【2021.08】python会员数据化运营task2
基于RFM的精细化用户管理
1.案例背景
对用户进行分组可以更好的了解用户价值。本案例使用某企业四年的家电订单数据,使用RFM模型对用户进行分组,基于业务部门的用户分群需求,我们计划将RFM的3个维度分别作3个区间的离散化,这样出来的用户群体最大有27个。
从交付结果看,给业务部门做的分析结果都要导出成Excel文件,用于做后续分析和二次加工使用。另外,RFM的结果还会供其他模型的建模使用,RFM本身的结果可以作为新的局部性特征,因此数据的输出需要有本地文件和写数据库两种方式。
本节案例选择了4年的订单数据,这样可以从不同的年份对比不同时间下各个分组的绝对值变化情况,方便了解会员的波动。本节案例的输入源数据sales.xlsx,程序输出RFM得分数据写入本地文件sales_rfm_score.xlsx。
数据链接:数据源
提取码:zdxx
2.案例主要应用技术
本案例使用的库包括time、numpy和pandas,使用sklean中的随机森林计算特征重要性,使用excel对结果进行展示。
3. 案例数据
案例数据是某企业从2015年到2018年共4年的用户订单抽样数据。Excel中包含5个sheet,前4个sheet分别为每年的数据,最后一张会员等级表为用户的等级表。
前4张表所含字段如下:
| 特征变量 | 描述 |
|---|---|
| 会员ID | 每个会员的ID唯一,纯数字 |
| 提交日期 | 订单日提交日期,日期 |
| 订单号 | 订单ID,每个订单的ID唯一,纯数字 |
| 订单金额 | 订单金额,浮点型数据 |
会员等级表中是所有会员的会员ID对应会员等级的情况,包括以下两个字段:
| 特征变量 | 描述 |
|---|---|
| 会员ID | 每个会员的ID唯一,纯数字 |
| 会员等级 | 会员等级以数字区分,数字越大,级别越高 |
4.案例过程
(1)导入库和读取数据
# 导入库
import time
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# 读取数据
sheet_name = ['2015', '2016', '2017', '2018', '会员等级']
sheet_datas = [pd.read_excel('sales.xlsx',sheet_name=i) for i in sheet_name]
(2)描述性分析
#对表格数据做显示,以审查一下我们的数据是否有误
for each_name,each_data in zip(sheet_names,sheet_datas):
print('[data summary for {0:=^50}]'.format(each_name))
print('Overview:','\n',each_data.head(4))
print('DESC:','\n',each_data.describe())
print('NA records',each_data.isnull().any(axis=1).sum())
print('Dtypes',each_data.dtypes)
[data summary for =======================2015=======================]
Overview:
会员ID 订单号 提交日期 订单金额
0 15278002468 3000304681 2015-01-01 499.0
1 39236378972 3000305791 2015-01-01 2588.0
2 38722039578 3000641787 2015-01-01 498.0
3 11049640063 3000798913 2015-01-01 1572.0
DESC:
会员ID 订单号 订单金额
count 3.077400e+04 3.077400e+04 30774.000000
mean 2.918779e+10 4.020414e+09 960.991161
std 1.385333e+10 2.630510e+08 2068.107231
min 2.670000e+02 3.000305e+09 0.500000
25% 1.944122e+10 3.885510e+09 59.000000
50% 3.746545e+10 4.117491e+09 139.000000
75% 3.923593e+10 4.234882e+09 899.000000
max 3.954613e+10 4.282025e+09 111750.000000
NA records 0
Dtypes 会员ID int64
订单号 int64
提交日期 datetime64[ns]
订单金额 float64
dtype: object
[data summary for =======================2016=======================]
Overview:
会员ID 订单号 提交日期 订单金额
0 39288120141 4282025766 2016-01-01 76.0
1 39293812118 4282037929 2016-01-01 7599.0
2 27596340905 4282038740 2016-01-01 802.0
3 15111475509 4282043819 2016-01-01 65.0
DESC:
会员ID 订单号 订单金额
count 4.127800e+04 4.127800e+04 41277.000000
mean 2.908415e+10 4.313583e+09 957.106694
std 1.389468e+10 1.094572e+07 2478.560036
min 8.100000e+01 4.282026e+09 0.100000
25% 1.934990e+10 4.309457e+09 59.000000
50% 3.730339e+10 4.317545e+09 147.000000
75% 3.923182e+10 4.321132e+09 888.000000
max 3.954554e+10 4.324911e+09 174900.000000
NA records 1
Dtypes 会员ID int64
订单号 int64
提交日期 datetime64[ns]
订单金额 float64
dtype: object
[data summary for =======================2017=======================]
Overview:
会员ID 订单号 提交日期 订单金额
0 38765290840 4324911135 2017-01-01 1799.0
1 39305832102 4324911213 2017-01-01 369.0
2 34190994969 4324911251 2017-01-01 189.0
3 38986333210 4324911283 2017-01-01 169.0
DESC:
会员ID 订单号 订单金额
count 5.083900e+04 5.083900e+04 50839.000000
mean 2.882368e+10 4.332466e+09 963.587872
std 1.409416e+10 4.404350e+06 2178.727261
min 2.780000e+02 4.324911e+09 0.300000
25% 1.869274e+10 4.328415e+09 59.000000
50% 3.688044e+10 4.331989e+09 149.000000
75% 3.923020e+10 4.337515e+09 898.000000
max 3.954554e+10 4.338764e+09 123609.000000
NA records 0
Dtypes 会员ID int64
订单号 int64
提交日期 datetime64[ns]
订单金额 float64
dtype: object
[data summary for =======================2018=======================]
Overview:
会员ID 订单号 提交日期 订单金额
0 39229691808 4338764262 2018-01-01 3646.0
1 39293668916 4338764363 2018-01-01 3999.0
2 35059646224 4338764376 2018-01-01 10.1
3 1084397 4338770013 2018-01-01 828.0
DESC:
会员ID 订单号 订单金额
count 8.134900e+04 8.134900e+04 81348.000000
mean 2.902317e+10 4.348372e+09 966.582792
std 1.404116e+10 4.183774e+06 2204.969534
min 2.780000e+02 4.338764e+09 0.000000
25% 1.902755e+10 4.345654e+09 60.000000
50% 3.740121e+10 4.349448e+09 149.000000
75% 3.923380e+10 4.351639e+09 899.000000
max 3.954614e+10 4.354235e+09 174900.000000
NA records 1
Dtypes 会员ID int64
订单号 int64
提交日期 datetime64[ns]
订单金额 float64
dtype: object
[data summary for =======================会员等级=======================]
Overview:
会员ID 会员等级
0 100090 3
1 10012905801 1
2 10012935109 1
3 10013498043 1
DESC:
会员ID 会员等级
count 1.543850e+05 154385.000000
mean 2.980055e+10 2.259701
std 1.365654e+10 1.346408
min 8.100000e+01 1.000000
25% 2.213894e+10 1.000000
50% 3.833022e+10 2.000000
75% 3.927932e+10 3.000000
max 3.954614e+10 5.000000
NA records 0
Dtypes 会员ID int64
会员等级 int64
dtype: object
通过上述结果我们可以得到如下结论:
- 日期列为日期格式。
- 订单金额分布不均匀的,存在极大值和极小值,对后续处理可能有影响。
- 订单金额中存在异常值。经过与业务方沟通后确认,最大值的订单金额有效,通常是客户一次性购买多个大家电商品;而订单金额低于1元的订单这类是使用优惠券支付的订单,并没有实际意义,因此需要在后续处理中去掉。
- 有的表中存在缺失值,需要处理。
(3) 数据预处理
#去除异常值与缺失值
for ind,each_data in enumerate(sheet_datas[:-1])
sheet_datas[ind] = each_data.dropna()
sheet_datas[ind] = each_data[each_data['订单金额'] > 1]
sheet_datas[ind]['max_year_date'] = each_data['提交日期'].max()
data_merge = pd.concat(sheet_datas[:-1],axis=0)
# 计算日期间隔和获取年份
data_merge['date_interval'] = data_merge['max_year_date'] - data_merge['提交日期']
data_merge['year'] = data_merge['提交日期'].dt.year
# 将日期间隔转换为数字
data_merge['date_interval'] = data_merge['date_interval'].apply(lambda x: x.days)
按会员id和年份做汇总:
rfm_gb = data_merge.groupby(['year','会员ID']).agg({'date_interval':'min',
'提交日期':'count',
'订单金额':'sum'})
rfm_gb = rfm_gb.reset_index()
这里我们对数据进行处理,选用三个统计数据作为RFM的三个维度,一是会员最近一次购买时间,二是会员的累积购买次数,三是会员的累计购买金额。
重命名列名:
rfm_gb.columns = ['year','会员ID','r','f','m']
rfm_gb.head()

(4)确定RFM划分区间
接下来我们对三个维度进行划分。
首先查看一下数据分布情况。
#查看数据分布
desc_pd = rfm_gb.iloc[:,2:].describe().T
print(desc_pd)
count mean std min 25% 50% 75% max
r 148591.0 165.524043 101.988472 0.0 79.0 156.0 255.0 365.0
f 148591.0 1.365002 2.626953 1.0 1.0 1.0 1.0 130.0
m 148591.0 1323.741329 3753.906883 1.5 69.0 189.0 1199.0 206251.8
我们将三维度各分为三组,这里我们将选择25%和75%作为r和m区间划分的2个边界值。
但需要注意的是,由于行业属性(大家电)的原因,f的值大多为1,用户发生复购确实很少,1年购买1次是比较普遍(其中包含新客户以及老客户在当年的第1次购买),因此划分时可以使用2和5来作为边界
:选择2是因为一般的业务部门认为当年购买2次及2次以上就可以被定义为复购用户(而非累计订单的数量计算复购用户)。
选择5是因为业务部门认为普通用户购买5次已经是非常高的次数,超过该次数就属于非常高价值的用户群体。可以说,这个值是基于业务经验和日常数据报表而获得的。
设置区间边界:
# 定义区间边界
r_bins = [-1,79,255,365] # 注意起始边界小于最小值
f_bins = [0,2,5,130]
m_bins = [0,69,1199,206252]
(5)计算RFM因子权重
会员等级往往与会员价值息息相关,会员价值越高的用户拥有更高的会员等级。因此,我们建议rfm与会员等级的模型,从而评价rfm三个特征的特征重要性。
匹配会员等级和RFM得分:
rfm_merge = pd.merge(rfm_gb,sheet_datas[-1],on='会员ID',how='inner')
通过建立随机森林模型获得RFM因子得分:
# rf获得rfm因子得分
clf = RandomForestClassifier()
clf = clf.fit(rfm_merge[['r','f','m']],rfm_merge['会员等级'])
weights = clf.feature_importances_
print('feature importance:',weights)
feature importance: [0.40432188 0.00604913 0.58962899]
由结果可知,用户的等级首先侧重于会员的价值贡献度(实际订单的贡献),其次是新近程度,最后是频次。
(6)RFM计算过程
RFM分箱得分
# RFM分箱得分
rfm_gb['r_score'] = pd.cut(rfm_gb['r'], r_bins, labels=[i for i in range(len(r_bins)-1,0,-1)])# 计算R得分
rfm_gb['f_score'] = pd.cut(rfm_gb['f'], f_bins, labels=[i+1 for i in range(len(f_bins)-1)])# 计算F得分
rfm_gb['m_score'] = pd.cut(rfm_gb['m'], m_bins, labels=[i+1 for i in range(len(m_bins)-1)])# 计算M得分
每个rfm的过程使用了pd.cut方法,基于自定义的边界区间进行划分,labels用来显示每个离散化后的具体值。F和M的规则是值越大,等级越高;而R的规则是值越小,等级越高。因此关于R的labels的规则与F和M相反。在labels指定时需要注意,4个区间的结果是划分为3份,因此labels的数量上通过减1实现边界数量与区间数量的平衡,而i+1则实现了区间从1开始,而不是0。
计算总得分:
方法1 加权得分
#方法一:加权得分
rfm_gb = rfm_gb.apply(np.int32) # cate转数值
rfm_gb['rfm_score'] = rfm_gb['r_score'] * weights[0] + rfm_gb['f_score'] * weights[1] + rfm_gb['m_score'] * weights[2]
代码中,用rfm_gb方法将每个值转换为np.int32类型,否则上面pd.cut的实现结果是类别型结果。然后将rfm三列分别乘以权重,得到新的rfm加权得分。
方法2 RFM组合
#方法二:RFM组合
rfm_gb['r_score'] = rfm_gb['r_score'].astype(np.str)
rfm_gb['f_score'] = rfm_gb['f_score'].astype(np.str)
rfm_gb['m_score'] = rfm_gb['m_score'].astype(np.str)
rfm_gb['rfm_group'] = rfm_gb['r_score'].str.cat(rfm_gb['f_score']).str.cat(rfm_gb['m_score'])
这种方式是传统的做会员分组的方式。目标是将3列作为字符串组合为新的分组。
代码中,现针对3列使用astype方法将数值型转换为字符串类型,然后使用pandas的字符串处理库中str的cat方法做字符串合并,该方法可以将右侧的数据合并到左侧,再连续使用两个str.cat方法得到总的R、F、M字符串组合。
(7)保存结果到excel
rfm_gb.to_excel('sales_rfm_score1.xlsx')
5.案例数据结论
(1)基于图形的交互式分析
重点人群分布:先通过Excel柱形图做简单分析,在整个分组中,212群体的用户是相对集中且变化最大的。
通过下图可以发现,从2016年到2017年用户群体数量变化不大,但到2018年增长了近一倍。因此,这部分人群将作为重点分析人群。
重点分组分布:除了212人群外,下图还显示了312、213、211及112人群都在各个年份占据很大数量,虽然各自规模不大,但组合起来的总量超过212本身。因此,后期也要重点做分析。

(2)基于RFM分组结果的分析
我们打开导出的sales_rfm_score.xlsx文件,然后建立数据透视表。
步骤为:
1.单击Excel顶部菜单栏的“插入–数据透视表”,在弹窗的窗口中单击“确定”按钮
2.在新建的sheet视图中,进行如下设置:
- 将rfm_group拖入数据透视表字段区域中的“行”区块
- 将会员ID拖入数据透视表字段区域中的“值”区块
- 单击会员ID项
- 在弹出的窗口中选择“值字段设置”
- 在弹窗中选择“计算类型”为“计数”
- 单击“确定”按钮
- 鼠标左键单击“计数项:会员ID”中的任意数值,单击顶部的排序功能,按从大到小排序。
到此,数据就以RFM分组为主题,以用户数量作为分类汇总了,如图

排序后发现,会员在所有分组的分布是不均匀的,我们需要按百分数进行汇总显示,这样可以知道每个分组的占比。在透视表中的“计数项:会员ID”列单击任意数值,然后单击右键,在弹出的菜单中选择“值显示方式”,从右侧菜单中选择“父行汇总的百分比”,如图所示。

设置完成后,我们对分区用户量进行累计求和,最后发现前9个分组的用户数量占比超过95%,如图所示
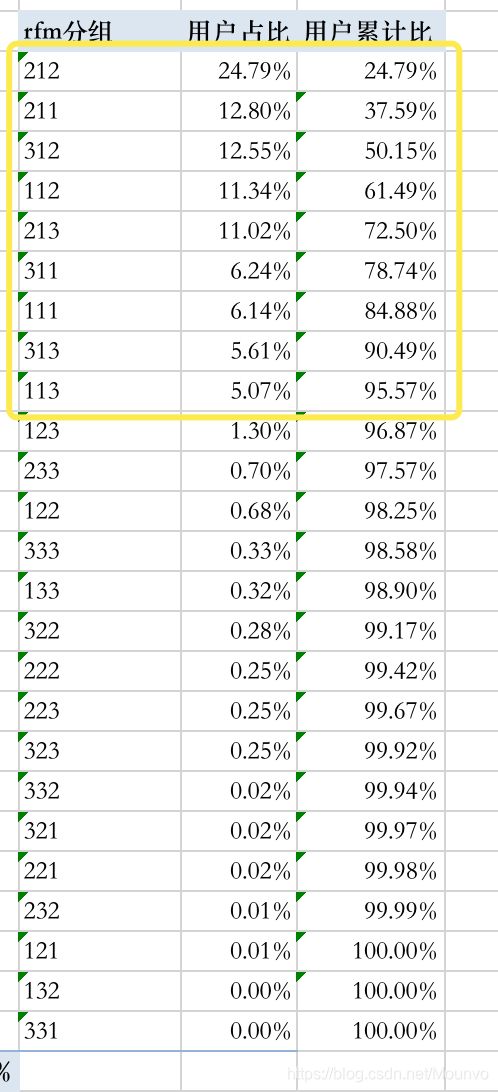
因此,我们需要把分析重点,放在这9组人群上。
(3)RFM用户特征分析 经过上面的分析,我们得到了要分析的重点客户群体。可根据用户的量级分为两类: 第1类是用户群体占比超过10%的群体;
第2类是占比在个位数的群体。
这两类人由于量级不同,因此需要分别有针对性的策略场景。
除此以外,我们还会增加第3类人群,虽然从用户量级上偏小,但是单个人的价值度非常高。
第1类人群:占比超过10%的群体。
由于这类人群基数大,必须采取批量操作和运营的方式落地运营策略,一般需要通过系统或产品实现,而不能主要依赖于人工。
212:可发展的一般性群体。这类群体购买新进度和订单金额一般,且购买频率低,考虑到其最大的群体基础,以及在新进度和订单金额上都还可以,因此可采取常规性的礼品兑换和赠送购物社区活动、签到、免运费等手段,维持并提升其消费状态。
211:可发展的低价值群体。这类群体相对于212群体,在订单金额上表现略差,因此在211群体策略的基础上,可以增加与订单相关的刺激措施,例如组合商品优惠券,发送积分购买商品等。
312:有潜力的一般性群体。这类群体购买新进度高,说明最近一次购买发生在很短时间之前,群体对于公司尚有比较熟悉的接触渠道和认知状态,购物频率低,说明对网站的忠诚度一般,订单金额处于中等层级,说明其还具有可提升的空间,因此可以借助其最近购买的商品,为其定制一些与上次购买相关的商品,通过向上销售等策略提升购买频次和订单金额。
112:可挽回的一般性群体。这类群体购买新进度较低,说明距离上次购买时间较长,很可能用户已经处于沉默或预流失流失阶段;购买频率低,说明对网站的忠诚度一般,订单金额处于中等层级,说明其还可能具有可提升的空间,因此对这部分群体的策略,首先是通过多种方式(例如邮件短信等)触达客户并挽回,然后通过针对流失客户的专享优惠(例如流失用户专享优惠券)措施促进其消费,在此过程中可增加接触频次和刺激力度的方式,增加用户的回访、复购以及订单价值回报。
213:可发展的高价值群体。这类人群发展的重点是提升购物频率,因此可指定不同的活动或事件来触达用户,促进其回访和购买,例如不同的节日活动,每周新品推送,高价值客户专享商品等。
第2类人群:占比为1%~10%的群体,这部分人群数量适中,在落地时无论是产品还是人工都可接入。
311:有潜力的低价值群体。这部分用户与211群体类似,但在购物新进度上更好,因此对其可采取相同的策略。除此以外,在这类群体的最近接触渠道上,可以增加营销或广告资源投入,通过这些渠道再次将客户引入网站完成消费。
111:这是一类在各个维度上都比较差的客户群体,一般情况下会在其他各个群体策略和管理都落地后才考虑他们。主要策略是先通过多种策略挽回客户,然后为客户推送与其类似的其他群体,或者当前热销的商品或折扣非常大的商品。在刺激消费时,可根据其消费水平、品类等情况,有针对性的设置商品暴露条件,先在优惠券及优惠商品的综合刺激下,使其实现消费,再考虑消费频率以及订单金额的提升。
313:有潜力的高价值群体。这类群体的消费新进度高且订单金额高,但购买频率低,因此只要提升其购买频次,用户群体的贡献价值就会倍增。提升购买频率上,除了在其最近一次的接触渠道上增加曝光外,与最近一次渠道相关的其他关联访问渠道也要考虑增加营销资源,另外213中的策略也要组合应用其中。
113:可挽回的高价值群体,这类群体与112群体类似,但订单金额贡献更高,因此除了应用112中的策略外,可增加部分人工的参与来挽回这些高价值客户,例如线下访谈,客户电话沟通等。
第3类群体:占比非常少,但却是非常重要的群体。
333:绝对忠诚的高价值群体。虽然用户绝对数量只有355,但由于其各方面表现非常突出,因此可以倾斜更多的资源,例如设计VIP服务、专享服务、绿色通道等。另外针对这部分人群的高价值附加服务的推荐,也是提升其价值的重点策略。
233、223、133:一般性的高价值群体。这类群体的主要着手点是提升新近购买度,及促进其实现最近一次的购买,可通过电话、客户拜访、线下访谈、微信、电子邮件等方式,直接建立用户挽回通道,以挽回这部分高价值用户。
322、323、332:有潜力的普通群体。这类群体最近刚完成购买,需要提升的是购买频次及购买金额。因此可通过交叉销售、个性化推荐、向上销售、组合优惠券、打包商品销售等策略,提升其单次购买的订单金额,及促进其重复购买。
6、案例应用和部署
针对上述得到的分析结论,会员部门采取了一下措施:
分别针对3类群体,按照公司实际运营需求和当前目标,制定了不同的群体落地的排期。
录入数据库的RFM得分数据已经应用到其他数据模型中,成为建模输入的关键维度特征之一。