GPDB7-新特性-Fast ANALYZE on Append-Optimized tables
GPDB7-新特性-Fast ANALYZE on Append-Optimized tables
9月28日,发布了GPDB7版本,对AO/CO表的ANALYZE进行了优化,有了很大性能提升。由于PG的两阶段采样方法并不能在AO/CO表上优雅工作,GP不得不解压缩所有的边长块(AO/CO表的block是变长的)直到达到目标记录。如果采样记录在表末尾,就很容易造成全表扫描。所以,之前版本是不支持在Append-optimized 表上进行analzye采样的。
Analyze heap表的采样方法
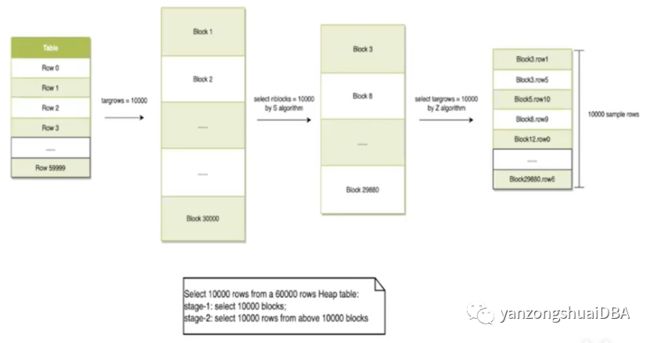
对于大表,ANALYZE使用表的随机样本,而不是采样每行。使用两阶段方法进行采样。
1)阶段1
扫描targetrows个随机block(若没有这么多块,则扫描秒所有块)。targetrows值的确定:
examine_attribute->std_typanalyze:默认typanalyze函数
attr->attstattarget = default_statistics_target;//guc参数,默认100
stats->minrows = 300 * attr->attstattarget;//30000
2)阶段2
从targetrows个块中扫描并随机采样targrows行。对每一个数据块使用 Vitter 算法按行随机采样数据。两个阶段同时进行,采样完成后,被采样的元组放到元组数组中,然后对这个数据使用快速排序法进行排序。并使用这些采样到的数据估算整个表中的存活元组和元组的个数:
代码逻辑:

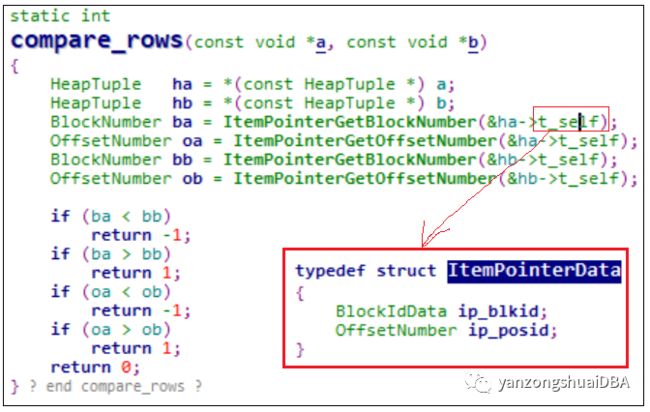
采样完,需要根据情况进行排序。即compare_rows函数的功能:即根据记录的物理位置进行排序(ItemPointerData:块号及块内偏移)。
【获取的是随机块,怎么保证存入数组内物理位置有序?随机块的顺序是否是有序的?】
BlockSampler_Next函数生成采样页面ID时,若页面总数小于采样总数,则不随机,按顺序遍历,否则需要随机。所以当采样个数超过采样目标数时才需要排序。
3)上述方法用在append-optimized表时问题
Vitter算法在GP6中就如同全部扫描一样,如果采样行落在表的尾部,为了获取最后的采样行就需要扫描所有的前置行。
对于AO/CO表以变长block存储的特性,基于block的采样并不能很好工作。问题1:阶段1中,AO/CO使用变长block,不能像heap表一样定位采样块的物理位置,没有采样块的物理位置,就不能定位变长块内的采样元组。问题2:阶段2中,由于会随机覆盖数组内物理有序的采样元组,导致采样元组乱序,所以需要重新进行排序。AO/CO表中,没有ItemPointerData,就不能进行排序了。
Fast Analyze on AO/CO表
基于下面的工作及特性,重构了AO/CO ANALYZE采样模块:
1)AO/AOC analyze两阶段采样
提出了一个包含固定数量元组的逻辑块的概念,以支持PG的两阶段采样机制。他还通过跳过变长块的解压缩来加速获取目标元组的速度。算法S中定义:一个拥有固定行数范围作为固定大小的块;针对非采样逻辑块,仅扫描块头;算法Z,采样逻辑块仅解压覆盖到的变长块。
https://github.com/greenplum-db/gpdb/pull/11190
2)利用AO block directory
利用AO Block Directory来定位目标样本元组,不需要扫描不必要的变长块。当然,也提升了性能
3)GPDB具有AO/CO特定特性,可以将元组总数存储在辅助表中,该辅助表很容易获取,而无需太多开销
4)GPDB具有fetch功能,基于AOTupleId查找变长块,而不需要解压不必要的变长块
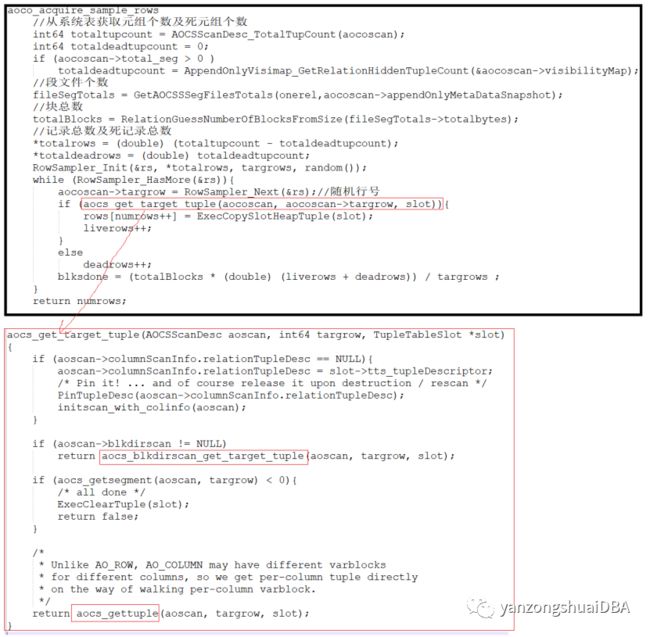
为此引入了append-optimized表的访问方法API:table_relation_acquire_sample_rows(),即aoco_acquire_sample_rows;引入64位的RowSampler_Next(heap的是32位返回值BlockSampler_Next),基于算法S仅作一阶段行采样;基于物理Varblock的analyze:没有block directory时的执行方式;基于Block Directory的analyze:有block directory的analyze。注意,它不用排序,因为直接采样那么多行就结束了。关于列存的介绍,参考:
https://mp.weixin.qq.com/s?__biz=MzU1OTgxMjA4OA==&mid=2247484941&idx=1&sn=37140f73541677296a87411a14ca60fd&chksm=fc10da9acb67538c4d82f0403cb504c9c27fc39df7881119d34c112fa43aeb3d60eea5f54806&token=1211222806&lang=zh_CN#rd
我们关注aocs_blkdirscan_get_target_tuple和aocs_gettuple两个函数。
1)aocs_blkdirscan_get_target_tuple
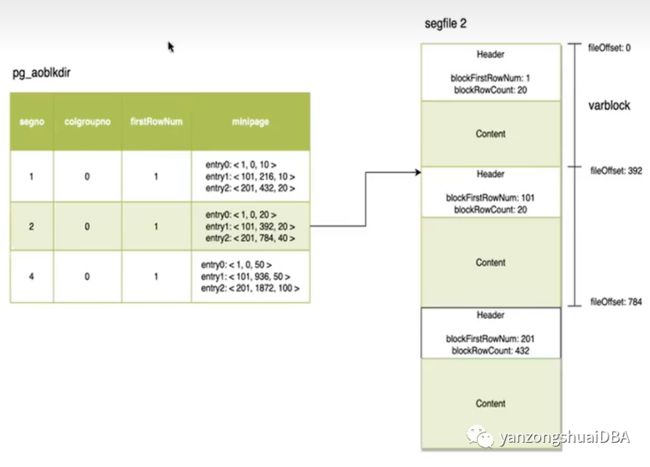
即利用辅助表pg_aoseg_OID。
1、定位段文件号
2、 pg_aoblkdir_oid创建索引的时候生成,通过Btree根据key找到AOTupleId(segno+rownum)
3、扫描辅助表pg_aoseg_OID,根据segno和colgroupno定位采样行位于哪个minipage
4、基于entry.dirstRowNum和采样行的距离,判断是哪个entry
5、entry中直接定位到对应的block,即文件偏移
6、从block中检索采样行
2)aocs_gettuple
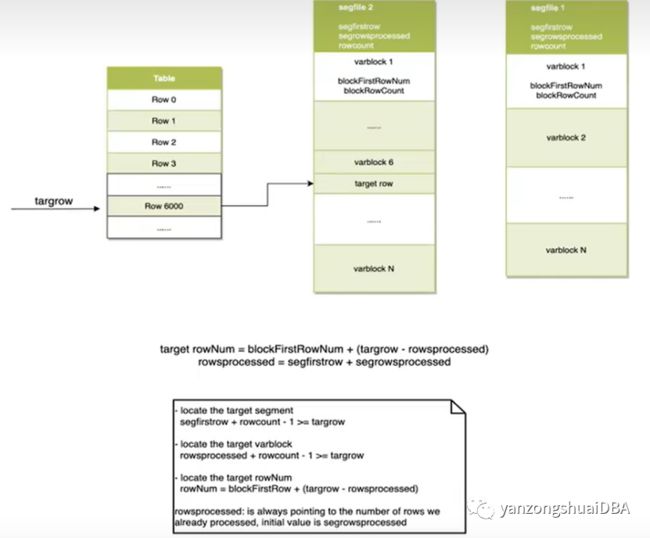
1、首先定位段文件号
段文件第一页有段文件第一行的行号以及该文件总行数,据此就可以判断采样行是否在该文件中
2、定位目标varblock
每个varblock块头有该块行数,据此可以判断采样行是否在该varblok中
如果在该varblock则加压缩,否则不解压缩跳过该块。
3、定位采样行
每个varblock中还有blockFirstRow,据此可以定位采样行位置
4、可见性检测,若可见则获取该tuple。
参考
https://github.com/greenplum-db/gpdb/pull/14416
https://zhuanlan.zhihu.com/p/538049580?utm_id=0
https://www.bilibili.com/video/BV1kc41137YK/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=10ce859f3f7b1da2094a1283c19fe9b9