速找到所需的内容, Pandas库中索引的作用如下:
(1)更方便地查询数据。
(2)使用索引可以提升查询性能。
6.1添加索引
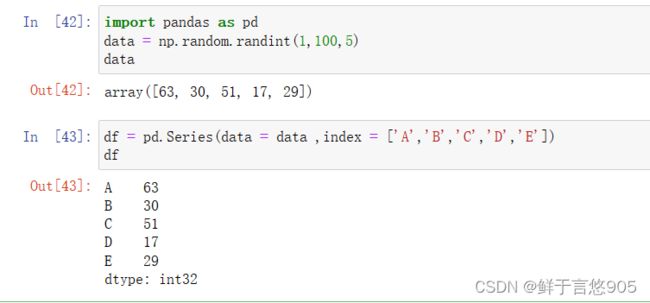
【例】创建数据为[1,2,3,4,5]的Series,并指定索引标签为[‘a’,‘b’,‘c’,‘d’,‘e’]。
关键技术: index方法设置索引。
该案例的代码及运行结果如下:
2、更改索引
【例】某公司销售数据集"work.csv"内容如下,请设定日期为索引,并用Python实现。关键技术: set_index()函数,可以指定某一字段为索引。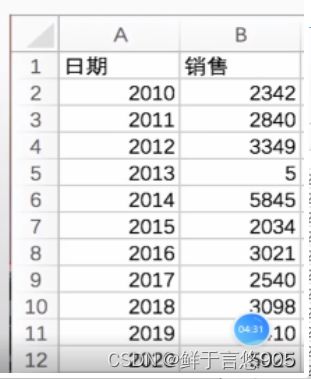
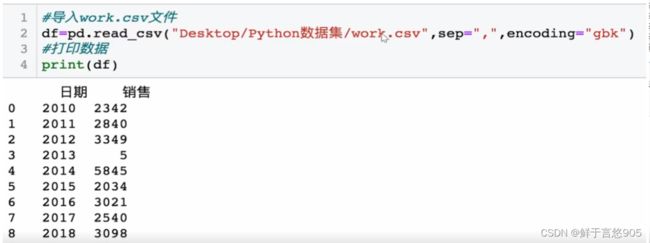
关于set_index
参数
- keys : 要设置为索引的列名(如有多个应放在一个列表里)
- drop : 将设置为索引的列删除,默认为True
- append : 是否将新的索引追加到原索引后(即是否保留原索引),默认为False
- inplace : 是否在原DataFrame上修改,默认为False
- verify_integrity : 是否检查索引有无重复,默认为False
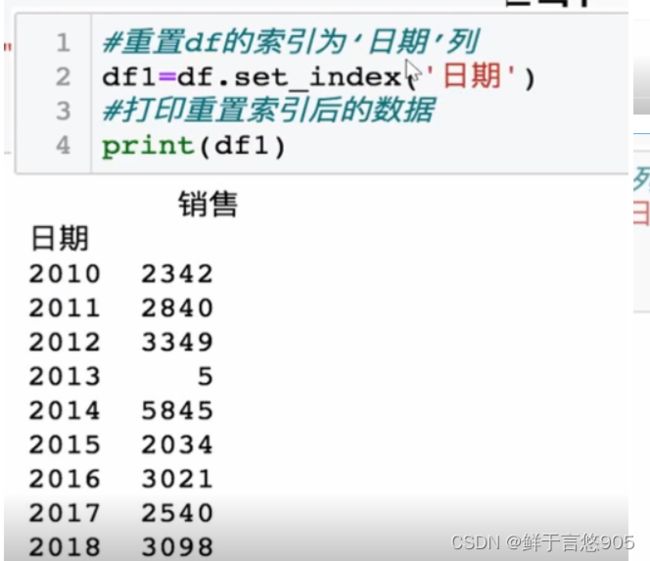
在该案例中,除了可以用set_index方法重置索引外,还可以在导入csv文件的过程中,设置index_col参数重置索引,代码及结果如下:
6.3重命名索引
【例】构建series对象,其数据为[88,60,75],对应的索引为[1,2,3]。请利用Python对该series对象重新设置索引为[1,2,3,4,5]。
关键技术: reindex()方法。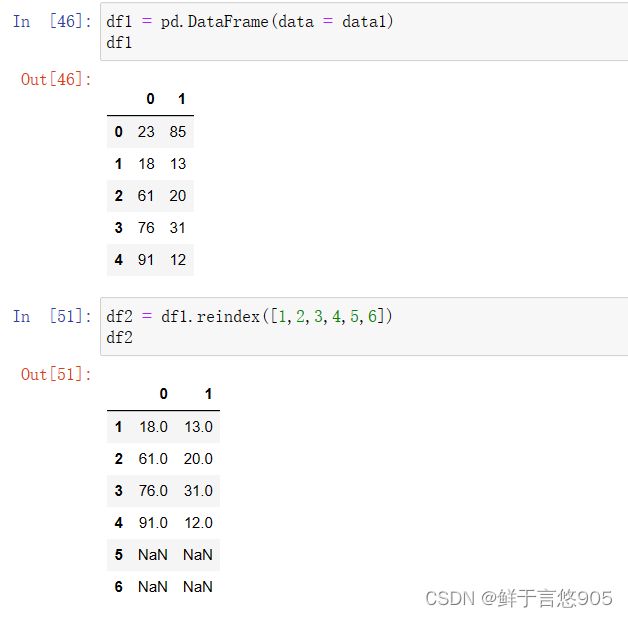
从运行结果中可以看出,对s1索引重置后,数据中出现了缺失值。若要对这些缺失值进行填补,可以设置reindex()方法中的method参数, method参数表示重新设置索引时,选择对缺失数据插值的方法。可以设置为None,bfill (向后填充)、ffill(向前填充)等。
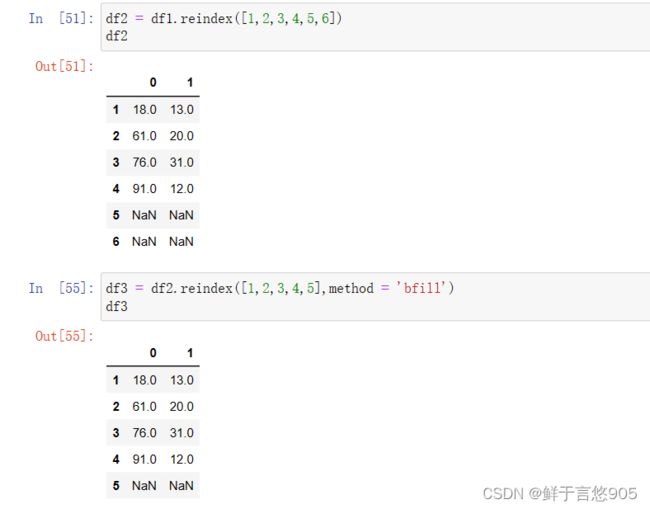
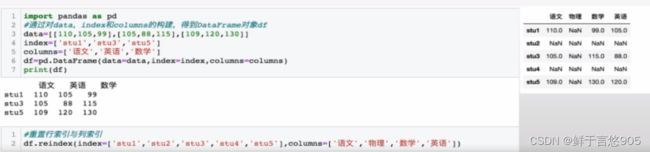
【例】通过二维数组创建如下所示的成绩表,并重置其行索引为stu1,stu2,stu3,stu4,stu5,重置其列索引为[‘语文’, ‘物理’,‘数学’,‘英语’]。
关键技术: reindex()方法中的index参数和columns参数。
在reindex)方法中, index参数表示重置的行索引, columns参数表示重置的列索引。本案例的代码及运行结果如下。
七、其他
7.1大小写转换
在数据分析中,有时候需要将字符串中的字符进行大小写转换。在Python中可以使用lower()方法,将字符串中的所有大写字母转换为小写字母。也可以使用upper()方法,将字符串中的所有小写字母转换为大写字母。
7.2数据修改与替换
(1)按列增加数据
【例】请创建如下所示的DataFrame数据,并利用Python对该数据的最后增加一列数据,要求数据的列索引为’four’ ,数值为[9,10,24]。若要在该数据的’two’ 列和 ‘three’列之间增加新的列,该如何操作?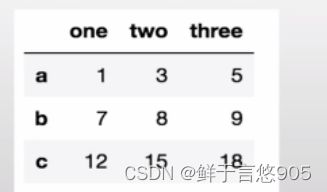





7.2数据修改与替换
(2)按行增加数据
【例】对于上例中的DataFrame数据,增加一行数据,数据行的索引为"d" ,数值为[9,10,11],请使用Python实现。若要向df数据中再增加三行数据,索引分别为"e" , “f” , “g”,数值分别为[1,2,3], [4,5,6], [7,8,9],在Python中该如何实现?
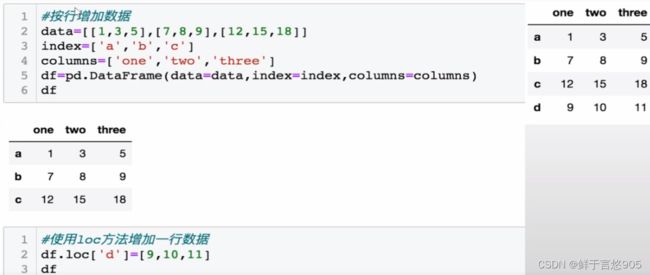
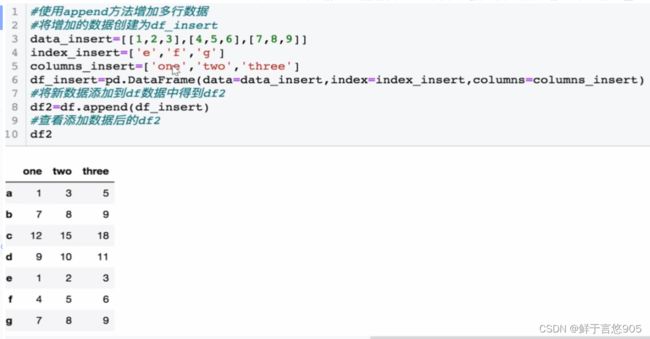
(2)按行增加数据
关键技术: loc()方法和append()方法。请利用Python将第三行数据替换为[10,20,30]
关键技术: loc()方法和iloc()方法。
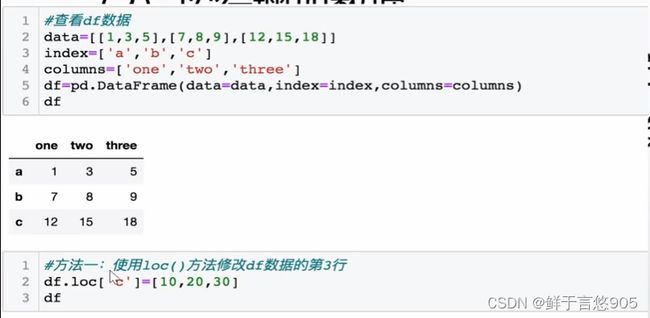
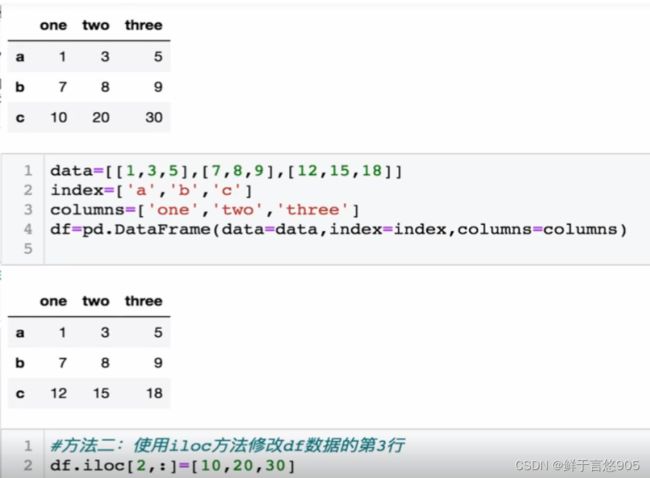
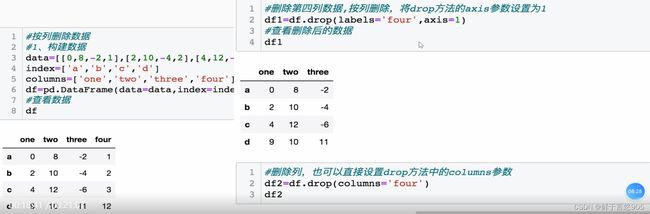
7.3数据删除
(1)按列删除数据
【例】请构建如下DataFrame数据并利用Python删除下面DataFrame实例的第四列数据。
关键技术:该案例中,使用DataFrame的drop0方法,删除数据中某一列。
drop()方法的参数说明如下:
labels:表示行标签或列标签。
axis: axis=0,表示按行删除,axis=1,表示按列删除。默认值为0。
index:删除行,默认为None。
columns:删除列,默认为None。
inplace:可选参数,对原数组作出修改并返回一个新数组。默认是False,如果为true,那么原数组直接被替换。
(2)按行删除数据
【例】对于上例中的DataFrame数据,请利用Python删除下面DataFrame实例的第四行数据。
关键技术:本案例可通过设置drop0方法的index参数, label参数实现,代码及运行结果如下。

总结
数据预处理可以提高数据的质量,并提高模型的准确性和可解释性。