pytorch实现文本分类
‘Attention Is All You Need’
“注意力就是你所需要的”
New deep learning models are introduced at an increasing rate and sometimes it’s hard to keep track of all the novelties .
新的深度学习模型被引入的速度越来越快,有时很难跟踪所有新颖性。
in this Article we will talk about Transformers with attached notebook(text classification example) are a type of neural network architecture that have been gaining popularity .
在本文中,我们将讨论带有笔记本的变压器 (文本分类示例)是一种已经越来越流行的神经网络体系结构。
In this post, we will address the following questions related to Transformers :
在这篇文章中,我们将解决与变形金刚有关的以下问题:
目录 : (Table Of Contents :)
Why do we need the Transformer ?
为什么我们需要变压器?
Transformer and its architecture in detail .
变压器及其架构详细。
Text Classification with Transformer .
用变形金刚进行文本分类。
useful papers to well dealing with Transformer.
有用的文章,以很好地处理Transformer。
我-为什么需要变压器? (I -Why do we need the transformer ?)
Transformers were developed to solve the problem of sequence transduction, or neural machine translation. That means any task that transforms an input sequence to an output sequence. This includes speech recognition, text-to-speech transformation, etc..
开发了变压器来解决序列转导或神经机器翻译的问题。 这意味着任何将输入序列转换为输出序列的任务。 这包括语音识别,文本到语音转换等。
For models to perform sequence transduction, it is necessary to have some sort of memory.
为了使模型执行序列转导,必须具有某种内存。
The limitations of Long-term dependencies :
长期依赖的局限性:
Transformer is an architecture for transforming one sequence into another one with the help of two parts (Encoder and Decoder), but it differs from the previously described/existing sequence-to-sequence models because it does not imply any Recurrent Networks (GRU, LSTM, etc.).
Transformer是一种通过两个部分(编码器和解码器)将一个序列转换为另一个序列的体系结构,但它与先前描述/现有的序列到序列模型不同,因为它并不暗示任何递归网络(GRU,LSTM)等)。
In the paper “Attention is All You Need” , the transformer architecture is well introduced , and like the title indicates transformer architecture uses the attention mechanism (we will make a detailed article about it later)
在“注意就是你所需要的一切”一文中,很好地介绍了变压器体系结构,并且正如标题所示,变压器体系结构使用了注意力机制(我们将在后面进行详细的介绍)
let’s consider a language model that will predict the next word based on the previous ones !
让我们考虑一种语言模型,该模型将根据前一个单词预测下一个单词!
sentence : “bitcoin the best cryptocurrency”
句子: “比特币是最好的加密货币”
here we don’t need an additional context , so obvious that the next word will be “cryptocurrency” .
这里我们不需要额外的上下文,很明显,下一个单词将是“ cryptocurrency”。
In this case RNN’s can sove the issue and predict the answer using the past information .
在这种情况下,RNN可以解决问题并使用过去的信息预测答案。
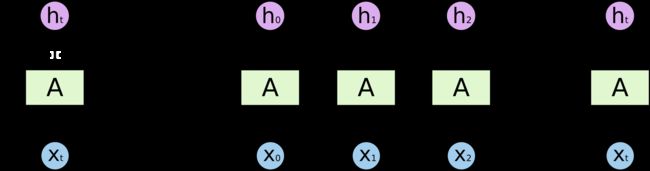
But in other cases we need more context . For example, let’s say that you are trying to predict the last word of the text: I grew up in Tunisia … I speak fluent ... Recent information suggests that the next word is probably a language, but if we want to narrow down which language, we need context of Tunisia, that is further back in the text.
但是在其他情况下,我们需要更多的上下文。 例如,假设您要预测文本的最后一句话: 我在突尼斯长大……我的语言说得很流利..... 最近的信息表明,下一个词可能是一种语言,但是如果我们想缩小哪种语言的范围,我们需要突尼斯的语境,这在文本中会更进一步。
RNNs become very ineffective when the gap between the relevant information and the point where it is needed become very large. That is due to the fact that the information is passed at each step and the longer the chain is, the more probable the information is lost along the chain.
当相关信息和需要的信息之间的差距变得很大时,RNN变得非常无效。 这是由于以下事实:信息在每个步骤中传递,并且链条越长,信息沿着链条丢失的可能性就越大。
i recommend a nice article that talk in depth about the difference between seq2seq and transformer .
我推荐一篇不错的文章 ,深入探讨seq2seq和Transformer之间的区别。
II-变压器及其架构的详细信息: (II -Transformer and its architecture in detail :)
An image is worth thousand words, so we will start with that!
一张图像值一千个单词,因此我们将从此开始!
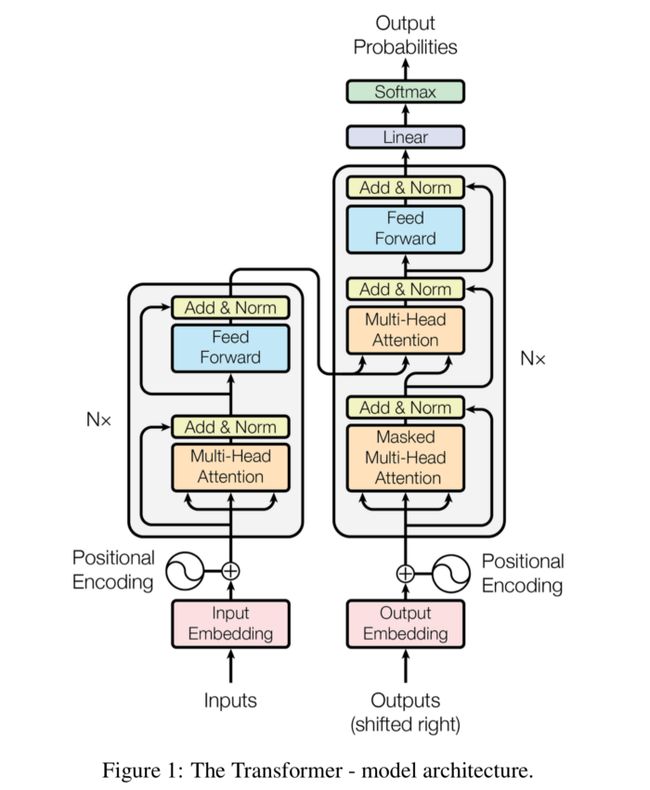
The first thing that we can see is that it has a sequence-to-sequence encoder-decoder architecture.
我们可以看到的第一件事是它具有序列到序列的编码器-解码器体系结构。
Much of the literature on Transformers present on the Internet use this very architecture to explain Transformers.
互联网上有关变形金刚的许多文献都使用这种架构来解释变形金刚。
But this is not the one used in Open AI’s GPT model (or the GPT-2 model, which was just a larger version of its predecessor).
但这不是Open AI的GPT模型(或GPT-2模型,只是其前身的较大版本)中使用的模型。
The GPT is a 12-layer decoder only transformer with 117M parameters.
GPT是仅12层解码器的变压器,具有117M个参数。
The Transformer has a stack of 6 Encoder and 6 Decoder, unlike Seq2Seq;
与Seq2Seq不同,该Transformer具有6个编码器和6个解码器的堆栈;
the Encoder contains two sub-layers: multi-head self-attention layer and a fully connected feed-forward network.
编码器包含两个子层:多头自我注意层和完全连接的前馈网络。
The Decoder contains three sub-layers, a multi-head self-attention layer, an additional layer that performs multi-head self-attention over encoder outputs, and a fully connected feed-forward network.
解码器包含三个子层,一个多头自我注意层,一个在编码器输出上执行多头自我注意的附加层以及一个完全连接的前馈网络。
Each sub-layer in Encoder and Decoder has a Residual connection followed by a layer normalization.
编码器和解码器中的每个子层都有一个残差连接,然后进行层归一化。
All input and output tokens to Encoder/Decoder are converted to vectors using learned embeddings.
使用学习到的嵌入,将编码器/解码器的所有输入和输出令牌转换为向量。
These input embeddings are then passed to Positional Encoding.
然后,将这些输入嵌入传递到位置编码。
The Transformers architecture does not contain any recurrence or convolution and hence has no notion of word order.
变形金刚架构不包含任何重复或卷积,因此没有词序的概念。
All the words of the input sequence are fed to the network
输入序列的所有单词都被馈送到网络
with no special order or position as they all flow simultaneously through the Encoder and decoder stack.
没有特殊的顺序或位置,因为它们都同时流经编码器和解码器堆栈。
To understand the meaning of a sentence,
要了解句子的含义,
it is essential to understand the position and the order of words.
了解单词的位置和顺序至关重要。
III —使用Transformer(Pytorch实现)进行文本分类: (III — Text Classification using Transformer(Pytorch implementation) :)
It is too simple to use the ClassificationModel from simpletransformes :ClassificationModel(‘Architecture’, ‘model shortcut name’, use_cuda=True,num_labels=4)Architecture : Bert , Roberta , Xlnet , Xlm…shortcut name models for Roberta : roberta-base , roberta-large ….more details here
使用来自simpletransformes的分类模型太简单了:ClassificationModel('Architecture','模型快捷方式名称',use_cuda = True,num_labels = 4)体系结构:Bert,Roberta,Xlnet,Xlm…Roberta的快捷名称模型:roberta-base ,roberta-large…。更多详细信息在这里
we create a model that classify text for 4 classes [‘art’, ‘politics’, ‘health’, ‘tourism’]
我们创建了一个模型,将文本分为4类['艺术','政治','健康','旅游']
we apply this model in our previous project
我们在之前的项目中应用了此模型
and we integrate it in our flask application here . (you can buy it for helping us to create better content and help community)
并将其集成到此处的烧瓶应用程序中。 (您可以购买它来帮助我们创建更好的内容并帮助社区)
here you will find a commented notebook :
在这里,您会找到一个有注释的笔记本:
- setup environment & configuration 设置环境和配置
!pip install --upgrade transformers
!pip install simpletransformers# memory footprint support libraries/code
!ln -sf /opt/bin/nvidia-smi /usr/bin/nvidia-smi
!pip install gputil
!pip install psutil
!pip install humanize importing libraries- Importing Libraries 导入库
import psutilimport humanizeimport osimport GPUtil as GPUimport numpy as npimport pandas as pdfrom google.colab import filesfrom tqdm import tqdmimport warnings
warnings.simplefilter('ignore')import gcfrom scipy.special import softmaxfrom simpletransformers.classification import ClassificationModelfrom sklearn.model_selection import train_test_split, StratifiedKFold, KFold import sklearnfrom sklearn.metrics import log_lossfrom sklearn.metrics import *from sklearn.model_selection import *import reimport randomimport torch
pd.options.display.max_colwidth = 200#choose the same seed to assure that our model will be roproducibledef seed_all(seed_value):
random.seed(seed_value) # Python
np.random.seed(seed_value) # cpu vars
torch.manual_seed(seed_value) # cpu vars
if torch.cuda.is_available():
torch.cuda.manual_seed(seed_value)
torch.cuda.manual_seed_all(seed_value) # gpu vars
torch.backends.cudnn.deterministic = True #needed
torch.backends.cudnn.benchmark = False
seed_all(2)- Reading Data 读取资料
import pandas as pd#We consider that our data is a csv file (2 columns : text and label)#using pandas function (read_csv) to read the file
train=pd.read_csv()
feat_cols = "text"- Verify the topic classes in the data 验证数据中的主题类
train.label.unique()- train the model 训练模型
label_cols = ['art', 'politics', 'health', 'tourism']
train.head()
l=['art', 'politics', 'health', 'tourism']# Get the numerical ids of column label
train['label']=train.label.astype('category')
Y = train.label.cat.codes
train['label']=Y# Print initial shape
print(Y.shape)from keras.utils import to_categorical# One-hot encode the indexes
Y = to_categorical(Y)# Check the new shape of the variable
print(Y.shape)# Print the first 5 rows
print(Y[0:5])for i in range(len(l)) :
train[l[i]] = Y[:,i]#using KFOLD Cross Validation is important to test our model%%time
err=[]
y_pred_tot=[]
fold=StratifiedKFold(n_splits=5, shuffle=True, random_state=1997)
i=1for train_index, test_index in fold.split(train,train['label']):
train1_trn, train1_val = train.iloc[train_index], train.iloc[test_index]
model = ClassificationModel('roberta', 'roberta-base', use_cuda=True,num_labels=4, args={
'train_batch_size':16,
'reprocess_input_data': True,
'overwrite_output_dir': True,
'fp16': False,
'do_lower_case': False,
'num_train_epochs': 4,
'max_seq_length': 128,
'regression': False,
'manual_seed': 1997,
"learning_rate":2e-5,
'weight_decay':0,
"save_eval_checkpoints": True,
"save_model_every_epoch": False,
"silent": True})
model.train_model(train1_trn)
raw_outputs_val = model.eval_model(train1_val)[1]
raw_outputs_vals = softmax(raw_outputs_val,axis=1)
print(f"Log_Loss: {log_loss(train1_val['label'], raw_outputs_vals)}")
err.append(log_loss(train1_val['label'], raw_outputs_vals))output :
输出:
Log_Loss: 0.35637871529928816
Log_Loss:0.35637871529928816
CPU times: user 11min 2s, sys: 4min 21s,
CPU时间:用户11分钟2秒,系统时间:4分钟21秒,
total: 15min 23s Wall time: 16min 7s
总计:15分23秒挂墙时间:16分7秒
Log Loss :
日志损失:
print("Mean LogLoss: ",np.mean(err))output :
输出:
Mean LogLoss: 0.34930175561484067
平均对数损失:0.34930175561484067
raw_outputs_valsOutput :
输出:
array([[9.9822301e-01, 3.4856689e-04, 3.8243082e-04, 1.0458552e-03], [9.9695909e-01, 1.1522240e-03, 5.9563853e-04, 1.2927916e-03], [9.9910539e-01, 2.3084633e-04, 2.5905663e-04, 4.0465154e-04], ..., [3.6545596e-04, 2.8826005e-04, 4.3145564e-04, 9.9891484e-01], [4.0789684e-03, 9.9224585e-01, 1.2752400e-03, 2.3997365e-03], [3.7382307e-04, 3.4797701e-04, 3.6257200e-04, 9.9891579e-01]], dtype=float32)
数组([[9.9822301e-01,3.4856689e-04,3.8243082e-04,1.0458552e-03],[9.9695909e-01,1.1522240e-03,5.9563853e-04,1.2927916e-03],[9.9910539e -01,2.3084633e-04,2.5905663e-04,4.0465154e-04],...,[3.6545596e-04,2.8826005e-04,4.3145564e-04,9.9891484e-01],[4.0789684e-03 ,9.9224585e-01,1.2752400e-03,2.3997365e-03],[3.7382307e-04、3.4797701e-04、3.6257200e-04、9.9891579e-01]],dtype = float32)
- test our Model 测试我们的模型
pred = model.predict(['i want to travel to thailand'])[1]
preds = softmax(pred,axis=1)
predsoutput :
输出:
array([[6.0461409e-04, 3.6119239e-04, 3.3729596e-04, 9.9869716e-01]], dtype=float32)
数组([[6.0461409e-04,3.6119239e-04,3.3729596e-04,9.9869716e-01]],dtype = float32)
we create a function which calculate the maximum probability and detect the topicfor example if we have 0.6 politics 0.1 art 0.15 health 0.15 tourism >>>> topic = politics
我们创建了一个计算最大概率并检测主题的函数, 例如,如果我们有0.6政治0.1艺术0.15健康0.15旅游业>>>> topic =政治
def estm(raw_outputs_vals):
for i in range(len(raw_outputs_vals)):
for j in range(4):
if(max(raw_outputs_vals[i])==raw_outputs_vals[i][j]):
raw_outputs_vals[i][j]=1
else :
raw_outputs_vals[i][j]=0
return(raw_outputs_vals)estm(preds)output :
输出:
array([[0., 0., 0., 1.]], dtype=float32)
数组([[0.,0.,0.,1.]],dtype = float32)
our labels are :['art', 'politics', 'health', 'tourism']so that's correct ;)
我们的标签是:['艺术','政治','健康','旅游'], 所以没错;)
i hope you find it useful & helpful !
我希望您觉得它有用和有用!
Download source code from our github.
从我们的github下载源代码 。
III-与变压器很好地打交道的有用论文: (III -useful papers to well dealing with Transformer:)
here a list of recommended papers to get in depth with transformers (mainly Bert Model) :
这是深入了解变压器的推荐论文清单(主要是伯特模型):
* Cross-Linguistic Syntactic Evaluation of Word Prediction Models* Emerging Cross-lingual Structure in Pretrained Language Models* Finding Universal Grammatical Relations in Multilingual BERT* On the Cross-lingual Transferability of Monolingual Representations* How multilingual is Multilingual BERT?* Is Multilingual BERT Fluent in Language Generation?* Are All Languages Created Equal in Multilingual BERT?* What’s so special about BERT’s layers? A closer look at the NLP pipeline in monolingual and multilingual models* A Study of Cross-Lingual Ability and Language-specific Information in Multilingual BERT* Cross-Lingual Ability of Multilingual BERT: An Empirical Study* Multilingual is not enough: BERT for Finnish
*单词预测模型的跨语言语法评估*预先训练的语言模型中新出现的跨语言结构*在多语言BERT中找到通用语法关系*关于单语言表示形式的跨语言可传递性*多语言BERT的多语言能力*多语言BERT会流利语言生成?*在多语言BERT中所有语言都创建相同吗?* BERT的层有何特别之处? 仔细研究单语言和多语言模型中的NLP管道*多语言BERT中的跨语言能力和特定于语言的信息的研究*多语言BERT的跨语言能力:一项经验研究*多语言是不够的:芬兰语的BERT
Download all files from our github repo
从我们的github上下载的所有文件回购
III-摘要: (III -Summary :)
Transformers present the next front in NLP.
变形金刚代表了NLP的下一个前沿。
In less than a couple of years since its introduction,
自推出以来不到两年的时间,
this new architectural trend has surpassed the feats of RNN-based architectures.
这种新的架构趋势已经超越了基于RNN的架构的壮举。
This exciting pace of invention is perhaps the best part of being early to a new field like Deep Learning!
如此激动人心的发明步伐也许是早期进入深度学习等新领域的最好部分!
if you have any suggestions or a questions please contact NeuroData Team :
如果您有任何建议或疑问,请联系NeuroData团队:
脸书
领英
Website
网站
Github
Github
Authors :
作者:
Yassine Hamdaoui
Yassine Hamdaoui
code credits goes to Med Klai Helmi : Data Scientist and Zindi Mentor
代码信用归于Med Klai Helmi:数据科学家和Zindi Mentor
翻译自: https://medium.com/swlh/text-classification-using-transformers-pytorch-implementation-5ff9f21bd106
pytorch实现文本分类